基于圖像特征和隨機森林的油菜生物量估算*
2022-01-19 08:34:34李海同陳旭王剛關卓懷江濤吳崇友
中國農機化學報 2021年12期
李海同,陳旭,王剛,關卓懷,江濤,吳崇友
(農業農村部南京農業機械化研究所,南京市,210014)
0 引言
喂入量是聯合收獲機的一個最重要設計參數和性能參數,喂入量過大會導致聯合收獲機作業質量下降,喂入量太小則不能充分發揮收獲機的性能導致工作效率低下[1-2]。為實現聯合收獲機工作參數和狀態依據作物田間狀態自動控制,首先要對其喂入量進行實時監測,為此許多學者圍繞在聯合收獲機喂入量檢測方法開展研究[3-4],而油菜生物量是聯合收獲機喂入量的重要決定因素。
機器視覺和圖像處理技術的進步及其在植被覆蓋率、含水率等農業領域的應用,為基于圖像處理的油菜生物量計算提供了思路和方法。潘靜等[5]通過水稻冠層密度圖像光譜分析,以2R+G顏色特征參數值作為收割機喂入密度特征,并與實際測得的喂入密度值進行擬合建立模型,能夠實現水稻喂入密度的檢測。劉漢青[6]設計了基于機器視覺的油菜收獲疏密度檢測系統,利用卷積神經網絡算法實現油菜疏密度檢測,并根據疏密度控制收割機的前進速度使喂入量保持在設定范圍內。劉楊等[7]提取馬鈴薯株高和植被覆蓋度,選取6種植被指數和3種農學參數作為特征參數,通過線性回歸、偏最小二乘回歸、隨機森林算法和支持向量機估算馬鈴薯生物量。陶惠林等[8]基于無人機高清數碼影像生成冬小麥的作物表面模型并提取21種數碼影像圖像指數,構建3種不同時期冬小麥的生物量估算模型并進行對比,挑選出冬小麥生物量估算的最優模型。楊雪峰等[9]通過面向對象影像分析和回歸分析等技術,獲取區域尺度下胡楊冠幅、樹高和密度等森林結構參數,通過生長方程計算得到區域尺度森林地上生物量。利用作物的可見光圖像提取與生物量有關的特征,通過回歸算法建立作物生物量估算模型可作為生物量計算的依據。
本研究利用無人機拍攝聯合收獲期油菜的圖像并稱量單位面積內地上油菜的質量,獲取油菜的可見光圖像和生物量信息,提取圖像的色彩和紋理特征并利用相關性分析篩選出與油菜生物量顯著相關的特征參數,分別建立基于隨機森林,主分成分析和支撐向量機的油菜生物量估算模型,訓練模型并比較3種估算模型的評價指標,探討利用無人機可見光圖像預測聯合收獲期油菜生物量的方法,為聯合收獲期油菜生物量智能化檢測提供參考。
1 材料與方法
1.1 圖像采集與數據集構建
本研究中的圖像采集于2020年6月在江蘇省鹽城市大豐區東方綠洲現代農業園(33°6′7″N,120°48′12″E)內進行試驗,如圖1所示。
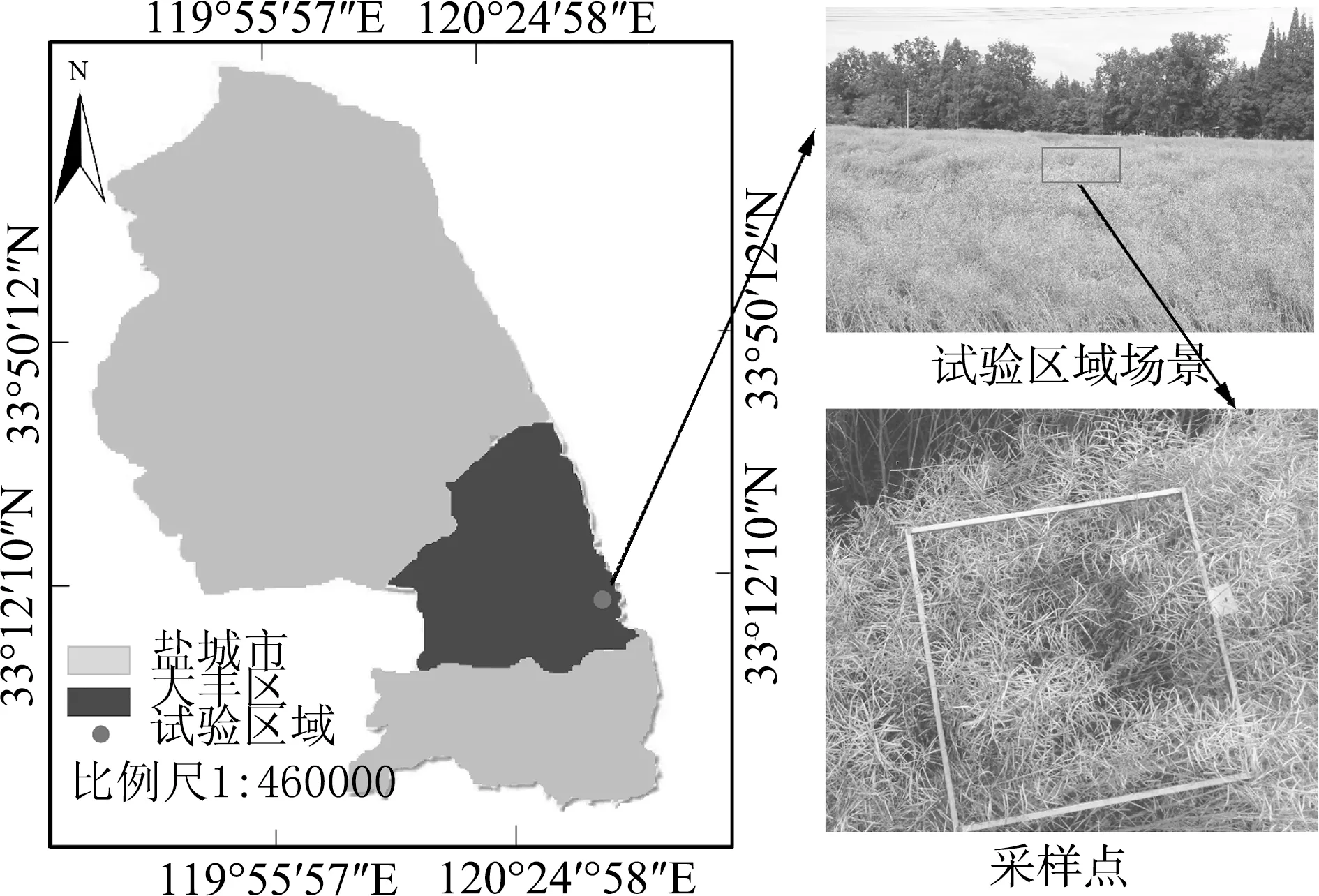
圖1 研究區域Fig.1 Location of the study area
采樣時試驗樣品油菜的農藝特性為:種植密度27萬株/hm2,植株平均高度1.72 m,莖稈、莢果和籽粒含水率分別為38.4%、19.8%、24.6%,采樣時將1 m×1 m 的正方形采樣框水平放置于采樣區的試驗油菜上作為采樣區。研究使用的無人機為大疆 PHANTOM 4PRO,相機有效像素為2 000萬,無人機在采樣框上方15 m處飛行拍攝采集圖像,數據采集時間為2019年6月2日,天氣晴朗無云,風速小于3級,適合無人機飛行,采集時間為14:00至17:00。每張照片拍攝完成后人工收割采樣區內地上部分油菜并稱重,得到單位面積內油菜的生物質量,由此獲得油菜生物量的實測值。本研究選取生長密度有差異的120個采樣區域作為研究對象獲得樣本圖像。
1.2 特征提取和篩選
由于采集的聯合收獲期油菜圖像包括采樣區內外兩部分,采樣框內的區域為本研究所需的圖像信息,而采樣框以外的區域可視為噪聲信息,需將其剔除后提取圖像特征,首先通過灰度化、平滑和膨脹掩膜等預處理方法獲取采樣框區內的圖像,如圖2所示。
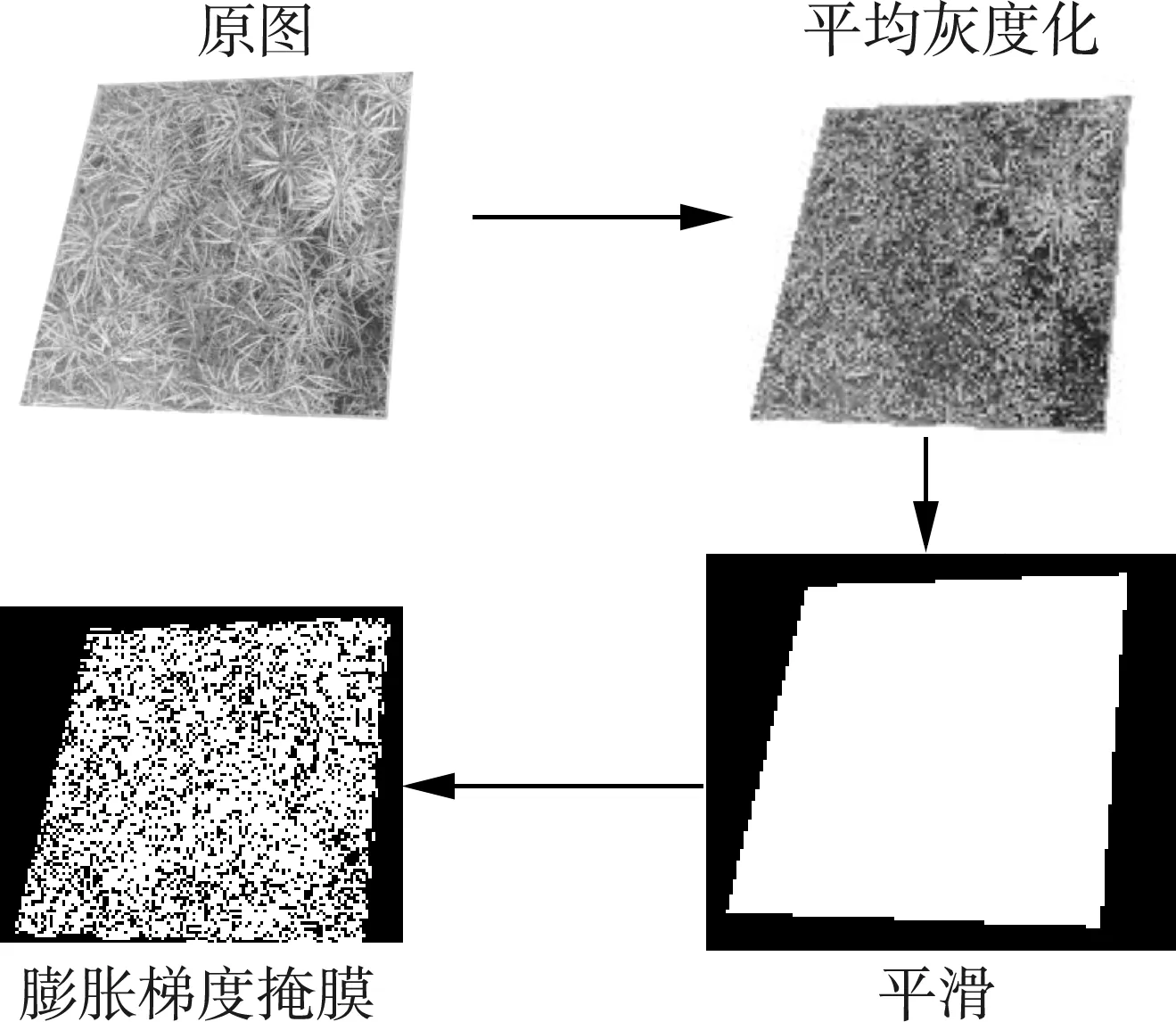
圖2 圖像預處理Fig.2 Pretreatment of image
根據文獻[5]、[10-12]的研究結果,作物生物量可由作物圖像的顏色和紋理特征表征,根據油菜圖像特征本研究提取樣本圖像的RGB和HSI顏色空間的顏色分量及歸一化顏色分量r、g、b共9個初始圖像顏色特征,并構造表1所示的13個可見光圖像指數。每次采樣時采樣框放置的角度難以完全一致,導致采樣區域性狀和大小不一,因此顏色分量采用均值消除采樣區域形態差異的影響。

表1 可見光圖像指數及數學表達式Tab.1 Characteristic parameters of optical images
灰度共生矩陣能反映出圖像灰度關于方向、相鄰間隔、變化幅度的綜合信息,本研究首先計算圖像的灰度共生矩陣P,然后提取共生矩陣的能量(ENG)、相關度(COR)、對比度(CON)、熵(HOM)和逆方差(IDM)5個紋理特征及其二階矩,紋理特征計算公式如式(1)~式(5)所示。
(1)
(2)
(3)
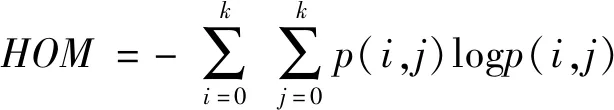
(4)
(5)
(6)
(7)
(8)
(9)
式中:k——灰度值的級數;
i——行號;
j——列;
p(i,j)——灰度值(i,j)出現的概率。
本研究共提取圖像的32個顏色和紋理特征,使用全部特征建模將產生信息冗余,導致數學模型過于復雜且影響運行速度。為降低維度精簡模型提高運算速度,首先采用Pearson相關性分析研究油菜生物量和圖像特征的相關系數,定量描述油菜生物量與特征參數的相關程度,明確油菜生物量的主要決定因素,與油菜生物量顯著相關的圖像特征和相關系數如表2所示。
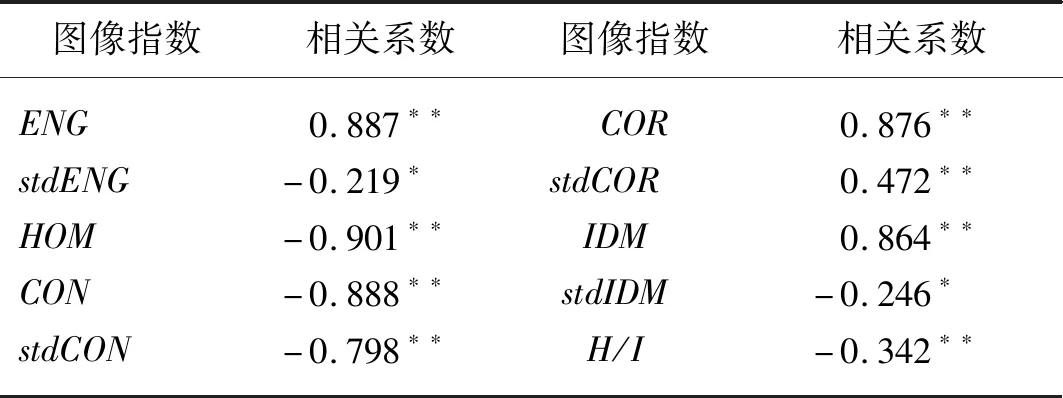
表2 油菜生物量圖像特征選擇結果Tab.2 Selection results of image features for rape biomass
從相關性分析結果中可以看出,初始圖像特征中的能量ENG、熵HOM、對比度CON、對比度二階矩stdCON、相關性COR、相關性二階矩stdCOR,逆方差IDM和色調與亮度的比值H/I,8個圖像特征與油菜生物量之間達到了極顯著水平(P<0.01);能量二階矩stdENG和逆方差二階矩stdIDM與油菜生物量之間呈現出了顯著的相關性(P<0.05)。
2 油菜生物量估算模型
以提取的 10個顯著特征參數作為輸入參數,以油菜生物量為輸出參數,分別基于隨機森林(Random forest,RF)、主成分分析(Principal component analysis,PCA)和支持向量機(Support vector machine,SVM)建立聯合收獲期油菜生物量的估算模型,獲取油菜生物量估算值,挑選 67%樣本數據(80個)作為建模集,33%樣本數據(40個)作為驗證集以此來構建油菜生物量估算模型[14],分別用于模型訓練和驗證。采用均方根誤差(RMSE)、相對誤差(RE)和決定系數(R2)3個指標評價估算模型的準確性,3個指標的計算方法如下。
(10)
(11)
(12)
式中:yi′——生物量估算值,kg/m2;
yi——生物量真實值,kg/m2;

n——測試集樣本個數。
2.1 基于RF的生物量估算模型
隨機森林是由多棵分類回歸樹(Classification And Regression Tree,CART)構成的組合分類模型,森林中的每一棵決策樹之間沒有關聯,但模型的最終輸出由森林中的每一棵決策樹共同決定。隨機森林是典型的集成學習算法,裝袋法的代表模型[13-14],CART決策樹模型為弱學習器,采樣樣本和特征的雙重隨機抽樣構建決策樹保證不出現過擬合的現象[15-17]。本研究首先建立基于隨機森林的油菜生物量估算模型,根據袋外誤差(Out of bag error,oob error)與決策樹數量之間的關系確定決策樹數量為50。
通過對120個訓練樣本進行有放回的隨機采樣,構建出50個采樣集,基于50個采樣集構建50棵決策樹作為油菜生物量估算模型的學習器,CART決策樹以最小平方誤差作為劃分樣本的依據。通過網格搜索方法確定決策樹的深度h為20,每個節點包含的最小樣本數量為2,分裂一個結點需要的最小樣本數為2。
2.2 基于PCA的油菜生物量估算模型
主成分分析法采用降維的思想,通過構造原變量適當的線性組合,利用較少的綜合指標代替原先的較多的變量,使復雜的信息簡單化[18-19]。本研究首先通過主成分累計貢獻率選取合適的主成分個數,根據成分的特征值和載荷得出各主成分關于標準變量的函數表達式,再利用回歸分析建立油菜生物量與主成分之間的回歸方程,最后將方程中的標準變量轉化為可見光圖像的特征參數,建立基于主成分分析(Principal component analysis,PCA)的油菜生物量估算模型。
本研究利用SPSS 22對10個特征參數進行主成分分析,自變量累積解釋因變量的能力如表3所示,成分矩陣如表4所示。X1~X10分別為能量、能量二階矩、熵、對比度、對比度二階矩、相關性、相關性二階矩、逆方差、逆方差二階矩和色調與亮度的比值10個變量經標準化處理后的標準化變量。
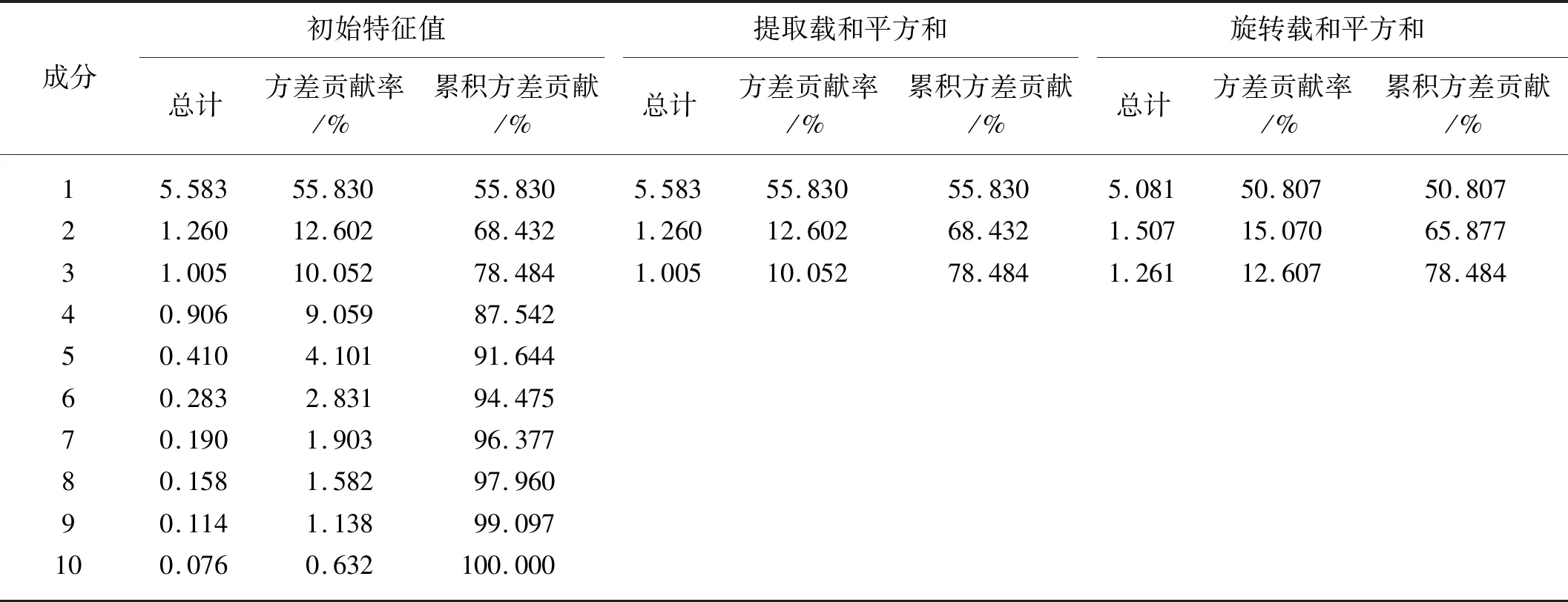
表3 主成分的特征值及貢獻率Tab.3 Characteristic value and accumulative contribution rate of each principal component
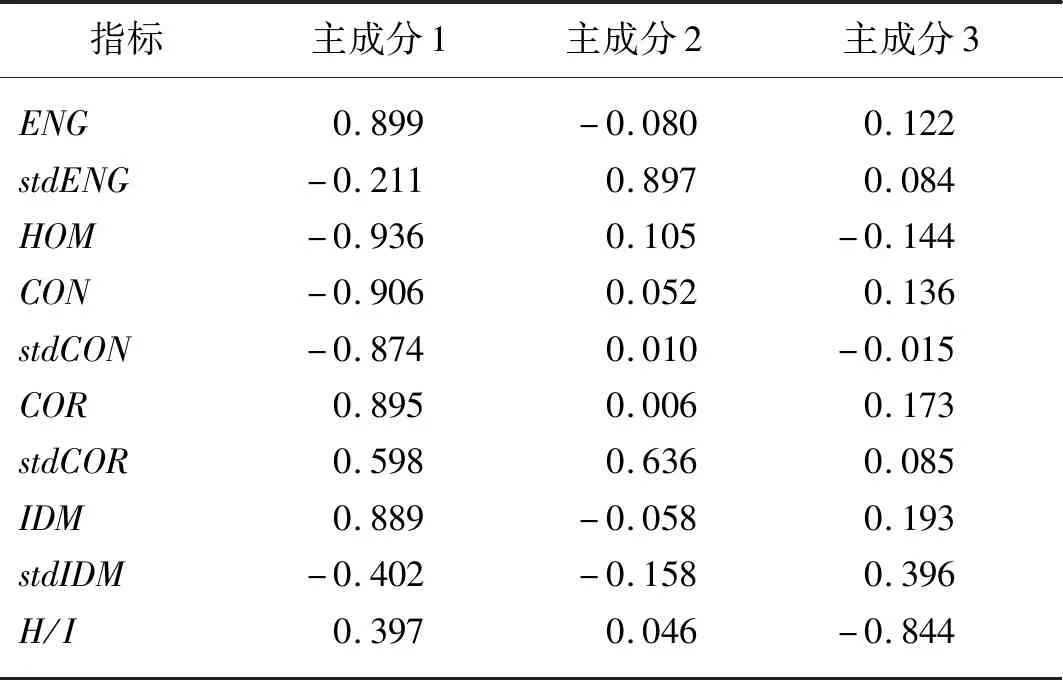
表4 各主成分的成分矩陣Tab.4 Component matrix of each principal component
由表3可知,前3個特征值大于1的主成分對因變量的累積解釋能力達到78.484%,因此提取3個主成分即可表現出10個指標的作用效果。據表3中的特征值和成分矩陣分別得到3個主成分Z1、Z2、Z3的函數表達式
Z1=0.089 9X1-0.211X2-0.936X3-
0.906X4-0.874X5+0.895X6+0.598X7+
0.889X8-0.402X9+0.397X10
(13)
Z2=-0.08X1+0.0897X2+0.105X3+
0.052X4+0.01X5+0.006X6+0.636X7-
0.058X8-0.158X9+0.397X10
(14)
Z3=0.122X1+0.084X2-0.144X3+0.136X4-
0.015X5-0.173X6-0.085X7+0.93X8+
0.396X9-0.844X10
(15)
以提取的3個主成分作為自變量,以與之對應的油菜生物量作為因變量進行線性回歸,并將模型中的標準變量轉換為提取的10個特征參數,得出基于主成分回歸的聯合收獲期油菜生物量估算模型。
2.3 基于SVM的生物量估算模型
支撐向量機(Support vector machine,SVM)作為一種有監督的學習方法,SVM 通過不同的核函數將線性不可分的數據映射到高維空間,將非線性問題轉換為線性可分數據[20-21],在用于回歸預測研究中有較多應用,并且有較高的預測精度。本文以聯合收獲期油菜的圖像特征和生物量為訓練數據,通過支持向量基(SVM)建立油菜生物量與可見光圖像之間的映射關系,獲得基于SVM的油菜生物量估算模型。
在SVM中對訓練和學習效果影響最大的2個參數為C和δ,其中參數C直接影響模型的穩定性,參數δ反映了支持向量之間的相關程度,決定模型預測的推廣能力和泛化性[22]。因此,在對油菜生物量預測時對參數C和δ進行調節和優化,得到較為理想的預測結果。本文對SVM預測生物量準確性的評價通過生物量估算值與真實值之間的誤差對比,以誤差最小為目標選擇最優參數,目標函數可表示為
minε=min|yie(C,δ)-yi|
(16)
式中:ε——估算值與真實值之間的偏差,kg/m2;
yie——第i個訓練樣本對應的估算生物量,kg/m2;
C——懲罰參數;
δ——核函數參數。
依據相關文獻中SVM參數的取值范圍,將取值范圍作為上下限約束,可表示為
(17)
本文核函數采用線性核函數進行計算,使用5-fold交叉驗證對SVM回歸模型進行交叉驗證,使用fitrsvm自動優化超參數,確定使交叉驗證損失減少5倍的超參數由此得出基于支持向量機的油菜生物量估算模型。
2.4 結果與分析
利用上述3個模型估算測試集中40個樣本的生物量,油菜生物量的估算值與真實值的關系如圖3所示,3個模型的評價指標如表5所示。
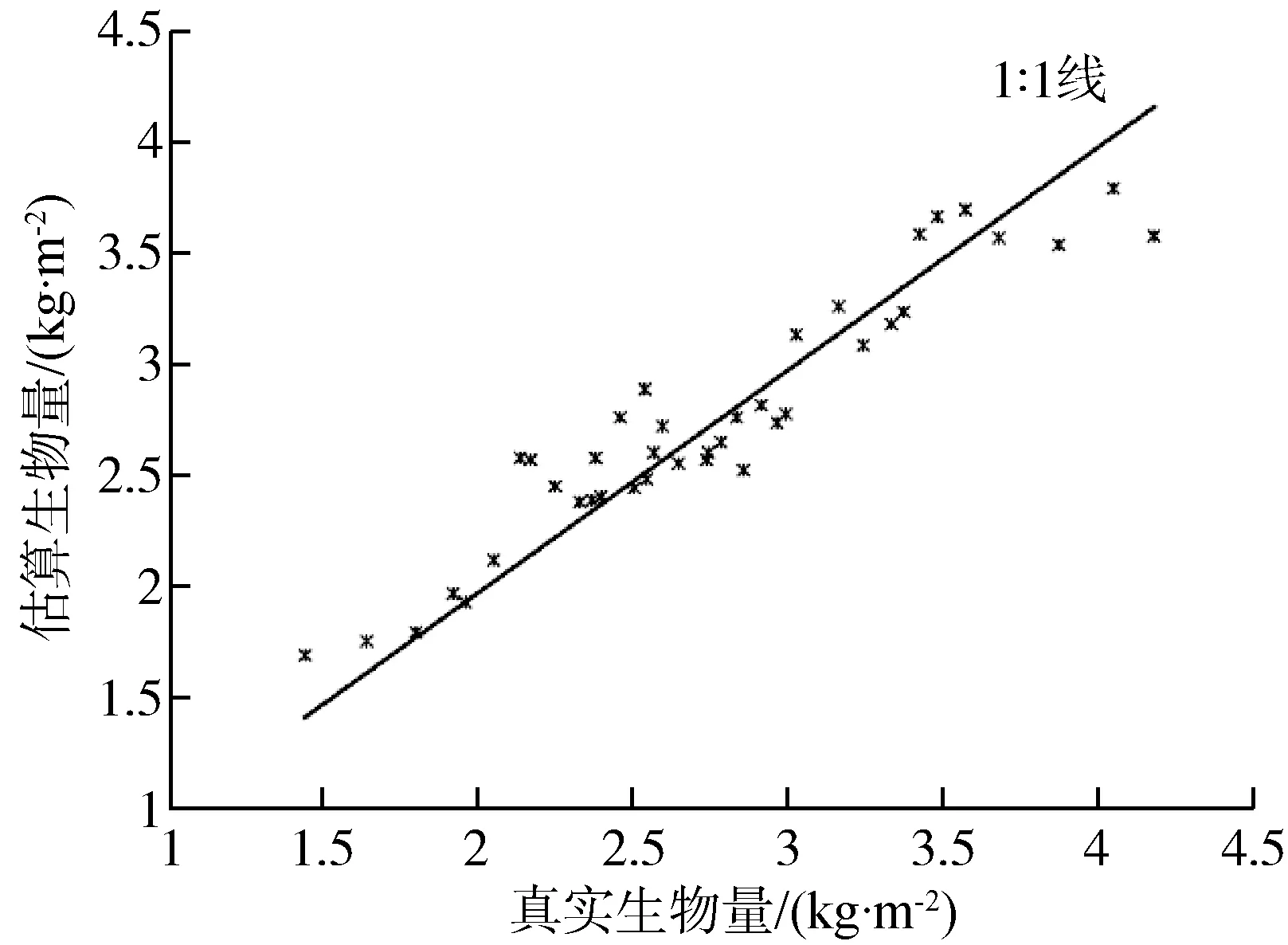
(a)基于隨機森林的油菜生物量估算模型
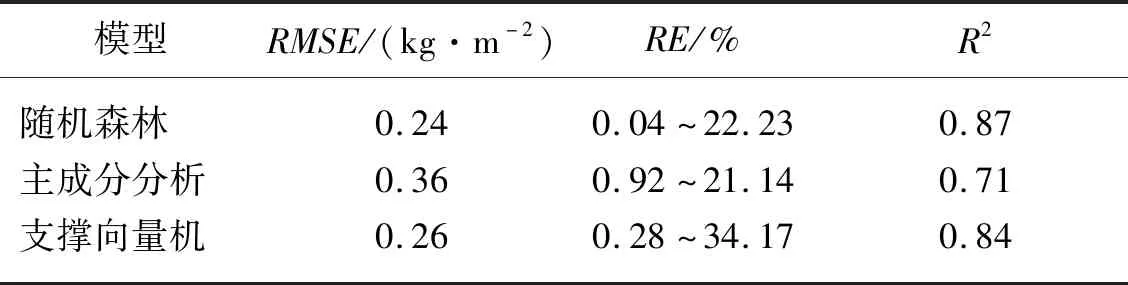
表5 不同估算模型的評價指標Tab.5 Evaluation indexes of different prediction models
由表5中估算結果的評價指標可知,油菜生物量在1.0~4.5 kg/m2時,基于隨機森林、主成分分析和支撐向量機三種方法的油菜生物量估算模型決定系數R2均大于0.5,可用于聯合收獲期油菜生物量估算。三種模型的評價指標—均方根誤差RMSE、相對誤差RE和決定系數R2分別為0.24 kg/m2、0.04%~22.23%、0.87,0.36 kg/m2、0.92%~21.14%、0.71和0.26 kg/m2、0.28%~34.17%、0.84,對比三種估算模型的估算精度可知,基于隨機森林的油菜生物量估算結果的決定系數最大且均方根誤差最小,最小相對誤差最小而最大相對誤差稍大于主成分模型的估算結果,表明模型的穩定性和精精度較高,是一種較優的估算模型。
3 討論
本文探討了利用聯合收獲期油菜無人機可見光圖像提取與油菜生物量相關性較高的圖像特征,主要為紋理特征,建立三種油菜生物量估算模型,這與以往估算作物生物量的方法和結果有所不同。原因是聯合收獲期油菜葉片已全部脫落,顏色特征差異較小而角果和分枝的粗細、疏密等特征差異較大,因此本文利用可表示出圖像色調的深淺亮度的HSI分量和紋理特征檢索具有粗細、疏密等方面較大差別的圖像。本研究僅用一個地區的聯合收獲期油菜數據構建生物量估算模型且暫未考慮油菜植株高度對生物量的影響,后續還需采集不同年限、不同地點和不同品種的油菜樣本進行分析,并將油菜植株高度融合計算模型提高模型的泛化能力。
4 結論
1)基于無人機可見光提取聯合收獲期油菜圖像的色彩和紋理特征共32個特征參數,通過顯著性檢驗與相關性分析篩選與油菜生物量顯著相關的10個特征參數,用于表征油菜生物量。
2)以篩選的顯著特征為輸入參數,以油菜生物量為輸出值,分別建立基于隨機森林、主成分分析和支持向量機的聯合收獲期油菜生物量估算模型;將樣本按照2∶1的比例分為訓練集和測試集,利用多次交叉驗證確定模型參數并估算測試集上的油菜生物量。
3)研究結果表明,三種模型估算聯合收獲期油菜生物量的3個評價指標RMSE、RE和R2分別為0.24 kg/m2、0.04%~22.23%、0.87,0.36 kg/m2、0.92%~21.14%、0.71和0.28 kg/m2、0.26%~34.17%、0.84;對比結果表明基于隨機森林算法的油菜生物量估算模型具有較高精度和穩定性,是一種較優的估算模型。本文基于圖像特征和決策樹的聯合收獲期油菜生物量估算方法探究了田間油菜生物量信息快速、無損檢測方法,可為油菜聯合收獲機作業過程中喂入量智能化檢測提供參考和依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
