基于指標體系的隧道圍巖智能分級方法研究
2022-01-19 07:02:00梁永忠
鐵道建筑技術 2021年12期
梁永忠
(中鐵十二局集團第一工程有限公司 陜西西安 710038)
1 引言
隧道圍巖分級是選擇施工方法的依據,是進行科學管理及正確評價經濟效益、確定結構上的荷載(松散荷載)與襯砌結構類型及尺寸、制定勞動定額及材料消耗標準等的基礎[1-2]。我國?公路隧道設計規范?(JTG 3370.1—2018)[3]主要采用BQ法對圍巖進行分級,但該方法的參數難于獲取,不能在隧道開挖后及時判別圍巖級別。而在實際隧道施工中,現場技術人員往往憑經驗判定圍巖級別。
20世紀以來,隨著人類科技進步,需要大量的工程建設,因此在工程實際基礎上發展出多種為巖體工程服務的工程巖體分級方法[4-6]。我國圍巖分級起步較晚,但在20世紀70年代后期水電、鐵路、公路、采礦等行業逐步發展了適合本行業的圍巖分級方法,并在各自的行業規范中得以體現[7-8]。這些圍巖分級方法都需要依靠復雜的設備以及相關專業人員到施工現場提取準確的圍巖參數,成本和效率的雙重限制以及施工現場的復雜狀況,使得準確、及時獲得圍巖等級難度很大。而在實際隧道施工中,往往是現場技術人員憑經驗判定圍巖級別,其主觀性較強。基于此,智能圍巖分級方法被提出并得到快速地發展,其是結合計算機技術和各種數學統計分析方法,建立圍巖分級模型[9-11]。然而,相關研究所選取的圍巖分級指標過于復雜或簡單,并未過多考慮現場指標獲取難易程度,其適用性有待考證。同時,上述研究中樣本數量較少,所獲得的分類模型在現場應用上準確率較低,同時樣本類別數量不均衡,導致模型訓練效果不夠理想。
本文詳細闡述在分析現場采集的隧道圍巖定性和定量指標的基礎上,選取圍巖硬度、巖體完整性、巖體結構、節理及風化情況、地下水狀況、地應力狀況等建立樣本數據庫,結合深度卷積神經網絡模型(HRNet)構建快速、準確的隧道圍巖智能分級方法。該方法可實現模型訓練過程中樣本高分辨率和低分辨率特征信息的融合,從而使模型能夠高效、準確地學習圍巖指標的高維特征和低維特征,最終提高圍巖等級的預測精度。
2 數據準備及預測方法
2.1 數據預處理
當前圍巖分級指標研究中,巖體完整度、巖體強度、軟弱結構面與孔軸夾角關系、地下水條件、結構面狀態、初始地應力狀態、巖體聲速等指標被廣泛選取用于圍巖分級的基礎[12]。然而,由于隧道復雜的施工環境和條件,許多指標由于其量化或半量化的特點往往難以準確收集。因此,綜合考慮指標收集難易程度及對圍巖分級的有利程度,選取巖石硬度、巖體完整性、巖體結構、風化程度、地下水情況、地應力情況為基礎進行研究,具體標準參考?工程巖體分級標準?(GB/T 50218—2014)。圍巖評價指標及因子見表1。
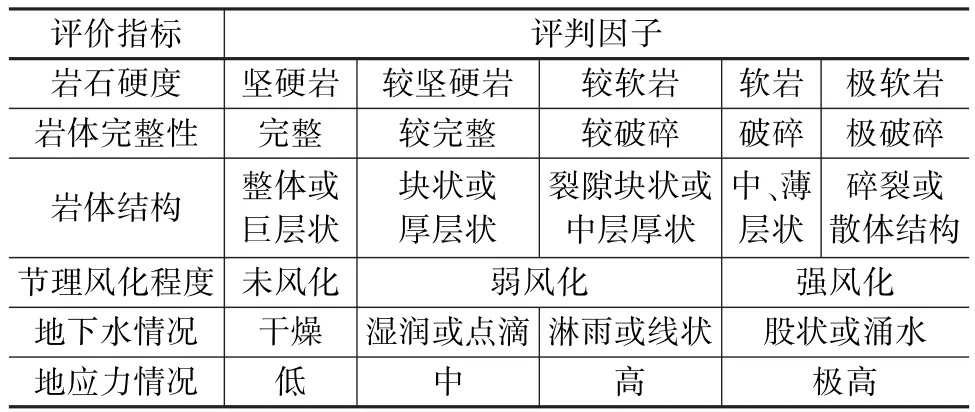
表1 圍巖評價指標和因子
可以發現,選取的六類圍巖分級評價指標包括25個評判因子(標簽),其值非連續且離散,因此采用獨熱編碼對上述評價指標進行編碼,最終25個標簽形成25×25的矩陣,稱為評價因子one-hot矩陣。在輸入每個訓練樣本矩陣預測圍巖等級之前,應對訓練樣本進行重塑,以適應深度學習模型。將訓練樣本矩陣每行的尾部與下一行的頭部連接起來,得到1×150個訓練數據并輸入到模型中預測圍巖等級。
2.2 相關方法
高分辨率網絡(HRNet,High Resolution Net)提出了在整個過程中的高分辨率的表示。為了解決高分辨率表示感受野不夠大的問題,HRNet采用了通過特征融合模塊交換高分辨率表示信息和低分辨率表示信息的方法。
圖1為HRNet主要結構圖,其中水平方向表示模型的深度變化,垂直方向表示特征圖的縮放。最上層網絡為主干網(即高分辨率網絡),隨著網絡深度加深,低分辨率并行子網逐漸引入主干網,并行網絡之間進行信息交換,實現多尺度融合和特征提取。最后,將經過信息提取和融合的高分辨率主干網作為輸出。在整個結構中,共享多分辨率信息的模塊包括兩類:轉換模塊(transition)和階段模塊(stage)。轉換模塊用于從輸入生成具有不同分辨率和深度的并行子網,每個轉換模塊復制原子網絡特征圖,并使用上采樣/下采樣方式進行分辨率和通道調整,見圖2。階段模塊用于融合不同分辨率的特征地圖信息,每個階段模塊遍歷并行子網,當其自身的分辨率低于待融合子網的分辨率時,采用上采樣方法擴大特征映射的大小,然后疊加特征映射;當子網的分辨率高于要融合的子網分辨率時,使用下采樣方法減小特征映射的大小,然后疊加特征映射。
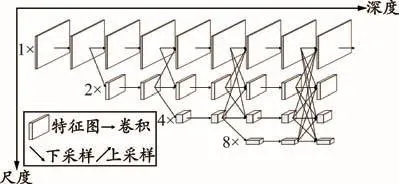
圖1 HRNet主要特征融合模塊
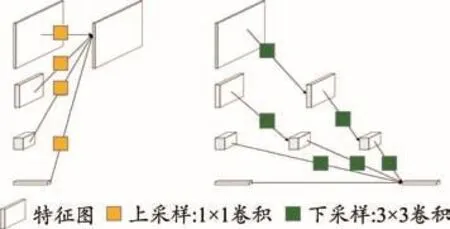
圖2 具有不同分辨率的特征圖分辨率調整示意
3 模型建立與訓練
結合上述高低分辨率特征融合理念,建立基于HRNet卷積神經網絡的圍巖智能分級方法,其主要包括四個模塊:輸入模塊、輸出模塊、用于生成并行子網的轉換模塊和用于信息融合的階段模塊。輸入模塊包含4個瓶頸結構,用于降低計算復雜度;轉換模塊采用3×3卷積核增加網絡深度,提高網絡學習能力;階段模塊采用3×3卷積核進行下采樣,實現高分辨率特征地圖信息融合,并利用1×1卷積核進行上采樣,最終實現低分辨率特征地圖信息的融合。
選取最低并行子網信道數(PSMCN)分別為16和32,并行子網數(PSN)分別為3、4和5構建不同的HRNet結構進行訓練,結合浮點運算(FLOPs)、權重參數量、驗證集(validation)的loss和accuracy用來評估模型的復雜程度和訓練性能。如表2所示,PSMCN和PSN的增加帶來了驗證集loss和accuracy的改善,表明了模型的計算功耗和存儲空間消耗與模型的性能呈正相關,但相應地導致了計算開銷和模型復雜度的增長。當PSMCN達到32、PSN等于4時,模型性能已達到較高水平,后續模型復雜程度的增加并未帶來更多的性能提高。綜合考慮計算開銷、模型復雜程度和性能表現可靠度,最終選擇并行子網通道數分別為32、64、128、256的HRNet32模型為基礎構架圍巖智能分類模型,見圖3。其中,Input和Output分別代表模型的輸入和輸出,Conv、BN、ReLU、Upsample和 Fusion 分別代表卷積層、Batch Normalization、ReLU激活函數、上采樣層和融合操作;Bottleneck和BasicBlock則是ResNet網絡的基本模塊。
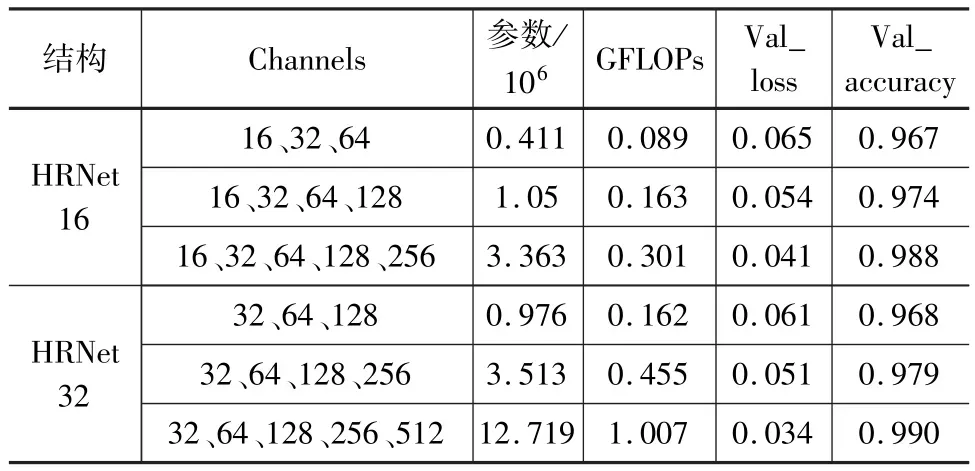
表2 不同HRNet模型結果表現對比
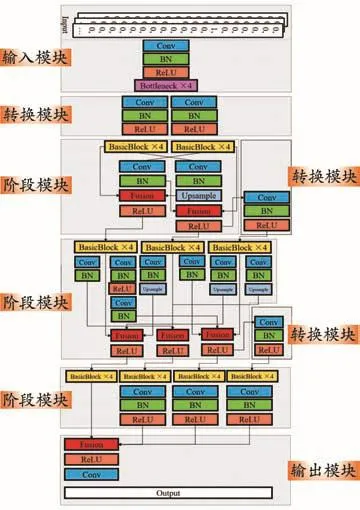
圖3 HRNet32結構
采用5-fold交叉驗證的方法對網絡進行訓練,并與VGG19和ResNet34做對比分析。以米拉山隧道[14]采集的圍巖指標樣本為基礎,按9∶1的比例分為訓練集(540)和測試集(60)。在模型訓練過程中,樣本集和相關參數設置均統一:Adam優化器、分類交叉熵損失函數,批量大小32,學習率0.001。訓練過程中當驗證損失在20個時期內不再降低,學習率減小到原來的0.1倍,Early stopping操作防止模型過度擬合。訓練結果顯示,HRNet32相對其他模型整體表現良好,說明其能夠對圍巖特征實現了良好的提取,形成較好的圍巖分級效果(見圖4)。
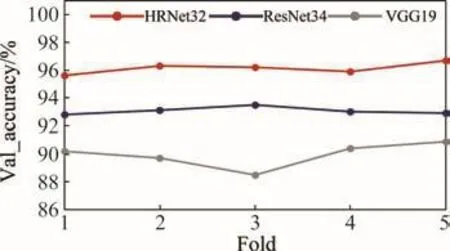
圖4 不同模型交叉驗證結果
4 模型性能評估和討論
4.1 模型性能評估
選取上述模型訓練過程中表現最佳的VGG19、ResNet34和HRNet32對測試數據集中的樣本進行測試。引入了精度(Precision)、召回率(Recall)和F1-score來監控這些模型的測試性能,具體計算公式如下:

式中:i為目標類別;TP、FP和FN分別為真陽性、假陽性和假陰性。精度定義為預測中正確預測的正比例(TP和FP),召回定義為實際正樣本(TP和FN)中正確預測的比例。F1-score用于評估模型的綜合性能,并消除樣本量不平衡的影響。Micro F1-score表示方法在每個類別上的表現,而Macro F1-score表示方法在所有類別上的綜合表現。一般來說,F1-score越高,模型的性能越好。
如表3所示,HRNet32模型在準確率、召回率、F1-score等方面普遍優于其他模型,這也證明HRNet32能夠有效地提取各圍巖等級樣本的高維特征。一般來說,一個優秀的模型應該具有良好的通用性來處理不同的情況。因此選取自鷓鴣山隧道、泥巴山隧道、二郎山隧道、福堂隧道、棗子林隧道和山嶺隧道等多條不同工程條件隧道的樣本進行測試,預測準確率達到了85%,說明提出的HRNet32圍巖智能分級模型具有較好的通用性。
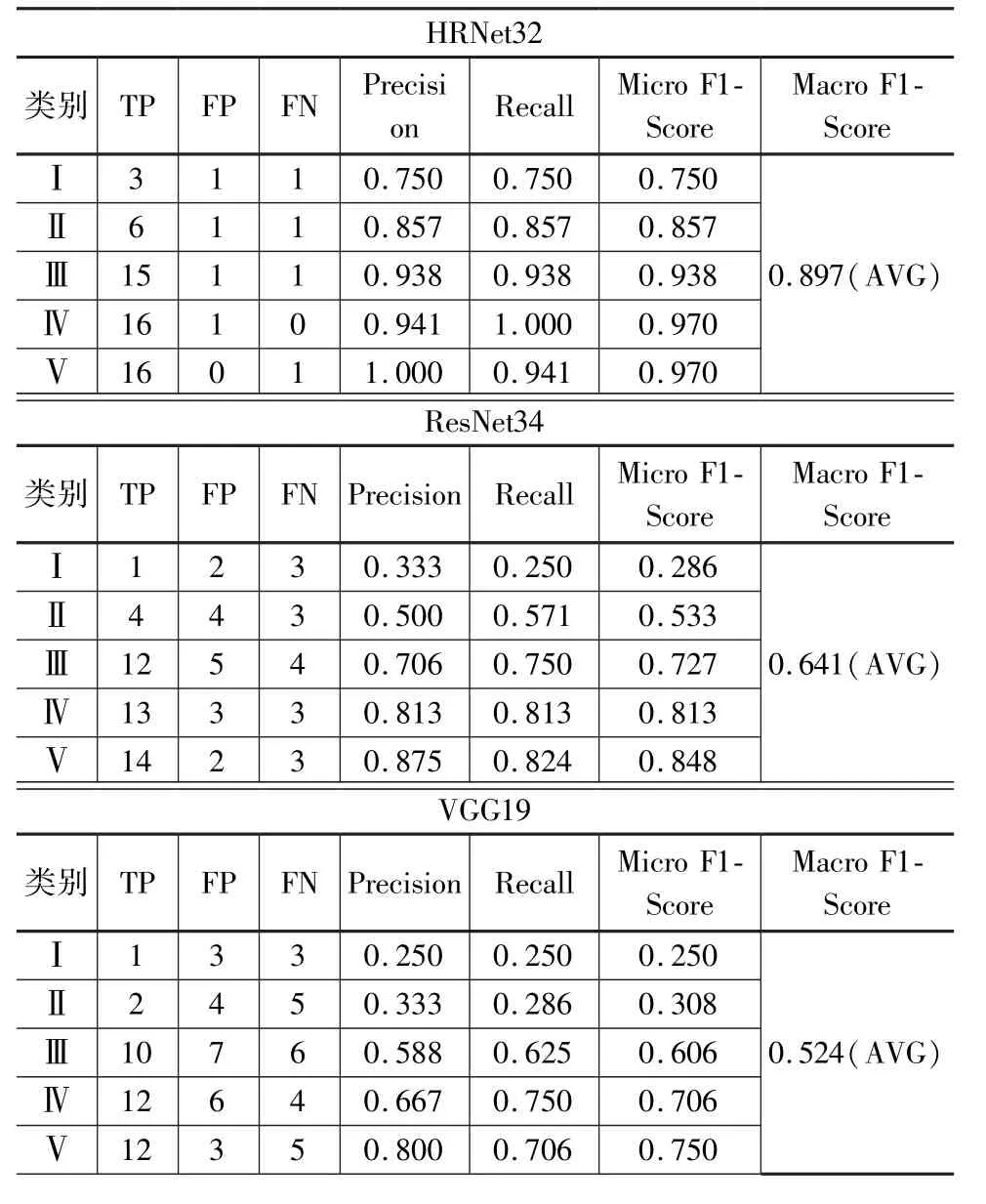
表3 不同模型在測試集上結果
4.2 討論
在訓練樣本庫建立過程中,發現5個圍巖級別樣本數據量不夠均衡,特別是對于Ⅰ和Ⅱ圍巖級別的樣本量明顯少于其他圍巖級別。因此,將上述訓練好的VGG19、ResNet34和HRNet32模型應用于僅選擇圍巖級別為Ⅰ、Ⅱ和Ⅲ的樣本數據庫,其結果見表4。HRNet32整體表現優于其他模型,特別在圍巖級別Ⅰ和Ⅱ這類小樣本量類別上,性能表現明顯更佳。綜上所述,所提出的模型能夠較好地提取圍巖級別的高維和低維信息,即使當訓練樣本出現數量不均衡情況。
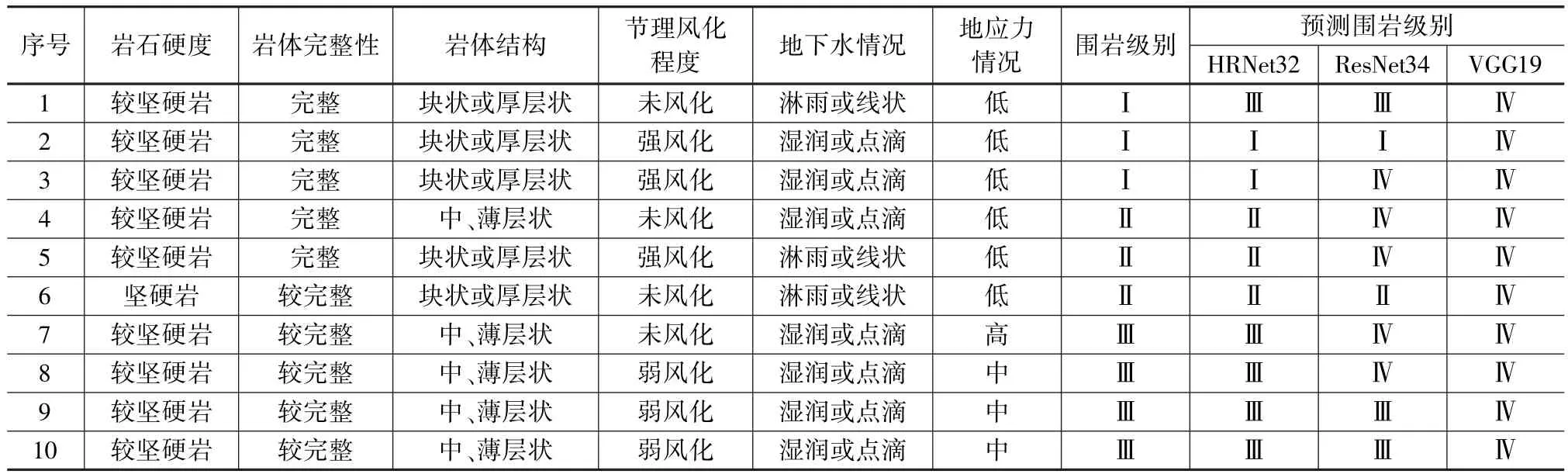
表4 不同模型在小樣本圍巖級別預測結果
5 結論
結合六類圍巖評價指標(巖石硬度、巖體完整性、巖體結構、風化程度、地下水情況、地應力情況),基于HRNet卷積神經網絡結構建立了隧道圍巖智能分級方法。采用獨熱編碼對樣本進行預處理并建立樣本數據庫,綜合考慮計算開銷、模型復雜程度和性能表現可靠度,選擇并行子網通道數分別為32、64、128、256 的 HRNet32 模型為基礎構建圍巖智能分類模型。訓練、交叉驗證、測試和對比分析結果表明所提出的方法在圍巖分類上表現良好,并將其運用于不同地質條件隧道的圍巖級別上驗證了模型的通用性。同時,對于樣本數量不均衡情況下的小樣本類別的特征同樣能夠較好提取,分類效果較為良好。該方法避免了人工查詢規范造成的人力和物力浪費,對隧道圍巖分級具有較大的應用價值,避免了深度學習圍巖分級對樣本質量要求高的問題,且結合專家經驗能使預測結果更加準確。
猜你喜歡
中華建設(2019年12期)2019-12-31 06:47:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
江西建材(2018年4期)2018-04-10 12:37:22
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
江西煤炭科技(2015年1期)2015-11-07 03:06:32
Coco薇(2015年1期)2015-08-13 02:47:34
中國鐵道科學(2015年5期)2015-06-21 06:53:18
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
