基于上下文學習的輕量級自動摳圖算法
2022-02-15 07:00:32王文韻黃根春王先培
計算機工程與設計 2022年1期
王文韻,黃根春,田 猛,王先培
(武漢大學 電子信息學院,湖北 武漢 430072)
0 引 言
自然圖像摳圖是指精確估計前景對象不透明度,并將前景對象和背景對象分離的問題,其有廣泛的應用[1]。傳統的摳圖算法主要通過傳播、采樣或兩者的結合來實現。該類方法很大程度將顏色作為區別特征,導致對于前景和背景顏色分布重疊的情況分割性能較差。近年來,基于深度學習的自然圖像摳圖算法逐漸取得了主導地位。Cho等[2]將兩種傳統摳圖方法(Closed-form算法及KNN算法)的結果和歸一化RGB圖像作為輸入,通過端到端神經網絡的學習來預測一個新的Alpha圖。這種方法雖然利用了深度學習,但輸入部分依賴于傳統方法的結果,因此很容易遇到與以往摳圖方法相同的問題。為了避免受到以往方法的影響,Xu等[3]提出了一種兩階段的網絡,包括編解碼階段和細化階段。該方法無需依賴于其它方法的結果,僅以原始圖像和相應的三分圖作為輸入便可預測Alpha圖。同時Xu等還提出了摳圖領域第一個大規模的數據集。由于該數據集的可用性,基于深度學習的摳圖方法得到了廣泛的探索。Lutz等[4]進一步改進了文獻[3]中的解碼器結構,提出了一種生成對抗網絡。Yu等[5]針對高分辨率圖像進行了基于深度學習的自動摳圖的研究。上述方法雖已取得較好的分割結果,但仍然存在一些不足。一是深層網絡易丟失部分低級語義信息,而低級特征對于保留Alpha圖的詳細紋理信息至關重要[6]。二是深層網絡普遍模型參量龐大,無法很好平衡精度和運行時間,而目前大部分嵌入式設備的算力很難支撐深度卷積神經網絡模型的實時運行[7]。
針對上述問題,本文提出一種輕量級的自然圖像摳圖算法。該算法以U-Net框架為基線結構,改進的MobileNetV2為編碼器,結合上下文特征聚合模塊捕獲多尺度的上下文信息,有效保證模型的輸出精度。同時將深度可分離卷積應用到上下文特征聚合模塊和解碼器模塊,大幅降低了模型參量。
1 網絡結構與原理
本文提出的模型使用定制的U-Net架構來實現自然圖像摳圖,系統框架如圖1所示。本文采用RGB圖像和相應的三分圖作為網絡輸入,其沿通道維度連接,形成一個4通道輸入。網絡首先通過編碼器部分將輸入圖像編碼為特征映射,然后使用上下文特征聚合模塊融合多尺度的上下文信息,最后將增強后的特征映射解碼恢復對象邊界信息,得到預測的Alpha圖。
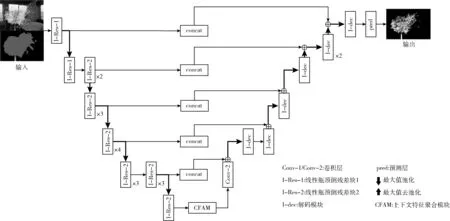
圖1 網絡模型
1.1 基線結構
本文采用U-Net網絡作為基本結構框架,該網絡由Ronneberger等提出。U-Net網絡近年來在語義分割領域取得了廣泛的成功,如Shelhamer等[8]進行全卷積網絡的語義分割,Liu等[9]用于圖像修復以及Fan等[10]基于改進的U型網絡進行高分辨率遙感圖像分割。U-Net網絡主要有兩個顯著特點。一是U型對稱結構,左側為編碼器,右側為解碼器。編碼器通過連續的卷積層和最大池化層對輸入數據進行降維和特征提取,解碼器則通過上采樣層對提取的特征層進行升維和特征放大。二是跳躍連接結構,U-Net網絡的每個卷積層得到的特征圖都會連接到對應的上采樣層,從而在后續的解碼過程中可以有效利用每層特征信息。對于摳圖問題,低層特征信息的保留對于恢復Alpha圖中詳細的紋理信息有著至關重要的作用。因此,本文設計解碼器在上采樣塊之前組合編碼器功能,避免在編碼器特征上發生更多的卷積,而該卷積應該提供較低級別的特征。
1.2 輕量級編碼器-解碼器網絡
本文將以U-Net框架為基礎,保留其U型對稱結構和跳躍連接結構,改進編碼器-解碼器結構,搭建一個適用于自然圖像摳圖的輕量級神經網絡。
為了更好平衡精度和模型參量,本文選取MobilbeNetV2的主干網絡作為編碼器結構。MobileNetV2[11]網絡是由google團隊2018年提出的輕量級神經網絡模型,該模型在大幅減少模型參數和運算量的同時保持了較高的準確率。MobileNetV2在保留了MobileNetV1[12]中的深度可分離卷積的基礎上,提出了線性瓶頸的倒殘差結構,進一步提高網絡的表征能力。倒殘差結構巧妙的反向利用了Resnet網絡[13]提出的殘差結構,如圖2所示。通過倒殘差結構,模型可以在高維度進行特征提取和低維度減少計算量上得到一個良好的平衡。值得注意的是,針對倒殘差結構中最后的1×1卷積層,MobileNetV2采用線性激活函數替代ReLU激活函數。由于倒殘差結構輸出的是低維特征,線性激活函數較ReLU激活函數能夠更好保留低維特征信息。因此,使用MobileNetV2網絡既能夠有效保留低級語義信息進而保證分割精度,又能降低模型的參數量。
具體地,本文采用的編碼結構主要包含7個線性瓶頸的倒殘差結構層和5個最大池化層。同時在最后一個倒殘差結構層后添加了上下文特征聚合模塊,以在多個尺度上對特征進行重新采樣,從而準確高效預測任意尺度的區域。該模塊將在后續的章節中詳細闡述。
本文使用更簡單的結構進行解碼操作,同時將深度可分離卷積添加到解碼模塊中進一步減低模型參量。解碼器部分由連續的最大值去池化層、卷積層以及和編碼器的跳躍連接組成,進行上采樣特征映射輸出預測的Alpha圖。其中跳躍結構能夠通過融合低層特征信息捕獲圖像中的精細結構,進而提高輸出精度。具體而言,解碼器包含7個解碼模塊(如圖3所示)和一個輸出預測層。每個解碼模塊的卷積層后使用批處理標準化層(batch normalization,BN)和ReLU6激活函數,緩解訓練過程中梯度消失的問題。
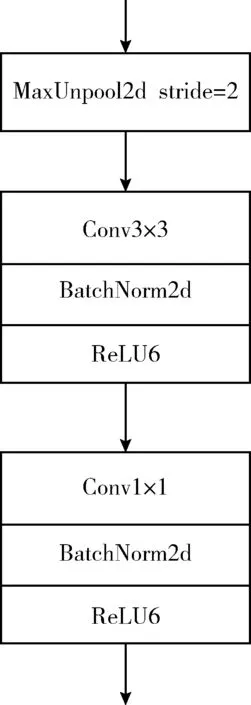
圖3 解碼模塊
1.3 上下文特征聚合模塊
本文提出了一種基于改進的空洞空間金字塔池化(astrous spatial pyramid pooling,ASPP)的上下文特征聚合模塊,用于捕獲多尺度的上下文信息。該模塊能夠與編解碼網絡結合,豐富網絡中的編解碼模塊。
空洞卷積是空洞空間金字塔池化(ASPP)中的重要組成部分,其通過在權重之間插入零來對卷積濾波器進行上采樣,如圖4所示。相比普通的卷積,空洞卷積引入了一個稱為擴張率(dilated rate)的超參數,該參數定義了卷積核處理數據時各值的間距。ASPP實質上是幾個以不同的擴張率并行的空洞卷積。DeepLabV3[14]首次應用了ASPP捕獲多個尺度上的上下文信息,經實驗證實,該模型在分割基準上確實取得了一定的提升。

圖4 空洞卷積
為了緩解網絡主干的池化或跨步卷積操作造成對象邊界詳細信息丟失的問題,同時避免增加過多的模型參量,本文將深度可分離卷積添加至空洞空間金字塔池化結構并與編解碼網絡結合,具體的模塊結構如圖5所示。該模塊能夠明確地控制由深度卷積神經網絡計算的特征分辨率,并通過調整擴張率以自適應修改濾波器的視場獲取多尺度的信息。同時使用深度可分離卷積替代普通卷積可以在很大程度上控制模型參量的增加。
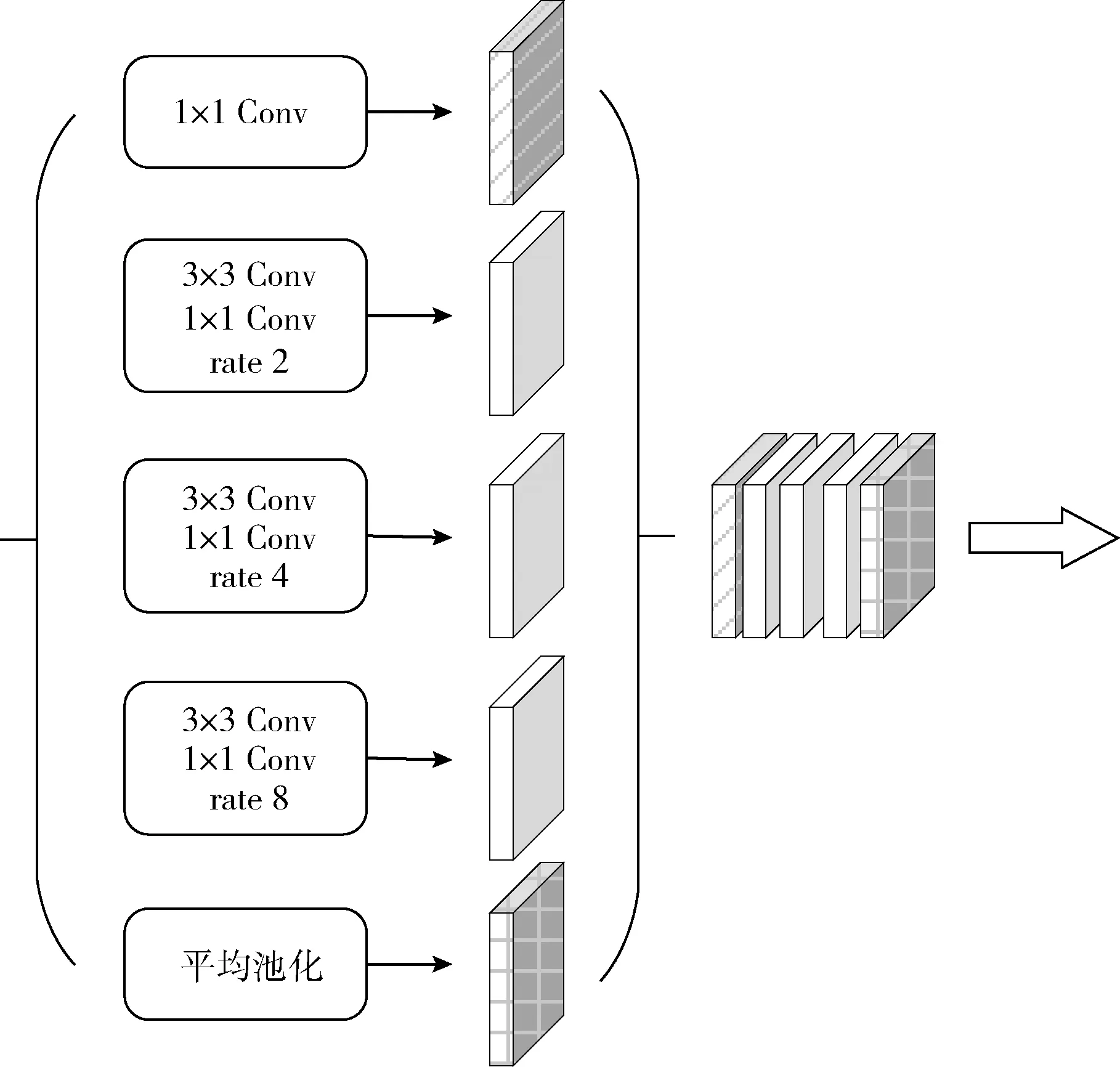
圖5 上下文特征聚合模塊
1.4 損失函數
本文提出的網絡使用兩個損失函數,分別為Alpha預測損失和合成損失。Alpha預測損失表示每個像素點處的真實Alpha值和預測Alpha值之間的絕對值差。合成損失則表示真實RGB顏色與預測RGB顏色之間的絕對差異,具體的計算公式如下[3]
(1)
(2)
式(1)中,αp表示閾值為0至1的預測層的輸出;αg表示真實值;ε取10-6。式(2)中,c為RGB通道,cp為預測的Alpha合成的圖像,cg為真實的Alpha合成的圖像。總損失為上述兩個損失的加權和,即Lo=ωlLα+(1-ωl)Lc。 在本文的實驗中,ωl設置為0.5。
2 實驗與分析
2.1 實驗環境
本文在基于Pytorch的深度學習框架下進行訓練和測試,接口語言為Python,操作系統為Ubuntu18.04,CPU為Intel i9-9900K,內存為32 GB,顯卡配置為Quadro RTX 6000。
2.2 訓練數據集
深度學習方法需要大量的數據才能很好地泛化。Alphamatting.com數據集(由Rhemann等提出)已經在加速摳圖研究的發展方面取得了巨大的成功。然而,該數據集只有27張訓練圖像和8張測試圖像,這遠不足以訓練神經網絡。直到Xu等[3]發布了由431個獨特的前景對象和對應的Alpha組成的新的摳圖數據集。該數據集使訓練深層摳圖神經網絡成為可能。然而,431張圖片仍不足以很好訓練深層網絡,因此本文采用和Xu等相同的方法對數據集進行增強。對于每一張前景圖像,隨機從MS COCO數據集(由Lin等提出)中選取100張圖像作為背景圖像與前景圖像進行合成,于是可得到包含43 100張圖像的訓練數據集。為進一步增強數據,本文采取隨機旋轉、剪裁等處理方法,使得網絡具有更好的魯棒性。
2.3 訓練細節
網絡編碼器部分用MobileNetV2在Imagenet數據集(由Russakovsky等提出)上的預訓練模型進行初始化,這種遷移學習的方式可以大大縮短訓練的時間,同時提升模型的精度。由于本文修改了網絡的第一層以適應4通道的輸入,因此采用零初始化卷積層中的額外通道。所有解碼器參數都用Xavier隨機變量初始化。
在訓練過程中,使用Adam來更新整個編碼器-解碼器網絡,學習速率(Learning rate)設置為10-2,訓練的批大小(batch size)設置為16,訓練周期(epoch)為30。同時為了降低合成圖像對預測結果造成的影響,訓練中使用了Alpha預測損失和合成損失兩種損失函數。
2.4 評價指標
為了定量地評估摳圖算法的性能,預測輸出值需通過誤差度量與真實值進行比較。本文實驗評價指標使用摳圖領域的4種通用衡量指標,分別是絕對誤差和(sum of absolute differences, SAD)、均分誤差(mean square error, MSE)、梯度誤差(Gradient)和連通性誤差(Connectivity)(2009年由Rhemann等提出)。絕對誤差和(SAD)和均分誤差(MSE)作為簡單的評價指標能夠為圖像誤差度量提供良好的基礎,梯度誤差(Gradient)和連通性誤差(Connectivity)作為高級的視覺質量評價指標能夠為摳圖算法提供與人類視覺感知相近的比較結果,具體的計算公式如下
(3)
(4)
(5)
(6)
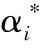
2.5 實驗結果與分析
本文在兩個數據集上評估了提出的算法。首先在Alphamatting.com數據集上進行了定性的評估,該數據集是現有的圖像摳圖的基準。其提供了8張測試圖像,每張圖像對應3種尺寸的三分圖,分別為“用戶”,“大”和“小”。由于Alphamatting.com數據集的規模較小,包含對象的大小和范圍有限,本文進一步在Composition-1k測試數據集進行了定性和定量的評估。該數據集是摳圖領域的第一個大規模測試數據集,包含1000張測試圖像和50張獨特的前景,具有更廣泛的對象類型和背景場景。
2.5.1 Alphamatting.com數據集
Alphamatting.com測試數據集中包括具有不同透明度的各種對象:高透明度(網、塑料袋)、較高透明度(娃娃、巨魔)、中透明度(驢、大象)和低透明度(菠蘿、植物),本文定性地將實驗結果與其它6種最先進的摳圖算法的實驗結果進行了比較,如圖6所示。對比算法分別為Closed-form算法(由Levin等提出)、Weighted color算法(由Shahrian等提出)、KNN算法(由Chen等提出)、Comprehensive Sampling算法(由Shahrian等提出)、Three-layer 算法[15](由Chao等提出)和DCNN算法[2](由Cho等提出),實驗結果選取的三分圖均為“大”尺寸。當前景與背景顏色相近時,傳統算法通常性能較差,無法正確的將前景對象分割出來。如圖6中第一個示例所示,傳統算法無法精準分割娃娃頭發與背景顏色相近部分,邊界區域明顯出現偽影。而本文提出的基于深度學習的方法明顯表現更好,對于非常精細的結構(如頭發),基于深度學習的方法也能較好完成分割工作。一個關鍵的原因是傳統算法缺乏學習高級上下文信息并依賴于顏色相關的傳播方法。其中,DCNN算法[2]雖然是基于深度學習的方法,但是由于其模型是在小的局部補丁上進行訓練的,因此很難真正理解語義信息。此外由于本文提出的算法引用了更多的全局信息,因此當面對較大的未知區域時,該算法具有更好的魯棒性。
2.5.2 Composition-1k測試數據集
Composition-1k測試數據集是由Xu等[3]提供,廣泛用于摳圖領域的評估數據集。為了進一步驗證模型的有效性,本文分別定量定性的在該數據集上評估了提出的方法。與文獻[3]中處理數據的方法相同,將作者提供的50個唯一的前景對象與Pascal VOC數據集(由Everingham等提出)中的1000個不同背景圖像進行組合,生成了1000個不同的測試圖像。
本文將提出的方法與其它8種主流的摳圖算法進行了定量比較,分別是:Closed-form算法、KNN算法、Comprehensive Sampling算法、Three-layer算法[15]、DCNN算法[2]、Information-flow算法[16](由Aksoy等提出)、DIM算法[3](由Xu等提出)、AlphaGAN算法[4](由Lutz等提出)。對于所有對比算法,使用作者提供的源代碼。本文方法的不同變體包括:a.編解碼網絡(基線結構)b.編解碼網絡(添加上下文特征聚合模塊)。定量比較的結果見表1,評估指標使用上述介紹的4種通用衡量指標。由表1可見,本文提出的算法在4項評價指標的綜合性能上優于以往的主流算法,梯度誤差指標較DIM(deep image matting)算法提高了7.63%。對比基線網絡結構,變體b在4項評價指標上均取得了一定的提升,SAD提高了3.24%,梯度誤差提高了7.38%,充分了驗證了本文提出的上下文特征聚合模塊的有效性。本文列出的DIM算法的實驗結果不包含后續優化模塊,僅對比編碼器-解碼器主干網絡的性能。
本文提出的網絡使用MobileNetV2作為編碼器結構,同時將深度可分離卷積應用至主干模塊,大幅減少模型參量,具體模型參量見表2。由表2可知,本文算法模型參數量和浮點計算量均遠小于對比算法,模型大小僅為2.50 M,較DIM算法降低了98.1%,浮點計算量較DIM算法降低了94.0%。
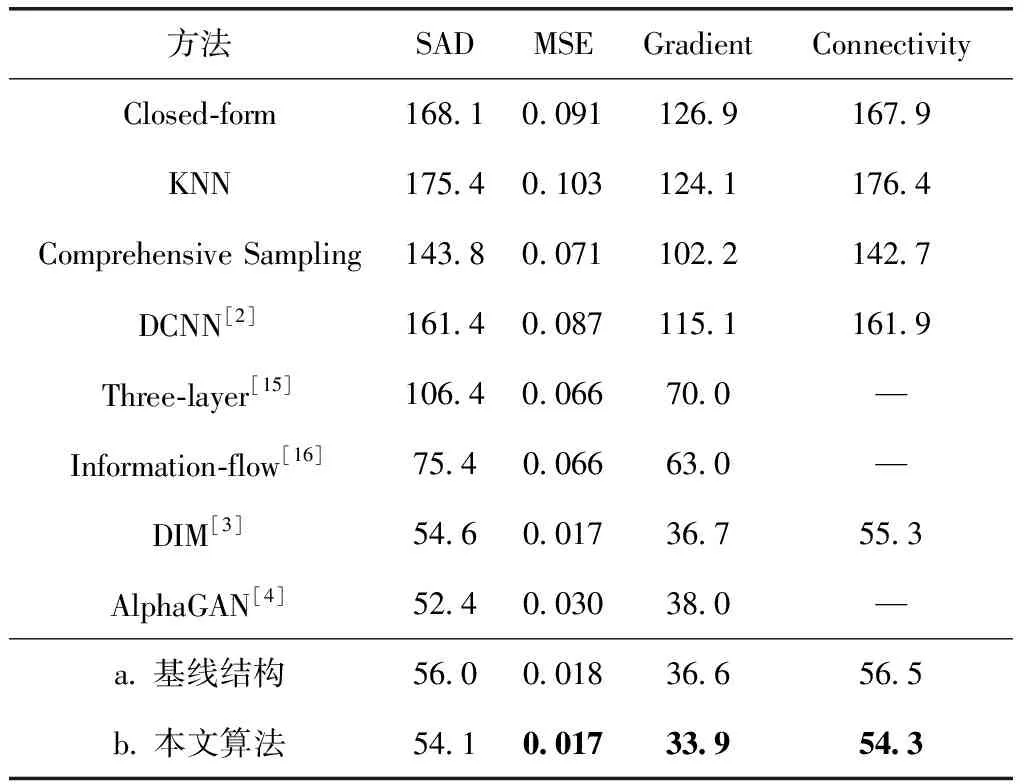
表1 Composition-1k測試數據集上的定量結果
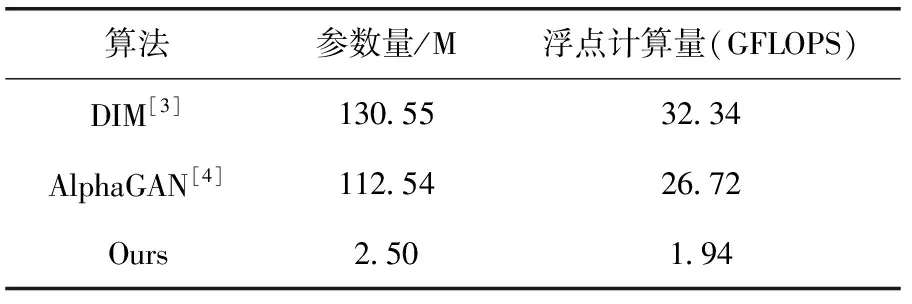
表2 模型參數量對照
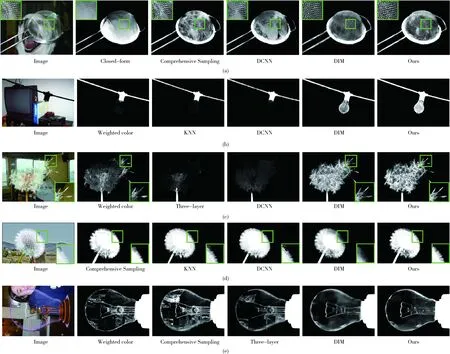
圖7 Composition-1k測試數據集的實驗結果
Composition-1k測試數據集上定性比較的實驗結果如圖7所示。由圖中第二個示例可知,對于一些未知區域較大的圖像,傳統方法根本無法完成分割任務,而本文提出的方法能夠利用U-Net網絡的跳躍連接結構及上下文特征聚合模塊捕獲更多的全局信息從而較好完成前景對象的精確分割任務。本文算法在透明度較高(如網篩、燈泡及蒲公英等)的摳圖任務中均取得了良好的視覺效果。這得益于該算法更多考慮了低級特征,這些特征有效保留了Alpha圖的細節紋理特征。
3 結束語
針對目前嵌入式設備難以運行基于深度學習的自動摳圖模型的問題,提出了一種基于編解碼網絡和上下文信息聚合模塊的輕量級自然圖像摳圖模型,該模型的參數量較對比算法降低了98.1%。基于MobileNetV2的編碼器能夠對豐富的上下文信息進行編碼,簡單而有效的解碼模塊有效恢復對象邊界信息,同時上下文特征聚合模塊能夠以任意分辨率提取編碼器特征。在Alphamatting.com數據集和Composition-1k數據集上進行測試,實驗結果表明本文提出的模型具有較為理想的摳圖精度,驗證了本文方法的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
