基于局部特征關聯與全局注意力機制的行人重識別
2022-01-14 03:02:34李佳賓李學偉劉宏哲
計算機工程 2022年1期
李佳賓,李學偉,劉宏哲,徐 成
(北京聯合大學北京市信息服務工程重點實驗室,北京 100101)
0 概述
行人重識別是從若干組攝像設備拍攝的多張多角度行人圖片或視頻中尋找目標行人的技術,但存在圖像模糊不清、易于遮擋、角度與姿態多變的問題。傳統算法通過距離度量人手動設計特征(如紋理、顏色等)的差異性,其適應性較差且效率較低。
深度卷積網絡在行人重識別領域中可以提取到諸多圖像特征。文獻[1]利用分類損失與驗證損失進行模型訓練,先使用分類函數進行識別,再使用驗證函數進行判別。三元組損失[2]作為度量學習中的一種損失函數,也是重識別中利用較廣的損失函數。文獻[3]通過Circle Loss 使相似性特征以不同速率進行學習,使算法收斂目標更明確。文獻[4]在遮擋方面利用一種具有判別遮擋能力的池化單元代替傳統池化層,有效地處理行人的遮擋情景。文獻[5]采用GAN 網絡生成行人的多種姿態近似表示。文獻[6]提出一種結合RGB 與灰度圖的方式提取特征,減少因色彩導致的損失與誤差。近年來,文獻[7-9]利用注意力機制加強辨別特征并抑制無關噪聲。由于注意力是通過局部感受野獲得,因此對圖像全局添加注意力較困難。針對該問題,文獻[10]采用大尺寸的卷積核堆疊多個小規模的卷積[11]。文獻[12]利用特征點與全局關系的全局注意力機制以有效地抑制無關特征。基于局部特征也是一種有效的方式,文獻[13]通過PCB 方法將特征圖進行水平切分并預測。文獻[14]提出一種顯著性協作融合的方法進行識別。文獻[15]使用人體關鍵點算法描繪關鍵點,再根據關鍵點進行識別。文獻[16]提出一種分析局部特征與全局關系的方法,分別從全局和局部兩個角度計算特征聯系。文獻[17]采用一種結合注意力機制與核動態上采樣的方式實現跨分辨率的識別研究。文獻[18]采用一種多任務金字塔的方式重疊匹配魯棒性特征。對于注意力機制,雖然以上方法與文獻[13,19]都能夠區分主要特征與無關噪聲,但是基于細粒度特征點與全局的關系,信息會分散,難以有效聚集特征點,因此無法充分利用局部信息。局部切分方案將多個局部特征進行相同的權重處理,然而無法利用最具判別力的關鍵特征,人為將各部分權重提前設定好則不利于算法的自適應性。
本文結合全局注意力機制與局部特征關聯方法,提出一種改進的特征關聯算法LFR-GA。通過調節局部特征之間的關系挖掘圖像全局特征,實現增強局部關鍵特征語義信息并區別非關鍵特征的目的。
1 相關工作
1.1 全局注意力
在深度學習算法中,注意力機制能有效突出關鍵特征點,并合理分配運算資源的算法。在注意力機制的支持下,機器學習算法對圖像中的特征信息進行重點提取,區分重要信息與普通信息,并去除背景等噪聲干擾,使得圖像特征信息得以有效利用。在多種注意力生成方法中,文獻[12]設計一種考慮圖像各點之間緊密聯系的全局注意力機制。這種技術可以有效地去除圖像背景等噪聲干擾,并具有一定的關鍵特征提取能力和較強的全局性,其立足點是各個像素點與全局像素點的關系。
1.2 局部特征關聯
在機器視覺領域中,不同階段的全局特征和局部特征能夠表示不同程度的視覺信息,將局部與全局特征相關聯也是視覺領域的主要方法。文獻[16]提出一種特征關聯網絡,同時考慮局部與全局、局部與局部的關聯程度,并計算不同局部特征之間的相互聯系,使得關鍵局部特征得以顯現。
1.3 全局注意力機制的改進
本文首先縮減全局注意力生成的步驟,其次使用一種新的局部特征組合方式進行局部特征關聯判斷,基于這兩種方法提出一種新型網絡,使得網絡可以去除多種噪聲干擾,并自適應地提取關鍵特征點,兼顧全局特征點與局部特征塊關系。
2 模型構建
2.1 LFR-GA 網絡結構
LFR-GA 網絡結構如圖1 所示,主要分為基礎特征提取網絡、全局注意力生成、局部特征關聯、損失函數計算4 個部分。
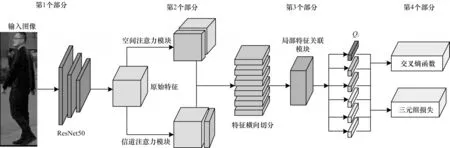
圖1 LFR-GA 網絡結構Fig.1 Structure of LFR-GA network
LFR-GA 網絡經過ResNet 50 基礎網絡提取特征,對特征分別進行空間注意力與信道注意力的生成計算,并進行初次處理。與原來算法相比,本文在拼接特征模塊時,刪除特征點轉置關系張量部分,并使用局部特征關聯補充局部特征關系權重。在局部特征關聯中,本文對特征進行分片,將全局特征切分為多個局部特征,并計算局部特征之間的聯系以突出關鍵特征。本文將局部特征分別與其他每個局部特征進行逐個關聯,將結果拼接再關聯以表示全局聯系,最終得到5 個1×1×C的向量,并根據特征向量進行識別。在損失函數計算中,本文使用交叉熵函數與三元組損失函數的聯合訓練,從分類與度量兩個角度進行整體優化。本文主要綜合全局注意力機制與局部特征關系,利用全局注意力彌補局部關聯中缺少的部分全局信息,并有效抑制無關噪聲的影響,以彌補局部特征可能包含噪聲導致的預測影響;而使用局部特征關系可以彌補全局注意力難以使用的局部特征塊的語義信息,將主要特征中最關鍵的特征重點利用,使算法能夠識別相似度較高且難以區分的樣本,進一步增強識別能力。
2.2 全局注意力機制
全局注意力機制考慮到全局范圍關系具有結構化信息,其觀點類似于聚類信息,具有從全局范圍關系中提取語義信息的可能性,使用此類結構信息生成注意力。對于任意一個特征節點,全局注意力機制均可計算出其與全局的關系向量,關系向量能有效地挖掘結構信息,包括其余各點的位置信息和兩兩成對的關聯信息。全局注意力機制包括空間位置注意力和特征通道注意力,兩部分注意力可以強化圖像特征以抑制無關信息,從單個特征點與全局特征點的聯系開始提取信息,生成特征點關聯信息圖,并依據關聯圖信息生成注意力。
2.2.1 ResNet50 網絡
ResNet 網絡又稱ResNet 深度殘差網絡,針對深度學習中網絡退化問題,HE 等提出ResNet 深度殘差網絡。殘差學習是ResNet 深度殘差網絡的核心,殘差學習的原理為跳躍連接,在卷積結果中加入原始特征的恒等映射,使得學習過程中即使效果不理想,結果也不會更差。ResNet50 深度殘差網絡參數設置如表1 所示。
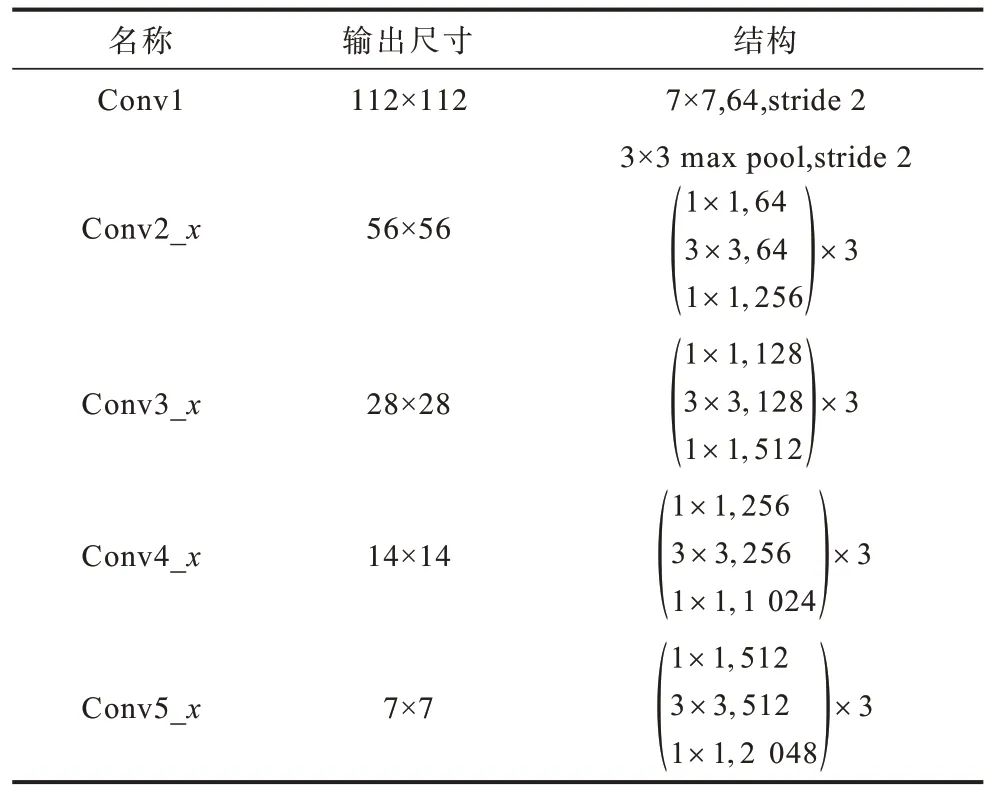
表1 ResNet50 深度殘差網絡參數設置Table 1 Parameter settings of ResNet50 deep residual network
2.2.2 空間注意力網絡結構
空間注意力網絡結構如圖2 所示,首先經過ResNet50 得到一個特征張量X∈RC×H×W,其中C為特征圖通道數,H為高度,W為寬度,從空間位置的角度考慮,每張特征圖中包含H×W個特征點,記為N個,則每個特征點可表示為xi∈RC,其中i=1,2,…,N,定義一種關系成為親和關系,表示空間節點之間的關聯程度,記為ri,j。對于空間位置上N個特征點,空間注意力模塊需要逐個對其與其他特征點的親和關系進行計算,將所有親和關系記錄在一個N×N的關系矩陣中,又稱空間特征點親和度圖。親和度既包括局部信息又包括全局信息的關聯信息,注意力生成還需要原始特征圖的特征信息。由于關系信息脫離關系主體則毫無意義,因此注意力計算需要將原始特征壓縮與親和關系信息結合,以利用與特征相關的全局結構信息。
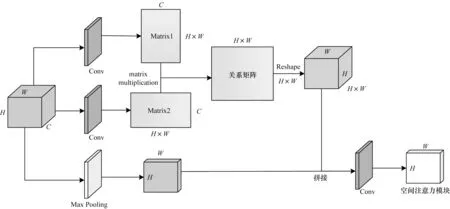
圖2 空間注意力網絡結構Fig.2 Structure of spatial attention network
空間注意力的生成步驟主要分為2 步:1)對特征張量R進行兩層卷積,調整其規模分別為(H×W)×C和C×(H×W)的兩個矩陣,將其進行相乘得到一個維度為(H×W)×(H×W)的關系矩陣,操作其Reshape 改變維度為(H×W)×H×W的三維張量;2)對初始特征圖進行最大池化操作得到一個H×W的特征圖,將特征圖與進行拼接,對結果進行卷積操作得到一個H×W的系數矩陣,對矩陣進行Sigmoid 操作得到空間注意力。親和關系的計算如式(1)所示:
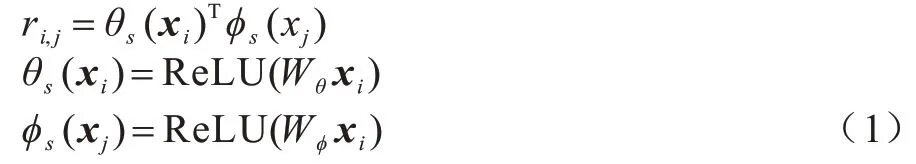
其中:θS和φS均為包含BN 以及ReLU 操作的1×1 卷積;Wθ∈RC/S1×C且Wφ∈RC/S1×C,S1為一個預定義的正整數,用于控制降維率。根據式(1)計算得到ri,j之間的關系信息,隨后對所有特征點逐一執行此操作得到一個親和關系圖RS∈RN×N。為綜合學習特征點i的全局與局部信息,空間注意力模塊不僅了解特征點之間的親和關系,還需要原始特征點的特征信息,考慮到這兩部分特征不在一個特征域,因此需要進行不同處理,如式(2)所示:
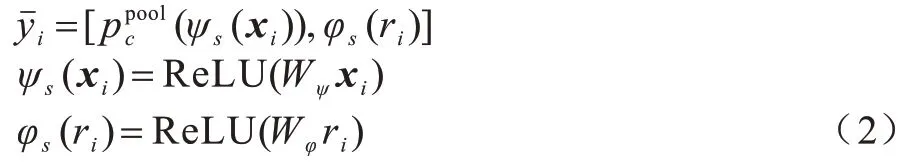
其中:ψs與φs分別為特征本身以及特征親和關系的嵌入函數,且兩者均為包含BN 以及ReLU 的1×1 卷積操作;是一個平均池化操作,將原始特征圖按照信道方向進行壓縮至維度降為1,使得原始特征為一張1×H×W的特征圖;yˉi將兩部分進行拼接,結果包含特征本身以及特征的全局關系,根據全局關系挖掘豐富的結構信息,結構信息中的注意力系數如式(3)所示:
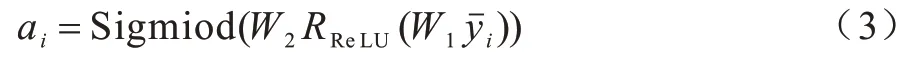
其中:W1和W2均為1×1 卷積操作,W1,W2將信道數量減少為1,各個數值經過Sigmoid 函數后變為注意力系數,其維度對應空間位置的所有特征點。
2.2.3 信道注意力模塊結構
信道注意力的生成原理與空間注意力基本一致,只是將計算空間特征點之間的關系注意力轉變為計算通道之間的關系注意力。信道注意力利用初始特征圖R計算C×C的通道關系矩陣,再經過Reshape 操作與特征圖R在通道方向的最大池化結果進行卷積得到一個1×C的系數向量。
2.3 局部特征關聯網絡結構
在全局注意力機制的無關特征抑制下,特征圖可以排除部分背景、遮擋等冗余噪聲的影響,在此基礎上,本文增加一個局部特征關聯模塊,不僅利用細粒度特征點的關系信息,還可以由多個特征點組成具有一定規模局部特征塊之間的關聯信息,使得圖像關鍵局部特征更易凸顯且自適應性增強。本文參考文獻[16]的關系網絡內容,具有上述空間注意力的全局關聯判斷,對另一部分網絡one-vs-rest 進行修改,并逐個判別,以增強局部特征關聯間的判斷。
局部特征關聯網絡結構如圖3 所示,從空間注意力模塊中獲得特征圖按照橫向進行切片,本文將圖像切為6 個部分,表示6 個C×H/6×W特征部分,分別計算得到其相關聯的程度信息。在計算某一部分的關聯程度時,局部特征關聯模塊需將其與其他5 個部分兩兩組合判別局部關聯,再將多個局部關聯整合提取全局關聯信息。
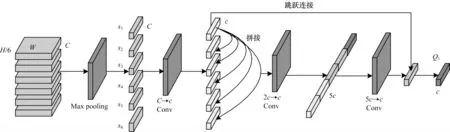
圖3 局部特征關聯網絡結構Fig.3 Structure of local feature association network
局部特征關聯模塊將6 個分割張量分別在空間方向上使用最大池化得到6 個局部特征塊pi(i=1,2,3,4,5,6),其維度為1×1×C;然后對pi進行1×1 卷積操作使其維度變為1×1×c,將卷積后的6 個特征塊記為,最終對每個分別計算其局部-全局的關系向量Qi,使用跳躍連接方式將每個局部特征與其關系向量結合,如式(4)所示:
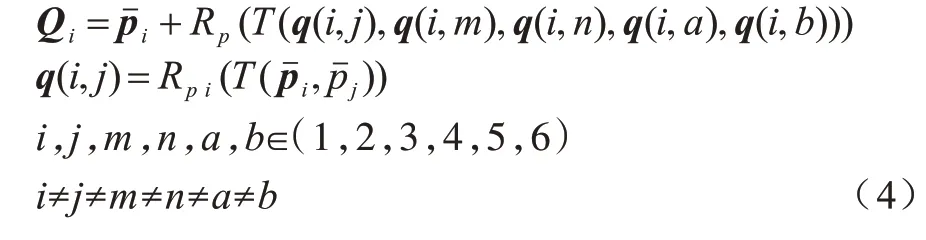
其中:Rp為一個由1×1 卷積,歸一化以及ReLU 非線性激活的子網絡,卷積操作將通道數量由5c轉變為c;T為特征串聯拼接操作;q為兩個局部特征模塊的關系向量;i、j、m、n、a、b為6 個局部特征中的某一個,各不相同,如i=1,j=2,m=3,n=4,a=5,b=6;Rpi為另外一類1×1 卷積,將2 個拼接特征向量進行卷積使得信道數量由2c變為c。式(4)分別計算某一個局部特征與其余各個局部特征的關系向量,再利用得到的5 個向量生成增強的特征向量。
局部特征關聯模塊可以充分考慮局部特征之間的相互聯系,使特征向量具備更豐富的結構信息,多個局部特征模塊能夠表示具體的關聯強弱,并利用較關鍵的局部特征以抑制弱化非重要特征的影響。
2.4 損失函數
為了使網絡能夠精準地提取關鍵特征,本文結合三元組損失函數與交叉熵函數進行訓練,這兩種損失函數是重識別算法中常用的函數。交叉熵函數作為一種分類損失函數,如式(5)所示:
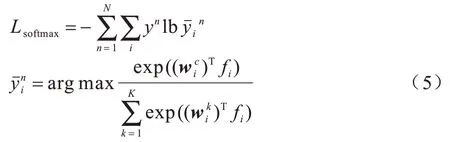
其中:N與yn分別為一個batch 數據中的數據數量以及真實標簽為每個行人在預測過程中每個識別特征的標簽;K為預測標簽的數量;為特征fi與標簽k的分類器。
三元組損失函數是識別算法中被廣泛應用的一種損失函數,其中A、P、N 分別表示目標圖片、正樣本圖片、負樣本圖片,分別計算AP 與AN 之間的差異性,結合AP 與AN 作為損失函數。三元組損失函數設計旨在增加類間距離,減少類內距離,在訓練時為了使算法更加精準,使用與A 距離最遠的P 以及與A 距離最近的N 作為訓練數據,三元組損失函數如式(6)所示:
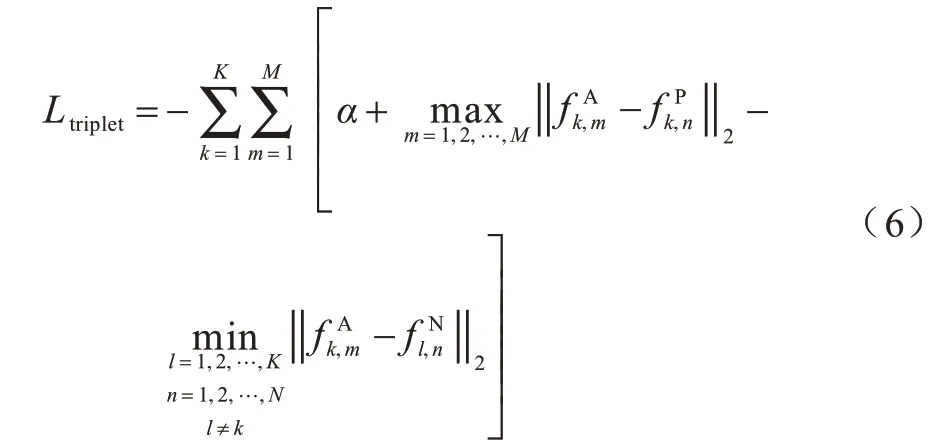
其中:K為一個批量數據中行人的數量;M為每個行人對應標記圖片的數量;α為預設值,用于調節正負樣本判別之間的距離;分別為目標圖像、正樣本圖像以及負樣本圖像中提取的特征。
3 實驗與分析
3.1 實驗數據集
本文在3 個數據集CUHK03[20]、Market1501[21]、DukeMTMC-reID[22]上進行實驗以驗證算法的有效性。CUHK03 數據集是在大學中采集的行人數據集,主要包含使用DPM 算法檢測標記的Detected 部分和人為手工標記的Labeled 部分,整個數據集使用6 個攝像頭分為3 組拍攝,包含1 467 個行人ID 以及14 097/14 096 個標記框,其測試集包括700 個行人ID 以及5 332/5 328 個標記框;訓練集包括767 個行人ID 以及7 365/7 368 個標記框。Market1501 數據集包含由6 個攝像頭拍攝的1 501 個行人ID,共有32 668 個檢測標記框,測試集包含750 個行人以及19 732 張圖片,訓練集包含751 個行人以及12 936 張圖片。DukeMTMC-reID 包含1 404 個行人ID 以及36 411 張圖片,測試集包含702 個行人ID 以及17 661 張圖片,訓練集包含702 個行人ID 以及12 936 張圖。
3.2 實驗條件
本文在實驗中使用ubuntu16.04 系統,python3.6 編程語言,pytorch1.1.0 深度學習框架,關鍵計算硬件為TITAN XP 顯卡進行加速運算。本文算法將輸入圖像尺寸調整為384×128,每個batch 的尺寸為64,其中一次選擇16 個行人ID,對于每個行人選擇4 張圖片,總訓練批次為500,模型網絡的初始學習率為0.000 8,權重衰減系數為0.000 5。
3.3 實驗評估指標
在行人重識別中,本文用首位命中率(Rank-1)和平均準確率均值(mmAP)作為評價指標。首位命中率是在所有組行人識別中,每組排在第一位的識別結果正確的命中率;mmAP需要先進行平均精度(AAP)計算,如式(7)所示:
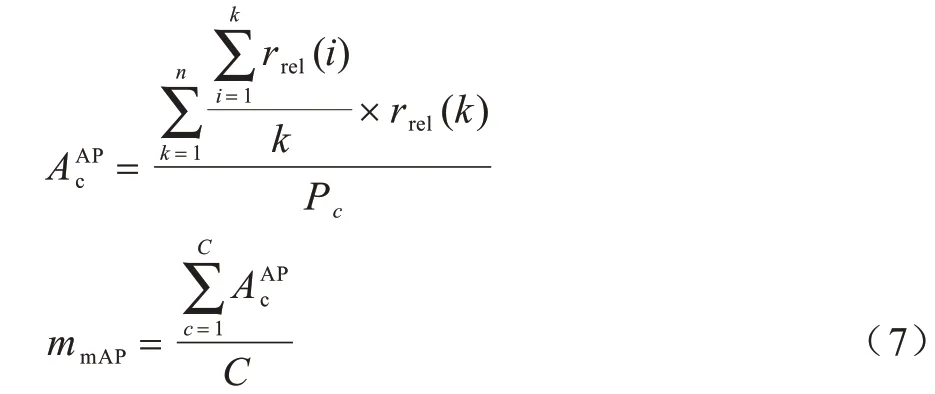
其中:Pc為這一組分類中命中的圖像數量;如果第k個圖像命中,則rrel(k)為1,否則為0;n為一組圖像預測中選擇的圖像總數量;C為總分類組數。
3.4 實驗結果分析
3.4.1 局部特征關系分塊數量的影響以及有效性
本文分別將水平切塊數量設置為5、6、7,并在CUHK03 數據集上進行驗證切分方法的有效性。不同分塊的mmAP對比如圖4 所示。局部特征關聯模塊評估指標對比如表2 所示,對比網絡為單一注意力網絡。
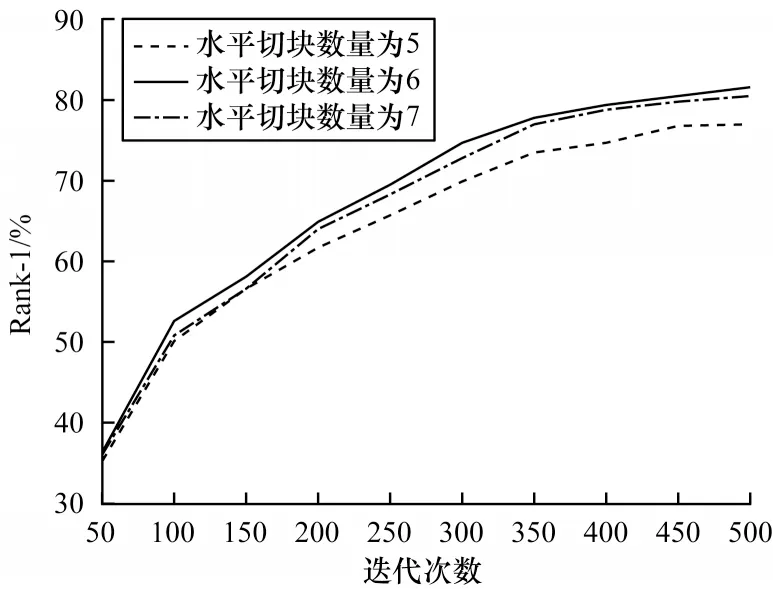
圖4 不同分塊的mmAP對比Fig.4 mmAP comparison among different blocks
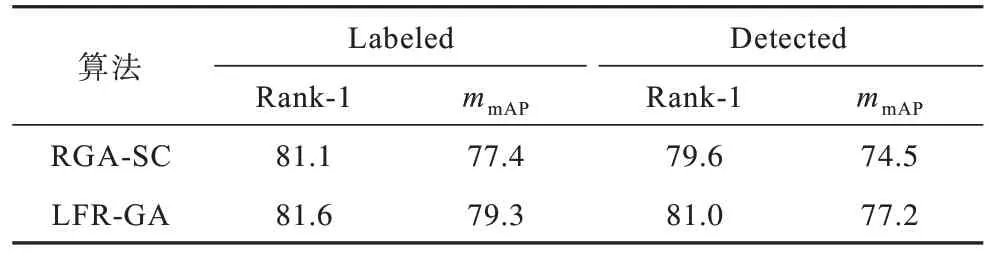
表2 在CUHK03數據集上局部特征關聯模塊評估指標對比Table 2 Evaluation indexs comparison of local feature association module on CUHK03 data set %
從圖4 可以看出,當分塊為5 塊時,最終Rank-1 低于80%。當分塊為6 塊時,Rank-1 能夠有效地提升,迭代次數500 后Rank-1 達到81.6%。當塊數增加為7 塊時,前250 迭代次數與6 塊的Rank-1 差別不大,與6 塊相比,后250 迭代次數7 塊的Rank-1 逐漸收斂并略微降低。實驗結果表明,局部特征分為6 塊時,Rank-1 值最佳。本文實驗將塊數分為5 時,Rank-1 得到進一步提升,說明將特征尺度縮小時,識別效果能夠有效提升;當塊數繼續增長為6 時,識別效果有了更大的提高,而分為7 塊時,局部信息分割過于細微,使得部分特征割裂,降低效果。
3.4.2 算法對比
本文算法在CUHK03、Market1501、DukeMTMCreID 3 個數據集上與目前行人重識別領域較經典以及先進的算法進行對比,以Rank-1 以及mmAP值作為衡量指標,選取的對比算法大多是將ResNet50 網絡作為基礎,同樣運用注意力機制或局部特征切分方法,驗證實驗存在可對比性,結果如表3、表4 所示。
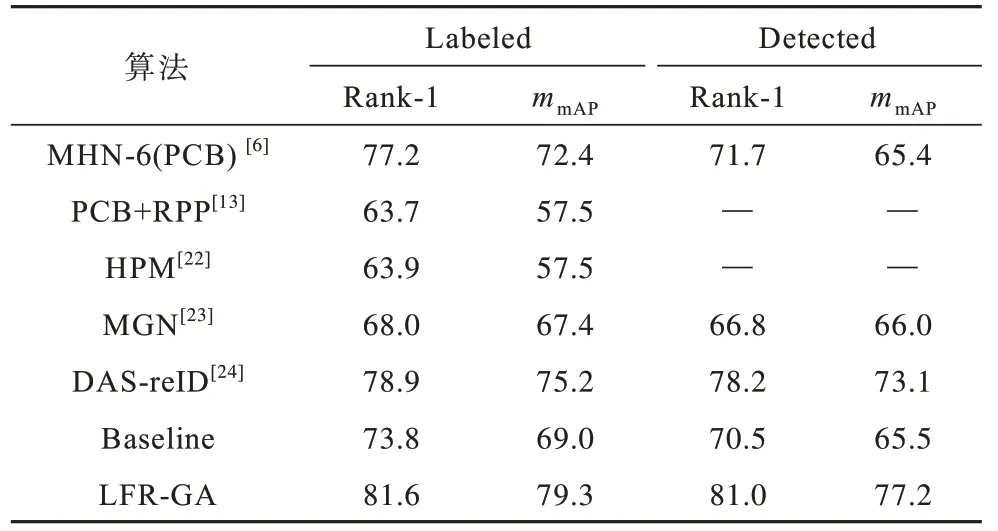
表3 在CUHK03 數據集上不同算法的實驗結果對比Table 3 Experimental results comparison among different algorithms on CUHK03 data set %
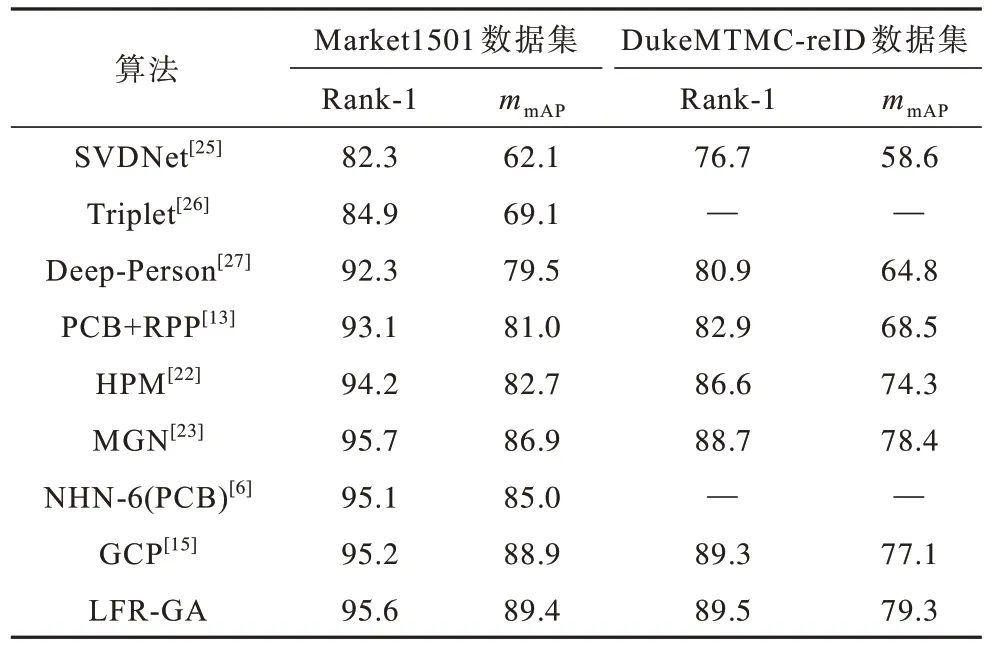
表4 在Market1501、DukeMTMC-reID 數據集上不同算法的實驗結果對比Table 4 Experimental results comparison among different algorithms on Market1501 and DukeMTMCreID data sets %
從表3 和表4 可以看出,本文算法在多個公開數據集上的評價指標均得到提高。與ResNet 的Baseline 算法相比,在CUHK03 數據集Labeled 上本文算法的Rank-1 與mmAP指標分別提升7.8、10.3 個百分點,在Detected 上其Rank-1 與mmAP指標分別提升10.5、11.7 個百分點。與DAS-reID 算法相比,在Labeled 上本文算法的Rank-1 與mmAP指標分別提升2.7、4.1 個百分點,在Detected 上 其Rank-1 與mmAP指標分別提升2.8、4.1 個百分點。相比GCP 算法,在Market1 501 數據集上本文算法Rank-1 與mmAP指標分別提高0.4、0.5 個百分點,在DukeMTMC-reID 數據集上,其Rank-1 與mmAP指標分別提升0.2、2.2 個百分點。實驗結果表明,本文算法無論在清晰還是模糊的數據集中Rank-1 與mmAP指標均較高,具有較優的魯棒性與自適應性。
3.4.3 實驗結果可視化
為了驗證本文算法的有效性以及與其他算法的對比效果,本節對上述實驗不同場景數據集中的部分實驗結果進行可視化。對比算法為PCB 與MGN,以Rank-5 為標準,其中無邊框的為正確識別結果,有黑色虛線邊框的為錯誤識別結果。不同算法的整體特征識別結果對比如圖5 所示,當查詢圖像與備選圖像整體高度相似時,LFR-GA 算法能夠有效利用最關鍵特征對圖像進行準確識別,其他算法在這種高度相似的情況下容易出錯。行人自遮擋對不同算法識別結果的影響如圖6 所示。在目標被其余行人遮擋的情況下,LFR-GA 算法能夠有效處理遮擋圖像信息,充分利用有效的局部特征信息識別目標。背景干擾對不同算法識別結果的影響如圖7 所示,當目標存在背景行人干擾時,LFR-GA 算法能夠充分利用目標的有效特征信息,去除背景噪聲影響。因此,針對復雜的多種場景,LFR-GA 算法在限制條件較為嚴格的情況下依然具有較強的識別效果。

圖5 不同算法的整體特征識別結果對比Fig.5 Recognization results of overall feature comparison among different algorithms

圖6 行人自遮擋對不同算法識別結果的影響Fig.6 Influence of recognization results of different algorithms on person self-occlusion

圖7 背景干擾對不同算法識別結果的影響Fig.7 Influence of recognization results of different algorithms on background interference
4 結束語
本文結合全局關系注意力機制和局部特征關聯方法,提出一種改進的局部特征關聯算法LFR-GA。根據特征的全局關聯與局部關聯提取圖像語義信息,以增強局部關鍵特征。實驗結果表明,相比PCB、MGN 等算法,LFR-GA 算法的平均準確率和首位命中率較高,具有更強的準確性和自適應性。后續將針對局部特征關聯與損失函數進行研究,通過簡化模型結構以減少計算量,在保證識別精度的前提下達到加快模型運行速度的目的。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
學苑創造·A版(2018年11期)2018-02-01 06:29:20
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
讀者(2017年5期)2017-02-15 18:04:18
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
當代修辭學(2011年2期)2011-01-23 06:39:12
