基于可拓神經網絡的排澇泵站主機組動力特性大數據修正方法
2022-01-24 02:46:52楊玉泉張仁貢
中國農村水利水電 2022年1期
關鍵詞:泵站
楊玉泉,張仁貢
(1.浙江同濟科技職業學院,杭州 311231;2.浙江禹貢信息科技有限公司,杭州 310009;3.浙江工業大學,杭州 310014)
0 引 言
為減少城市及工礦洪澇災害改善水環境,許多城市、礦山都建設了排澇泵站。隨著泵站綜合效益日益提高,泵站主機組常年在配水調度需求下運行。主機組是泵站運行安全的重要設備,成為泵站長期穩定運行關鍵要素。泵站經多年運行,受自然和人為因素作用(制造、安裝、運行管理等),泵站主機組設備常會出現振動、噪聲以及機組故障問題。一個泵站若有多臺機組,還涉及機組的優化組合、機組負載均衡以及機組損耗等問題[1]。上述問題的解決都涉及泵站主機組的動力特性研究。但是如何獲取精確的泵站主機組動力特性是一個世界性難題,主要原因有:①我國大部分水泵建設時未考慮安裝在線監測儀表,當泵站主機組安裝完成后,無環境條件再加裝在線監測儀表。②泵站主機組動力特性的主要參數中包含功率、揚程和流量,流量監測本身難度較大,尤其是流量的在線監測。③泵站主機組動力特性需要在不同揚程條件下的流量數值,其特性是一個曲面,但為了簡化問題的分析,一般依據實際情況選取多個典型揚程,功率從0 到額定功率的條件下,獲取流量數值,形成典型揚程下的動力特性方程。水工模型試驗是解決復雜水力學問題的有效手段,所得到的試驗結果真實可信。為此,需要做水泵主機組的真機試驗,泵站要在維修工況下安裝試驗儀器,成本高,測量時間長,對整個泵站的運行產生較大影響。綜上所述,尋找一種既可靠安全、又能夠較高精度獲取泵站主機組動力特性的方法具有較高的研究價值和較為廣闊的實用前景。
一般在泵站主機組制造時,先做泵機模型,再對該模型進行模擬試驗得到模型運轉綜合特性曲線,以指導泵站主機組的制造和安裝,并作為第一手廠家試驗資料提供給泵站主機組使用單位。從泵站主機組模型運轉綜合特性曲線獲得的泵站主機組動力特性在教科書上有一定的介紹,本文簡稱為泵站主機組模型動力特性,該動力特性精度很低,往往與真機動力特性存在很大差距。隨著自動化技術和物聯網技術的發展,泵站運行基本上都采用自動化,利用物聯網感知技術[2],將泵站主機組的運行數據存儲在云數據庫中,多年運行積累形成了大數據[3]。但如何利用運行存儲的大數據,來不斷修正泵站主機組模型動力特性,使之不斷自學習接近泵站主機組真機動力特性[4],目前,國內外尚沒有相關文獻刊載該研究。
為此,筆者依托國家自然基金項目“流程化工業生產過程中的不確定動態調度方法及其應用(60874074)”、浙江省教育廳科研項目“基于大數據的杭州七堡排澇泵站運行優化研究”(Y201942901)和浙江省水利廳課題“泵站機組異常振動和溫升研究——以七堡排澇泵站為例”(RC1981)的研究,通過泵站主機組模型運轉綜合特性曲線獲得泵站主機組模型動力特性,利用大數據技術,結合可拓神經網絡方法的動態修正和逼近,以獲取排澇泵站主機組真機動力特性,并將該方法編譯為計算機動態鏈接庫(DLL),開發了“七堡泵站大數據倉庫管理信息系統V1.0”(國家軟件著作權登記號:2018R11L1440166),為下一步開展泵站的主機組振動原因分析、機組優化組合以及負荷優化調度奠定基礎[5]。
1 關于模型動力特性方程
泵站主機組廠家提供給用戶單位的模型綜合運行特性曲線和獲得的主機組模型動力特性曲線如圖1 所示。功率流量(揚程)特性是主機組模型動力特性的主要特性,以下就以該動力特性為例進行研究。
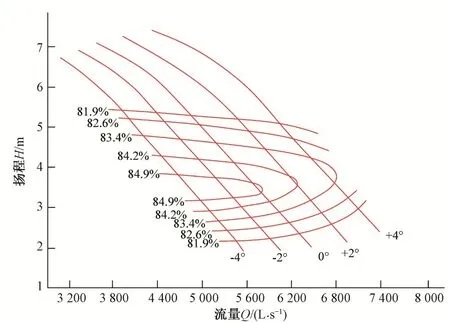
圖1 水泵運轉綜合特性曲線Fig.1 Operation synthesized characteristic curves of hydraulic turbine
教科書中已有將水泵運轉綜合特性曲線獲取功率流量(揚程)特性離散數據的步驟,本文不再累述。離散數據通過最小二乘法進行擬合為樣條三次曲線方程[6],在計算機語言求解中主要采用高斯函數和牛頓替代法[7],技術應用常見于文獻。所獲得的方程在界面中繪制,即為圖1。
2 三次指數矩陣數據處理方法
采用水泵運轉綜合特性曲線獲取的水泵主機組模型動力特性對于正在運行的真機而言,精確的是很不夠的。模型機經過放大制造、安裝和長期運行,變化比較大。特別是對于大流量等非標準水泵,需要定制生產。故水泵主機組模型動力特性尚不能用于指導水泵的運行[8]。為此,筆者通過計算機監控系統的歷史數據庫以及云端運行管理數據庫抽取實際數據,對水泵主機組模型動力特性方程進行修正,以提高動力特性精度。水泵主機組的揚程、功率、流量及效率的計算公式為:

式中:Qj為水泵主機的出口流量,m3∕s;Pj為水泵輸入功率,kW;Hj為揚程,m;ηj為水泵的運行效率;j為水泵主機組的編號。
假設在歷史數據庫或云端運行管理數據庫的大數據中抽取到一組數據,如某主機組的流量Qi和功率Pi,采用三次多項式擬合方程[9]表示為:
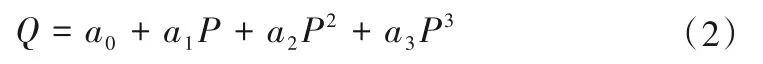
而依據模型動力特性方程獲得流量為:
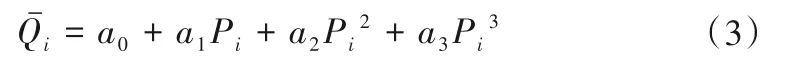
則它們的誤差為:
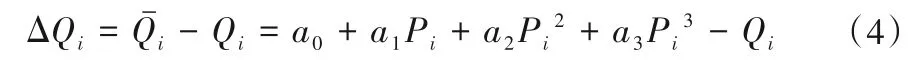
兩邊平方可得:
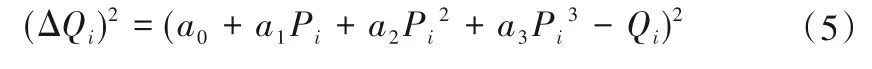
若有在歷史數據庫或云端運行管理數據庫的大數據中抽取到n組數據,其總誤差平方和為:
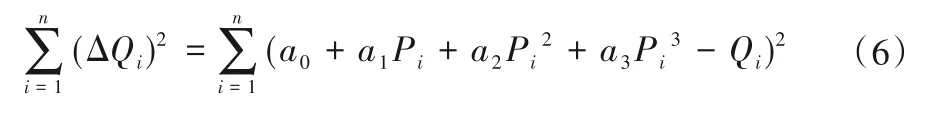
根據最小二乘法原理,當式(6)關于待定系數a0,a1,a2,a3的偏導數為零時,總的誤差平方和取到最小值。并采用指數矩陣表示可得:
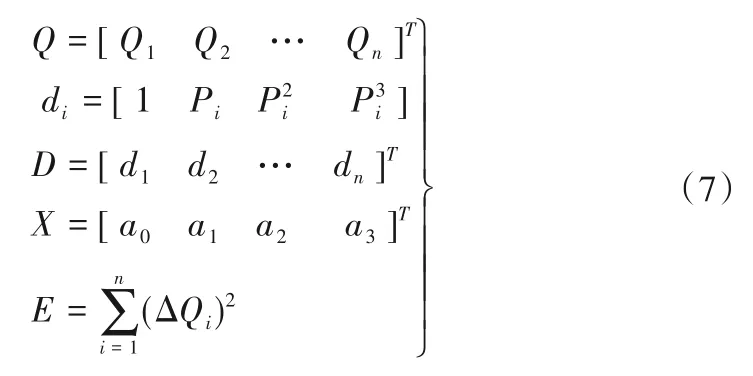
式中:Q為主機組的出口流量矩陣;di為主機組的功率矩陣;D表示功率轉置矩陣;E 為總誤差平方和;X 為系數矩陣。于是E 可表示為:
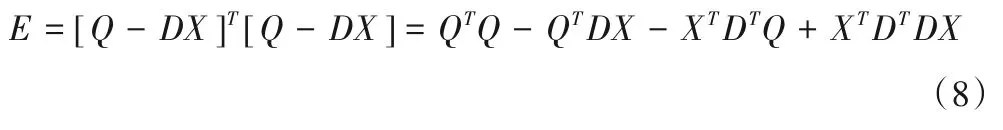

其中:

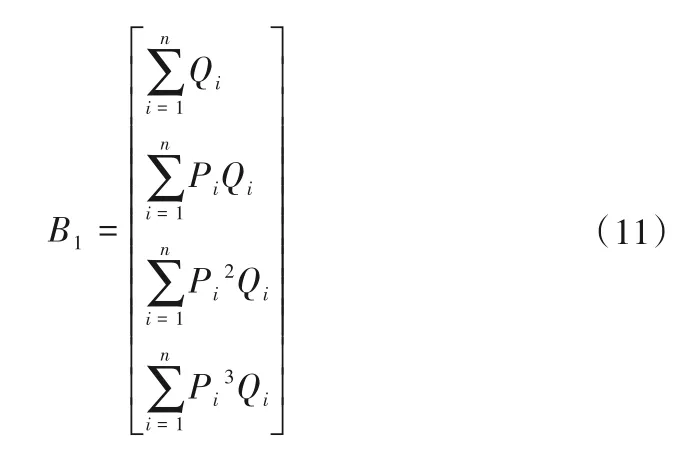
依據指數矩陣計算方法,原數據和新數據是一個疊加關系,對于大數據中抽取所得的一對流量數據Q和功率數據P,計算可得:
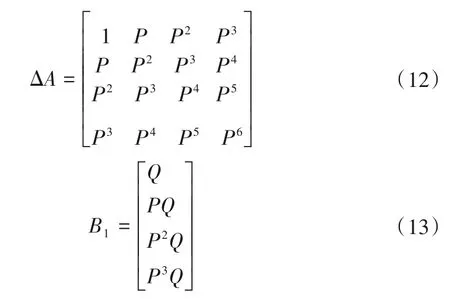
對于原數據引入衰減因子α(0 <α <1,可取α=0.95),并與新數據合并可得:

于是,對于大數據中抽取所得的新數據流量Q和功率P,通過以上方法重新擬合新的功率流量(揚程)動力特性方程。
由于泵站主機組的動力特性方程在不同揚程或上下游水位下,具有相同趨勢且不相交的特點(同趨不相交),研究表明所得曲線方程依據揚程的不同,具有線性等間距的特性(揚程等間距)[10]。由上述的三次指數矩陣數據處理方法可知,該方法是一種靜態的以點替代點從而帶動整個曲線進行修正的處理方法。該方法的缺點在于:①無法保證動力特性的“同趨不相交”和“揚程等間距”;②僅僅從歷史數據庫中抽取數據進行修正,無法從后續不斷運行的數據中抽取數據而進行動態連續修正,使之不斷逼近真機運行特性工況。為此,本文引入一種基于神經網絡的動態可拓訓練修正方法。
3 神經網絡可拓訓練方法
目前,隨著大數據、云計算、5G、人工智能等技術的發展,神經網絡(Artificial N euron Networks.ANN)[11,12]計算方法逐步得到流行,在使用該方法之前,需要將歷史數據庫云端化,并與云端運行管理數據合并為統一數據倉,本文稱之為泵站云數據倉[13]。如何清洗、合并、存儲、量化、歸一等多數據倉庫合并技術需要另外著文論述,本文不做介紹。神經網絡方法將模擬人的大腦和神經元,將泵站云數據倉分為多個神經元節點,利用信息傳輸系統實現并行分布式處理,具有將數據進行快速分析、存儲、計算、擬合和閉環循環,具有自學習和自適應能力,但神經網絡方法的缺點在于比較適應于初始值為零或隨機數據,對于抽取數據密集度過高,往往會陷入局部極值或死循環[14]。為此,筆者受到蔡文教授可拓理論(extension theory)[15]和趙燕偉教授的《可拓設計》[16]等啟發,引入了可拓理論中的元理論,有效地解決了神經網絡方法的上述缺點。
泵站云數據倉中將不斷產生新的數據,一旦數據觸發了規定的閥值,即可作為初始值輸入神經網絡系統進行計算,為了避免陷入局部極值或死循環,在定義閥值時引入可拓元理論,即計算舊數據與獲取的新數據的可拓距,當可拓距滿足條件時再進入神經網絡系統進行計算,可拓距可以變換為閥值使用[17]。本研究利用可拓物元模型確定初始權值,可拓距的計算采用下式:

式中:ED為可拓距;[wU,wL]為可拓物元區間;x為可拓區間外待測對象即泵站主機組(或具體的流量、功率、揚程等工況)。
ED 用來判別待測對象x和一個可拓物元區間[wU,wL]的可拓距。由于在泵站云數據倉中存在海量數據,同時存在多個分類或聚類數據,例如振動區間、氣蝕區域、磨損趨向等聚類,為了辨識多個分類或聚類數據并與神經網絡的并列分布計算方法相適應,采用一種雙向并列的鏈接結構[18],融入到神經網絡計算方法中,不妨稱該算法結構為可拓神經網絡雙向并列鏈接結構,圖2所示。
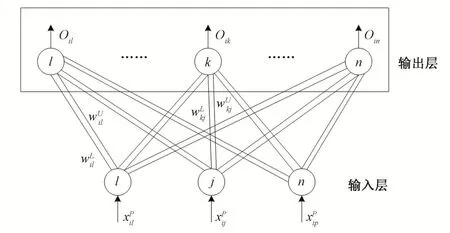
圖2 可拓神經網絡雙向鏈接拓撲結構Fig.2 Topological structure diagram of extension neural network with bidirectional links
由于采用泵站云數據倉的可拓距過濾式閥值數據采納方法,所用的神經網絡方法是一種具有自適應的非監督學習算法,而可拓神經網絡雙向并列鏈接結構有效改進了神經網絡的非監督學習算法,利用可拓距ED 度量聚類中心、符合目標的邊界數值和初始權值。
具體方法為:①當可拓距ED 度量通過時,獲取對應初始權值的樣本,作為第一個樣本,稱之為原始樣本。②在符合目標的邊界數值的條件下,采用神經網絡方法計算原始樣本,每次傳到至下一個神經元時,采用可拓距ED 度量聚類中心,避免陷入局部極值或死循環,直到獲得計算最優結果,作為第二個樣本。③第一個樣本和第二個樣本進行可拓距ED 度量,記錄比較后符合條件的樣本。④不斷并行和循環計算該過程,直到所有樣本數據計算完成,進入穩定的分類和聚類集合,更新替換原來數據樣本集合。若將可拓距ED 度量轉換為對應參數如流量、功率、揚程等數據閾值時,可以設置樣本特征的總個數。由于根據可拓距原理,當一個數據點落在可拓區間內時,則可拓距小于1。
因此,當泵站云數據倉獲取n個特征數據,對于xi={xx1,xx2,…,xxn},則當EDp=min{EDm}>n,則說明了xi不屬于聚類p,需要創建一個新的樣本聚類。如果EDp<n,則樣本xi屬于聚類p,對于聚類p 所對應的樣本需要進行調整或替換,主要動態修正樣本的權值和聚類中心點,如式(18)~(21)。

式中:Mp是為修正后聚類p的新樣本個數。
如果輸入第i 個新樣本的數據物元xi從原聚類O 變換到新聚類k,則修正后調整聚類O 所相對應的權值和聚類中心點,如式(22)~(25)所示。
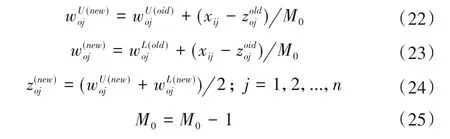
綜上所述,本研究所提出的神經網絡可拓訓練方法,將可拓元理論及計算方法融入到神經網絡非監督學習算法中,經過實驗比較可知,其訓練時間平均可提升50%,且容易獲取數據庫的數據或知識[19]。同時,優化了神經網絡算法,避免局部收斂,具有穩定性和可塑性等特點。值得注意的是,要保持神經網絡的良好優化計算效果,可拓距的選取非常重要,可拓距與閾值距離參數緊密關聯,這就使得閾值距離參數的選取至關重要,因此需要進行不斷試驗研究和較長時間的觀察積累,進行調整才能結合實際數據實時修正訓練的需要。
4 實例分析
杭州市某排澇泵站位于江干區和睦港出江口,主要承擔上塘河流域防洪排澇,兼顧上塘河流域的環境景觀配水。共布置7臺10 kV直接啟動的高壓潛水軸流泵,1~4號泵采用1400QZ-130 型,5~7 號泵采用1600QZB-125 型。由于制造、安裝或運行工況偏差(泵站受錢塘江潮位影響,其揚程變化頻繁,變化幅度大)等原因,5 號泵運行狀態不穩定,振動較大,噪音偏高,故障率較高,對整個泵站的安全和優化運行及調度產生較為明顯影響。因此本文取5 號泵為例進行研究,5 號泵設計流量12 m3∕s,設計揚程3.5~6.0 m,轉速295 r∕min,電機功率800 kW,葉輪直徑1.54 m,設計運行效率81.3%~84.3%。
依據5 號泵廠家提供的泵主機組模型運轉綜合特性曲線,獲取模型動力特性數據,然后采用最小二乘法進行擬合,擬合后的方程組如式(26),流量功率動力特性曲線如圖3(a)所示。
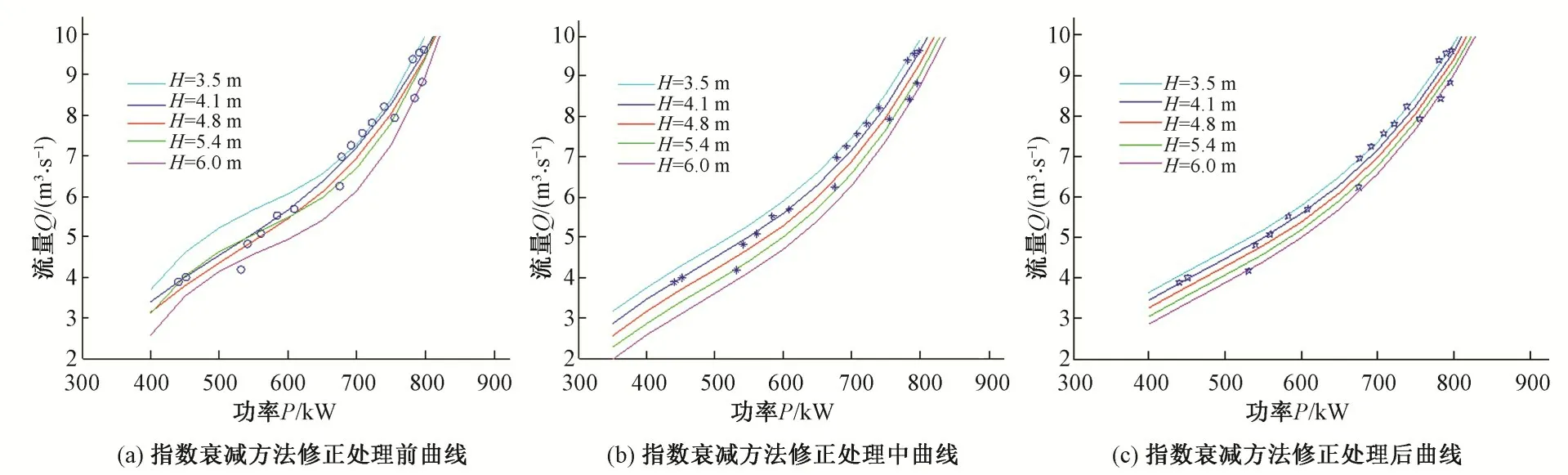
圖3 指數衰減方法修正處理前后曲線Fig.3 Before and after comparisons fixed by Exponential decay method

從圖3(a)可知,在設計揚程3.5~6.0 m 之間,除了3.5和6.0最小和最大揚程外,另取4.1、4.8、5.4 作為典型主機組揚程,從模型運轉綜合特性曲線獲取的離散數據擬合的流量功率動力特性曲線方程,繪制后可見其趨勢和間隔都不均勻,且各個典型揚程特性的曲線有明顯的相交現象,不符合實際要求,尤其是當揚程為H=3.5 m時,失真特別厲害。
從該泵站云數據倉由計算機監控系統歷史數據庫[20]和泵站標準化運行管理數據庫云化合并而成[21,22],從云數據倉中挖掘3.5、4.1、4.8、5.4、6.0 m 等典型泵機揚程的真機運行數據進行基于三次多項式指數矩陣處理方法的修正,取矩陣修正系數α=0.95,修正替代后重新最小二乘法三次多項式擬合后其特性方程如式(26),繪制的曲線如圖3(b)所示。從圖3(b)可知,修正后的方程其曲線有比較明顯的改變,但是3 個典型揚程下的特性曲線雖然不再交叉,但是依然存不等距現象,不符合泵站主機組流量功率動力特性“揚程等間距”的要求。這也是上文所提到的基于三次多項式指數矩陣處理方法的缺陷,因此需要采用可拓神經網絡方法進行進一步動態數據訓練和修正。

按照“同趨不相交”和“揚程等間距”的流量功率動力特性的要求,將3.5、4.1、4.8、5.4、6.0 m 揚程作為泵站數據倉觸發器[23],激發實時獲取后續運行樣本,采用可拓神經網絡方法進行動態訓練和修正,經過一年多時間的訓練運行,獲得各數據樣本98 個,符合可拓距的樣本62 個,選擇符合聚類可更新數據樣本54個進行列表,如表1所示。
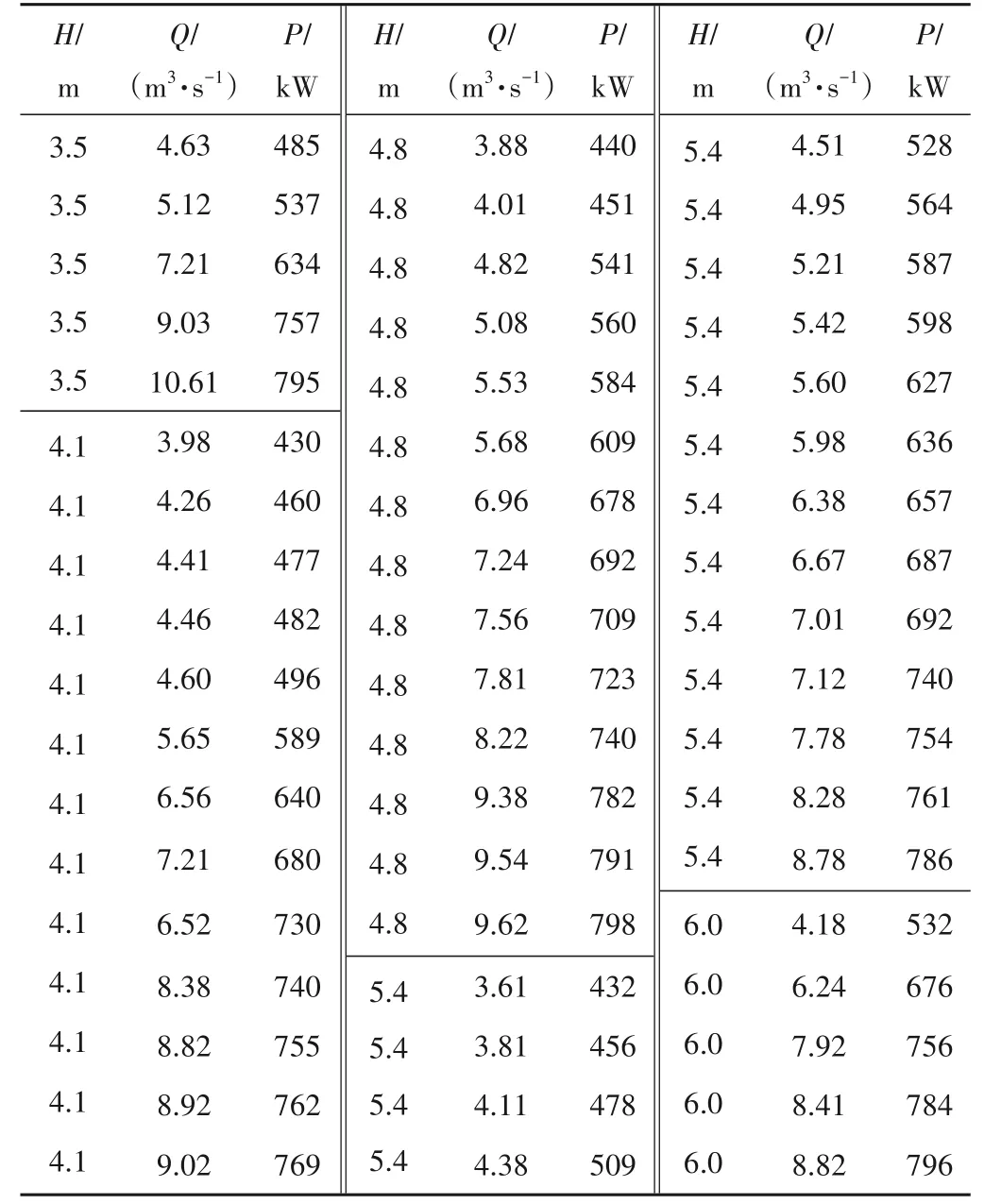
表1 各典型揚程下的流量功率聚類更新數據樣本Tab.1 Cluster updating data samples of traffic and power under each typical head
可拓距調整每月進行一次,最后經過12 次調整,可拓距閾值距離參數設置如下:{H ≡3.5}∈[0.02,0.26]、{H ≡4.1}∈[0.27,0.46]、 {H ≡4.8} ∈[0.47,0.65]、 {H ≡5.4}∈[0.66,0.86]、{H = 6.0}∈[0.87,0.98]。
經過54個數據樣本的可拓神經網絡實時訓練修訂后,重新擬合的方程如式(28),特性曲線如圖3(c)。

從圖3(c)可知,泵站主機組流量功率動力特性基本符合“同趨不相交”和“揚程等間距”的要求,符合實際情況。表1 中的數據樣本比較集中在中高功率段,且最低揚程和最高揚程兩個典型揚程的數據樣本偏少,這與實際運行的工況密集度有關。隨著時間的推移,樣本數量越來越多的情況下,特性曲線方程也必將越來越符合泵站主機組的實際運行工況,越來越能指導實際運行調度與決策[24,25]。
采用C++語言將可拓神經網絡方法編譯形成DLL動態鏈接庫文件,嵌入到七堡泵站大數據倉庫管理信息系統中,計算結果可以通過客戶端軟件泵站主機組動力特性分析系統進行展示,系統主界面如圖4。
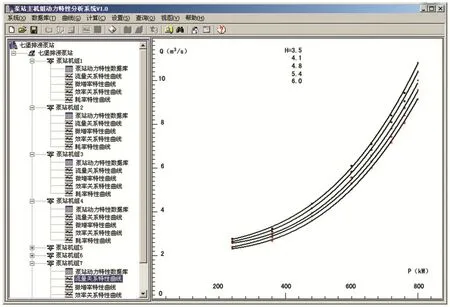
圖4 泵站主機組動力特性分析系統主界面Fig.4 Cluster updating data samples of traffic and power under each typical head
5 結 論
通過以上研究,得出如下結論:
(1)通過廠家提供的泵站主機組模型運轉綜合特性曲線獲取模型動力特性方程,再通過靜態和動態相結合的方法,逐步獲取泵站主機組真機動力特性方程的方法是可行有效的。
(2)三次指數矩陣數據處理方法可作為靜態的點數據處理,也是不可缺少的中間步驟,它可將真機歷史運行數據盡數挖掘修正的特性曲線方程中,使得曲線方程接近泵站主機組真機動力特性。
(3)神經網絡可拓訓練方法是一種在大數據技術基礎下創新的動態修正方法,是本文研究的核心方法,該方法將可拓理論融入到神經網絡方法中,揚長避短,解決了神經網絡在本案例優化計算中的局部收斂或死循環,在數據處理中發揮出較好的效果。
(4)應用實踐表明,神經網絡可拓訓練方法,具有自適應性、自主學習性和可拓性,在泵站主機組動力特性方程的動態修正應用中是有效而可靠的方法,修正結果滿足了“同趨不相交”和“揚程等間距”等特性要求。 □
猜你喜歡
水泵技術(2022年3期)2022-08-26 08:59:42
湖南水利水電(2021年6期)2022-01-18 06:07:40
黑龍江水利科技(2020年8期)2021-01-21 09:28:02
中華建設(2017年1期)2017-06-07 02:56:14
河南水利年鑒(2017年0期)2017-05-19 02:32:09
河南水利年鑒(2016年0期)2016-08-03 05:01:40
水利科技與經濟(2016年5期)2016-04-22 03:43:36
工程建設與設計(2016年1期)2016-02-27 10:50:17
河南水利年鑒(2015年0期)2015-08-16 04:25:49
水電站機電技術(2014年6期)2014-09-26 12:07:47
