知識本體與詞向量結合的詞義相似度強化學習計算方法
2022-02-17 14:08:48楊泉
重慶理工大學學報(自然科學) 2022年1期
楊 泉
(北京師范大學 漢語文化學院, 北京 100875)
詞語語義相似度(本文簡稱詞義相似度)是隨著計算語言學發展而產生的一個概念,指一種語言中任意2個詞語之間相似或相關的程度。詞義相似度計算在信息抽取、機器翻譯、人機對話等諸多自然語言處理領域都有著廣泛應用,其主要任務是研究用什么方法來計算或比較2個詞語的語義相似度[1]。隨著人工智能領域的不斷發展,詞義相似度計算逐漸成為自然語言處理中的重要基礎性工作,其在更高層面自然語言處理中的應用受到廣泛重視[2]。
詞義相似度計算方法可分為兩大類[3]:一類基于知識本體進行計算;另一類基于詞向量進行計算。很多關于英文的詞義相似度計算方法都是使用WordNet作為知識本體實現的,例如,Phi-lip[4]在“IS-A”分類體系基礎上,提出了一種基于共享信息內容概念的詞義相似度計算方法;Mohamed等[5]在WordNet層級結構中深度分布的基礎上,提出了一種最近公共結點的概念下位詞子圖量化法。
在漢語知識本體中,《同義詞詞林》(本文簡稱《詞林》)是計算詞義相似度的重要底層框架,《詞林》層級體系與WordNet框架較為接近,都將同義詞集合(synset)作為基本建構單位進行組織。因此基于詞林的詞義相似度計算方法與基于Wordnet的計算方法有許多類似的地方。目前已有很多基于《詞林》的中文詞義相似度計算模型,田久樂等[6-11]的計算模型中利用了《詞林》的編碼、深度、路徑或距離等相關信息計算詞語之間的語義相似度。
另一類計算語義相似度的方法是基于語料庫的方法。詞向量是一種把詞語數量化的方法,將語料庫中的單詞映射到向量空間中,就可以方便機器學習算法在自然語言處理任務中更好地理解、使用和處理詞語。Word2vec[12]是目前構建詞向量最常用的方法之一,其使用的n-gram模型將一個單詞與其上下文的n個單詞相關聯,可以生成具有上下文語義信息的稠密詞向量,由于在Word2vec詞向量中結合了上下文詞語的信息,因此又稱為詞嵌入方法。該方法基于詞向量進行計算,與基于本體知識的方法相比,具有更強的可計算性。
對比知識本體和詞向量2種方法后,發現基于知識本體的方法依據人類對于世界知識的認識對詞語之間的相似程度進行計算,一般都具有較強的理論依據,計算結果反映的是知識本體中蘊含的詞義相似度信息;而基于詞向量的計算方法是在大規模語料庫基礎上訓練所得,其結果反映的是受訓語料中蘊含的詞義相似度信息。程婧等[13]認為在基于詞向量的計算方法中,基本假設是語義相似的詞語之間上下文語境也會比較相似,因此可以結合上下文信息進行相似度計算。由此可見每種方法都有各自的優缺點,分別適合解決不同的自然語言處理任務。
縱觀前人已有研究成果及其觀點,如果能夠充分厘清2種方法各自的優缺點和相似度計算的側重點,在使用時有機結合、揚長避短,一定能夠計算出更符合實際需求的詞語語義相似度結果,以便提升更高層次自然語言處理任務的效果。
本文擬采用《詞林》作為知識本體,在充分解析其義項編碼信息內容的基礎上,確定語義相似度計算模型,并結合基于詞向量語義相似度計算方法,最后運用強化學習策略建立一種更為合理的詞語語義相似度計算方法。
1 基于知識本體的方法
《同義詞詞林》是由梅家駒等[14]于1983年編撰的可計算漢語詞庫,經哈爾濱工業大學研究人員擴展成為《哈工大信息檢索研究室同義詞詞林擴展版》。經哈工大擴展后的《詞林》體系將詞語分為5個層級:大類、中類、小類、詞群和原子詞群,上面4層結點都代表詞語的類別,第5層葉子結點上是原子詞群,每個原子詞群可以用一個8位編碼唯一表示,表1展示了《詞林》中的義項編碼情況(1)參見《哈工大同義詞詞林擴展版》, 網址:http://www.ltp-cloud.com/download。。
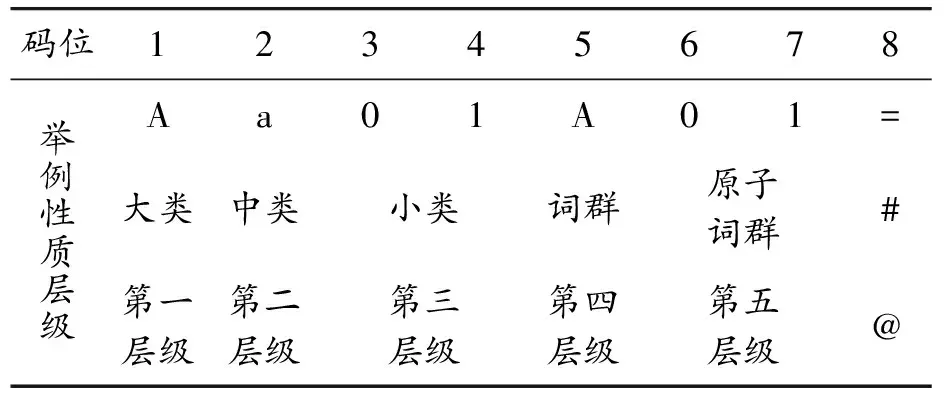
表1 《詞林》義項編碼表
經統計,《詞林》共有77 456條詞語,分為12個大類,95個中類,1 428個小類,4 026個詞群和 17 817個原子詞群。
《詞林》的義項編碼可以轉化為二叉樹的結構形式,所有詞語都對應該樹的葉子結點,不同詞語編碼在該樹上所處節點間的距離就表示了詞語間的相似程度,例如,對于詞匯w1、w2,文獻[15]中給出了一種基于深度的語義相似度計算方法:
(1)
式中:D是w1、w2對應的《詞林》編碼在樹形結構圖中最近公共父結點的深度。這種簡單的計算公式將距離信息轉化為0到1之間的相似度數值,能很好地體現相似度。《詞林》中的編碼實際上是原子詞群的編碼,同一個原子詞群中的詞語具有相同的編碼,即具有相同的路徑。在已有算法中使用《詞林》編碼路徑深度計算詞義相似度的方法,實際上計算的是不同原子詞群之間的相似度。
在《詞林》中共有17 817個不同的義項編碼,每個義項編碼可以代表一個原子詞群,按第8位義項編碼可以將全部原子詞群分為三大類,分別以“=”“#”“@”3種符號結尾,這三類編碼代表原子詞群內部的詞語之間是“相似”“相關”和“唯一”的關系,各類義項編碼具體數量及占比統計結果見表2。

表2 《詞林》按第8位義項編碼統計表
以“@”結尾的原子詞群中只包含一個詞語,占比25%,即《詞林》中只有一個詞語的原子詞群共有4 377個。以“=”和“#”結尾的原子詞群包含2個或2個以上詞語,共占比75%,即在《詞林》中有13 440個原子詞群包含2個或2個以上詞語,這種情況下,同一個原子詞群內部的詞語與其他原子詞群詞語計算語義相似度的結果相同。
事實上,基于其他知識本體的詞義相似度計算方法也都使用了類似的思想。雖然同義詞是一個經典概念,但對于同義詞之間相似程度的量化表示卻是隨著自然語言處理而產生的概念。因此這種計算相似度的思想就是將已有知識本體中蘊含的相似度信息進行量化表示。由于建立知識本體時不是以相似度量化表示為目的,所以在計算量化的相似度時難免會存在一些問題。首先,《詞林》的世界知識對于語言學知識表示的精細程度是否足以準確體現詞語之間的語義相似度;其次,《詞林》對于新詞語的覆蓋程度是否能滿足應用需求;第三,對于《詞林》中所蘊含的世界知識計算模型能否準確解讀和表示;最后,由于詞語的多義性,同一個詞語可能對應多個義項編碼,使用編碼進行計算時將面臨義項選擇的困境。
因此,僅使用《詞林》編碼,很難準確計算出同一個原子詞群內部詞語之間的相似度。對于這些問題,需要結合新的計算方法,更加合理地進行計算。
2 基于詞向量方法
詞義相似度計算任務中的詞向量一般是指通過大規模語料訓練得到的詞向量。雖然還有其他的詞向量訓練方法,例如熱點表示法,但由于該方法需要將不同詞的向量相互正交,當詞匯量較大時會出現維數災難,因此基本上不在詞義相似度計算中使用。在《詞林》中將詞語用其編碼表示,從數學角度來說,也可以看作一種向量表示,其中包含了相應的語言學知識,但不包含詞語在具體語境中的上下文信息。在詞嵌入詞向量模型中,Skip-Gram(SG)模型是當前應用最廣泛的詞嵌入方法之一[12],該方法通過學習一個詞與其相鄰詞的關系來實現詞嵌入。SG模型通過最大化式(2)來預測每個給定單詞wt的上下文單詞。
(2)
式中:V為訓練詞向量所用語料;|V|為詞匯總數;wt為當前的中心詞所對應的向量;c為上下文窗口的大小;wt+i是上下文詞匯向量;p(wt+i|wt)是在wt的條件下wt+i的概率。
使用該模型得到的詞向量維度比起詞匯總數|V|來要低得多,在具體訓練中人們發現,如果向量維度太低,則不能很好地表示語料中的信息,難以達到實用的要求;但若維度太高,則在訓練過程中會出現過擬合問題,將語料中的噪聲學習到了詞向量中,也會影響使用效果。因此當前常見的詞向量維度一般是幾百維的向量,通過嵌入式詞向量不僅解決了維數災難問題,而且向量中蘊含了詞語的上下文語境信息。
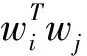
S(w1,w2)=cos(w1,w2)
(3)
詞向量空間中越相近的2個向量,夾角越小,余弦越大,正好可以表示詞語間的相似度。所以把詞語進行了向量化表示后,在向量空間中就會自然形成一種相似度的量化標準。
“詞向量”的概念來源于語言學中的“價值”(value) 和“分布”(distribution) 等概念[16]。即詞語的語義由其上下文信息決定,因此這樣得到的詞向量受語料的影響非常大。在一類語料上訓練得到的詞向量,應用到其他語言學任務中可能得不到很好的處理效果。因此在一些特定的應用中需要基于其任務和語料來重新訓練詞向量。但這種訓練詞向量的方法對語料的規模及運算資源的要求都非常高,要想得到高質量的詞向量,必須要基于海量的語料,并且需要使用大量的計算資源和時間才能完成。因此目前出現了一些通用的詞向量,這些詞向量使用的語料體量大,涵蓋的詞語豐富,訓練的準確率也比較高,在通用型任務中往往能取得較好的效果。例如騰訊提供的詞向量數據庫,這個數據庫提供800多萬個中文詞條,每個詞條展開后是一個200維的向量,其數據量有16G(2)騰訊詞向量下載網址:https://ai.tencent.com/ailab/nlp/embedding.html。,它使用Directional Skip-Gram(Skip-Gram的改進版)訓練而成,是目前開源的通用型高質量詞向量之一。
根據訓練詞向量方法的語言學原理,詞向量之間的比對更多的是表示詞語在具體語境中的相似性,而不是詞語間語義的相似度,例如在語義上“狗”和“犬”是同義詞,在《詞林》中具有相同的語義編碼“Bi07B01=”,理論上應該具有最高級別的相似性,而“狗”和“貓(Bi08A01@)” 在《詞林》中的編碼不同,在語義上的距離肯定比“狗”和“犬”大,相似度也應該沒有“狗”和“犬”高。但是根據騰訊詞向量的計算結果卻恰好相反,“狗”和“犬”之間的相似度為 0.738,“狗”和“貓”之間的相似度為 0.747,超過了相同語義編碼的2個詞語之間的相似度。這說明了基于語料的詞義相似度計算與基于知識本體的詞義相似度之間的差異較大。此外語料庫訓練出來的詞向量還是會受到受訓語料規模的限制,不能保證一種語言中每個詞語的詞向量都得到訓練,例如,雖然騰訊詞向量數據庫收錄了800多萬中文詞匯,但像“以色列”這樣并不算太生僻的詞語卻沒有查到。因此詞向量雖然為計算詞義相似度提供了重要方法,但也不能解決詞義相似度計算的全部問題。
3 基于強化學習的混合式詞義相似度計算方法
基于知識本體和基于詞向量的語義相似度計算方法都顯性或隱性地運用了一些語言學信息進行計算,但每種方法都有不足之處,如果能將2種方法有機結合,使其應用的語言學信息更加全面,則可提高語義相似度計算質量。
本文選擇《詞林》作為計算詞義相似度的知識本體,選擇騰訊詞向量作為計算詞義相似度的詞向量,以Miller & Charles發布的30個詞對(本文簡稱MC30)[17]的詞義相似度人工判別值為學習目標。根據我們接觸到的詞語,基于這2種方法可能會出現以下幾種情況:
1) 不被《詞林》和騰訊詞向量同時收錄的詞匯。《詞林》共有77 456條詞語,騰訊詞向量數據庫收錄800多萬中文詞匯,兩類數據庫收錄詞語情況還是有較大差距,主要分為以下2種情況:① 在《詞林》里存儲了某個詞語,但是在騰訊詞向量數據庫中查找不到。如“以色列”是專有名詞,在《詞林》里的編碼是“Di02A23#”,但是用騰訊詞向量標注時卻沒有查到這個詞,這是由于所錄專有名詞不同造成的收詞差異。② 在騰訊詞向量數據庫中存儲了某個詞語,但是在《詞林》中卻查找不到。如“弗洛伊德”“本拉登”這類專有名詞;另外“電子計算機”“計算機網絡”在騰訊詞向量數據庫中可以查到,但是在《詞林》中卻沒有,不過在《詞林》中可以查到“網絡(Bb06A01=)”“電子(Ba01H08#)”“計算機(Bo01A27=)”,這主要是由于2個數據庫存儲詞語顆粒度不同造成的。
2) 在《詞林》和騰訊詞向量數據庫中都收錄了2個詞語,且2個詞語在《詞林》中的語義編碼完全相同,根據第8位編碼又分為以下2種情況:① 2個詞語的語義編碼完全相同,且第8位編碼是“=”。如“消費者(Aj06A01=)”和“顧客(Aj06A01=)”,對于這種情況使用《詞林》編碼算法計算結果都為1,無法進一步算出2個詞的差異。② 2個詞語的語義編碼完全相同,且第8位編碼是“#”。如“美元(Dj05A14#)”和“日元(Dj05A14#)”;“搖滾樂(Dk28A08#)”和“爵士樂(Dk28A08#)”。
3) 在《詞林》和騰訊詞向量數據庫中都收錄了2個詞語,但是2個詞語在《詞林》中的語義編碼不同,這時根據《詞林》中語義編碼的數量又分為以下幾種情況:① 2個詞語在《詞林》中都只有一個語義編碼,這時第8位編碼都是“@”,如“家兔(Bi07C03@)”和“貓(Bi08A01@)”。② 2個詞語在《詞林》中一個詞語只有一個語義編碼,而另一個詞語有多個語義編碼的情況。這時2個詞語中有一個詞語的第8位編碼是“@”,另一個詞語的第8位編碼是“=”或“#”,如“自然科學(Dk03A02@)”和“自然(Ed51A01=、Ee10A01=、Ka15A01=、Ka32B01=)”。③ 2個詞語在《詞林》中都有多個語義編碼的情況。這時2個詞語的第8位編碼是“=”或“#”。如“工作(Di19A01=、Di19B01=、Hj11A01=)”和“生活(Da17B01=、Di19C01=、Hj01A01=、Ib03A01=)”。
基于有監督式學習的詞義相似度計算方法,需要預先給定足夠的訓練數據,并為數據中的詞對給定相似度值。運用這些數據獲得可靠的模型后,再輸入未標注相似度的詞對,經過訓練的模型就能夠給出相應的相似度值。而強化學習與此不同,是無監督式的學習。不同于采用靜態數據集的學習框架,強化學習采用動態環境數據,其目標是學習如何做,即如何根據環境情況采取動作,從而實現收益的最大化。強化學習的學習者不會接到動作指令,必須自行嘗試去探索環境,與環境交互并從環境中學習,發現收益最高的動作方案。在狀態和動作空間較大、環境信息復雜且不完善的任務中,強化學習也經常能找出最佳動作。
在詞義相似度計算中,當前僅有少數公開人工判定結果可供學習和比較,因此有監督學習的方法往往缺少足夠的支撐數據。在大多數情況下,語義相似度計算結果需要根據具體任務的完成情況進行評判。基于知識本體和詞向量的2種不同的語義相似度計算方法,都有其合理性和適應范圍,因此本文建立了強化學習模型,尋找最優策略,充分利用2種方法的合理性,以便更好地滿足實際應用中的需求。
在強化學習模型中,首先需要有一個可接收狀態觀測量(輸入)的函數(策略),然后將狀態映射到動作集 (輸出)上。在詞義相似度計算時,強化學習所觀測的環境是指語言學任務所涉及的語言學環境,如上下文語境,語法知識等。在本文研究的強化學習模型中,學習者所能觀測到的環境狀態觀測量是指給定詞對的2種相似度計算結果。對于基于知識本體的詞義相似度,其結果記為s1,使用式(1)進行計算;對于基于詞向量的詞義相似度計算,其結果記為s2,使用式(3)計算;無法計算的情況,其值均記為0。記S=(s1,s2)為觀測量,定義為狀態集。
對于每個狀態S=(s1,s2),強化學習模型根據策略F,得到最佳動作A=(a1,a2),
A=F(s1,s2)
將此策略下的收益
V(S,A)=a1s1+a2s2
(4)
作為語義的相似度計算結果。獎勵是一個函數,會生成一個標量,表示處于某個特定狀態并采取特定動作的“優度”。本模型中用動作的收益與人工判斷結果差值平方的倒數作為所采取策略的獎勵。
強化學習算法的整體過程如圖1所示。
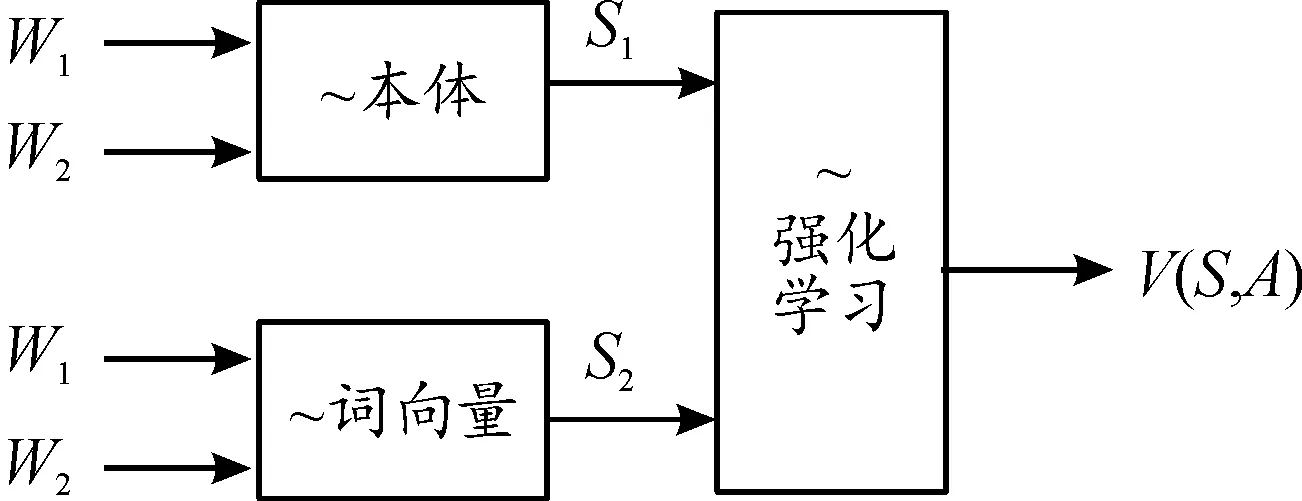
圖1 強化學習過程圖
其中,強化學習模型部分,將輸入(s1,s2)作為其狀態觀測量,用線性函數表示策略,通過ε-貪婪評估策略進行訓練,用動作的收益與人工值的差構造獎勵函數,最終得到學習結果。學習模型在ε-貪婪評估策略選擇動作時,會以ε的概率選擇一個新的動作,以1-ε的概率選擇已有動作中獎勵最大的那個動作。經過訓練最后得到相應的算法模型。
人們在判別語義相似度時往往綜合多方面信息進行比較與判斷,本文所提的混合式強化學習模型將基于知識本體的信息與基于詞向量的信息充分融合,從理論上來說應該會與人工判斷值具有較高的相似度。
4 實驗結果與分析
實驗以MC30人工判定結果為標準,給出了基于強化學習的相似度計算結果。最終評價標準是本文計算結果與人工結果之間的皮爾遜系數,系數值越大,數據相關性越強,說明強化學習算法的學習計算詞義相似度的能力越強。
針對上面給出的數據,分別計算出其對應強化學習模型中的不同環境觀測量S=(s1,s2),取ε=0.1,經訓練后得到的策略為:
(5)
式中:S1是指前文所述的情況1)。S2是前文所述的情況2),使用該策略時,若計算結果為負值,則取相似度值為0,因為相似度不能為負值。在這種情況下,詞向量方法更偏重詞義的相關性,在語義相似度計算方面起到負作用。S3是前文所述的情況3)。本文方法所得計算結果如表3所示。
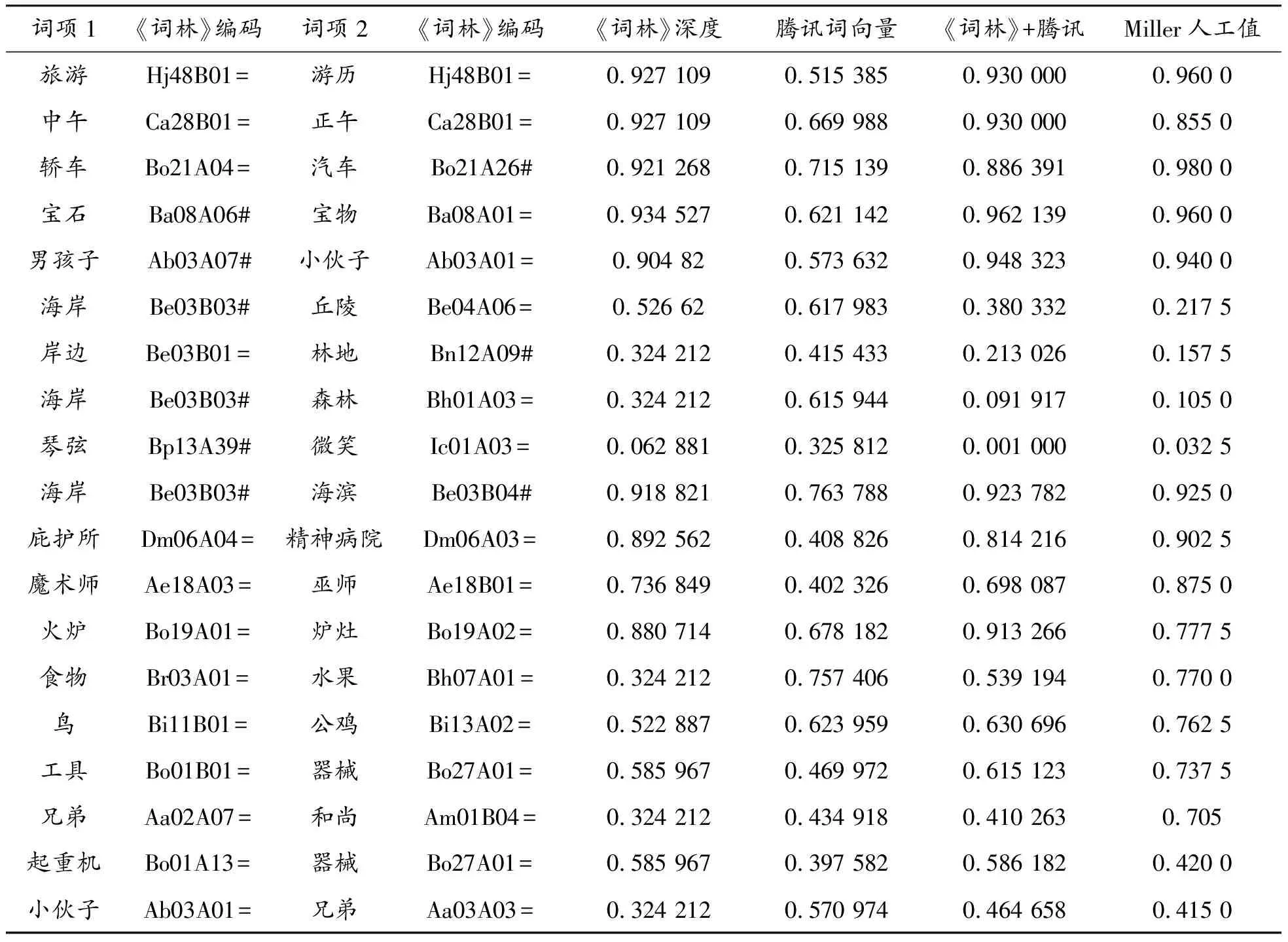
表3 詞義相似度計算結果
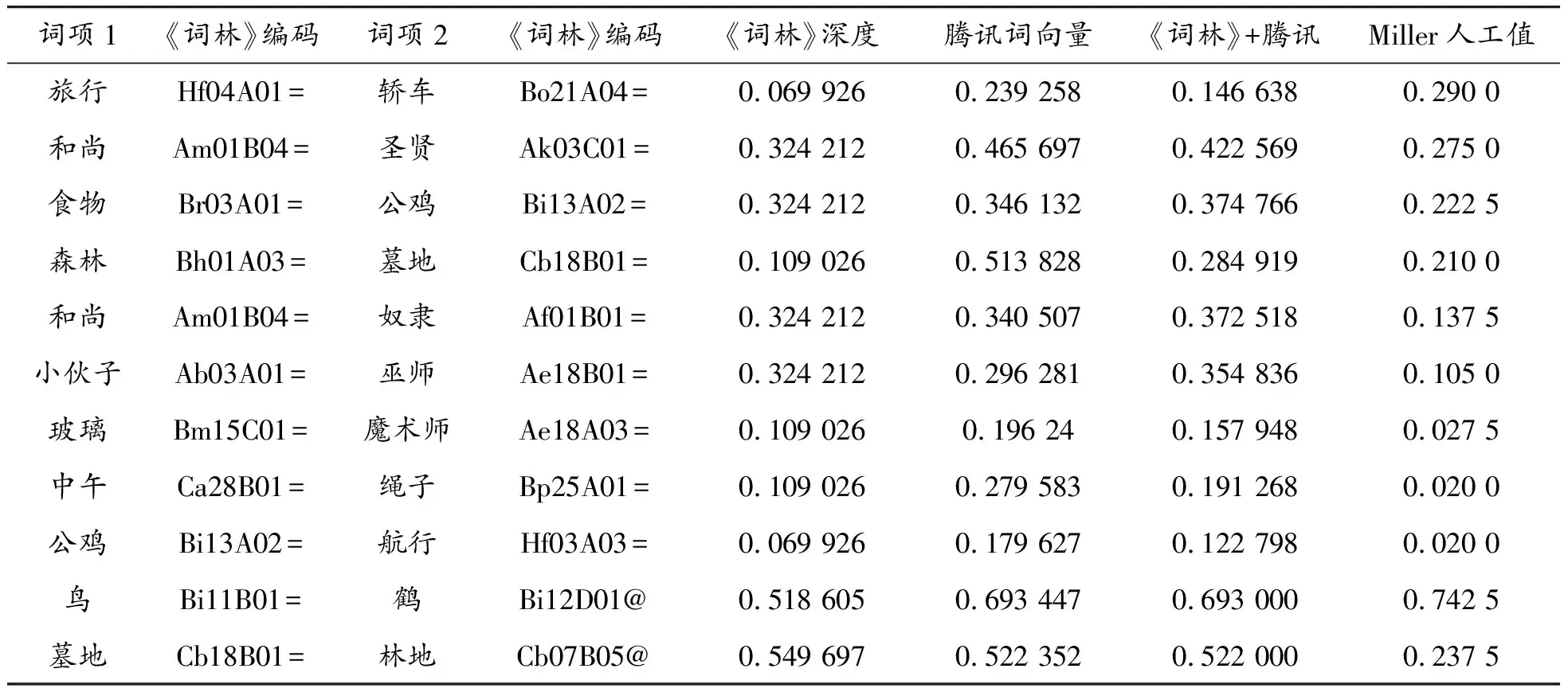
續表(表3)
經過計算,僅使用《詞林》深度的方法與MC30人工值的皮爾遜相關系數為0.855;僅使用騰訊詞向量的方法與MC30人工值的皮爾遜相關系數為0.656;本文所用《詞林》與騰訊詞向量相結合的方法與MC30人工值的皮爾遜相關系數為0.917。實驗結果說明:強化學習算法能利用兩類方法中的語義信息,因此獲得了更接近于人工值的結果。
5 結論
1) 人在判斷2個詞語的語義相似度時,雖然受詞語相似性和相關性的共同影響,但是人主要還是從詞語的語義相似程度出發判斷其相似值。
2) 單純基于《詞林》的方法在判斷2個詞語的語義相似度時,當2個詞語語義編碼相同且第8位編碼為“=”或“#”時,相似度值為1;顆粒度太粗不能很好地適應實際應用需求。
3) 單純基于騰訊詞向量的方法判斷2個詞語的語義相似度時,受詞向量訓練過程和結果的影響,其計算結果主要是2個詞語的相關性。
基于知識本體和基于詞向量的方法各有優缺,單純使用《詞林》或單純使用騰訊詞向量數據庫都不能取得令人滿意的結果,需要將二者有機結合才能更加客觀、準確地計算2個詞語的語義相似度,這也將是詞義相似度計算未來的發展趨勢。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
兒童故事畫報(2019年5期)2019-05-26 14:26:14
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
