人臉妝容遷移研究綜述
2022-01-25 18:53:58米愛中喬應旭許成敬霍占強
計算機工程與應用 2022年2期
米愛中,張 偉,喬應旭,許成敬,霍占強
1.河南理工大學 計算機科學與技術學院,河南 焦作 454003
2.河南能源化工集團有限公司 九里山礦,河南 焦作 454150
隨著社會的發展,人們越來越注重自己的外表形象,在面部美化技術中,化妝是一種通過化妝品來有效改善面部外觀的方法。據國家統計局數據顯示,2020年12月,全國化妝品零售額為324億元,同比增長9%;1~12月份全國化妝品零售額為3 400億元,同比增長9.5%。美妝產業推出眾多美妝產品,包括粉底、眼影、唇膏、腮紅、貼紙等。但是面對琳瑯滿目的美妝產品,人們無從選擇,更不知什么樣的妝容更適合自己。因此,虛擬試妝逐漸成為愛美人士備受青睞的一項技術,而人臉妝容遷移技術是虛擬試妝的核心。
人臉妝容遷移是一項具有挑戰的任務。首先它需要從帶有妝容的參考圖像中提取化妝品成分;其次還需要分析人臉面部結構,以便在未對齊的面部之間準確遷移妝容;最后人臉妝容遷移過程中有許多因素需要考慮,包括頭部姿勢、面部表情、光照和遮擋等。如圖1所示,人臉妝容遷移提供了一種高效的方式來實現虛擬試妝。其中,Sourcex指素顏圖像,Referencey指參考圖像,Result指妝容遷移后的結果。
由于人臉妝容遷移的研究在零售業和娛樂業有著非常重要的應用價值,越來越多的研究者試圖設計各種算法來解決人臉妝容遷移問題。特別是在過去的幾年里,隨著生成對抗網絡的出現,基于生成對抗網絡的模型在包括人臉妝容遷移的各種圖像生成任務中取得了壓倒性的優勢。
據作者所知,目前國內外還沒有公開發表的關于人臉妝容遷移的綜述性文章。本文重點對基于生成對抗網絡的人臉妝容遷移方法進行梳理、分析、總結和展望,主要貢獻可以歸納為以下三點:
(1)從關注問題、網絡架構、優缺點等方面對人臉妝容遷移領域的現有方法進行全面系統的梳理,有利于研究者系統了解基于生成對抗網絡的人臉妝容遷移算法的研究現狀及核心技術。
(2)對人臉妝容遷移方法常用的數據集、性能評價指標及損失函數進行總結,為未來研究人員設計更好的妝容遷移模型提供經驗。
(3)對人臉妝容遷移領域相關發展趨勢進行展望,為進一步研究基于生成對抗網絡的人臉妝容遷移技術提供可能的發展方向。
1 人臉妝容遷移方法概覽
人臉妝容遷移的各種方法主要分為三類:傳統方法、卷積神經網絡方法以及生成對抗網絡(generative adversarial networks,GAN)方法。
基于傳統方法的妝容遷移:Tong等[1]通過計算化妝前后色彩與光照變化,調整素顏圖像和妝容圖像的皮膚紋理和膚色差異,將妝容遷移到素顏圖像上。該方法對化妝前后圖片對要求較高,實用性較低。Guo等[2]提出類似于物理化妝的人臉妝容遷移方法,其核心是先將源圖像和參考圖像分為三個圖層:面部結構層、皮膚細節層和顏色層,再將參考圖像的妝容信息通過每個圖層遷移到源圖像。該方法遷移過程較為復雜,處理速度較慢,耗費時間較長。Scherbaum等[3]使用人臉的三維形變模型[4]建立素顏到化妝的映射,該方法需要收集同一個人妝前妝后的成對圖片。Li等[5]將圖像分解成多個固有圖層,根據基于物理的反射模型,通過操作圖層來模擬化妝,最終實現面部化妝。該方法根據化妝品屬性直接對圖層進行操作,不要求數據集中的樣本妝前妝后人臉對齊。但由于該方法很大程度上依賴固有圖層分解的精確性,因此分解誤差會降低遷移結果的質量,另外,其處理速度也有待提高。
基于卷積神經網絡的妝容遷移方法:隨著深度學習的不斷發展以及傳統人臉妝容遷移方法的局限性,一些學者對基于卷積神經網絡的妝容遷移進行了研究。Liu等[6]提出一種深度局部妝容遷移網絡,具體流程為:首先從已上妝人臉數據庫中挑選與當前素顏人臉最相近的圖片;然后采用全卷積圖像分割網絡進行人臉分割,提取五官區域;最后是完成對粉底(對應面部)、唇彩(對應雙唇)、眼影(對應雙眼)的妝容遷移。該方法雖然可以控制妝容濃度,但整體效果不夠自然。Wang等[7]提出了一種自動化妝檢測器和卸妝框架,對于化妝品檢測,其采用局部約束字典學習算法來定位化妝品的使用情況,并使用一種基于局部約束的耦合字典學習(LC-CDL)框架來實現卸妝。王偉光等[8]提出一種基于卷積神經網絡的新方法,首先對源圖像和參考圖像的特征信息進行定位和提取,通過妝容遷移網絡和損失函數實現妝容的自動遷移。黃妍等[9]提出一種多通路的分區域快速妝容遷移網絡模型,通過人臉關鍵點檢測完成端到端的人臉校準,利用通路差異的損失函數根據不同面部區域的妝容特點優化網絡,最后通過泊松融合及多通路的輸出生成遷移結果。
基于生成對抗網絡的妝容遷移方法:傳統方法和基于卷積神經網絡的方法雖能夠實現人臉妝容遷移的效果,但是幾乎所有方法都將妝容風格視為不同組件的簡單組合,這導致整體輸出圖像看起來不自然,遷移效果整體較差。近年來,生成對抗網絡技術[10]不斷發展,由于其能夠產生視覺上逼真的圖像的能力而被廣泛用于計算機視覺任務[11-14]。相比于傳統和基于卷積神經網絡的人臉妝容遷移方法,基于生成對抗網絡的人臉妝容遷移方法可以顯著提升遷移效果,已經成為當前人臉妝容遷移領域的研究熱點。
圖2按時間順序展示了近幾年基于生成對抗網絡的代表性工作。根據重點解決的問題不同,基于生成對抗網絡的人臉妝容遷移研究可以分為五類:第一類受CycleGAN[15]啟發,在循環生成對抗網絡上訓練的面向上妝和卸妝的妝容遷移網絡,如BeautyGAN[16]、Paired-CycleGAN[17]、LADN[18];第二類是面向遷移魯棒性的人臉妝容遷移網絡,如PSGAN[19]、FAT[20]、PSGAN++[21];第三類是基于3D人臉模型的人臉妝容遷移網絡,如CPM[22];第四類是基于弱監督的人臉妝容遷移網絡,如CA-GAN[23];第五類是除以上四類之外的其他解決人臉妝容遷移問題的方法,如DMT[24]。
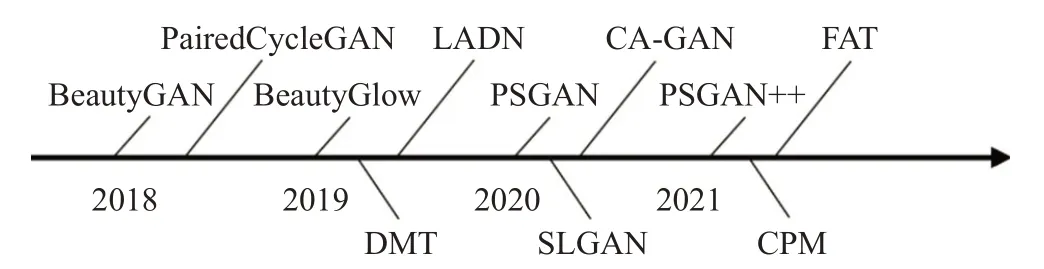
圖2 近年來人臉妝容遷移領域的代表性工作Fig.2 Chronological overview of recent representative work in facial makeup transfer
2 生成對抗網絡方法
表1從基礎網絡、模型、年份、優點、局限性和適用場景六個方面對2018年到2021年基于對抗生成網絡的代表性人臉妝容遷移方法進行了歸納總結。下面將詳細介紹面向上妝和卸妝的妝容遷移方法、面向魯棒性的妝容遷移方法、基于3D人臉模型的妝容遷移方法、基于弱監督的妝容遷移方法、其他妝容遷移方法等五類方法。

表1 基于GAN的人臉妝容遷移模型對比Table 1 Comparison of facial makeup transfer models based on GAN
2.1 面向上妝和卸妝的妝容遷移方法
面向上妝和卸妝的妝容遷移方法是指一個妝容遷移網絡同時訓練兩個映射,一個用于上妝,一個用于卸妝。代表工作主要有BeautyGAN[16]、PairedCycleGAN[17]、LADN[18]和SLGAN[25],典型網絡架構如圖3所示。
BeautyGAN:由于妝容風格是由幾種局部化妝品組成,現有風格遷移方法無法實現提取并遷移局部的精致的妝容信息。針對該問題,Li等[16]提出一個雙輸入/輸出生成對抗網絡框架——BeautyGAN,將全局域級損失和局部實例級損失合并在同一網絡中,在統一的框架下實現妝容遷移,該模型的網絡框架圖如圖3(a)所示。為了保持面部特征和消除偽影,作者在總目標函數中加入了感知損失和循環一致性損失,具體公式見3.2和3.3節。在域級遷移的基礎上,采用基于不同面部區域計算的像素級直方圖損失來實現實例級遷移,對比實驗證明了直方圖損失對實例化妝品遷移是有益的。BeautyGAN作為最早使用GAN進行妝容遷移的方法,從人類視覺感角度,相比于傳統方法,遷移效果獲得顯著的提升。但BeautyGAN只在正臉圖像上有較好的遷移效果,魯棒性相對較差,不能對妝容遷移結果進行編輯。
PairedCycleGAN:受到CycleGAN的啟發,Chang等[17]提出了面向上妝和卸妝的PairedCycleGAN模型。該模型使用無監督學習方法解決妝容遷移問題,不要求妝前妝后成對的訓練數據。該模型中引入兩個不對稱函數G和F,其中G負責遷移妝容風格,F負責卸妝,該模型的網絡框架圖如圖3(b)所示。由圖3(b)可知,給定一張素顏圖片和一張化妝圖片,該模型同時學習一個妝容遷移函數G和一個卸妝函數F。為了實現遷移特定化妝風格的同時保持源圖像的身份一致性,作者提出身份損失和風格損失,具體損失函數見3.5節的公式(6)~(8)。相比于之前的工作,該模型生成圖像的速度更快,源圖像的身份特征信息保持得更好,但在遷移適用性、魯棒性和可編輯方面存在和BeautyGAN相同的局限性。

圖3 面向上妝和卸妝的妝容遷移方法框架圖Fig.3 Framework diagram of makeup transfer methods for makeup and makeup removal
LADN:針對生成對抗網絡不能在全局對抗中傳遞高頻細節,只適用于簡單風格的問題,Gu等[18]提出一種局部對抗分離網絡(LADN)。其核心思想是在一個內容-風格分離網絡中,使用多個重疊的局部對抗鑒別器,實現面部圖像之間的局部細節遷移。局部對抗鑒別器可以在無監督的環境下進行跨圖像風格遷移時,更好地區分生成的局部圖像細節是否與給定參考圖像中的相應區域一致。跟之前的方法相比,LADN是第一個實現極端和戲劇性妝容風格上妝和卸妝的。為了處理極端妝容風格包含的高頻成分,LADN引入非對稱損失函數,具體損失函數見3.5節的公式(9)、(10)。LADN在上妝和卸妝效果上較之前的方法有了進一步的提高,但在對極端妝容風格進行卸妝時,存在局部顏色一致而整個面部顏色存在差異的問題。
SLGAN:Horita等[25]提出一個風格編碼(style code)和潛在編碼(latent code)聯合引導的生成對抗網絡模型——SLGAN,這是第一個將風格編碼和潛在編碼引導框架應用于妝容遷移和卸妝的方法。該框架由生成器G、風格編碼器SE、映射網絡MN和判別器D組成,如圖3(c)所示。生成器包括共享編碼器Enc、風格引導解碼器Gs和風格不變解碼器Gi。判別器D為多任務判別器,與風格編碼器SE架構相同。SLGAN提出了一個感知化妝損失和風格不變的解碼器,前者可以根據直方圖匹配遷移化妝風格,后者可以通過計算解碼器輸出和風格引導編碼器之間的歐式距離以避免身份遷移。此外,SLGAN還使用自適應實例歸一化(AdaIN)來調整生成器參數,能夠執行插值妝容遷移。定性和定量實驗表明,SLGAN的妝容遷移和卸妝效果相比于之前的方法有一定的提升,局限性在于SLGAN不適用于極端妝容風格遷移。
2.2 面向魯棒性的妝容遷移方法
面向魯棒性的妝容遷移方法是指在面部表情和姿態具有差異的條件下,妝容遷移網絡仍能獲得滿意的遷移效果。代表工作主要有PSGAN[19]、FAT[20]和PSGAN++[21],其網絡架構如圖4所示。

圖4 面向魯棒性的妝容遷移方法框架圖Fig.4 Framework diagram of robustness oriented makeup transfer methods
PSGAN:針對在源圖像和參考圖像存在表情和姿態差異的情況下遷移效果較差和不能實現可控的妝容色彩遷移以及特定部位遷移的問題,Jiang等[19]提出了姿態和表情魯棒的空間感知生成對抗網絡,如圖4(a)所示。該網絡主要包括三個模塊:妝容蒸餾網絡(MDNet)、注意力妝容形變模塊(AMM)、妝容應用網絡(MANet)。PSGAN使用注意力妝容形變模塊來處理不同頭部姿態和面部表情之間的轉換以實現魯棒性的妝容遷移,但當參考圖像存在遮擋和陰影時,遷移魯棒性較差,且該方法也不能實現卸妝。
FAT:受Transformer[33]中的自注意力機制的啟發,Wan等[20]設計了一個面部屬性變換器(FAT)對源圖像和參考圖像之間的語義對應和交互進行建模,進而精確地估計和遷移人臉屬性,其網絡框架圖如圖4(b)所示。此外,為了方便面部形狀變形和變換,作者將薄板樣條函數(TPS)集成到FAT中,創建了空間FAT。通過FAT和空間FAT可以實現高質量的妝容遷移,空間FAT是結合顏色遷移和形狀變換的妝容遷移方法,這也是第一個除了顏色和紋理之外,還可以遷移幾何屬性的方法。值得注意的是,該方法不僅適用于人臉妝容屬性遷移,也適用于其他人臉屬性遷移,比如人臉年齡屬性,局限性在于不能實現卸妝和妝容編輯。
PSGAN++:Liu等[21]在PSGAN的基礎上,解決了妝容遷移中的上妝和卸妝問題,其網絡框架如圖4(c)所示。該網絡框架主要包含四個模塊:妝容蒸餾網絡(MDNet)、注意力妝容形變模塊(AMM)、風格遷移網絡(STNet)以及身份蒸餾網絡(IDNet)。相比于之前的妝容遷移方法,PSGAN++是一種多功能的方法,能夠實現姿勢/表情魯棒、部分妝容遷移、妝容程度可控、細節保存遷移以及卸妝等多個功能。無論是定性還是定量實驗結果,都表明該方法在遷移效果上有進一步的提升。但與PSGAN相同的是,當參考圖像存在遮擋和陰影問題時,遷移效果會受到影響。
2.3 基于3D人臉模型的妝容遷移方法
基于3D人臉模型的妝容遷移方法是指通過對源圖像和參考圖像擬合一個三維人臉模型來分解圖像的形狀和紋理以實現妝容遷移的方法。代表工作主要有CPM[22]和SOGAN[26],其網絡架構如圖5所示。
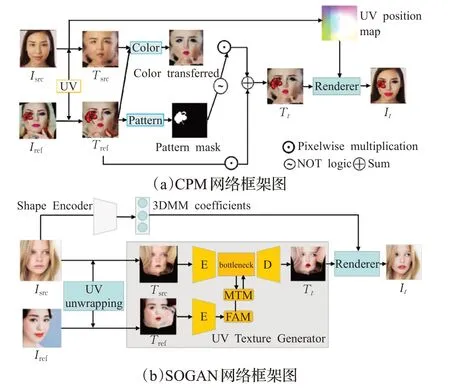
圖5 基于3D人臉模型的妝容遷移方法框架圖Fig.5 Framework diagram of makeup transfer methods based on 3D facial model
CPM:Nguyen等[22]于2021年提出一個不僅可以遷移妝容顏色,還可以實現圖案遷移的整體妝容遷移框架。該框架包括兩個分支:顏色遷移分支和圖案遷移分支,分別處理妝容顏色和妝容圖案的遷移,兩個分支可以獨立地并行運行,如圖5(a)所示。為了減少源圖像和參考圖像在形狀、頭部姿勢和表情之間的差異,顏色遷移分支和圖案遷移分支在訓練時都使用了UV空間中的扭曲面。受3D人臉模型的啟發,作者借鑒PRNet[34]的思想,使用UV轉換函數提取面部圖像的UV位置圖和UV紋理圖,并將紋理圖分別送入兩個分支在UV空間實現妝容變換,兩個分支的輸出融合為最終的紋理圖,使用渲染函數UV-1將其轉換為標準圖像表示。實驗結果表明,無論是圖案遷移還是顏色遷移,CPM的遷移效果都領先于當前的方法,但不足之處是CPM不能實現卸妝。
SOGAN:目前的妝容遷移方法雖然在較大的姿勢和表情變化時也有不錯的遷移效果,但當參考圖像上存在遮擋和陰影時,就會錯誤地遷移陰影,導致輸出圖像出現重影偽影,這使得輸出圖像的相應位置缺少妝容細節。為此,Lyu等[26]提出一種新的妝容遷移方法——SOGAN(3D-aware shadow and occlusion robust GAN),其網絡框架如圖5(b)所示。該方法只在UV紋理空間中遷移化妝,利用人臉在UV空間的對稱性,提出翻轉注意模塊(FAM)和妝容遷移模塊(MTM)來減輕陰影和遮擋的影響,以實現更精確的妝容遷移。但其局限性在于該方法不適用于極端妝容風格遷移,且不能實現卸妝功能。
2.4 基于弱監督的妝容遷移方法
基于弱監督的妝容遷移方法是指在妝容遷移過程中采用弱監督方式訓練遷移網絡的方法。代表工作主要有CA-GAN[23]和MakeupBag[27],MakeupBag[27]的網絡架構如圖6所示。
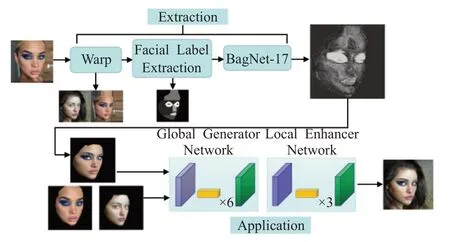
圖6 MakeupBag網絡框架圖Fig.6 Framework diagram of MakeupBag
CA-GAN:Robin等[23]為人臉妝容遷移提出一個新的目標,即學習一種顏色可控的妝容風格合成。CA-GAN是一種顏色感知的條件GAN,可以將圖像中特定對象的顏色修改為任意的目標顏色。CA-GAN引入了一個生成模型,它可以將圖像中的特定對象(如嘴唇或眼睛)的顏色修改為任意目標顏色,且保留背景。由于顏色標簽很少,并且獲取成本較高,該方法使用的是弱監督條件生成對抗網絡,這能夠更好地學習可控合成。雖然該模型可以實現對多種化妝品的顏色控制,但人臉妝容的空間信息卻沒有被考慮。
MakeupBag:Hoshen[27]提出MakeupBag,將妝容遷移過程分為兩個階段,(1)妝容提取;(2)妝容應用,其網絡框架如圖6所示。MakeupBag將妝容提取視為一項弱監督的妝容分割任務,該模塊的輸出是一個妝容分割掩膜(Mask),用于創建妝容遷移后的目標圖像的估計圖像。在妝容應用階段,生成器由全局生成器和局部增強器組成,將源圖像和參考圖像以及分割圖作為輸入,輸出一個妝容遷移后的真實圖像,以實現在任意人臉上應用妝容風格。相比于之前的方法,MakeupBag不僅允許編輯化妝風格,還可以實現更高分辨率和更高質量的妝容遷移,其局限性為該方法也不能實現卸妝和妝容編輯。
2.5 其他妝容遷移方法
DMT:Zhang等[24]提出了DMT(disentangled makeup transfer),實現了不同場景下妝容遷移的模型。該模型能夠處理不同的化妝遷移場景,包括成對遷移、插值遷移、混合遷移和多模態遷移,這些都是相關研究無法實現的。DMT是第一個借助解耦表征(disentangled representation)來解決妝容遷移的模型,相比之前的方法,模型在遷移效果上有進一步的提高,其局限性為不適用于極端妝容遷移且不支持卸妝。
BeautyGlow:Chen等[29]提出一種無監督的按需妝容遷移方法——BeautyGlow,該方法是第一個基于Glow[35]的妝容遷移框架。BeautyGlow不需要訓練生成器和鑒別器,使得它更加穩定。該方法不適用于極端妝容遷移且魯棒性較差。
Eye Makeup Transfer:Zhu等[28]提出了一種自動編碼器結構,使用合成的成對數據和非成對數據進行眼妝遷移。同時,基于妝容表征,該框架通過簡單地調整妝容權重來控制化妝程度,但該方法只適用于眼妝遷移。
IPM-Net:Huang等[30]提出一個新的身份保持化妝模型IPM-Net,該模型將人臉圖像分解成兩種不同的信息編碼——身份內容編碼和妝容風格編碼,只需改變妝容風格編碼就可以生成目標人物的各種妝容圖像。該模型既可以保持源圖像的背景信息,也可以保持原始身份信息。在遷移效果評定標準方面,IPM-Net采用FID[36]和LPIPS[37]用于妝容真實性和多樣性評價。該方法不適用于極端妝容遷移和不支持卸妝。
自動上妝模型:包仁達等[31]提出一種掩碼控制的自動上妝生成對抗網絡,通過利用掩碼,能夠重點編輯上妝區域且約束無需化妝的區域不變,保持源圖像主體信息。同時可對人臉的眼睛、嘴唇和膚色單獨編輯妝容,實現特定區域上妝,豐富了上妝功能,但該方法也不適用于極端妝容遷移且魯棒性有待提高。
SCGAN:Deng等[32]提出了一種全自動的妝容遷移模型,通過編輯樣式編碼,即可實現帶有陰影控制的全局/局部妝容遷移。該模型由目標風格碼編碼、人臉身份特征提取和妝容融合三部分組成。參考圖像被分解成三部分——眼睛、皮膚、嘴,特定的風格編碼器提取每部分的特征,并將這些特征映射到一個解耦風格潛在空間W,人臉身份特征編碼器從源圖像中提取人臉身份特征,妝容融合解碼器將風格碼ω與人臉身份特征融合生成最終遷移結果。該方法靈活且準確,但無法遷移面部區域的局部圖案。
2.6 小結
面向上妝和卸妝的妝容遷移方法需要同時訓練兩個子網絡,一個用于上妝,一個用于卸妝。關鍵在于網絡架構和損失函數的設計,既要考慮全局域級損失又要考慮局部實例級損失。總的發展趨勢是從監督學習向無監督、半監督和自監督方向發展,由簡單妝容遷移向支持極端妝容遷移發展。
面向魯棒性的妝容遷移方法重點關注妝容遷移的魯棒性問題,提升遷移前后面部表情和姿態存在差異時的遷移效果。目前仍然存在的問題是當參考圖像存在遮擋和陰影問題時,遷移效果不能滿足市場需求,有待進一步提高。
基于3D人臉模型的妝容遷移方法可能是人臉妝容遷移網絡發展的主流。用三維人臉模型分解圖像的形狀和紋理來實現妝容遷移有著天然的優勢。選擇更合適的三維人臉模型,設計更合理的網絡模型和損失函數,同時提高模型的魯棒性,較好地解決遮擋和陰影問題,可能是人臉妝容遷移繼續發展的趨勢。
基于弱監督的妝容遷移方法主要解決特定問題時標注數據少,并且獲取成本較高的問題。使用有限的、含有噪聲的或者標注不準確的數據來進行模型參數的訓練,也是一種解決數據標注的可行方法。
3 常用損失函數
在人臉妝容遷移任務中,損失函數是影響遷移效果的關鍵因素之一。常用的人臉妝容遷移損失函數主要包括對抗損失、循環一致性損失、感知損失、妝容損失等。在本章中,用A和B分別表示源圖像域和參考圖像域,Isrc指源圖像,Iref指參考圖像,指妝容遷移圖像,指卸妝后圖像,和指源圖像和參考圖像的重構圖像。
3.1 對抗損失
對抗損失是基于生成對抗網絡人臉妝容遷移網絡的基本損失函數,其原理為通過生成器和判別器的不斷博弈,使生成器生成的圖像更加真實,使判別器不斷提高對來自不同域的圖片的判別能力。對抗損失計算公式為:
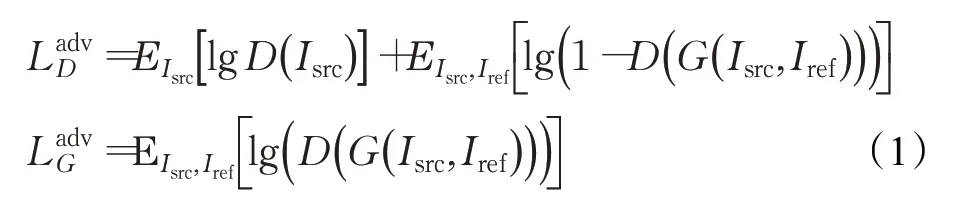
其中,E(*)代表分布期望,G代表生成器,D代表判別器。
3.2 循環一致性損失
由于缺少足夠的三元組數據(源圖像、參考圖像及遷移圖像),大多數妝容遷移方法以無監督方式訓練網絡。引入循環一致性損失可以約束重建圖像,循環一致性損失函數的定義為:
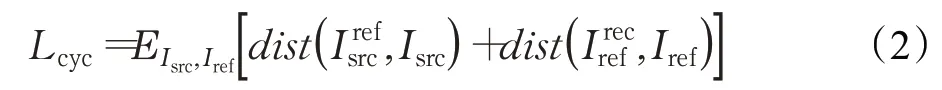
3.3 感知損失
感知損失函數可以在遷移妝容風格時保持源圖像的個人身份信息,感知損失不是直接計算像素級歐氏距離之間的差異,而是計算深度卷積網絡提取的高級特征之間的差異,該網絡一般使用在ImageNet上預訓練的VGG-16模型。感知損失計算公式為:
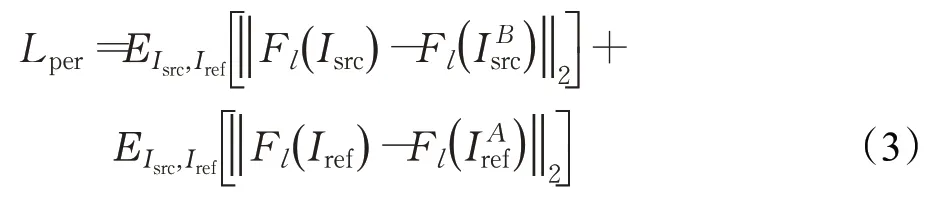
3.4 妝容損失
妝容損失包含嘴唇、眼睛和面部的三個局部顏色直方圖損失。在生成圖像和參考圖像Iref的相同面部區域分別執行直方圖匹配得到一個重新映射圖像,其約束生成圖像和參考圖像在Mitem的位置具有相似的化妝風格。Mitem是通過人臉解析模型獲得的局部區域,item∈{l ips,eye,face}。局部直方圖損失計算公式為:
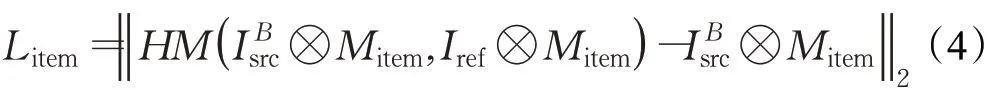
總妝容損失計算公式:
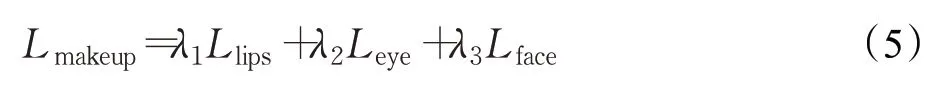
其中,λ1、λ2、λ3為權重參數,一般設為λ1=1,λ2=1,λ3=0.1。
3.5 其他損失
除了以上四種損失函數外,不同的妝容遷移方法還根據網絡訓練的不同目標提出了一些特有的損失函數,包括PairedCycleGAN[17]提出的身份損失、風格損失,LADN[18]提出的高階損失、光滑損失,PSGAN++[21]提出的妝容細節損失等。
(1)身份損失
身份損失類似于循環一致性損失,其目的是在妝容遷移過程中保持源圖像的身份信息,利用L1損失減小源圖像的重構圖像和源圖像之間的差異,其公式為:
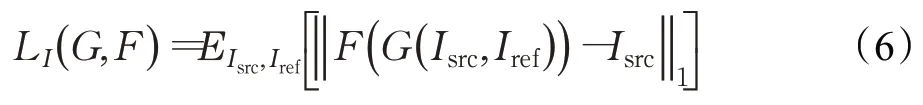
其中,G負責妝容遷移,F負責卸妝,E(*)代表分布期望。
(2)風格損失
PairedCycleGAN[17]除了身份損失,還提出了兩種風格損失——L1重建損失LS和風格判別器損失LP。風格損失是為了確保特定化妝風格細節的成功遷移。首先LS是為了保證參考圖像的重構圖像和參考圖像越接近越好,如公式(7)所示。然而在像素域使用L1損失雖有助于一般結構和顏色(例如眉毛的形狀和眼影)的遷移,但不能遷移睫毛和眼線這些邊緣區域。針對這一問題,作者增加了一個輔助判別器DS來判斷給定的一對面部圖像是否妝容相同。由于缺乏真實妝容圖像對,作者根據通過扭曲Iref來匹配Isrc中檢測到的面部特征點(Landmarks)生成一個合成Ground-truth——W(Isrc,Iref)。輔助判別器DS的損失函數如公式(8)。
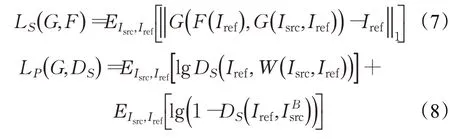
其中,G負責妝容遷移,F負責卸妝,E(*)代表分布期望。
(3)高階損失
為處理極端妝容包含的高頻成分,LADN[18]在妝容遷移分支中增加了高階損失Lho。受PairedcycleGAN[17]的啟發,作者也生成一個合成groundtr uth——W(Isrc,Iref),其保留了參考圖像妝容風格的大部分紋理信息。通過對W(Isrc,Iref)和Iref的局部塊(local patches)應用拉普拉斯濾波器計算高階損失,其計算公式為:
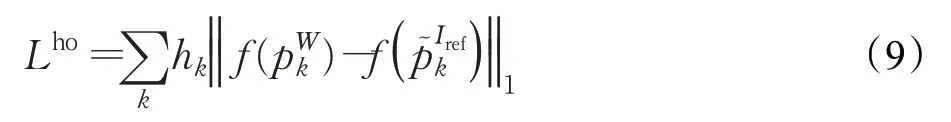
(4)平滑損失
在一些極端妝容卸妝的過程中,很難從化妝后的圖像中觀察到人的原始面部顏色。因此LADN[18]基于化妝后的面部顏色通常是平滑的這一假設在卸妝分支中加入了平滑損失Lsmooth,其計算公式為:

(5)妝容細節損失
妝容損失提供了面部區域級別的約束,但這樣的損失很難遷移包括高光和腮紅在內的化妝細節。因此,PSGAN++[21]提出一個妝容細節損失。首先使用密集面部對齊方法來檢測源圖像和參考圖像的密集面部特征點。然后選擇位于化妝細節區域(鼻子、臉頰)的K個特征點構成妝容細節標志。妝容細節損失是計算I Bsrc和Iref之間相應妝容細節特征點之間的差,其公式為:
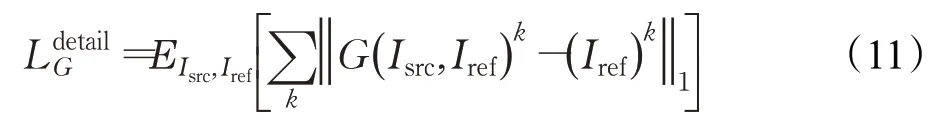
其中,E(*)代表分布期望,G表示生成器,k表示第k個特征點。
4 數據集與評價指標
4.1 數據集
隨著人臉妝容遷移算法的不斷發展,該領域數據集越來越豐富且更具針對性,圖像的質量和數量不斷提高。表2從數據集名稱、時間、主題數量、每個主題包含圖像張數、是否有妝前妝后圖像和圖像總數六方面列舉了2012年至2021年提出的有關人臉妝容數據集。

表2 人臉妝容數據集Table 2 Facial makeup dataset
YMU(YouTube makeup)于2012年提出,它主要是來自YouTube視頻化妝教程,共收集了151個主題,特別是白人女性。通過拍攝人臉化妝前后的照片,每張人臉對應四張圖像:化妝前兩張圖像和化妝后兩張圖像,該數據集共有604張圖片。這些面部圖像中的妝容從細微到濃重不等。同時該數據集包含了表情和姿勢的一些變化,在同一個對象的多張照片上,照明條件相對固定。
VMU(virtual makeup)于2012年提出,它是使用Taaz的公開工具修改了FRGC(face recognition grand challenge)數據集中的51名白人女性的面部圖像以模擬化妝而形成的。其主要創造了三個虛擬妝容:(1)僅使用口紅;(2)僅使用眼妝;(3)整個面部化妝,包括唇膏、粉底、腮紅和眼妝。因此,該數據集包含每個主題的4個圖像,1張妝前圖像,3張妝后圖像,共有204張圖片。
MIW(makeup in the“wild”)于2013年提出,數據集中化妝和素顏的面部圖像是從互聯網上獲取的,其面部是不受約束的,不包含人臉圖像的妝前妝后的成對圖像。該數據集包含154張圖片,其中化妝圖像77張,素顏圖像77張。
MIFS(makeup induced face spoofing)于2017年提出,該數據集是為了研究化妝引起的人臉欺騙問題而提出的,共包含107個化妝變換前后對象,這些變換都來自隨機的YouTube化妝教程視頻。每個對象有兩對化妝前后的圖像和兩個目標圖像。
MT(makeup transfer)于2018年提出,是目前大多數人臉妝容遷移研究采用的數據集。該數據集包括3 834張女性圖片,其中包含1 115張素顏圖像,2 719張化妝圖像,包括亞洲人、歐美人等,在姿勢、表情、背景等方面都有不同。素顏圖像均為裸妝,化妝圖像包含了許多化妝風格,比如煙熏妝、復古妝、韓國化妝風格以及日本化妝風格等。與之前的化妝數據集相比,MT是最大的數據集。該數據集示例樣本如圖7(上)所示,第一行為素顏圖像,第二行為化妝圖像。
LADN Makeup于2019年提出,其構造過程如下:首先從互聯網上收集沒有遮擋的高質量人臉圖像,通過面部特征點檢測器過濾掉沒有正面人臉的圖像;然后根據是否有化妝對其中一小部分圖像進行標記,從中提取眼影和嘴唇區域的色調直方圖,進而訓練一個簡單的多層感知機分類器;最后利用分類器對剩余圖像進行標注,最終得到333張素顏圖像和302張化妝圖像。同時,為了實現極端妝容遷移,該數據集還增加了115張化妝色彩、風格、區域覆蓋差異較大的極端妝容圖像。
FCC Dataset于2019年提出,它共有18 425張包含濃妝、淡妝以及不化妝的面部圖像,數據集有低分辨率(256×256)和高分辨率(512×512)子集,包含了不同種族的不同化妝風格。該數據集包含了不同對象的化妝前后圖像,也可以用來研究彩妝應用下的人臉識別問題。
Makeup-Wild于2020年提出,它包含具有各種姿勢、表情以及復雜背景的人臉圖像,主要是從網上收集素顏和化妝人臉圖像,并手動刪除正面臉和中性表情的圖像,包含了403張妝容圖像和369張素顏圖像,其主要是用來對人臉妝容遷移算法的魯棒性進行測試。該數據集示例樣本如圖7(中)所示,第一行為素顏圖像,第二行為化妝圖像。
CPM于2021年提出,它包含了四類數據集:CPM-Real、CPM-Synt-1、CPM-Synt-2和Stickers,其中CPM-Real為無監督的數據集,包含了3 895張妝容圖像,數量比之前最大的妝容數據集MT多43%。化妝風格方面,該數據集既包含顏色化妝又包含圖案化妝,Stickers是577張高質量圖像的貼紙數據集,用于增加妝容風格的多樣性。CPM-Synt-1和CPM-Synt-2為監督數據集。CPM-Synt-1是帶有圖案的妝容數據集,共包含了5 555張圖像,每張圖像都有對應的圖案ground-truth分割掩碼以及UV圖。CPM-Synt-2數據集專為圖案遷移評估設計,包含1 625個圖像三元組(源圖像、參考圖像、ground-truth)。該數據集示例樣本如圖7(下)所示,從上往下依次為CPM-Real、CPM-Synt-1、CPM-Synt-2。

圖7 流行妝容數據集的視覺實例Fig.7 Visual examples of popular makeup datasets
4.2 評價指標
(1)定性指標
該指標具有一定的主觀性,主要是通過人眼來進行判斷人臉妝容遷移的效果。圖8展示了不同人臉妝容遷移方法在MT數據集上的定性實驗效果。由圖可知,當參考圖像和源圖像之間沒有明顯的空間錯位時,雖然使用特定妝容遷移方法可以有效提高妝容遷移的準確度,但也存在一定的問題,如BeautyGlow生成的圖像中,眼影明顯比參考圖像暗;LADN生成的圖像包含頭發周圍的偽像,幾乎沒有保留源圖像的身份;PSGAN在眼睛周圍生成了不自然的結果;SLGAN的頭發顏色發生了改變等。

圖8 不同方法在MT數據集上的定性結果Fig.8 Qualitative results of different methods on MT dataset
(2)定量指標
定量評估主要包括:用戶感知評價;inception score(IS);弗雷歇距離(Frechet inception distance,FID);MS-SSIM等四種評測指標。
①用戶感知評價是對風格遷移效果的主觀評價指標。一般做法為:隨機選擇N名學生,并每次提供若干張圖像,其中一個是素顏圖像,一個是妝容圖像,不同方法得到的遷移圖像。參與者需要根據質量、真實感和化妝風格對遷移圖像排序,排名越高表示遷移效果越好。
②inception score(IS)[42]是一種衡量生成圖像清晰度和多樣性的指標。IS值越大,表示生成圖像質量越高。計算公式為:
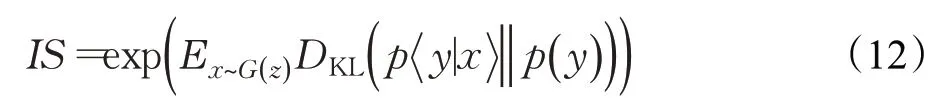
其中,E表示期望值,DKL表示兩分布之間KL散度。
③弗雷歇距離(Frechet inception distance,FID)[36]是計算真實圖像和生成圖像的特征向量之間距離的一種度量。距離越近,即FID值越小,表示生成模型的效果越好,即圖像質量好和清晰度高。計算公式為:
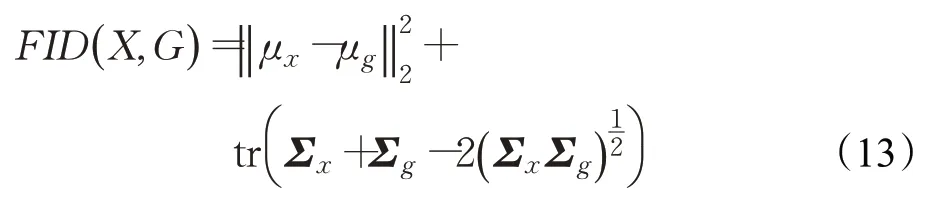
其中,X和G表示真實圖像和生成圖像,μx和μg是各自特征向量的均值,Σx和Σg表示各自特征向量的協方差矩陣,tr表示矩陣的跡(主對角線各元素的和)。相比于IS,FID對噪聲有更魯棒的敏感性,且對模式崩潰也更為敏感,故FID的實際應用相對更廣泛一些。
④MS-SSIM(multiscale structural similarity)是在SSIM[43]算法基礎上提出的,是一種計算多尺度結構相似性的方法,可以衡量兩幅圖像之間的相似度。計算公式如式(14)所示。當M=1時,表示原始圖像;當M=2時,表示原始圖像縮小一半,以此類推。
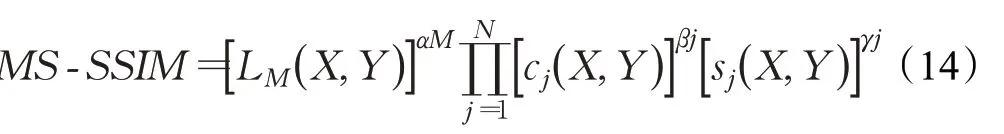
其中,L(X,Y)是亮度對比因子,C(X,Y)是對比度銀子,S(X,Y)是結構對比因子,α、β和γ是用于調整各個分量的權重。
5 總結與展望
人臉妝容遷移具有重要的理論研究價值和巨大的市場應用價值,但據作者所知,目前還沒有公開發表的關于人臉妝容遷移的綜述文章。本文根據人臉妝容遷移領域重點解決的問題,將基于生成對抗網絡的人臉妝容遷移算法分為面向上妝和卸妝的妝容遷移方法、面向魯棒性的妝容遷移方法、基于3D人臉模型的妝容遷移方法、基于弱監督的妝容遷移方法和其他妝容遷移方法五類。從網絡架構、損失函數、數據集和評價指標四個方面對現有人臉妝容遷移算法進行了系統的總結和梳理,并分析了各個模型的貢獻及局限性。經過對該領域的系統研究,基于生成對抗網絡的人臉妝容遷移技術下一步可能的發展趨勢主要有:
(1)引入單張圖像的三維人臉建模技術
現實中人臉是三維的,其三維特征將影響人臉圖像的視覺外觀,比如形狀、姿勢和表情。又因為目前人臉妝容遷移數據集都是由單張圖像組成的。因此,如何將單張圖像的三維人臉建模技術有效地引入人臉妝容遷移領域,并重建包含三維人臉特征信息的妝容圖像將是人臉妝容遷移領域中一個很有價值的發展方向。CPM[22]首次在這一方向上有所嘗試,但還有許多問題有待完善。
(2)將妝容遷移方法應用于實時視頻中
近年來對妝容遷移方法的研究主要集中在靜態圖像,針對視頻的研究很少。每一幀的姿勢和表情在視頻中是不斷變化的,與圖像妝容遷移相比,視頻妝容遷移是一項更具挑戰性但更有意義的任務,在視頻中實現良好的妝容遷移效果具有非常廣闊的市場應用前景,是未來的重點研究方向。
(3)交互式人臉妝容遷移
將圖像語義分割中的交互式分割和人臉妝容遷移相關結合,研究交互式人臉妝容遷移,具有重要的市場應用價值。交互式人臉妝容遷移指使用點、框或線標記遷移的目標區域,也可以標記非目標區域,實現用戶定制化的人臉妝容遷移。無論從用戶個性化需求還是化妝品企業的產品設計,交互式人臉妝容遷移有巨大的潛在市場應用價值。
(4)構建高分辨率的人臉妝容遷移數據集
目前的大多數妝容數據集規模小且分辨率不高,隨著算法模型的發展,對數據集的要求也越來越高。如何構建高分辨率的人臉妝容遷移數據集,進而實現高分辨率圖像的妝容遷移,也是后續值得研究的一項課題。
總之,基于生成對抗網絡的人臉妝容遷移是一項新興的具有挑戰性的課題,既是機遇也有挑戰,不僅受到學術界的廣泛研究,在商業界也有重要的研究價值。此綜述的目的也是為基于對抗生成網絡的人臉妝容遷移算法的進一步研究提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
