計算社會學的基礎問題及未來挑戰
2022-02-18 02:04:24范曉光劉金龍
西安交通大學學報(社會科學版) 2022年1期
范曉光,劉金龍
1.浙江大學 社會學系,浙江 杭州 310058;2.中國社會科學院大學 社會學系,北京 102488
計算社會學是計算社會科學與社會學的學科交叉,是一門新興學科。社會學作為一門獨立的學科經歷了近200年的發展,已經形成完善的學科體系,但是其倡導的實證主義在宏觀解釋與微觀解釋、數據驅動與理論驅動、相關分析與因果推斷、信度與效度等方面長期存在內在“張力”[1]。計算社會科學是對社會科學實證主義傳統的推進,借助于計算機和信息通信技術(ICT)的迭代更新,其研究方法和研究設計都有別于傳統范式,研究議題越來越突破傳統的學科界限。面對作為典型的復雜性系統的社會,計算社會學具有的學科交叉、基礎理論和應用對策并行等特質,使其在回應實證主義面臨的諸多困境時具有明顯優勢。
一、實證社會科學面臨的不確定性
實證社會科學是指利用實際調查或訪談資料來驗證理論假設或者構建理論的研究范式,它有別于純理論思辨式的傳統社會科學[2]。社會學在實證社會科學的發展早期發揮了舉足輕重的作用。孔德提出的社會物理學力圖用科學的方法研究人類社會的構想,在實證社會科學的發展歷史中遇到了許多困難。如果將社會科學研究看成研究主體、研究客體和研究過程所構成的三個有機整體,則可以更清晰地理解其面臨的不確定性。
首先,理解并揭示社會現象發生和發展的因果關系是實證社會科學一直追求的,但社會復雜性所帶來的不確定性使得實現上述目標的難度大大增加。在復雜系統內,多元個體在某一框架之內進行互動,行為會彼此影響,并且個體具有適應性和學習能力,最終引起特定的功能涌現[3]。正是由于社會系統的復雜性,并不存在像“萬有引力”那樣的普遍規律,加之系統成員具有自主選擇和創造的能力,使得實證研究發現在一般化上總是不甚理想。
其次,實證社會科學已經發展出完備的理論和方法工具箱,但是研究者在方法論的認同和運用上的偏好都會帶來實證發現的不確定性。社會科學家有一種自然而然的研究傾向,即嘗試通過理解行動者的意圖、信念、場景和機遇,去解釋他們的行動及后果[4]。如在社會分層與流動領域,衡量社會不平等的取向包括階梯型和關系型兩種,而在如何恰當地使用不同的分層框架上卻長期缺乏共識。之所以產生以上分歧,很難簡單歸因于研究對象本身的差異,而是要充分考慮作為行動者的研究者個體偏好。在田野調查中,不同的研究者即使從訪談對象那里獲得完全相同的信息,在“裁剪”的過程中仍然無法避免出現理解偏差;在定量研究中,雖然開放性、透明性和標準化程度相對更高,但這并不意味著研究者偏好對實證研究的“干預”更少。
最后,研究設計是實證社會科學區別于思辯哲學的關鍵環節,當然也是不確定性的主要生成器。一方面表現為模型設定起點的不確定性。理論導向的實證研究尤為強調理論對模型建立的指導,通常采取的策略是以所對話的理論為起點。要探究理論之核心變量對因變量的影響模式,必須排除若干競爭性解釋,這在模型上主要通過引入控制變量來實現。例如,一個模型有10個控制變量,那么最多存在1 024(210)種可能的變量組合,盡管可以用多模型分析的計算框架(computational framework for multi-model analysis)窮盡這些組合后的結果,以獲得核心變量關聯模式的動態變化[5],但如何解讀這些發現也并非易事。此外,社會是一個開放系統,有些看似外生性的因素仍然可能影響我們試圖解釋的現象。另一方面,模型假定、數據構成、操作化測量、事后因果框架等都導致模型輸出結果的不確定性。任何模型對資料(定性或定量)構成都有相應的前提假定,如總體分布、代表性(包括類型)、信度、效度等,研究者不得不通過“改造”資料以減少實際研究中遇到的前提假設違背困境。同時,經驗觀察的重要假設是研究者和觀察者對研究的“干擾”是可控的,但現實中不僅極易違背,而且較難評估。尤其是在“默頓系統”中,反身性所帶來的不確定性凸顯[6]。此外,被廣泛使用的事后因果分析框架很大程度上也制約了因果推斷的實際預測力。
總之,研究結果的不確定性是實證社會科學的基本特征之一,如何消解其對社會科學的約束一直是個棘手的問題。數據密集型(data-intensive)科學范式的到來,為實證社會科學提供了許多變革的機遇。由此,筆者認為有必要將該問題置于計算社會科學的發展脈絡中。
二、計算社會科學的主要傳統
計算社會科學能夠積極應對實證社會科學的不確定性。其中,基于模擬社會系統或過程的社會仿真可以克服傳統模型的線性思維和化約主義,對于復雜性有著更科學的探究;大數據分析通過對海量數據的挖掘推動知識生產,減少了模型設定、測量和結論泛化的不確定性。
(一)社會仿真:生成解釋的傳統
生成解釋(generative explanation)是通過建立有關被研究社會系統的模型,并從模型的運行過程和結果中獲得對研究對象的理解[7]。該傳統主要通過對主體的行動及其相互作用規則的設定,從演化過程中獲得新的機制解釋。“復雜性”是生成解釋背后的認識論基礎,它將現代物理和生物學結合,認為社會永遠處于時間的邊緣,結構時刻在組合、衰敗和發展[8]。
社會仿真(simulation)是生成解釋的主要方法,它始于20世紀50年代,在研究社會的復雜性上遠遠超越了其他多數研究方法。該方法通過建立一個模擬社會系統或過程的計算機模型,即建立一個能夠表征現實世界的“人工社會”,開展各種社會科學分析。仿真模型能夠容納具有適應性的主體,實現主體之間的交互,展現了從微觀個體行為到宏觀系統狀況的“涌現”。它能夠將行動主體的異質性、自我適應性、有限理性、交互性等重要因素重新納入研究框架之中,克服多數模型的線性外推思維、無法反映宏觀—微觀線性內在聯系、缺乏對“活”系統成員的描述等不足[9],自下而上地構建一個逼近真實的人工社會,以揭示事件發生的條件、概率、限度以及多種可能選擇的策略。社會仿真之所以有效,很大程度上是因為它與真實人類社會的多功能性、高維度、隨機性、非線性、不完全性等直接相關。除了完全基于理論的與真實社會無法直接對接的方式,社會仿真還有注入真實數據對現實對接的方式。例如,針對恐怖分子在美國華盛頓市區引爆一顆1萬噸當量的小型原子彈,導致輻射開始在整個城市擴散的問題,很難想象科學家可以采用社會仿真完成這項傳統方法幾乎不可能完成的研究。
總體而言,社會仿真經歷了從宏觀仿真到微觀仿真,再到基于主體仿真的發展歷程,主要分為面向變量模型、面向對象模型和混合社會模型等類型。其中,基于行動者的模型(agent-based modelling,ABM)屬于面向對象建模,為研究者提供了創建、分析和試驗由在環境中互動的行動者構成的模型[10]。ABM擅長模擬微觀行動者的互動,進而對其“涌現”的有關社會后果進行分析,解釋已經被觀察到的宏觀現象或者預測變化趨勢。經典的隔離模型(segregation model)假定個體都希望1/3以上的鄰居和自己同屬一個種族,如果同種族比例小于1/3才會搬走,否則就留在原地不動。該過程利用元胞自動機(后來逐步改進為ABM)模擬個體搬家的過程,直到無人搬家為止,結果表明即使個體與不同種族鄰居相處很寬容(只有當同種族少于1/3才離開),仍然可能出現種族隔離的宏觀后果[11]。社會仿真研究不僅包括投票交易、創新擴散、謠言傳播、組織決策、廣義交換形成等集體行動議題,也包括社會分化、制度起源與維持等有關結構的議題[12]。雖然仿真在物理學、生物學、計算機科學、網絡科學等領域應用更為廣泛,但不可否認的是,以社會學為代表的社會科學在該傳統的推廣和應用上發揮了重要作用。
(二)大數據分析:數據挖掘的傳統
數據挖掘傳統主要基于互聯網興起在線實時所產生的大數據,利用數據科學和計算科學的前沿技術做數據挖掘,進行理論檢驗和社會預測。有別于社會仿真,該傳統的數據資料來源更加多元、時空跨度更大、體量更大、形式多樣,由此為計算社會科學的發展提供了難得的機遇。大數據最早是由道格·萊尼設想的,他提出了一個著名的“三V”模型(容量大、高速增長、種類繁多),用來應對日益龐雜的三維數據管理[13]。目前,大數據已經呈現出痕跡數據匯集,存儲和運用并行化、在線化、生活化和社會化的新樣態[14],它對社會科學的最大意義是“從無到有”。與傳統主要通過收集觀察、抽樣調查的數據不同,大數據是在弱選擇性觀察、弱設計、弱標準化、弱目的性的前提下自動存取的非結構化的痕跡數據。雖然無法回避算法干擾、數據漂移、代表性、個人隱私等方面的困擾,但它還是為社會科學家打開了一扇理解人類社會的新大門。
同時,大數據在方法論層面為傳統社會科學研究注入了新的活力,即來自計算科學的數據驅動。如果說傳統的實證社會科學倡導以理論為研究起點,那么大數據為我們提供了另外一種可能,即基于對海量數據的挖掘去探尋突破人類既有知識結構的新發現,并在此技術上發現和建構新理論和新理解[15]。這種方法論上的革新,促使演繹和歸納更為密切地結合,也使得計算科學、數據科學和社會科學的聯系更為緊密。由于該傳統的數據生產多來自互聯網,大量研究都圍繞著由互聯網平臺衍生的輿論傳播、情感計算和文化生產等議題展開。此外,數據挖掘與數據科學和計算科學結合,也使得計算社會科學可以開展時間和空間跨度更大的人文和歷史研究。
數據挖掘無論在數據屬性、分析方法和研究目標上都與實證社會科學存在明顯不同。該傳統的分析對象主要是以文本、圖片、視頻等為形式的非結構化數據,大部分并不是為研究者而設計。雖然它們不是全數據,在代表性上存在一定的偏差,但不容否認的是其維度更高、結構更復雜。也正是因為數據挖掘的分析對象有別于傳統數據,研究者往往需要借助自然語言處理(包括情感分析、潛在狄利克雷模型等)、圖像識別、深度學習等發端于計算科學的分析工具。在研究目標上,大數據分析將預測置于核心位置,有別于實證社會科學強調因果解釋的傳統。由于大數據不再局限于“觀察”,全息記錄不會對非直接關聯變量進行過早篩選,因此恰恰可以為預測提供更全面的基礎信息。加之機器學習強調偏差與方差的權衡(bias-variance tradeoff),也使得模型預測的穩健性得到顯著提升。
三、計算社會學的基礎問題
(一)概念界定
計算社會學是計算社會科學的分支。要對計算社會學進行概念界定,首先得從什么是計算社會科學入手。計算社會科學的定義有多種,不同學科取向的學者所采取的方式也不盡相同。有學者認為計算社會科學是“以計算為媒介,以不同規模的社會團體為著眼點,對社會學領域開展的跨學科研究,其研究對象小至個體行動者,大到社會群體”的新領域[16]。有學者提出,計算社會科學是對復雜的,通常是大規模人類行為數據計算方法的開發和應用[17]。國內學者指出,計算社會科學的分支學科主要包括計算社會學、計算政治學、計算經濟學、計算傳播學和計算法學及計算(運籌)管理學等[18],其核心內容是關于人類社會發展的各類信息的自動化處理,專注于透過行為分析、媒體分析、網絡分析和對現實社會的典型化事實分析,借助代碼、算法、程序、建模、模擬等數字化手段,更深入地觀察探討個體行為特征與社會運行規律及二者的互動關系。
按照《布萊克威爾社會學百科全書》的定義,計算社會學是“利用計算機模擬和人工智能去發展理論和開展實證研究的新社會學路徑”[19]。大數據時代,新計算社會學被提出,主要是指“利用大數據新方法來獲取數據與分析數據,從而研究與解釋社會的一種新的方式或思維方式”[20]。本文認為,計算社會學是以計算科學、數據科學等為主要分析工具,將非介入方式收集的大規模數據與傳統數據集相結合,挖掘人類社會和社會互動的規則和模式,用以解釋人類行為與社會運行規律的科學。毋庸諱言,計算社會學的定義與許多傳統的學科界定形式不同,給人的印象是邊界不夠明晰,理論性也不夠強。如果構建一個理論(橫坐標)和計算(縱坐標)組成的象限,計算社會科學處于45°角的話,計算社會學將位于40°~45°的夾角之間。其數據來源涵蓋了語言、位置與運動、網絡、圖像以及視頻等多種內容,并應用復雜的算法來識別數據中的多重依賴性。
由于計算社會學也是社會學的組成部分,因此總是與“常識”緊密相連。與物理學、化學、生物學等自然科學探索人類未知世界一樣,論證常識也極為重要。因為同樣一個觀點作為常識和作為理論存在的意義完全不同,不少觀點看上去像是常識,其實是學術研究后產生了常識的錯覺[21]。然而,計算社會學的數據收集、數據挖掘、算法設計、論證過程都遠比傳統社會學復雜,如果對邏輯起點和方法局限缺乏充分反思,研究發現就會無法超越“常識”,表現為“酷炫技術,理論貧乏”;如果對重大的現實問題缺少關切,表現為“強解釋,弱預測”,則難免落入“計算社會學是個筐,什么都往里面裝”的批評之中[22]。以上對傳統社會學似曾相識的批評,當然與計算社會學的學科使命不符。
(二)學科界限
20世紀70—90年代,信息革命使得科學發展變得越來越快且越來越復雜,大工業和高科技為人類創造了巨大財富的同時,也產生了貧富差距、社會沖突、環境惡化等大量關乎人類命運的重大問題。在這種背景下,各門學科都開始意識到自身的相對性及與其他學科的密切關聯。對于社會科學而言,無論在問題還是在方法維度上都應該面向現實,面向其他知識體系,因此,自然科學和社會科學開始走到一起。
如圖1所示,計算社會學處于自然科學和社會科學之間的連通地帶。它不是傳統意義上以研究對象、研究問題和研究范疇等為基本內容來定義的學科,而是特別強調研究方法和研究設計的創新。其看似遵循了通常的“某某社會學”的命名慣例,但是除了將計算作為研究對象,更多的是將計算作為一種理解人類社會的工具,因此更適合與定量社會學、分析社會學等相提并論[22]。
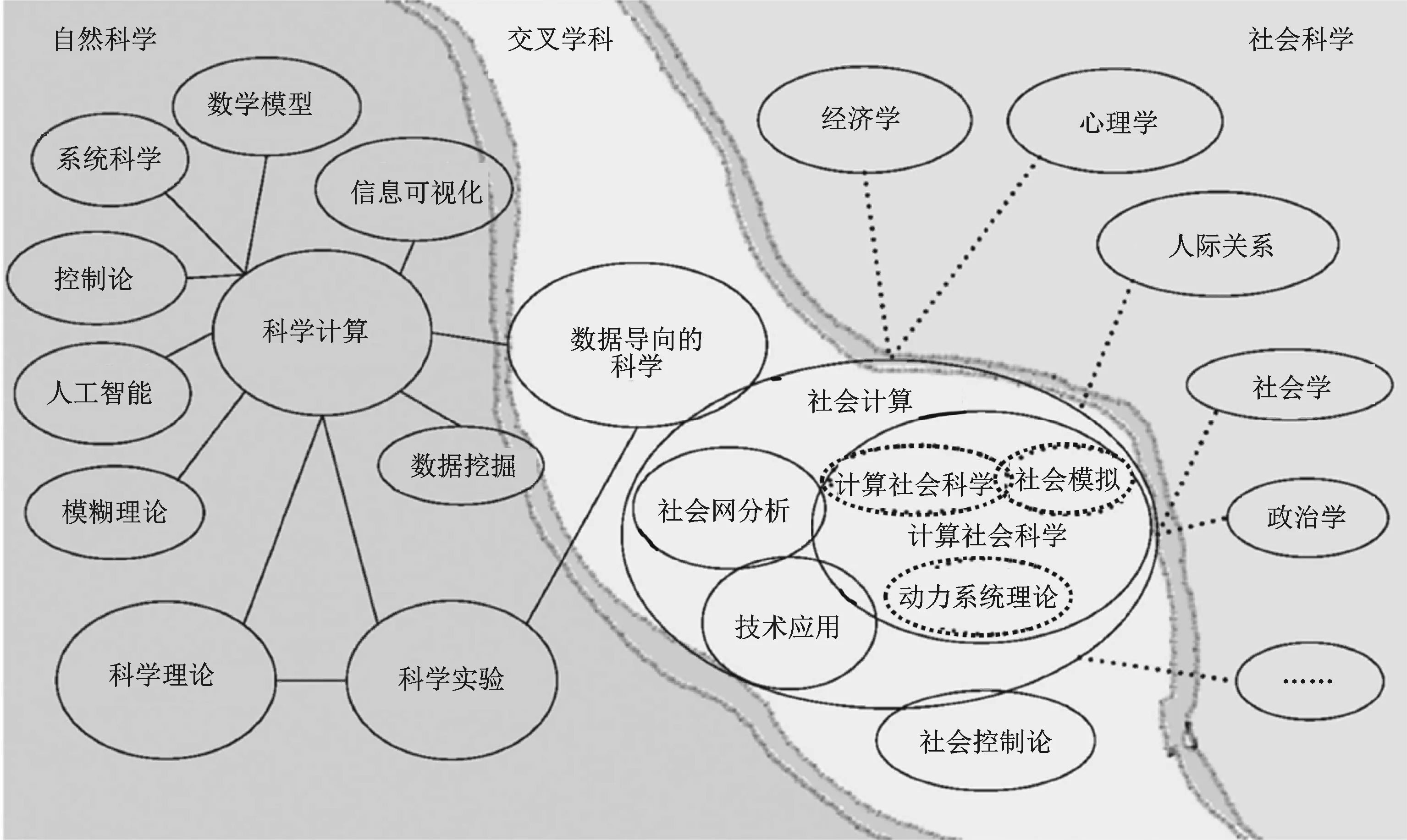
圖1 計算社會學的學科分類示意[23]
與社會學其他分支相比,計算社會學的理論更多來自相鄰分支,而研究方法則從計算科學和數據科學遷移而來。在學科內部,計算社會學是一門提供“范式”的學科,它能夠在方法論和研究方法上開辟新的方向,有助于拆除社會學中定性和定量研究之間的藩籬;從經濟社會學、組織社會學、政治社會學等分支學科汲取理論養分,使學科內部彼此融通;通過多理論整合、多方法融合和多類型數據匹配,將傳統社會學在數據生產上的優勢得以延展。在學科之間,計算社會學采用人工智能和數據挖掘等計算科學方法,不局限于總體性思維,在技術的層面具有天然的開放性和包容性,有助于達成共識;其同時重視理論創新和現實關懷,既可以與管理學、新聞傳播等應用性強的學科交叉,也能與哲學、歷史學等基礎性學科交叉。
(三)研究范式
計算社會學作為一門“范式”型的學科,至少包括方法論和學科定位兩個面向。在方法論層面,歸納和演繹是知識發現的基礎。囿于社會科學的特殊性,歸納和演繹并不能較好地整合起來。計算社會科學的核心之一是數據挖掘,實際上是一個知識發現的過程,包括理解問題領域、理解數據、數據準備、數據挖掘、評估新知識和使用新知識等環節,融合了歸納和演繹兩種研究方法[24]。
由此,計算社會學主要包括兩種:一是理論與數據雙向驅動。單純的數據驅動是在沒有理論假設的前提下,通過模式識別的深度學習方法開展分析和研究,從人類行為互動數據中發現規律,進而給出合理的理論解釋,難以滿足社會科學研究的需要。理論與數據雙向驅動是以現實問題為導向,以社會科學相關領域的理論知識經驗為基礎,提出理論假設和研究框架,然后收集適當的原始數據,并采用適切的分析技術從中提取信息挖掘知識,然后以科學可靠的方式運用數據和知識來檢驗理論假設,最終發現和揭示人類社會的規律[25]。二是理論引導的大數據分析。計算社會學把社會學理論以及研究方法與大數據分析融為一體,為大數據分析開啟了許多新議題。一方面,理論指導下的定性、定量調查可以為數據挖掘的結果提供校準;另一方面,在數據挖掘的結果中也可以找到建構理論的線索,提供驗證理論的資料,從而指導預測模型的建構,推論并解釋更多的現象[26]。
在學科定位層面,與傳統社會學不同,計算社會學更強調理論創新與現實關懷的結合,而不滿足于象牙塔。首先是社會預測。傳統的量化實證研究往往使用全部樣本數據來擬合模型,這樣就導致了擬合的模型往往只能代表對該數據集的分析及過度擬合。機器學習可以為社會科學處理結構更為復雜、樣式更加多元的信息內容,并生成可供分析的變量形式,從而拓展社會科學的研究視界:獲得潛藏指標、啟發理論假說、助力因果推斷、實現數據增生和推動理論創新[27]。
其次是整合“解釋—預測”。需要承認的是,不同類型的學者在價值觀上長期存在分歧。如數據科學家強調開發準確預測的模型,不苛求于因果推斷,時常因為無法解釋而被批評;社會科學家則追求對個體和集體行為提供合理解釋,以因果機制為基礎,在解釋真實世界上存在不足。該范式試圖建立一種綜合模型,提倡一個明確的標簽系統,用以更清楚地描述個人的研究貢獻,識別其所屬的象限,倡導開放的科學實踐[28]。
最后是社會干預。計算社會學有著更強的科學性和應用性傾向,社會計算不僅是技術手段,也是社會現實的生成過程。除了能在研制與開發新型社會計算工具中發揮重要作用,研究計算與社會的關系和有關計算/技術的社會問題同樣是計算社會學的重要內容。在平臺治理中,社會干預可以發展算法治理、開源平臺賦能、社會價值評估、企業社會工作、平臺工作參與、規范制訂和觀念培訓等渠道。
(四)研究方法
計算社會學的研究方法很大程度上受益于計算社會科學。有學者指出,信息的加工在理解社會復雜性方面起到了關鍵作用,而計算社會科學就是基于一種對社會的信息加工范式[16]。目前,計算社會科學已經形成了社會數據計算、互聯網社會科學實驗、社會模擬三大方法體系[29]。除了社會模擬屬于計算社會科學的第一傳統,其他方法均為第二傳統。其中,社會數據計算主要集中于數據挖掘過程,這種方法背后的計算思維強調對所需優化問題的理解,將其分解為不同的任務,最后通過計算機的自動化實現這些分解的任務。社會數據計算的應用場景不僅包括對大數據的清洗(如針對變量缺失、代表性弱、非結構化等),還涵蓋特征提取、交叉驗證、模型校準等,其基礎是機器學習。
機器學習是處理大規模數據和多語義文本的核心,被喻為計算社會科學的元算法[30]。機器學習通常遵循非線性和非參數方法,而不是預先限制模型的復雜性,實現聚類、分類及預測等任務,主要分為監督學習(supervised learning)與無監督學習(unsupervised learning)兩種。與傳統統計模型相比,機器學習模型的復雜性通過一個或多個超參數進行控制,通過交叉驗證進行選擇,提高預測能力,使得它在平均干預效應的因果推斷、項目評估等方面優勢明顯[31]。深度學習是一個復雜的機器學習算法,強調從連續的“層”中學習。機器學習和深度學習的最大區別在于兩者提取特征的方式不同:前者具備自動提取抽象特征的能力,而后者大多是手動選取特征和構造特征。目前,計算社會科學中的算法多為基于機器學習的底層技術,在自然語言處理(NLP)和網絡科學等多個細分方向上深化和拓展。
互聯網社會科學實驗是將互聯網平臺作為一種“實驗室”,運用新興的信息技術作為工具開展隨機實驗。和實驗室實驗、自然實驗等傳統社會科學實驗相比,該方法在樣本代表性、環境仿真度、條件控制力、可復制性、主事者偏差、受試者偏差、內在效度和外部效度等方面都具有不同程度的優勢[29]。目前,互聯網實驗在計算社會學中已經產生了一些影響力,應用主要分為兩大塊:一是通過和線下實驗、自然實驗等傳統實驗結合,提高因果推斷的內外部效率;二是利用互聯網實驗回應大數據時代的一些基礎性命題,如假新聞的傳播、政治極化的擴散、音樂產品的成功等。當然,互聯網實驗能夠在信息技術的更新迭代中得到更廣泛的運用,而它在實驗過程的信度和結果的外部效度上面臨新的不確定性,而且研究倫理如何遵循也還有許多未解。
最后,社會仿真實質上是在計算機中構造與現實世界相對應的人工世界,建立起與真實系統相對應的平行系統,并在人工世界與平行系統中對現實復雜系統進行試驗性研究[32]。如前文所述,社會仿真是生成解釋的主要方法。ABM主要包括主體環境、交互規則、時間尺度等基本要素[10]。其早期主要是從概念模型出發,如模型設置和檢驗往往都屬于抽象概念模型,近年來開始注入實證數據,即數據驅動的自主行動者建模(data-driven agent-based modeling)[33]。與國外相比,社會仿真在國內計算社會學的應用還比較小眾,但已經被用來分析技術擴散、集體行動和社會信任等議題,相關研究呈現增長態勢。在大數據時代,大數據、網絡科學、實驗開始與ABM融合,成為該方法發展的新方向。
四、計算社會學在中國發展的挑戰
計算社會學作為計算社會科學的子集,無法逃脫數據共享、數據基礎設施建設、倫理遵循、學術復合型人才培養等諸多挑戰。然而,計算社會學還具有社會學的基因。費孝通在其學術生涯的最后一篇長文《試談擴展社會學的傳統界限》中強調了社會學“科學”和“人文”的雙重性格,并指出社會學在探索新的領域時,不可避免地要涉及“方法論和方法”的創新。本文將從國家定位與學科自覺、定性與定量、抽樣調查與感應器采集之間的內在張力等方面歸納計算社會學在中國發展可能面臨的挑戰。
(一)學科定位
中國社會學恢復以來,始終堅持“兩條腿”走路,即遵循學科發展規律不斷建立和健全學科體系的同時,回應重大的理論和現實問題。與管理學、經濟學等其他社會科學大類不同,社會學是一個更偏向對社會現象和社會過程進行后驗式解釋的基礎學科,對成果的應用性和產學研轉換要求略低,學科評價還是以理論創新為主導。然而,在新時代,國家對包括社會學在內的哲學社會科學界提出了主動服務國家重大戰略的更高期望,這促使社會學學科必須思考如何增強理論研究與應用研究之間的粘性。
計算社會學自提出以來就有著很強的應用性底色。以社會決策為例,傳統的預測和決策多依賴于對常規性事實的研究,而計算社會學提供了一個應對高度復雜和快速變化環境的高效能、低成本的新工具[6]。加上社會學一直對風險和不確定性有著很強的理論傳統,計算社會學很可能對決策科學帶去突破性的變革,使得社會學的公共政策影響力更強,借此拓展傳統學科界限。如基于疫情相關的行政數據、輿情數據和調查數據進行挖掘,使用ABM建模對疫情防控政策施行的效果進行預測,提升決策的科學性。
當然,計算社會學在學科拓展的過程中要始終保持理論自覺。在計算社會學中,理論和計算的關系不再是單向的指導與被指導關系,而是雙向促進和螺旋上升的過程。理論導向的實證研究是社會學知識生產的重要方式,這種導向在計算社會學中仍然是成立的。也就是說,理論不是變得不重要,而是要更加強調理論的意義。如前所述,機器學習是計算社會學的三大方法之一,在數據準備、數據挖掘和數據理解等環節都離不開理論。除了數據理論和計算理論,還有社會理論。
(二)方法超越
定性和定量研究方法的爭論在國內社會科學中較為普遍。由于社會學兼具“人文”和“科學”雙重性格,加上社會學在中國恢復發展的特定歷史原因,超越定性與定量之爭的問題相對突出。雖然兩種研究方法各具優勢,但有的研究者為了強調所用方法的優越性和普適性而指責其他方法的局限性。事實上,從研究者的角度來看,沒有任何捷徑可以超越該爭論,只有把握多種方法并理解各自的優缺點,才能夠在面對具體的研究議題時,恰當地運用不同的方法組合來較好地進行回答。
然而,必須指出的是,定性定量之爭實際上對學術交流、合作乃至學術評價都產生了直接或間接的影響。相對來說,以定性研究見長的學者更強調個體的創造性,從問題提出、資料收集、文本書寫到成果署名,都凸顯“獨立性”;而量化研究者則更強調團隊的創造力,利用資料收集、操作化測量和統計方法上的開放性和程式化,可以由不同的人在同一框架下通過協作進行知識生產。前者會批評后者除了第一作者均有“掛名”之嫌,研究缺乏“溫度”,而后者批評前者缺乏合作精神,對理論有夸大之嫌。根據筆者的觀察,這種以方法之爭為起點的分野有擴散和強化之勢,并且把研究方法等同于技術,造成“術”與“道”的失衡。
囿于計算社會學天然的量化屬性,也就自然被卷入研究方法之爭。相比于傳統的量化研究,計算社會學的資料收集和分析邊界變得更加模糊,數據挖掘的算法不再僅僅是一種簡單的應用,其團隊協作對成員的知識構成和規模都提出了更高的要求。如今,計算社會科學正在引發數據觀念、研究設計、模型選擇和推論原則等方面的實質性影響,調整了社會科學研究中依賴理論的思維定勢。然而,如果無法超越定性與定量之爭,計算社會學的合法性危機在相當長的時期內都將難以消解。
(三)數據生產
實證社會科學的發展離不開數據的采集及處理技術的進步。事實上,社會學不僅輸出了許多理解人類社會的“語法”,也構建了以抽樣調查為核心的研究方法體系,為知識界生產和積累了大量的高質量數據。有學者批評“讓數據自己說話”是一種“狂妄”,不過如何利用數據創造新知識,一直是社會學家的歷史擔當。然而,作為工業化產物的社會調查,正在受到以感應器為基礎設施的數據生產體系越來越多的挑戰。該挑戰除了數據規模,還表現在數據顆粒化、測量效度、觀測廣度等方面。
與此同時,感應器的背后是龐大的算法系統。在算法融合的社會中,不僅社會、經濟、政治和科學之間相互影響,不同層次上運行算法的形成也被環境所塑造。如圖2所示,當新開發的算法引導新的測量、假設和理論時,科學過程就形成了新的算法平臺。由此,個體和社會層面的各種現象都會受到算法系統的影響,很難將算法和人類行為以及兩者的相互影響完全分離[34]。感應器所生產的數據并非是為社會學研究專門收集的,通過自然語言處理去識別、轉換成結構數據的過程中,存在著用算法去挖掘被算法所生產的數據的復雜境遇。
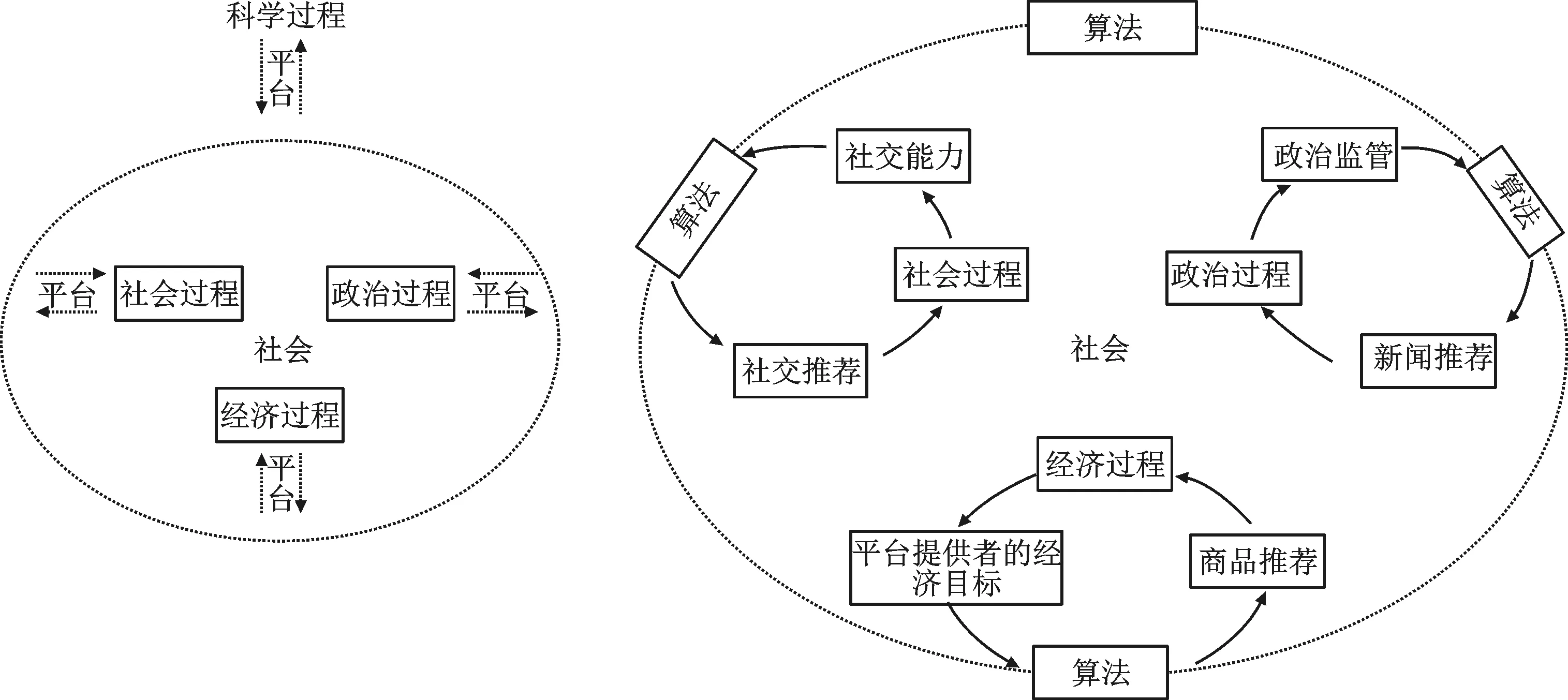
圖2 算法對社會的影響示意[35]
總之,面對以上新變化,探索隨機抽樣與大數據的結合、傳統測量與大數據測量的結合、經典理論與大數據的結合等都是非常有效的應對。然而,大數據資源壟斷導致數據準入限制成為不爭的事實。在算法和社會日益融合的新階段,繼續采用傳統的數據生產手段獲取資料并與大數據對接的思路有著較濃的路徑依賴之嫌。如果社會學希望在資料的生產環節繼續發揮關鍵作用,就必須進行方法和方法論上的創新。那么,計算社會學家是否可以和計算科學家類似,建立起屬于自己的數據收集感應器,并在學術共同體探索共享機制呢?是否可以進入算法生產的前端去干預感應器,以克服數據準入問題帶來的相關研究無法復制和檢驗的困境呢?以上疑問都不失為計算社會學學者思考和探索的新方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
當代陜西(2022年5期)2022-04-19 12:10:18
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:28
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
湘潮(上半月)(2021年4期)2021-07-20 08:05:28
汕頭大學學報(自然科學版)(2020年4期)2020-12-14 07:05:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
