基于深度強化學習的知識推理研究進展綜述
2022-01-22 07:46:48宋浩楠孫若瑩
計算機工程與應用 2022年1期
宋浩楠,趙 剛,孫若瑩
北京信息科技大學信息管理學院,北京 100192
近年來,隨著云計算、物聯網等技術的快速發展,數據規模呈現爆發式增長,如何組織和利用數據中的知識備受關注,知識圖譜由此應運而生。知識圖譜的概念起源于語義網[1-2](semantic Web),Google 公司于2012 年率先提出知識圖譜(knowledge graph,KG)的相關概念。KG本質上是一種用圖模型來描述知識和建模世界萬物之間關聯關系的技術方法[3]。知識圖譜是由節點和邊組成,常用事實三元組(頭實體、關系、尾實體)對其進行形式化表示。將實體(頭實體、尾實體)表示成圖上的節點,實體之間的關聯關系對應于圖上節點之間的連邊,實體包括客觀事物和概念。
隨著知識圖譜研究和應用的深入,知識圖譜被廣泛運用于搜索引擎、問答系統和推薦系統等領域。現階段,大批知識圖譜已經涌現出來,具有代表性的通用知識圖譜有Freebase[4]、DBpedia[5]、NELL[6]等,其中,國內知識圖譜也得到了一定的研究和應用,例如搜狗的知立方[7]、百度知心[8]等。然而,由于構建知識圖譜的源數據規模有限,尤其是一些隱含的常識性知識并不能直接獲取,導致知識圖譜不完整。根據West等人[9]在2014年的統計結果,在Freebase[4]中存在大量實體和關系缺失情況。知識圖譜的不完整問題給實際的應用帶來了很多障礙,成為人工智能進一步發展的重要制約因素。因此,將不完整的知識圖譜進行補全完善成為了知識圖譜研究亟待解決的問題之一。
面向知識圖譜的知識推理作為解決上述問題的重要方法,引起了研究人員的廣泛關注。近年來,知識圖譜的研究已經取得了較大的進展,有不少關于知識圖譜的綜述性文獻陸續發表。譬如,文獻[10]對知識圖譜構建技術進行了綜述;文獻[11]從知識表示、知識獲取和知識應用三個方面進行了總結;文獻[12-13]對知識表示學習技術進行了綜述;文獻[14-16]分別從不同角度對知識推理技術進行了綜述。然而,盡管已有上述諸多知識圖譜綜述文獻,但仍然缺乏對基于深度強化學習的知識推理研究進行系統、深入地梳理與總結的工作。為此,本文對面向知識圖譜的深度強化學習知識推理的最新研究進展進行歸納總結,并展望未來發展方向和前景。
1 知識推理方法
1.1 知識推理簡介
對于知識推理的基本概念,國內外諸多學者給出了許多相類似的定義。王永慶[17]認為,推理就是從實際出發,運用已有知識,按照某種策略由已獲得的知識推出新的事實的思維過程。Kompridis[18]定義推理為一系列能力的集合。Tari[19]認為,知識推理為基于特定的規則和約束,從已存在的知識中獲得新的知識。總的來說,知識推理本質上就是利用已經存在的知識推出未知的或者新知識的過程。
本文研究的知識推理是指通過知識推理方法來完成知識圖譜補全(knowledge graph completion,KGC)工作。KGC旨在將不完整的知識圖譜進行補全完善[14],包括鏈接預測和事實預測兩個任務,其中,鏈接預測是指預測三元組的缺失部分,事實預測則是判斷三元組正確與否。于是,本文研究的知識推理方法的具體任務為鏈接預測、事實預測和以它們為基礎的上層應用(如問答問題)。
1.2 知識推理相關方法
本文從不同視角對知識推理給出了詳細劃分,如圖1 所示。官賽萍等人[14]根據推理背景的不同,將知識推理劃分為傳統的知識推理和面向知識圖譜的知識推理。其中,傳統的知識推理包括演繹推理與歸納推理、確定性推理與不確定性推理等,而面向知識圖譜的知識推理被劃分為單步推理和多步推理,而這兩類推理方式又被分為基于規則的推理、基于分布式表示的推理、基于神經網絡的推理和混合推理。吳運兵等人[20]根據知識推理過程中使用的模型和原理,將知識圖譜的知識推理方法分為基于張量分解方法、基于轉換方法、基于路徑推理方法和其他推理方法。徐增林[21]、劉嶠等人[10]將知識圖譜的知識推理方法分為基于邏輯的推理與基于圖的推理兩種類別。漆桂林等人[22]將知識圖譜的知識推理分為基于符號的推理和基于統計的推理兩種類別。
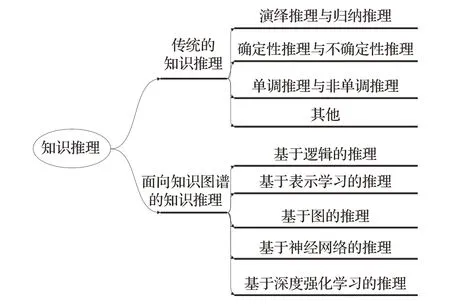
圖1 知識推理的方法分類Fig.1 Method classification of knowledge reasoning
綜上,本文將面向知識圖譜的知識推理方法劃分為基于邏輯的推理,基于表示學習的推理、基于圖的推理、基于神經網絡的推理和基于深度強化學習的推理方法。基于邏輯的推理方法[23-31]主要是通過一階謂詞邏輯(first order logic)、描述邏輯(description logic)以及規則等推理出新的知識。該類方法的規則獲取難度大,推理能力受限;基于表示學習的推理方法[32-42]主要是利用知識表示學習模型,將知識圖譜中的實體和關系映射到低維向量空間,并對知識圖譜的低維向量表示進行計算來實現推理。該類方法未能充分利用KG 中關系路徑等信息,推理準確率尚有較大提升空間;基于圖的推理方法[43-48]主要是將知識圖譜中實體間的不同的關系路徑作為特征,通過統計關系路徑來提取特征向量,建立針對關系的分類器,從而實現實體間關系的預測。該類方法未考慮路徑的可靠性計算問題,難以適用于大規模知識圖譜;基于神經網絡的推理方法[49-54]是基于神經網絡模型來實現推理,該類方法具有更高的學習和泛化能力,可直接建模知識圖譜事實元組,提高了推理的性能。
雖然基于神經網絡的推理方法得到廣泛重視和研究,但是該類模型的解釋性缺乏仍然是迄今無法擺脫的問題。相比之下,基于邏輯的推理方法具有可解釋性、高準確率等特點,但卻嚴重依賴于邏輯規則。這些都制約著知識推理方法的發展。近年來,由于強化學習在可解釋性和性能等方面的優勢,使得基于強化學習的知識推理方法迅速成為研究熱點。基于深度強化學習的知識推理在具備神經網絡模型優勢的基礎上,還具備更好的可解釋性,因此基于深度強化學習的知識推理模型不斷涌現。隨著知識圖譜研究的不斷深入,知識圖譜應用逐漸向封閉域和開放域兩個方向發展。于是,本文從封閉域推理和開放域推理兩個角度,對現有推理模型的基本思路與方法進行總結分析。
2 基于深度強化學習的知識推理
2.1 面向封閉域的深度強化學習知識推理
2.1.1 DeepPath模型
Xiong 等人[55]于2017 年首次提出了基于強化學習(reinforcement learning,RL)的知識推理模型DeepPath,將知識圖譜中知識推理過程轉化為馬爾可夫序列決策過程,以實體集合E為狀態空間S、關系集合R為動作空間A,通過增量方式進行推理,即RL 智能體每次都選擇最優動作以拓展其路徑來實現知識圖譜中的推理,如圖2 所示。該模型使用知識表示學習模型TransE[32],將知識圖譜映射到低維稠密向量空間中從而得到知識的向量表示形式。為使智能體自動撤銷錯誤的決策,完成推理任務,關系集合R由知識圖譜中已存在的關系r和新添加關系r-1兩部分組成,r-1是關系r的逆關系。
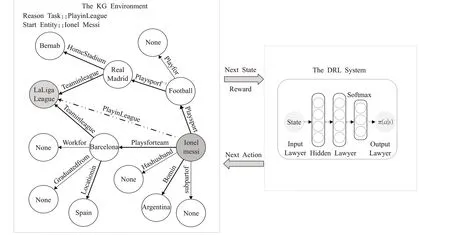
圖2 DeepPath模型Fig.2 Model of DeepPath
該模型由外部環境和RL 系統兩部分組成,外部環境為RL 智能體和知識圖譜交互的環境,由知識圖譜的向量表示空間構成。RL 系統主要由

其中et表示RL智能體的當前位置,etar表示目標位置。動作空間A中動作a(a∈A)是RL 智能體在et位置時選擇的下一個動作,即圖中的某個邊。該動作a由模型中策略網絡的輸出決定,其表示如下:
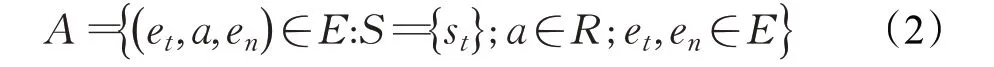
其中en表示下一個可能的位置,a表示RL智能體采取的動作。
獎勵函數γ的設計考慮了準確性、效率和路徑多樣性三方面。
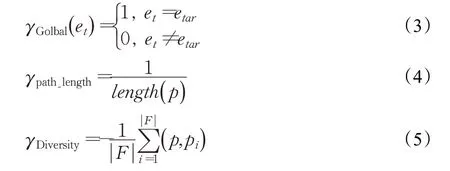
其中p、pi分別表示當前推理過程中發現的推理路徑和歷史推理過程中已發現的關系路徑,F表示已發現的關系路徑數量。
由于大規模知識圖譜的關系數量眾多,基于強化學習方法建模的動作空間規模龐大,因此該模型直接選擇基于策略網絡的深度強化學習來完成推理任務。策略網絡由三層全連接神經網絡構成,其中每個隱藏層后都添加非線性層(ReLU),使用softmax函數對輸出層進行歸一化處理,同時使用REINFORCE[56]方法對模型進行優化。該模型的訓練過程是由基于高質量的正確路徑進行有監督策略學習預訓練和基于多樣性獎勵的策略學習再訓練兩個過程組成。
DeepPath 模型從圖的角度首次將強化學習方法引入知識推理,思路新穎,相比于之前的推理方法,性能得到較大提升。但由于DeepPath模型簡單,并且需要提供大量已知路徑進行預訓練,訓練過程復雜,因此其推理性能存在很大提升空間。
2.1.2 MINERVA模型
隨著知識圖譜規模的不斷增加,圖中的路徑數量也呈現指數增長。先前的基于路徑模型的強化學習方法僅考慮了預測給定兩個實體的缺失關系或評估給定三元組的真實性的問題,卻不能解決更為復雜和實際的問答問題(知識推理的上層應用問題),即在已知關系和一個實體情況下,直接推理出另一個實體。針對該問題,Das等人[57]提出了MINERVA,將起始實體到目的實體之間的路徑選擇問題轉化為序列決策問題,通過在知識圖譜環境中,以輸入查詢為條件,RL 智能體進行交互轉移,最終停留在答案實體(目標位置),從而實現端到端的查詢回答。該模型不依賴于目的答案實體,具備更為強大的推理能力。為了使智能體自動撤銷錯誤的決策和到達答案實體時停止交互轉移,關系集合R由知識圖譜中已存在的關系r、新添加關系r-1和關系NO-OP三部分組成,r-1是關系r的逆關系,NO-OP 是實體指向自身的關系。
由于該任務中答案實體未知,因此該模型是建立在確定性的部分觀測馬爾可夫決策過程上。該RL模型也是由外部環境和RL 系統兩部分組成,外部環境是由知識圖譜構成。RL系統主要由

其中et表示RL智能體的當前位置,(e1q,rq)表示已知實體和關系組成的查詢對,e2q表示目標位置。
觀察O是部分可觀察的,直觀上,RL 智能體僅已知當前位置et和查詢對(e1q,rq),即:
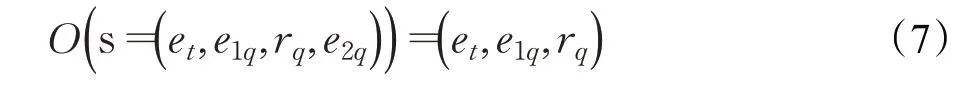
動作空間A中動作a(a∈A)的定義與DeepPath 模型相同。
獎勵函數γ僅定義了一個最終獎勵,即RL 智能體在規定步長內成功到達目標位置,則系統給予智能體+1的獎勵,反之獎勵為0。
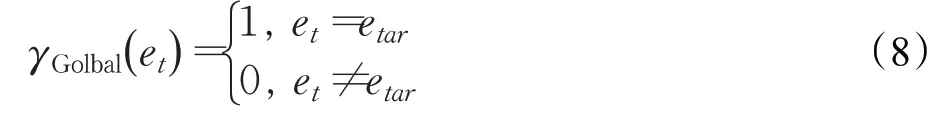
為了解決在大規模知識圖譜中針對確定性部分觀測馬爾可夫決策過程的建模問題,該模型直接設計了一種依賴歷史Ht的策略,其中Ht={}Ht-1,At-1,Ot是一系列觀測和執行動作的組合。該模型使用基于LSTM[58]的RL 智能體將歷史ht編碼為連續向量ht=LSTM(ht-1,[at-1;ot]),其中at-1是t-1 時刻智能體選擇的動作,ot是t時刻智能體所在的實體節點。該模型使用基于策略網絡的深度強化學習來完成推理任務,策略網絡由三層全連接神經網絡設計而成,其中輸入層為歷史ht、觀測ot和問答關系rq的組合,在每個隱藏層之后添加非線性層(ReLU),并使用softmax函數對輸出層進行歸一化處理,即:
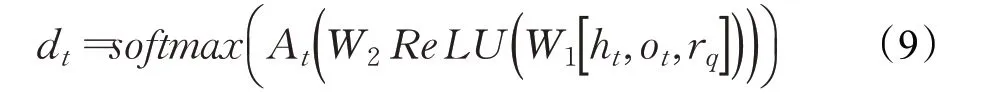
其中W1、W2表示神經網絡的權重。
為了解決策略網絡的優化問題,實現最大化期望獎勵的任務。該模型同樣使用REINFORCE[56]方法對模型進行優化。
MINERVA 模型以查詢問題為條件,利用強化學習方法引導智能體在知識圖譜中找出預測路徑,從而實現推理任務,解決了在已知一個實體和關系情況下的問答問題。在公開數據集的綜合評估中,MINERVA 相比于之前眾多先進方法具有競爭力。但該模型是基于查詢的問答模型,面臨著因知識缺失而導致無法獲取正確答案和因錯誤路徑引導而導致模型效果較差的問題。
2.1.3 Multi-Hop模型
基于深度強化學習知識推理方法研究中,智能體不僅會因訓練數據中的錯誤路徑引導而獲得獎勵,而且也會因訓練數據中正確路徑引導失敗而丟失獎勵,這些問題都將影響強化學習推理的準確率。為此,Lin 等人[59]提出了Multi-Hop,在深度強化學習方法中引入軟獎勵機制和智能體Action-Dropout方法,如圖3所示。首先,該模型采用預訓練的基于嵌入的先進模型ConvE[60],對無法確定的正確目標進行軟獎勵評估,從而得到相應的替代原獎勵方式的軟獎勵,該獎勵可保證未被智能體搜索出來但正確的目標獲得更高的獎勵分數。其次,該模型執行Action-Dropout操作,在訓練過程中,隨機掩蓋圖中節點某些向外的邊,以便實現智能體對路徑的多樣性探索。
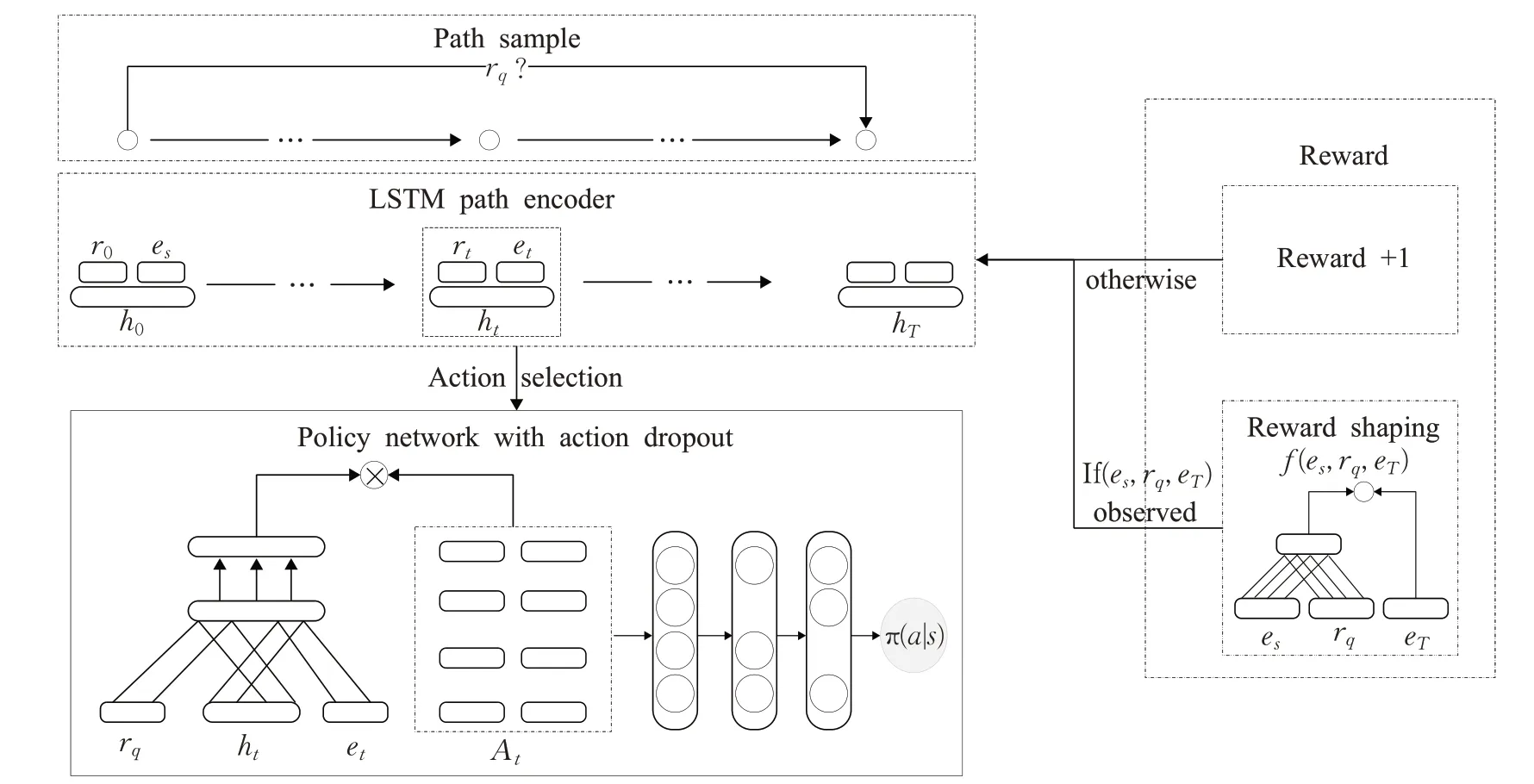
圖3 Multi-Hop模型Fig.3 Model of Multi-Hop
該強化學習模型主要是由以下三部分組成。
狀態空間S中狀態st(st∈S)的表示如下:

其中,et表示智能體t時刻所在位置,()es,rq表示初始實體和關系組成的查詢對。
動作空間A中的動作的定義與DeepPath模型相同。
獎勵函數R的表示如下:

其中,sT表示智能體的最終狀態,eT表示智能體最終位置,f(es,rq,eT)表示該模型評估出來的軟獎勵。Rglobal(sT)表示推理過程中獲得的獎勵,其定義如下:
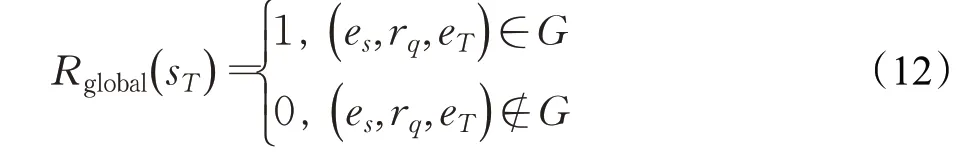
為了解決在大規模知識圖譜中建模馬爾可夫決策過程的問題,該模型設計了結合狀態信息、全局信息和搜索歷史信息來參數化搜索策略。知識圖譜的所有實體和關系都被初始化為維度為d的低維稠密向量(e,r∈Rd)。搜索歷史ht=(es,r1,e1,…,rt,et)∈H,其中H={ht} 是一系列搜索歷史的集合。該模型使用基于LSTM 模塊的RL 智能體將搜索歷史ht進行編碼,其定義如下:
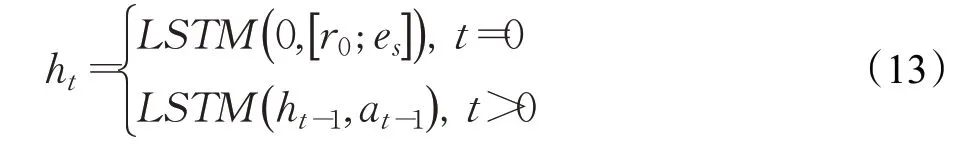
其中r0是為了引出起始實體es而設計的特殊關系,ht-1和at-1分別表示t-1 時刻的搜索歷史和選擇的動作。
該模型使用基于策略網絡的深度強化學習來完成該推理任務。策略網絡定義及優化與MINERVA 模型相同。
相比于MINERVA 模型,該模型主要進行了兩處改進,分別是引入軟獎勵機制和智能體Action-Dropout方法,解決了RL 智能體推理過程中遇到的兩個問題:(1)訓練數據中的錯誤路徑引導而獲得獎勵;(2)訓練數據中正確路徑引導失敗而丟失獎勵,從而提高了模型的性能。
2.1.4 DIVINE模型
針對深度強化學習知識推理方法中存在的兩個問題:(1)策略網絡的動作空間過大,導致訓練過程中策略網絡難以收斂;(2)策略網絡更新的獎勵函數是由人工設計,并且面向于特定數據集,不僅效率低、工作量大,而且難以滿足當前快速變化的知識圖譜推理需求。研究者提出了一種基于生成對抗模仿學習[61](generative adversarial imitation learnin,GAIL)的即插即用型模型框架DIVINE[62],基于引導路徑發現過程,通過模仿演示從知識圖譜中自動采樣來自適應地學習推理策略和獎勵函數,以解決靜態知識圖譜推理過程中存在的問題。該框架由生成式對抗推理器和演示采樣器兩個模塊組成。通過使用生成式對抗訓練獲得的演示和采樣器獲取的演示,訓練一個包含生成器和判別器的推理器,如圖4所示。經過訓練,該框架可使用基于策略網絡的智能體(即生成器)來發現與演示的分布相匹配的證據路徑,并通過綜合這些證據路徑實現推理。
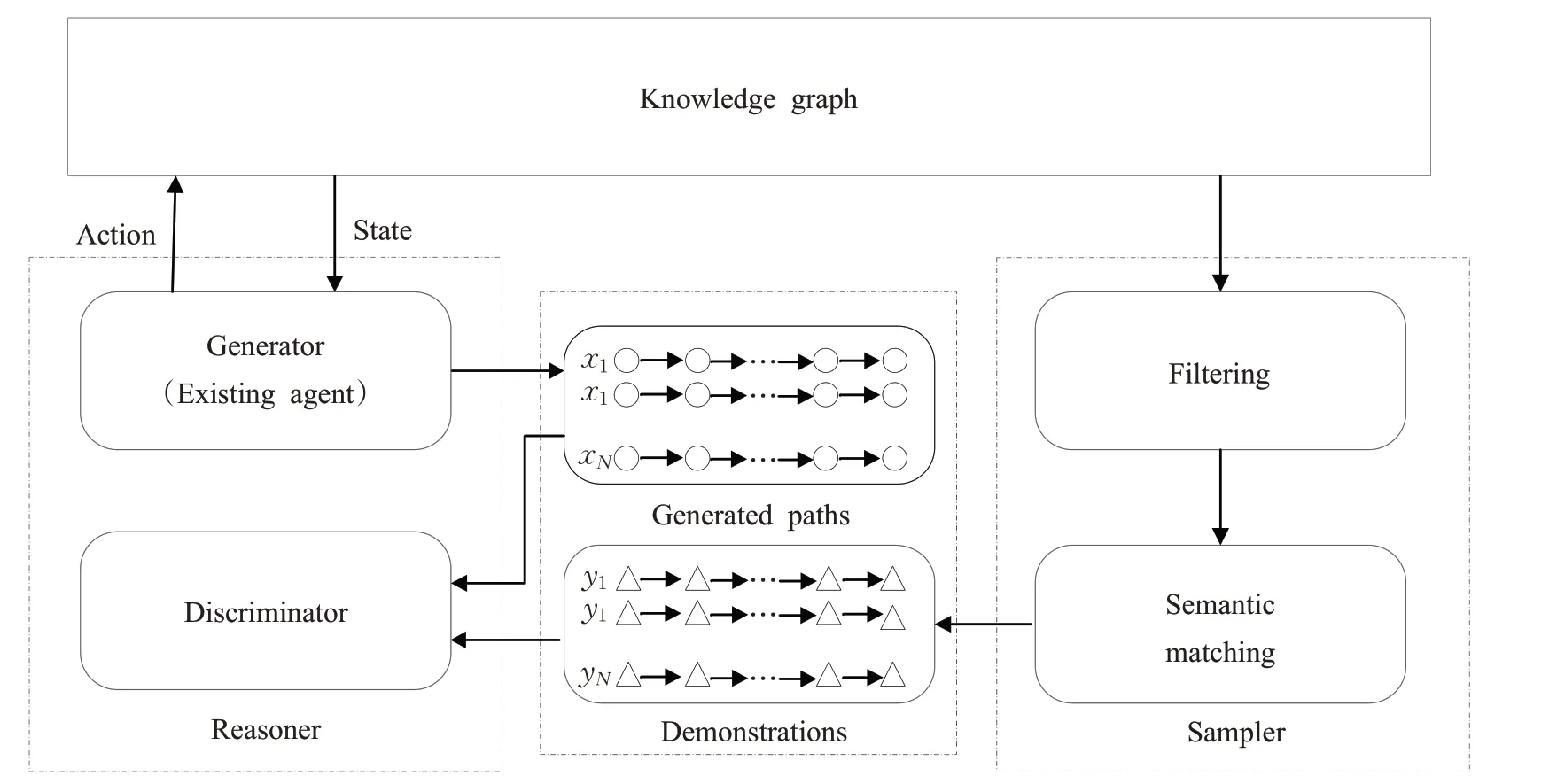
圖4 DIVINE模型Fig.4 Model of DIVINE
該DIVINE 框架由兩個模塊組成,即生成式對抗推理器和演示采樣器,推理器由生成器和判別器組成,生成器是RL 中的任何一個基于策略網絡的智能體,而判別器是一個自適應獎勵函數。具體而言,對于每一個查詢關系,分別使用采樣器和生成器來自動提取演示并從給定的知識圖譜中生成關系路徑。然后,使用判別器來評估生成的路徑和演示之間的語義相似性,以更新生成器。在生成器和判別器之間經過足夠的對抗訓練之后,使用訓練好的基于策略的智能體(即生成器)來找到與演示的分布相匹配的證據路徑,并通過綜合這些證據路徑來進行預測。
(1)生成式對抗推理器
該模型通過生成式對抗訓練從演示中學習推理器。為了鼓勵智能體盡可能多地挖掘多樣性證據路徑,通過模仿每一個軌跡而不是每一個動作對來訓練智能體,提高模型的整體性能。該模型提出了一種基于路徑的GAIL 方法,通過模仿僅由關系路徑組成具有路徑級語義特征的演示來學習推理策略。該推理器由兩部分組成,即生成器和判別器。
(2)演示采樣器
為了滿足模仿學習對高質量的演示需求,同時避免人工構建推理演示的低效率問題,該模型設計了一種自動采樣器,在無監督、無人工干預條件下,實現從知識圖譜中采樣大量的高質量的推理演示。該模型使用了靜態和動態兩種演示采樣方法采樣演示,針對長尾實體無法提取足夠數量演示的問題,該模型使用語義匹配的方法來探索更多演示。
在訓練過程中,該模型將采樣器得到的演示集合和生成器生成的路徑集合輸入到模型判別器中進行訓練,通過最小化損失函數實現對判別器的訓練。
基于生成對抗模擬學習的知識圖譜推理即插即用框架DIVINE,增加了現有的基于深度強化學習推理方法自適應地學習推理策略和獎勵功能,以適應快速發展的真實世界知識圖譜。
2.1.5 AttnPath模型
為了解決深度強化學習知識圖譜推理方法研究過程中,缺乏記憶組件和訓練過程復雜的問題,研究者提出了一種基于深度強化學習的模型AttnPath[63],該模型將長短期記憶網絡(LSTM)和圖注意力機制作為記憶組件,同時定義了兩個指標:均值選擇率(mean selection rate,MSR)和均值替換率(mean replacement rate,MRR),實現對目標關系替代路徑的難易程度定量化評價,如圖5所示。為了避免智能體停滯在同一實體節點,該模型引入了一種新的強化學習機制,強制智能體在每一步都進行狀態轉移。該模型不僅可以擺脫預訓練過程,而且同其他模型相比也能達到最佳性能。

圖5 AttnPath模型Fig.5 Model of AttnPath

為了定量地衡量每個關系的難度值,該模型定義了兩個指標:均值選擇率(MSR)和均值替換率(MRR)。其中均值選擇率(MSR)表示學習關系r的難度,其定義如下:
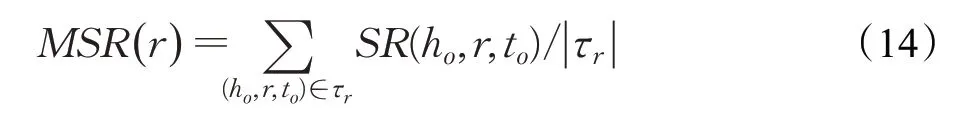
其中τr表示所有與關系r相關的三元組,SR(h,r,t)表示對于關系r的選擇率,具體定義如下:
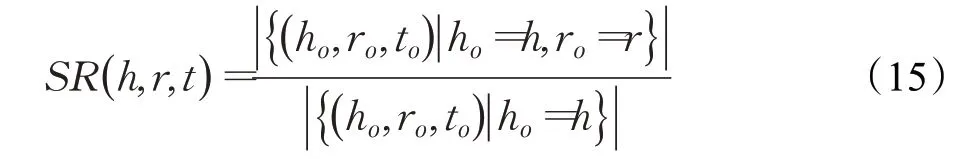
相似地,均值替換率(MRR)的定義如下:
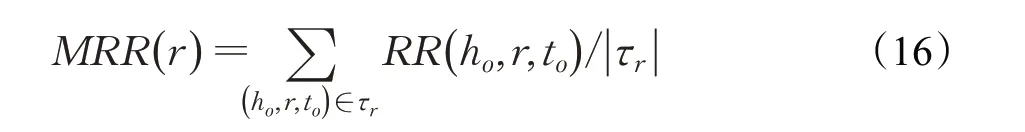
其中,RR(h,r,t)表示關系r的替代率,具體定義如下:
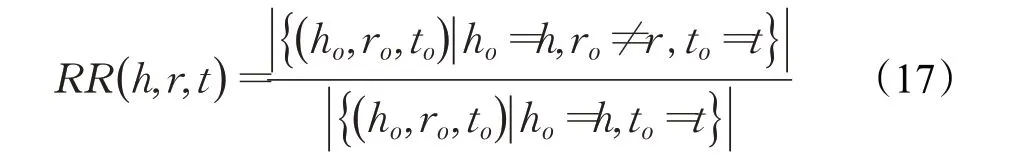
該模型使用三層神經網絡訓練,輸出層使用Softmax函數進行歸一化處理,使用REINFORCE[56]方法進行參數優化,同時使用L2 正則化、dropout、action-dropout三種方式防止過擬合。具體地,對于MSR和MRR高的關系,該模型使用多種方式指導智能體盡可能多的去發現多樣性路徑;反之,則使用少量的方式指導訓練。
AttnPath 是一種基于深度強化學習的知識推理模型,該模型將LSTM 和圖注意力機制作為記憶組件,以減輕模型的預訓練,還定義了兩個指標MSR和MRR來衡量關系的學習難度,并將其用于微調訓練超參數,提高了訓練效率。對比實驗結果表明,該模型明顯優于DeepPath和基于表示學習的方法。
2.2 面向開放域的深度強化學習知識推理CPL模型
為了應對知識圖譜稀疏和不完整的情況,克服封閉域知識圖譜中知識缺失造成模型性能受限的問題,研究者提出了一種新穎的基于強化學習面向開放域知識圖譜推理的模型CPL(collaborative policy learning)[64],該模型通過聯合訓練多跳圖推理器和事實提取器兩個協作智能體,實現開放知識圖譜推理任務,如圖6 所示。事實提取器中的智能體從背景語料庫中生成事實三元組來實現知識圖譜的動態擴充,而多跳圖推理器中的智能體在基于擴充的知識圖譜構建的強化學習環境中進行推理,同時該智能體在知識圖譜推理過程中向事實提取器提供反饋,并指導其生成有助于模型推理的事實。由于現有模型對知識圖譜推理的研究都是建立在封閉空間中,即假定知識圖譜是靜態的,所以無法實現對知識圖譜中事實的動態添加。該模型從文本語料庫向知識圖譜動態添加事實增強路徑查找以改善推理性能,同時基于強化學習框架設計模型,進一步提升了模型的可解釋性。該模型的主要任務是已知查詢對(es,rq),通過RL 智能體在知識圖譜中推理出目的實體eq。
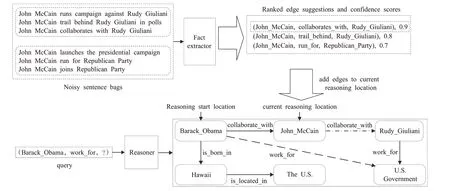
圖6 CPL模型Fig.6 Model of CPL
該模型是由圖譜推理和事實提取兩個智能體構成。對于圖譜推理智能體而言,其目的是幫助推理器在知識圖譜中進行路徑發現從而完成推理。圖推理器的馬爾可夫決策過程被定義為如下三個部分。
狀態空間S的表示如下:

其中,et是智能體當前位置,rt是連接et的前一個關系。
動作空間A的表示如下:
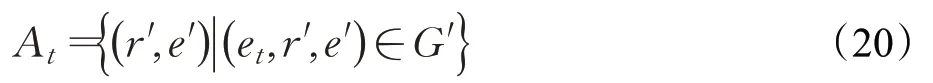
其中,G′表示擴充后的知識圖譜,其具體定義如下:
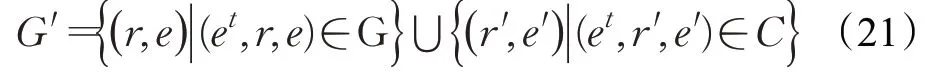
其中G表示知識圖譜中原有的三元組。C表示從文本語料庫中提取的三元組。
獎勵函數R的表示如下:
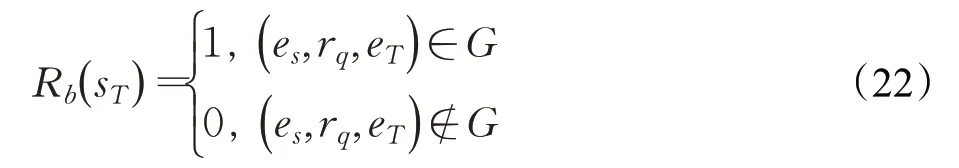
其中,sT表示智能體的最終狀態,eT表示智能體的最終位置。
事實提取器的馬爾可夫決策過程被定義為如下三個部分。
狀態空間S的表示如下:

其中,bet表示文本語料庫中包含當前推理位置的實體的句子集合,et表示智能體當前推理的位置。
動作空間A的表示如下:

該模型中的事實提取智能體和圖譜推理智能體采用單一訓練過程,即訓練事實提取智能體時,凍結圖譜推理智能體的相關參數,反之亦然。圖推理器根據圖譜提取器對知識推理任務的貢獻程度向圖譜提取器提供反饋。該模型使用REINFORCE[56]通過最大化期望獎勵的方式,來訓練模型中的兩個智能體,同時定義了推理智能體和事實提取智能體兩個策略網絡,推理智能體的策略網絡是由三層神經網絡構成。
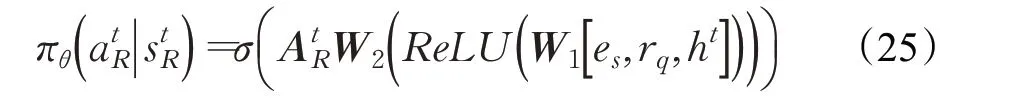
其中,σ表示softmax函數,AtR表示所有動作嵌入組成的矩陣。
事實提取智能體的策略網絡定義如下:

其中,Etb是文本語料庫中提取的候選句子嵌入組成的矩陣,可看作潛在狀態的嵌入。AtE是所有關系嵌入組成的矩陣。
該模型使用預訓練和自適應采樣兩種方法來增加模型的訓練效率。
為了加強開放域知識圖譜推理研究,研究人員提出了一種新穎的協作策略學習模型CPL,通過構建圖推理器和事實提取器,實現路徑推理和開放文本信息提取的策略學習。該模型不僅實現高效的可解釋性推理,而且還對噪音文本進行過濾。在兩個大規模數據集上的實驗結果表明,該模型具有很強的競爭力。
2.3 不同方法的對比分析
本文從方法描述、方法優缺點以及使用場景對各種類型的深度強化學習知識推理方法進行對比分析,如表1所示。
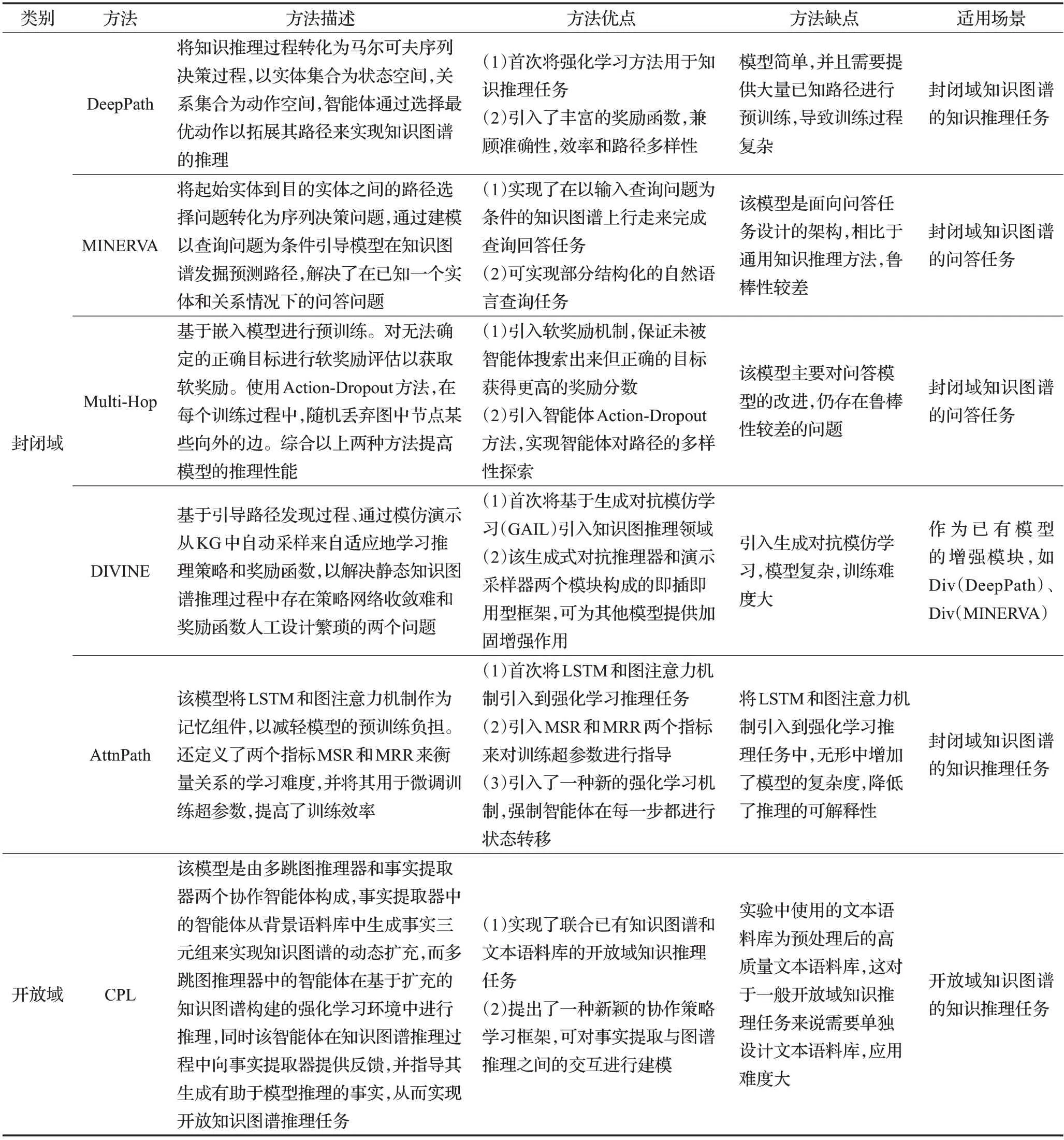
表1 基于深度強化學習的知識推理典型模型匯總表Table 1 Summary of typical models of knowledge reasoning based on deep reinforcement learning
3 強化學習推理研究常用數據集及其評價指標
3.1 公開數據集
針對封閉域和開放域這兩個不同領域的深度強化學習知識推理研究,相關實驗中使用的數據集也分為兩類,第一類為面向封閉域的公開數據集,包括FB15K-237[65]、NELL-995[55]、WN18RR[60]三種數據集。第二類為面向開放域的公開數據集,包括FB60K-NYT10(https://github.com/thunlp/OpenNRE)和UMLS-PubMed(http://umlsks.nlm.nih.gov/,https://www.ncbi.nlm.nih.gov/pubmed/)兩種數據集。
FB15K-237 是通過公開知識圖譜Freebase 的子集FB15K創建而來,FB15K數據集共592 213個三元組,具有14 951個實體和1 345種關系。FB15K-237在FB15K訓練集、測試集、驗證集的基礎上,進行了部分實體融合,刪除了大量冗余的關系數據,是FB15K經過精簡的子數據集,它包含14 505個實體,237種關系。WN18RR是從WN18創建的鏈接預測數據集,WN18是公共知識圖譜WordNet的一個子集,WN18RR數據集包含86 835個三元組,其中包含40 945個實體和11種關系。NELL-995 是基于NELL 系統的第995 次迭代產生的數據集整理后的數據集,它包含75 492個實體,200種關系。實驗數據集的統計信息如表2所示。
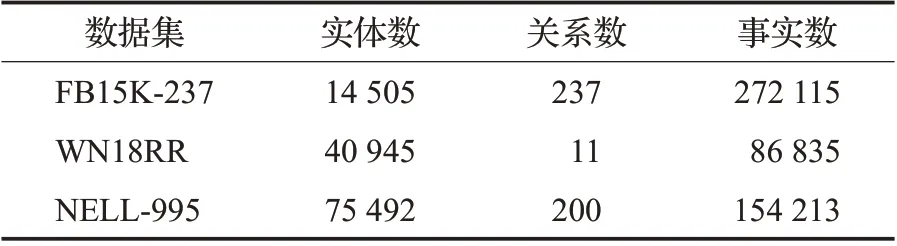
表2 開放域知識圖譜知識推理公開數據集匯總表Table 2 Summary of public dataset for open domain knowledge graph knowledge reasoning
FB60K-NYT10數據集包括FB-60K知識庫和NYT10語料庫;UMLS-PubMed 數據集包含UMLS 知識庫和PubMed 語料庫。實驗數據集的統計信息如表3 所示,其中C表示語料庫,G表示知識庫。

表3 封閉域知識圖譜知識推理公開數據集匯總表Table 3 Summary of public dataset for closed domain knowledge graph knowledge reasoning
3.2 評價指標
對于知識推理任務的評價方式,通常是鏈接預測(link prediction,LP)和事實預測(fact prediction,FP)。鏈接預測是預測三元組中缺失的部分。事實預測是在判斷三元組的正確與否。數據集一般按7∶3 的比例分為訓練集和初始測試集,而測試集是由初始測試集和其生成的負樣本組合而成,其中負樣本是由正樣本被替換尾實體生成。而實驗中使用的評價指標包括:平均精度均值(mean average precision,MAP)、前k命中率指標(hits at ranksk,Hits@k)和平均倒數排名(mean reciprocal rank,MRR)三種。
3.2.1 平均精度均值(MAP)
平均精度均值(MAP)反映了模型在數據集中平均精度(average precision,AP)的平均值,是信息檢索領域常用的性能評價標準,也作為知識圖譜推理的評價指標。MAP的取值在[0,1]之間,其計算公式如下:
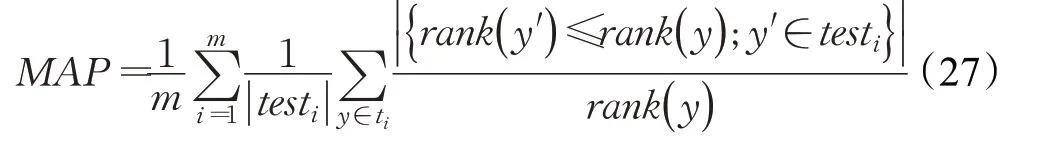
其中rank(y)和rank(y′ )分別為正樣本和負樣本的排名,testi為測試集,m為樣本總數。
3.2.2 前k命中率指標(Hits@k)
前k命中率指標(Hits@k)表示的是所有正確樣本在評分后排名進入前k以內的比例,k常用的取值1、3、10。Hits@k用測試集中排名進入前k名的三元組個數累加值除以測試集中所有三元組個數,取值范圍為[0,1]。Hits@k的值越大,則表明推理算法效果越好,其計算公式如下:
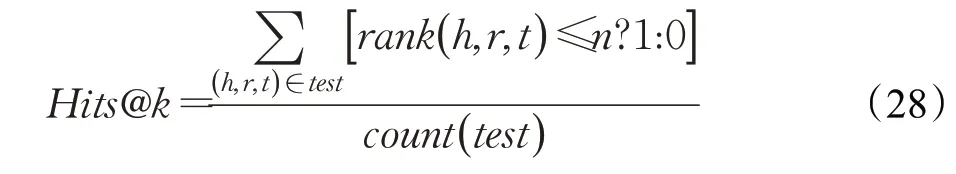
其中rank(h,r,t)≤n?1:0 為判別樣本排名是否進入前n以內的條件表達式,若rank(h,r,t)≤n成立表達式值為1,否則為0,count(test)表示測試集中三元組總數。
3.2.3 平均倒數排名(MRR)
平均倒數排名(MRR)反映正確樣本在候選列表中的整體排名情況。MRR根據模型的評分函數對所有候選的三元組打分后,按照得分順序,求得真實的三元組在其中評分排名的倒數的平均值,作為整體結果。MRR是將排名取倒數使結果落在[0,1]之間,MRR的值越大越靠近1表示模型效果越好,其計算公式如下:
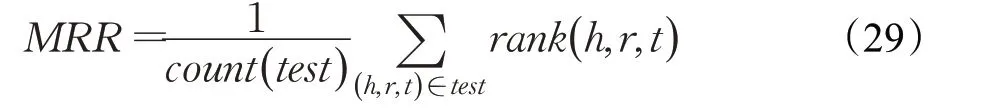
為了更直觀地認識本文介紹的各類基于深度強化學習知識推理模型,表4給出了模型對比實驗中的基線模型、訓練數據集和評價指標的匯總信息。
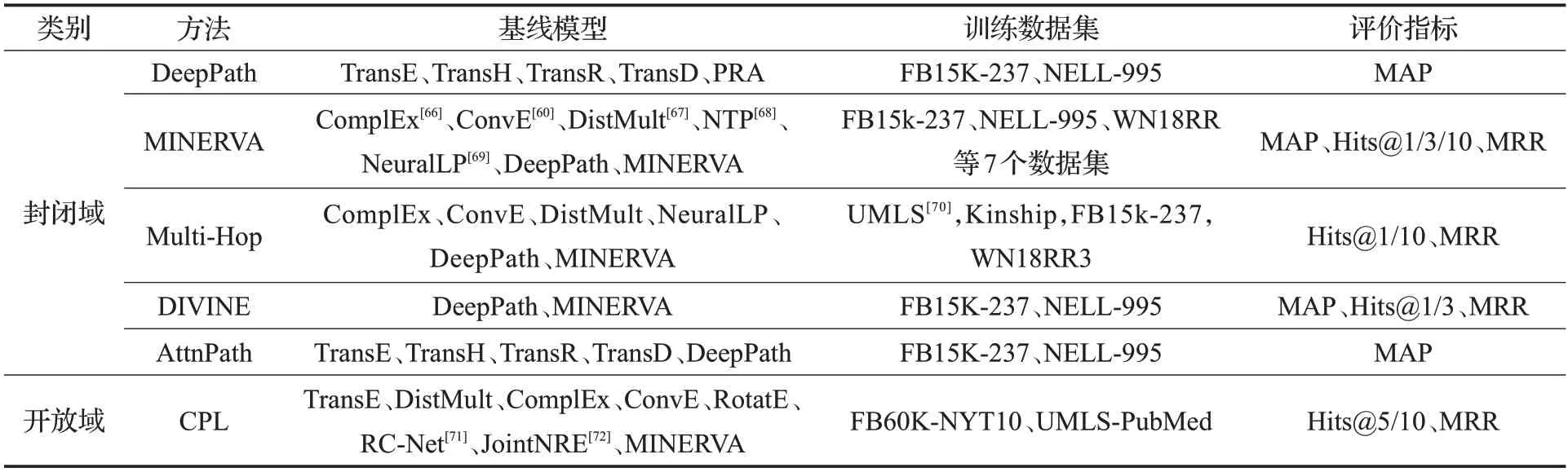
表4 基于深度強化學習的知識推理典型模型匯總表Table 4 Summary of typical models of knowledge reasoning based on deep reinforcement learning
4 總結和展望
知識推理作為知識圖譜的重要組成部分,是人工智能領域的重要研究方向,不僅在深度搜索、智能問答、智能醫療、金融反欺詐等領域中有著重要的研究價值,而且也將在未來人工智能的研究中充當重要一環。近年來國內外涌現出大量的知識推理方法,取得了一定成果,但仍有不同程度的問題亟待解決。面向知識圖譜的知識推理的發展經歷了從簡單的邏輯推理到表示學習推理,圖推理,再到神經網絡推理的過程。早期基于邏輯的推理方法嚴重依賴于推理規則,在小規模數據中,取得了較好的效果,但隨著數據規模的增加,有效的推理規則的獲取難度增大甚至無法獲取,這便導致其發展受限;受詞嵌入模型的啟發,基于表示學習的推理方法迅速發展,并取得了較好的結果,但該類方法將知識推理轉化為單一的向量計算,可解釋性較差,同時僅使用了關系信息進行了推理,推理能力受限。基于圖的推理方法,因其充分利用圖的結構信息,推理效率和質量得到明顯提升,更適用于大規模知識圖譜推理,然而,該類問題面臨的一個重要問題就是如何有效地搜索路徑。基于神經網絡的推理方法依靠神經網絡模型更強的學習能力和泛化能力,提升了推理的性能。但隨著人們對知識推理的可解釋性要求日益增加,知識推理的可解釋性受到了越來越多研究人員的關注。
本文對知識推理的概念、知識推理的方法、強化學習知識推理模型、公開數據集和評價指標等進行總結。具體而言,首先,按照面向知識圖譜的知識推理方法所依據的原理不同,將知識推理分為基于邏輯推理、基于表示學習推理、基于圖推理、基于神經網絡推理和基于深度強化學習推理五大類。由于基于深度強化學習的知識推理具備良好的性能和可解釋性,于是近年來該類推理方法迅速成為了研究的熱點。本文從面向封閉域的深度強化學習知識推理和面向開放域的深度強化學習知識推理兩個角度,對面向知識圖譜的基于深度強化學習的推理方法進行了詳細總結分析。此外,本文還對已有的公開數據集和評價指標進行總結。
分析近年來相關研究發現,基于強化學習知識推理方法研究還不夠完善。展望未來,存在以下四個發展方向。
(1)融合邏輯方法知識推理:增強推理的可解性和性能。基于邏輯的推理方法具有滿足當前知識推理高準確率和強可解釋性應用需求的特點,一直以來都是推理研究及應用的熱點,但該方法局限于規則獲取難和數據噪音抵抗差。相反,深度強化學習推理具有挖掘推理規則和增加容錯性的特點。因此,探索融合邏輯推理和深度強化學習推理方法成為了進一步增強推理可解釋性和性能的可行途徑。
(2)多智能體知識推理:解決更為復雜的推理任務。近幾年,多智能體強化學習因具備強大的學習能力、推理能力和自組織能力,已在許多領域都得到了實際應用。隨著知識圖譜規模的不斷增加,知識推理的復雜度也隨之增大。借鑒本文介紹的DIVINE模型,可以看到將多智能體強化學習引入到知識推理中,不僅能夠使用多個智能體相互協作解決復雜問題,而且還將進一步減少人工干預,提高推理性能。
(3)圖神經網絡知識推理:創新利用推理依據。知識圖譜內含信息豐富,既有語義信息,如實體名稱、關系名稱、實體描述、屬性信息,又包含大量的結構信息,如三元組、多元組、路徑等,這些與事實三元組緊密相關的信息都可以作為推理的依據。因此,可以嘗試使用圖神經網絡,在推理過程中充分利用實體、關系、路徑等多種信息,信息量更大,推理效果更好。
(4)開放域知識推理:探索更好的開放域知識推理方法。開放域知識推理能夠建立封閉世界知識圖譜與開放世界知識圖譜之間的通道,使得新的實體和關系以及新的知識能夠更便捷地添加到知識圖譜中,將其與知識推理結合能夠更好地應對開放域推理問題。因此,不妨嘗試借鑒CPL 模型的方法,探索通過結合開放域知識進行推理的新渠道。目前封閉域知識推理研究較為成熟,而面向開放域的知識推理研究仍存在較大空間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
