改進遺傳算法的RBF神經網絡控制研究*
2022-02-11 09:45:10周勇
科技與創新 2022年2期
關鍵詞:優化
周勇
(荊州學院信息工程學院,湖北 荊州 434020)
RBF(徑向基函數)神經網絡是具有單隱層的一種三層前向神經網絡,其具有網絡結構簡單、學習速度快、逼近能力強等特點,在系統辨識、函數逼近、模式識別等領域得到廣泛應用。RBF神經網絡具有模擬人腦中局部調整、相互覆蓋接收域的神經網絡結構,能以任意精度逼近任一連續函數[1],一直是研究的熱點之一。RBF神經網絡在學習過程中,其性能主要取決于隱層神經元基函數中心、寬度和隱層節點到輸出層之間的連接權值的整定。目前,RBF神經網絡的參數整定方法主要有K均值聚類方法、梯度下降法、粒子群算[2]、進化算法[3]等,其中,普通梯度下降法在訓練過程中極易出現振蕩、不穩定的情況,而且實時性和魯棒性較差[4]。其他方法如粒子群算法、進化算法等,雖然有一定的全局收斂能力,但收斂速度慢,網絡計算代價大。遺傳算法(Genetic Algorithm,GA)是一種高度并行的隨機優化方法,具有很好的全局搜索能力和魯棒性,然而,遺傳算法雖然應用廣泛,但在解決復雜問題時,由于其自身的隨機搜索特點也帶來了收斂速度慢和算法局部收斂(早熟)等問題[5]。本文在前人研究的基礎上,結合改進的遺傳算法提出一種改進遺傳算法優化的RBF神經網絡控制器,通過系統辨識仿真分析,驗證了其參數優化效果。
1 RBF神經網絡
RBF神經網絡模擬人腦中局部調整、相互覆蓋接收域的神經網絡結構,是一種具有單隱層的三層全局逼近性能的前饋網絡。RBF神經網絡在結構具有從輸入層到隱含層的高斯非線性關系和隱含層到輸出層的權值線性關系,從而使網絡學習快速易行,避免了局部最優的問題。RBF神經網絡結構如圖1所示。
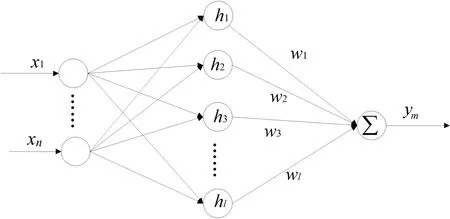
圖1 RBF神經網絡結構
RBF神經網絡一般由3層構成,即輸入層、隱含層和輸出層,其中輸入層節點主要負責傳遞輸入信號到隱含層,隱含層節點由高斯函數組成,對輸入的信號產生局部響應,即當輸入信號接近高斯函數的中央范圍時,隱含層節點產出較大輸出,輸出層節點為各隱含層的輸出加權和,隱含層到輸出層之間的權值可調。
RBF神經網絡的學習包括兩部分:一是高斯函數中心和寬度的確定,另一個是輸出層權值的確定。給定網絡輸入X=(x1,x2,…,xn)為n維向量,RBF神經網絡的輸入層到隱含層實現x→h(x)的非線性映射,即隱含層的變換函數h(x)為一個徑向基函數,其徑向基函數最常采用高斯函數,則RBF神經網絡隱含層第j個節點的輸出為:
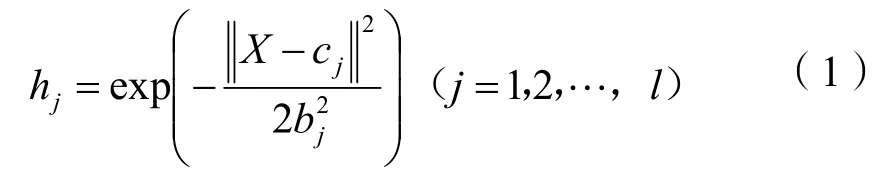
式(1)中:cj和bj分別為第j個隱含層節點的高斯函數中心和基寬參數,bj為大于零的數,它決定了該基函數曲線圍繞中心點的寬度;l為隱含層節點的個數。
假設wj為第j個隱含層節點到輸出層的加權系數(權值),則RBF神經網絡的隱含層到輸出層實現h(x)→yk的線性映射,即:
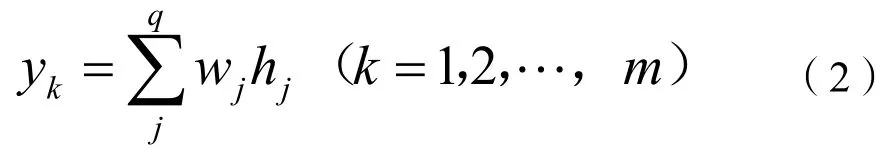
式(2)中:yk為第k個節點的輸出;m為輸出層的節點數。
RBF神經網絡的學習過程是將采集到的數據樣本對神經網絡進行訓練,不斷調整基函數中心c、寬度b和權值w使網絡總均方誤差為最小,即對于N個訓練樣本,RBF神經網絡的希望輸出為d,則總均方誤差函數為:

式(3)中:N為樣本對數;m為網絡輸出節點數;dpk為第k個輸出節點在第l個樣本的希望輸出;ypk為第k個輸出節點在第p個樣本的實際輸出。
2 改進遺傳算法優化RBF神經網絡的實現
遺傳算法(Genetic Algorithm,GA)是美國Holland教授于1975年首先提出來的一種借鑒生物進化理論和門德爾基因遺傳理論的高度并行、隨機的優化方法[6]。在遺傳算法中,交叉和變異算子是算法進化的核心,其交叉率Pc和變異率Pm是算法收斂和穩定的關鍵參數。交叉算子是通過基因重組來獲取優良個體,決定了遺傳算法的全局搜索能力[7]。變異算子是通過改變群體個體基因,使群體具有較好的多樣性,克服早熟。遺傳算法的Pc和Pm反映了算法交叉和變異操作的概率,決定了算法的收斂性能。標準遺傳算法因為隨機搜索的特點,在進化過程中,其Pc和Pm恒定不變,收斂性能較差。結合文獻[8],本文引入一種改進的遺傳算法,使算法的Pc按Sigmoid函數變化,變異率Pm自適應按進化代數變化,提高算法的全局搜索能力和收斂速度。
改進遺傳算法優化RBF神經網絡參數步驟如下。
第一步,編碼及初始化群體。選擇高斯函數中心c、基寬參數b和連接權值w為優化參數,實數編碼,并根據種群規模產生初始群體為[0,1]之間的隨機數。
第二步,解碼,計算種群個體適應度,確定適應度函數F,評價是否滿足收斂條件。目標函數求最大值,則F=f(x),否則,F=1/f(x)。同時,對個體適應度按從小到大進行排序,選出最大個體適應度。改進遺傳算法的適應度函數為F=1/J,J為均方誤差函數E,即f=1/E。
第三步,如果滿足要求(精度1e-5或進化代數T),輸出結果;否則繼續第四步。
第四步,設計遺傳算子。本設計采用輪盤賭的選擇方法,算術交叉和均勻變異的遺傳算子,為了防止遺傳算法的早熟和收斂較差的問題出現,采用改進的自適應交叉概率和變異概率,將S曲線變化模式和進化代數用于交叉概率和變異概率,使個體的變異和交叉分別受進化代數和適應度的約束。改進的自適應調節公式和自適應變化曲線如式(4)(5)和圖2、圖3所示。
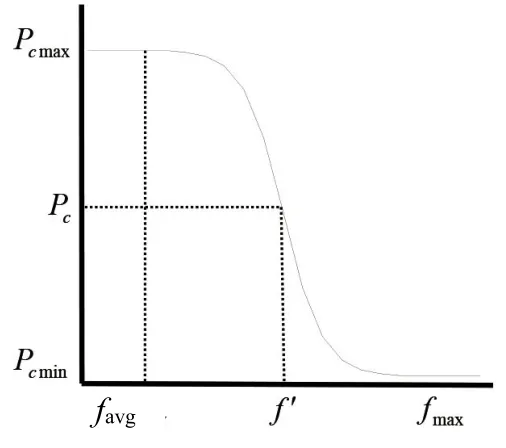
圖2 交叉率調節曲線
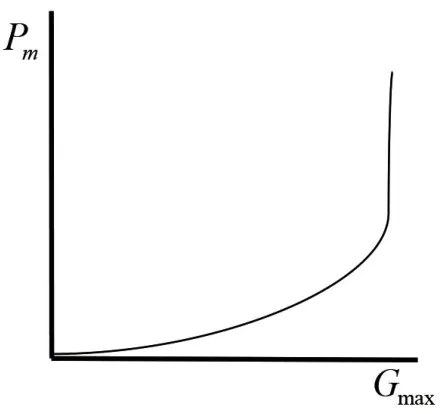
圖3 變異率調節曲線

式(4)(5)中:Pcmax、Pcmin分別為交叉率的最大值和最小值;f'為要交叉的2個個體中較大的適應度值;k1為曲線平滑參數,用來調節曲線的光滑程度;favg為種群的平均個體適應度值;fmax為種群中最大的個體適應度值;Pm1、Pm2和Pm3都是正實數;Gmax為最大進化代數;G為當前進化代數。
由圖2、圖3和改進的公式(4)(5)可知,Pc按照個體適應度在favg和fmax之間隨S曲線進行非線性調整,Pm按進化代數進行非線性調整。在種群進化初期,保證了當前種群優良個體Pc和Pm較小,使算法收斂速度變慢。同時,隨著進化代數的增加,當大多數個體適應度與favg接近時,使個體Pc最大,進化代數最大時Pm也趨近于最大,避免了算法停滯不前。在個體適應度接近fmax時,盡可能緩慢地減小個體Pc,使Pc最小,最大限度地保留favg處的優良個體,克服算法早熟和局部收斂。
第五步,根據favg、個體適應度和進化代數,結合自適應調節公式進行交叉和變異操作。
第六步,返回第二步,如達到指定要求,算法結束,否則繼續執行操作。
改進遺傳算法RBF參數優化流程如圖4所示。
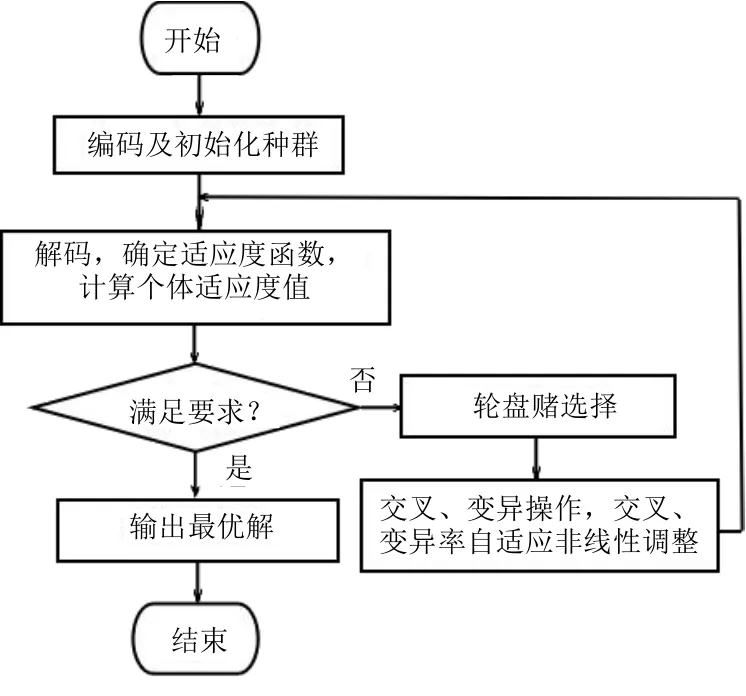
圖4 改進遺傳算法RBF參數優化流程圖
3 實驗及結果分析
為了研究改進遺傳算法優化RBF神經網絡的性能,將該算法應用于一個典型的非線性系統的辨識,通過函數逼近能力來說明該方法的實用性和合理性。為了比較,同時采用梯度下降法來訓練RBF網絡,所有算法程序均采用MATLAB語言編程,非線性系統模型為:
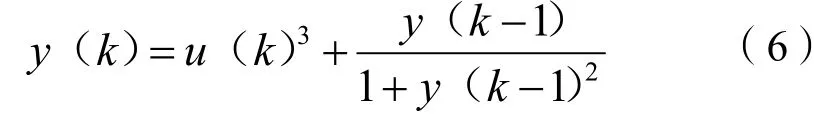
3.1 算法參數選擇
改進遺傳算法參數如表1所示。
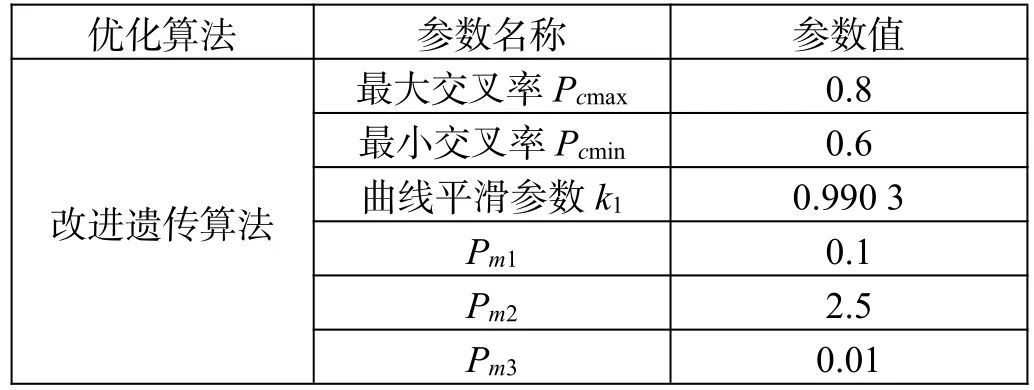
表1 改進遺傳算法參數設置
其中,在遺傳算法優化中,種群規模為30,最大進化代數為250代。由式(6)可知,y(k)與歷史輸出y(k-1)和u(k)有關,因此RBF神經網絡輸入x(k)定義為[y(k-1),u(k)]T,選擇隱含層個數為20,因此RBF神經網絡結構為2-20-1。
3.2 仿真結果分析
用于測試的RBF神經網絡辨識中,取輸入信號為正弦信號:u(k)=sin(10πt),得到300個學習樣本(輸入輸出對),前100樣本個訓練RBF神經網絡模型,后200個樣本作為測試樣本。改進遺傳算法優化均方誤差曲線如圖5所示,當輸入為u(k)=sin(10πt)時,采用改進遺傳算法優化RBF神經網絡時,網絡經過120代后,均方誤差為0.013 4,不再發生變化,基本達到誤差要求,能較好地克服基本遺傳算法學習時間長、收斂速度慢等缺點。曲線擬合分別如圖6、圖7所示,圖中虛線表示實際輸出有ym,實線表示目標輸出y。

圖5 改進遺傳算法優化均方誤差曲線

圖6 改進遺傳算法優化RBF神經網絡的曲線擬合

圖7 梯度下降法的曲線擬合
由圖6和圖7可知,改進遺傳算法優化后的RBF神經網絡實際輸出數據與目標數據基本吻合,符合函數的總體趨勢,擬合效果優良,而采用梯度下降法優化RBF神經網絡時,在初始和結束擬合時有一些發散,且在中間的數據擬合偏差較大。可見應用改進遺傳算法優化的RBF神經網絡控制器有著更強的優化效果。
4 結語
針對常規RBF網絡學習算法的不足,提出一種改進遺傳算法優化RBF神經網絡的參數,利用改進遺傳算法實現高斯函數的中心c、基寬參數b和連接權值w的選擇。在改進遺傳算法中,著重對交叉率和變異率的非線性自適應調節進行了設計。通過對典型非線性函數的仿真分析,本文提出的改進遺傳算法優化的RBF神經網絡控制器有著較好的優良性能,為實際工程應用提供了理論支持和有效途徑。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
