一種優(yōu)化初始點(diǎn)與自適應(yīng)半徑的密度聚類(lèi)算法
2022-01-14 03:01:54王治和曹旭琰
計(jì)算機(jī)工程 2022年1期
王治和,曹旭琰,杜 輝
(西北師范大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院,蘭州 730070)
0 概述
數(shù)據(jù)挖掘是從大量數(shù)據(jù)中提取有價(jià)值信息的過(guò)程,將其轉(zhuǎn)化成人們需要的且有組織的知識(shí)信息[1-2],已在許多領(lǐng)域取得重要成果。聚類(lèi)分析是數(shù)據(jù)挖掘的重要技術(shù)之一,可以作為一種獨(dú)立的工具深入了解數(shù)據(jù)集的分布情況。其主要任務(wù)是將數(shù)據(jù)集中的每一個(gè)數(shù)據(jù)樣本劃分到相應(yīng)的簇中,使簇內(nèi)的樣本彼此相似,而簇間的樣本彼此不相似[3-4]。目前,聚類(lèi)分析已經(jīng)廣泛地應(yīng)用于圖像分析[5]、模式識(shí)別[6]、生物信息學(xué)[7]、知識(shí)發(fā)現(xiàn)[8]、醫(yī)學(xué)[9-10]和農(nóng)業(yè)[11]等領(lǐng)域。基于密度的聚類(lèi)算法是聚類(lèi)分析的重要技術(shù)之一,其中經(jīng)典算法有DBSCAN 算法[12]、OPTICS算法[13]、DENCLUE 算法[14]等。
文獻(xiàn)[12]提出的DBSCAN 算法,聚類(lèi)初始點(diǎn)是從數(shù)據(jù)集中任意取出一個(gè)樣本,判斷其為核心點(diǎn)后開(kāi)始聚類(lèi),增加了算法的時(shí)間開(kāi)銷(xiāo)。該算法中的Eps和MinPts 是全局參數(shù),在聚類(lèi)過(guò)程中不能改變,所以不能正確聚類(lèi)密度不均勻的數(shù)據(jù)集。因此,如何恰當(dāng)?shù)剡x擇聚類(lèi)的初始點(diǎn)和Eps 值是提高聚類(lèi)準(zhǔn)確度的關(guān)鍵因素,很多學(xué)者對(duì)此做了大量研究和改進(jìn)。文獻(xiàn)[13]提出OPTICS 算法,該算法并不產(chǎn)生數(shù)據(jù)集聚類(lèi),而是輸出一個(gè)表示數(shù)據(jù)的基于密度的聚類(lèi)結(jié)構(gòu)的簇排序,克服了使用一組全局參數(shù)的缺點(diǎn)。但這種總是朝高密度區(qū)域擴(kuò)張的策略,使那些無(wú)法連向下一個(gè)高密度區(qū)域的低密度點(diǎn)往往被累積在結(jié)果序列的末尾,導(dǎo)致這些低密度點(diǎn)與高密度點(diǎn)的相鄰關(guān)系在映射時(shí)被分離[15]。文 獻(xiàn)[16]提出的OSDBSCAN 算法優(yōu)化了初始點(diǎn)的選擇,并結(jié)合數(shù)據(jù)集的特點(diǎn)自適應(yīng)計(jì)算Eps 和MinPts 值,但是引入了聚類(lèi)個(gè)數(shù)k、密度參數(shù)α、倍率參數(shù)β3 個(gè)參數(shù),不僅沒(méi)有減少人為干預(yù),而且?guī)?lái)更大的復(fù)雜性。文獻(xiàn)[17]提出VDBSCAN 算法,該算法能夠聚類(lèi)密度不同的數(shù)據(jù)集,求每個(gè)數(shù)據(jù)樣本的第k個(gè)近鄰,利用k-dist 圖選取不同密度層次相應(yīng)的Eps 值,但是選取過(guò)程需要人為干預(yù),存在很大的不確定性。文獻(xiàn)[18]提出RNN-DBSCAN 算法,使用反向最近鄰(RNN)的思想來(lái)定義密度和核心樣本,但整體的聚類(lèi)效果不佳且運(yùn)行時(shí)間較長(zhǎng)。文獻(xiàn)[19]提出ADBSCAN 算法,利用最近鄰圖(NNG)固有的性質(zhì)來(lái)識(shí)別局部高密度樣本,運(yùn)用密度估計(jì)對(duì)噪聲樣本進(jìn)行濾波,但在某些情況下,該算法有時(shí)無(wú)法識(shí)別正確的簇?cái)?shù),而且需要對(duì)多個(gè)參數(shù)組合進(jìn)行測(cè)試。
通過(guò)上述研究發(fā)現(xiàn),RNN 算法對(duì)獲取全局密度最大的數(shù)據(jù)樣本起到重要作用,解決了DBSCAN 算法隨機(jī)取初始點(diǎn)的問(wèn)題。本文提出一種新的OIRDBSCAN 算法,借鑒OPTICS 算法中核心距離和可達(dá)距離的思路,通過(guò)調(diào)整核心距離和可達(dá)距離的值得到適合該簇的半徑r,以解決DBSCAN 算法中Eps是全局參數(shù)的問(wèn)題。
1 相關(guān)工作
1.1 DBSCAN 算法
DBSCAN 算法可以發(fā)現(xiàn)任意形狀的簇,并識(shí)別噪點(diǎn),不需要設(shè)定具體的簇?cái)?shù),聚類(lèi)效果穩(wěn)定。在Eps 鄰域、MinPts 密度閾值、核心點(diǎn)、直接密度可達(dá)、密度可達(dá)的基礎(chǔ)上設(shè)定了密度相連[20]概念。
DBSCAN 算法從任意一個(gè)點(diǎn)p出發(fā),先判斷其是否是核心點(diǎn),若是,尋找Eps 鄰域內(nèi)與p直接密度可達(dá)的點(diǎn),將這些點(diǎn)放入集合U中,然后遍歷集合U中的所有核心點(diǎn),尋找與它們密度可達(dá)的點(diǎn),迭代上述步驟,直到集合U中沒(méi)有可擴(kuò)展的核心點(diǎn),此時(shí)形成了一個(gè)完整的簇;若不是,暫時(shí)將其標(biāo)注為噪點(diǎn)。聚類(lèi)完成其中的一個(gè)簇后,對(duì)未遍歷的數(shù)據(jù)點(diǎn)重復(fù)上述過(guò)程,進(jìn)行其他簇的擴(kuò)展,直至所有的點(diǎn)被遍歷。其中既不是核心點(diǎn)也不是邊界點(diǎn)的被稱(chēng)為噪點(diǎn)。
1.2 點(diǎn)x 的k 近鄰和反向最近鄰
假設(shè)X是d維空間中的數(shù)據(jù)點(diǎn)集,用n表示X的大小,n=|X|。?x∈X,x∈Rd。對(duì)于X中的任意兩個(gè)點(diǎn)x和y,用表示兩點(diǎn)之間的距離,其中k的取值范圍為1≤k≤n-1。
定義1點(diǎn)x的k近鄰用Nk(x)=N表示,其中N滿(mǎn)足以下條件:
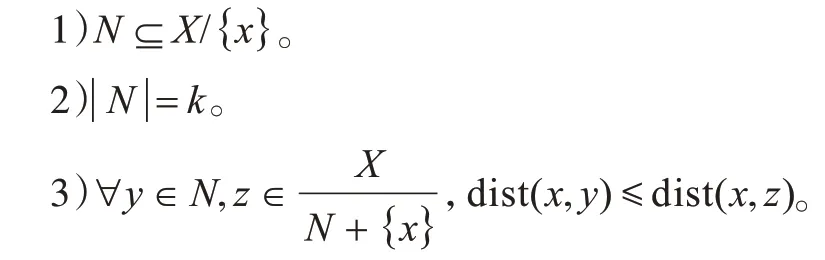
定義2點(diǎn)x的反向最近鄰用Rk(x)=R表示,其中R滿(mǎn)足以下條件:
1)R?X/{x}。
2)?y∈R:x∈Nk(y)。
下文用具體的示例對(duì)上述定義做出解釋?zhuān)摂?shù)據(jù)集共有5 個(gè)點(diǎn),如圖1 所示。
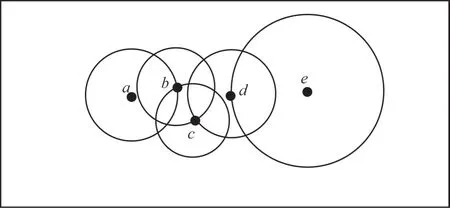
圖1 二維空間5 個(gè)數(shù)據(jù)點(diǎn)的最近鄰圖Fig.1 Nearest neighbor graph of five data points in two-dimensional space
從圖1可以看出:a點(diǎn)的最近鄰是b,b點(diǎn)和c點(diǎn)互為最近鄰,d點(diǎn)的最近鄰是c,以此類(lèi)推。在k近鄰中,k取1 時(shí)為最近鄰點(diǎn),k取2 時(shí)為第二近鄰點(diǎn),k取n(n為正整數(shù))時(shí)為第n個(gè)近鄰點(diǎn)。圖1 的最近鄰表如表1 所示,取k=1。對(duì)于反向最近鄰,需要滿(mǎn)足定義2 的2 個(gè)條件,具體分析如表2 所示。

表1 二維空間5 個(gè)數(shù)據(jù)點(diǎn)的最近鄰表Table 1 Nearest neighbor table of five data points in two-dimensional space
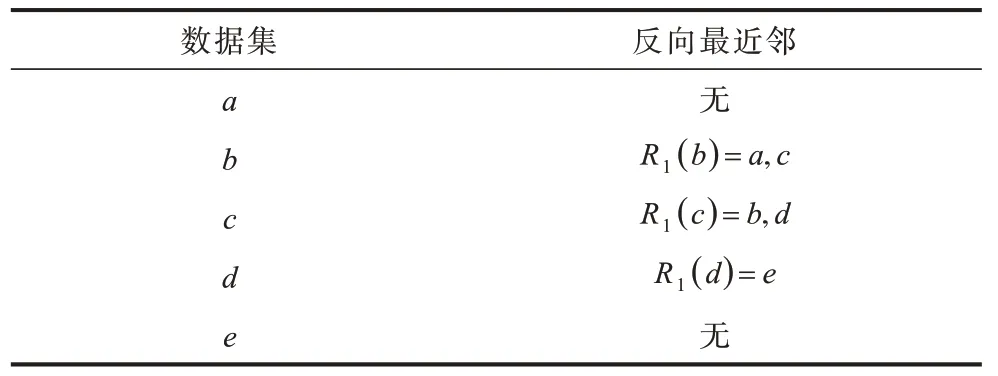
表2 二維空間5 個(gè)數(shù)據(jù)點(diǎn)的反向最近鄰表Table 2 Reverse nearest neighbor table of five data points in two-dimensional space
反向最近鄰表如表2 所示,其中以點(diǎn)b為例進(jìn)行分析。點(diǎn)c滿(mǎn)足?x∈X:dist(b,c)≤dist(c,x),所以c是b的反向最近鄰點(diǎn),a同理,滿(mǎn)足?x∈X:dist(b,a)≤dist(a,x),所以a也是b的反向最近鄰點(diǎn)。其他點(diǎn)的分析方法類(lèi)似。
2 OIR-DBSCAN 算法
2.1 設(shè)計(jì)方法
首先尋找數(shù)據(jù)集中全局密度最大的數(shù)據(jù)樣本,將該樣本作為聚類(lèi)初始點(diǎn),然后用自適應(yīng)半徑的方法計(jì)算出該初始點(diǎn)所在簇相應(yīng)的r值。以該樣本為初始點(diǎn),r值為半徑開(kāi)始聚類(lèi)。當(dāng)一個(gè)簇聚類(lèi)完成后,再?gòu)氖S嗟臄?shù)據(jù)樣本中選出新的聚類(lèi)初始點(diǎn),迭代上述過(guò)程,直至所有數(shù)據(jù)樣本被劃分類(lèi)別或有部分?jǐn)?shù)據(jù)樣本被當(dāng)作噪聲處理,聚類(lèi)結(jié)束。
2.2 初始點(diǎn)優(yōu)化
在K-means 算法中初始點(diǎn)的優(yōu)化對(duì)算法的改進(jìn)尤為重要。盡管DBSCAN 算法中初始點(diǎn)的優(yōu)化對(duì)聚類(lèi)結(jié)果的影響不太明顯,但從算法的角度考慮,如果初始點(diǎn)選擇的是全局密度最大的點(diǎn),那么該點(diǎn)一定是核心點(diǎn),可以省去判斷某個(gè)點(diǎn)是否是核心點(diǎn)的時(shí)間。本文從文獻(xiàn)[16,18]中得到啟發(fā),改進(jìn)的算法能夠找到數(shù)據(jù)集中全局密度最大的點(diǎn)。
在初始點(diǎn)優(yōu)化思路中,運(yùn)用到1.2 節(jié)中提到的k近鄰算法和反向最近鄰。從表2 可以看出,a點(diǎn)和e點(diǎn)無(wú)反向最近鄰,b點(diǎn)的反向最近鄰是a和c,c點(diǎn)的反向最近鄰是b和d。也可以理解為:a和e沒(méi)有出現(xiàn)在任何點(diǎn)的好友圈中,而b出現(xiàn)在a和c的好友圈中,c出現(xiàn)在b和d的好友圈中,d出現(xiàn)在e的好友圈中。可以看出b和c在好友圈的活躍程度最高,在一定程度上證明其周?chē)鷶?shù)據(jù)點(diǎn)的密度較高。
首先根據(jù)反向最近鄰表計(jì)算出每個(gè)點(diǎn)反向最近鄰的個(gè)數(shù)m,m越大,意味著該點(diǎn)的活躍度越高,越有可能成為初始點(diǎn)。但是要計(jì)算出最終的聚類(lèi)初始點(diǎn),不能只根據(jù)m值,需要考慮下面這種情況,如圖2 所示(設(shè)k=1)。
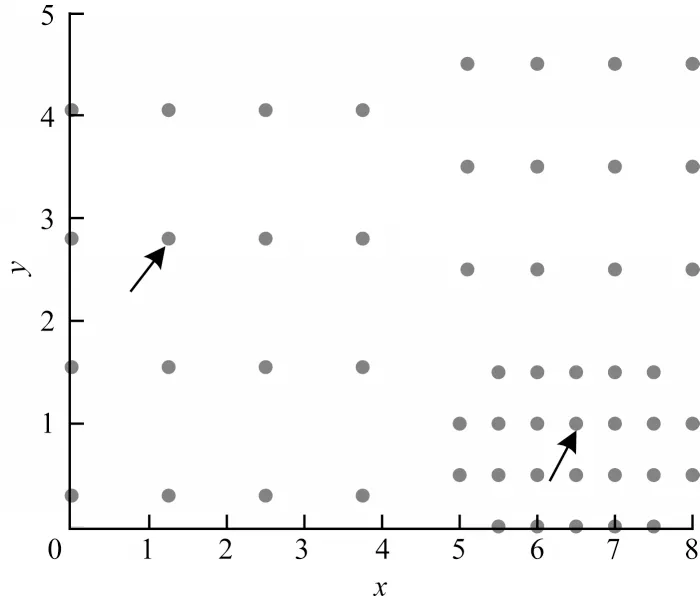
圖2 52 個(gè)數(shù)據(jù)樣本考慮m 值的示意圖Fig.2 Fifty-two data samples only consider the schematic diagram of m value
觀察箭頭所指的兩個(gè)點(diǎn),通過(guò)計(jì)算得出它們的反向最近鄰個(gè)數(shù)m均等于4。那么如果只考慮m,則兩者大小一樣。但圖2 中右下角箭頭所指的點(diǎn)所在簇的密度顯然大于左上角中箭頭所指的點(diǎn)所在簇的密度。因此,不能只考慮m的取值,還應(yīng)該考慮該點(diǎn)與k個(gè)鄰近距離和的大小,記為dist。dist 越大,密度越小;反之dist 越小,密度越大。
設(shè)數(shù)據(jù)集的相似度矩陣為MMatrix,相似度矩陣用歐式距離表示,每行按從小到大排序后,去除第一列的零元素,記為KNNMatrix。每個(gè)數(shù)據(jù)樣本對(duì)應(yīng)的m值記為minit。VValue(init)的大小決定該init 點(diǎn)是否可以作為聚類(lèi)初始點(diǎn),值越小,表明該點(diǎn)越適合作為聚類(lèi)初始點(diǎn);反之,不適合。因此,聚類(lèi)初始點(diǎn)的判別公式如式(1)所示:
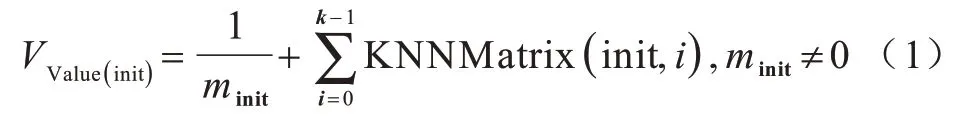
將當(dāng)前最小的VValue(init)值對(duì)應(yīng)的init 作為聚類(lèi)初始點(diǎn)。當(dāng)一個(gè)簇聚類(lèi)完成后,將已經(jīng)有聚類(lèi)標(biāo)簽的點(diǎn)從候選init 隊(duì)列中刪除,方便重新選出下一次聚類(lèi)的初始點(diǎn)。
初始點(diǎn)的選擇如圖3 所示,數(shù)據(jù)集的初始點(diǎn)依次為三角形、六邊形和五角星所在的點(diǎn)。
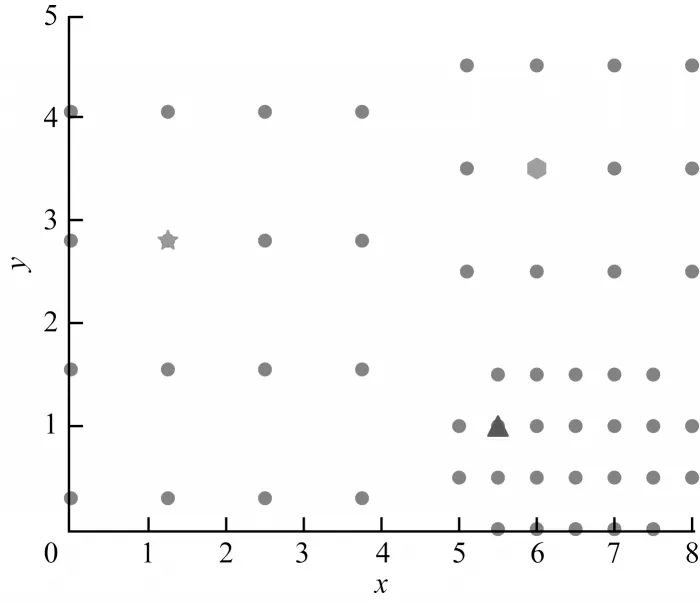
圖3 52 個(gè)數(shù)據(jù)樣本初始點(diǎn)示意圖Fig.3 Schematic diagram of initial points of fifty-two data samples
初始點(diǎn)的優(yōu)化算法如算法1 所示。
算法1初始點(diǎn)優(yōu)化
輸入k(k=4)
輸出init
步驟1求出各個(gè)樣本之間的相似度矩陣MMatrix,用歐式距離表示。
步驟2對(duì)Matrix 按行升序排序,去掉第一列的0 元素,得到矩陣KNNMatrix。
步驟3計(jì)算每個(gè)樣本的反向最近鄰個(gè)數(shù)m。
步驟4計(jì)算每個(gè)樣本的k個(gè)近鄰的距離和dist。將該樣本的序號(hào)、步驟4 計(jì)算出的dist 值和步驟3 計(jì)算出的m放入列表RNNDist 中。
步驟5計(jì)算RNNDist列表中每個(gè)對(duì)象的VValue(init)值,參考式(1),按升序排列,得到列表SortRnnDist。
步驟6取SortRnnDist 列表的第一個(gè)值對(duì)應(yīng)的init 為聚類(lèi)初始點(diǎn)。
步驟7從第一個(gè)初始點(diǎn)開(kāi)始的聚類(lèi)結(jié)束后,將已經(jīng)有標(biāo)簽的樣本從SortRnnDist 列表中刪除,重復(fù)步驟6,選取下一次的聚類(lèi)初始點(diǎn),重復(fù)步驟7,迭代直至聚類(lèi)結(jié)束。
2.3 自適應(yīng)半徑r
在傳統(tǒng)的DBSCAN 算法中,Eps 在聚類(lèi)過(guò)程中不能改變。如果Eps 取值太小,將會(huì)導(dǎo)致數(shù)據(jù)集被分割成多個(gè)簇;如果Eps 取值太大,將會(huì)出現(xiàn)多個(gè)簇被合并的現(xiàn)象。無(wú)論哪種情況,都不能對(duì)有密度變化的數(shù)據(jù)集進(jìn)行正確聚類(lèi)。為克服上述困難,引入以下3 個(gè)概念:
1)核心距離。對(duì)象p的核心距離ε'是使得p的ε'-領(lǐng)域內(nèi)至少有k個(gè)對(duì)象,即ε'是使得p成為核心對(duì)象的最小半徑閾值。對(duì)于數(shù)據(jù)集中的任意一個(gè)對(duì)象,每個(gè)對(duì)象p的ε'都不同。如圖3 所示,五角星點(diǎn)的ε'=0.5;六邊形點(diǎn)的ε'=1;三角形點(diǎn)的ε'=1.25。
2)ε距離。ε的取值是一個(gè)全局的參數(shù),由用戶(hù)設(shè)定,如圖4 所示,取ε=1。
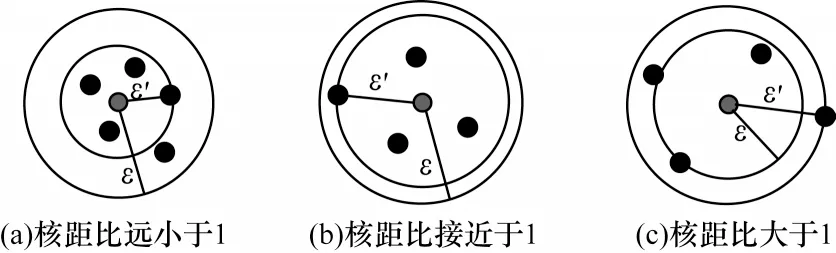
圖4 核距比之間的關(guān)系Fig.4 Relationship of kernel’s distance radio
3)核距比。表示核心距離ε'與ε距離的比值,核距比在一定程度上可以反映數(shù)據(jù)點(diǎn)分布的疏密情況。
在圖4 中,圖4(a)和圖4(b)的核距比均小于1,其中圖4(a)的核距比最小,得出數(shù)據(jù)之間的密度分布緊湊;圖4(b)的核距比幾乎為1,數(shù)據(jù)之間的密度分布適中;圖4(c)的核距比大于1,明顯數(shù)據(jù)較分散。但是對(duì)于核距比大于1 的數(shù)據(jù)點(diǎn),存在是噪點(diǎn)的可能性,需要做進(jìn)一步的判斷。
設(shè)置一個(gè)參數(shù)α用來(lái)與核距比作比較,α設(shè)定的大小可以對(duì)自適應(yīng)半徑r的調(diào)節(jié)起到伸縮作用。α越小,半徑r可調(diào)整的伸縮性越大;反之,伸縮性越小。自適應(yīng)半徑r的判斷如圖5 所示。
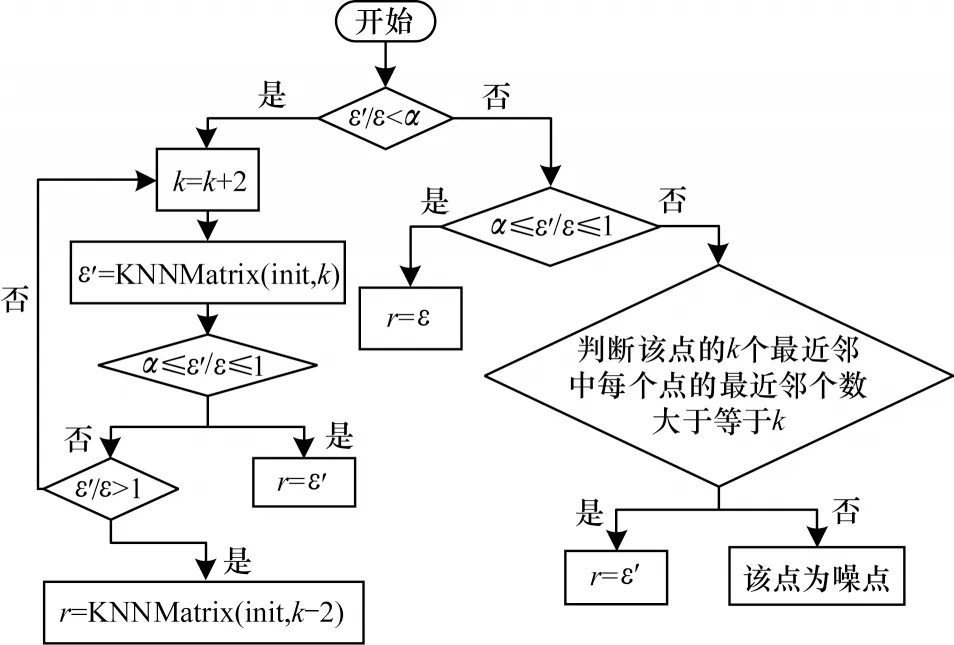
圖5 自適應(yīng)半徑流程Fig.5 Procedure of self-adapting radius
從圖5 可以看出,r的選擇有如下3 種情況:
1)數(shù)據(jù)對(duì)象的密度緊密,當(dāng)核距比遠(yuǎn)小于α?xí)r,如果直接取r=ε',那么半徑r取值太小,會(huì)導(dǎo)致本屬于同一個(gè)簇的數(shù)據(jù)點(diǎn)被分割成多個(gè)簇。所以,采用圖5 中適當(dāng)增大ε'的方法重新計(jì)算核距比,使得α落在規(guī)定區(qū)間,此時(shí)取r=ε'。
2)數(shù)據(jù)對(duì)象的密度適中,當(dāng)核距比正好落在α規(guī)定區(qū)間時(shí),直接取r=ε。因?yàn)榇藭r(shí)ε和ε'的大小相差甚微,所以選取值較大的ε,加快聚類(lèi)速度。
3)數(shù)據(jù)對(duì)象的密度稀疏,當(dāng)核距比遠(yuǎn)大于α?xí)r,如果直接判斷為噪點(diǎn),那么可能會(huì)忽略如圖2 所示的左邊簇的情況。所以,判斷該數(shù)據(jù)對(duì)象的ε'鄰域中的每個(gè)點(diǎn)是否有大于等于k個(gè)未被標(biāo)識(shí)的對(duì)象,若有,則說(shuō)明該點(diǎn)附近只是密度稀疏,并不是噪點(diǎn),取r=ε';反之,則為噪點(diǎn)。
2.4 算法描述
通過(guò)上述初始值的選取和半徑的判定,得到init和r值,然后采用密度聚類(lèi)的方法進(jìn)行聚類(lèi)。第一次聚類(lèi)結(jié)束之后,從剩余未被標(biāo)記的數(shù)據(jù)樣本中選出第二次聚類(lèi)的初始點(diǎn)init′和半徑r′,進(jìn)行第二次聚類(lèi)、迭代,直至所有數(shù)據(jù)樣本被劃分類(lèi)別或有部分?jǐn)?shù)據(jù)做噪聲處理。
對(duì)于數(shù)據(jù)集X中的每個(gè)樣本x,標(biāo)簽用cluster表示,聚類(lèi)過(guò)的樣本添加到visited 列表中,未被聚類(lèi)的樣本存放在unvisited 列表中,將聚類(lèi)結(jié)果存放在數(shù)組assign中。OIR-DBSCAN 算法的流程如算法2 所示。
算法2OIR-DBSCAN 算法
輸入數(shù)據(jù)集dataset
輸出assign
步驟1對(duì)數(shù)據(jù)集作歸一化處理。
步驟2根據(jù)算法1 計(jì)算出初始點(diǎn)init。
步驟3根據(jù)圖5 的流程圖計(jì)算出自適應(yīng)半徑r。
步驟4通過(guò)DBSCAN 算法,將和初始點(diǎn)init 屬于同一類(lèi)的數(shù)據(jù)樣本劃分出來(lái),cluster 加1。
步驟5執(zhí)行步驟2、步驟3。
步驟6用步驟4 的方法對(duì)剩余點(diǎn)聚類(lèi)。
步驟7迭代,直至所有數(shù)據(jù)被聚類(lèi)或部分?jǐn)?shù)據(jù)被當(dāng)作噪聲處理。
2.5 參數(shù)選擇
算法中k值是固定參數(shù),取值為4,k主要用來(lái)控制核心距離ε',進(jìn)而影響半徑r。參數(shù)ε人為設(shè)定。α的大小可以對(duì)自適應(yīng)半徑r的調(diào)節(jié)起到伸縮作用,經(jīng)大量實(shí)驗(yàn)測(cè)試,α的取值范圍是0.25~0.8。參數(shù)MinPts 和DBSCAN 算法中的MinPts 一樣,用來(lái)控制核心點(diǎn)的判斷。雖然該參數(shù)也是人為設(shè)定的參數(shù),但經(jīng)過(guò)大量實(shí)驗(yàn)論證,取值范圍一般為3~15,且為正整數(shù)。
3 實(shí)驗(yàn)結(jié)果與分析
為對(duì)本文算法性能進(jìn)行評(píng)估,檢測(cè)其有效性,本文進(jìn)行以下對(duì)比實(shí)驗(yàn)。對(duì)比算法包括DBSCAN 算法、OPTICS 算法和RNN-DBSCAN 算法。數(shù)據(jù)集采用人工數(shù)據(jù)集和真實(shí)數(shù)據(jù)集,人工數(shù)據(jù)集包括Compound、Pathbased、Jain、Aggregation、grid.orig;真實(shí)數(shù)據(jù)集包括iris、WBC、Thyroid、Ecoli、Pima、Vote、Vowel 等。其中人工數(shù)據(jù)集如表3 所示。
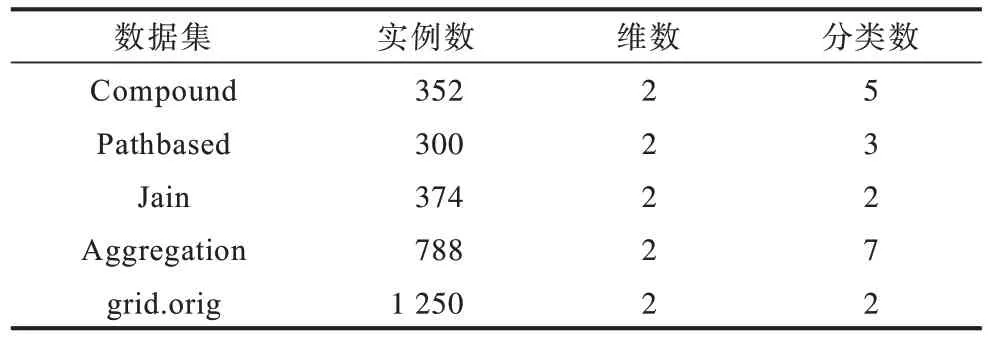
表3 人工數(shù)據(jù)集Table 3 Artificial datasets
實(shí)驗(yàn)環(huán)境為Inter?CoreTMi7-1065G7 CPU@1.30 GHz 1.50 GHz,內(nèi)存為16 GB,編程環(huán)境為python3.8,編譯器為Jupter Notebook、PyCharm。
聚類(lèi)的評(píng)價(jià)指標(biāo)選用調(diào)整蘭德指數(shù)(ARI)[21]、歸一化交互信息(NMI)[22]、同質(zhì)性指標(biāo)(homogeneity)、完整性指標(biāo)(completeness)和同質(zhì)性與完整性的調(diào)和平均(V-measure)[23]。
ARI 是調(diào)整的RI,相對(duì)RI 來(lái)說(shuō)有更高的區(qū)分度。ARI 的取值范圍是[-1,1],數(shù)值越接近1 代表聚類(lèi)結(jié)果越好,越接近0 代表聚類(lèi)結(jié)果越差,計(jì)算公式如式(2)所示:

其中:max 表示取最大值;E表示期望。
ARI 計(jì)算公式如式(3)所示:
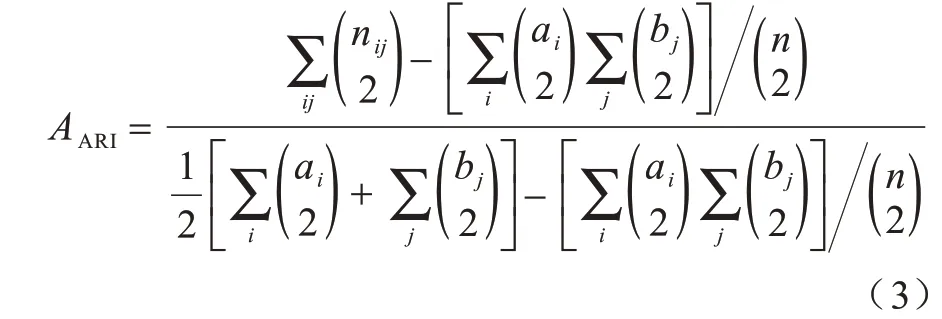
其中:i、j分別表示為真實(shí)簇類(lèi)和預(yù)測(cè)簇類(lèi);nij表示聚類(lèi)正確的樣本個(gè)數(shù);max(RI)表示如果聚類(lèi)結(jié)果完全正確時(shí)的值;E[RI]表示求RI 的期望值。
NMI 是一個(gè)外部指標(biāo),通過(guò)將聚類(lèi)結(jié)果與“真實(shí)”的類(lèi)標(biāo)簽對(duì)比衡量聚類(lèi)效果,如式(4)所示:
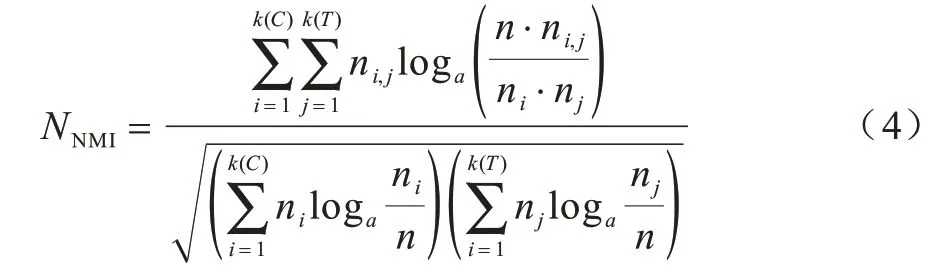
其中:k(C)是聚類(lèi)結(jié)果的簇?cái)?shù);k(T)是真實(shí)聚類(lèi)結(jié)果的簇?cái)?shù);ni是簇i的樣本個(gè)數(shù);nj是簇j的樣本個(gè)數(shù);ni,j是聚類(lèi)結(jié)果C中屬于簇i的樣本與真實(shí)聚類(lèi)結(jié)果T中屬于簇j的樣本之間的樣本個(gè)數(shù);n是數(shù)據(jù)集的樣本總數(shù)。
同質(zhì)性h表示每個(gè)簇只包含單一類(lèi)別成員的程度;完整性c表示一個(gè)給定類(lèi)的所有成員分配到單一簇的程度;V-measure 表示兩者的調(diào)和平均。其中同質(zhì)性和完整性如式(5)和式(6)所示:

其中:H(C|K)是給定簇。
類(lèi)的條件熵如式(7)所示:
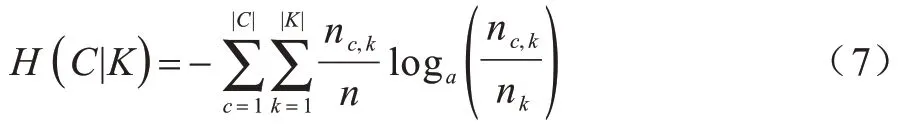
H(C)是類(lèi)的熵,計(jì)算公式如式(8)所示:
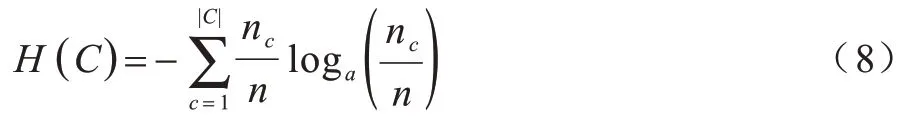
其中:n表示數(shù)據(jù)集的樣本總數(shù);nc和nk分別表示屬于簇c和簇k的樣本數(shù);nc,k為類(lèi)c中的樣本分配給簇k的數(shù)量。
V-measure 的表達(dá)式如式(9)所示:

3.1 人工數(shù)據(jù)集
本組實(shí)驗(yàn)用上述提及的5 個(gè)人工數(shù)據(jù)集進(jìn)行測(cè)試,聚類(lèi)結(jié)果如圖6~圖10 所示。Compound 數(shù)據(jù)集中有若干個(gè)密度不同的簇,圖6 的實(shí)驗(yàn)結(jié)果表明,只有本文提出的OIR-DBSCAN 算法能得到正確的聚類(lèi)結(jié)果,而DBSCAN 算法中由于Eps 參數(shù)的局限性,誤將左上角的簇當(dāng)作噪點(diǎn)處理,OPTICS 算法和RNN-DBSCAN 算法的聚類(lèi)結(jié)果差強(qiáng)人意;在圖7中,數(shù)據(jù)集的分布較為松散且密度分布無(wú)規(guī)律,DBSCAN 算法、OPTICS 算法和RNN-DBSCAN 算法在聚類(lèi)內(nèi)部簇的過(guò)程中都會(huì)將最外層的數(shù)據(jù)樣本聚類(lèi)進(jìn)來(lái),導(dǎo)致一個(gè)簇中出現(xiàn)了很多本不屬于該簇的數(shù)據(jù)樣本,而OIR-DBSCAN 算法通過(guò)對(duì)核心距離和ε距離的調(diào)整計(jì)算出合適的半徑r,從而進(jìn)一步得到較好的聚類(lèi)結(jié)果;在圖8 中,上下兩個(gè)簇有較大的密度差異,DBSCAN 算法中若Eps 取值小,則上面的簇會(huì)被分割成幾部分,如圖8(a)所示,RNN-DBSCAN算法和OPTICS 算法在聚類(lèi)過(guò)程中將一個(gè)簇分成兩個(gè),聚類(lèi)效果較差,只有OIR-DBSCAN 算法能得到正確的聚類(lèi)結(jié)果;在圖9 中,數(shù)據(jù)樣本的密度分布相對(duì)均勻,部分簇之間相連,經(jīng)過(guò)聚類(lèi)結(jié)果分析發(fā)現(xiàn)4 種算法都有不錯(cuò)的聚類(lèi)效果,其中OIR-DBSCAN聚類(lèi)結(jié)果最好,RNN-DBSCAN 算法次之,OPTICS 算法相對(duì)最差;在圖10 中,簇內(nèi)樣本分布均勻,但兩個(gè)簇的密度差異大且簇間距離很近,這種數(shù)據(jù)集最能充分體現(xiàn)出OIR-DBSCAN 算法的優(yōu)越性,該算法針對(duì)不同密度的簇自適應(yīng)地計(jì)算出不同的半徑r進(jìn)行聚類(lèi),得到了較好的聚類(lèi)結(jié)果,而DBSCAN 算法和OPTICS 算法在聚類(lèi)右下角的簇時(shí),將離該簇最近但本屬于左簇的部分?jǐn)?shù)據(jù)樣本聚類(lèi)進(jìn)來(lái),得到了錯(cuò)誤的聚類(lèi)結(jié)果,RNN-DBSCAN 算法的聚類(lèi)結(jié)果最差。

圖6 4 種算法在Compound 數(shù)據(jù)集上的聚類(lèi)結(jié)果Fig.6 Clustering results of four algorithms on Compound dataset
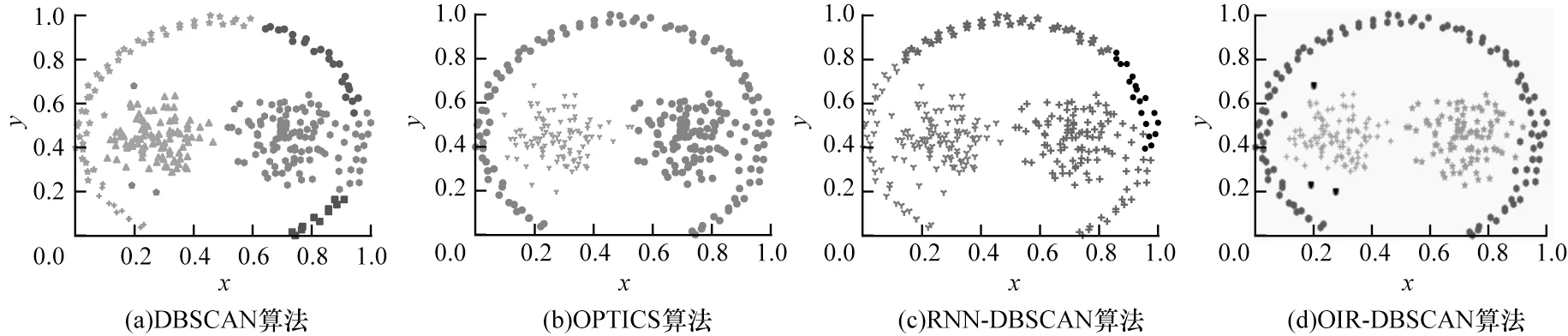
圖7 4 種算法在Pathbased 數(shù)據(jù)集上的聚類(lèi)結(jié)果Fig.7 Clustering results of four algorithms on Pathbased dataset
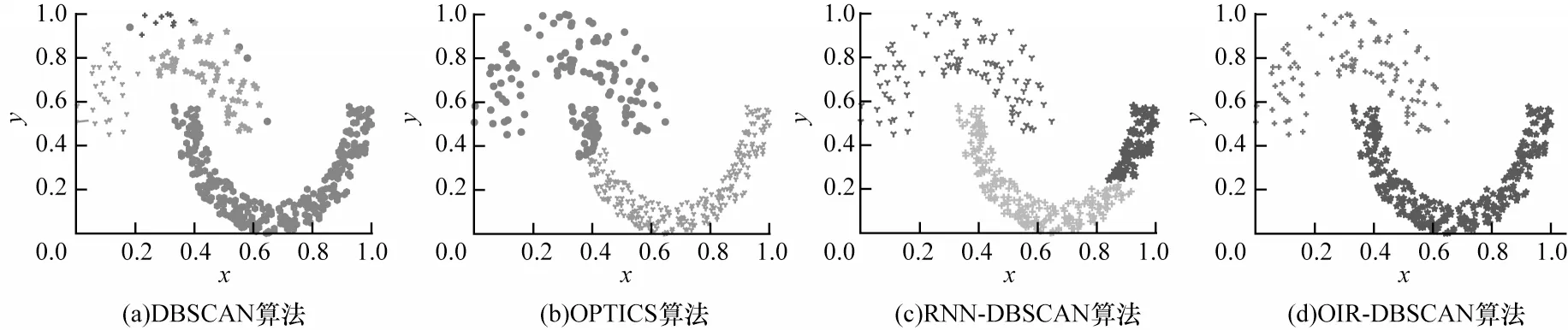
圖8 4 種算法在Jain 數(shù)據(jù)集上的聚類(lèi)結(jié)果Fig.8 Clustering results of four algorithms on Jain dataset

圖9 4 種算法在Aggregation 數(shù)據(jù)集上的聚類(lèi)結(jié)果Fig.9 Clustering results of four algorithms on Aggregation dataset

圖10 4 種算法在grid.orig 數(shù)據(jù)集上的聚類(lèi)結(jié)果Fig.10 Clustering results of four algorithms on grid.orig dataset
通過(guò)圖6~圖10 所示的可視化對(duì)比實(shí)驗(yàn)分析可以得到,在Aggregation 等數(shù)據(jù)集上,其中一部分算法也可以達(dá)到較好的聚類(lèi)效果。但總體來(lái)說(shuō),無(wú)論是密度不均勻的數(shù)據(jù)集還是普通數(shù)據(jù)集,OIRDBSCAN 算法都能夠得到很好的聚類(lèi)結(jié)果。4 個(gè)聚類(lèi)算法在人工數(shù)據(jù)集上性能的對(duì)比如表4 所示(粗體為最優(yōu)值)。4 種算法在聚類(lèi)過(guò)程中達(dá)到最優(yōu)效果的具體參數(shù)取值如表5 所示。

表5 4 種算法在人工數(shù)據(jù)集上的參數(shù)值Table 5 Parameter values of four algorithms on artificial datasets
3.2 真實(shí)數(shù)據(jù)集
在人工數(shù)據(jù)集上,OIR-DBSCAN 算法表現(xiàn)出較好的聚類(lèi)結(jié)果。為進(jìn)一步驗(yàn)證其聚類(lèi)性能,還需要在真實(shí)數(shù)據(jù)集上進(jìn)行驗(yàn)證,UCI 數(shù)據(jù)集如表6所示。
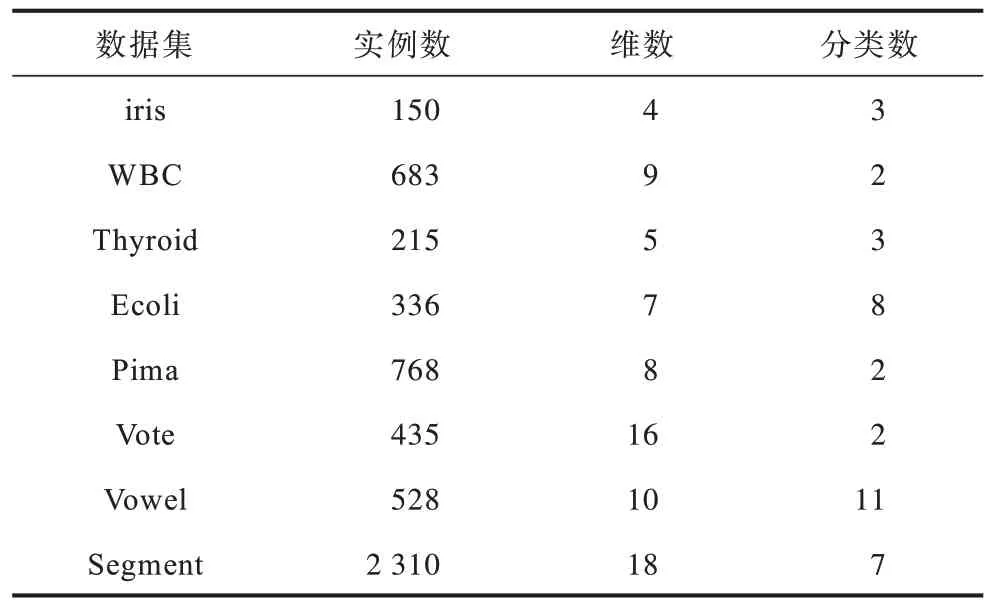
表6 UCI 數(shù)據(jù)集Table 6 UCI datasets
在UCI 數(shù)據(jù)集中,因?yàn)楦呔S數(shù)據(jù)集可視化難度較大,所以通過(guò)聚類(lèi)評(píng)價(jià)指標(biāo)ARI、NMI、homogeneity、completeness 和V-measure 進(jìn)行對(duì)比,聚類(lèi)評(píng)價(jià)指標(biāo)的對(duì)比結(jié)果如表7 所示(粗體為最優(yōu)值)。在Pima 數(shù)據(jù)集中,DBSCAN 算法的NMI 值高于OIR-DBSCAN算法0.006 9,在Vote 數(shù)據(jù)集中,DBSCAN 算法的NMI 值高于OIR-DBSCAN算法0.013 9,但從整體對(duì)比結(jié)果來(lái)看,OIR-DBSCAN 算法的ARI、NMI 等評(píng)價(jià)指標(biāo)都明顯高于其他聚類(lèi)算法。通過(guò)比較發(fā)現(xiàn),OIR-DBSCAN 算法的聚類(lèi)效果最好,DBSCAN 算法和OPTICS 算法次之,RNN-DBSCAN 算法效果相對(duì)最不理想。
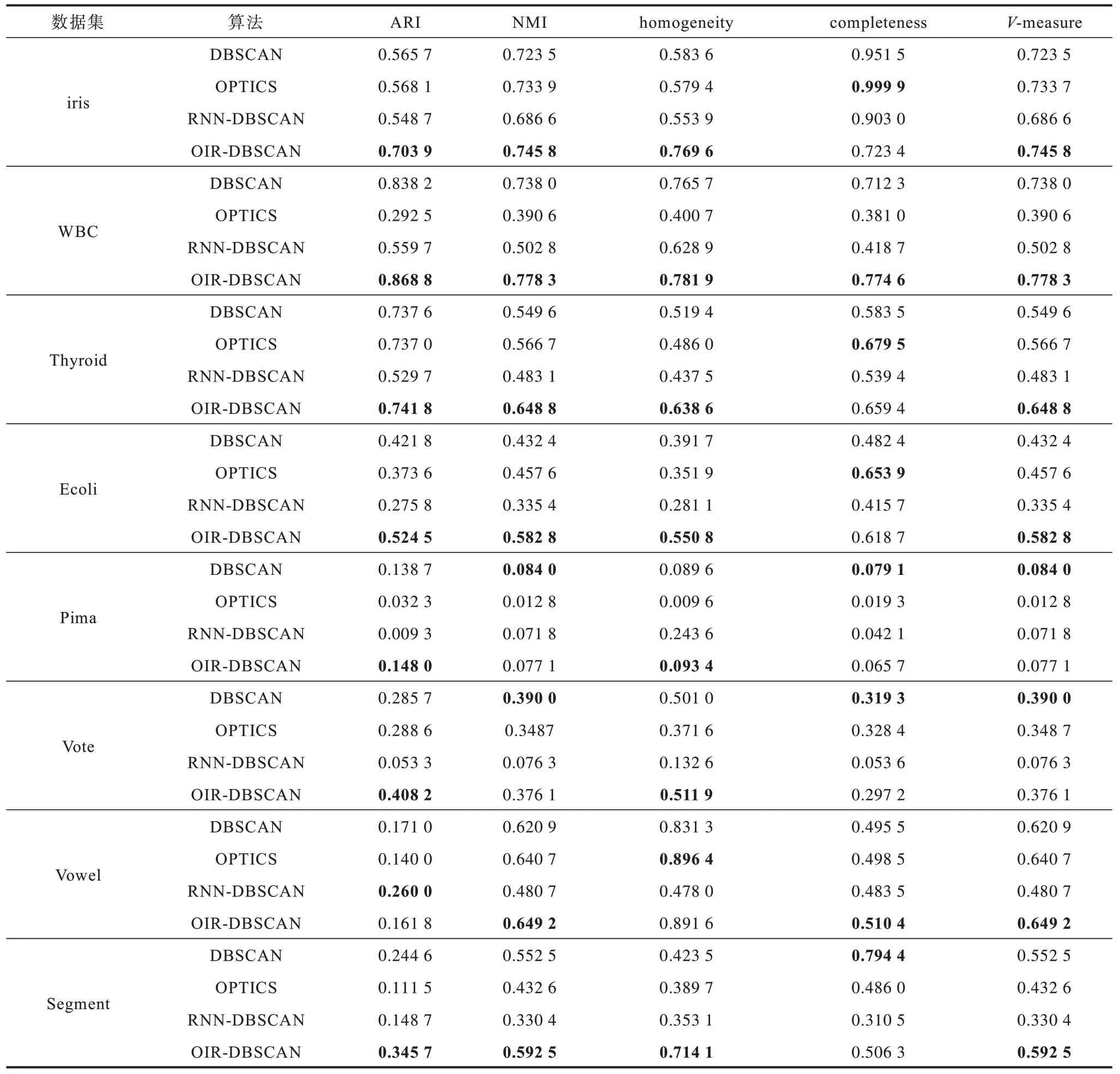
表7 4 種算法在UCI 數(shù)據(jù)集上的評(píng)價(jià)指標(biāo)對(duì)比Table 7 Comparison of evaluation index of four algorithms on UCI dataset
4 結(jié)束語(yǔ)
本文提出一種優(yōu)化初始點(diǎn)與自適應(yīng)半徑的密度聚類(lèi)算法。將反向最近鄰和相似度矩陣相結(jié)合,迭代選取每次聚類(lèi)開(kāi)始的初始點(diǎn),該初始點(diǎn)即為全局密度最大的樣本。優(yōu)化DBSCAN 算法中Eps 全局參數(shù),調(diào)整核心距離ε'和ε距離之間的核距比與參數(shù)α得出最終半徑值r,使得密度稀疏的簇和密度稠密的簇分別對(duì)應(yīng)各自適合的r值,該參數(shù)具有較好的靈活性。實(shí)驗(yàn)結(jié)果證明,OIR-DBSCAN 算法可以正確聚類(lèi)密度不均勻的數(shù)據(jù)集,而且對(duì)高維甚至簇間有重疊的數(shù)據(jù)集也有較好的聚類(lèi)能力。本文算法在聚類(lèi)大規(guī)模數(shù)據(jù)集時(shí)會(huì)出現(xiàn)聚類(lèi)時(shí)間較長(zhǎng)的現(xiàn)象,下一步將從改進(jìn)算法性能和提高聚類(lèi)速度方向入手,以使算法的聚類(lèi)效果達(dá)到最優(yōu)。
