基于用戶意圖的微博文本生成技術研究
2022-01-14 03:02:08高永兵黎預璇高軍甜馬占飛
計算機工程 2022年1期
高永兵,黎預璇,高軍甜,馬占飛
(1.內蒙古科技大學信息工程學院,內蒙古包頭 014010;2.包頭師范學院信息工程系,內蒙古包頭 014010)
0 概述
微博文本自動生成屬于文本生成領域的一個研究熱點。文本生成是機器根據輸入信息,經過組織規劃過程自動生成一段高質量的自然語言文本,其為自然語言處理研究中一項具有挑戰性的任務。文本生成可以形式化為順序決策過程,即在每個時間步t中,將先前生成的單詞序列作為當前狀態,表示為st(x1,x2,…,xi,…,xn),其中,xi為詞匯表中所給的單詞,用當前的單詞序列狀態st預測下一時間步單詞序列的生成。
近年來,文本生成技術取得了較大進展。2014年,GOODFELLOW 等[1]針對圖像生成等任務,提出生成對抗網絡(Generation Adversarial Networks,GAN),GAN 由生成器和鑒別器組成,生成器的作用是模擬真實數據的分布,鑒別器的作用是判斷一個樣本是真實樣本還是模型模擬生成的樣本,GAN 的目標就是訓練一個生成器以完美地擬合真實數據分布使得判別器無法區分。自GAN 被提出以來,基于GAN的文本生成引起研究人員的廣泛關注,學者們提出多種基于GAN 的文本生成方法。GOU 等[2]提 出LeakGAN,其允許鑒別器將自己的高層特征泄漏到生成器中,指導生成器的預測生成,從而解決長文本的生成不連貫問題。ZHU 等[3]提出Texygen,其為一種開放域文本生成的標桿平臺,囊括大多數文本生成模型,如SeqGAN[4]、MaliGAN[5]等。
除GAN 之外,Sequence2Sequence[6]技術和編解碼框架也在自然語言生成任務中得到廣泛應用。編碼器將輸入的序列編碼為隱藏狀態,經過特征提取作為解碼器的輸入,解碼器預測生成與編碼器輸入相應的自然語言。
基于上述方法,許多文本生成研究取得了顯著成果。LI 等[7]實現了基于對抗條件變分自編碼器的中文詩歌生成,其使用LSTM 訓練的微軟小冰參加詩詞創作比賽,并通過了圖靈測試。YAO 等[8]根據主題、靜態和動態情節線實現故事的自動生成,生成的故事連貫、多樣且符合主題。ZENG 等[9]根據微博用戶的配置文件、個人描述、歷史微博評論,自動生成個性化的微博評論。
文本生成技術在以上任務中取得較好效果,但是上述都是針對特定域的文本生成,在進行其他域的文本生成時需要重新訓練模型,相當耗費資源。微博文本復雜多樣,所訓練模型的健壯性低,難以學習微博文本的語言風格,但是,經過大量規范文本訓練的預訓練語言模型能直接微調(fine-tuning)處理下游任務,避免從零開始訓練模型,從而降低了訓練代價。因此,針對微博文本自動生成問題,本文采用預訓練語言模型加微調的方法,在給定微博主題的條件下,將微博文本中蘊含的用戶意圖和用戶對話功能作為其個性化特征,微調預訓練語言模型生成符合用戶預期的微博文本,并整體生成“@用戶”,實現用戶對話交流功能。具體地,本文從語義和語言風格2 個角度挖掘微博文本的個性化特征,提出一種基于主題和用戶意圖的微博文本控制生成技術。微調預訓練模型GPT2-Chinese[10],實現聯合主題和用戶意圖的微博文本個性化生成。在此基礎上,對“@用戶”進行特殊處理,自動預測用戶交流的對象,在營銷推薦意圖上實現“@用戶”的對話功能。
1 相關工作
近年來,預訓練語言模型引起研究人員的廣泛關注,語言模型在高質量、大規模的數據集上預先訓練,學習理解自然語言的表示,研究人員可直接使用預訓練語言模型微調處理下游任務,省去了繁瑣的模型訓練過程,從而促進了各種自然語言處理技術的快速發展。
預訓練語言模型主要學習詞的上下文表示,根據不同的序列預測方式可分為自編碼和自回歸2 種語言模型。谷歌提出的BERT[11]是典型的自編碼語言模型,其使用Transformer 抽取特征,引入MLM(Masked Language Model)和NSP(Next Sentence Prediction)預訓練目標,能夠獲取上下文相關的雙向特征表示,從而處理句子或段落的匹配任務,但是,該模型預訓練過程和生成過程的不一致導致其在生成任務上效果不佳。自回歸語言模型的典型代表有ELMo[12]、GPT[13-15]、XLNet[16]。ELMo 是最早的預訓練語言模型,其使用雙向長短時記憶(BiLSTM)網絡串行提取特征,模型按照文本序列順序拆解的方式在從左至右和從右至左2 個方向學習詞的深度上下文表示,從而獲取上下文信息的雙向特征,但是,ELMo 本質上是2 個單向語言模型的拼接,不能同時獲取上下文表示,且神經網絡LSTM不能解決長距離依賴問題,特征提取能力弱。GPT 使用Transformer 進行特征抽取,能快速捕捉更長范圍的信息,目前已經更新到第三代:GPT1 微調階段引入語言模型輔助目標,解決了微調過程中的災難性遺忘問題;GPT2 在GPT1 的基礎上進行改進,使用覆蓋更廣、質量更高的訓練數據,認為預訓練中已包含很多特定任務所需的信息,其沒有針對特定模型的精調流程,在生成任務上取得了很好的效果;GPT3 使用比GPT2 更多的訓練數據和性能更高的計算資源以提高模型性能。XLNet 模型使用Transformer-XL 抽取特征,該模型針對BERT 預訓練過程與微調不一致的缺點,引入PLM(Permuted Language Modeling),能學到各種雙向上下文表示,分析結果表明,XLNet在20 個任務上的性能表現優于BERT,且性能都有大幅提升。
綜上,雖然XLNet 語言模型學習上下文表示的能力強于其他預訓練語言模型,但是單向的自回歸語言模型更適合生成任務。微博文本生成任務的訓練數據是中文且在生成任務中預訓練與微調應具有一致性,因此,本文選擇在中文版的預訓練模型GPT2-Chinese 下研究微博文本生成任務。雖然GPT3 已經問世,但是其模型要求更高的計算資源,實驗布置難度較高,因此,本文選擇GPT2 進行研究。
2 用戶意圖
當今社會快速發展,人們的生活節奏不斷加快,信息流動的速度越來越快,碎片化的微博內容比長篇文章更適合閱讀。因此,自動生成的微博文本能準確表達用戶意圖至關重要。一方面,用戶意圖反映了用戶發表博文最直接的社交需求,比如,普通用戶發表心情感悟,分享日常生活,企業公司發表博文營銷宣傳產品和活動,媒體工作者借助微博平臺傳播新聞事件,呼吁廣大群眾的關注,文藝工作者借助博文傳播知識,實現與其他用戶的經驗共享、共同進步;另一方面,社交意圖蘊含于微博文本中,是更深層次的語義特征,能在一定程度上表現微博文本的個性化特征。因此,具有清晰明確的用戶意圖的微博文本能促進用戶間信息的有效獲取和交流,幫助用戶在微博平臺上實現社交的目的。本文挖掘和提取微博文本中的用戶意圖類別,在給定微博主題的條件下按照用戶意圖自動生成微博文本。
2.1 用戶意圖示例
用戶意圖蘊含于微博文本中,能從詞和句子中挖掘。華為終端官方微博用戶發的一條博文如下:
#華為Mate40#系列新品發布盛典將于10 月30 日14:30 正式開啟!鎖定@華為終端官方微博,帶你直通發布會現場。
結合“華為”“新品”“鎖定”“發布會”等詞和整個句子的語義,可以推斷出這是華為官博為推出“華為Mate40”發表的博文,旨在營銷宣傳。用同樣的方法對大量的微博文本進行統計分析,可將微博文本中的用戶意圖大致分為營銷推薦、新聞評論、知識傳播、心情感悟、日常分享這5 個類別。從上述例子來看,基于用戶意圖的微博文本生成過程如表1 所示。

表1 微博文本生成過程示例Table 1 Example of the Weibo text generation process
在表1 中,給定主題“華為Mate40”和用戶意圖“營銷推薦”,經過訓練的語言模型自動預測與主題、用戶意圖類別相符合的詞,最終構成一個完整的文本段落。
2.2 用戶意圖識別與分類
為了便于數據處理和輔助GPT2-Chinese 生成更加符合用戶預期意圖的微博文本,本文額外訓練一個用戶意圖識別與分類模型。
目前,研究人員已經在消費意圖、查詢意圖、人機對話意圖識別中取得了較多成果,但多數是基于傳統機器學習的方法[17-19]。傳統機器學習模型在特征工程中需要人為對數據進行提煉清洗,與深度學習模型相比有很大不足。為此,研究人員更加專注在神經網絡上進行意圖識別[20-22]并取得了較好的效果。
本文為了學習句子、段落以及關鍵詞的語義編碼,從而準確識別微博文本中的用戶意圖,訓練一個用戶意圖識別與分類模型,該模型采用編解碼器框架,融合BiLSTM、自注意和詞句聯合訓練等要素進行用戶意圖的識別與分類,模型框架[23]如圖1 所示。
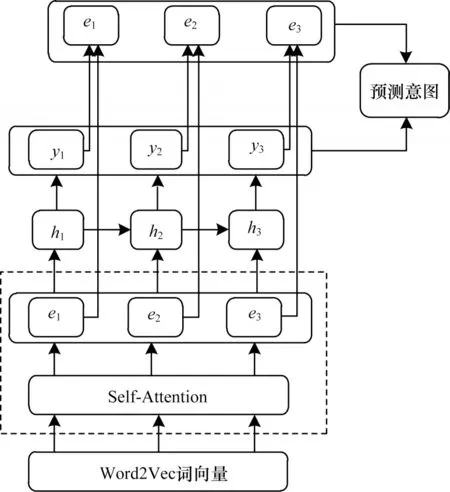
圖1 用戶意圖識別與分類模型框架Fig.1 User intention recognition and classification model framework
3 本文方法
本文方法的主要目的是使自動生成的樣本在內容上與微博主題保持一致且從用戶意圖的角度展示出微博文本的個性化特征。針對微博文本生成問題,本文作出如下定義:將用戶意圖定義為特征向量Ui,微博主題定義為T,模型預測生成的微博文本定義為X,生成模型可視作條件概率模型P(X|Ui,T),最后將微博文本作為訓練數據,結合微博主題和用戶意圖微調GPT2-Chinese語言模型,預測生成微博文本。
由于存在多個控制文本生成的用戶意圖,統一訓練可能導致模型學習能力降低,為此,本文使用MAO等[24]提出的兩階段微調方式:第一階段,微調預訓練語言模型GPT2-Chinese 學習微博文本的語言風格;第二階段聯合主題和用戶意圖進行微調,使生成的微博文本流暢且符合用戶發博的目的。圖2 所示為微博文本生成任務的GPT2 兩階段微調流程。
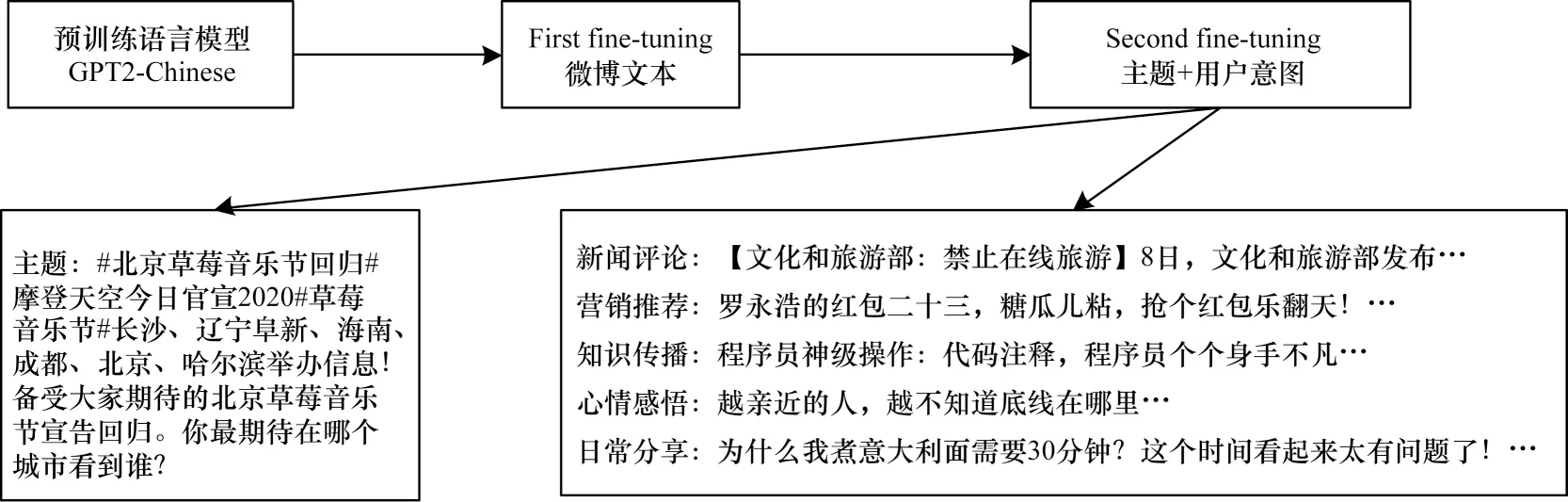
圖2 GPT2 兩階段微調流程Fig.2 GPT2 two-stage fine-tuning procedure
3.1 文本生成語言建模
在實際應用中,自然語言模型是學習序列單詞的概率分布p(x1,x2,…,xn),文本生成可以形式化為在給定單詞序列的情況下預測下一個單詞的條件概率p(xn|x1,x2,…,xn-1),其中,xi為單詞序列。自回歸語言模型按照序列預測的條件概率形式可進行單向或雙向訓練。單向語言模型按照前向序列預測的訓練定義為:
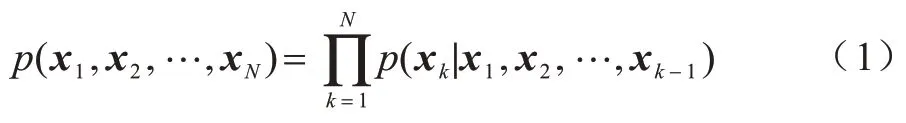
預訓練語言模型GPT2 采用與上述相同的訓練方法,其過程是給定提示(Prompt)序列(x1,x2,…,xk-1)與生成文本序列(xk,xk+1,…,xn),共同構成一段連貫的文本,具體形式如下:
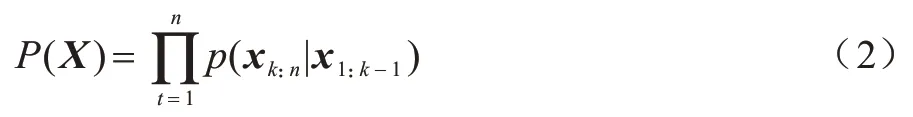
本文在GPT2 下完成微調微博文本生成任務,可將微博主題T作為提示條件,式(2)可更新為:
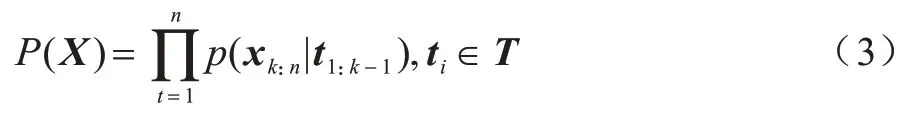
為了在生成的微博文本中表現用戶意圖(Ui),可將用戶意圖與GPT2 預訓練語言模型進行簡單地模型融合,融合方式如下:
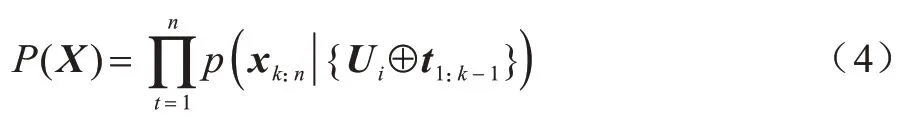
3.2 GPT 框架
GPT1 使用半監督的方式學習理解自然語言,利用大量的無監督語料庫訓練語言模型,然后模型以很小的微調遷移到眾多特定的有監督學習任務上[13],其訓練的最大似然目標函數如下:
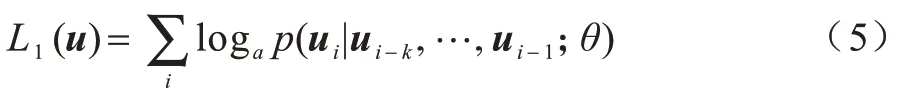
GPT1語言模型不采用RNN 或LSTM,而是采用深層的transformer decoder(Masked),其計算公式如下:
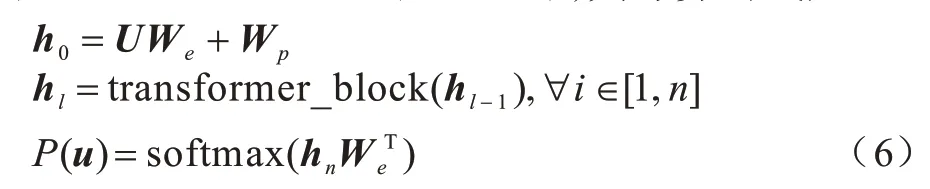
無監督的語言模型經過式(6)的預訓練后,將該模型參數作為初始參數應用到一些特定的有監督任務上。例如,對于有標簽的數據集C,利用網絡中最后一個transformer_block 的輸出進行如下處理:
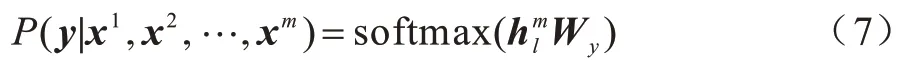
此時最大化目標函數如下:
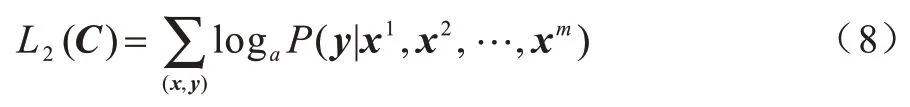
將語言建模作為微調的輔助目標,改進監督模型的泛化能力,加速收斂。優化后的目標訓練函數如下:

GPT2 是在GPT1 基礎上做的改進,是完全無監督學習,其在模型結構上移動了Layer normalization的位置,修改了殘差層的初始化方式,增加了模型的部分參數,從而提高了生成文本的質量。
3.3 微博文本生成訓練
GPT2 預訓練語言模型允許對下游微博生成任務采取微調的方法,即不需要從零開始訓練模型,只需針對特定的任務調整訓練參數。目前已開源了許多版本的GPT2 模型,本文選擇中文的GPT2-Chinese 作為預訓練語言模型。GPT2-Chinese 采用的訓練集是15 GB的Large Scale Chinese Corpus for NLP 和THUCNews,能夠自動生成詩歌、小說、新聞等內容,且生成的內容連貫。因此,在微博文本生成任務中,本文選擇用GPT2-Chinese 模型來實現兩階段微調任務:第一階段,用一個高質量微博訓練集進行域適應訓練,即微調GPT2-Chinese 讓模型學會從通用自然語言預測轉向符合微博文本語言風格的預測生成,得到中間微調的模型;第二階段,用微調好的GPT2-Chinese 模型在帶有主題標簽和用戶意圖標簽的微博數據集上進行二次微調,最終實現微博文本的個性化生成。
自動生成微博比自動生成詩歌、自動講故事等生成任務更具挑戰性。詩歌有具體形式,且每種形式都有各自的規律,故事有明確的主題和便于規劃的故事線,機器更容易學習這種有明確特征的文本。然而微博文本長短不一、書寫風格參差不齊,既不似詩歌字數工整、體裁清晰,也不似故事主題明確、上下文連貫。官方公布的GPT2 模型更適用于連續的長文本訓練,而GPT2-Chinese 在訓練時設置文本最低長度為128,模型在自動預測微博文本時表現不佳,上下文的相關性低,無法降低訓練的損失率,簡單地修改訓練文本長度也無法提高生成效果。因此,在訓練時本文用微博鏈接來增加文本長度從而降低損失,生成結果表明,該方法能夠提高模型的文本生成性能。
3.4 個性化微博文本生成訓練
微調GPT2-Chinese 語言模型能生成與所給主題相符的樣本,且隨著實驗數據的增多,語言模型學習微博文本特征的能力增強,但是沒有明確的控制條件,生成的博文個性化特征不明確。因此,本文從語義特征和語言風格2 個角度提取微博文本的個性化特征,用其指導博文的預測生成。
通過對微博文本深層次的語義特征進行分析,發現博文中蘊含了微博用戶的各種社交意圖,且社交意圖大致分為新聞評論、營銷推薦、知識傳播、心情感悟、日常分享這5 個類別,本文將其作為微博文本語義層次上的個性化特征,指導博文生成,且在該過程中采用2 個方案進行微調:
1)在第二階段微調時,用GPT2-Chinese 聯合主題和用戶意圖進行多任務微調,實驗中發現預先訓練的GPT2-Chinese 有很強的基礎性知識,再次按照用戶意圖訓練能夠產生高質量的個性化微博文本,且多個用戶意圖微調能幫助實現微博文本的個性化預測生成。
2)將本文提出的用戶意圖識別與分類模型和GPT2 相結合,輔助GPT2 生成博文。該方法能提高預測文本中預期的用戶意圖的準確度。
從語言風格角度可以發現微博文本中會出現大量用戶對話的情況,即用戶在發表博文時會@另一個用戶,從而實現用戶之間的交流。本文將用戶對話功能看作微博文本的另一個個性化特征,在微調時自動預測用戶對話的對象,從而幫助用戶實現自動信息交流的目的。
3.4.1 多意圖控制生成
為實現個性化微博生成,本文實驗中引入5 個類別的用戶意圖以控制微博文本的生成。雖然大型預訓練語言模型的誕生提高了處理自然語言任務的能力,但直接在特定條件的數據上微調往往很困難。在CRTL[25]模型中,將控制條件作為標簽加在文本前面,這樣在模型訓練過程中attention[26]會計算控制條件與序列之間的聯系,從而實現控制生成。ZACHARY 等[27]觀察到預先訓練的transformer 模型在微調過程中對模型參數的變化很敏感,因此,提出一種直接向selfattention注入任意條件的適應方法pseudo self attention,使用該方法的預訓練語言模型適應于任意條件的輸入。為了不改變預訓練語言模型的結構,DATHATHRI等[28]提出用于可控語言生成的即插即用語言模型(PPLM),其將預先訓練的LM 與一個或多個簡單的屬性分類器相結合以指導文本生成,而不需要對LM 進行額外的訓練。本文在意圖控制生成時學習PPLM 的思想,將用戶意圖識別與分類模型作為意圖分類器,意圖分類器判別生成的文本類別并用梯度回傳的方式傳遞給語言模型,預訓練語言模型根據意圖判別回傳的梯度更新模型的內部參數,重新采樣生成下一個token,使生成的樣本接近用戶輸入的意圖。上述過程可以形式化表示為:

此時用戶意圖分類模型可看作P(Ui|X),語言模型GPT2 中具有歷史信息的矩陣Ht,再給定xt,GPT2利用Ht預測xt+1和更新Ht:
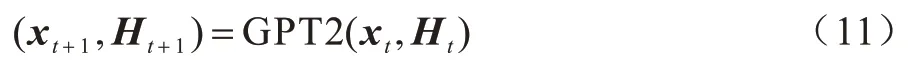
其中:xt+1是經過softmax 在詞匯表中采樣生成的文本。PPLM 的思想是從2 個方向計算分類模型和語言模型的梯度之和,然后通過ΔHt更新歷史矩陣Ht,實現xt+1的重新預測。在用戶意圖的控制上,本文將意圖分類模型P(Ui|X)改寫為P(Ui|Ht+ΔHt),ΔHt的更新方式如下:
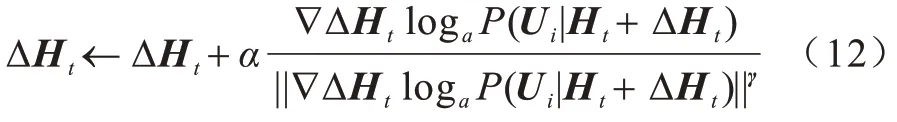
其中:α 是步長;γ為歸一化縮放系數。式(11)就可以更新為:
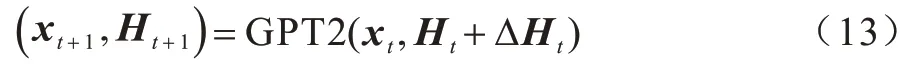
3.4.2 “@用戶”的對話實現
通過對微博文本進行分析可知,“@用戶”的功能也是微博文本的特征,因此,本文還研究自動@正確用戶名的方法。在生成過程中,本文發現模型能自動生成“@用戶名”,但在訓練時用戶名被當作文本進行了分詞處理,因此,模型生成的用戶名往往不存在,且由于用戶名是一個實體,經過分詞后影響了文本的上下文相關性,降低了生成文本的質量。為此,本文將“@用戶名”作為一個詞并用UNi替換,然后為其建立詞表,當生成時出現UNi模型會自動將其轉換為“@用戶”,其中,i表示詞表中的第i個詞。最后,本文在數據中發現,在營銷推薦意圖上使用“@用戶”的對話概率更大,因此,將營銷推薦數據中的“@用戶”經過特殊處理,從而實現能準確“@用戶”的對話功能。
4 實驗結果與分析
4.1 數據集與實驗環境
本次實驗數據集是通過新浪微博接口獲取的27 萬條微博文本,本文將數據集根據用戶意圖和微博主題預處理為適合微調的格式。首先標注7 000 條用戶意圖數據,進行用戶意圖識別與分類模型訓練;然后使該語言模型自動進行用戶意圖標注,人工標注和自動標注的標簽數據集如表2 所示;最后在數據集上批量進行微調微博生成實驗,觀察不同訓練樣本數量時的微博文本生成效果。
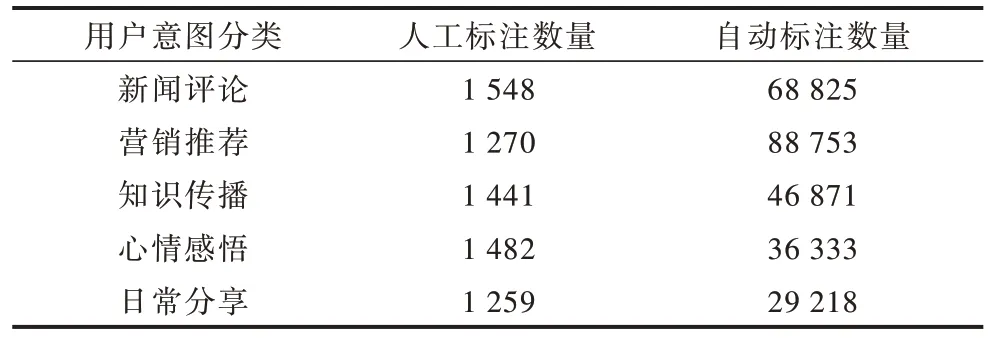
表2 標簽數據集信息Table 2 Label datasets information
實驗環境是使用谷歌Colab 免費的GPU,雖然谷歌能提供免費的計算環境,但是一天掛載時間只有12 h,因此,在模型訓練過程中本文加入checkpoint,如果訓練中斷,還可以接著上次中斷位置繼續訓練。
4.2 用戶意圖識別與分類實驗
用戶意圖識別與分類實驗使用表2 中的人工標注數據集,用詞和句子的意圖對文本意圖進行打分訓練,實驗過程中分別用準確率和F1 值進行評價,實驗結果如表3 所示。其中,詞句+BiLSTM 是本文提出的用戶意圖識別與分類模型,即從詞、句2 個方面關注用戶意圖,并將BiLSTM 融入編解碼框架中訓練用戶意圖識別與分類模型。從表3 可以看出,本文模型能獲得93.109%的F1 值,優于BERT 模型。

表3 用戶意圖識別與分類實驗結果Table 3 Experimental results of user intention recognition and classification %
4.3 微調微博文本生成任務
在模型訓練開始前,本文從GitHub 上下載了中文的GPT2 訓練模型GPT2-Chinese,用于微博文本生成任務。首先用無標簽的數據訓練模型將其轉換為微博文本語言的預測生成,得到中間微調的語言模型;然后用表2 中的自動標簽數據微調生成符合微博主題和用戶意圖的博文,在訓練時,GPT2-Chinese模型參數量為81 894 144,為提高GPU 的利用率,設置batchsize 為4,epoch 為5,每個epoch 有10 212 步,設置微博文本的生成溫度為0.8,對下一個單詞的預測采用ANGELA 等[29]提出的Top-k隨機抽樣方法,其中,下一個單詞從k個候選詞中抽取,設定k=10;接著聯合主題標簽和用戶意圖標簽,利用中間微調的模型進行二階段微調學習,從用戶意圖角度控制微博文本的個性化特征,且在該過程中加入用戶意圖分類模型,以提高生成樣本中指定用戶意圖的準確性。在此基礎上,將“@用戶名”進行整體替換,實現用戶對話的生成預測。實驗結果表明,本文方法生成的微博文本可讀性高,且能從用戶意圖的角度表現微博文本的個性化特征。
4.4 生成樣例
本文列出基于主題、基于主題和用戶意圖2 種方式預測生成的微博文本樣例,分別如圖3、圖4 所示,在此僅展示營銷推薦和新聞評論2 個用戶意圖生成樣例。在營銷推薦意圖上實現“@用戶”的對話功能,生成樣例如圖5 所示。

圖3 基于主題的生成樣例Fig.3 Generation sample based on topic
5 人工評價
與傳統文本不同,微博文本生成屬于特型文本生成任務,傳統的文本評價指標BLEU 和ROUGE 不適用于對微博文本生成進行評價。本文通過人工方式評價生成樣本的質量。人類評審者需要考慮樣本與微博主題、用戶意圖的匹配度,然后對需要評價的樣本進行打分,實驗過程中共有5 位評審,隨機采樣600 條生成樣本,其中,100 條是只根據主題生成的,500 條是根據主題和用戶意圖生成的,每類用戶意圖各100 條。將每種類型的樣本平均分配給5 個評審,讓其對生成的樣本進行打分,分數為0~10 分,最后計算每類樣本得分的平均值,結果如表4 所示,可以看出,基于主題與用戶意圖生成的微博文本更符合人類預期。

表4 人工評價得分對比Table 4 Manual evaluation scores comparison
6 結束語
本文提出一種基于用戶意圖的微博文本生成技術,采用預訓練語言模型與微調相結合的方法,在給定微博主題的條件下,將微博文本中蘊含的用戶意圖和用戶對話功能作為其個性化特征,微調預訓練語言模型生成符合用戶預期的微博文本。實驗結果驗證了該技術的有效性。微博文本生成技術能夠為博文編寫者提供參考,也可以為后續的文本生成研究提供思路,但是,本文模型僅從統計的角度并利用靜態的方式挖掘微博文本的個性化特證,下一步將挖掘興趣品味、行文風格等更多的用戶個性化特征,此外,探索一種性能更好、聯合多個控制條件微調預訓練語言模型的方法,以提高訓練技術同時節省時間和資源成本,也是今后的研究方向。
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
商用汽車(2016年11期)2016-12-19 01:20:16
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
