基于視頻圖像和深度學習的車輛軌跡檢測與跟蹤
2022-02-12 12:13:44李志堅郭玉彬趙建東
公路交通科技 2022年12期
李志堅,郭玉彬,趙建東
(1. 中交建冀交高速公路投資發展有限公司,河北 石家莊 050000;2. 北京交通大學 交通運輸學院,北京 100044)
0 引言
對車輛進行實時的異常行為檢測,有利于提高道路交通管理的效率和車輛出行安全。利用計算機視覺方法對視頻圖像進行車輛檢測成本低、實施方便,受到了越來越多的關注。
通過目標檢測算法可以將圖片中車輛的位置和類別信息檢測出來,高精度的目標檢測算法是進行車輛跟蹤的重要基礎。2015年,首個單階段目標檢測模型YOLO算法由Joseph[1]提出,該算法直接利用回歸方法使用提取后的特征預測分類和邊界框,具有快速檢測的能力。隨后該作者又提出速度更快精度更高的YOLO9000[2]、YOLOv3[3]算法。AlexAB[4]通過整合圖像處理領域的各種提高精度的方法,提出了YOLOv4算法,相較于前一代精度提高10%。同年YOLOv5[5]發布算法,該模型在保持高精度檢測的同時,速度更快。針對單階段目標檢測中前景與背景類別不均衡導致識別準確率較低的情況,Lin[6]等人提出RetinaNet模型和Focal Loss損失函數,使模型能夠對所有類別進行充分的訓練。但是當前針對類別不均衡問題并未得到完全的解決,仍然值得近一步研究。
在跟蹤算法的研究中,Alex Bewley等人[7]提出SORT算法,該算法具有檢測精度高,在檢測速度方面比其他算法快20倍,但是該算法存在ID切換問題。隨后提出的Deep Sort[8]算法,增加了級聯匹配機制,并提取車輛外觀特征,該算法有效地解決了ID切換和遮擋問題。Zhou等[9]提出CentreTrack跟蹤算法,與Sort類算法不同的是,該算法是端到端的模型,以前一幀和后一幀圖像以及前一幀圖像檢測結果渲染的熱力圖作為輸入,直接完成追蹤任務。如何解決遮擋問題是跟蹤任務中的關鍵難點,雖然Deep Sort算法通過提取外觀特征找回因遮擋而丟失的目標,但該模型性能較差,仍有改進空間。
綜上,實時的車輛檢測和跟蹤算法研究主要存在以下難點:(1)如何在保證檢測精度的同時,保持較高的檢測速度;(2)在車輛軌跡追蹤過程中如何解決遮擋問題,避免出現軌跡中斷和ID跳變情況。本研究針對上述難點,建立高速公路車輛檢測圖像庫,利用優化后的YOLOv5和Deep Sort算法進行車輛檢測跟蹤,得到精確的車輛軌跡。
1 道路監控視頻圖像庫的建立
車輛檢測作為監督學習,需要對每張圖片標注車輛類型以及在圖像中的位置信息。由于研究場景為高位相機拍攝下的道路監控視頻,視頻中的車輛難以區分詳細的類別信息,因此本研究將高速公路上的車輛分為小型車、公交客運車、貨車3類,并用矩形框將車輛的位置標注出來。
從道路監控視頻中抽取8 056張圖片用于構建數據集,各類型車輛數量如表1所示。在數據集構建的過程中,發現數據集中各類型車輛數量存在嚴重的不均衡現象,如小型車的數量比公交客運車多50 217 個,另外道路監控視頻下的車輛過于模糊,給檢測造成一定的困難。在研究中,將數據集按6∶2∶2 的比例進行劃分。

表1 數據集中各型車數量
2 基于YOLOv5的車輛檢測研究
2.1 YOLOv5算法
(1)網絡結構
YOLOv5網絡結構如圖1所示,輸入的圖片首先經過Focus結構進行下采樣,接著通過由CBH結構和BottleneckCSP[10]結構組成的主干特征提取網絡。CBH結構由卷積層、批歸一化層、激活函數構成。經過主干特征網絡后,使用空間池化金字塔層[11],融合不同尺度的特征圖信息,提高檢測精度[12]。最后,使用PANet(Path Aggregation Network)[13]結構,針對3個不同尺度的特征圖進行預測車輛目標信息。
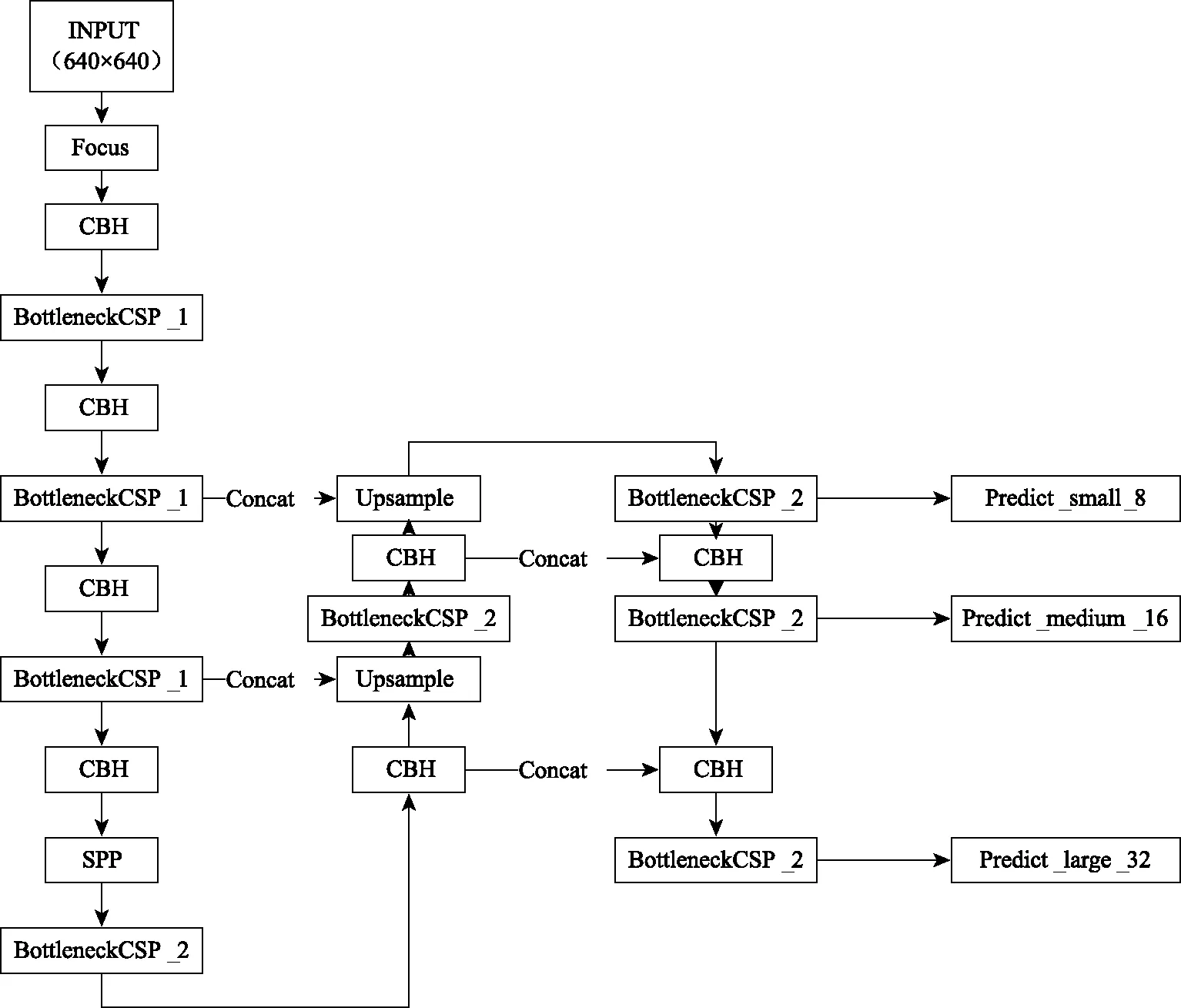
圖1 YOLOv5網絡結構
(2)損失函數
YOLOv5中使用的是損失函數如式(1)所示:
(1)
式中,N為檢測層的個數;YOLOv5中為3層;Lbox為邊界框損失;Lobj為目標物體損失;Lcls為分類損失;λ1,λ2,λ3分別為上述3種損失對應的權重。
CIoU損失計算如式(2):
(2)
式中,b,bgt分別為預測框和標簽框;wgt,hgt為標簽框的寬高;w,h為預測框的寬高;ρ為兩個矩形框中心的距離[12];α為權重系數。
Lobj和Lcls計算方式如式(3):
(3)
2.2 YOLOv5基準網絡訓練結果
通過對YOLOV5基準模型試驗后發現,不同類別車型的檢測精度和車型數量成正比,如數據集中小型車數量最多,模型可以學習到該類車型豐富的特征信息,因此檢測精度最高。而數據集中公交客運車數量最少,模型沒有得到很多的訓練,因此檢測精度最低。
2.3 YOLOv5算法優化
(1)網絡結構優化
在基準YOLOv5網絡中,Bottleneck模塊中的Conv2層作為一種過渡層,不承擔主要的特征提取任務,但增加了模型計算量,因此將該層去掉,減少參數;另一方面考慮引入Ghost Module[14]替換原始的右側分支中Conv3卷積層,減少參數量。綜合上述改進,提出CG3瓶頸層結構,其結構如圖2所示。其次,在CG3結構中的Bottleneck層中,引入參數相對較少的輕量注意力機制ECA(Efficient Channel Attention)[15],旨在提高網絡模型的性能。
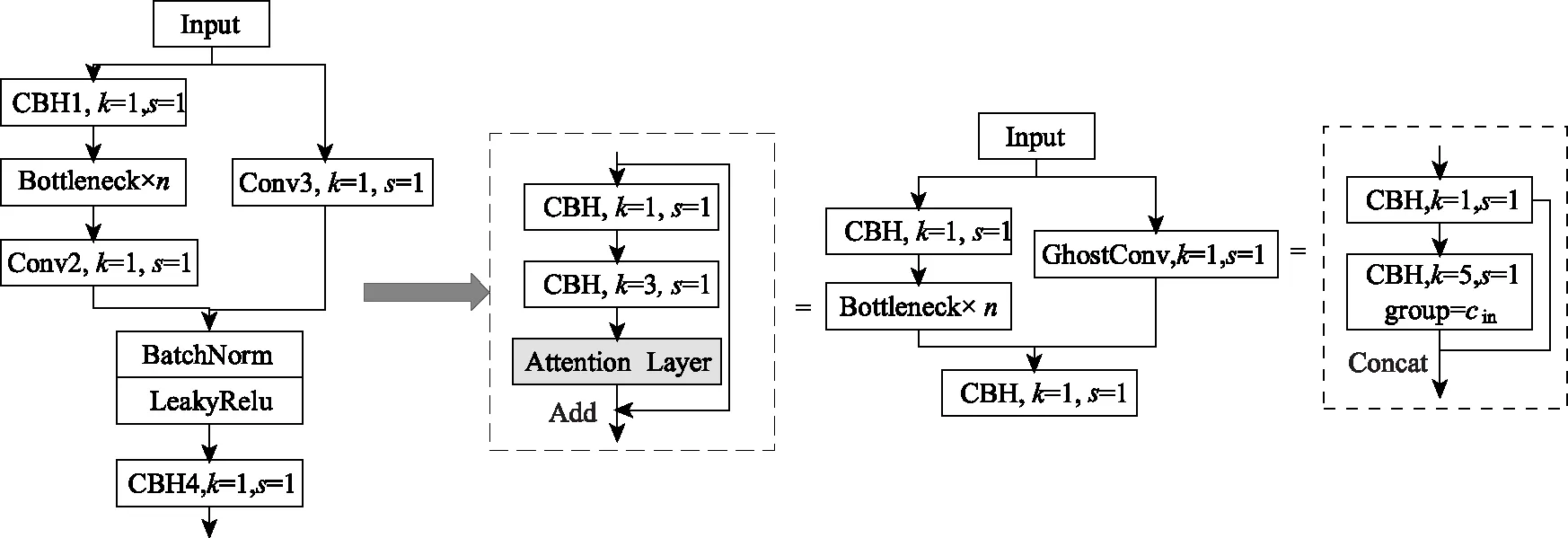
圖2 CG3-Attention瓶頸層
(2)數據輸入端優化
在基準網絡試驗中,發現不均衡的類別差異會給最后的檢測結果帶來較大的影響,因此從數據輸入端進行優化。本研究以Mosaic[4]數據增強方法作為基礎結合本數據集特點,提出Class-Weighted Mosaic(C-W-Mosaic)數據增強方法。具體步驟如下:
①統計數據集中各車型的數量總數,取倒數,作為每一類車型的權重;
②求每張圖片的權重,每類車型的權重乘圖片中各車型的數量;
③將圖片依據權重大小進行排序;
④首先隨機抽取第1張圖片,第2,3張圖片從前n張圖片中選取,按照權重由大到小順序選擇,第4張在剩余的部分中選擇;
⑤隨機將區域分為4部分,將上一步選擇的4張圖片放入;
⑥對于合成后的圖片采用常用的數據增強手段。
(3)網絡結構改進試驗結果對比
為了驗證上述改進效果,在相同的試驗條件(模型的超參數、訓練數據集等)下,進行對比試驗,驗證集測試結果如表2所示。通過表2可以看出,在基準網絡中使用CG3-Attention瓶頸層,檢測指標mAP50和mAP50∶95分別提高了1.7%和2.4%。在數據輸入端使用C-W-Mosaic數據增強相較于Mosaic方法,樣本量較少的公交客運車檢測精度AP50和AP50∶95分別提升0.9%和2.0%。通過試驗結果表明,優化后的YOLOv5模型可以快速準確地檢測車輛目標。
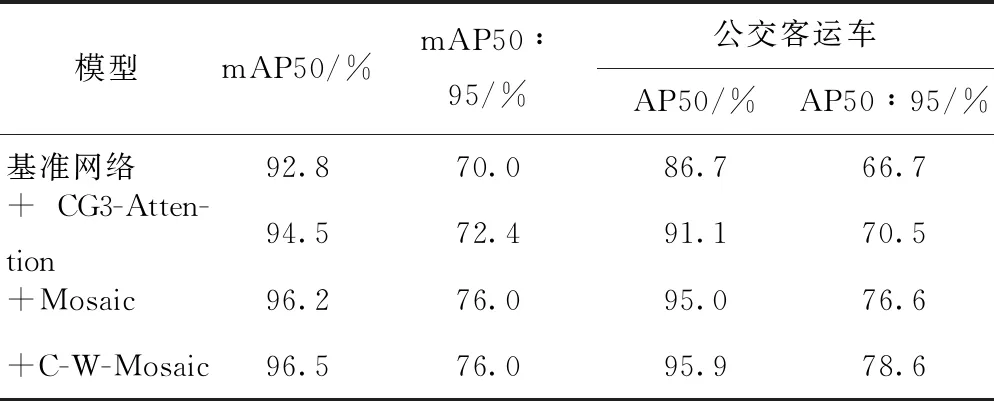
表2 試驗比對結果
3 基于Deep Sort的多目標車跟蹤改進算法
3.1 Deep Sort多目標跟蹤算法原理
如圖3所示,本研究使用了Deep Sort多目標跟蹤算法,完成車輛追蹤任務,該算法通過提取車輛的外觀特征,完成多幀圖像車輛的匹配跟蹤,使得車輛即使是在被遮擋的情況下仍能被再次匹配找回,增加了跟蹤的穩定性。
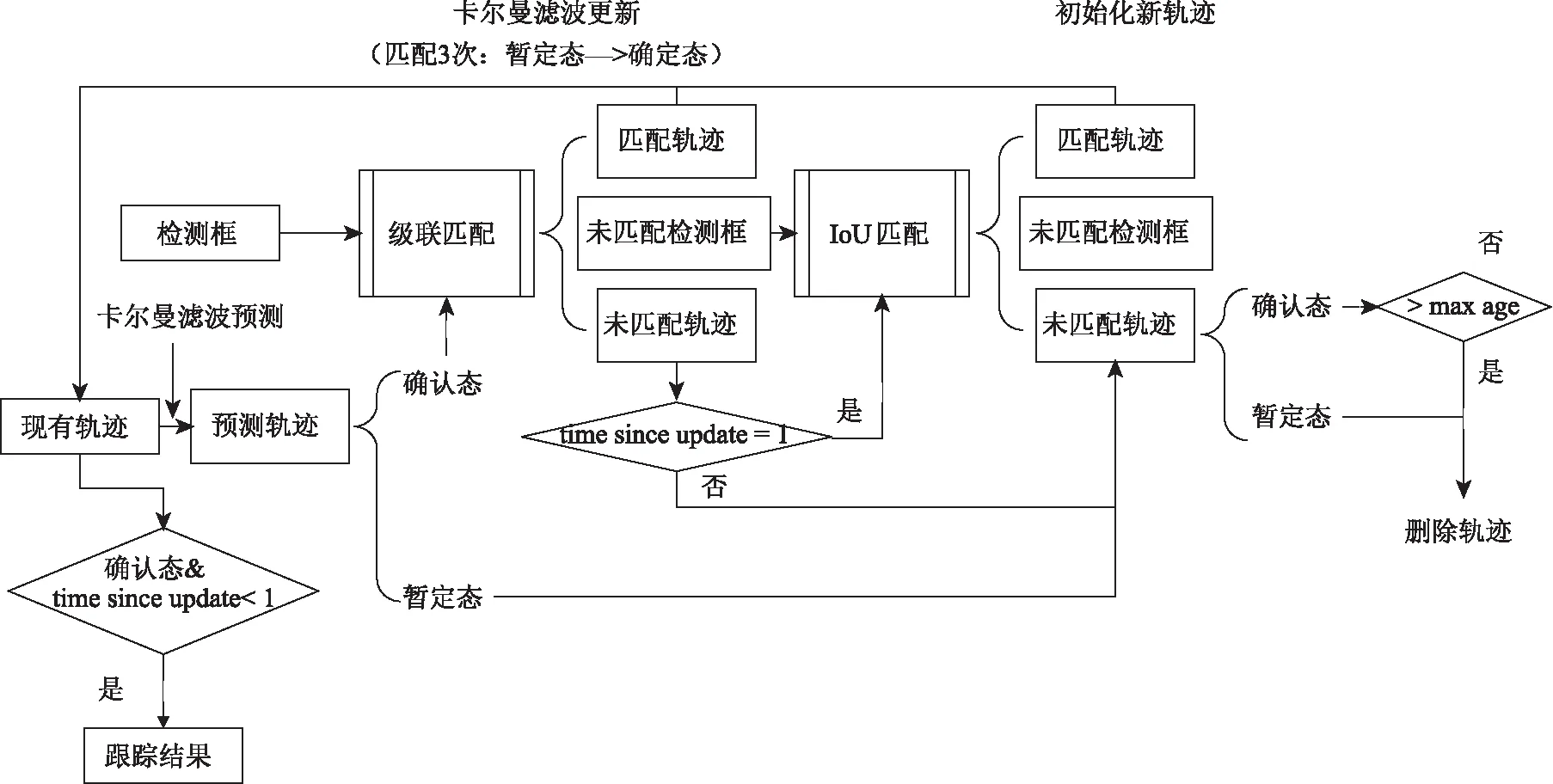
圖3 Deep Sort多目標跟蹤算法流程圖
3.2 Deep Sort算法優化
(1)外觀提取特征優化
原Deep Sort網絡中,特征提取能力較差,并且高速公路高位相機拍攝的車輛尺度變化較大,同時容易受到環境因素影響,圖像質量難以保證,加劇了Deep Sort的不穩定性。因此,本研究提出將Resnet18[16]殘差網絡作為原模型的特征提取網絡,在保證檢測速度的同時,提取更有分辨性的特征。另外,引入三元組損失[17],替換原有的損失函數。
三元組損失公式化表現如下:
Ltriple=max{dcosine(a,p)-dcosine(a,n)+α,0},
(4)
式中dcosine(A,B)計算公式如式(5),表示兩個向量之間的余弦距離。
(5)
使用公開的VeRi776車輛重識別數據集[18]進行訓練,驗證改進效果,結果對比如表3所示。
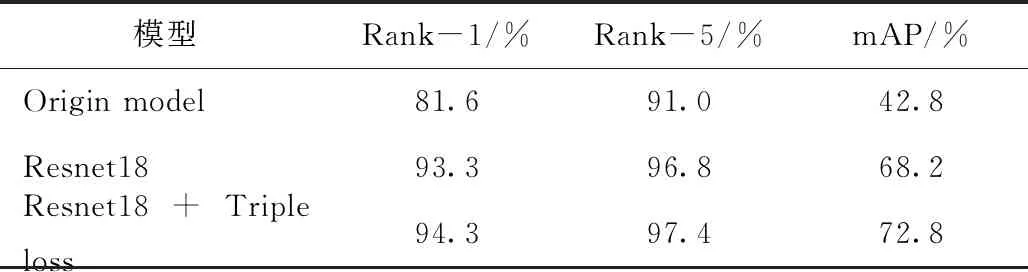
表3 重識別模型訓練結果對比
通過表3可以發現原始的網絡模型由于特征提取能力較弱,所以表現較差;使用Resnet18殘差網絡之后,模型可以有效學習到相應的特征,檢測精度相較于原始網絡模型得到提升;損失函數改為三元組損失之后,模型檢測精度得到近一步提升,對于車輛的區分能力更強。
3.3 改進跟蹤算法結果對比
選取高速公路監控視頻對所提出的優化算法進行驗證,所選擇視頻存在大量遮擋情況,具有一定的挑戰性,能夠有效的檢驗出優化后算法的穩定性。另外,選擇主流的多目標追蹤算法CenterTrack[9]和FairMOT[19]做對比試驗。評價指標選用常用的MOTA(多目標跟蹤準確率)、MOTP(多目標跟蹤精確率)、MT(被跟蹤到的軌跡占比)、FM(真實軌跡被打斷的次數)[20]。
試驗結果如表4所示,可以發現改進后的模型跟蹤效果更加穩定,軌跡被打斷和ID跳變現象得到了有效緩解,在檢測速度方面,優化后的模型可以達到25~30 fps,能夠實時完成跟蹤高速公路監控場下的車輛檢測跟蹤任務。
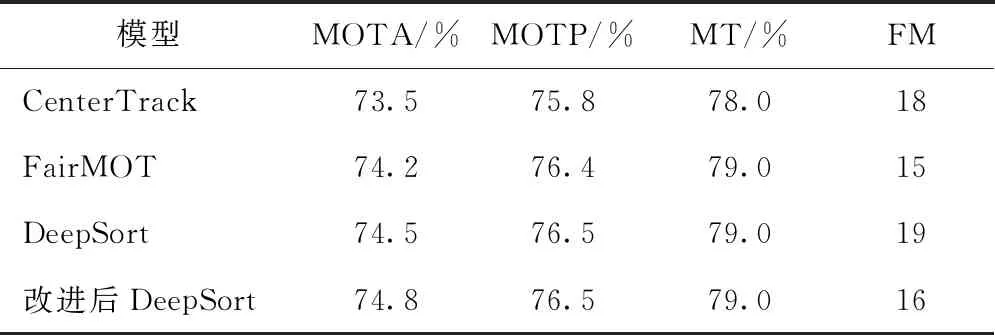
表4 跟蹤結果對比
4 結論
本研究主要利用高速公路監控視頻,研究車輛的檢測和跟蹤算法。制作了車輛檢測數據集,從網絡結構和數據增強方面優化了YOLOv5車輛檢測模型,從外觀特征提取模型和跟蹤關聯參數優化了多車跟蹤模型,具體結論如下:
(1)提出Class-weighted Mosaic數據增強方法,應用在YOLOv5目標檢測模型的數據輸入端,有效緩解少數量樣本帶來的問題;為了提高YOLOv5目標檢測模型的檢測效率和精度,設計CG3瓶頸層結構,提高車輛檢測精度。
(2)使用Resnet18殘差網絡作Deep Sort追蹤模型的特征提取網絡,并且將損失函數換成三元組損失函數,使得Deep Sort能夠在車輛遮擋的情況下保持較高的檢測穩定性。
(3)試驗結果表明,優化后的YOLOv5車輛檢測模型,精確度由92.8%提高到了96.3%;Deep Sort多車跟蹤優化模型有效降低了ID跳變和跟蹤軌跡中斷的次數,并且優化算法檢測跟蹤車輛可以達到25~30 fps的速度。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
