結合遷移學習與可分離三維卷積的微表情識別方法
2022-01-14 03:02:30梁正友劉德志
計算機工程 2022年1期
梁正友,劉德志,孫 宇
(1.廣西大學計算機與電子信息學院,南寧 530004;2.廣西多媒體通信與網絡技術重點實驗室,南寧 530004)
0 概述
根據表情持續時間的長短和運動強度的大小,可以將表情分成宏表情和微表情兩類。宏表情的持續時間約為2~3 s,運動涉及整個面部區域。目前,研究人員已經利用計算機實現了接近100%的宏表情識別率[1]。與宏表情相比,微表情的運動時間相對較短,僅為0.5 s 左右[2],且運動強度非常微弱,通常只涉及局部的面部區域。這些特點導致微表情特征提取較為困難,使當前微表情自動識別的準確率遠低于宏表情。但微表情是由內心真實情緒激發所產生,難以抑制或偽造,比宏表情更能準確地反映人內心的真情實感,因此能夠作為測謊的重要依據。
近年來,隨著深度學習相關技術的迅速發展,具有時空特征提取能力的三維卷積神經網絡(3D Convolutional Neural Networks,3D CNN)[3-4]在視頻分類任務中的效果優于僅能提取空域特征的二維卷積神經網絡。受到這些成果的鼓勵,一些研究人員開始嘗試利用3D CNN 來提取微表情的時空特征,從而提高識別準確率。文獻[5]設計的3D-FCNN 通過三流結構的3D CNN 同時提取微表情原始視頻幀序列和光流幀序列的時空特征,在全連接層對三流提取到的時空特征進行融合。但由于樣本數量過少導致的過擬合問題,準確率的提升有限。文獻[6]利用3D CNN 提取眼睛、嘴部等微表情運動較為頻繁部位的時空特征,減少了無關區域對算法的影響。文獻[7]提出一種雙流結構的3D CNN,使模型能夠提取包含在微表情光流幀序列中的時空特征,同時增強了模型對不同幀率樣本的適應性,與STCLQ[8]、MDMO[9]等手工特征方法相比,準確率提高了約10%。文獻[10]利用具有全局搜索及優化能力的遺傳算法對3D CNN 的結構和參數進行編碼、選擇、交叉、變異等操作,從而得到適用于微表情識別任務的最佳參數組合和模型結構,提高了模型的識別能力。但微表情運動強度較弱,相鄰兩幀之間的差異非常小,在原始的微表情視頻幀序列中提取用于分類的時空特征難度較大。
遷移學習是一種常用于解決由于樣本數量過少導致模型在訓練過程當中出現過擬合現象的方法。遷移學習首先在擁有大量樣本的源任務上對模型進行預訓練,然后用目標任務的少量樣本對預訓練獲得的模型參數進行微調,以找到源任務與目標任務間能夠共享的模型參數,并使模型更加適用于目標任務[11]。近年來,一些研究人員開始采用遷移學習的方法解決當前微表情樣本數量過少導致的模型過擬合問題。文獻[12]利用遺傳算法,從VGG-Net 學習到的宏表情分類特征中篩選出適用于微表情分類的特征進行識別。文獻[13]在利用ResNet10 提取微表情特征前,先用大量的宏表情樣本對模型進行預訓練,有效地提升了模型在小規模的微表情數據集上的表現。為解決微表情運動強度較弱的問題,文獻[14]首先采用歐拉視頻運動放大算法(Eulerian Video Magnification,EVM)[15]對微表情進行運動放大,然后利用能夠進行人臉識別的模型VGG-Face 來提取微表情運動強度峰值幀的特征,并用于分類。但如果EVM 算法的放大倍數過大容易產生偽影,對算法的識別準確率造成一定影響。
由于自發式微表情的采集難度較大,可用于研究的樣本數量較少,導致當前采用3D CNN 來提取時空特征進行微表情識別的研究普遍存在樣本數量過少造成的過擬合問題,對識別準確率造成一定的影響,而當前采用遷移學習技術進行微表情識別的研究,通常僅利用二維卷積神經網絡來提取靜態微表情圖像的空域特征,并未考慮微表情變化過程中的動態時域特征,準確率提升較為有限。
針對上述問題,本文提出一種結合遷移學習和可分離三維卷積神經網絡(Separable 3D Convolutional Neural Networks,S3D CNN)的微表情自動識別方法。利用光流法提取每一個宏表情和微表情視頻幀序列相鄰兩幀的水平、垂直方向光流圖,并導出對應的光流應變模式圖。將3 個光流圖以通道疊加的方式構成光流特征圖后,按時間順序將光流特征圖連接成光流特征幀序列。此外,利用宏表情樣本的光流特征幀序列對S3D CNN 進行預訓練,使模型獲得與表情分類相關的時空特征,從而緩解傳統的3D CNN 訓練參數較多、所需計算量較大的問題。在此基礎上,將預訓練得到的模型參數遷移至用于微表情識別的模型中,利用微表情樣本的光流特征幀序列對模型參數進行微調,從而使模型更加適用于微表情識別任務。
1 可分離三維卷積
可分離三維卷積[16-18]是近年來出現的一種介于二維卷積與三維卷積之間的輕量化時空特征提取方法,其原理是利用二維空域卷積加一維時域卷積來模擬三維卷積的時空特征提取過程。傳統3D CNN 的三維卷積核大小為k×k×t,其中:k為卷積核空域維度的高度和寬度;t為卷積核時域維度的長度。設3D CNN 的三維卷積層輸出的特征映射(i,j,z)處的值為yi,j,z則:
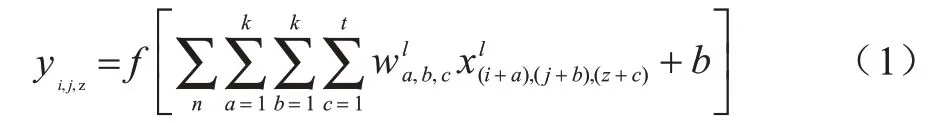
其中:f(x)為三維卷積層的激活函數;n為上層傳入的特征映射中包含的幀數;為 第l個卷積層的三維卷積核(a,b,c)處的權重值;為輸入第l個卷積層的特征映射(i,j,z)處的元素值;b為偏置值。
可分離三維卷積將三維卷積拆分成了二維的空域卷積和一維的時域卷積2 個獨立的過程,如圖1 所示。利用卷積核大小為k×k×1 的二維空域卷積層來提取輸入幀序列的空域特征,計算公式如下:
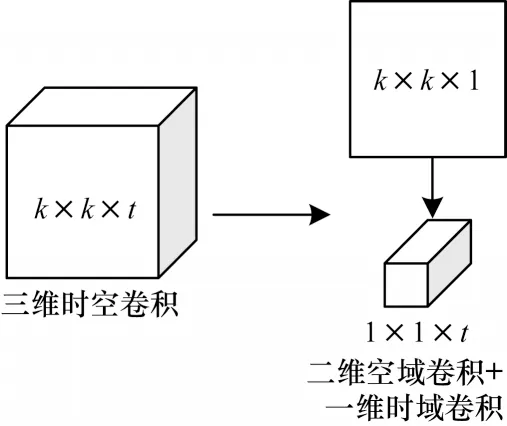
圖1 可分離三維卷積原理Fig.1 Separable 3D convolution principle
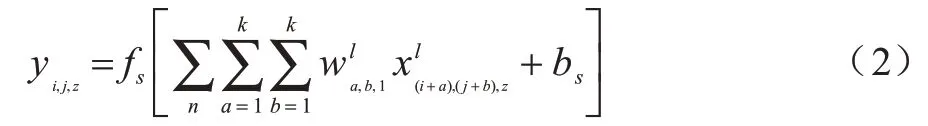
其中:yi,j,z為空域卷積層輸出的特征映射(i,j,z)處的元素值;fs(x)為空域卷積層的激活函數;bs為空域卷積層的偏置值。
將卷積結果輸入卷積核大小為1×1×t的一維時域卷層中,提取幀與幀之間的時域特征,計算公式如下:

其中:ft(x)為時域卷積層的激活函數;bt為時域卷積層的偏置值;ai,j,z為輸出特征映射(i,j,z)處的時域卷積結果。
與2D CNN 相比,由可分離三維卷積層構建的S3D CNN 只在每個二維空域卷積層之后增加了一個一維時域卷積層,用于提取視頻幀序列的時域特征,但模型的訓練參數與所需計算量并未顯著增加。與3D CNN 相比,將三維卷積層拆分成二維空域卷積層和一維時域卷積層后,2 個卷積層間增加了1 個額外的激活函數,使模型比3D CNN 能更好地擬合非線性函數,增強了模型的學習能力。
2 本文方法
本文所提方法首先需要對原始的宏表情與微表情視頻幀序列進行預處理;然后利用光流法對每個視頻幀序列的相鄰兩幀進行運動估計,提取相鄰2 幀的光流特征圖來組成光流特征幀序列;最后采用遷移學習的方法對S3D CNN 進行訓練。主要流程如圖2 所示。
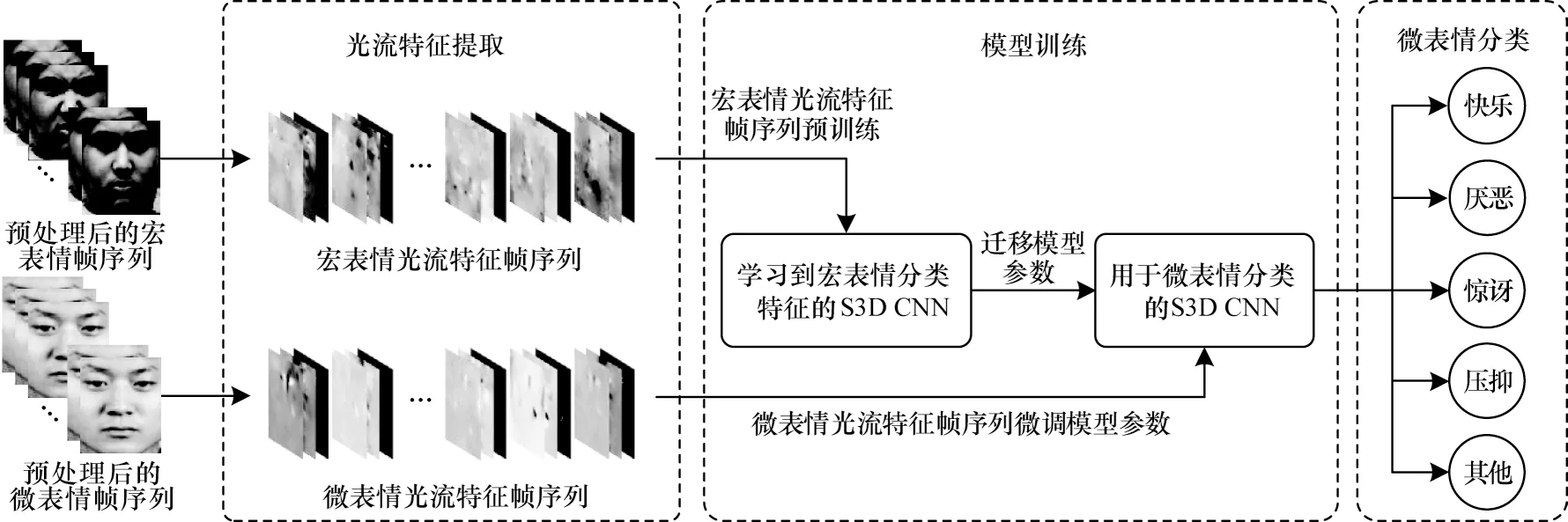
圖2 本文所提微表情識別方法流程Fig.2 Flowchart of micro-expression recognition method proposed in this paper
2.1 預處理
為減少微表情運動過于微弱對光流特征提取和模型學習效果的影響,在預處理過程中,首先通過EVM 算法將每個微表情樣本的面部運動放大10 倍。然后利用時域插值模型(Temporal Interpolation Model,TIM)[19]將每個宏表情和微表情視頻幀序列歸一化為11 幀,以滿足輸入S3D CNN 的樣本幀數必須一致的要求。最后,采用平移裁剪和隨機旋轉等數據增強方式獲取更多的宏表情樣本,增強模型的魯棒性,并通過類別重采樣來避免宏表情和微表情數據集的樣本類別分布不均衡對模型學習效果的影響,具體步驟如下:
1)利用OpenCV 的Dlib 庫來檢測每個宏表情和微表情樣本第1 幀的68 個面部特征點,根據最左側、最頂部、最右側和最下側共4 個特征點的坐標確定面部矩形區域。
2)將步驟1)中確定的面部矩形區域分別向上、下、左、右、左上、右上、左下、右下共8 個方向平移10 個像素,并按照平移前后的面部矩形區將樣本第1 幀和剩余幀的面部區域均裁剪下來,使每個宏表情和微表情樣本能夠獲得9 個視頻幀序列,從而將樣本數量擴充9 倍。
3)對數據增強后的宏表情數據集進行類別重采樣,從每個宏表情類別中隨機抽取1 500 個樣本,共7×1 500=10 500 個樣本組成新的宏表情數據集,并將抽取到的樣本隨機旋轉0°、90°、180°或270°,以增加樣本的多樣性。
4)將按照步驟1)確定的面部矩形區域裁剪的微表情樣本作為測試集,并從步驟2)平移后的微表情樣本中以類別重采樣的方式隨機抽取訓練集樣本。在類別重采樣過程中,每個微表情類別分別抽取50 個樣本,共5×50=250 個微表情樣本構成新的訓練集,與原數據集的樣本量近似。
2.2 光流特征提取
光流特征提取是對每個宏表情和微表情樣本的相鄰2 幀進行運動估計,提取高層次的面部表情運動特征。根據文獻[20]的實驗結果可知,相對于其他光流法,TL-V1 光流法[21]的魯棒性較好,更加適用于微表情識別任務,因此本文采用TL-V1 光流法對宏表情和微表情進行運動估計。光流法基于亮度恒定原則估計視頻中的運動物體。設(dx,dy)為圖像上某個像素點在dt時間后的下一幀移動的距離,由亮度恒定原則可以認為這2 個像素的值不變,即:
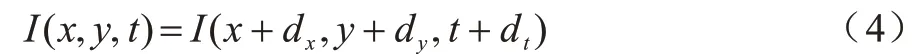
上述方程稱為光流方程。光流法的目的是利用光流方程求出圖像上每個像素運動的大小和方向矢量
此外,本文進一步利用宏表情和微表情相鄰2 幀的光流場來導出對應的光流應變模式。應變模式用于衡量物體在外力作用下的形變程度。設u=[u,v]T表示三維空間中面部表情形變導致的位移在二維圖像上的投影向量,則可用柯西張量來表示表情發生過程中面部肌肉組織的形變程度:

其中:?表示對u進行求導。可以將式(5)的二維應變張量展開成矩陣形式:
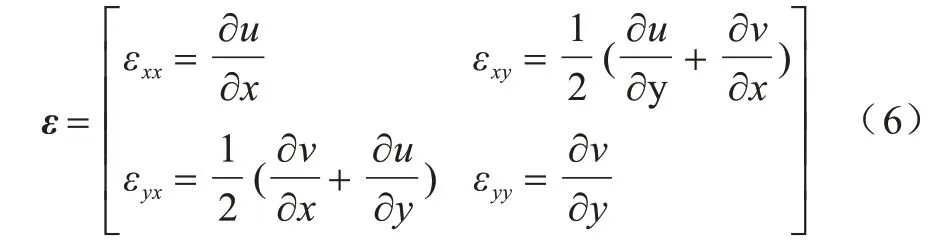
由于表情發生過程中的肌肉運動可能包含多個方向,因此采用應變模式的4 個分量來計算每個像素的應變大小,如式(7)所示:
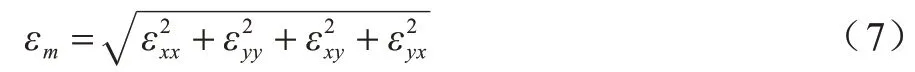
應變模式具有僅與物體表面的形變有關,不易受到光照條件等外部因素影響的優點[22],魯棒性較強,在微表情識別任務中有較好的表現[23]。
在提取光流特征之后,每個宏表情和微表情樣本能得到3 個光流幀序列,即水平、垂直方向光流幀序列和光流應變模式幀序列。圖3 展示了CASME II 微表情數據集其中1 個樣本的原始灰度幀序列和對應的3 個光流幀序列。將3 個光流幀序列中相對應的每一幀以通道疊加的方式連接起來,構成三通道的光流特征幀序列。在預處理過程中每個宏表情和微表情視頻幀序列均用TIM 算法歸一化為11 幀,因此1 個光流特征幀序列共包含10 幀反映原樣本相鄰兩幀之間面部運動和形變情況的光流特征圖。將光流特征幀序列的空域維度調整至96×96 并進行標準化處理后,輸入模型進行訓練。
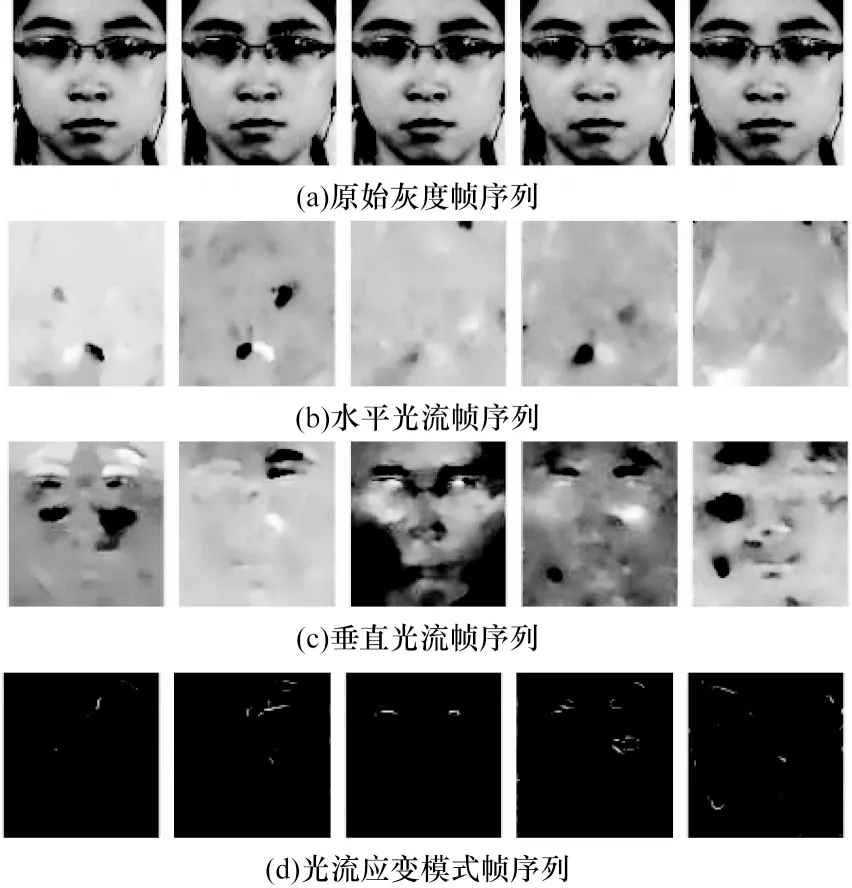
圖3 微表情原始灰度幀序列和光流幀序列Fig.3 Original gray frame sequence and optical flow frame sequence of micro-expression
2.3 模型設計
本文用于特征提取和分類的S3D CNN 主要由8 個可分離三維卷積層、4 個池化層和1 個全連接層組成,模型結構和主要參數如表1 所示。表中的Conv_s_i和Conv_t_i分別表示第i個可分離三維卷積層的空域卷積層和時域卷積層,空域卷積層用于提取視頻幀序列的靜態空域特征,而時域卷積層則對幀與幀之間的動態時域特征進行編碼。

表1 S3D CNN 參數設置Table1 S3D CNN parameter settings
采用4 個池化層對特征映射進行特征降維,以減少冗余信息。其中前3 個池化層采用最大池化,即通過保留池化窗口內最大元素的方式進行特征降維,從而突出重要的特征。最后1 個池化層采用平均池化,使池化窗口內的每個元素均對降維結果產生影響,防止損失過多的高維特征。由于樣本的幀數較少,為更好地保留時域特征,僅在平均池化層采用三維時空池化,而在最大池化層采用二維的空域池化。為充分利用從預訓練過程中學習到的宏表情分類特征,本文在微調過程中凍結了部分卷積層的參數,被凍結的卷積層參數在微調過程中保持不變,僅以較低的學習率對余下的卷積層和全連接層進行調整,使模型更加適用于微表情識別任務。表1 中“是否參與微調”一列表示模型中對應的卷積層是否參與了微表情的微調訓練,即該層在微調訓練中是否被凍結。
本文在全連接層后加入了丟棄率為0.2 的Dropout層。Dropout 層能以一定概率使某個神經元的激活值失效,避免模型依賴某些局部特征,以增強模型的泛化性,并緩解模型的過擬合問題。最后,將Dropout 層輸出的特征送入Softmax 層中完成分類。
3 實驗
3.1 表情數據集
3.1.1 Cohn-Kanade 擴展數據集
Cohn-Kanade 擴展數據集(CK+)[24]常用于人臉宏表情識別研究,樣本形式為動態的視頻幀序列。CK+收集了123 個受試者的593 個宏表情樣本,其中327 個樣本帶有情感類型標簽。該數據集將宏表情分為7 個類別,各個類別的樣本數量分別為憤怒45、蔑 視18、厭 惡59、恐 懼25、快 樂69、悲 傷28 和驚訝83。
3.1.2 CASME II 微表情數據集
CASME II 微表情數據集[25]由來自26 名受試者的246 段視頻樣本組成。樣本的幀率為200 frame/s,分辨率為640×480,平均幀長為68 幀。每個樣本根據誘導材料內容、受試者的自我報告等信息被分成5 個類別,各個類別的樣本數量分別為快樂32、厭惡60、驚訝25、壓抑27 和其他102。CASME II 還提供了每個樣本的起始幀、峰值幀和結束幀位置。
3.2 模型訓練
本文采用遷移學習的方法對所設計的S3D CNN 進行訓練,具體步驟如下:
1)利用從宏表情樣本中提取的光流特征幀序列對S3DCNN進行預訓練。預訓練的學習率初始化為0.0001,迭代周期為80,每迭代20 個周期學習率下降10 倍,batch_size=20。迭代80 個周期后,模型在訓練集上對7 種宏表情的識別準確率達到95.73%。
2)將預訓練獲得的卷積層和全連接層參數遷移至用于微表情分類任務的模型中,并按照表1 中“是否參與微調”一列所示凍結部分卷積層參數后,利用微表情樣本提取到的光流特征幀序列對模型參數進行微調。此外,為使模型輸出的判別向量維度與CASME II 數據集的類別數相同,還需將預訓練模型中具有7 個輸出單元的Softmax 層替換成一個新的具有5 個輸出單元的Softmax 層。微調的學習率初始化為0.000 01,迭代周期為40,每迭代10 個周期學習率下降10 倍,batch_size=10。
3.3 實驗環境與評價指標
本文主要采用留一受試交叉驗證(Leave-One-Subject-Out,LOSO)對算法性能進行評估。每一輪交叉驗證將1 名受試者的樣本作為測試集,通過式(8)計算LOSO 準確率:

其中:k為受試者數量。CSAME II 微表情數據集包含26 名受試者的微表情樣本,因此需要執行26 輪驗證,即k=26。Aacci為第i輪驗證的準確率。
實驗的操作系統環境為Centos6.5,利用Keras2.3.1 完成模型的搭建,編程語言為Python3.6,模型訓練的主要硬件設備為NVIDIA TESLA T4。
3.4 實驗結果與分析
3.4.1 與前沿方法的對比
將所提方法的LOSO 準確率與現有的手工特征識別方法及深度學習識別方法進行對比,如表2 所示。與當前較為前沿的STLBP-IP[26]、LBP-TOP[25]等手工特征識別方法相比,深度學習識別方法能避免繁瑣的手工特征提取過程,直接從原始的微表情視頻幀序列中提取特征,并通過學習的方式不斷調整模型參數,以優化所提取的分類特征,在簡化特征提取步驟的基礎上取得更好的識別效果。本文所提S3D CNN-transfer 微表情識別方法結合了近年來新興的可分離三維卷積和遷移學習技術,使模型能夠同時提取光流特征幀序列中的微表情靜態空域特征和動態時域特征。此外,通過遷移學習技術避免微表情樣本數量過少造成的過擬合問題,使利用深度學習的方法進行微表情識別的準確率有了進一步的提升。
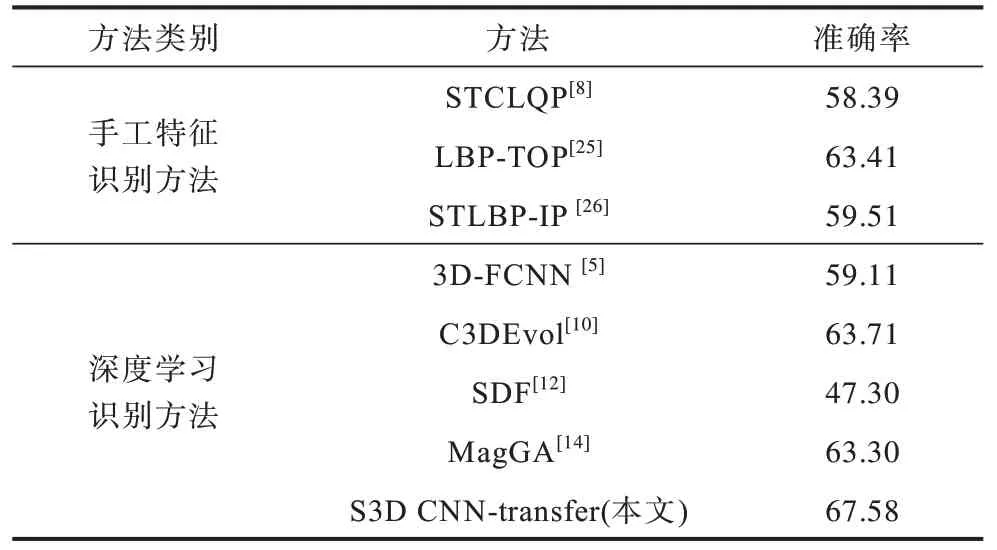
表2 不同微表情識別方法準確率對比Table 2 Accuracy comparison of different micro-expression recognition methods %
3.4.2 遷移學習對模型學習效果的影響
為了探索遷移學習對模型學習效果的影響,本節對遷移學習與非遷移學習模型的識別準確率進行了對比,如圖4 所示。S3D CNN 通過隨機賦值的方式對模型參數進行初始化。由于需要從0 開始學習與表情分類相關的特征,因此該模型與遷移學習的預訓練一樣從學習率為0.000 1 開始訓練,迭代周期為40,每迭代10 個周期學習率下降10 倍。S3D CNN-transfer 則遵循了3.2 小節的遷移學習方法和參數進行訓練。

圖4 S3D CNN 與S3D CNN-transfer 方法識別準確率比較Fig.4 Comparison of recognition accuracy between S3D CNN and S3D CNN-transfer method
由圖4 可知,S3D CNN 的識別準確率僅為49.46%,而采用遷移學習方法進行訓練的S3D CNNtransfer 則有效避免了直接利用小規模數據集訓練深度神經網絡出現的過擬合問題,準確率達到67.58%,提升了18.12 個百分點。
本節還探究了遷移學習對模型學習效率的影響。如圖5 所示為S3D CNN 和S3D CNN-transfer兩個模型在LOSO 驗證中的其中2 輪驗證結果的對比。在圖5(a)所示的第6 輪驗證中可以看出,S3D CNN-transfer 在迭代10 個周期左右訓練準確率趨于穩定,模型開始收斂。而S3D CNN 需要迭代20~25 個周期才收斂,且波動相對較大。在圖5(b)所示的第16 輪驗證中,S3D CNN-transfer 在迭代11 個周期左右就開始達到收斂狀態,而S3D CNN 在迭代15~20 個周期左右才逐漸達到收斂狀態。在其它輪次的驗證中也存在類似的情況。從圖中還可以看出,S3D CNN-transfer 的訓練準確率遠遠高于采用隨機賦值進行初始化的S3D CNN。表3 對2 個模型在26 輪交叉驗證中的平均收斂周期、訓練40 個周期后的平均訓練準確率和平均訓練損失進行了對比。從表3 中可以看出,由于采用遷移學習方法進行訓練的S3D CNN-transfer 在預訓練階段已經學習到了一些與表情分類相關的特征,因此在微調階段實現了更好的學習效果,在26 輪交叉驗證中的平均收斂周期和平均訓練損失分別降低了9.27 和0.36;平均訓練準確率提高了27.81 個百分點。由表3 可知,采用遷移學習的方法后,模型能夠利用在宏表情分類任務中學習到的模型參數來提高在微表情分類任務中的學習效率,加快了模型的收斂速度,提升了模型的學習效果。
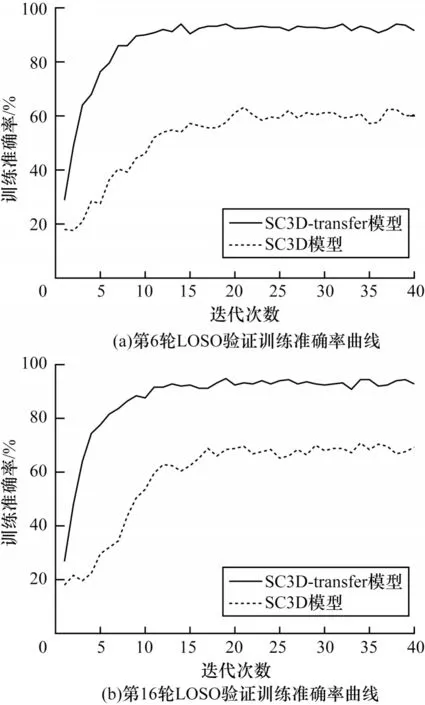
圖5 S3D CNN 與S3D CNN-transfer 模型訓練準確率對比Fig.5 Comparison of training accuracy between S3D CNN and S3D CNN-transfer model

表3 S3D CNN 與S3D CNN-transfer 模型訓練效果對比Table 3 Comparison of training effect between S3D CNN and S3D CNN-transfer model
3.4.3 不同模型識別效果比較
本節將所提出的S3D CNN-transfer 與2D CNNtransfer 和3D CNN-transfer 兩個模型的訓練參數數量、每秒浮點數運算次數(Floating Point Operations,FLOPs)和LOSO 準確率進行了比較,如表4 所示。2D CNN-transfer 將S3D CNN-transfer 中的一維時域卷積層全部刪除,僅保留了二維空域卷積層用于提取光流特征幀序列的空域特征。3D CNN-transfer 將S3D CNN-transfer 中的可分離三維卷積層全部替換成了傳統的三維卷積層。3 個模型均采用了3.2 節的遷移學習方法和參數進行訓練。
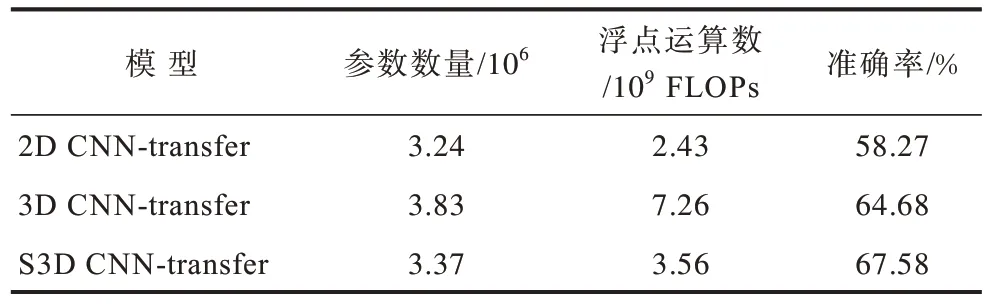
表4 2D CNN-transfer、3D CNN-transfer 與S3D CNNtransfer 方法識別效果對比Table 4 Comparison of recognition effect between 2D CNN-Transfer,3D CNN-Transfer and S3D CNNTransfer method
通過對比表中的數據可知,由于2D CNN-transfer無法捕獲表示微表情動態變化的時域特征,僅能通過空域特征識別,準確率低于能夠同時提取空域特征和時域特征的3D CNN-transfer 和S3D CNNtransfer。3D CNN-transfer 雖然能夠提取微表情的時空特征,實現了比2D CNN-transfer 更好的識別效果,但增加了較多的訓練參數,且模型所需的計算量也大幅增加。S3D CNN-transfer 利用二維空域卷積加一維時域卷積的方式來模擬3D CNN-transfer 的三維卷積過程,使模型與3D CNN-transfer 一樣具有時空特征提取能力,而訓練參數和計算量比采用傳統三維卷積的3D CNN-transfer 更少。此外,在S3D CNN-transfer 的二維空域卷積層和一維時域卷積層之間增加的激活函數有效提升了模型的學習能力,因此準確率稍高于3D CNN-transfer。
4 結束語
現有的微表情識別方法準確率較低,且由于微表情樣本數量不足導致了過擬合問題。本文提出一種結合遷移學習與S3D CNN 的微表情自動識別方法,提取包含宏表情和微表情運動與形變特征的光流特征幀序列,并根據遷移學習的方法,利用宏表情的光流特征幀序列對S3D CNN 進行預訓練。在此基礎上,通過使用微表情的光流特征幀序列微調預訓練后的模型參數,有效提升微表情自動識別的準確率。實驗結果表明,所提方法相比于MagGA、C3DEvol 等前沿微表情識別算法,具有更高的識別準確率。但光流法仍然存在計算量較大、算法較為復雜、實時性和實用性較差等問題。下一步將在保證識別準確率的前提下,通過降低算法的復雜度、減少運行所需時間和計算資源,使該方法能更好地滿足實時應用及在復雜場景下的應用需求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
