基于緩存的時變道路網最短路徑查詢算法
2022-02-11 14:12:04楊志邦曾源遠李肯立
計算機研究與發展 2022年2期
關鍵詞:策略
黃 陽 周 旭 楊志邦 余 婷 張 吉 曾源遠 李肯立
1(湖南大學信息科學與工程學院 長沙 410082) 2(之江實驗室 杭州 311100)
近年來,隨著現代綜合化交通運輸體系結構的改變,無線通信網絡安全的快速發展,具有定位功能、提供地圖服務的設備在物聯網中被廣泛應用.利用基于位置服務來獲取從指定源點到目標點的最短路徑查詢結果已經逐漸成為主流的查詢方式.尤其是面臨緊急情況出行時,人們往往選擇旅行時間最短的路徑作為行駛路線,但是現實世界道路網中街道旅行時間具有時變性,交通狀況并不穩定,會面臨道路臨時修建、雷雨天氣等突發事件,導致街道的旅行時間發生動態的改變.盡管已經存在許多求解最短路徑的方法,但是能否高速有效地實現檢索動態道路網中旅行時間不確定的最短路徑仍面臨如下問題:
1) 查詢結果的時效性與查詢請求響應速度的平衡問題.文獻[4]提出無索引方法,在保證路徑權重有效的情況下,通過服務器計算2點之間成本最小的路徑,但在非大規模圖上執行路徑查詢仍需花費幾秒鐘,其查詢性能有待提高.為解決查詢耗時長的問題,文獻[5]提出預構建全局索引的算法,以加速最短路徑查詢.雖然引入全局索引的查詢技術能夠快速響應查詢請求,但索引維護開銷較大,將面臨索引未完成更新,路況就可能發生了新的變化的情況,導致查詢結果不適用路況而變得無效.
2) 查詢響應速度與服務器工作負載的平衡問題.當道路網處于查詢高峰期時,查詢請求的峰值可達百萬次,此時服務器將產生極高的工作負載、延遲查詢的響應時間.雖然可以通過部署更多的服務器解決負載過高的問題,但成本昂貴,并非所有公司都可以承擔.該挑戰在可以保證查詢結果有效性的無索引算法中尤為突出.為提高大規模路徑的查詢效率,可利用緩存中的數據來提升查詢請求的響應能力,減少服務器工作負載.文獻[7]通過引入緩存技術啟發式地將動態圖中收益值最大數據替換緩存中無效路徑來提高緩存命中率,加速查詢效率.然而該方法只適用于單路徑更新的場景.文獻[8]利用歷史日志信息將查詢頻率高的數據預加載到緩存來提高緩存命中率.而復用歷史日志信息中的高頻路徑來構建緩存,并不適用于時變道路網場景,主要是因為過往數據不具備時效性,不能應對動態變化的場景,導致緩存命中率降低,命中的路徑也因數據失效而出現結果偏差,繼而影響用戶體驗.
例如,在偏遠地點A
開設一場萬人以上的大型演唱會,那么在演唱會當天會存在上萬次前往地點A
的路徑查詢請求.
若是基于歷史信息的緩存策略,偏遠地區的數據不會預存入緩存,緩存則不會命中有關地點A
的查詢請求,從而只在代理服務器中執行查詢.
此時,若出現大量與地點A
相關的查詢,將導致服務器負荷驟增,系統整體的查詢性能變差.
若此時提供一種可以實時識別查詢頻率高的路徑并用來替換緩存中的低效的路徑,則可以有效地避免上述情況的發生.
意味著在演唱會當天,緩存中的數據能夠及時且有效地應答多條前往地點A
的路徑查詢請求,以減少代理服務器的計算量.
此外,當地點A
的查詢頻率變低后,緩存中與A
相關的數據則會自動被其他高頻率數據置換.通常采用15 min為一個時鐘間隔來更新緩存數據,該方式得以有效應用,是因為一段時間內路況的變化非常小,短時間內可以維持命中路徑的準確性.因此采用實時更新緩存數據的方式不僅可以提高緩存命中率,減少服務器的運行成本,還可以提高命中數據結果的有效性.
綜上分析,在具有時變特征的道路網中,一個良好的基于緩存的最短路徑查詢算法是能夠支持最短路徑快速查詢和提高緩存命中率的必要條件.因此,本文設計了一個盡可能最大化利用緩存的算法來支持最短路徑查詢.并在緩存存儲策略中,將路徑共享能力計算方法和差異多樣性技術相結合,用于減小緩存中冗余數據的占用容量,提高緩存命中率.此外,緩存中的數據存儲結構具有數據弱相關、結構緊湊的優點,不僅可以減少數據的存儲空間,還可以實現動態數據的快速維護、加快路徑的檢索速度.
本文主要貢獻有3個方面:
1) 提出的新緩存存儲結構包含用于存儲節點的鄰接點索引、記錄路徑節點的位圖索引以及記錄路徑基本信息的路徑信息索引.該結構新穎之處在于其存儲空間較小,索引間可獨立地維護緩存中的數據;
2) 提出一種緩存存儲策略,其不僅顯著地減少了緩存中的冗余數據,還可以有效且實時地識別出存入緩存的最短路徑,以提高緩存命中率.
3) 提出了基于緩存的時變道路網最短路徑查詢算法(cache-based time-varying shortest path query, CTSPQ).其巧妙地借助緩存存儲結構的特性,提高了最短路徑在緩存中的查詢速度.
在真實的數據集上進行大量實驗,驗證了本文提出的策略以及查詢方法的有效性.
1 相關工作
1.1 最短路徑查詢
近年來,最短路徑查詢問題被廣泛應用在各行各業,其變體問題被廣泛用來研究,如查找從給定源點到目標點最短路徑的單源點對(single pair shortest path, SPSP)問題、查找給定頂點到圖中每個頂點最短路徑的單源點(single source shortest paths, SSSP)問題以及查詢圖中所有頂點最短路徑的全對(all-pairs shortest path, APSP)問題.但是在道路網中檢索最短路徑的花費時間仍舊高,如常用的Dijkstra算法的時間復雜度為O
(m
+n
logn
).為解決大規模網絡上最短路徑查詢耗時長的問題,文獻[5,12-17]提出了支持快速檢索最短時間/油耗/距離路徑問題的索引結構,縮小了最短路徑查詢理論與實踐之間的差距.文獻[14]設計的HoD(highways-on-disk)索引結構通過采用較小的I/O消耗成本來回答單原點距離(single source distance, SSD)和SSSP等查詢問題,但HoD僅適用于數據變換頻率低的情況.文獻[15]通過使用關系數據庫管理系統解決了SSSP查詢慢的問題,但是當網絡中的數據或者結構發生變化時,該方法將耗較長的時間重新計算節點之間的關系.
文獻[16]給出了維護索引結構時間復雜度的理論上下界,最優下界與網絡中頂點數量呈線性關系,但在節點數量非常龐大的網絡中才能表現出線性優勢。文獻[17]利用隨機化技術提出了一個有效預測路徑距離的方法.是通過以空間換時間的方法來構建索引,雖然可以通過部署大量服務器提高查詢速度,但運行成本高、可擴展性較差.
1.2 緩存管理
緩存具有快速交換數據的能力,文獻[18-25]利用緩存技術減少大規模最短路徑查詢時間.即預先構建一個緩存區,若緩存中的數據能夠直接應答查詢請求并返回結果,則無需采用代理服務器計算路徑,從而加快系統整體的響應速度.故利用緩存加速查詢的關鍵點在于查詢請求在緩存中命中率.
現有提升緩存命中率的策略主要有3種:動態緩存策略、靜態緩存策略及混合緩存策略.靜態策略將根據歷史日志中查詢頻繁的路徑對緩存進行更新,該策略的數據無法應對突發事件,不適用于本文.動態策略包括最近最少使用(least recently used, LRU)和最不經常使用(least frequently used, LFU)等,LRU策略是將新路徑置換緩存中最近最久未使用的路徑的策略,LFU策略則是將當前時間使用次數最多路徑置換緩存中使用次數最少的路徑,以此來提高緩存命中率.文獻[19]設計了最短旅行時間的路徑緩存(shortest travel-time path cache, TPC)算法,用于計算時變道路網中旅行時間最短的路徑,但路徑能否加入緩存依賴于緩存已有節點.文獻[20]提出的最短路徑緩存(shortest-path-cache, SPC)方法,雖然能回答查詢頻繁高的路徑,但面對突發狀況時的查詢將不具備穩定性.混合緩存策略將靜態策略和動態策略相結合來更新緩存.
除此之外,文獻[22]利用寄存器設計了通用的框架來生成時序關鍵路徑,減少了相同查詢請求的計算次數,但其存儲空間較小.文獻[23]引入的Cache-Oblivious模型為多級內存系統設計算法提供了理論基礎.該模式是專門為標準的兩級I/O模型設計的算法,但需要小心地調優它們所運行的系統的參數.文獻[6]提出了批量處理最短路徑的算法,首先將查詢請求生成云狀查詢集,再利用緩存統一查詢以減少查詢次數.文獻[8]不僅考慮了日志路徑的查詢頻率,還通過路徑的覆蓋范圍來衡量最短路徑的影響力,將高影響力的路徑存儲入緩存,進而提高其命中率.文獻[24]設計了路徑緩存規劃系統,將緩存中部分匹配的查詢請求結果的路徑作為返回用戶端路徑的子路徑段,以此減少服務器對整條路徑的計算量.文獻[25]不再關注網絡節點之間的組織情況,而是通過邊來構造路徑緩存,首先定位查詢請求點在緩存中的候選邊,由邊之間連接得到最短路徑.雖然上述緩存技術可以加速最短路徑查詢、平衡索引維護的時間和路徑查詢速度的關系,但僅有少部分文獻涉及時變道路網中最短路徑查詢的緩存策略,因此在高度動態網絡中,利用緩存設計高速、有效應答路徑查詢方法變得十分重要.
1.3 基于差異多樣性的路徑規劃
提高緩存命中率的常規方法是將高頻率路徑加入緩存,但高頻路徑往往存在大量重復路徑段.為減少冗余數據存入緩存,本文采用差異多樣性技術來避免緩存存儲大量相似的路徑.現在有關差異性的研究多集中在數據新穎度,或者多目標空間Skyline查詢的問題上,但不適用于本文的場景.雖然也有學者研究路徑多樣性問題,但并不能完全移植到當前問題,因為在道路網中求解具有差異多樣性的路徑是一個NPC問題,除此之外,在不同場景下處理數據方式不一,時間復雜度也不相同.
文獻[29-30]基于閾值剪枝策略來測量路徑的差異多樣性,以此減少路徑查詢以及比較路徑之間相似性的次數.其中,文獻[29]結合閾值約束條件,返回K
條不僅可以兼顧查詢結果總得分還能兼顧查詢結果多樣性的數據,既除掉了結果集中相似的數據又保證了結果的質量.但這種用精確查找的方式來獲取最優結果的耗時較長,與本文提高用戶響應速度的目標背離.文獻[30]通過結合相似度閾值精心地設計了算法的下界,以計算從查詢源點到目標點的前Top-K
條不相似的最短路徑,有效地減少了搜索空間并顯著提高了效率.不同于文獻[29-30],本文在引入差異多樣性策略的同時,采用貪心思想實現最大化存入緩存的K
條最短路徑的收益,進而減少服務器的計算量.
其中存入緩存的K
條路徑來自不同查詢結果,是互不相關的路徑集合,這些路徑既存在差異性,又存在共同節點,便于路徑緊密聯系.
此處,緩存中的路徑數量K
并非固定數值.2 定 義
本節重點介紹基于緩存的時變道路網最短路徑查詢的相關理論.表1描述了基本符號.

Table 1 Summary of Notation
2.1 基本定義
定義1.
時變道路網模型.
時變道路網G
=(V
,E
,W
,T
),其中V
和E
分別表示G
的節點集和邊集,節點v
∈V
,邊e
=(v
,v
)∈E
,函數W
:E
×T
→RV
表示邊集E
在時刻T
的權重映射函數,其中邊e
=(v
,v
)的時間權重為w
(v
,v
).
定義2.
最短路徑.
給定道路網G
=(V
,E
,W
,T
),G
上從v
到v
的所有路徑中,具有最短旅行時間的路徑P
,被稱為最短路徑P
,其中節點v
,v
∈V.
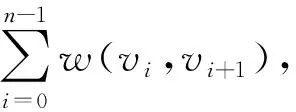
定義3.
查詢請求.
在道路網G
=(V
,E
,W
,T
)上,由用戶終端發出查詢請求Q
,用于查詢從v
∈V
到v
∈V
的最短路徑P
.
其中v
稱為Q
的查詢源點,v
稱為Q
的查詢目標點.
定義4.
緩存空間容量.
給定緩存C
,C
中所有最短路徑的集合為ψ.
其中,C
的空間容量為|C
|,C
中數據的占用空間為|ψ
|≤|C
|.
定義5.
完全命中、部分命中及未命中.
給定緩存C
和查詢請求Q
,完全命中表示C
的最短路徑集ψ
中至少存在一條包含節點v
,v
的最短路徑,完全命中的路徑集可形式化為ц(P
)={P
,|(v
∈P
,)∧(v
∈P
,)∧ (v
≠v
),P
,∈ψ
};部分命中表示ψ
中至少存在一條包含節點v
或v
的最短路徑,部分命中v
的路徑集可形式化為ц(v
)={P
,|(v
∈P
,)∧(v
?P
,),P
,∈ψ
};否則稱為未命中,即ψ
中不存在包含節點v
或v
的最短路徑P
,未命中可形式化為?P
∈ψ
,(v
?P
)∧(v
?P
)∧(v
≠v
),其中,完全命中意味著ψ
中至少存在一條最短路徑的子路徑作為Q
的結果.
由文獻[20]提出的最優子路徑性質可知,最短路徑的子路徑也是最短路徑,故完全命中獲得的路徑可以保證命中結果的準確性.
定義6.
連接路徑.
給定最短路徑P
,和P
′,′,節點v
,v
∈P
,,v
,v
∈P
′,′,存在子路徑〈v
→…→v
〉?P
,和〈v
→…→v
〉?P
′,′,?表示路徑間的包含關系.
通過v
連接2條子路徑組成一條從v
到v
再到v
的新路徑,該路徑稱為連接路徑JPath
(v
,v
)=〈v
→…→v
→…→v
〉.
其中連接路徑JPath
(v
,v
)可近似為最短路徑P
,用于應答查詢請求Q
,減少服務器的計算量.
2.2 問題定義
本節給出CTSPQ問題的形式化定義.
定義7.
CTSPQ
(G
,v
,v
,C
,T
,T
).
給定節點v
,v
∈G
,C
為時刻T
的緩存,T
為每條最短路徑在C
中滯留的最長時間.
記ψ
為時刻T
之前存入C
的n
條最短路徑集合,Ω
為時刻T
待存入C
的m
條最短路徑集合,Sh
為Pi
∈(ψ
∪Ω
)的共享能力,t
為Pi
存入C
的時刻.
0-1變量x
表示Pi
是否存儲于C
中,x
=1表示Pi
存于C
中,x
=0表示Pi
未存C
中,并記X
=(x
1,x
2,…,x
(+)).
CTSPQ的目標是最大化緩存C
中最短路徑集ψ
的收益B
(ψ
,Ω
,T
,T
),并以在線的形式在C
中快速規劃出一條從v
到v
的最優最短路徑P
,使得服務器的計算量最小.
其中,B
(ψ
,Ω
,T
,T
)滿足:
(1)
緩存技術之所以能提高路徑查詢速度是因為其可以降低服務器對數據庫的讀操作.
因此,能否較好地解決CTSPQ問題取決于C
中ψ
的收益,即緩存收益越大,命中越高.
此外,加入緩存C
的路徑數量有限,若C
中的數據無法應答從v
到v
的查詢請求,則可從服務器中查詢并獲取最短路徑P
.
由式(1)可知,求解緩存最大收益問題的時間復雜度為O
(n
|C
|),是一個偽多項式問題.
其計算成本較高,因此本文將采用貪心思想計算緩存中數據的最大收益,以減少構建緩存的計算時間.
3 基于緩存的時變最短路徑緩存查詢算法
本節首先介紹基于緩存的時變道路網最短路徑查詢算法CTSPQ的總體框架.如圖1所示,框架包含3個模塊:查詢請求檢測模塊、最短路徑評估模塊和緩存管理模塊.首先從用戶終端發出具有真實地理坐標源點v
(lat
,lng
)和目標點v
(lat
,lng
)的查詢請求Q
(步驟①);通過查詢請求模塊將v
(lat
,lng
),v
(lat
,lng
)映射為節點v
,v
∈G
,以轉化為G
上的查詢請求,繼而從緩存C
中獲取Q
完全命中或部分命中的路徑作為候選路徑集(步驟②~④);然后,在最短路徑評估模塊判斷候選路徑集中是否存在有效應答Q
的路徑,若是則將一條近似最優的路徑返回用戶終端,否則從代理服務器檢索Q
的最短路徑,并返回到用戶終端(步驟⑤~⑧);此外,緩存管理模塊中的緩存結構用于存儲數據,緩存存儲策略決定從服務器獲取的實時最短路徑是否能存入C
(步驟⑨~⑩).
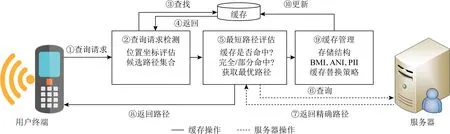
Fig. 1 CTSPQ schematic diagram圖1 CTSPQ框架示意圖
3.1 緩存管理模塊
構建索引是加速最短路徑查詢的主要技術之一,在數據的檢索和存儲中起著重要作用.因此本文在本模塊中設計了便于更新緩存數據的索引結構以及提高緩存命中率的路徑緩存存儲策略,以快速響應時變環境下的查詢請求,減少服務器的工作負載.
如圖1所示,無論執行哪個模塊,只要執行操作皆離不開緩存中的數據.即一旦觸發其他模塊,緩存管理模塊也隨之觸發.
3.1.1 緩存存儲結構
圖2展示了一個簡單緩存最短路徑的例子.根據圖2(a)的子圖得到了圖2(b)的5條最短路徑,并按照路徑節點的旅行順序將路徑存入緩存列表,如路徑P
=〈v
→v
→v
→v
〉存放節點的順序為v
,v
,v
,v
.
當存在查詢請求Q
時,首先判斷緩存列表中的路徑是否存在從由v
到v
的子路徑,若是則直接應答Q
.
如查詢請求Q
可由圖2中的P
應答.
雖然此存儲方式可應答查詢請求,但會導致緩存出現大量的冗余數據,如v
存儲了3次,v
存儲了4次,甚至出現了冗余路徑,如P
是P
的子路徑.
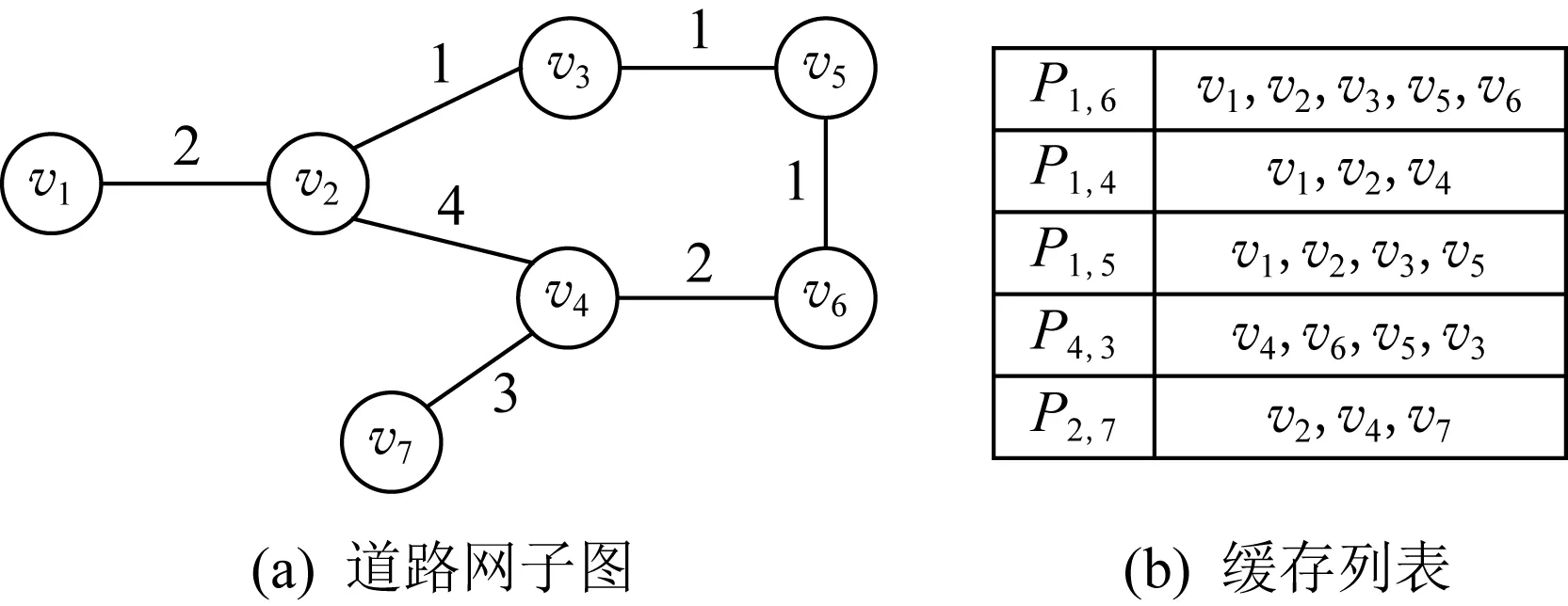
Fig. 2 An example of simple cache storage圖2 簡單緩存實例圖
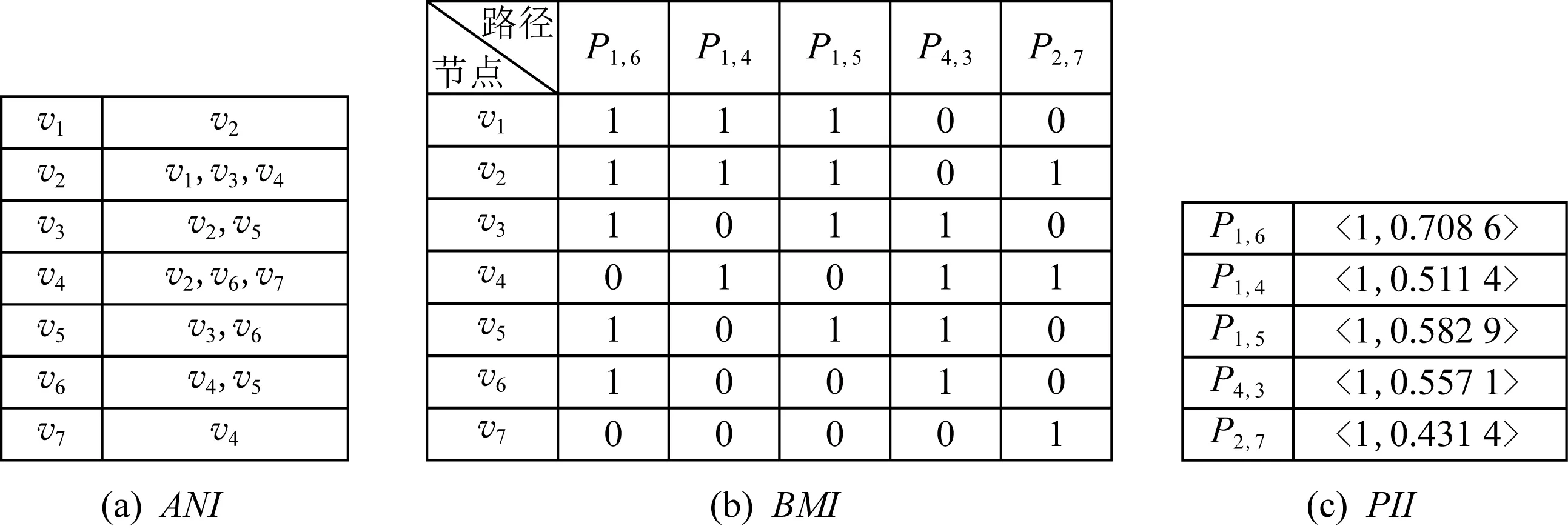
Fig. 3 An example of the AMPS storage path圖3 AMPS存儲路徑示意圖
因此,為減少數據的存儲空間,本文設計了一個數據弱相關、結構緊密的緩存存儲結構.該結構由存儲節點的鄰接點索引(adjacency node index,ANI
)、存儲路徑的位圖索引(bit map index,BMI
)以及記錄路徑基本信息的路徑信息索引(path information index,PII
)等3部分組成,并簡稱為AMPS.圖3展示了以AMPS形式存儲圖2中5條最短路徑的例子.1) 鄰接點索引ANI.
ANI
記錄了緩存C
中每條路徑節點的鄰接點關系,記為鄰接點對〈v
,v
〉,并為返回一條有序的最短路徑做準備.
其中,每個鄰接點對在ANI
中最多存儲一次,表示C
中至少存在一條從v
到v
(或從v
到v
)的路徑.ANI
引用了文獻[8]的模型,它無需存儲G
上所有鄰接點對關系,減少了冗余數據存入C.
以圖3(a)為例,v
的鄰接點有v
,v
和v
,存在路徑P
,P
經過v
到達v
;P
,P
經過v
到達v
.
雖無路徑經過v
到達v
,但存在經過v
到達v
的路徑P
,P
和P
,故ANI
記錄了鄰接點對〈v
,v
〉的關系.
2) 位圖索引BMI.
BMI
以位圖形式記錄了最短路徑P.
如圖3(b)所示,存在于路徑上的節點用“1”標注,否則標注為“0”,其中路徑P
=〈v
→v
→v
〉上的節點v
,v
,v
在BMI
中被“1”標記.
因為位圖可以執行二進制操作,因此BMI
可以快速識別查詢請求的候選路徑,并快速判斷C
中數據所涉及的節點.
以圖3(b)為例快速識別Q
和Q
的候選路徑.
令操作BMI
(v
)表示求解節點v
所在的路徑集合,請求Q
通過執行BMI
(v
)∩BMI
(v
)={P
,P
}得到完全命中的候選路徑集;而Q
執行BMI
(v
)∩BMI
(v
)=?,無完全命中的候選路徑集,但可以通過部分命中操作獲取與源點v
和目標點v
相關的2個部分命中候選路徑集BMI
(v
)={P
,P
},BMI
(v
)={P
},根據候選路徑集執行連接操作獲得應答Q
的連接路徑,即通過v
連接候選路徑P
和P
獲得答查詢請求的候選連接路徑JPath
(v
,v
)=〈v
→v
→v
→v
〉.
3) 路徑信息索引PII.
PII
記錄了ψ
中每條路徑P
的基本信息〈t
,Sh
〉,用于更新緩存C
中的數據,以保證從緩存中得到有效的查詢結果.
其中t
表示P
加入C
的時刻、Sh
表示P
的共享能力(見定義8).
利用t
計算P
在C
中滯留的時長,當時長超過T
時,從C
中移除P
;Sh
用于判斷P
是否被新路徑置換,因為路徑共享能力是反映路徑受歡迎程度和重要性的指標,是計算緩存收益的主要影響因素.
定義8.
路徑共享能力.
給定道路網G
=(V
,E
,W
,T
)上的一條最短路徑P
=〈v
→v
→…→v
〉,P
的路徑共享能力記做Sh
.
歸一化的Sh
可形式化為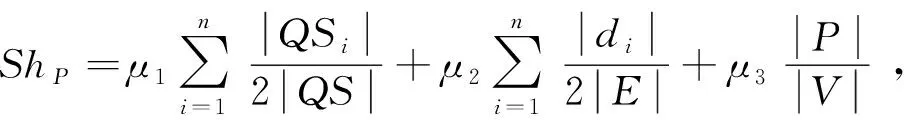
(2)
其中,0≤μ
,μ
,μ
≤1,μ
+μ
+μ
=1;QS
為當前G
中所有查詢請求的集合,|QS
|為QS
中請求的數量;|QS
|為節點v
∈P
在QS
的源點集和目標點集中出現的次數;|d
|為節點v
∈V
的度數;|E
|表示邊E
的數量;|V
|為節點集V
中節點的數量;P
的節點數量為|P
|=n.
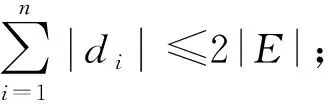
G
′,令圖2(b)中最短路徑的查詢請求為查詢請求集QS
,μ
=0.
4,μ
=0.
2,μ
=0.
4;故|QS
|=5,|E
|=7,|V
|=7.
若求解P
=〈v
→v
→v
→v
→v
→v
〉共享能力,可知
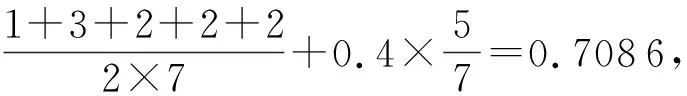
.
算法1展示了在時刻T
將最短路徑P
加入緩存C
的偽代碼.
假設P
的共享能力為Sh
,首先獲取C
中AMPS的數據(行①);接著依次遍歷P
上的節點v
及其鄰接點v
+1∈P
,并將2點添加至BMI
,ANI
中,其中,若ANI
中已存在鄰接點對〈v
,v
+1〉的信息,則無需對索引ANI
進行操作(行②~④).
最后將P
的信息〈T
,Sh
〉存入PII
,并返回C
(行⑤~⑥).
算法1.
插入算法Insert
(P
,C
,T
,Sh
).
輸入:新路徑P
、緩存C
、當前時間T
、共享能力Sh
;輸出:緩存C.
①ANI
,BMI
,PII
←get
(C
);/
*從緩存C
中獲取索引信息*/
② for each nodev
inP
③add
(ANI
,BMI
,v
,v
,P
);/
*分別在ANI
,BMI
中添加鄰接點對〈v
,v
+1〉及路徑v
∈P
信息*/
④ end for
⑤addPII
(PII
,T
,Sh
);/
*將P
的信息加入PII
*/
⑥ returnC.
以圖3為例,令T
=1,|ψ
|=0,此時向C
中添加共享能力為0.
511 4的最短路徑P
=〈v
→v
→v
〉.
首先從v
開始,在ANI
中加入v
的鄰接點v
,v
的鄰接點v
,在BMI
中用“1”標注v
∈P
;然后在ANI
中加入v
的鄰接點v
,v
的鄰接點v
,在BMI
中用“1”標注v
∈P
;循環上述步驟,直至用“1”標注v
∈P
;最后在PII
中添加P
的信息〈1,0.
511 4〉.
算法2.
刪除算法Delete
(P
,C
,T
).
輸入:刪除路徑P
、緩存C
、當前時間T
;輸出:緩存C.
①Z
←空棧,D
←空集合;②ANI
,BMI
,PII
←get
(C
);/
*從緩存C
中獲取索引信息*/
③v
′←random
(P
);/
*隨機獲取P
上的一個節點*/
④Z.push
(P
,v
′,D
);/
*將節點v
′入棧Z
*/
⑤ while 棧Z
中存在元素時⑥v
←Z.pop
();/
*出棧Z
中的元素放入v
*/
⑦ if節點v
′和v
當且僅當存在于路徑P
⑧delete
(ANI
,v
,v
′ );/
*在ANI
中刪除鄰接點對〈v
,v
′ 〉的信息*/
⑨ end if
⑩D.add
(v
);/
*記錄已刪除的節點*/

Z
*/


/
*刪除PII
,BMI
中P
*/

3.1.2 緩存收益模型
求解緩存最大收益問題是NPC問題,本文首先采用簡單的Baseline策略構建緩存數據.Baseline策略結合了貪心思想,將路徑共享能力近似為路徑存入緩存的收益,在保證在較高命中率的前提下,減少存儲過程的計算量.Baseline策略首先按照待加入緩存的最短路徑共享能力以從大到小的順序依次加入緩存C
,直到C
中無多余空間存入新路徑,因此Baseline的時間復雜度為O
(n
lgn
).
以圖4說明采用Baseline策略構建路徑緩存C
的方法.
在道路網子圖G
′上,首先為方便計算C
中數據的占用空間|ψ
|,舉例時僅考慮PII
及ANI
的占用空間.
令一個節點的占用空間為1,一條PII
信息占用空間為2,T
=6,初始化|ψ
|=0,|C
|=16.
在T
=1時,待加入C
的3條最短路徑的共享能力的大小依次是Sh
>Sh
>Sh
.
故首先確定P
加入C
需要在ANI
中增加10個節點(5個鄰接點對),故將P
加入C
時|ψ
|=10+2<|C
|;接著P
是P
的子路徑,只需增加PII
信息,加入C
時|ψ
|=12+2<|C
|;最后判斷P
加入C
還需在ANI
中新增鄰接點對〈v
,v
〉,占用4個空間,而|ψ
|+4=18>|C
|,故P
不被加入C.
此時緩存中的共享能力總和為0.
861 9+0.
695 2=1.
557 1,并且可以應答路網上v
~v
之間的查詢請求.
雖然采用Baseline策略可以減少構建緩存的計算量,但是無法避免子路徑等冗余數據存入緩存,如P
是P
的子路徑.
然而道路網中訪問頻率高的路徑,其子路徑也往往具有較高的訪問頻率,這些子路徑極易存入緩存.
因此在第3.
1.
3節改進了Baseline策略.

Fig. 4 Example diagram of TSPC strategy圖4 TSPC策略實例圖
3.1.3 改進存儲策略
本節為優化Baseline策略提出了時變最短路徑緩存(time-varying shortest path cache, TSPC)策略.該策略在Baseline的基礎上結合了差異多樣性技術,在保證緩存路徑有效的前提下,盡可能使得緩存中的任意2條路徑不相似,以減少緩存中的冗余數據,達到提高緩存命中率的效果.
衡量數據相似度常用的方法為Jaccard相似系數,但Jaccard適用于衡量路徑重合度而差異性.故本文改進相似度度量方法來判斷緩存路徑的相似性.
定義9.
相似度度量.
給定最短路徑P
和P
以及相似度約束值τ
,P
和P
相似度為
(3)
其中,|S
(P
)∩S
(P
)|表示P
和P
具有一樣節點的數目;min(|P
|,|P
|)表示P
和P
之中擁有較少節點數量的數值;τ
的取值范圍為[0,1].
與Jaccard略為不同,本文相似度度量方法選擇min(|P
|,|P
|)作為分母,它可以清楚地感知較多節點數目的路徑能夠作為較少節點數目路經的共享路徑.
其中,τ
值的大小決定緩存中路徑間最高相似度,τ
值越大冗余數據越多.
TSPC策略的最壞時間復雜度為O
(kn
+n
lgn
),其中k
表示|ψ
|=k
,n
表示在時刻T
待加入緩存的最短路徑數量,O
(n
lgn
)表示排序的時間復雜度,O
(kn
)表示構建k
條互不相似最短路徑的最大開銷.
而最優時間復雜度是O
(n
lgn
),即共享能力最大的前k
條最短路徑兩兩不相似.
以圖4為例說明TSPC策略構建緩存C
的方法.
為方便與Baseline策略進行比對,TSPC的初始條件與Baseline一致,除此之外,令τ
=0.
7.
當T
=1時,首先對待加入C
的3條最短路徑按照其共享能力排序,即Sh
>Sh
>Sh
.
由TSPC策略可知,先將P
加入緩存C
,此時|ψ
|=12<|C
|;接著判斷P
與C
中路徑集ψ
的相似度,由Sim
(P
,P
)=1>τ
可知,C
拒絕P
的加入;接著判斷P
與C
中ψ
的相似度,即Sim
(P
,P
)=2/
3<τ
,此時將P
加入C
需在ANI
中新增鄰接點對〈v
,v
〉,占用空間為|ψ
|+4=16≤|C
|,故將P
加入C.
雖然緩存的共享能力總和為0.
861 9+0.
523 8=1.
385 7<1.
557 1(Baseline策略1.
557 1),但緩存C
中的數據不僅可以應答Baseline策略可應答的查詢,還可以通過構建連接路徑應答與v
有關的查詢請求,提高了緩存的命中率.
此外,當T
=7時,待加入C
的2條最短路徑的共享能力為Sh
>Sh
.
首先由T
-T
=1可知,在1時之前加入C
的路徑已逾時,故清空緩存C
,|C
|=0.
接著將P
加入C
,空間容量|ψ
|=10<|C
|,然后判斷P
與C
中ψ
的相似度,Sim
(P
,P
)=2/
3<τ
滿足約束條件,還需在ANI
中增加鄰接點對〈v
,v
〉、PII
中增加基本信息,|ψ
|+4=14<|C
|,故可將P
加入C.
算法3.
TSPC更新緩存算法Update
(C
,P
,T
,T
,τ
).
輸入:緩存C
、最短路徑P
、當前時間T
、最大滯留時間T
、相似度閾值τ
;輸出:緩存C.
①Z
←空優先隊列,D
←空優先隊列;②Sh
←根據式(2)計算路徑P
的共享能力;③ for eachPi
inC
④ ifT
-t
≥T
⑤Delete
(Pi
,C
,T
,Sh
);/
*刪除路徑Pi
*/
⑥ else ifSim
(Pi
,P
)>τ
且Sh
<Sh
⑦Z.push
(Pi
);/
*將路徑Pi
入隊Z
*/
⑧ else ifSh
<Sh
⑨D.add
(Pi
);/
*將路徑Pi
入隊D
*/
⑩ end if
/
*刪除緩存C
中與Z
有關的路徑*/
/
*將P
加入緩存C
*/


/
*將緩存C
中與Z
相關的路徑刪除*/

/
*出隊D
中的路徑并刪除緩存C
與其相關的數據,直至緩存容量滿足|C
|≥|ψ
+P
|*/


3.2 查詢請求檢測模塊
本模塊用于識別緩存中可應答查詢請求的候選路徑集.在位置坐標評估時需執行節點映射操作,是因為真實地理空間中的坐標是連續不斷的,而現有的存儲設備無法將所有坐標點存入存儲設備,所以首先將連續坐標點映射成離散點.
映射可以將查詢節點變得規范,不僅可以快速確定查詢請求能否在緩存中命中路徑,還可以識別同一批次中查詢結果相同的查詢請求,通過共享一個結果,減少查詢次數.
為快速定位地理空間坐標點在G
上的位置,本文采用KD-Tree索引映射二者之間的關系.與基于網格均勻劃分區域空間的方式不同,KD-Tree將節點多的區域分割更加細致,節點少的區域分割更加粗糙.以此來提高映射的效率,為批量處理提供條件.在獲取應答Q
的候選路徑集時,只需通過當前緩存中BMI的信息查詢與源點v
和目標點v
相關的路徑,即獲得部分命中的候選路徑集ц(v
)和ц(v
),以及完全命中的候選路徑集合ц(P
).
3.3 最短路徑評估模塊
本模塊用于評估從查詢請求檢測模塊得到的候選路徑集能否應答查詢請求.本模塊可以通過執行直接查詢操作(direct query operation, DQO),選擇一條最優路徑應答查詢請求,或者通過執行連接查詢操作(join query operation, JQO)獲取一條連接路徑用于應答查詢請求.若2種操作皆無法獲取應答查詢請求的路徑,則只能通過代理服務器獲取最短路徑.
直接查詢操作DQO表示從ц(P
)中選擇一條距離當前時間最近的最短路徑應答Q
.
DQO可形式化為DQO
(ц(P
),T
,T
),滿足: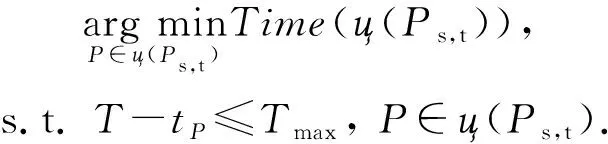
(4)
連接查詢操作JQO表示從ц(v
)及ц(v
)中各任選一條路徑P
∈ц(v
),P
′∈ц(v
)來組成連接路徑JPath
(v
,v
)應答Q
.
其中,JPath
(v
,v
)需要滿足時間約束T
以及歐氏距離約束EDR
(v
,v
,v
).
JQO形式化為JQO
(v
,v
,θ
,T
,T
),滿足: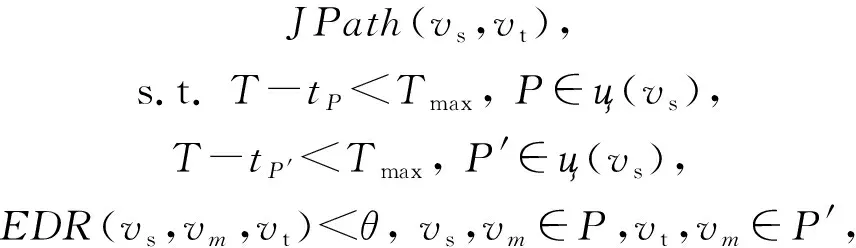
(5)
其中,JQO引入距離約束閾值θ
,是因為連接路徑JPath
(v
,v
)的連接點v
可能偏離最短路徑P
,并出現在很遠的位置,此時連接路徑的旅行時間將變得不可靠.
為避免連接路徑的偏離,故設置歐氏距離比來控制v
的偏離程度,即: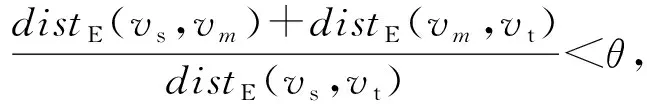
(6)
表示從v
到v
和v
到v
的歐氏距離之和與v
到v
的歐氏距離比小于θ.θ
的大小影響連接路徑的旅行時間,θ
越小連接路徑的長度越趨近于最短路徑,但當θ
=1時并不一定是最短路徑.
算法4.
查詢算法CTSPQ
(C
,Q
,G
,θ
,T
).
輸入:緩存C
、查詢請求Q
、道路網G
、歐氏距離比θ
、最大滯留時間T
;輸出:最短路徑P.
① ц(v
),ц(v
)←空棧;P
←空集;sign
←false;PII
,ANI
,BMI
←從緩存C
中獲取數據信息;
②v
,v
←KD
-tree
(Q
,G
);/
*查詢請求映射*/
③ ц(v
)←BMI
(v
);/
*獲取v
所在的路徑*/
④ ц(v
)←BMI
(v
);/
*獲取v
所在的路徑*/
⑤ if ц(v
)∩ц(v
)的路徑集合不為空⑥P
←DQO
(v
,v
,T
,T
);/
*見式(4)*/
⑦ returnP
;/
*返回路徑P
*/
⑧ else
⑨P
←JQO
(v
,v
,ц(v
),ц(v
),θ
);/
*見式(5)*/
⑩ if 存在連接路徑P
/
*從服務器獲取路徑*/
T
發出查詢請求Q
,首先將Q
的源點和目標點映射到道路網子圖G
′上的節點v
和v
,然后在索引BMI
中執行部分命中操作BMI
(v
)={P
,P
,P
},BMI
(v
)={P
,P
,P
}獲取候選路徑集ц(v
),ц(v
)和ц(P
),在ц(P
)中存在路徑P
滿足|t
4,3-T
|<T
,即滿足DQO約束,故可以直接向用戶端返回路徑P
.
路徑P
的旅行次序可以結合索引BMI
和ANI
中的數據獲得.
而獲取旅行次序的過程與刪除過程相似,繼續以P
為例說明如何確定路徑走向.
令D
記錄已檢索鄰接點的節點,Z
記錄已訪問但未檢索鄰接點的節點,第1步,通過random
(P
)函數隨機獲取節點v
為P
檢索起點,Z
={v
};第2步,根據ANI
檢索既在P
上又是v
鄰接點的節點{v
,v
},此時D
={v
},Z
={v
,v
}.
第3步,Z
出棧v
,在P
上v
的鄰接點集為{v
},v
∈D
已被訪問,且無其他鄰接點,故可確定P
的一段子路徑為〈v
→v
〉,此時D
={v
,v
}、Z
={v
}.
同理,Z
出棧v
,找到v
鄰接點v
,v
,而v
∈D
已被訪問,得到P
的另一段子路徑〈v
→v
→v
〉,此時D
={v
,v
,v
},Z
={v
}.Z
出棧v
,其在P
上的鄰接點為{v
},而v
∈D
,Z
=?,已遍歷上的P
所有節點,故通過檢索起點v
連接2條子路徑段可確定P
的旅行方向為〈v
→v
→v
→v
〉.
4 實驗分析
本節通過在真實數據集上進行大量實驗,驗證了所提算法的有效性及可擴展性.
4.1 實驗設置
本文實驗環境見表2,采用的編程語言為Java.此外在相同的環境下,本文分別對SPC,EPC,Baseline,TSPC策略方法進行了對比測試.

Table 2 Experiment Environment
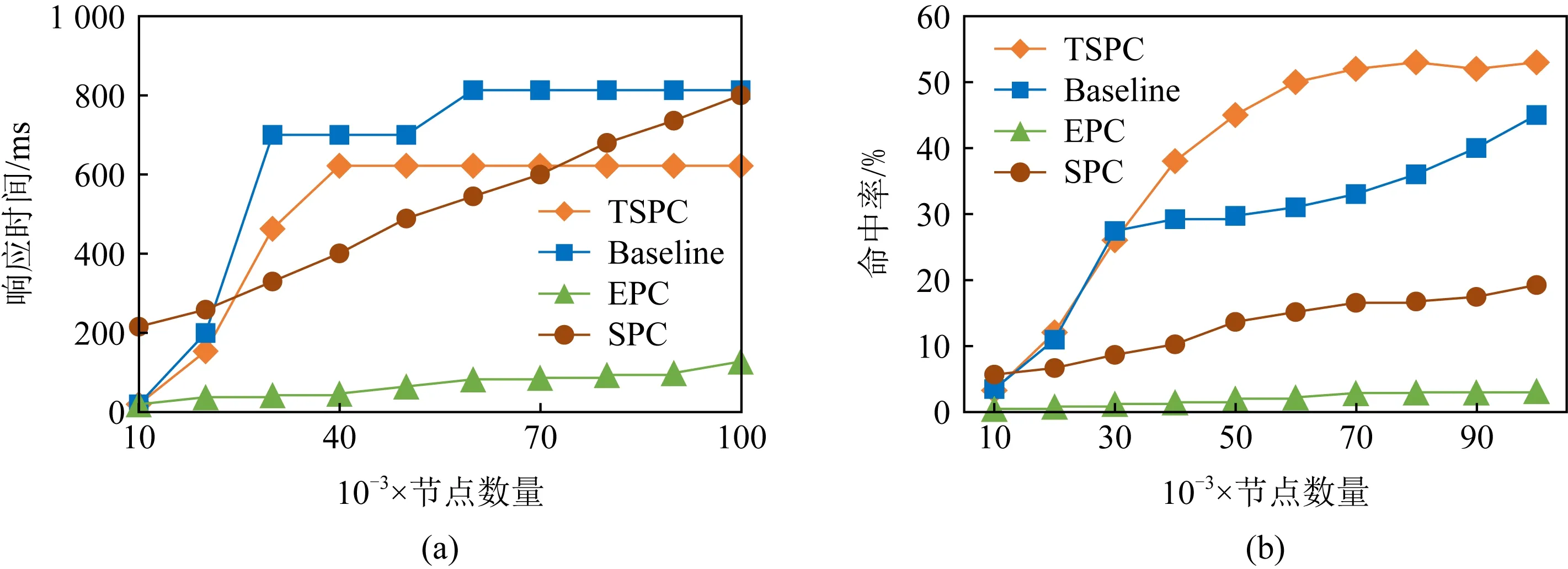
Fig. 6 Effect of cache size圖6 緩存大小的影響
4.2 數據集
本文使用的實驗數據集來自文獻[25],利用加利福尼亞州道路網上的真實數據集進行實驗.該網絡具有真實的興趣點,包含了21 693條邊、21 048個節點和104 770個興趣點.我們從興趣點中隨機選擇2點作為測試的源點和目標點,用于生成時空路徑進行實驗,此外,測試部分的數據除了來自文獻[25]之外,還有來自必應地圖的實時查詢數據.在實驗過程中利用必應地圖的API作為提供準確的最短旅行時間的服務器.在測試之前我們隨機獲取某一時刻的查詢來預熱緩存.
本文所涉及的實驗若無特殊說明則代表緩存最多可容納的節點數為50 000(每個節點占4 B),緩存中所有數據的總容量不超過1 MB,同一時刻下的查詢請求數量設為10 000,構建緩存的候選路徑數量設為10 000,相似度閾值設為0.7,距離約束設為1.05.T
=15,緩存中路徑滯留時間最大為15 min.4.3 實驗結果
4.3.1 映射
將地理坐標點映射到道路網G
的過程中,本文采用了KD-Tree算法.KD-Tree劃分的層級越多,映射結果越準確,為了更準確地識別數據,本文對道路網進行了精確的分割識別,在保證結果正確的前提下,可快速識別基于位置服務的點在G
中的位置.圖5描繪了Gird,KD-Tree,linear等方法在不同大小數據集下運行的時間.采用KD-Tree方法的映射速度明顯優于Gird和linear方法.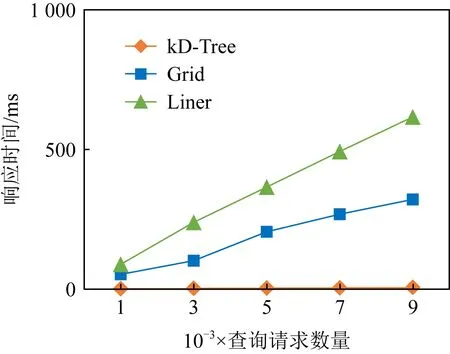
Fig. 5 Response time of different mapping methods圖5 不同映射方法的響應時間
4.3.2 緩存大小
緩存容量的大小關乎整個系統的性能.緩存容量越小,命中率越低,但當緩存容量過大時,雖然命中率會明顯提高,但會降低查詢速度.
圖6展示了不同緩存大小下SPC,EPC,Baseline,TSPC等算法的查詢響應時間以及命中率,其中查詢響應時間由映射過程時間以及在緩存中獲取路徑的時間組成.在圖6(a)中,當緩存|C
|>30 000時, 雖然EPC策略在緩存中的總耗時為TSPC,Baseline策略的10%~20%,但EPC在緩存中的命中率是TSPC和Baseline命中率的4%左右.綜合分析,本文策略的整體效率較優.在圖6(b)中,隨著緩存容量的增加,TSPC的命中率逐漸趕超Baseline的命中率.是因為受相似度的約束,TSPC緩存的節點種類比Baseline的多,可通過連接操作得到應答查詢請求的路徑.正因相似度約束,TSPC緩存的數據量并不會因為緩存容量的無限擴大而增加,緩存中的數據量會維持在一個范圍內.
4.3.3 參數θ
分析由三角形三邊關系可知,在連接操作中引入歐氏距離比閾值θ
,意味著連接路徑的長度不會被無線延伸,可避免偏差較大的候選路徑.圖7顯示了在不同θ
下緩存的命中率及路徑查詢結果的準確度,θ
的取值范圍為[1.00,1.10].由圖7(a)可知隨著θ
約束力度的放寬,以連接路徑的形式應答查詢請求的數量增多,命中率有較大的提升,但結果會出現較大的偏差.而在允許有10%的偏差下,TSPC和Baseline策略的命中率提升為90%以上,故在誤差允許的范圍內使用TSPC和Baseline可提高服務器的整體運行效率.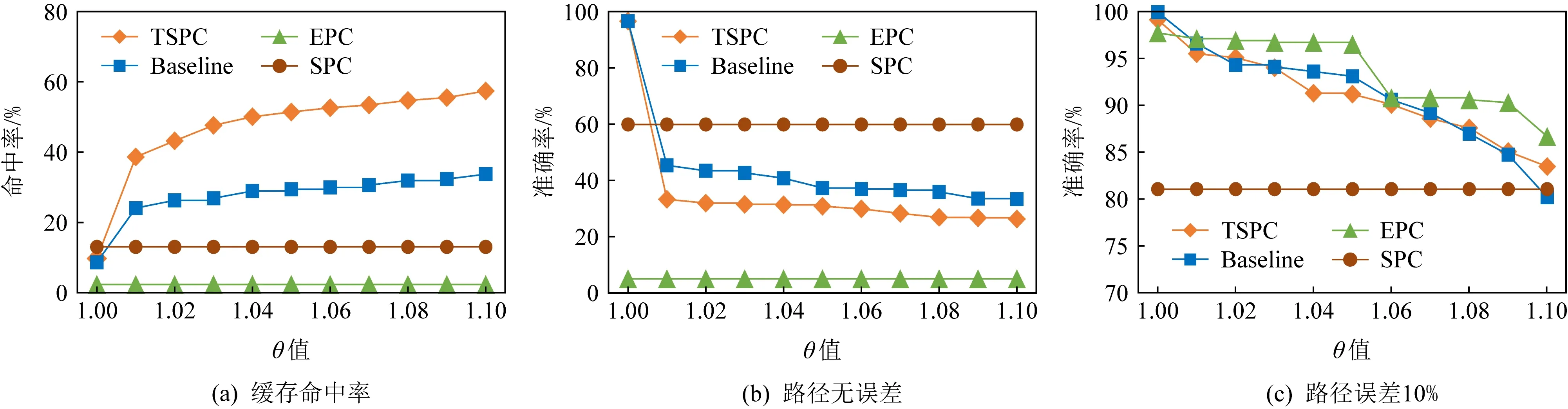
Fig. 7 Effect of θ圖7 θ值的影響

Fig. 8 Effect of τ圖8 τ值的影響
4.3.4 參數τ
分析圖8顯示了不同相似度閾值τ
下的命中率以及準確率,τ
值大小影響緩存中路徑的多樣性.
當τ
=0時,表示緩存中的數據集不存在相同節點,也就意味著當執行查詢操作時,緩存路徑只能進行完全命中操作,此時準確率達到最高;當τ
=1時,緩存中的存儲的路徑不再受到相似度的約束,而是僅受到緩存容量的限制,即為Baseline操作.如圖8(a)所示,當τ
∈[0.5,0.7]時,TSPC的緩存命中率遠比未采用相似度約束的算法高,故相似度約束可明顯改善小容量緩存的命中率.圖8(b)~(c)顯示了不同τ
值下命中結果的準確率,雖然TSPC和Baseline策略在無誤差情況下的準確率低于SPC的準確率,但是在τ
=0.7時其命中率近似于SPC命中率的3倍,此外在容許存在10%誤差的情況下,準確率達到90%以上.5 總 結
針對時變道路網中在線查詢最短路徑效率慢的問題,本文利用緩存減少服務器的工作負載,首先為降低數據占用緩存空間,設計了一個緩存存儲結構;其次,為實時地構建路徑緩存提出了基于貪心策略和相似度約束的緩存存儲策略,提高了緩存的命中率;最后根據存儲結構中的索引特性,設計了一個利用緩存高效應答最短路徑查詢的算法.最終通過大量實驗結果表明了本文所提的算法具有有效性和高效性.
作者貢獻聲明
:黃陽負責實驗及論文的起草;周旭、楊志邦提出算法優化方案,為共同通信作者;余婷、張吉負責索引設計及文字潤色;曾源遠、李肯立負責實驗方案及論文整體架構設計.猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
