基于顏色名稱的彩色圖像質量評價
2022-01-27 09:53:30張選德
液晶與顯示 2022年1期
馬 暢,張選德
(陜西科技大學 電子信息與人工智能學院,陜西 西安 710021)
1 引 言
IQA是圖像處理領域的基本問題之一,且在圖像壓縮、視頻通訊、圖像恢復等眾多問題中有著十分重要的應用。例如:圖像壓縮中需要在圖像質量和壓縮率之間作均衡,視頻通訊中需要對圖像質量進行實時監控,而圖像恢復系統中也需要一個合適的圖像質量指標對其性能進行評價。IQA的研究目標在于利用數學模型來模擬人類視覺系統(Human Vision System,HVS)對圖像質量的感知和評價過程,構建同主觀評價盡可能一致的客觀圖像質量指標[1]。根據參考圖像的可用性,圖像質量評價可以分為3種類型:全參考(Full-Reference,FR)、部分參考(Reduced-Reference,RR)和無參考(No-Reference,NR)[2]。本文針對全參考圖像質量評價進行研究,構建彩色圖像質量評價模型。
當前大多數圖像質量評價算法都是針對灰度圖像設計的,如SSIM(Structure SIMilarity)[3],GMSD(Gradient Magnitude Similarity Deviation)[4]等,而彩色圖像質量評價方面的工作相對較少。Li Leida等人提出了基于稀疏表示和重構殘差的彩色圖像質量評價(Sparse Representation and Reconstruction Residual,SRRR)算法[5],使用自然彩色圖像訓練的過完備顏色字典表示參考圖像和失真圖像,構造兩個特征圖度量圖像的結構和顏色失真,計算重構殘差度量圖像的對比度變化,還引入亮度相似性以得到彩色圖像的最終質量得分。Jens Preiss等人[6]提出了一種使用彩色圖像差異(Color Image Difference,CID)作為目標函數來優化色域映射的算法,在解決傳統色域映射算法生成圖像中包含各種視覺偽像問題的同時給出了改進的彩色圖像差異(Improved Color Image Difference,ICID)指標,提高了對彩色圖像質量的預測性能。Dogancan Temel和Ghassan AlRegib提出基于多尺度和多通道誤差表示的頻譜理解的圖像質量評價(Spectral Understanding of Multi-scale and Multi-channel Error Representations,SUMMER)算法[7],該方法關注誤差圖像(參考圖像與失真圖像之差)的幅度譜,解決了灰度圖像的光譜統計量忽略了的顏色信息以及HVS的選擇性和層次性的問題。Sun Wen等人提出基于超像素的圖像質量評價(SuperPixel-Based SIMilarity,SPSIM)算法[8],基于感知上有意義的超像素圖像塊計算亮度、色度和梯度相似度,根據梯度區域一致性來進一步調整這3個特征,最后用紋理復雜度作為池化階段的加權函數,得到了與主觀評分較高的一致性。
對于彩色圖像,我們不能將其簡單地轉到灰度域進行評價,而是要引入顏色特征來度量圖像的色彩變化,以提高算法對彩色圖像質量的評價性能。一種直觀的彩色圖像質量評價方法是在顏色通道中計算逐像素的保真度,如PerSIM(Perceptual SIMilarity)[9]和FSIMc(Feature SIMilarity extend to Color)[10],但是各個顏色通道之間的差異未必對應于顏色之間的感知差異。從人類感知的角度來看,通常顏色空間不是均質(Homogeneous)的度量空間[11],因此彩色圖像質量評價研究中不應對各個顏色通道作分離處理,而應著眼于整體感知的顏色并計算顏色差異。從根本上講,彩色圖像質量評價的關鍵在于建立與HVS色彩感知能力相一致的色彩描述與量化方法。但色彩的描述與量化是計算機視覺領域至今尚未完全解決的問題,這使得彩色圖像質量評價成為了IQA領域的開放性問題。
CN[12]是近年來頗為知名的顏色描述方法,這種方法用11維概率向量來描述顏色,這個向量的每個分量表示了色彩屬于11個可被準確感知亦可用語義描述的顏色的概率。CN的獨到之處在于使用了顏色的語義描述,這些語義描述間接地反映了人類的色彩感知能力。本文利用CN構建彩色圖像質量模型,該模型將參考圖像和失真圖像的每個像素值映射為CN概率向量,并利用Wasserstein距離計算兩個向量分布之間的差異來度量兩幅圖像間的感知色差;然后將參考圖像與失真圖像轉換到各通道相互獨立的對抗顏色空間(Opponent Color Space)[13],并在其亮度通道中計算能夠表征圖像結構信息的梯度特征。由于HVS對亮度變化感知比對顏色更敏感,且人眼對顏色的感知與亮度關系密切,所以我們在模型中加入亮度特征作為補充。在池化階段使用視覺顯著性作為加權函數來獲得圖像質量得分。在幾個公開數據集上的實驗結果表明,提出的模型能夠獲得很好的評價效果。
2 顏色名稱
人們通常使用顏色名稱(CN)輕而易舉地描述人眼所看到的世界。而在計算機視覺中,我們學習圖像像素值與CN之間的映射關系,以將語義顏色標簽分配給圖像像素來描述圖像的顏色信息。這里使用的11種基本顏色名稱包括黑色、藍色、棕色、灰色、綠色、橙色、粉紅色、紫色、紅色、白色和黃色[12]。
為了獲得圖像像素值與CN之間更準確的映射關系,我們使用概率潛在語義分析(Probabilistic Latent Semantic Analysis,PLSA)模型從Google圖像上搜索大量真實世界的圖像構成的數據集中學習顏色名稱。PLSA是由Hofmann[14]提出的一種用于文檔分析的生成模型。給定一組文檔D={d1,…,dN},每個文檔都用單詞表W={w1,…,wM}描述,這些單詞是由潛在主題Z={z1,…,zK}產生的。在PLSA模型中,文檔d中單詞w的條件概率由式(1)計算:
(1)
其中:p(z|d)和p(w|z)都是離散多項式分布,可以使用EM算法[14]通過最大化對數似然函數L進行估算:
(2)
其中p(d,w)=p(d)p(d|w),n(d,w)是文檔d中出現單詞w的次數。
在學習顏色名稱的問題中,圖像對應文檔,像素值對應單詞,顏色名稱對應潛在主題。我們將圖像中的像素值建模為由顏色名稱生成的顏色值,PLSA模型的目的是找到最能解釋所觀察數據(圖像像素)的潛在主題(顏色名稱)。該過程可以理解為將p(w|d)分解為單詞-主題分布p(w|z)和文檔-主題固定比例p(z|d),則在p(w|z)中可以得到主題(顏色名稱)在單詞(像素值)上的分布,如圖1所示。

圖1 用于學習顏色名稱的標準PLSA模型概述[12]
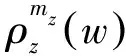
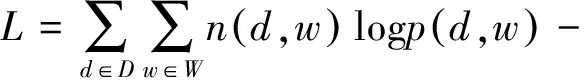
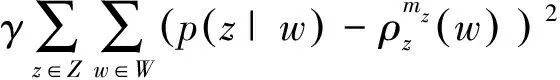
(3)
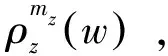
3 基于CN的彩色圖像質量評價模型
3.1 感知色差
這里利用Wasserstein距離來計算參考圖像與失真圖像的CN概率向量之間的差異,度量兩幅圖像之間的感知色差。首先利用文獻[12]中提供的映射關系表將參考圖像和對應的失真圖像中的每個像素映射為11維CN概率向量,然后利用兩個向量之間的距離來度量感知色差。如何度量兩個概率向量(分布)之間的距離呢?常用的方法有KL散度和Wasserstein距離,其中Wasserstein距離也被稱為推土機距離(Earth Mover Distance,EMD),是將一個直方圖轉換成為另一個直方圖所必須付出的最小代價。Wasserstein距離較之KL散度具有更好的數學性質,即使兩個分布的支撐集沒有重疊或者重疊非常少,仍然能反映兩個分布的遠近。因此選用Wasserstein距離來度量兩個CN概率向量的差異:
(4)
其中,fr表示參考圖像,fd表示失真圖像,i表示“圖像塊”索引,Y()表示圖像像素值到CN概率向量的映射,WS()表示Wasserstein距離運算符,CND表示顏色名稱距離。圖2是參考圖像和失真圖像以及它們的CND圖的示例。

圖2 顏色名稱距離圖
Wasserstein距離是兩個概率分布或直方圖之間在感知上有意義的統計指標[15]。給定兩個概率分布P1和P2,則P1和P2之間的Wasserstein距離可定義為:
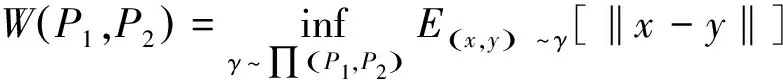
(5)
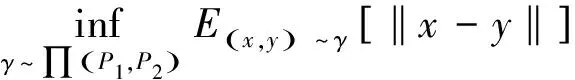
3.2 梯度相似度
圖像梯度是IQA問題中最常用的特征之一,它對失真很敏感,并且可以反映圖像的對比度和結構信息。有多種不同的算子可用于計算圖像梯度,這里使用Scharr算子[16]。首先,利用公式(6)將圖像轉換到對抗顏色空間(Opponent Color Space)中,該空間亮度與顏色信息完全分開,且各顏色通道相互獨立[13]。

(6)
其中,L表示亮度通道,M和N表示顏色通道。上述轉換中的權重針對HVS進行了優化[17]。然后,我們從L通道計算圖像的水平和垂直梯度,分別用Gx(i)和Gy(i)表示,并計算其梯度幅度GM(i),其中i代表第i個像素。
圖像f(i)的水平和垂直梯度Gx(i)和Gy(i)計算為:

(7)

(8)


圖3 梯度幅度圖
參考圖像fr和失真圖像fd之間逐像素的梯
度幅度的相似度定義為:
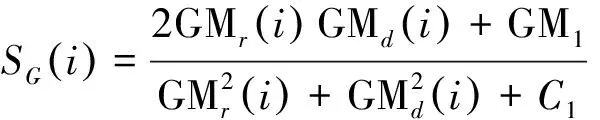
(9)
其中GMr(i)和GMd(i)分別表示參考圖像fr和失真圖像fd中第i個像素的梯度幅度,C1是一個正常數,以保持SG(i)的穩定性。
3.3 亮度相似度
與顏色信息相比,HVS對圖像的亮度變化更加敏感[18]。亮度總是對圖像的感知質量有很大影響,因此在彩色圖像質量評價的問題中,仍然需要考慮圖像的亮度特征。亮度相似度是基于每個圖像塊的平均值來計算的,參考圖像與失真圖像的每一組圖像塊對的平均值構成一組平均值對。根據恰可察覺失真(Just Noticeable Distortion,JND)模型,我們知道人類視覺系統無法察覺到處于一定閾值以下的圖像內容的變化[19]。因此,我們不必使用所有平均值對來度量亮度失真,因為一些差異較小的平均值對不會影響人類對圖像質量的感知,甚至還會緩和人眼對亮度變化較大的圖像區域質量的感知,因此,我們僅考慮亮度差異較大的平均值對,然后計算兩組選定平均值圖像塊對之間的相關性。
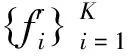
(10)
其中median()表示中位數計算。最后,亮度相似度的得分計算如式(11)所示:
(11)
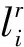
3.4 基于CN的彩色圖像質量評價模型
以基于CN定義的感知色差為基礎,以梯度幅值相似性和亮度相似性作為補充,我們構建了一個全參考彩色圖像質量評價模型,簡稱為CNCI(CN based Color image quality Index)。CNCI的總體框架如圖4所示。
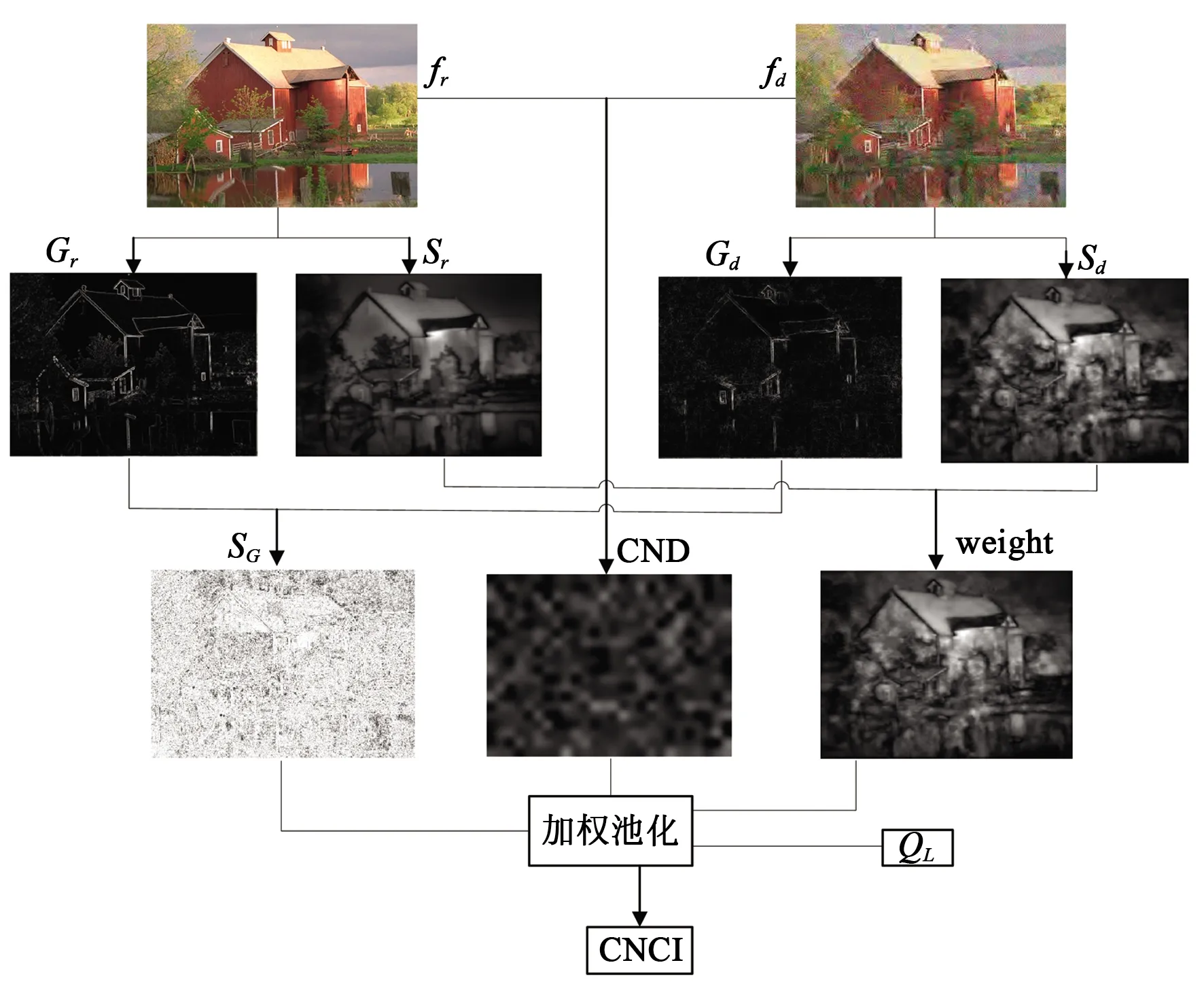
圖4 CNCI模型總體框架圖
參考圖像fr和失真圖像fd之間的相似度圖S(i)包括兩個部分,一個是顏色名稱距離圖(CND),另一個是梯度相似度圖(SG)。我們用參考圖像和失真圖像之間的顏色名稱距離圖來表示兩幅圖像間的感知色差,用梯度相似度圖表示圖像的結構變化,然后將二者融合,如公式(12)所示:
S(i)=(SG(i)α·(1-CND(i))β).
(12)
我們采用SDSP視覺顯著模型[20]來計算參考圖像的視覺顯著圖VSr和失真圖像的視覺顯著圖VSd,使用w(i)=max(VSr(i),VSd(i))來加權S(i),為圖像的不同區域賦予不同的權重大小,從而產生一個分數:
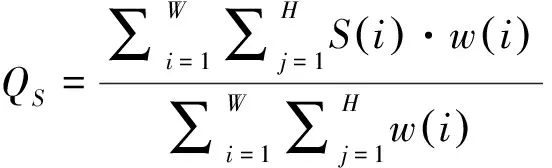
(13)
其中,W和H表示相似度圖的大小。考慮亮度對感知質量有很大影響,因此我們將該模型的最終質量得分Q定義為QS和QL的線性組合:
Q=a·QS+b·QL,
(14)
其中a和b是用于調整兩個分量相對重要性的參數,滿足a+b=1。
4 實驗結果分析
4.1 數據集和評價指標
我們在5個數據集TID2008[21]、TID2013[22]、CSIQ[23]、LIVE[24]和KADID-10k[25]上測試所提出的彩色圖像質量評價模型的性能。這些數據集中包含參考圖像、失真圖像以及針對失真圖像所收集的平均主觀分數(Mean Opinion Scores,MOS)或差異平均主觀分數(Differential Mean Opinion Scores,DMOS)。其中,TID2008包含1 700張失真圖像,17種失真類型和4個失真等級;TID2013包含3 000張失真圖像,24種失真類型和5個失真等級;CSIQ包含866張失真圖像,5種失真類型和4~5個失真等級;LIVE包含779張失真圖像,5種失真類型和4~5個失真等級;KADID-10k包含10 125張失真圖像,25種失真類型和5個失真等級。
圖像質量評價模型的性能通常以主客觀評分之間的一致性來衡量。常用的評價指標有Spearman秩相關系數(SROCC)、Kendall秩相關系數(KROCC)、Pearson線性相關系數(PLCC)和均方根誤差(RMSE)。其中,SROCC和KROCC用來衡量主客觀評分之間的一致性,PLCC和RMSE用來衡量模型預測的準確性。SROCC、KROCC、PLCC越大或RMSE越小,代表模型性能越好。在計算PLCC和RMSE前需要先進行回歸分析,建立主客觀評分間的非線性映射。這里采用公式(15)中的logistic回歸函數,其中Q代表IQA方法計算得到的客觀評分,P代表Q的回歸值,βi|i=1,2,3,4,5為要擬合的參數。
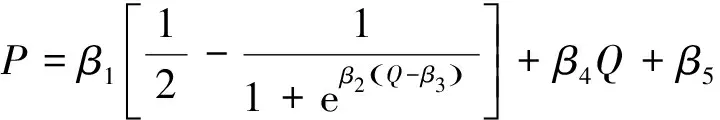
(15)
4.2 實驗參數
在本文方法中需要設置的參數有C1和C2、α和β、a和b。我們選取TID2008數據集中前8幅參考圖像和對應的544幅失真圖像作為測試子集,在該子集上選取不同參數組進行數值實驗,通過最高的SROCC值來確定最佳參數組,最終分別取C1、C2、α、β、a和b的值為386,0.001,0.6,0.02,0.7,0.3。
4.3 性能比較
實驗中采用的對比算法包括PSNR、SSIM[3]、MS-SSIM[26]、FSIM[10]、FSIMc[10]、GMSD[4]、SRRR[5]、RVSIM[27]和SUMMER[7]。這些算法均采用作者公布的代碼及其參數設置。表1列出了本文算法與9個對比算法在5個測試數據集上的評價結果,其中加粗顯示了排名前兩位的實驗結果。從表中可以看出,CNCI出現12次,SRRR出現10次,FSIMc出現8次,GMSD出現6次,FSIM出現4次。在TID2008數據集上,CNCI的SROCC和KROCC值均為最高,PLCC和RMSE值與SRRR相當,并優于大多數算法,這表明其可以獲得與主觀評價較高的一致性。在TID2013和KADID-10k數據集上,CNCI的4個指標均為最高,具有很好的質量評價能力,這是因為CNCI考慮了顏色信息,對于顏色失真類型的圖像能夠獲得更好的評價效果。而SRRR和SUMMER算法中也引入了顏色信息,但其總體性能并不突出,只在CSIQ數據集上SRRR算法的性能略高于CNCI。
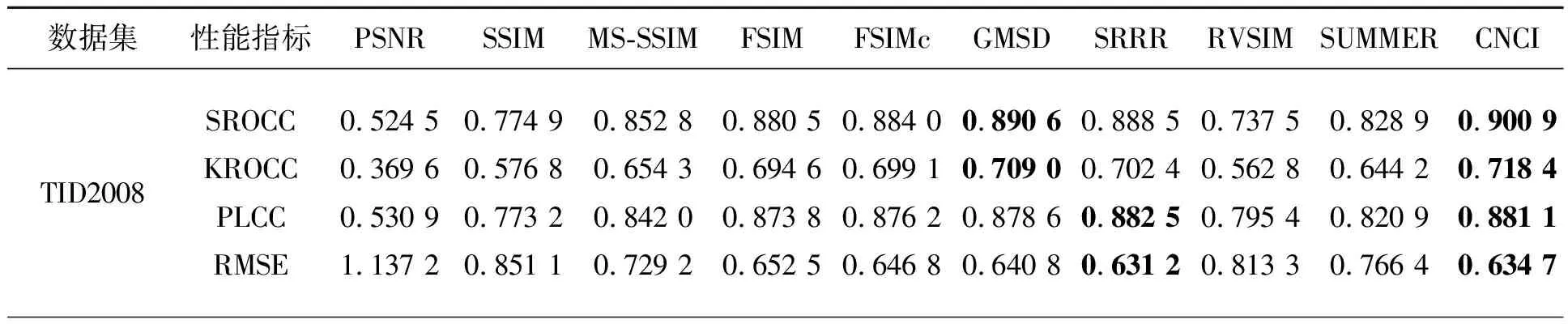
表1 不同IQA模型在TID2008、TID2013、LIVE、CSIQ和KADID-10k數據集上的實驗結果比較
實驗進一步驗證了模型關于單一失真類型的評價效果。表2列出了本文算法與9個對比算法在TID2013數據集上對每一種失真類型關于SROCC指標的評價結果,并加粗顯示了排名前兩位的實驗結果。從表中可以看出,CNCI模型可以在TID2013中大部分失真類型上產生較好的效果,且在AGN、JPEG、JP2K、JGTE和J2TE失真類型上獲得最佳效果。就單一失真類型來看,CNCI能夠達到與GMSD和SUMMER相當的性能。
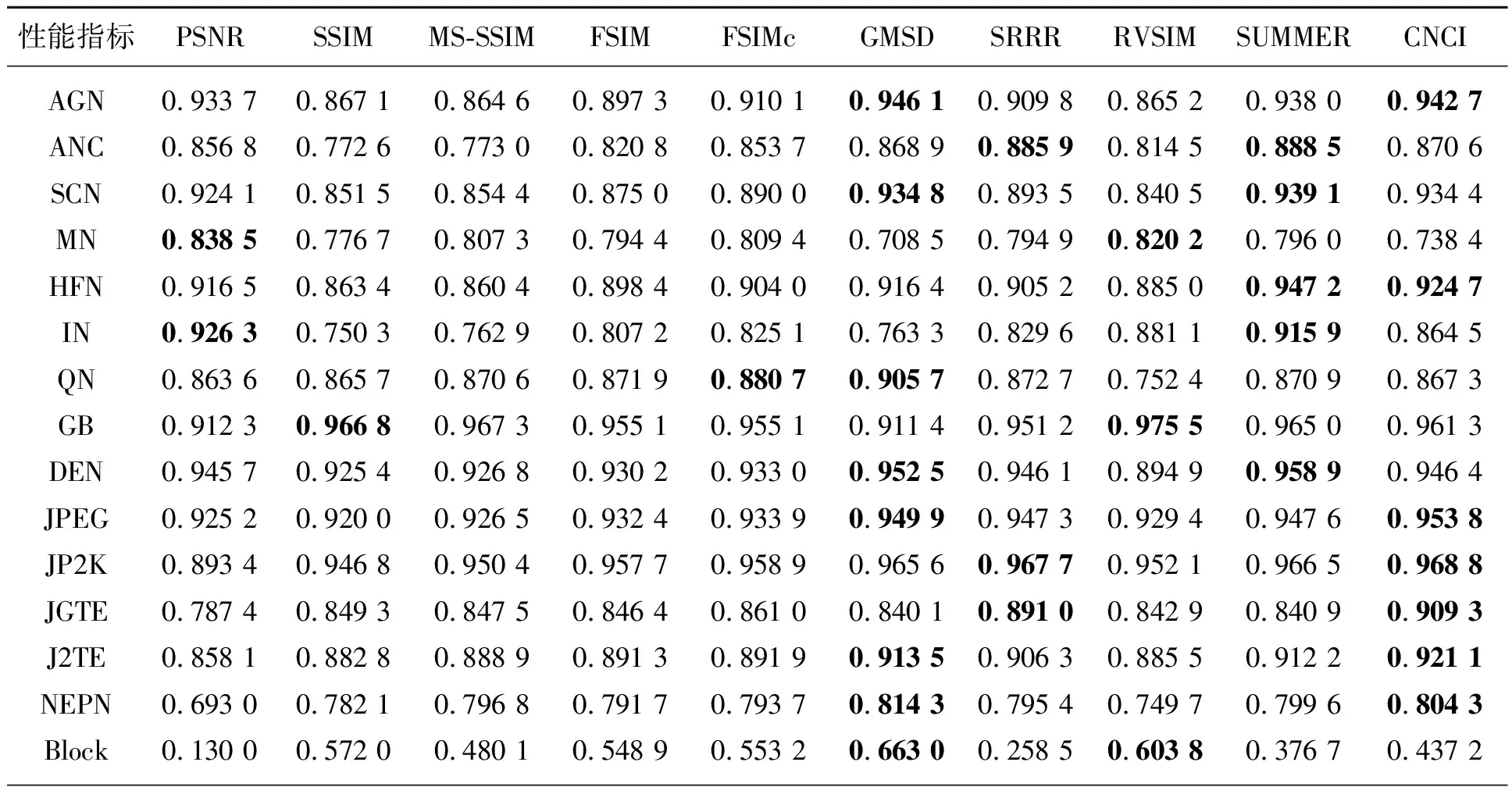
表2 不同IQA模型在TID2013數據集上單一失真性能(SROCC)的比較
4.4 消融實驗
為了驗證顏色名稱距離(CND)特征對彩色圖像質量評價模型預測性能的提升作用,實驗在TID2008數據集上對CND特征、梯度特征和亮度特征進行消融實驗。表3列出了在TID2008數據集上,CNCI模型僅使用CND特征、梯度特征和亮度特征,3個特征之間兩兩組合以及同時使用3個特征時所能達到的SROCC值。可以看出,同時使用3個特征能夠得到最高的SROCC值。由于HVS對亮度感知比對顏色感知更加敏感,因此僅使用亮度通道提取的梯度特征和僅使用亮度特征的效果要稍好于僅使用CND特征。但是從表3中可以看出,引入CND特征后,彩色圖像質量評價模型的評價性能有明顯提升,這證明了顏色名稱距離對兩幅彩色圖像之間的感知色差度量的有效性。
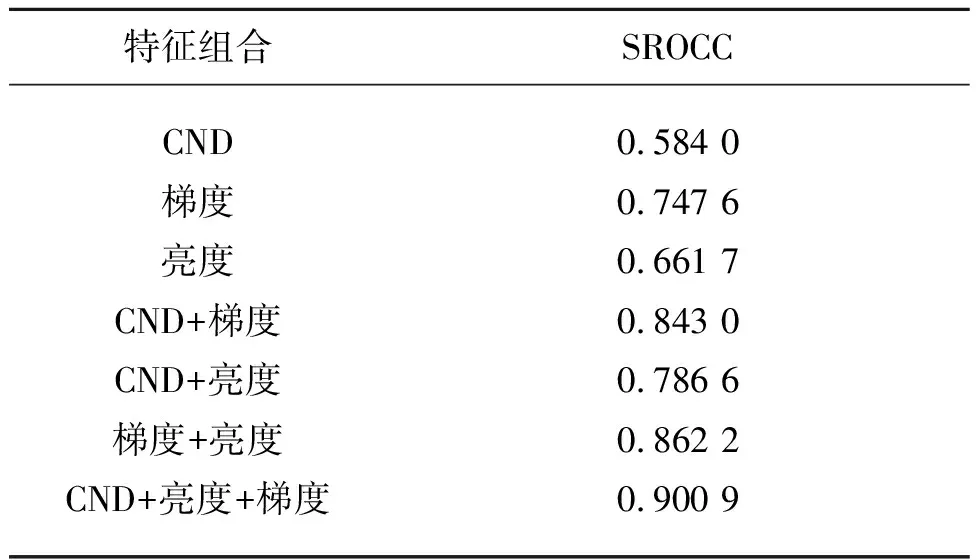
表3 CNCI模型在TID2008數據集上的消融實驗性能(SROCC)比較
5 結 論
本文提出一個基于顏色名稱的彩色圖像質量評價模型(CNCI),該模型采用顏色名稱距離度量圖像的整體感知顏色差異,同時結合梯度幅度相似性度量圖像的結構變化。在質量分數池化階段,將視覺顯著性用作加權函數來表示局部圖像區域的重要性,并加入亮度相似性作為補充,進一步提高算法的性能。在5個公開測試數據集上對CNCI和其他最新或著名的9個算法進行了比較,實驗結果表明,該模型能夠獲得與主觀評價更好的一致性,并且在TID2008、TID2013和最新的KADID-10k數據集中獲得最佳效果,其SROCC值分別為0.900 9,0.890 1,0.863 7。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
