3D多重注意力機制下的行為識別
2022-01-21 07:35:24吳麗君李斌斌陳志聰林培杰程樹英
福州大學學報(自然科學版) 2022年1期
吳麗君,李斌斌,陳志聰,林培杰,程樹英
(福州大學物理與信息工程學院, 福建 福州 350108)
0 引言
人的行為識別是視頻分析中一個備受關注和具有挑戰性的研究課題.相比于圖片,視頻存在更多的時間信息及多幀之間的關聯性,且數據量龐大.因此,用于視頻的人的行為識別模型需能提取時間關聯信息,且需兼顧處理速度.
近幾年,深度卷積網絡對圖像的處理能力得以飛速提升.大量CNN結構被提出,如GoogLeNet、DenseNet、ResNet、VGG等[1-3]二維卷積神經網絡,在單張圖像特征的提取上取得良好性能.然而,二維卷積神經網絡難以提取視頻中的時間信息且難以關注圖像中的重點空間信息.針對第一個問題,Tran等[4]提出三維卷積神經網絡(3D CNN),利用三維卷積和三維池化操作來兼顧視頻中的時間信息的處理,ResNet和GoogLeNet等二維卷積網絡在后續也有三維結構的版本[5-8];針對第二個問題,一些注意力機制[9, 10]被提出,這些模塊都有一個共同的特性,就是能夠幫助二維卷積網絡更加關注一張圖像當中的重點信息.其中,Woo等[11]提出的一種卷積塊注意模塊(convolutional block attention module, CBAM),分為通道和空間兩個子模塊,以分別關注圖像中重點信息“是什么”以及“在哪里”.
視頻不僅包含著單幀的信息,還有幀與幀之間的關聯信息,因此現有的二維的注意力機制難以在三維的數據及相應的三維卷積網絡上進行部署.Wang等[9]認為卷積的操作只考慮了局部區域,而丟失了全局的聯系,提出一種非局部網絡,其非局部操作對空間中所有位置取加權平均值,以表示圖像中某個位置的響應.此結構不僅能在同一張圖像中建立某一個像素與其他任意像素點的聯系,也能針對視頻建立不同幀之間像素點的聯系,從而為后面的層提供一些更豐富的信息.然而該結構涉及到矩陣點乘的操作導致在三維任務中產生大量參數,計算量龐大.
基于此,本文提出一種多重注意力機制,可用于提升3D卷積網絡的性能.由于3D ResNet計算簡單、效率高、能解決梯度消失等優點,因此選擇3D ResNet[5]作為基礎網絡.多重注意力機制結構簡單緊湊,能夠無縫適用于3D卷積網絡,使卷積網絡能夠更加關心時間的重點信息和空間位置的重點信息,在僅增加微量參數的情況下提升一定的精度.本文主要貢獻點包括:1)設計一種多重注意力機制,分為通道結合時間注意力機制和空間位置注意力機制兩個模塊;2) 分別在空間位置注意力機制上進行冗余時間壓縮、在通道時間注意力機制上進行信息保留的改進;3) 將多重注意力機制部署到3D ResNet中,使其在參數只有微量增加的情況下,在UCF-101和HMDB-51數據集的性能有一定的提升.
1 相關工作
在視頻分析中行為識別一直是重點研究的方向,傳統特征提取方法如改機密集軌跡方法(improved dense trajectories,iDT)[12],其在性能上可以達到不錯的效果,但是手動設計帶來的繁瑣及復雜尤為不便;自從深度學習在行為識別被引入以后,不斷取得更優的效果.該領域中,深度學習主要分為3種方法: 雙流法(two-stream)[13]、長短期記憶網絡方法(long short-term memory, LSTM)[14]及3D卷積方法(3D CNN)[5].雙流法通過提取視頻中的光流信息和單幀圖像進行融合訓練,最終整合輸出結果,目前能夠達到的精度最高,然而其光流的提取需要占用大量的訓練時間[15];LSTM方法通過選擇性忘記和選擇性記憶來傳輸狀態,在序列建模問題上具有一定優勢,能夠解決長序列訓練過程中梯度消失和梯度爆炸的問題,然而其在面對超長序列時依舊會失去效果且網絡計算量很大、耗時偏多;3D卷積網絡通過引入3D卷積和3D池化的操作.解決了2D卷積在時間維度上時間信息丟失的問題,雖然計算量較大于2D卷積網絡,但相比于前兩種方法處理速度會更快,在2015年就已達到了313 f·s-1[4].
注意力機制被引入卷積神經網絡后對網絡的提升效果相當顯著,它能夠讓網絡更加關注重點信息并且抑制無關信息.注意力機制按作用域來區分有空間域、通道域、層域、混合域的注意力機制.Xiao等[16]提出的空間變換器網絡,其通過一個空間變換來提取空間域的信息;Hu等[17]提出的擠壓激勵網絡 (squeeze-and-excitation networks, SENET)通過擠壓、激勵、注意3個步驟來完成通道域的注意力機制;Wang等[18]提出的殘差注意力網絡借鑒了殘差網絡的想法,將當前層的信息加上掩碼作為下一層的輸入來完成混合域的注意力機制,這使得網絡得到的特征更為豐富.
在行為識別中,也有注意力機制的引入.Girdhar等[19]結合變換器設計一種注意力機制,能夠自發學習跟蹤并且從人的行為中獲取上下文的語義信息.Kim等[20]通過引入一種自我監督來學習視頻幀的空間外觀和時間關系,以此進行行為識別的任務.可以發現,目前注意力機制更多的是在二維卷積上使用,而三維卷積則很少使用注意力機制.
基于以上問題的思考,本文提出一種適用于3D卷積網絡的多重注意力機制.此注意力機制分為兩個子模塊,一個是通道結合時間的注意力機制模塊,關心視頻中的重要時間信息;另一個是空間位置注意力機制模塊,關心的是單幀視頻中空間位置的重點信息.此外,分別在通道結合時間的注意力機制上加強信息提取、在空間位置注意力機制上進行冗余時間壓縮,改進完的注意力機制性能均有提升.
2 原理實現
2.1 整體方案
研究一種多重注意力機制的結構,使卷積網絡能夠更加關注視頻中重點的時間信息和空間信息.文中將多重注意力機制部署至3D ResNet的每個卷積塊中: 在卷積層之后先提取特征圖中通道和時間上的重點信息,然后提取輸出特征圖中的重點空間位置信息, 如圖1所示.
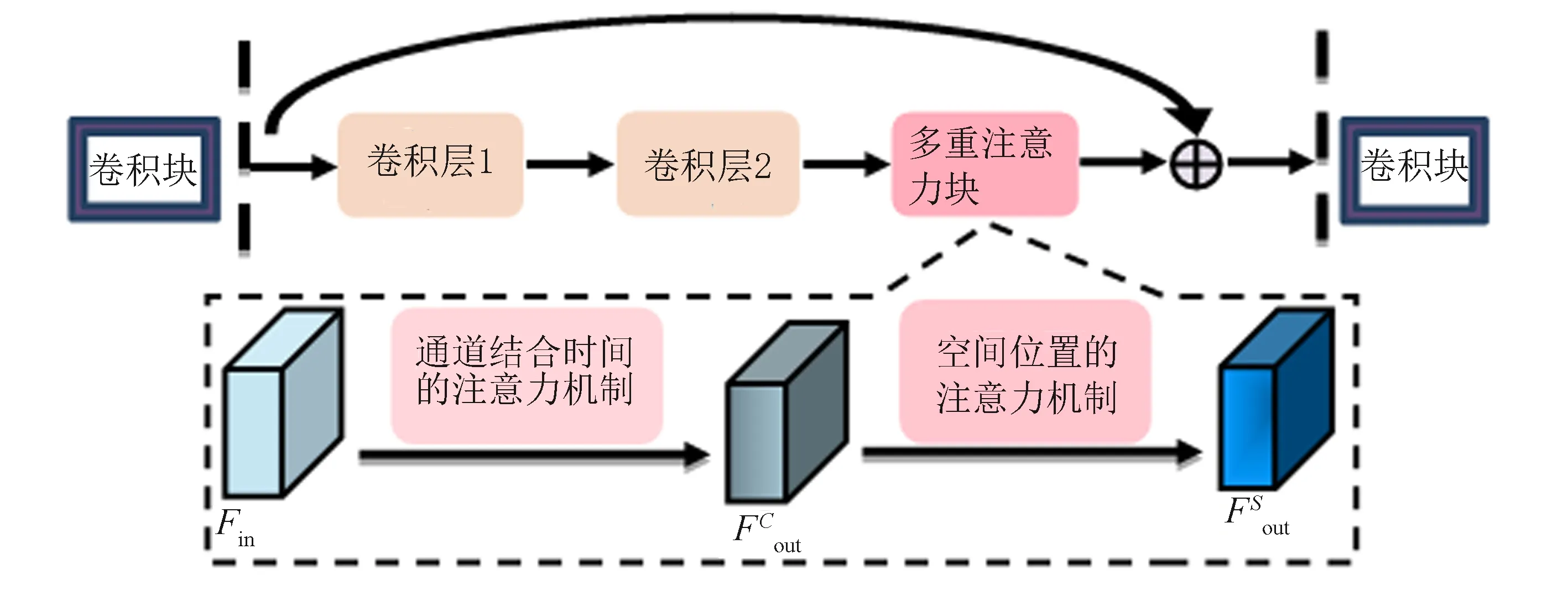
圖1 鑲嵌多重注意力機制的3D ResNet結構Fig.1 3D ResNet structure embedded with multiple attention mechanisms
2.2 通道結合時間注意力機制
在3D卷積中輸入和輸出的特征圖一共有5個維度,分別是(N、C、D、H、W),其中N代表批尺寸大小,C代表通道數,D代表時間長度,H和W代表高度和寬度. 由于通道信息維度C和時間維度D的信息具有關聯性,因此將通道信息與時間信息進行結合以更好地關注視頻中的重點時域信息. 具體實現方式如圖2所示,設計了三種不同的結構.

圖2 兩種通道結合時間的注意力機制結構Fig.2 Two attention mechanism structures of channel combined with time
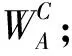
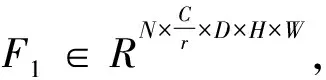
2.3 空間位置注意力機制
如圖3所示,借鑒經典的CBAM算法中空間注意力機制子模塊的思想,并將其推廣到3D卷積網絡中得到空間位置模塊A(spatial position A,SPA)模塊.

(a) SPA模塊
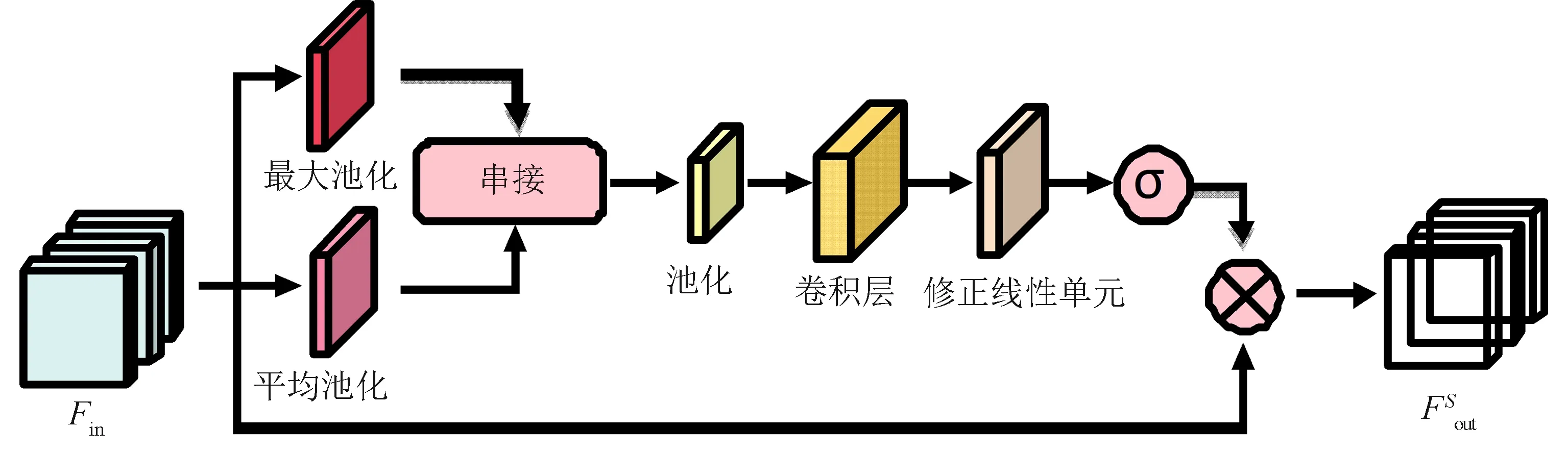
(b) SPB模塊 圖3 兩種空間位置的注意力機制結構Fig.3 Two attention mechanism structures of spatial position

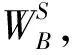
2.4 網絡架構

3 實驗驗證
3.1 數據集
實驗使用的數據集為UCF-101[21]和HMDB-51[22]兩個中型數據集.UCF-101包含101類動作,共13 000多個視頻,在動作的采集上具有多樣性.HMDB-51包含51類動作,共6 000多個視頻,包含一般的身體動作和交互動作等.
在所有實驗中,網絡的參數設置如下: 視頻一次輸入16幀,并以紅綠藍顏色的形式被調整成大小為128 px×171 px的尺寸;而后在每個輸入中加入一個16 px×112 px×112 px 的隨機抖動和50%概率的水平翻轉;優化器選擇帶有動量的隨機最速下降法,設置動量為0.9;批尺寸設為16,初始學習率設為10-3,并且每30個回合下降為原來的十分之一,共訓練100個回合.
3.2 消融實驗
本研究分別進行了5組實驗,即3D ResNet-18、CTA模塊與SPA模塊的組合、CTA模塊與SPB模塊的組合、CTB模塊與SPA模塊的組合、CTB模塊與SPB模塊的組合.從頭開始訓練最終得到幾組實驗的Top-1精度,如表1所示.

表1 幾種組合在UCF-101和HMDB-51下的Top-1精度
3.3 實驗分析
根據表1可看到,在4種組合的多重注意力機制上,CTB模塊與SPB模塊的組合性能最好,且它們在單獨和模塊A組合時性能也優于CTA和SPA模塊的組合.最終,CTB模塊與SPB模塊的組合在UCF-101數據集精度上可達到91.70%,相比于原始3D ResNet-18的90.2%的精度提升了1.5%;且在HMDB-51數據集上相比于3D-ResNet提升了1.24%.
為進一步驗證多重注意力機制的通用性,文中將CTB + SPB模塊的組合嵌入現有的3D網絡,并在UCF-101下訓練得到精度對比, 如表2所示.在加入多重注意力機制后,各3D卷積網絡的性能相較于原始結構的性能均有提升,由此證明多重注意力機制的通用性強,可嵌入各3D卷積網絡.

表2 各3D網絡加入CTB + SPB與原始結構精度對比
3.4 對比實驗
從表1中可得到在鑲嵌了多重注意力機制的3D ResNet-18上的Top-1精度為91.7%.如表3所示,和現有的其他3D網絡相比,它在UCF-101數據集上精度僅次于雙流I3D方法.然而,雙流法高精度因光流信息的提取步驟占據整個訓練過程90%的時間,較為費時.文中的結構無需提取光流信息,在訓練速度上優于雙流I3D方法.為進一步探索模型的速度和衡量模型的復雜度,文中還進行了各網絡之間浮點運算次數(FLOPs)的對比,如表4所示.可見雙流I3D的光流輸入及紅綠藍顏色輸入需要經過兩次網絡,浮點運算為原I3D的兩倍;而文中提出的 3D ResNet-18 + CTB + SPB結構浮點運算優于雙流I3D.
在3D ResNet-18網絡結構添加了多重注意力機制之后,參數量從33.24 MB增加到33.32 MB,只增加0.24%,可見加入多重注意力機制的殘差網絡參數量僅會微量增加.此外,本文的模型是未經過預訓練的,在容易產生過擬合的中型數據集上依舊能夠取得較佳的性能.

表3 現有3D網絡在UCF-101上精度和參數量的對比
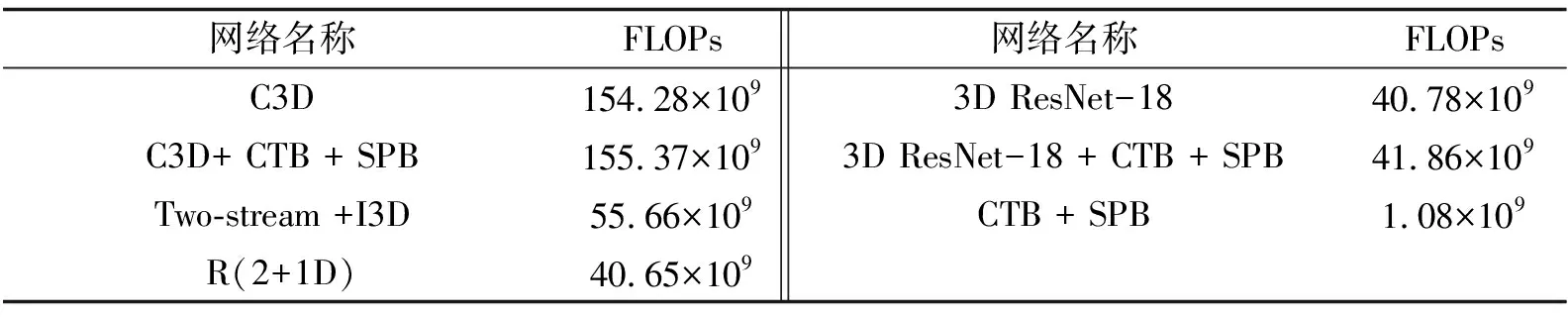
表4 現有3D網絡浮點運算次數(FLOPs)的對比
4 結語
本文提出一種多重注意力機制用于提升3D卷積網絡的表達能力,此多重注意力機制分為通道結合時間注意力機制和空間位置注意力機制.在探索結構中提出兩種優化方法: 首先,去除通道結合時間注意力機制中的多層感知器并先進行卷積,減少信息損失并提高精度;其次,壓縮空間位置的注意力機制中的時間維度,減少冗余時間信息.文中將多重注意力機制部署到3D ResNet-18中,相比于原始3D ResNet-18,在保持參數量僅增加0.24%情況下,在從頭訓練的UCF-101數據集上提升了1.5%,在HMDB-51數據集上提升了1.24%.此外,多重注意力機制模塊通用性強,可以無縫鑲嵌到各種3D卷積網絡中.
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
文苑(2018年21期)2018-11-09 01:23:06
中華手工(2017年2期)2017-06-06 23:00:31
中國衛生(2016年9期)2016-11-12 13:28:08
中國衛生(2015年9期)2015-11-10 03:11:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
