基于環視圖的車位檢測算法研究
2022-02-07 09:20:38饒啟鵬翟樹龍
智能計算機與應用 2022年12期
饒啟鵬,凌 銘,王 鑫,劉 暢,翟樹龍
(上海工程技術大學 電子電氣工程學院,上海 201620)
0 引言
隨著Xavier、Atlan、Orin 等車載芯片的發展,其算力將應用于L4 及L5 級別自動駕駛,與此同時人們對高級輔助駕駛的需求也在增加,完全支持ADAS 自動泊車功能被量產。然而,戶外長時間使用的公共停車位除了本身可能出現的照明不足、遮擋嚴重等現象,甚至還會存在掉漆、灰塵污染、腐蝕等問題,如圖1 所示。

圖1 某地車位經過使用前后對比Fig. 1 Comparison of a certain parking space before and after use
綜上所述,這些問題就容易導致裝配了環視攝像頭的自動泊車系統出現漏檢。面對這一狀況,現已相繼提出了一些神經網絡算法,比如針對小目標的目標檢測[1]、注意力機制、以及偽裝目標檢測(Camouflage Object Detection,COD)等。研究可知,生物學術語中有背景匹配偽裝(background matching camouflage)一詞,變色龍就是詮釋該詞含義的一個最好的例子,即為了安全起見而使自己的身體看起來和周圍的環境無異。然而一般戶外公共的車位線經過反復使用后,就會出現與周圍地面背景匹配的現象,只有人眼依稀能看見的車位線。因此本文將其視作背景匹配偽裝,并設計了相應的檢測算法。原本白色的車位線在經由車輛、行人造成的灰塵臟污后看上去與灰色的水泥路面融為一體,甚至會出現車位線之間的材料被磨掉的現象,這對于自動泊車系統研究來說無疑就是一個技術難點。因此也給針對顯著性目標和通用目標的偽裝檢測提出了不小的挑戰。偽裝檢測不僅可以應用于自動駕駛檢測,目前也已廣泛應用于搜救工作、醫學圖像分割、稀有物種的發現和藝術創作等方面。
1 相關工作
1.1 偽裝目標檢測
根據目標的狀態可分為普通目標、顯著性目標和偽裝目標。針對偽裝目標檢測,SINet[2]根據自然界捕食者特點設計了搜索模塊和辨認模塊,PFNet[3]針對實驗分析過程中出現的難例問題,設計網絡結構時在聚焦模組(Focus Module,FM)中添加了逐元素加減操作以達到增強前景假陰性部分或抑制背景假陽性部分,這種方法明顯削弱了假陽性的干擾。
1.2 車位檢測
Hough 和Radon[4]變換作為傳統的車位線檢測線段特征,DeepPS[5]和DMPR-PS[6]采用了方形描述子檢測直角車位頂點,但缺點是對斜向停車位檢測性能會下降許多,PSDet[7]則改用圓形描述子來形容并提高對多種類型車位線的檢測魯棒性,VHHFCN[8]對斜向停車線設計的冗余模塊導致了性能的下降。文獻[9]和VSP-NET[10]則針對不同形狀、不同角度的停車位,利用二階或一階的深度卷積網絡同時檢測車位入口的角特征與線特征。隨著語義分割的流行,相比基于檢測方法的網絡模型來說,SPFC[11]的檢測精度和實時性要更高,因此本文采用基于分割的方法進行車位檢測。
2 車位檢測網絡模型
2.1 網絡結構
本文采用超像素網絡與偽裝檢測網絡的并行設計,為了進一步提高模型的效率,使用逆殘差塊(Inverted Residual Block,IBN)替代殘差塊,輸出的單級特征圖經過RF(Receptive Field)模塊,RF 模塊的結構是根據人類視覺系統來設計的,因此本文用SINet[2]中的RF 模塊代替膨脹卷積編碼器。研究給出的車位檢測網絡結構如圖2所示。
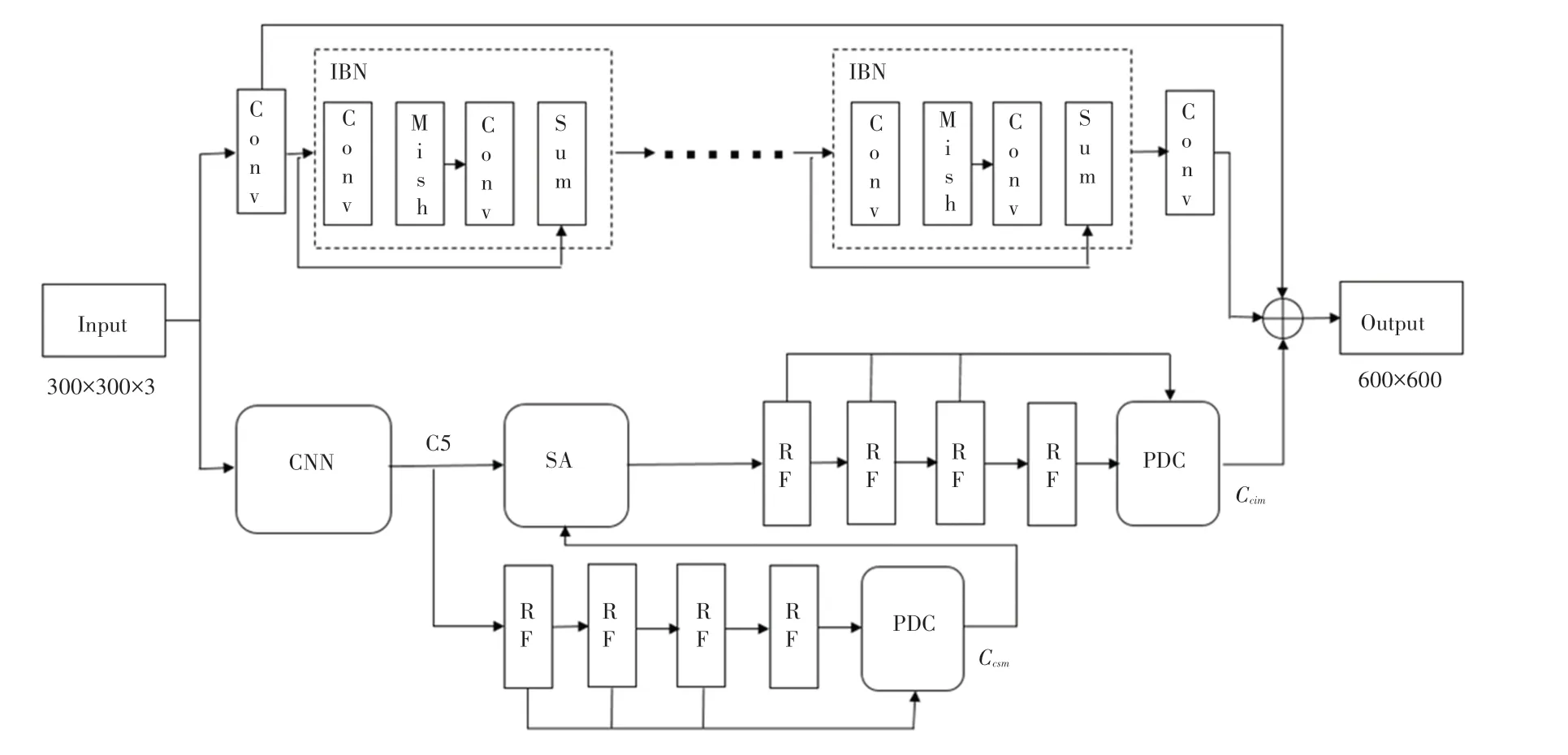
圖2 車位檢測網絡結構Fig. 2 Parking space detection network structure
2.2 主網絡
采用改進的YOLOF(You Only Look One-level Feature)[12]作為特征提取網絡,網絡僅僅輸出單級特征圖,同時為了進一步提高模型效率,主干網絡使用EfficientNet-B0[13],輸出單級特征圖(C5),如圖3所示。

圖3 主干網絡提取特征圖Fig. 3 The backbone extraction feature map
通過輸出的單級特征圖一路經過4 個級聯的RF 得到不同尺度的特征圖,另一路輸入搜索注意力(Search Attention,SA)模塊。SA 模塊接受C5 和部位解碼組件(Partial Decoder Component,PDC)計算的特征圖作為輸入,由PDC 解碼輸出的特征圖直接與標注的真值作為損失函數的輸入。
2.3 輔助網絡
車位檢測網絡下采樣等操作造成了原來圖像的細節損失,從而導致定位精度降低。因此添加超像素網絡實時處理低像素圖像。超像素網絡主要由殘差塊組成,殘差學習的設計特點是在原來的卷積模塊中加入了跳轉連接(Skip Connection)結構,低層的網絡可以直接連接到高層網絡中,很多超像素的相關工作都借鑒了這一點[14]。考慮到效率問題,利用IBN 模塊代替殘差塊,除了局部連接外,額外加入了全局連接融合各殘差塊,詳見圖2。
2.4 損失函數
訓練的損失函數為交叉熵損失函數(Cross Entropy Loss,CEL),損失函數定義如下:
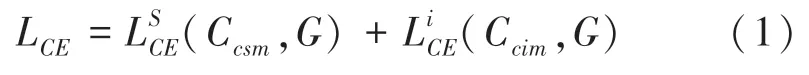
其中,Ccsm、Ccim分別表示2 張檢測到的車位掩碼圖,G為真值標簽。除了CEL外,還添加了局部對象損失(Objet-aware Loss)。具體來說,所提方法為每個訓練圖像生成相應的車位掩碼。在大多數像素點為零的每個掩碼中,收集車位區域中的損失函數定義如下:
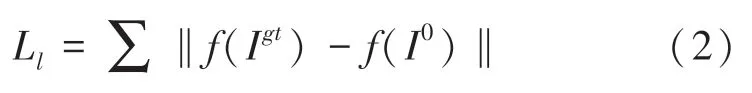
其中,f表示輸出的掩碼與真值圖像相乘而得到相應的車位區域。因此總體損失函數定義如下:

3 模型訓練及結果分析
3.1 實驗數據集
目前,用于自動泊車的數據集有:PSV 數據集[8]、ps2.0 數據集[5]、PSDD 數據集[7]。其中,ps2.0由4 顆魚眼相機拼接后的圖片制作而成,600×600像素對應實際上10 m×10 m 的地面范圍,數據均屬于停車場景,訓練集約10 000張,測試集不到5 000張。PSV 數據量較小,訓練集2 550張,驗證集425張,測試集1 274張。PSDD 數據集則涉及了更多場景和更豐富的停車位幾何形狀。
與當前流行的車位檢測數據集不同,本算法構建數據集的目標是提供視覺上更具挑戰性、卻也與現實特殊情形最貼近的數據集。作為一個偽裝目標檢測數據集,實驗分別從當前各流行的車位檢測數據集中精心選擇近似偽裝的圖片,并加入了一些數字處理手段:
(1)圖片經下采樣操作變成300×300,將這些低像素值圖片作為輸入,經過本文所提出的檢測器輸出600×600 的圖片。
(2)模糊化和隨機旋轉等操作,用來增強檢測器的檢測精度和魯棒性。
經處理后,一共得到了10 000張圖片(6 000 張用來訓練,4 000 張用于測試)。并按照偽裝目標檢測的標準進行標注,作為實驗的訓練集和測試集。
3.2 訓練策略與參數
實驗執行的算法在Linux18.04 64 位操作系統上實現,使用設備為Intel(R)Core(TM)i7-10510U CPU@1.80 GHz 32 G 內存、顯卡為NVIDIA GeForce 1080Ti、PyCharm2019 社區版、PyTorch 深度學習框架。在訓練階段,批大小設置為36 張圖片,學習率設為0.001,循環次數設為500,利用自適應矩估計(Adam)優化器,該優化器可以自動調節學習率,加速模型訓練過程,減少模型參數調整數目等優點。
3.3 對比實驗
為驗證所提方法的有效性,在服務器工作站上進行了實驗。圖4 為同等條件下,所提方法與其他3 種方法在數據集上經過訓練后求出的val_loss最低的權重進行預測后,得到的效果圖。從圖像的對比可以看出,所提方法比一般的基于分割的方法更能精確定位出車位線位置,提升了對車位線目標的捕捉能力,從而使得包含空車位鑒別等后處理任務在內的整體檢測精度有了提升。
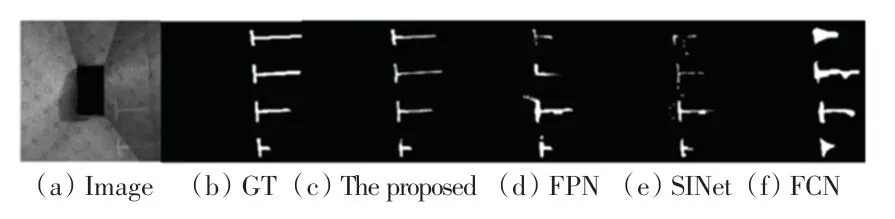
圖4 在數據集上的分割效果Fig. 4 Segmentation effect on the dataset
實驗使用MAE、Fβ、交并比(IoU)作為性能評估標準進行定量分析,先對所提出方法與其他3 種方法用相同的性能指標進行比較,并且采用相同的訓練和測試方法,得到在本文數據集上檢測結果,定量分析結果見表1。針對分割任務,基于自然界的捕獵方法設計的車位檢測器更利于檢測到近似偽裝的目標,IoU值為82.1,Fβ值為88.4,MAE值為0.045。對于車位線預測較好,但對于隱蔽性較強的特征分類能力仍有進步空間。
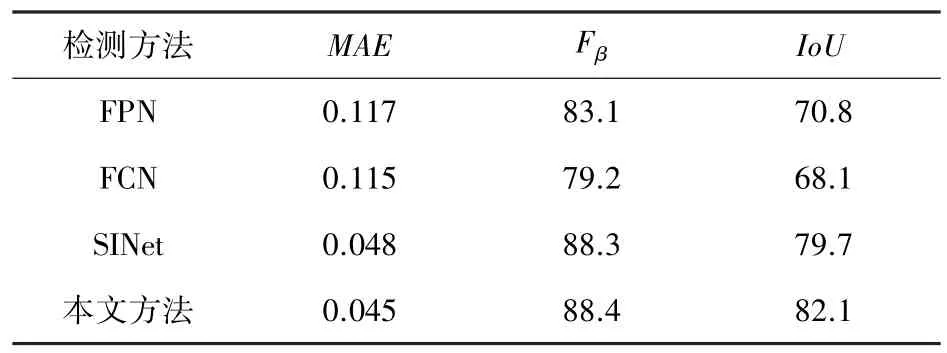
表1 數據集上不同分割算法性能對比Tab.1 Performance comparison of different segmentation algorithms on the dataset proposed in this paper %
YOLOF 框架下不同主干網絡對性能的影響見表2。由表2 可知,YOLOF 框架下EfficientNet-B0相比EfficientNet-B1 性能并未下降多少,且在降低模型尺寸的條件下提高了網絡運行的效率。
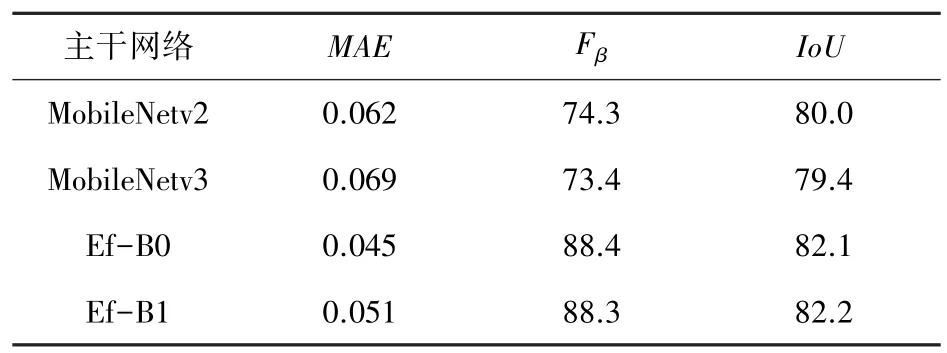
表2 數據集上不同主干提取網絡性能對比Tab.2 Performance comparison of different backbone extraction networks on the dataset proposed in this paper %
4 結束語
基于自然界捕食者捕捉原理,設計出一種緊湊而高效的神經網絡模型。先對目標區域進行搜索,再進行邊界框的精確定位;基于建立的數據集,提出的車位檢測算法能實現高精度的同時滿足實時性的性能要求;通過超像素并行模塊,實現對目標的更精確定位。實驗證明,所提出的網絡模型擅長在遮擋、陰影、灰塵污染等難以辨認的環境中對車位線進行精確識別并回歸出位置。今后會采用生成對抗網絡(Generative Adversarial Networks,GAN)方法生成更多近似偽裝的車位線圖片并做成數據集,從而增強模型的魯棒性,提高檢測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
