分布式系統數據倉庫工具Hive 的工作原理及應用
2022-01-18 02:33:54陳新房劉義卿
科學技術創新 2021年36期
陳新房 劉義卿
(防災科技學院信息工程學院,河北 廊坊 065201)
1990 年,比爾·恩門(Bill Inmon)第一次提出了數據倉庫概念,與結構化數據庫不同的是,數據倉庫研究和解決如何從數據庫中獲取信息的問題,數據倉庫的基本特征表現為是一個用戶主題域的、集成統一的、穩定性較強的、反映歷史變化的數據的集合,為管理層進行分析決策(Decision Making Support)提供強有力的支撐。就重要功能而言,數據倉庫仍然是對聯機事務處理(OLTP)長時間以來產生的海量大數據,通過數據倉庫組件特有的數據儲存結構,進行系統的、全面的分析與整理,以便通過不同的方法如聯機分析處理(OLAP)等進行分析處理。同時,隨著數據挖掘(Data Mining) 技術、決策支持系統(Decision-making Support System, DSS)、主管資訊系統 (Excutive Information System)的創建,通過數據倉庫操作能夠幫助決策者從大量數據中,快速高效的分析提取出有價值的信息,以利與決策制定以及對外部環境的變化租出響應。數據倉庫體系結構如圖1 所示。
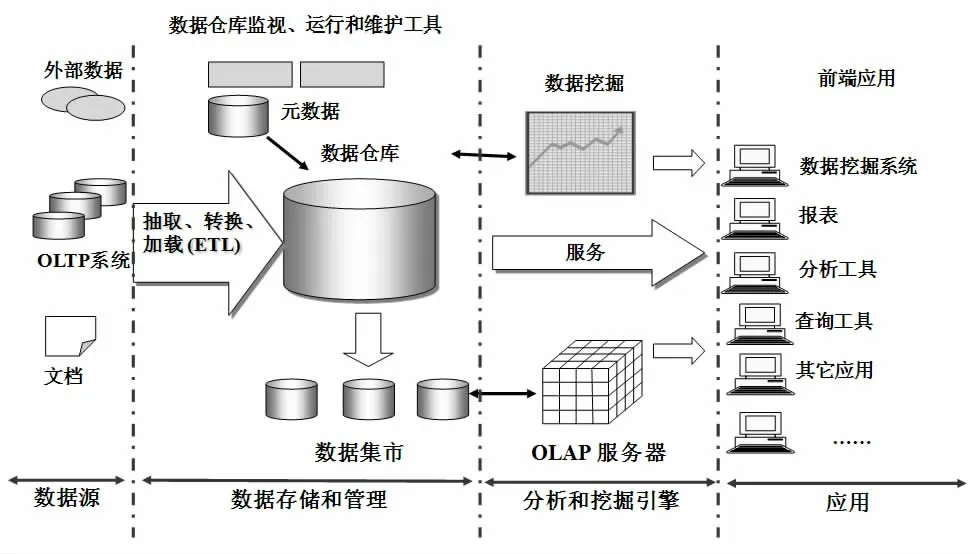
圖1 數據倉庫體系結構
1 數據倉庫工具Hive 概述
Hive 的實現是基于Hadoop 生態系統的,通過Hive 工具,可以對數據進行提取、轉化、加載等操作,能夠對存儲在Hadoop 集群中的海量數據進行存儲、查詢和分析的操作機制。設計Hive工具的主要目的是使得對Java 編程技能掌握相對較弱但是對SQL 技能比較精通的數據分析師對存儲在HDFS 中的海量數據進行查詢功能操作。
Hive 工具將數據文件映射成一張數據庫表,通過類SQL 語言即HiveQL 語言的查詢功能,數據分析師通過編寫相對精通的HiveQL 語句,即可實現MapReduce 任務的功能。這一特性使得Hive 十分適合對大規模數據存儲、統計、分析、查詢操作,由于是部署在Hadoop 平臺之上,因而具有良好的擴展性。Hive 的優點是相對簡單易學,可以快速通過類似SQL 語句實現MapReduce 統計功能,可以大幅提高開發效率。
HiveQL 的設計只是降低了學習成本,其實質仍然是MapReduce 任務的實現。在此,再次強調,Hive 工具本身是數據倉庫,而不是結構化的數據庫系統,二者的主要區別如表1 所示。

表1 Hive 與數據庫的區別
2 Hive 系統架構
Hive 的體系結構可以分為以下幾部分:
2.1 用戶可以通過三種接口實現Hive 的操作,分別是CLI、Client 以及WUI(Web User Interface)等接口。最常用的實現方式是CLI,這種借口形式啟動CLI 接口同時會啟動一個Hive 副本。利用Client 模式可以實現用戶連接至Hive Server,這種形式需要指出Hive Server 所安裝的節點,在該節點上將啟動Hive Server 起來。顧名思義,WUI 接口形式是用戶通過瀏覽器實現Hive 的操作。
2.2 處于Hive 核心位置是驅動程序,由解釋器、編譯器、優化器三部分組成,通過驅動程序將HiveQL 語句進行詞法分析、語法分析、編譯、優化以及生產查詢計劃,進一步將生成的查詢計劃存儲在集群中,隨后轉換為MapReduce 任務執行完成。
2.3 與此同時,Hive 也有結構化數據庫,如MySQL、derBy 數據庫,這種結構化數據表存儲的是數據表的元數據,包括數據表名稱、列(字段)、分區以及是否為外部表、數據所在目錄等信息。如圖2 所示。
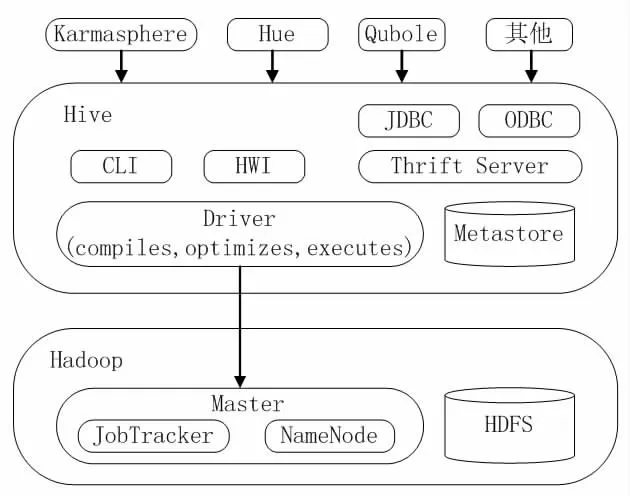
圖2 Hive 系統架構
3 Hive 的數據類型
雖然Hive 與結構化數據庫有很大區別,但是在數據類型方面,Hive 有著與結構化數據庫相同的基本數據類型,同時具有結構化數據庫不具有集合數據類型。
選擇數據類型時,需要考慮的因素主要有兩個方面:一是文本文件中數據類型如何表示的,二是需要考慮數據存儲過程中為了提高存儲、計算性能問題以及其他問題是否具備可以替代的方案。
相比與結構化數據庫,Hive 具有一個獨特的功能就是文件中數據的編碼方式具有非常大的靈活性。如表2、3 所示。

表2 Hive 的基本數據類型
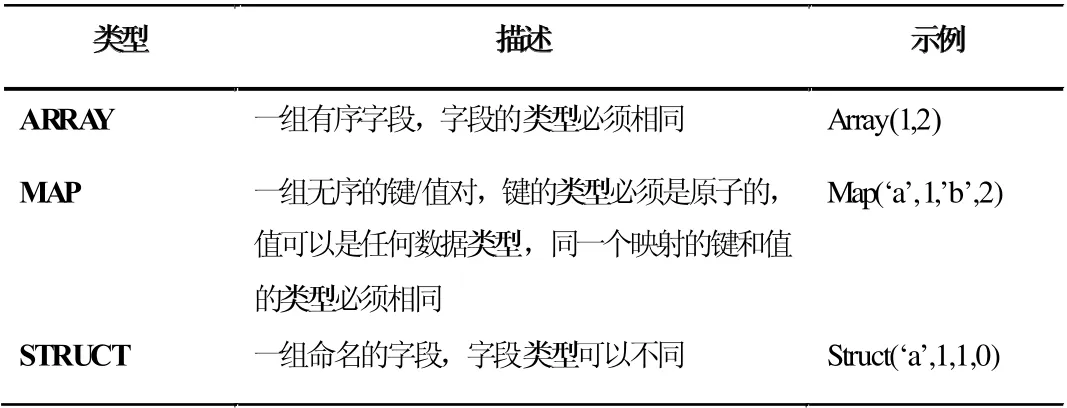
表3 Hive 的集合數據類型
4 Hive 工作原理
簡單來說,Hive 就是基于Hadoop 平臺上的數據倉庫。在Hadoop 平臺上層設計了一個類SQL 接口(即HiveQL)作為查詢接口,可以將HiveQL 裝換為MapReduce 任務在Hadoop 平臺上運行實現。數據分析人員可以通過HiveQL 語言實現對海量數據的統計、分析、查詢操作,而不需要使用編程語言(例如Java)編寫MapReduce 程序進行實現。下面以常見的Group By 操作為例介紹實現過程。
現有一個數據分組Group By 操作,要求是將Score 表中的數據信息進行合并,合并的過程按照rank 與level 構成的組合鍵進行操作,計算出在每一個rank 和level 的組合鍵值下數據記錄的條數,不難寫出其sql 語句為:
select rank, level ,count (*) as value from score group by rank, level
對于group by 操作轉換為MapReduce 的過程如圖3 所示。
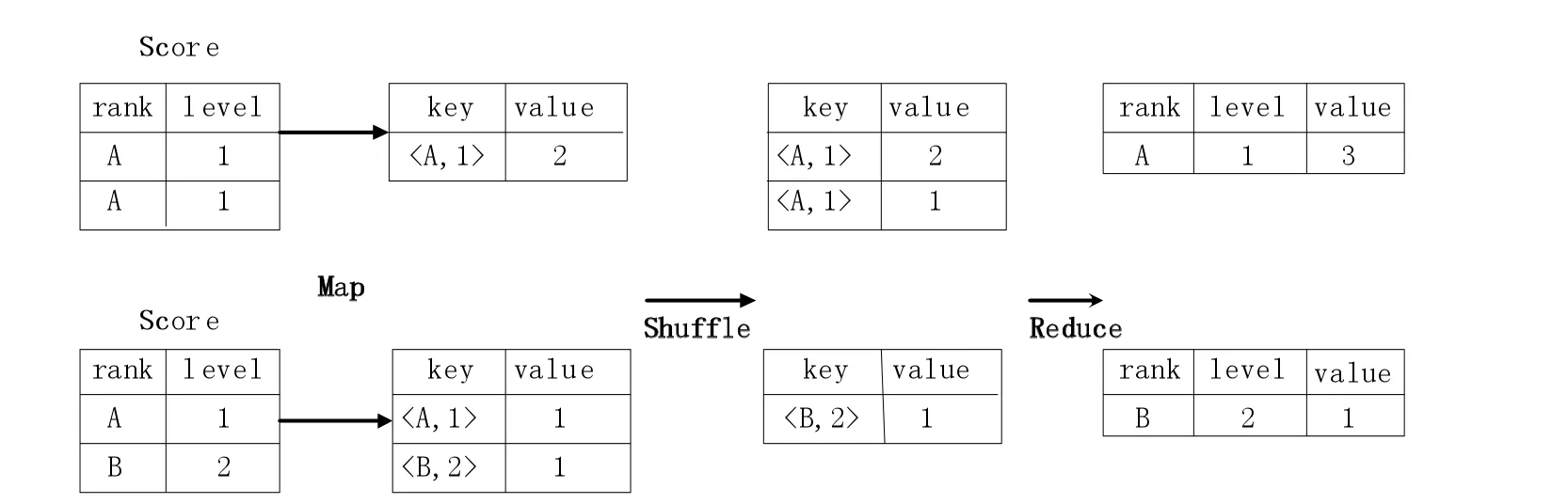
圖3 HSQL 語句轉換成MapReduce 的基本原理
5 Hive 數據分析
在此舉一個實例實踐操作Hive 數據分析過程。現有一個300000 行用戶信息的數據信息,將其上傳到分布式系統中,并利用數據倉庫Hive 工具進行數據分析。
5.1 數據準備
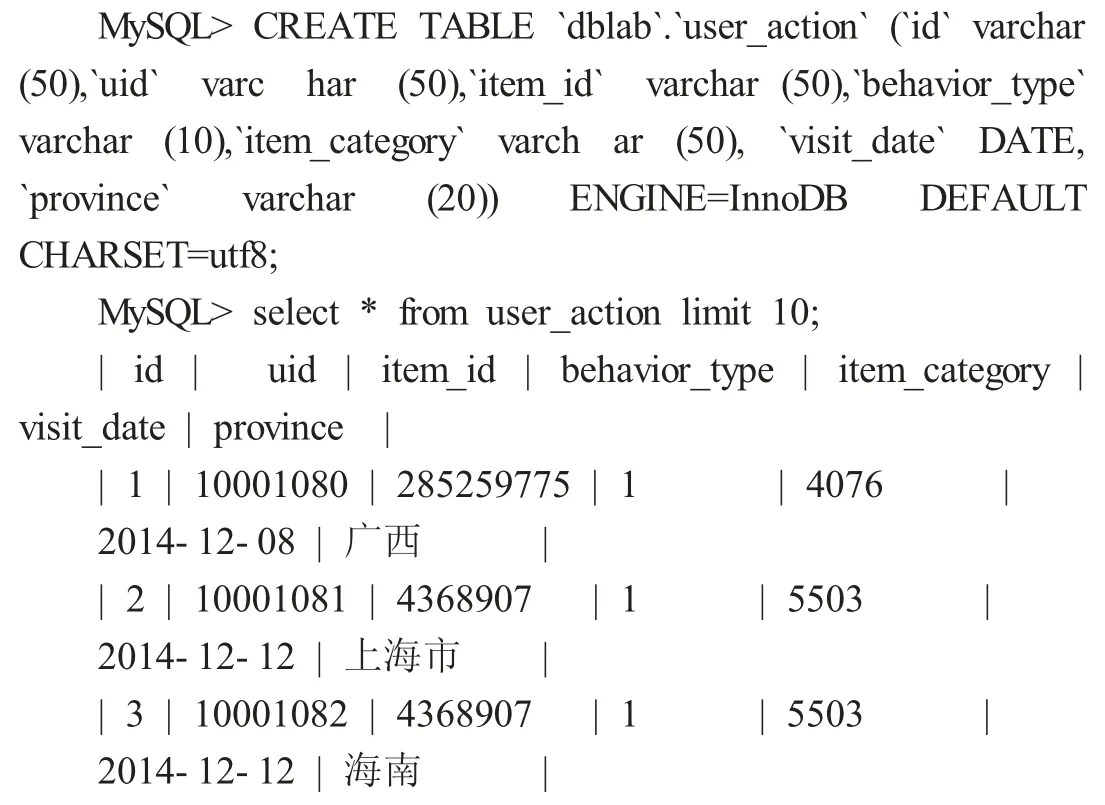
在HDFS 上創建數據存儲目錄,將數據上傳到HDFS 分布式文件系統中,并顯示其前10 行內容。
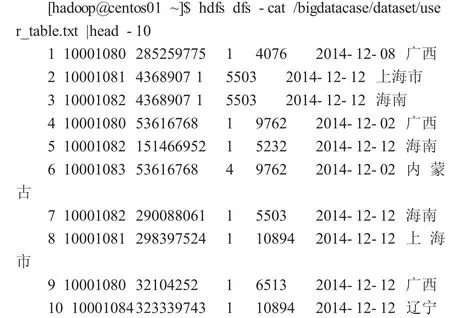
這是存儲在HDFS 文件系統中的數據,不能進行數據分析、清晰以及提取等操作,需要通過MapReduce 編程或Hive 實現對數據分析。但是MapReduce 要求數據分析人員對編程實現要求較高,實現較復雜,Hive 工具解決了這一難題,為精通SQL 語言而編程能力較弱的數據分析師對存儲在集群中的大規模數據進行查詢操作提供了便利。
5.2 啟動MySQL 服務,創建外部表

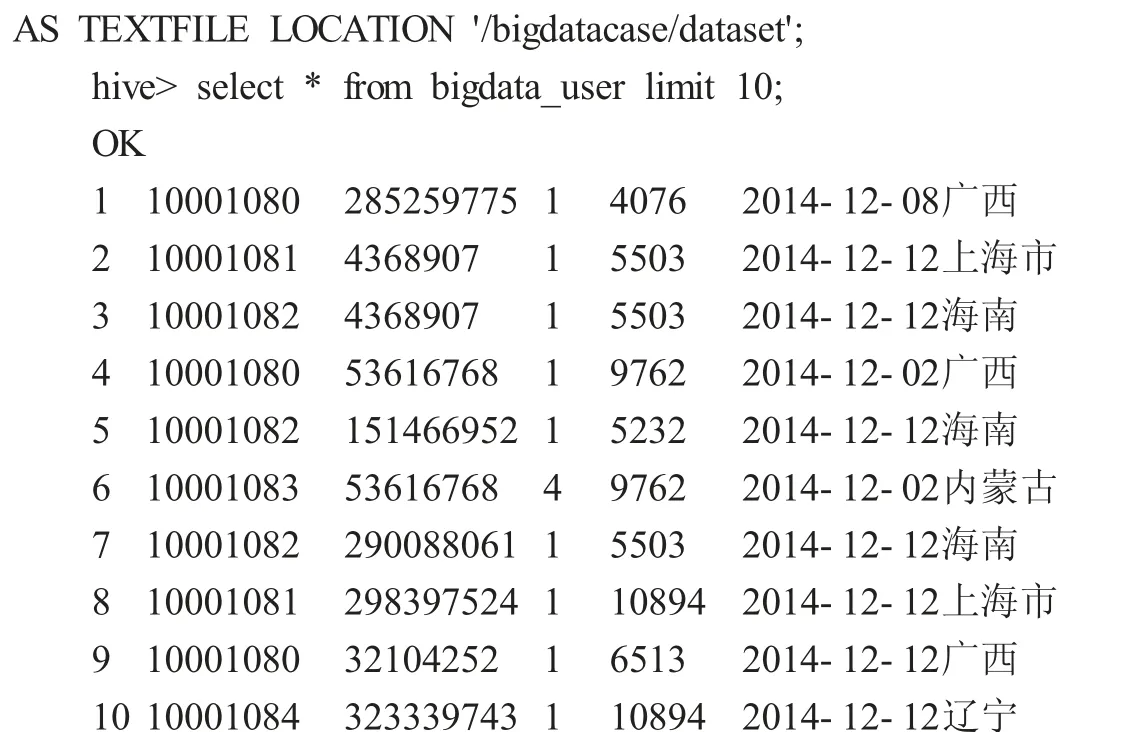
在Hive 數據倉庫中創建了外表并且加載數據后,就可以通過HSQL 語言進行數據分析操作了。
5.3 數據分析
①利用Hive 語句,查詢前20 位用戶購買商品時的時間和購買的商品種類。
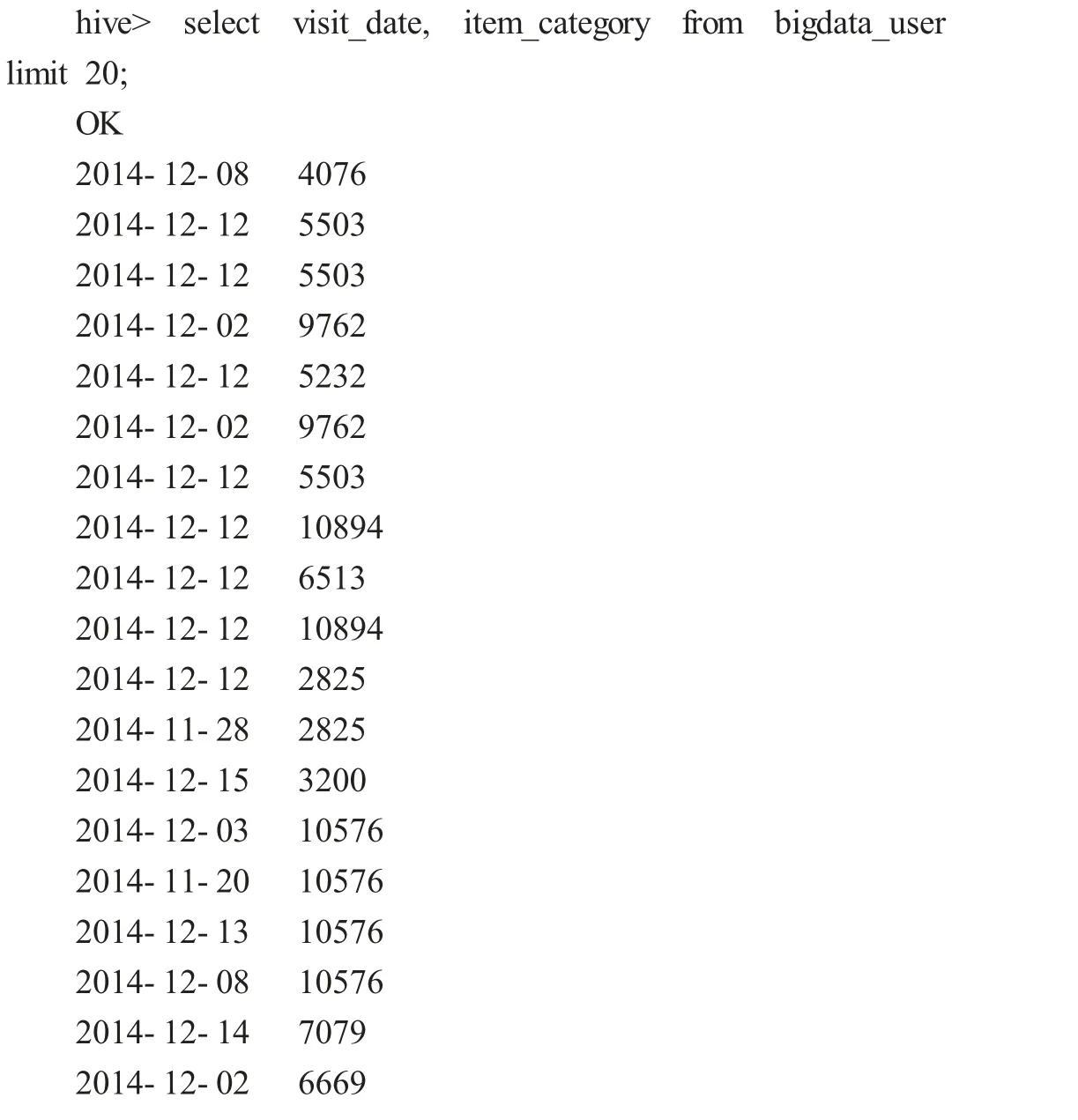
2014-12-12 5232
②查詢出uid 不重復的數據有多少條。
hive>select count(distinct uid) from bigdata_user;
OK
270
此查詢編寫Mapreduce 實現過程至少70 行代碼,在此不在贅述。
5.4 數據導出
對數據分析完后,可以通過Sqoop 工具將其由Hive 導出到MySQL 結構化數據庫中,已方便使用者進行分析、存儲以及可視化等操作,各省消費用戶數如圖4 所示。
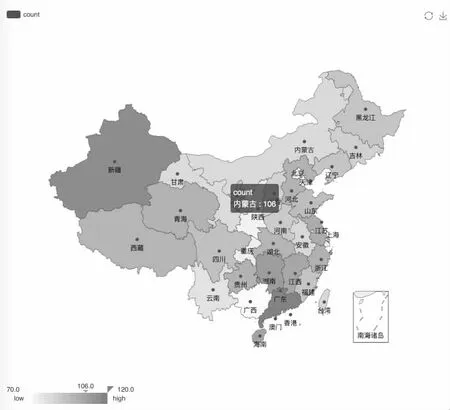
圖4 各省消費用戶數

總結,本文首先介紹了數據倉庫的概念,進而引入Hive 數據倉庫工具,設計Hive 工具的主要目的是使得對Java 編程技能掌握相對較弱但是對SQL 技能比較精通的數據分析師對存儲在HDFS 中的海量數據進行查詢功能操作進行論述,并介紹了Hive 的數據類型以及HiveQL轉換為MapReduce 任務的過程。最后利用HiveSQL 對300000行用戶信息進行數據分析操作,充分表明Hive 在數據分析上的特點,并將數據結果導出進行可視化。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
