基于K?Means 聚類與深度學習的RGB?D SLAM 算法
2022-01-14 03:02:32張晨陽吳壯壯
計算機工程 2022年1期
張晨陽,黃 騰,吳壯壯
(河海大學地球科學與工程學院,南京 211100)
0 概述
同時定位與制圖(Simultaneous Localization and Mapping,SLAM)是機器人在未知場景中構建地圖和實時更新、環境自主定位的過程[1],SLAM 算法是機器人在未知環境作業的關鍵技術和機器人自動化領域的研究熱點[2]。距離傳感器常被作為SLAM 感知周圍環境的數據源[3],相比聲吶、雷達等測距傳感器,其視覺相機體積較小、功耗較低且能夠獲取豐富的紋理信息,為機器人導航定位提供周圍實時的環境信息。視覺SLAM 已被運用于美國NASA 火星探測計劃以及我國嫦娥三號、嫦娥四號探月計劃[4-6]。RGB-D 相機是一種新型的視覺傳感器,由彩色相機和深度相機組成,能夠同時感知未知環境的深度信息和彩色紋理信息[7]。目前,以微軟Kinect 系列為代表的RGB-D 相機被廣泛應用于機器人、計算機視覺、生物醫學工程等領域[8-10]。因此,以RGB-D 相機作為數據源輸入的傳感器成為視覺SLAM 的研究熱點。
本文提出一種結合全新的跨平臺神經網絡(NCNN)框架深度學習和K-Means 聚類的RGB-D SLAM 算法。該算法對動態場景中不同特征種類進行識別分割,根據相鄰幀極線約束和深度值約束剔除動態特征點,并計算相機的位姿,從而準確地剔除動態特征。同時,保留靜態特征以避免由特征點過少導致的SLAM 系統跟蹤失效問題。
1 相關工作
大部分視覺SLAM 算法多數是基于靜態環境條件下完成的,但是當場景中存在移動物體(如行人、車輛等)時,基于特征的SLAM 算法(ORB-SLAM2[11]、LSD-SLAM[12]、PTAM[13])和直接法的SLAM 算 法(DTAM[14])都無法區分這些場景中移動目標區域的特征種類。動態物體上的特征匹配點會產生數據錯誤關聯,直接導致視覺SLAM 估計姿態精度退化甚至錯誤,使得現有許多魯棒的視覺SLAM 算法應用受到了很大局限。近年來,眾多研究人員關注基于動態場景的視覺SLAM 的研究。
文獻[15]提出動態場景的視覺SLAM 算法,該算法主要包含動態特征的檢測與跟蹤,利用激光測距儀獲取數據并驗證算法的合理性。基于動態場景SLAM 算法的基本原理是在圖像序列中檢測動態物體并剔除。研究者利用稠密場景流識別5 m 范圍內的移動物體,但這種方法識別動態物體存在距離范圍限制且在低紋理場景易將靜態的點特征誤判定為動態點特征[16]。由于視覺場景中大部分特征都處于靜止狀態,只有少數特征處于運動狀態,文獻[17]將這一假設融入動態與靜態特征分割從而提出稠密的RGB-D SLAM 算法。文獻[18]通過假設相鄰圖像幀是勻速運動,對于圖像序列上運動的物體而言,運動物體上的特征點速度大于靜態特征點速度,根據這一準則實現動態特征點剔除。此外,與上述方法不同,文獻[19-20]提出不依賴于先驗假設信息,結合基于粒子濾波的最大后驗估計和碼書模型以實現動態特征的稠密分割,并融合在稠密視覺里程計(Dense Visual Odometry,DVO)中,最后在RGB-D 公開數據集完成測試。
以上動態場景的視覺SLAM 算法都是通過建立直接探測移除動態特征,且假設約束條件比較苛刻。另外一類是利用魯棒的數學模型處理算法盡可能探測動態特征并剔除。文獻[21]利用隨機有限元模型表達視覺特征和測量結果,并用貝葉斯遞歸表示靜態和動態地圖點位置。文獻[22]針對動態場景利用多個相機提出一種CoSLAM 算法,CoSLAM 模型利用特征點二維重投影誤差區分特征點的種類。文獻[23]利用位姿圖表示機器人姿態,根據位姿圖節點誤差閾值剔除尺度動態特征關聯。由于RGB-D 相機能實時提供深度測量值,研究人員利用深度值檢測動態物體,文獻[24]通過估計深度場景的背景模型和幀間位姿以消除移動物體的影響。文獻[25-26]分別利用深度學習建立深度濾波器結合語義信息識別運動物體,文獻[27]利用基礎矩陣以及結合深度聚類約束相機之間姿態,消除動態點特征錯誤的關聯匹配。基于數學模型剔除動態特征的方法定位精度較低且不能準確地區分動態特征和靜態特征。此外,光流也被應用在圖像動態物體檢測,例如,文獻[28]利用光流和高斯混合模型識別動態場景點,文獻[29]結合光流和基礎矩陣剔除動態特征。在實際的動態場景中,由于相機存在運動,基于光流法的視覺SLAM 通常效果不佳且受光照影響較大。除了基于光流場原理,研究人員還借助額外的傳感器來剔除動態場景中外點,文獻[30]結合GMS 特征點匹配原理和滑動窗口借助于多個傳感器消除動態場景中的外點。慣性測量單元(Inertial Measurement Unit,IMU)被運用在動態SLAM中以移除外點。文獻[31]利用RGB-D相機和IMU 以實現動態場景SLAM,其中IMU 測量信息被當作位姿估計的先驗信息以消除動態場景中的錯誤視覺關聯。
近年來,隨著深度學習的快速發展,人們結合深度學習來識別并移除動態特征實現動態場景的視覺SLAM 算法。文獻[32]通過結合卷積神經網絡Fast-RCNN[33]提出一種動態的RGB-D SLAM,利用卷積神經網絡探測矩形框中的人物,然后移除特征關聯位于矩形方框的特征點關聯。文獻[34]根據ORB-SLAM2 結合RGB-D 相機深度值確定動態物體并移除動態物體實現SLAM。文獻[35-36]提出利用YOLO 深度學習模型識別圖像序列中的移動物體。此外,文獻[37]將Dyna-SLAM 結合多視圖幾何以及Mask-RCNN 識別動態場景物體并提供開源的代碼程序,文獻[38]在Dyna-SLAM 基礎上結合語義信息剔除動態特征從而提出DM-SLAM,文獻[39]構建自適應窗格匹配模型并利用Mask-RCNN 實現語義信息識別,實現動態場景的三維重建。文獻[40]利用YOLO 深度學習模型以及對極約束識別動態特征點提出DS-SLAM,文獻[41]利用YOLO 學習模型結合貝葉斯濾波后驗估計識別動態特征,在ORB-SLAM2 基礎上提出一種改進的動態SLAM。基于深度學習的視覺SLAM 算法定位精度較高,但是目前大部分基于深度學習的視覺SLAM 算法易造成動態物體的過剔除現象,導致靜態特征大量丟失,使得視覺SLAM 精度退化,最終位姿估計失敗。
2 算法流程
本文算法流程如圖1 所示,主要分為前端動態特征檢測和后端平差兩部分。對于輸入的RGB和深度圖像數據,本文算法利用RGB 圖像提取ORB[42]點特征,基 于NCNN 網絡框架識別動態特征獲取對應的動態區域。同時,在深度圖像中,本文利用K-Means 進行深度值聚類,根據潛在動態特征占據深度區域內絕大多數像素對其進行識別和分割,然后根據相鄰幀極線約束和深度值約束,剔除動態特征點。最后,通過相鄰幀匹配的靜態特征點計算相機姿態。本文結合前端獲取的靜態特征,在后端進行光束法平差從而獲取高精度相機位姿。
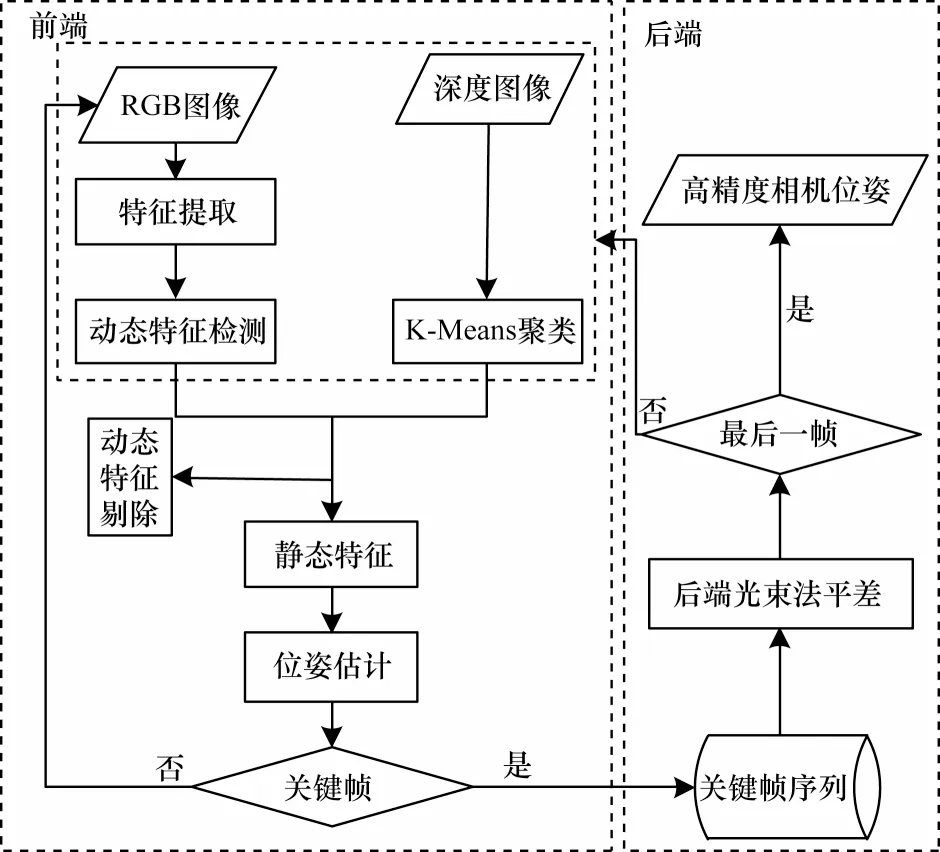
圖1 本文算法流程Fig.1 Proceduce of the proposed algorithm
2.1 準動態信息檢測
為保證目標檢測算法的實時性,本文以Mobile Net 網絡作為目標檢測網絡的前端特征提取網絡。Mobile Net[43]是谷歌團隊推出的一款輕量級網絡模型。Mobile Net 利用深度分離卷積代替傳統卷積,從而減少模型參數數量并提升整體運行效率。Mobile Net 模型是基于深度可分離的卷積,該分解卷積是將標準卷積分解成一個深度卷積和一個1×1的逐點卷積。對于移動網絡,深度卷積在每個輸入通道用一個濾波器。逐點卷積用1×1 的卷積來組合輸出深度卷積。標準卷積在一個步驟對深度卷積和逐點卷積輸入過濾并組合為一組新的輸出。深度上可分離的卷積分為用于過濾的單獨層和單獨的結合層,這種因式分解大幅減少了運算量和模型。傳統卷積與深度可分離卷積示意圖如圖2所示。
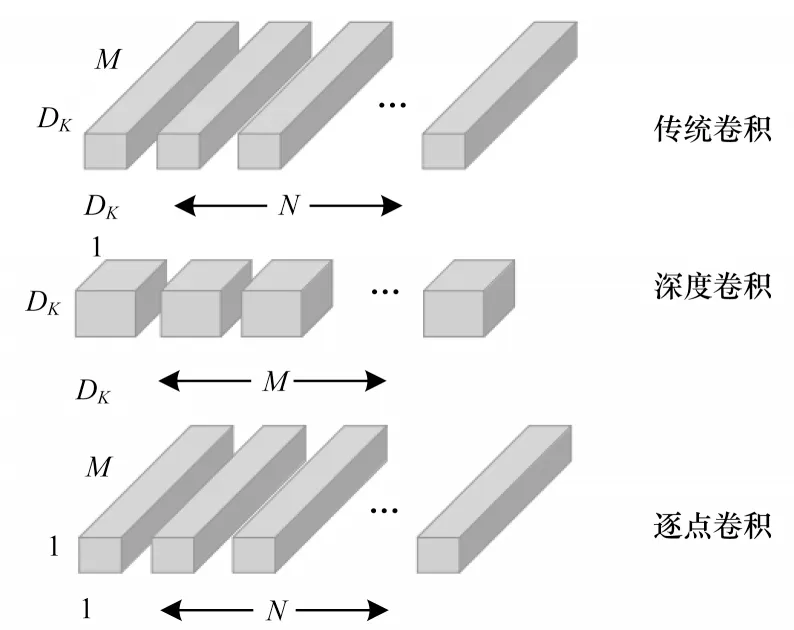
圖2 傳統卷積與深度可分離卷積示意圖Fig.2 Schematic diagram of traditional convolution and deeply separable convolution
傳統卷積的運算量P1如式(1)所示:

其中:Df為輸入圖像的寬和高;M為輸入通道數;Dk為卷積核的長和寬;N為卷積核的個數。此外,為獲取輸入通道數的深度,傳統卷積需要對每個輸入通道深度卷積用單個卷積核進行卷積,隨后利用1×1逐點卷積來線性組合深度卷積新的輸出項。深度可分離卷積的運算量P2如式(2)所示:
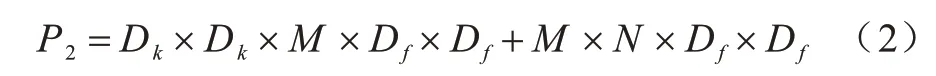
深度可分離卷積與傳統卷積的運算量之比如式(3)所示:

因此,深度可分離卷積能夠大幅降低運算量。根據Mobile Net 目標檢測網絡可以在普通PC 機上使用,本文基于NCNN 平臺框架近似地實現準動態語義信息檢測范圍。語義目標檢測范圍如圖3所示。

圖3 語義目標檢測范圍Fig.3 Detection range of semantic target
2.2 深度圖像K-Means 聚類與動態特征識別
K-Means 聚類是一種簡單的迭代型聚類算法。距離被作為相似性指標,實現劃分給定數據集為k類,且每個聚類的中心都是通過所屬類中所有元素的均值獲得。對于給定的一個包含一維以及n維以上數據點的數據集S和需要聚類的類別數量k,一般以元素間的歐氏距離作為相似度指標,代價函數為聚類后最小化每類的距離平方和。假設數據Si需要劃分為k類,每個數據所屬的類別記作qi,且k個聚類中心表示為cj。對應的代價函數如式(4)所示:

K-Means 聚類算法首先隨機選取k個樣本作為聚類中心,然后按照以下4 個步驟迭代進行:1)計算各樣本與各個聚類中心的距離;2)將各樣本回歸于與其距離最近的聚類中心;3)求各類樣本的均值,并將其作為新的聚類中心;4)若各個聚類中心不再變化或者算法迭代次數超過設定閾值,則退出,否則返回步驟2 循環。
本文根據Mobile Net 獲取圖像上語義信息對應的像素范圍(圖3 方框中),從而得出范圍內的特征點;然后利用深度圖像獲取對應特征點的深度值并對這些特征點深度實行K-Means 聚類,在本文中聚類獲取分為準動態特征聚類和靜態特征聚類。由于語義信息框中動態信息所占區域范圍遠大于靜態背景信息,本文根據聚類值最大的一類劃分為準動態特征,剩下的劃分為靜態特征;依次對每幀彩色圖像和深度圖像進行語義信息識別以及語義信息對應的深度圖像聚類。動態特征剔除流程如圖4所示。
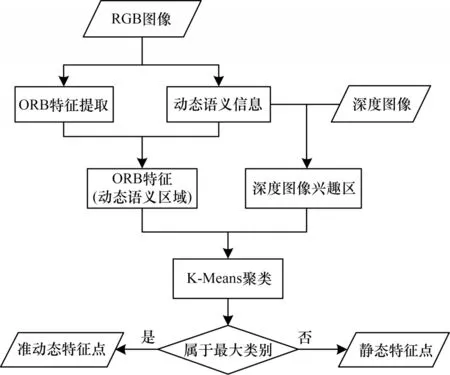
圖4 動態特征剔除流程Fig.4 Culling proceduce of dynamic features
為了能最大程度保留靜態特征,本文在獲取最大聚類集合M時,按照升序排序后的M′,獲取S、B的閾值,如式(5)所示:

其中:m為M’的數量個數;[]表示集合中元素索引對應的元素值。本文根據計算每個語義信息的S和B作為閾值范圍,以區別動態和靜態特征。為了不過大分割動態特征導致靜態丟失,本文選擇的區間位于集合總數的10%~90%。如果特征點深度值位于選擇的閾值區間時,該特征點屬于準動態特征,否則屬于靜態特征。因此,本文根據上述原則實時自定義檢測準動態特征點和靜態特征點。在TUM 數據集序列中準動態特征提取識別的示例如圖5 所示(彩色效果見《計算機工程》官網HTML 版)。紅色十字表示準動態特征點,綠色十字表示靜態特征點。從圖5 可以看出,在不同的場景中,本文算法能較準確地識別靜態和準動態特征點,以提高相機位姿估計的精度。

圖5 準動態特征提取識別示例Fig.5 Extraction and recognition example of quasi dynamic features
本文在獲取靜態特征點后,首先利用當前幀和參考幀進行靜態特征點匹配獲取匹配點集合Q;其次根據靜態匹配點集合Q計算相機運動的基礎矩陣F。對于上述的每個準動態特征點,本文利用對極約束識別動態特征點,設置一定的閾值并根據式(6)計算每個準動態特征點到極線的距離,若距離大于閾值則認為是動態特征點,否則歸為靜態特征點。對極幾何約束如式(6)所示:

其中:Ci和Ri分別為當前幀和參考幀匹配點的齊次坐標;F為基礎矩陣。
對極幾何約束如圖6 所示。
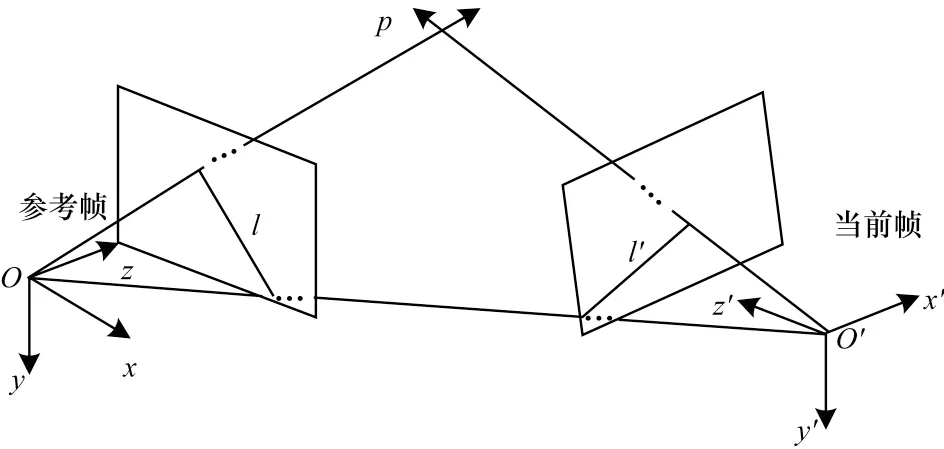
圖6 對極幾何約束Fig.6 Constraints of epipolar geometry
由于每幀彩色圖像對應深度圖像,本文通過兩幀匹配點對應的深度差再次識別動態特征點,利用上述靜態特征點和對應的深度值結合P3P 算法計算當前幀和參考幀之間的位姿。本文根據計算的參考幀和當前幀的位姿,采用潛在動態特征點對應的深度值恢復當前幀匹配點,匹配點在三維空間下的距離差Derror如式(7)所示:

其中:Xref為參考幀三維坐標;Xcurr為當前幀三維坐標。
本文根據每對匹配點在三維空間下坐標差獲取匹配點誤差集合并進行降序排列,定義匹配點誤差集合中元素總數量的20%作為動態特征點的閾值,即集合元素值索引排在總數的前20%將被視為動態特征點且剔除。動態特征點識別算法流程如圖7 所示,最后保留的靜態特征點匹配如圖8所示。
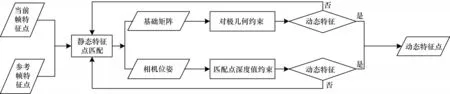
圖7 動態特征點識別算法流程Fig.7 Proceduce of dynamic features point for recognition algorithm

圖8 靜態特征點匹配Fig.8 Static features point matching
本文算法在完成相機位姿估計的同時,判斷當前幀是否為關鍵幀,若是,則插入關鍵幀序列同時進行后端光束平差(Bundle Adjustment,BA)計算,否則該幀將繼續與下一幀進行特征匹配完成相機位姿估計。當完成所有數據序列前端位姿跟蹤估計及后端平差時,最終輸出高精度相機位姿估計結果。
3 實驗與結果分析
本文使用公開的TUM RGB-D 數據集進行驗證并利用絕對路徑誤差(ATE)進行評估。TUM 數據集[44]是慕尼黑工業大學計算機視覺組提供的RGB-D 數據集,動態場景數據集主要是fr3/sitting_xx 系列和fr3/walking_xx 系列,其 中fr3/sitting 和fr3/walking 分別表示低動態和高動態場景數據集。本文實驗計算機的硬件參數為:ThinkPad T480,CoreTMi5-8250U CPU@1.60 GHz,4 GB內存。算法基于C++、g2o、OpenCV3.2.0等進行編寫,并在Ubuntu 16.04 操作系統上實現,最后利用fr3/walking_rpy 公共數據序列驗證算法有效性。本文對所有的fr3 數據序列進行定性和定量實驗,進一步驗證算法的精度和魯棒性。
為了驗證算法的有效性,本文首先使用數據集fr3/walking_rpy 分別對經典的ORB-SLAM2 算法、基于Mobile Net 深度學習動態SLAM 算法以及本文(Mobile Net+K-Means)算法進行實驗對比。不同算法的相機絕對位姿誤差對比如表1 所示,其中,RMSE 表示均方根誤差,Mean 表示均值,Median 表示中位數,Std 表示方差,Min 和Max 分別表示最小值和最大值。

表1 不同算法的相機絕對位姿誤差對比Table 1 Absolute pose error of camera comparison among different algorithms m
從表1 可以看出,ORB-SLAM2 算法的相機位姿估計結果受動態特征的影響精度較差;利用Mobile Net 剔除動態特征的視覺SLAM 位姿估計精度有所提高;本文算法可以最大程度地保留多數靜態特征點,因此獲得較高精度的相機位姿估計結果。
為進一步驗證該算法的位姿估計精度,本文在TUM RGB-D 數據集上完成實驗并與MR-SLAM[19]算法、基于光流(Optical Flow)的動態SLAM(OFDSLAM)[29]算法、ORB-SLAM2 算法、Dyna-SLAM[37]算法和DS-SLAM[40]算法分別比較相機絕對位姿估計的均方根誤差。在數據集序列中不同算法的均方根誤差對比如表2 所示,其中“—”表示該算法沒有提供對應的數據。從表2 可以看出,在8 個實驗數據序列中,本文算法的相機位姿估計精度相對于ORB-SLAM2 和OFD-SLAM 算法都有很大的提升。與其他動態SLAM 算法的實驗結果對比,本文算法在5 組數據集上表現更優,在剩余的3 組數據集中獲取次優結果。
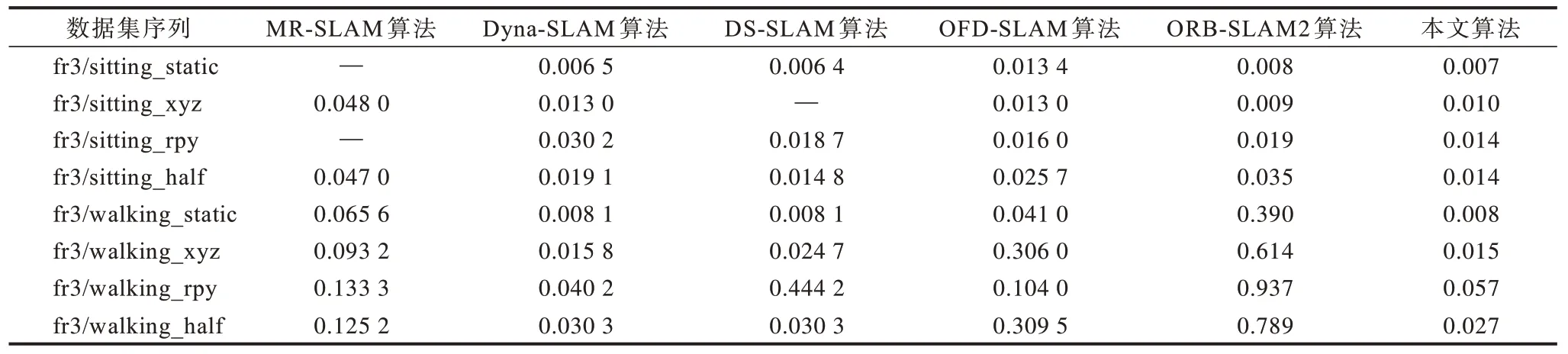
表2 在數據集序列中不同算法的均方根誤差對比Table 2 Root mean square error comparison among different algorithms on data set sequence m
不同算法的相機絕對軌跡誤差如圖9 所示(彩色效果見《計算機工程》官網HTML 版),紅色線表示相機軌跡真實值和估計值之間的差,黑色實線表示相機軌跡真實值,藍色實線表示相機軌跡估計值。從表2 和圖9 可以看出,ORB-SLAM2 和OFD-SLAM算法在低動態場景下軌跡誤差相對較小,在高動態場景下相機絕對軌跡誤差較大并且OFD-SLAM 算法容易丟幀。由于ORB-SLAM2 算法不能區分場景中靜態和動態特征,高動態場景中受動態特征影響易導致精度退化。由于相機存在運動,在高動態場景下光流往往不能較準確地區分動態和靜態特征,從而導致相機位姿估計精度退化。相比其他經典的動態SLAM 算法,本文算法能夠最大程度地保留靜態特征點,獲取相對絕對誤差較優的定位結果。因此,本文算法在低動態場景和高動態場景均能表現較優的準確性和魯棒性。
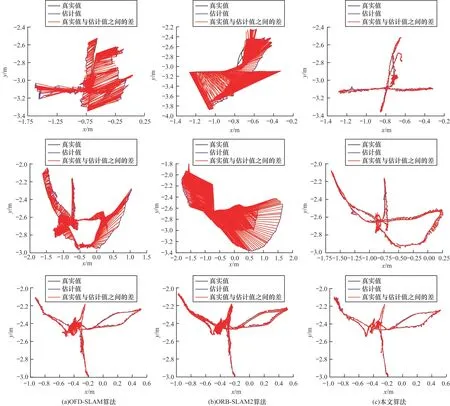
圖9 在TUM 數據集上不同算法的相機絕對軌跡誤差對比Fig.9 Absolute trajectory error of camera comparison among different algorithms on TUM dataset
本文使用RGB-D 相機(X-Tion)在實際的動態場景中進行驗證測試,在場景中存在移動人員的情況下,通過RGB-D 相機連續采集圖像進行實驗,同時利用實時跟蹤設備記錄相機真實的運行軌跡[41]。本文完成實際動態場景實驗并與ORB-SLAM2、OFD-SLAM 算法進行對比。在實際場景中不同算法的相機絕對位姿誤差如表3 所示,在實際場景中不同算法的相機絕對軌跡誤差如圖10 所示(彩色效果見《計算機工程》官網HTML 版),紅色線表示相機軌跡真實值和估計值之間的差,黑色實線表示相機軌跡真實值,藍色實線表示相機軌跡估計值,方框表示相機存在跟蹤丟幀現象。ORB-SLAM2 算法不需要識別動態特征點,跟蹤一幀時間約0.032 s;OFD-SLAM算法需要識別動態特征,跟蹤一幀時間為0.062 s。本文算法基于K-Means 聚類和深度學習需要耗費大量的運算時間,跟蹤一幀時間約為0.680 s,與本文實驗使用的硬件配置也有一定的關系。
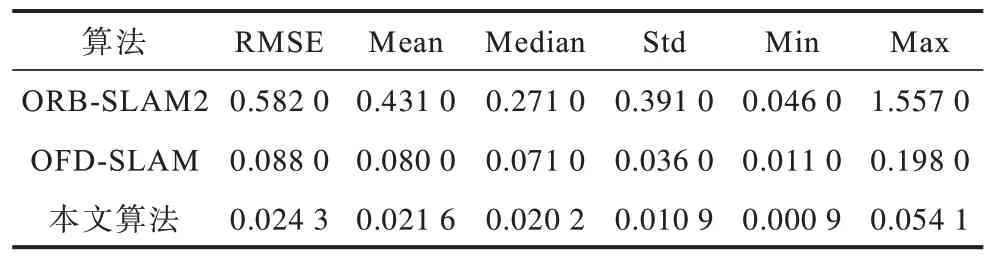
表3 在實際場景中不同算法的相機絕對位姿誤差對比Table 3 Absolute pose error of camera comparison among different algorithms in actual scenario m
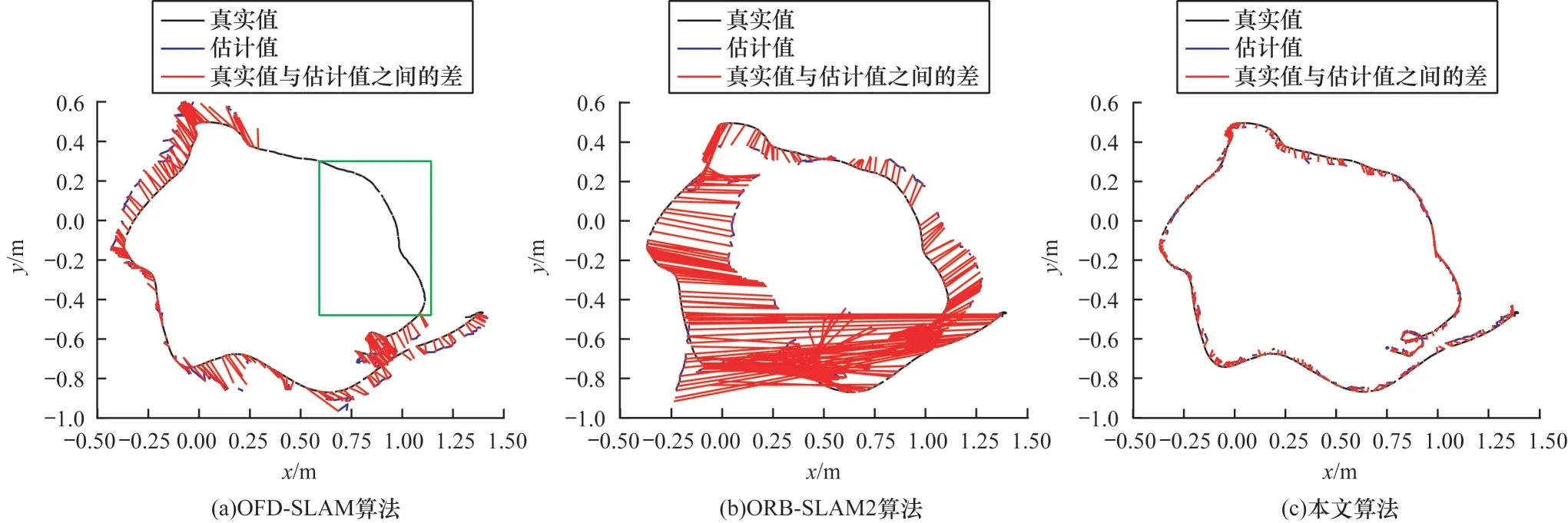
圖10 在實際場景中不同算法的相機絕對軌跡誤差對比Fig.10 Absolute trajectory error of camera comparison among different algorithms in actual scenario
4 結束語
本文提出一種結合深度學習和K-Means 聚類的目標檢測算法RGB-SLAM,通過對動態特征點和靜態特征點進行分類處理,以減少動態特征點對相機位姿跟蹤產生的誤差。實驗結果表明,本文算法能夠有效提高檢測精度,其相機絕對位姿估計性能優于ORB-SLAM2 和OFD-SLAM 算法。后續將通過提取點線特征處理動態場景區域,進一步提高相機位姿估計的準確性和魯棒性。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
