基于路網(wǎng)層次收縮的快速分布式地圖匹配算法
2022-02-11 14:11:56李瑞遠(yuǎn)朱浩文王如斌
計(jì)算機(jī)研究與發(fā)展 2022年2期
關(guān)鍵詞:方法
李瑞遠(yuǎn) 朱浩文 王如斌 陳 超 鄭 宇
1(重慶大學(xué)計(jì)算機(jī)學(xué)院 重慶 400044) 2(京東城市(北京)數(shù)字科技有限公司 北京 100176) 3(北京京東智能城市大數(shù)據(jù)研究院 北京 100176)
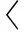

Fig. 1 Illustrationof Map-Matching圖1 軌跡地圖匹配示例
作為軌跡數(shù)據(jù)挖掘最基本的操作之一,地圖匹配在許多空間數(shù)據(jù)智能場景中都非常有用.例如,在軌跡壓縮應(yīng)用中,先將GPS點(diǎn)軌跡轉(zhuǎn)化成由路段ID組成的匹配軌跡,然后利用整數(shù)編碼或者最短路徑的方法對軌跡進(jìn)行壓縮,減少存儲空間.文獻(xiàn)[3]通過比較匹配軌跡和原始GPS點(diǎn)距離評估城市區(qū)域的GPS環(huán)境友好性,即哪些地方的GPS誤差高,哪些位置的GPS誤差低,從而指導(dǎo)部署輔助定位設(shè)備.文獻(xiàn)[4]通過地圖匹配操作實(shí)現(xiàn)對移動(dòng)機(jī)器人的定位.文獻(xiàn)[5]通過查詢經(jīng)過某一點(diǎn)的匹配軌跡,找到從該點(diǎn)出發(fā)一段時(shí)間內(nèi)能夠抵達(dá)的區(qū)域范圍.在軌跡異常檢測中,通過比較匹配軌跡與預(yù)設(shè)路徑的差異判斷車輛是否偏離了給定路線.文獻(xiàn)[8-9]查詢經(jīng)過給定路徑的所有匹配后的軌跡,可以分析每條道路的交通流量,或者更好地為車輛導(dǎo)航.
軌跡地圖匹配非常困難,特別是在并行道路或者高架橋等路網(wǎng)密集的區(qū)域.目前應(yīng)用最廣泛的方法是基于隱馬爾可夫模型(hidden Markov model, HMM)的地圖匹配方法,因?yàn)槠洳粌H考慮了路網(wǎng)的連接性,還考慮了GPS點(diǎn)之間的相互關(guān)系,因此具有較高的準(zhǔn)確率.然而,基于HMM的地圖匹配算法的運(yùn)行效率很低,難以滿足實(shí)時(shí)性很高的場景需求,在大規(guī)模軌跡數(shù)據(jù)的場景下,單臺計(jì)算機(jī)的資源有限,這個(gè)問題顯得尤為突出.例如,在實(shí)時(shí)可達(dá)區(qū)域分析文獻(xiàn)[5]中,需要實(shí)時(shí)匹配全城范圍內(nèi)的車輛,才能捕捉每條道路的交通情況,最終響應(yīng)用戶實(shí)時(shí)可達(dá)區(qū)域查詢的需求;在危化品監(jiān)管項(xiàng)目中,需要實(shí)時(shí)監(jiān)控危化品車輛是否偏離了既定的路線,因?yàn)橐坏┌l(fā)現(xiàn)異常,需要實(shí)時(shí)地對其進(jìn)行攔截,防止其駛?cè)刖用駞^(qū)域,造成安全隱患.即使對于離線匹配的場景,也需要盡可能地加快地圖匹配的效率,減少資源的消耗.
有大量的工作用來加速基于HMM的地圖匹配效率.例如,通過構(gòu)建空間索引加速查找每個(gè)GPS點(diǎn)的候選路段,但僅采用這種方法對整體提速并不明顯,因?yàn)榛贖MM的地圖匹配的瓶頸在于大量的最短路徑計(jì)算.為此,一部分研究工作簡化了最短路徑計(jì)算,包括減少待匹配的GPS點(diǎn)個(gè)數(shù)、略過較低概率匹配點(diǎn)之間的最短路徑計(jì)算、用近似值替代最短路徑等.然而,簡化計(jì)算的方法通常需要一些額外的信息,包括GPS點(diǎn)方向、路網(wǎng)等級等,其通用性受限,還會(huì)降低地圖匹配的準(zhǔn)確率.因此,另一部分工作直接加速最短路徑的計(jì)算,但它們?nèi)杂休^大的提升空間.還有一部分工作利用并行計(jì)算或分布式計(jì)算技術(shù),充分利用更多機(jī)器資源來提高計(jì)算效率,但是它們沒有考慮到路網(wǎng)和軌跡之間的大小差異,按照采樣軌跡對數(shù)據(jù)進(jìn)行分區(qū),容易造成數(shù)據(jù)不均衡,或者軌跡切分過細(xì)破壞軌跡完整性從而導(dǎo)致匹配準(zhǔn)確率降低等問題.
針對已有工作的不足,面向大規(guī)模軌跡數(shù)據(jù)的場景,本文提出了一個(gè)基于層次收縮的分布式地圖匹配處理框架(contraction hierarchy-based map-matching, CHMM).首先,在大多數(shù)實(shí)際項(xiàng)目中,涉及到的路網(wǎng)數(shù)據(jù)非常小,因此,我們將路網(wǎng)數(shù)據(jù)廣播到整個(gè)集群,對軌跡進(jìn)行隨機(jī)分區(qū),保證了數(shù)據(jù)平衡和軌跡完整性.其次,針對基于HMM的地圖匹配算法效率較低問題,我們提出了使用基于層次收縮的多對多最短路徑查詢算法,在保證匹配準(zhǔn)確率不變的情況下,大大加速了圖匹配過程.層次收縮算法最初被用來加速計(jì)算兩點(diǎn)之間的最短路徑,其思想是,先對路網(wǎng)進(jìn)行預(yù)處理,增加一些捷徑,并對每個(gè)道路頂點(diǎn)進(jìn)行編號;然后采用雙向搜索算法,利用編號限制搜索方向,利用捷徑跳過一些節(jié)點(diǎn)的遍歷,從而顯著提升最短路徑的計(jì)算效率.本文對基于層次收縮的最短路徑算法加以改造,實(shí)現(xiàn)多對多(即多個(gè)出發(fā)點(diǎn),多個(gè)目標(biāo)點(diǎn))的最短路徑查詢,從而減少重復(fù)計(jì)算,提升地圖匹配效率.注意,本文提出的優(yōu)化方案與其他加速方案是正交的,即可以與其他加速方案同時(shí)使用.本文的貢獻(xiàn)主要包含4個(gè)方面:
1) 提出了一個(gè)分布式地圖匹配框架.采用了一種新的分區(qū)策略,即將路網(wǎng)廣播、軌跡分段后再隨機(jī)分區(qū),從而實(shí)現(xiàn)負(fù)載均衡,保持軌跡完整性.
2) 提出了基于層次收縮的多對多最短路徑搜索算法,從而加速地圖匹配算法的效率;
3) 采用了4個(gè)真實(shí)的數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果表明,本文提出的分布式算法能夠大大提升地圖匹配的效率,同時(shí)具有很強(qiáng)的可擴(kuò)展性;
4) 本文提出的CHMM算法已經(jīng)落回到了產(chǎn)品JUST中,并支持了多個(gè)真實(shí)的項(xiàng)目落地.我們開源了CHMM算法的核心代碼,并提供了一個(gè)在線演示環(huán)境供讀者體驗(yàn).
1 先驗(yàn)知識
本節(jié)先給出一些形式化的定義,然后介紹Apache Spark的必要知識.
1.1 問題定義
定義1.
路網(wǎng)(road network).路網(wǎng)是一個(gè)有向圖G
=(V
,E
),其中,V
={v
,v
,…,v
}是節(jié)點(diǎn)集合,表示交叉路口;E
={e
,e
,…,e
}是有向邊集,表示路段集合.
每條路段e
∈E
是一個(gè)三元組e
=(v
,v
,l
),v
,v
∈V
表示e
的通行方向?yàn)閺?p>v到v
,路段長度為l
,稱v
和v
分別是e
的起始節(jié)點(diǎn)和終止節(jié)點(diǎn).
為方便起見,令e
=(v
,v
),l
=len
(v
,v
).
對于雙向路段,可以用2條有向邊來表示.
1.2 Apache Spark
Apache Spark(簡稱Spark)是一個(gè)基于內(nèi)存的分布式處理框架,它能夠處理大規(guī)模的數(shù)據(jù),并保證了容錯(cuò)性.Spark提供了一種數(shù)據(jù)抽象,稱為RDD(resilient distributed dataset),每個(gè)RDD包含多個(gè)分區(qū)(partition),不同的分區(qū)可能分布在集群的不同機(jī)器中,每臺機(jī)器可以有多個(gè)executor,每個(gè)executor可以并行處理多個(gè)分區(qū),每個(gè)分區(qū)即為一個(gè)并行處理單元.RDD可以通過一些并行的操作(例如map,filter,reduce等)進(jìn)行構(gòu)建和轉(zhuǎn)換.我們應(yīng)當(dāng)盡可能保證每個(gè)RDD分區(qū)內(nèi)的數(shù)據(jù)量差不多,從而實(shí)現(xiàn)負(fù)載均衡,加快整體的效率.RDD可以緩存在內(nèi)存中,或者持久化在磁盤中,以便重復(fù)使用,減少數(shù)據(jù)計(jì)算,這在循環(huán)迭代的場景中非常有用.在Spark中,可以將變量廣播(broadcast)到所有executor中,或者通過zipPartitions操作將2個(gè)RDD合并成一個(gè)RDD,這樣能夠?qū)崿F(xiàn)2個(gè)RDD之間的信息交換.Shuffle操作能夠?qū)?shù)據(jù)在不同的分區(qū)中重新組織和分配,但是shuffle操作代價(jià)非常昂貴,因?yàn)樗鼤?huì)造成不同分區(qū)甚至不同機(jī)器之間的數(shù)據(jù)轉(zhuǎn)移,因此我們應(yīng)該盡可能地減少shuffle的次數(shù).
盡管CHMM算法是基于Spark實(shí)現(xiàn)的,但是我們可以很方便地將它移植到其他的分布式計(jì)算框架中,例如Apache Hadoop或者Apache Flink.
2 基本框架
圖2給出了基于層次收縮的分布式地圖匹配算法CHMM的基本框架,共包含3個(gè)部分:軌跡數(shù)據(jù)預(yù)處理、路網(wǎng)數(shù)據(jù)預(yù)處理、軌跡地圖匹配.
1) 軌跡數(shù)據(jù)預(yù)處理.如圖2左上部分所示,我們首先讀取軌跡數(shù)據(jù),然后對軌跡進(jìn)行分段,即將一條長的軌跡分段成多條短的子軌跡,一方面能夠更好地組織軌跡數(shù)據(jù),另一方面也能夠加快后續(xù)地圖匹配的效率(詳見第3.1節(jié)).
2) 路網(wǎng)數(shù)據(jù)預(yù)處理.如圖2左下部分所示,我們首先讀入路網(wǎng)數(shù)據(jù),然后利用層次收縮算法進(jìn)行收縮,最終得到收縮后的路網(wǎng),用來加快后續(xù)地圖匹配過程中的最短路徑計(jì)算(詳見第3.2節(jié)).
3) 軌跡地圖匹配.如圖2右半部分所示,這個(gè)過程接收層次收縮的路網(wǎng)和分段后的軌跡作為輸入,基于這2個(gè)數(shù)據(jù)集,首先對軌跡數(shù)據(jù)進(jìn)行分區(qū),使得每個(gè)分區(qū)中的數(shù)據(jù)量盡可能相等,從而達(dá)到負(fù)載均衡.然后在每個(gè)分區(qū)里面并行執(zhí)行地圖匹配算法,得到最終的匹配軌跡(詳見第3.3節(jié)).我們還將CHMM算法落回到了JUST中,并提供了一個(gè)用戶界面,用戶可以通過該系統(tǒng)觸發(fā)地圖匹配過程,并查看匹配結(jié)果(詳見第4節(jié)).

Fig. 2 Framework of CHMM圖2 CHMM算法的基本框架
3 分布式地圖匹配算法CHMM
在本節(jié)中我們將詳細(xì)介紹CHMM的各個(gè)步驟,最后對算法性能進(jìn)行分析.
3.1 軌跡數(shù)據(jù)預(yù)處理

為解決上述問題,本文在地圖匹配之前,先對軌跡進(jìn)行分段.軌跡分段是指將一條長的軌跡分解成多條短的子軌跡.有多種軌跡分段的方法,例如:根據(jù)出租車的一次載客過程或者共享自行車一次借車過程對軌跡進(jìn)行分段,根據(jù)快遞員一次送貨過程對軌跡進(jìn)行分段等.上述的分段方法都需要具體的業(yè)務(wù)知識,并不適用于所有軌跡數(shù)據(jù).因此,本文采用基于駐留點(diǎn)和時(shí)間跨度的方法對軌跡進(jìn)行分段,只利用軌跡的時(shí)空信息,適用范圍更廣(任何其他的軌跡分段方法都可用于CHMM算法).具體分成2步:駐留點(diǎn)檢測和軌跡切分.
1) 駐留點(diǎn)檢測.
駐留點(diǎn)是移動(dòng)對象在一段時(shí)間t
內(nèi)產(chǎn)生在一個(gè)區(qū)域范圍d
中的GPS點(diǎn).我們采用文獻(xiàn)[42]的駐留點(diǎn)檢測方法,依次將每個(gè)GPS點(diǎn)作為錨點(diǎn),檢查其后繼節(jié)點(diǎn)是否滿足時(shí)間和空間條件.
如圖3所示,假設(shè)p
是當(dāng)前的錨點(diǎn),其后繼節(jié)點(diǎn)p
,p
,p
到p
的距離都小于d
,p
到p
的距離大于d.
接著我們檢查p
與p
的時(shí)間間隔是否大于t.
若大于t
,那么p
,p
,p
,p
都是駐留點(diǎn).
接著,我們以p
作為錨點(diǎn)重復(fù)前面的過程,直到所有的GPS點(diǎn)都檢查完畢.
在本文中,我們令d
=100 m,t
=100 s.該取值不但能夠排除十字路口等紅綠燈的情況(通常紅綠燈的等待時(shí)間在100 s以內(nèi)),也能夠避免GPS的定位誤差而帶來的影響(GPS的定位誤差通常不超過100 m),還能夠較好地捕捉長時(shí)間停留在某處的情形.
Fig. 3 Illustration of trajectory segmentation圖3 軌跡分段示例
2) 軌跡切分.獲得所有的駐留點(diǎn)后,我們以駐留點(diǎn)作為其中一類分割點(diǎn).另一類分割點(diǎn)考慮相鄰2個(gè)GPS點(diǎn)的時(shí)間間隔,若間隔大于t
′,那么這2個(gè)GPS點(diǎn)之間也會(huì)形成一個(gè)分割點(diǎn),如圖3的p
,p
所示.
軌跡分段利用這些分割點(diǎn),將長軌跡分割成多段短的子軌跡.
圖3中將一條長軌跡分成了3段子軌跡.
注意,t
′不能設(shè)置得過低,因?yàn)槿绻O(shè)置得過低,將會(huì)產(chǎn)生過多的子軌跡,每條子軌跡的起/
止節(jié)點(diǎn)無法充分利用前/
后GPS點(diǎn)的信息,影響匹配結(jié)果的準(zhǔn)確性.
在本文中,我們令t
′=60 min,因?yàn)槿绻?個(gè)連續(xù)GPS點(diǎn)超過了這個(gè)時(shí)間,它們之間的距離通常會(huì)相距非常遠(yuǎn),它們相互之間參考價(jià)值不大,其間的地圖匹配結(jié)果的正確性也難以保證.

Fig. 4 Distributed trajectory processing based on Spark圖4 基于Spark的分布式軌跡預(yù)處理
分布式實(shí)現(xiàn).利用Spark,可以很容易實(shí)現(xiàn)軌跡數(shù)據(jù)預(yù)處理.如圖4所示,我們首先利用textFile操作從外部存儲中讀取軌跡數(shù)據(jù),形成軌跡RDD.然后調(diào)用Spark的map操作識別出軌跡的駐留點(diǎn),得到新的軌跡RDD,最后繼續(xù)調(diào)用flatMap操作對軌跡切分(因?yàn)橐粭l長軌跡將會(huì)切分成多條子軌跡),得到分段后的子軌跡RDD.注意,整個(gè)軌跡預(yù)處理過程不涉及到數(shù)據(jù)的shuffle,利用Spark的并行處理能力,能夠高效地預(yù)處理海量的軌跡數(shù)據(jù).
3.2 路網(wǎng)數(shù)據(jù)預(yù)處理
為了加快基于HMM的地圖匹配算法效率,一種最有效的方式是提升最短路徑的查詢效率.基于層次收縮的最短路徑查詢權(quán)衡了預(yù)處理時(shí)間、存儲空間、查詢效率3方面的因素,能夠以較少的預(yù)處理時(shí)間、較少的存儲空間、高效地支持兩點(diǎn)之間的最短路徑.為此,在本節(jié),我們對路網(wǎng)數(shù)據(jù)進(jìn)行層次收縮,得到收縮后的路網(wǎng);同時(shí)討論當(dāng)路網(wǎng)非常大時(shí),我們應(yīng)當(dāng)如何處理.在3.3節(jié),我們闡述如何利用層次收縮后的路網(wǎng)加速地圖匹配.
3.2.1 路網(wǎng)層次收縮
v
的邊差是1-3=-2,因?yàn)榧僭O(shè)刪除v
,我們會(huì)刪除v
的3條相鄰邊(v
,v
),(v
,v
),(v
,v
),但是為保持所有節(jié)點(diǎn)對的最短路徑長度不變,我們需要增加1條長度為6的捷徑(v
,v
),否則節(jié)點(diǎn)v
到v
的最短路徑長度無法得以保留.
我們隨機(jī)選擇最小邊差的一個(gè)節(jié)點(diǎn)v
進(jìn)行收縮,并對v
進(jìn)行層數(shù)編號,得到如圖5(b)所示的路網(wǎng),虛線表示已經(jīng)刪除的邊和節(jié)點(diǎn),邊(v
,v
)表示增加的捷徑,節(jié)點(diǎn)內(nèi)的數(shù)字表示層數(shù)編號.
同時(shí),我們更新剩余節(jié)點(diǎn)的邊差.
接著,我們收縮節(jié)點(diǎn)v
,得到如圖5(c)所示的路網(wǎng).以上過程不斷迭代重復(fù),直到所有的節(jié)點(diǎn)都收縮完畢,最后得到如圖5(d)所示的收縮路網(wǎng).

Fig. 5 Example of contraction hierarchy圖5 層次收縮的例子

算法1.
路網(wǎng)層次收縮算法.
G.
① 初始化一個(gè)優(yōu)先隊(duì)列q
,并將所有的v
∈V
入隊(duì),按照給定的度量標(biāo)準(zhǔn)排序;level
=1;② whileq
≠null do③v
←q.pop
();④v
的層次編號設(shè)為level
;level
++;⑤ for each(u
,v
)∈E
并且u
尚未編號do⑥ for each(v
,w
)∈E
并且w
尚未編號do⑦ ifu
→v
→w
是u
到w
的最短路徑then⑧l
←len
(u
,v
)+len
(v
,w
);⑨ if(u
,w
)已經(jīng)存在E
中then⑩ 更新(u
,w
)的長度為l
;







.
2.
2 超大路網(wǎng)處理方案一般而言,城市中的路網(wǎng)數(shù)據(jù)更新周期較長,例如按月或者按季度更新,因此,上述路網(wǎng)收縮過程可以周期性執(zhí)行,并將收縮結(jié)果存儲起來,再次使用時(shí)直接加載收縮后的路網(wǎng)即可.
此外,在實(shí)際落地項(xiàng)目中,通常是以城市甚至區(qū)域作為交付的基本單元,而一個(gè)城市中的路網(wǎng)通常不會(huì)很大,例如,作為中國大都市的北京,其路網(wǎng)占用的磁盤大小約為100 MB,任何一臺標(biāo)準(zhǔn)的服務(wù)器均可以進(jìn)行處理.
對于無法完全加載到單臺機(jī)器內(nèi)的情形,我們可以先對路網(wǎng)切割,例如按照行政區(qū)域進(jìn)行切割或者采用圖分割算法,將一張大的路網(wǎng)切割成多個(gè)小的子路網(wǎng),然后對每個(gè)子路網(wǎng)單獨(dú)進(jìn)行層次收縮,最后對落在每個(gè)子路網(wǎng)內(nèi)的軌跡數(shù)據(jù),依次采用本文提出的分布式地圖匹配算法(見第3.
3節(jié)).

Fig. 6 Handling trajectories and road networks at boundaries圖6 處理邊界的軌跡和路網(wǎng)


Fig. 7 Distributed road network preprocessing based on Spark圖7 基于Spark的分布式路網(wǎng)預(yù)處理
3.2.3 分布式實(shí)現(xiàn)
圖7展示了利用Spark實(shí)現(xiàn)路網(wǎng)預(yù)處理的過程.首先,通過textFile操作從外部文件中讀取路網(wǎng)數(shù)據(jù),形成路網(wǎng)RDD.注意這里的路網(wǎng)圖是以路段的形式存儲的,在不同的分區(qū)之間以點(diǎn)分割的形式進(jìn)行分割.接著,我們通過partitionBy操作對路網(wǎng)重新分區(qū).我們實(shí)現(xiàn)了一種按照城市范圍的自定義分區(qū)方法,使得落在同一個(gè)城市擴(kuò)張范圍內(nèi)的路段重新分配到同一個(gè)分區(qū)中.若路段與多個(gè)城市擴(kuò)張范圍相交,則會(huì)分配到多個(gè)分區(qū)中.在每個(gè)新的分區(qū)中,我們可以得到一個(gè)子路網(wǎng),通過mapPartitions操作實(shí)現(xiàn)對子路網(wǎng)的層次收縮,采用mapPartitions的原因是單個(gè)分區(qū)內(nèi)的所有路段都會(huì)參與整體的收縮運(yùn)算.最后,同樣通過調(diào)用mapPartitions操作,將每個(gè)分區(qū)內(nèi)的層次收縮子路網(wǎng)存儲為單個(gè)文件,同時(shí)記錄了每個(gè)文件的路網(wǎng)空間范圍,方便后續(xù)地圖匹配過程使用.
3.3 軌跡地圖匹配


(1)


Fig. 8 Steps of Map-Matching based on HMM圖8 基于HMM的地圖匹配步驟


(2)


(3)



(4)
確定每個(gè)GPS點(diǎn)的候選點(diǎn)后,通過計(jì)算相鄰2個(gè)候選點(diǎn)的最短路徑,即可獲得最終匹配結(jié)果.

算法2.
基于層次收縮的最短路徑搜索算法.
輸入:層次收縮路網(wǎng)G
=(V
,E
),起始點(diǎn)s
,終止點(diǎn)t
;輸出:從s
到t
的最短路徑長度d
.
① ifs
和t
在同一條路段上then② returns
到t
的路段距離;③ end if
④ 初始化優(yōu)先隊(duì)列q
和q
,用來存儲待檢查的節(jié)點(diǎn),其鍵為對應(yīng)節(jié)點(diǎn)到s
或t
的最短路徑距離;⑤ 初始化哈希表h
和h
,其鍵為已檢查的節(jié)點(diǎn),值為對應(yīng)節(jié)點(diǎn)到s
或t
的最短路徑距離;⑥ 將s
的所有出口節(jié)點(diǎn)加入q
,將t
的所有入口節(jié)點(diǎn)加入q
;d
←∞;⑦ whileq
≠null或者q
≠null do⑧ ifq
≠null do/
*正向走一步*/
⑨ (d
,v
)←q
.pop
();⑩ ifd
>d
do/
*正向擴(kuò)張結(jié)束*/
/
*表示在中間相遇*/
v
.level
do









/
*表示在中間相遇*/



v
.level
do





.
2節(jié),我們已經(jīng)對路網(wǎng)進(jìn)行了層次壓縮.
給定壓縮后的路網(wǎng)G
,起始點(diǎn)s
,終止點(diǎn)t
,基于層次收縮的最短路徑搜索過程類似于雙向Dijkstra搜索算法.
如算法2所示,若s
和t
(可能不是路網(wǎng)節(jié)點(diǎn))在同一個(gè)路段,則直接計(jì)算s
到t
的路段距離并返回(行①~③).
否則,我們通過3個(gè)步驟獲得最終結(jié)果:1) 初始化(行④~⑥).
我們借助于2個(gè)優(yōu)先隊(duì)列來分別控制正向和反向的搜索順序,借助于2個(gè)哈希表來分別記錄某個(gè)節(jié)點(diǎn)是否已經(jīng)被訪問過以及它們到s
或t
的最短距離,并將s
的出口節(jié)點(diǎn)(即從s
出發(fā)能夠抵達(dá)的第1個(gè)道路節(jié)點(diǎn))和t
的入口節(jié)點(diǎn)(即能夠抵達(dá)t
的最后一個(gè)道路節(jié)點(diǎn))分別加入到2個(gè)優(yōu)先隊(duì)列中.d
表示當(dāng)前解,初始化為正無窮大.
v
到v
的最短路徑長度,其過程如表1所示,每一步執(zhí)行完畢后,各變量的取值在相應(yīng)位置給出.
例如,在第4輪擴(kuò)張時(shí),正向擴(kuò)張從優(yōu)先隊(duì)列q
中取出v
,它到s
的距離為6,小于d
,因此不會(huì)手動(dòng)清空q
.
此外,它尚未被正向擴(kuò)張?jiān)L問過,因此將v
加入h
中.
由于它已被反向擴(kuò)張?jiān)L問過,說明此時(shí)已經(jīng)找到了一條經(jīng)由v
的路徑,更新d
.
然后檢查v
的鄰居,發(fā)現(xiàn)不存在層級比v
大并且未訪問過的節(jié)點(diǎn).
此時(shí),2個(gè)優(yōu)先隊(duì)列均為空,搜索完畢.
最后得到v
到v
的最短距離為7.
注意,整個(gè)過程中,我們都沒有訪問節(jié)點(diǎn)v
.
相對于雙向Dijkstra算法,基于層次收縮的最短路徑算法主要有2點(diǎn)優(yōu)化:1)利用捷徑,能夠繞過一些中間節(jié)點(diǎn),從而減少迭代次數(shù);2)限制了搜索方向,即正向搜索沿著層次增加的方向,反向搜索沿著層次減少的方向.因此,基于層次收縮的最短路徑搜索算法更快.注意,基于層次收縮的最短路徑算法雖然與A算法有相似之處,即通過啟發(fā)式方法控制了搜索方向,但兩者的啟發(fā)式方法不能直接結(jié)合在一起,因?yàn)閷τ趯哟问湛s算法而言,每條邊的層級數(shù)都不一樣,也就無法先按照層級數(shù)擴(kuò)張,再按照A算法的啟發(fā)函數(shù)來擴(kuò)張;在路網(wǎng)收縮前,我們也無法事先得知起止點(diǎn),也就無法利用A的啟發(fā)函數(shù)來對路網(wǎng)進(jìn)行收縮.

Table 1 Example of Shortest Path Search Based on CH表1 基于層次收縮的最短路徑搜索示例
然而,針對地圖匹配的情形,算法2仍有較大的優(yōu)化空間.
如圖8(b)所示,假設(shè)GPS點(diǎn)p
有m
個(gè)候選點(diǎn),p
+1有n
個(gè)候選點(diǎn),在轉(zhuǎn)移圖中,p
到p
+1共有m
×n
條有向邊,因此需要觸發(fā)m
×n
次最短路徑的計(jì)算.
一種最直觀的方式,是調(diào)用m
×n
次算法2,每次計(jì)算一組候選點(diǎn)對的最短路徑.
然而,這樣會(huì)帶來很多冗余的計(jì)算.
給定如圖9(a)所示的路網(wǎng),節(jié)點(diǎn)從左往右層級逐漸升高.
要計(jì)算A
到D
和F
的最短路徑,采用一對一的最短路徑計(jì)算方法,其搜索過程如圖9(b)所示,路徑中的節(jié)點(diǎn)表示訪問的先后順序.可見,圖9(b)中虛線部分的搜索過程是冗余的.
Fig. 9 Redundant computing for one-to-one shortest path圖9 單對單最短路徑冗余計(jì)算
為了盡可能地減少冗余計(jì)算,本文提出了基于層次收縮的多對多最短路徑搜索方法.
其大體思想是,給定一個(gè)層次收縮路網(wǎng)G
=(V
,E
),出發(fā)節(jié)點(diǎn)集合S
={s
,s
,…,s
}和目標(biāo)節(jié)點(diǎn)集合T
={t
,t
,…,t
},我們依次從每個(gè)出發(fā)節(jié)點(diǎn)s
和目標(biāo)節(jié)點(diǎn)t
往外擴(kuò)張一步.
其中,對于每個(gè)出發(fā)節(jié)點(diǎn),我們沿著有向邊且層級增加的方向擴(kuò)張;對于每個(gè)目標(biāo)節(jié)點(diǎn)我們沿著有向邊的反方向且層級增加的方向擴(kuò)張.
若某個(gè)出發(fā)節(jié)點(diǎn)(或目標(biāo)節(jié)點(diǎn))與所有目標(biāo)節(jié)點(diǎn)(或出發(fā)節(jié)點(diǎn))確定了最短路徑距離,那么該出發(fā)節(jié)點(diǎn)(目標(biāo)節(jié)點(diǎn))便停止擴(kuò)張.
算法3.
基于層次收縮的多對多最短路徑搜索算法.

QS
={q
,q
,…,q
}和QT
={q
,q
,…,q
},q
∈QS
,q
∈QT
的排序鍵分別為對應(yīng)節(jié)點(diǎn)到s
和t
的最短路徑距離;② 初始化2個(gè)哈希表集合HS
={h
,h
,…,h
}和HT
={h
,h
,…,h
},h
∈HS
,h
∈HT
的鍵為已檢查的節(jié)點(diǎn),值為該節(jié)點(diǎn)到s
或t
的最短路徑;

s
∈S
的所有出口節(jié)點(diǎn)加入q
,將t
∈T
的所有入口節(jié)點(diǎn)加入q
;⑥ whileQS
≠?或者QT
≠? do⑦ for eachq
∈QS
do/
*所有起始點(diǎn)正向走一步*/
⑧ (d
,v
)←q
.pop
();
/
*s
正向擴(kuò)張結(jié)束*/
⑩ 從QS中移除q
;
do

v
.level
do
/
*所有終止點(diǎn)反向走一步*/
/
*t
反向擴(kuò)張結(jié)束*/
do

v
.level
do
.
在第3.
2節(jié),我們獲得了多份收縮后的子路網(wǎng),并存儲在了外部磁盤中.
在地圖匹配過程中,我們首先計(jì)算分段軌跡的空間范圍range
,然后在Spark的Driver進(jìn)程中依次讀取與range
相交的每個(gè)子路網(wǎng)文件,匹配完某個(gè)子路網(wǎng)內(nèi)的軌跡后,銷毀該路網(wǎng)變量,再讀取下一個(gè)路網(wǎng).
由于每個(gè)子路網(wǎng)不會(huì)很大,因此可以在Driver進(jìn)程的內(nèi)存中存儲起來.對于每個(gè)子路網(wǎng),我們首先向集群中廣播其空間范圍.分段后的軌跡RDD調(diào)用filter方法,過濾掉路網(wǎng)空間范圍外的軌跡數(shù)據(jù).由于經(jīng)歷了軌跡分段和過濾,分區(qū)間的軌跡數(shù)目可能會(huì)相差比較大,因此,需調(diào)用repartition方法,一方面調(diào)整分區(qū)的數(shù)目,使得耗時(shí)的地圖匹配能夠充分利用集群資源,另一方面能緩解數(shù)據(jù)不平衡的問題.最后通過調(diào)用map方法結(jié)合廣播的子路網(wǎng)對每條軌跡進(jìn)行地圖匹配.
Fig. 10 Distributed trajectory map matching based on Spark圖10 基于Spark的軌跡地圖匹配
3.4 性能分析



盡管從時(shí)間復(fù)雜度上看CHMM算法與相對于傳統(tǒng)基于HMM的地圖匹配算法相同,但是通過以下3個(gè)優(yōu)化,大大提升了地圖匹配效率:1)分布式計(jì)算充分利用了多臺機(jī)器資源;2)通過層次收縮路網(wǎng)限制了最短路徑的搜索方向,跳過了大量中間節(jié)點(diǎn)的訪問;3)多對多最短路徑搜索減少了大量冗余計(jì)算.
4 系統(tǒng)展示
本文提出的基于層次收縮的地圖匹配算法已經(jīng)落回了JUST系統(tǒng)中,用戶通過如下的SQL語句,就能夠?qū)崿F(xiàn)快速地圖匹配功能.
SELECT
st_trajMapMatchToCompletePath(t
1.traj
,t
2.rn
)
(SELECT
st_makeRoadNetwork(collect_list(r
))ASrn
圖11展現(xiàn)了JUST系統(tǒng)的用戶界面,用戶在SQL面板中輸入上述地圖匹配SQL語句,就能在地圖面板中查看地圖匹配的結(jié)果,如圖中綠色線所示.本文提出的算法已經(jīng)支持了危化品車輛行為分析、地圖路網(wǎng)修復(fù)等多個(gè)項(xiàng)目的落地.

Fig. 11 UI of JUST for Map-Matching based on CH[38]圖11 JUST實(shí)現(xiàn)基于層次收縮的地圖匹配界面[38]
5 實(shí)驗(yàn)及分析
本節(jié)先介紹實(shí)驗(yàn)相關(guān)設(shè)置,然后分析實(shí)驗(yàn)結(jié)果.
5.1 實(shí)驗(yàn)設(shè)置
5.1.1 數(shù)據(jù)集
我們采用4個(gè)真實(shí)的數(shù)據(jù)集來驗(yàn)證本文提出的地圖匹配方法的性能.
1) 西安軌跡數(shù)據(jù)集.采用滴滴蓋亞數(shù)據(jù)開放計(jì)劃提供的軌跡數(shù)據(jù),原始數(shù)據(jù)共包含中國西安市從2018-10-01—2018-11-30這2個(gè)月的出租車軌跡數(shù)據(jù),其空間范圍為經(jīng)緯度坐標(biāo)(108.92,34.20)到(109.01,34.28),包含了2 846 251 982條GPS點(diǎn),未分段的軌跡有3 960 100條,磁盤占用為217 GB,相鄰2個(gè)GPS點(diǎn)的采樣時(shí)間間隔約為3 s.分段后平均每條軌跡包含42個(gè)GPS點(diǎn).我們隨機(jī)采樣一些GPS點(diǎn),數(shù)據(jù)分布如圖12(a)所示,由圖12可知,軌跡在空間上分布非常不均勻.
2) 西安路網(wǎng)數(shù)據(jù).從OSM(open street map)網(wǎng)站中下載了西安軌跡空間范圍向外擴(kuò)了5 km的路網(wǎng)數(shù)據(jù),這樣確保邊界處的軌跡匹配結(jié)果正確.截取的路網(wǎng)共包含了71 906條邊,33 370個(gè)頂點(diǎn),磁盤占用8.47 MB.
3) 北京軌跡數(shù)據(jù)集.T-Drive數(shù)據(jù)集包含中國北京市從2008-02-02—2008-02-08一周內(nèi)10 366輛出租車的軌跡數(shù)據(jù),原始數(shù)據(jù)共有17 662 984個(gè)GPS點(diǎn),平均采樣時(shí)間間隔為177 s,磁盤占用為752 MB,去除明顯噪聲(坐標(biāo)為(0,0)的GPS點(diǎn))后,其空間范圍為經(jīng)緯度坐標(biāo)(116.24,39.83)到(116.48,40.02),分段后的軌跡數(shù)目為314 086條.圖12(b)展示了T-Drive采樣數(shù)據(jù)的分布.
4) 北京路網(wǎng)數(shù)據(jù).從OSM中下載北京軌跡數(shù)據(jù)集對應(yīng)空間向外擴(kuò)張5 km范圍內(nèi)的路網(wǎng)數(shù)據(jù),共有43 856條邊,19 665個(gè)頂點(diǎn),磁盤占用3.89 MB.
前2個(gè)數(shù)據(jù)集統(tǒng)稱為西安數(shù)據(jù)集,后2個(gè)數(shù)據(jù)集統(tǒng)稱為北京數(shù)據(jù)集.默認(rèn)情況下,我們采用西安數(shù)據(jù)集,因?yàn)槠滠壽E數(shù)據(jù)量更大、采樣時(shí)間間隔更小、數(shù)據(jù)質(zhì)量更好.

Fig. 12 Data distribution圖12 數(shù)據(jù)分布
5.1.2 衡量標(biāo)準(zhǔn)
本文在保證與基于HMM的地圖匹配算法準(zhǔn)確率不變的情況下,主要聚焦在地圖匹配效率的提升上.因此,我們主要比較不同方法的預(yù)處理時(shí)間、地圖匹配的時(shí)間.
5.1.3 對比方法
我們比較以下方法的地圖匹配效率.注意對于不同方法,使用的都是分段后的軌跡.所有對比方法的代碼均隨著我們的方法一起開源.
1) CHMM.本文提出的方法,即采用廣播路網(wǎng)的方式、軌跡隨機(jī)分區(qū)的方法、多對多的層次壓縮最短路徑算法來加速地圖匹配過程.
2) FMM.FMM方法首先計(jì)算每條路段到一段范圍內(nèi)所有其他路段的最短路徑,然后通過查表的方式來計(jì)算最短路徑,從而加快地圖匹配的效率.我們實(shí)現(xiàn)了其分布式版本.在預(yù)計(jì)算過程中,采用單源Dijkstra算法計(jì)算δ
范圍內(nèi)的最短路徑并存儲在一個(gè)二維哈希表中.在地圖匹配階段,若在二維哈希表中存在2條路段的最短距離,則直接返回,若不存在,則使用Dijkstra算法計(jì)算最短距離.3) PartitionSpace.文獻(xiàn)[44]首先對軌跡數(shù)據(jù)進(jìn)行采樣,在Spark Driver中采用四叉樹的方式對空間進(jìn)行劃分,使得每個(gè)子空間的軌跡樣本數(shù)目相近.接著對全量軌跡數(shù)據(jù)集按照此空間進(jìn)行劃分,使得每個(gè)分區(qū)內(nèi)的軌跡數(shù)目盡可能相同.它還考慮了邊界路網(wǎng)的問題,對于每個(gè)分區(qū),往外擴(kuò)張500 m路網(wǎng).文獻(xiàn)[15]采用的是一對一Dijkstra計(jì)算最短路徑,但為了公平起見,我們在每個(gè)分區(qū)內(nèi)采用了CHMM算法,即這個(gè)方法與我們的方法不同之處在于數(shù)據(jù)分區(qū)方式的不同.
4) Dijkstra.采用傳統(tǒng)的采用單向Dijkstra算法計(jì)算最短路徑距離,例如文獻(xiàn)[13,51].
5) Bi-Dijkstra.文獻(xiàn)[23]采用雙向單對單Dijkstra算法計(jì)算最短路徑距離,用來加速地圖匹配.
6)m
-n
-Dijkstra.文獻(xiàn)[24-25]采用雙向多對多Dijkstra算法計(jì)算最短路徑距離,用來加速地圖匹配.7) A.文獻(xiàn)[39]采用A算法計(jì)算最短路徑距離.
8) CH.采用單對單CH算法計(jì)算最短路徑距離.
注意,實(shí)驗(yàn)結(jié)果中未展示雙向A算法,因?yàn)槲墨I(xiàn)[52]指出,雙向A算法在雙向搜索相遇時(shí),得到的只是近似結(jié)果.為得到準(zhǔn)確結(jié)果,仍會(huì)繼續(xù)搜索很長的時(shí)間,導(dǎo)致算法極慢.實(shí)際上,我們也實(shí)現(xiàn)并開源了雙向A搜索算法,終止條件為:任何一個(gè)雙向搜索開放隊(duì)列為空,或者可能的最短路徑大于當(dāng)前已經(jīng)找到的最優(yōu)值.在我們的實(shí)驗(yàn)環(huán)境中,即使匹配一條只有14個(gè)GPS點(diǎn)、采樣間隔為24 s的軌跡,雙向A算法花費(fèi)的時(shí)間也超過了130 min.我們不比較多對多A算法以及雙向多對多A算法,因?yàn)锳算法的啟發(fā)式函數(shù)是針對單個(gè)起止點(diǎn)的,當(dāng)涉及到多個(gè)起止點(diǎn)時(shí),難以設(shè)計(jì)啟發(fā)式函數(shù),這將是一個(gè)有趣的研究點(diǎn).
5.1.4 參數(shù)設(shè)置
表2顯示了實(shí)驗(yàn)過程中的各參數(shù)變量取值,其中若無特殊說明,默認(rèn)的參數(shù)用粗體表示.我們通過查看機(jī)器數(shù)目和軌跡集大小的變化驗(yàn)證我們方法的

Table 2 Parameter Settings表2 參數(shù)設(shè)置
高可擴(kuò)展性;通過不同采樣率和GPS點(diǎn)個(gè)數(shù)的軌跡驗(yàn)證我們方法的廣泛適用性.對于所有方法,在尋找候選點(diǎn)時(shí),我們先對路網(wǎng)構(gòu)建R-tree索引.
5.1.5 實(shí)驗(yàn)環(huán)境
集群由5臺物理機(jī)器組成,每臺機(jī)器有24個(gè)物理CPU核、128 GB內(nèi)存,操作系統(tǒng)為CentOS 7.4.我們部署了Hadoop 2.7.3和Spark 2.3.3,編程語言使用Java和Scala,JDK的版本為1.8.在實(shí)驗(yàn)過程中,我們分配了5核和5 GB內(nèi)存給了Spark Driver進(jìn)程,為每個(gè)機(jī)器啟動(dòng)了30個(gè)executor,每個(gè)executor分配了5核和16 GB內(nèi)存.
5.2 實(shí)驗(yàn)結(jié)果

Fig. 13 Preprocessing performance of FMM (Xi’an)圖13 FMM預(yù)處理性能 (西安)
5.2.1 路網(wǎng)數(shù)據(jù)預(yù)處理性能對比
我們首先比較不同方法的路網(wǎng)數(shù)據(jù)預(yù)處理性能.注意我們沒有比較軌跡的預(yù)處理性能,因?yàn)樗蟹椒ǘ际腔诜侄魏蟮能壽E進(jìn)行地圖匹配的,他們的軌跡預(yù)處理過程相同.在這些方法中,只有CHMM,CH和FMM需要進(jìn)行路網(wǎng)數(shù)據(jù)預(yù)處理,而CHMM和CH方法都是對路網(wǎng)進(jìn)行同樣的層次壓縮,因此我們只比較CHMM與FMM的路網(wǎng)預(yù)處理性能.路網(wǎng)數(shù)據(jù)預(yù)處理都是在Spark Driver程序中進(jìn)行的.圖13展示了FMM算法對西安路網(wǎng)數(shù)據(jù)的每一條路段,采用Dijkstra算法預(yù)計(jì)算其到δ
空間范圍內(nèi)所有路段間的最短路徑所需的時(shí)間和結(jié)果占用空間.由圖13可知,F(xiàn)MM算法的預(yù)處理時(shí)間和預(yù)處理結(jié)果大小都隨著δ
增大呈指數(shù)增長,當(dāng)δ
=3 km時(shí),預(yù)處理結(jié)果大小達(dá)到了1.67 GB,當(dāng)加載到內(nèi)存時(shí),占用空間會(huì)更大,不適合分布式場景下廣播.而CHMM的路網(wǎng)預(yù)處理時(shí)間,需要的時(shí)間僅為13 s,壓縮后序列化的路網(wǎng)大小僅為19 MB,因此適合廣播.綜上,CHMM方法僅需要少量的預(yù)處理開銷,非常適合分布式的場景.5.2.2 地圖匹配性能隨采樣間隔變化
由于地圖匹配非常耗時(shí),在這一組實(shí)驗(yàn)中,我們選取了西安數(shù)據(jù)集預(yù)處理后前10 000條軌跡進(jìn)行分布式匹配,用來比較不同方法的匹配時(shí)間隨著采樣時(shí)間間隔的變化.原始軌跡的采樣時(shí)間間隔為3 s一個(gè)點(diǎn),9 s表示每3個(gè)點(diǎn)保留一個(gè)GPS點(diǎn),以此類推.
表3展示了實(shí)驗(yàn)結(jié)果,其中括號中的數(shù)字表示對應(yīng)采樣時(shí)間間隔下軌跡的平均GPS點(diǎn)個(gè)數(shù).從表3中我們可以得出以下7個(gè)結(jié)論:
1) 隨著采樣時(shí)間間隔從3 s增加到60 s,幾乎所有方法的地圖匹配時(shí)間先減少,然后緩慢增加.因?yàn)椴蓸訒r(shí)間間隔越大,一條軌跡中包含的GPS點(diǎn)越少,需要計(jì)算的最短路徑點(diǎn)對的數(shù)目越少,因此地圖匹配時(shí)間越少.但是隨著采樣間隔越大,2個(gè)相鄰的GPS點(diǎn)距離也就越大,計(jì)算最短路徑的時(shí)間也越長,導(dǎo)致采樣時(shí)間間隔從24 s增加到60 s時(shí),地圖匹配時(shí)間有所增加.
2) 對于FMM算法,隨著δ
的增加,從緩存中能夠查到的最短路徑記錄命中率也就越大,因此,δ
=1 000 m時(shí)的地圖匹配效率比δ
=500 m時(shí)更快.但是在我們的實(shí)驗(yàn)環(huán)境中,當(dāng)δ
=2 000 m時(shí),路網(wǎng)預(yù)計(jì)算結(jié)果在內(nèi)存中的空間大于2 GB,Spark無法廣播大于2 GB的變量,因此我們未比較δ
≥2 000 m的情形.3) 當(dāng)采樣間隔較低時(shí),F(xiàn)MM算法比Dijkstra更快,因?yàn)槲覀兛梢栽陬A(yù)計(jì)算結(jié)果中,直接查詢到某些最短路徑,從而避免耗時(shí)的Dijkstra計(jì)算.例如,當(dāng)δ
=1 000 m、采樣時(shí)間間隔為3 s時(shí),命中率約為60%,避免了大部分的計(jì)算開銷.隨著采樣時(shí)間間隔增加,F(xiàn)MM的用時(shí)與Dijkstra的差距越小,因?yàn)槊新蕰?huì)變小.4) Bi-Dijkstra算法、m
-n
-Dijkstra算法、A算法、CH算法、CHMM算法都比原始的Dijkstra更快,而本文提出的CHMM最快,因?yàn)橥ㄟ^壓縮路網(wǎng),CHMM算法能夠限定搜索的方向,通過捷徑能夠跳過一些中間節(jié)點(diǎn),而且通過多對多搜索,減少了重復(fù)計(jì)算.5) Bi-Dijkstra算法比A算法快,甚至是Dijkstra算法性能的20倍左右,因?yàn)锽i-Dijkstra算法減少了許多無效的路網(wǎng)擴(kuò)張;此外,在實(shí)現(xiàn)中,我們采用了文獻(xiàn)[53]的方法,一旦雙向擴(kuò)張相遇后,只擴(kuò)張隊(duì)列內(nèi)的路段,進(jìn)一步限定了搜索范圍.
6)m
-n
-Dijkstra與CHMM類似,共享了部分中間結(jié)果,減少了大量的重復(fù)計(jì)算過程,這非常適合基于HMM的地圖匹配算法,因此A算法不如m
-n
-Dijkstra算法.7) PartitionSpace方法內(nèi)部也采用了CHMM算法,但是采用四叉樹根據(jù)軌跡分布對軌跡進(jìn)行分區(qū)(在我們的實(shí)驗(yàn)中,最大分區(qū)數(shù)目為150,因?yàn)榧旱目偤藬?shù)為150).由于軌跡的空間分區(qū)非常不均衡,通過采樣對空間進(jìn)行分區(qū),仍會(huì)造成分區(qū)不均衡的問題,而本文提出的CHMM能夠保證分區(qū)均衡,因此比PartitionSpace方法更快.

Table 3 Map-Matching Time VS Sampling Interval on Xi’an Datasets
5.2.3 地圖匹配性能隨GPS點(diǎn)個(gè)數(shù)變化
在這組實(shí)驗(yàn)中,我們展示了采用北京數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果.西安數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果類似,因此結(jié)果未展出.我們選取了北京數(shù)據(jù)集中GPS點(diǎn)個(gè)數(shù)大于30的10 000條軌跡,每條軌跡的采樣時(shí)間間隔大約是24 s.對于每條軌跡,分別截取前5,10,15,20,25,30個(gè)GPS點(diǎn),形成新的軌跡,用來驗(yàn)證不同方法隨著GPS點(diǎn)個(gè)數(shù)增加的耗時(shí)變化情況.
由表4可知,隨著GPS個(gè)數(shù)的增加,所有方法所需要的耗時(shí)都增加,因?yàn)槲覀冃枰ヅ涓嗟狞c(diǎn),計(jì)算更多的最短路徑.所有方法中,CHMM算法效率最高.m
-n
-Dijkstra算法表現(xiàn)也很不錯(cuò),因?yàn)樗蚕砹瞬糠种虚g結(jié)果,減少了重復(fù)計(jì)算.在不需要多次執(zhí)行地圖匹配算法或者路網(wǎng)更新較頻繁的場景,可以使用m
-n
-Dijkstra算法,因?yàn)樗鼰o需對路網(wǎng)數(shù)據(jù)預(yù)處理.有趣的是,F(xiàn)MM(500 m)比FMM(1 000 m)效率更快,這與常識以及表3的結(jié)果相反.經(jīng)分析,本組實(shí)驗(yàn)中FMM算法的耗時(shí)都不高,因此其廣播變量的時(shí)間不可以忽略.當(dāng)δ
=500 m時(shí),預(yù)計(jì)算的最短路徑結(jié)果的磁盤占用為14 MB;而當(dāng)δ
=1 000 m時(shí),預(yù)計(jì)算的最短路徑結(jié)果的磁盤占用為48 MB,所需的廣播耗時(shí)更大.
Table 4 Map-Matching Time VS Number of GPS Points on Beijing Datasets
結(jié)合表3和表4來看,匹配北京數(shù)據(jù)集所需的時(shí)間比匹配西安數(shù)據(jù)集所需的時(shí)間小很多,因?yàn)楸本?shù)據(jù)集的路網(wǎng)更稀疏,每個(gè)GPS點(diǎn)的候選點(diǎn)更少,需要計(jì)算的最短路徑更少.
各步驟的耗時(shí)占比.表5和表6分別統(tǒng)計(jì)了各個(gè)算法在地圖匹配過程中,每個(gè)步驟的時(shí)間占比以及耗時(shí)情況.這里選用了西安數(shù)據(jù)集預(yù)處理后GPS點(diǎn)個(gè)數(shù)在30~50的1 731條軌跡,軌跡采樣時(shí)間間隔為24 s.由于本組實(shí)驗(yàn)主要查看各部分耗時(shí)占比,我們采用單機(jī)版單線程環(huán)境運(yùn)行了實(shí)驗(yàn),各步驟的耗時(shí)是匹配這1 731條軌跡的時(shí)間之和.注意,PartitionSpace算法與CHMM算法只是分布式分區(qū)方法不同,在單機(jī)版單線程環(huán)境中,與CHMM算法一致,因此其結(jié)果未列出.所有的方法中,構(gòu)建候選圖的耗時(shí)最大,因?yàn)槔锩嫔婕暗胶臅r(shí)的最短路徑查詢操作;確定匹配路徑耗時(shí)最少(接近于0%),這得益于Viterbi算法的使用.例如,對于傳統(tǒng)的Dijkstra算法,其構(gòu)建候選圖的耗時(shí)高達(dá)99.19%,即使作了一些優(yōu)化,最佳對比方法(即m
-n
-Dijkstra)構(gòu)建候選圖的耗時(shí)也需要占用92.65%.而CHMM是所有方法中構(gòu)建候選圖耗時(shí)唯一少于90%的方法,但也占用89.87%.將表3和表5結(jié)合起來看,構(gòu)建候選圖占比越小的方法整體運(yùn)行得更快.因此,加快最短路徑的計(jì)算對于基于HMM的地圖匹配至關(guān)重要.另一個(gè)需要說明的現(xiàn)象是,表3與表6中各算法的性能之比是不同的,因?yàn)樗鼈兯褂玫臄?shù)據(jù)集不一樣,而且執(zhí)行環(huán)境不同,但他們之間的相對性能是一致的.
Table 5 Time Ratio of Different Steps in Map-Matching on Xi’an Datasets表5 西安數(shù)據(jù)集地圖匹配各步驟時(shí)間占比 %

Table 6 Time Cost of Different Steps in Map-Matching on Xi’an Datasets表6 西安數(shù)據(jù)集地圖匹配各步驟時(shí)間 s
5.2.4 擴(kuò)展性比較
為了驗(yàn)證CHMM方法的擴(kuò)展性,我們做了2組實(shí)驗(yàn).在第1組實(shí)驗(yàn)中,我們對西安數(shù)據(jù)集中100萬條軌跡進(jìn)行地圖匹配,分析在不同集群節(jié)點(diǎn)數(shù)目情況下,所需要的匹配時(shí)間.我們從表3中選取了較快的4個(gè)算法CHMM,CH,m
-n
-Dijkstra,PartitionSpace進(jìn)行對比,因?yàn)槠渌乃惴ㄐ侍停ヅ?00萬條軌跡數(shù)據(jù),即使使用5臺節(jié)點(diǎn)的集群,運(yùn)行一整晚均未出結(jié)果.由圖14(a)可知,隨著節(jié)點(diǎn)數(shù)目的增加,所有的方法所需的時(shí)間逐漸減少,然后趨于平穩(wěn).因?yàn)楣?jié)點(diǎn)數(shù)目越多,計(jì)算資源越多,因此會(huì)更快,但當(dāng)節(jié)點(diǎn)更多時(shí),瓶頸將會(huì)由計(jì)算開銷轉(zhuǎn)化成通信開銷,因此會(huì)趨于平穩(wěn).CHMM算法的運(yùn)算效率比其他的方法更高,而且可以更快地穩(wěn)定下來.
Fig. 14 Scalability of different methods (Xi’an)圖14 不同方法的擴(kuò)展能力(西安)
圖14(b)展示的是不同方法的執(zhí)行時(shí)間隨著數(shù)據(jù)集大小的變化情況.其中,100%的數(shù)據(jù)表示西安數(shù)據(jù)集中約為500萬條軌跡.由圖14可知,隨著數(shù)據(jù)集的增大,所有方法所需的時(shí)間開銷呈線性增長,但CHMM方法所需的時(shí)間少得多,而且增長率更低,CHMM優(yōu)勢更明顯.整體而言,CHMM算法所需的時(shí)間是PartitionSpace算法的1/3.因此,CHMM的可擴(kuò)展性更強(qiáng),效率更高.
6 相關(guān)工作
對軌跡地圖匹配問題的研究由來已久,其中基于HMM的軌跡地圖匹配應(yīng)用最為廣泛,因?yàn)槠渚哂休^高的準(zhǔn)確率,能夠處理噪聲和低采樣率軌跡的情形.但它也面臨著效率較低的問題,因此,有大量加速軌跡地圖匹配的研究工作.這些工作大體可分成4類:構(gòu)建索引、簡化計(jì)算、加速最短路徑計(jì)算、并行計(jì)算或者分布式計(jì)算.
1) 構(gòu)建索引.基于HMM的軌跡地圖匹配的第一步是尋找每個(gè)GPS點(diǎn)周圍一定范圍內(nèi)的路段,用于確定候選點(diǎn).大多數(shù)地圖匹配工作都對路網(wǎng)構(gòu)建空間索引,以加快對周圍路段的查詢.許多空間索引可供選擇,例如:R-trees,Quad-trees,k
-d
trees、網(wǎng)格索引或者它們的變種.盡管構(gòu)建空間索引能夠一定程度上加快地圖匹配效率,然而,候選點(diǎn)的確定并不是基于HMM的軌跡地圖匹配的最大瓶頸,僅僅通過空間索引對全局軌跡地圖匹配的提速是非常有限的.2) 簡化計(jì)算.研究發(fā)現(xiàn),基于HMM的軌跡地圖匹配的瓶頸在于確定匹配路徑,其效率跟軌跡點(diǎn)的個(gè)數(shù)、路網(wǎng)的稠密度、最短路徑的計(jì)算有關(guān).為提升地圖匹配的效率,直觀方法是減少匹配GPS點(diǎn)的個(gè)數(shù)、減少候選路段的條數(shù)、簡化最短路徑的計(jì)算.①減少匹配GPS點(diǎn)的個(gè)數(shù).當(dāng)軌跡采樣率非常高時(shí),可以通過對軌跡進(jìn)行降采樣或者軌跡化簡的方式,減少待匹配的GPS點(diǎn)從而加快地圖匹配.文獻(xiàn)[19]設(shè)計(jì)了一種考慮空間信息(例如路段長度和回轉(zhuǎn)方向)的加權(quán)函數(shù)用來進(jìn)行軌跡化簡,并提出了3種軌跡化簡方法來減少軌跡中的GPS點(diǎn)的個(gè)數(shù).文獻(xiàn)[20]首先考慮GPS點(diǎn)的移動(dòng)方向?qū)壽E進(jìn)行聚類,然后將同一個(gè)聚類內(nèi)的GPS點(diǎn)匹配到同一條路段中,因?yàn)榫垲惖膫€(gè)數(shù)比GPS點(diǎn)的個(gè)數(shù)少很多,因此能夠顯著提升匹配效率,同時(shí)這種方法還能夠緩解噪聲點(diǎn)帶來的影響.實(shí)時(shí)地圖匹配通常只考慮最近一段時(shí)間的GPS點(diǎn)數(shù)據(jù),因此通常比離線地圖匹配更快.②減少候選路段的條數(shù).ST-Matching算法只保留當(dāng)前為止得分最多的l
個(gè)候選點(diǎn).SD-Matching算法首先對每個(gè)候選點(diǎn)計(jì)算一個(gè)綜合概率,它同時(shí)考慮了空間概率和角度概率的.然后只選擇k
個(gè)綜合概率最大的點(diǎn)作為最終候選點(diǎn),從而加快地圖匹配效率.③簡化最短路徑的計(jì)算.SD-Matching算法通過運(yùn)動(dòng)方向找到一個(gè)搜索區(qū)域,然后只考慮在搜索區(qū)域內(nèi)的路徑,大大簡化了最短路徑的計(jì)算.文獻(xiàn)[17]針對手機(jī)基站數(shù)據(jù),改造了HMM算法,提出了一個(gè)快速實(shí)時(shí)的維特比解碼器,具有線性的空間復(fù)雜度和時(shí)間復(fù)雜度,其大體思路是消除了乘以0的路徑組合.針對高頻軌跡,文獻(xiàn)[21]直接用GPS點(diǎn)的歐氏距離替代路網(wǎng)距離.簡化計(jì)算的方法通常需要額外的信息,例如GPS點(diǎn)的方向,其通用性受限.此外,這類方法在一定程度上會(huì)降低匹配精度.3) 加速最短路徑計(jì)算.與簡化計(jì)算不同,這類方法能保持匹配結(jié)果與原生HMM類的地圖匹配算法一致.針對Dijkstra算法計(jì)算2個(gè)候選點(diǎn)的最短路徑非常耗時(shí)的問題,文獻(xiàn)[39]采用A算法或ALT算法加速最短路徑的計(jì)算.文獻(xiàn)[23]采用雙向Dijkstra算法來加速,而文獻(xiàn)[24-25]采用多對多Dijkstra算法進(jìn)行加速.前面這些提速方法需要在原始的路網(wǎng)上進(jìn)行搜索,其加速效果仍然有較大提升的空間.文獻(xiàn)[22]預(yù)計(jì)算并緩存了一定空間范圍內(nèi)任何一對路段之間的最短距離,當(dāng)進(jìn)行匹配時(shí),通過查表的方式求得2個(gè)候選點(diǎn)之間的最短距離.這種方法非常消耗內(nèi)存,在路網(wǎng)稠密的地方,常常容易內(nèi)存溢出.
4) 并行計(jì)算或者分布式.另外一種方式通過使用更多的CPU來加速地圖匹配過程.文獻(xiàn)[51]采用多線程的方式并行化構(gòu)建路網(wǎng)索引,同時(shí)并行化地圖匹配過程,大大提升了匹配效率.文獻(xiàn)[27]使用Hadoop實(shí)現(xiàn)大規(guī)模GPS軌跡的分布式地圖匹配.針對Hadoop執(zhí)行效率較低的問題,涌現(xiàn)了很多基于Spark的分布式地圖匹配工作.例如,文獻(xiàn)[21]根據(jù)軌跡點(diǎn)采用了Quad-tree進(jìn)行分區(qū),同時(shí),對于分區(qū)邊界的路網(wǎng),進(jìn)行擴(kuò)張和拷貝,從而提升邊界點(diǎn)的匹配準(zhǔn)確率.它還提出了一種分批處理的方法,防止數(shù)據(jù)過大時(shí)內(nèi)存開銷太大.但是根據(jù)軌跡進(jìn)行分區(qū)的方法,在空間范圍不大并且軌跡數(shù)目較多時(shí),可能會(huì)面臨著路網(wǎng)拷貝過多、單個(gè)分區(qū)內(nèi)軌跡數(shù)目較多的問題,當(dāng)劃分空間非常小,軌跡也會(huì)被切分成很小,極端情況下,一個(gè)分區(qū)內(nèi)的軌跡點(diǎn)數(shù)目只有1~2個(gè),嚴(yán)重影響了地圖匹配準(zhǔn)確率.因此它的擴(kuò)展性受限,效率不高,準(zhǔn)確率可能會(huì)受影響.
本文提出的CHMM方法利用了空間索引加速候選點(diǎn)的查找,基于層次收縮的路網(wǎng)采用多對多的方式加速最短路徑計(jì)算,同時(shí)提出了一個(gè)分布式處理框架,在保持高匹配率的同時(shí),具有更高的效率和更強(qiáng)的可擴(kuò)展性.
7 總結(jié)與展望
本文提出了一個(gè)基于層次收縮的分布式地圖匹配算法框架,能夠?qū)崿F(xiàn)海量軌跡數(shù)據(jù)的快速匹配.具體來說,提出了一個(gè)簡單但非常有效的數(shù)據(jù)分區(qū)策略,能夠保證分布式環(huán)境下任務(wù)的負(fù)載均衡;提出了利用層次收縮的方法加速地圖匹配效率,并在此基礎(chǔ)上提出了基于層次收縮的多對多最短路徑查詢算法.實(shí)驗(yàn)結(jié)果表明我們提出的方法具有較高的效率和可擴(kuò)展性.例如,在我們的實(shí)驗(yàn)環(huán)境中,對于500萬條軌跡進(jìn)行地圖匹配,CHMM算法的耗時(shí)僅為PartitionSpace算法的1/3.所提的方法已經(jīng)支持了多個(gè)真實(shí)空間數(shù)據(jù)智能項(xiàng)目的落地.我們還提供了一個(gè)在線演示系統(tǒng),開源了核心代碼,期待能夠推動(dòng)相關(guān)技術(shù)在更多的空間數(shù)據(jù)智能場景中落地.未來工作中,我們期待增加更多過濾條件在層次路網(wǎng)搜索中,同時(shí)考慮將本文提出的方法與其他優(yōu)化方法例如文獻(xiàn)[57]相結(jié)合,更進(jìn)一步地提升地圖匹配效率.
作者貢獻(xiàn)聲明
:李瑞遠(yuǎn)負(fù)責(zé)想法的提出、文章的撰寫以及rebuttal等事宜;朱浩文、王如斌負(fù)責(zé)執(zhí)行實(shí)驗(yàn)、將算法落回產(chǎn)品;陳超負(fù)責(zé)論文算法討論和整體質(zhì)量把控;鄭宇給我們提供了工作、實(shí)驗(yàn)環(huán)境,提出問題及大體方向,確定論文框架.猜你喜歡
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
