基于多粒度空間混亂的細粒度圖像分類算法
2022-02-18 08:12:30宋思雨苗奪謙
智能系統學報 2022年1期
宋思雨,苗奪謙,2
(1.同濟大學 電子與信息工程學院, 上海 201804; 2.同濟大學 嵌入式系統與服務計算教育部重點實驗室, 上海201804)
細粒度圖像分類是計算機視覺領域中一項非常具有挑戰性的任務,它的目標是對圖像中的物體在同一大類下的許多子類中進行正確分類[1],因此細粒度圖像分類也被稱作子類別圖像分類[2]。細粒度圖像分類存在類內相似度小且類間相似度大的分類難點[3]。在細粒度圖像分類的數據中,具有區分度的重要信息往往包含在一些局部區域,并且多數情況下同一子類別物體也僅有局部微小區域不同,如何尋找到有判別力的局部區域,并借助于極其細微的局部差異較好地完成分類是細粒度圖像分類任務的難點。
近年來深度學習技術[4-6]在人工智能領域已成為主流的方法,對基于卷積神經網絡(convolutional neural networks, CNN)的細粒度圖像分類按照監督信息,可以分為基于強監督信息和基于弱監督信息兩類。基于強監督信息的細粒度圖像分類方法為了獲取更好的分類準確度,除了使用圖像的類別標簽以外,還使用了物體標注框(object bounding box)和部位標注點(part annotation)等額外的強監督信息,而基于弱監督信息的細粒度分類模型只使用圖像級別的標注信息來提取有判別性的局部特征完成分類。為了更好地尋找判別性局部區域,本文提出了一種基于弱監督信息的細粒度圖像分類方法,在骨干網絡中加入多粒度空間混亂模塊。空間混亂模塊對圖像進行碎片化后重組,打破圖像整體關聯性,迫使網絡去尋找對分類更有幫助的局部區域,細粒度圖像分類的重要判別點往往都在這些局部區域。在此基礎上引入多粒度思想[7-9],從多個粒度層面[10]更加全面地尋找不同粒度[11]的局部區域并提取特征,來提高分類準確率。
本文的主要貢獻如下:
1) 提出了一種基于弱監督信息的細粒度圖像分類方法,無需部位級別的標簽,僅需類別標簽即可達到不錯的分類精度,而且模型的空間成本和時間成本低;
2) 提出空間混亂模塊,對輸入圖像進行切分并打亂重組的操作,破壞圖像局部區域之間的關聯性,使網絡更好地尋找有判別力的局部區域,方法簡單但非常有效;
3) 在單一尺度的空間混亂模塊基礎上引入多粒度思想,迫使網絡學習到如何捕捉不同粒度層次的判別性區域,使網絡分類性能更魯棒。
1 相關工作
細粒度圖像分類任務的研究方向主要分為兩種:基于強監督信息和基于弱監督信息的細粒度圖像分類。區別在于,基于強監督信息的方法在模型訓練階段,為了獲得更好的分類精度,除了圖像的類別標簽外,還使用局部區域位置和標注框等額外的人工標注信息,用于定位圖像局部關鍵區域。而基于弱監督信息的細粒度圖像分類的方法僅僅依靠圖像級別的標簽,在不借助部位標注的情況下對細粒度圖像進行分類。
1.1 基于強監督信息的方法
最早的具有代表性的方法是2014年被提出的基于部位的區域卷積神經網絡[12],該方法使用自底向上的區域選擇算法[13]來產生候選區域,用區域卷積神經網絡(regions with convolutional neural networks, R-CNN)算法給出評價分值,選出分值高的區域,進行特征級聯作為總體特征送進支持向量機(support vector machines, SVM)分類器進行分類。Branson等[14]提出了姿態歸一化網絡,該研究工作采用對不同級別的圖像塊進行姿態對齊[15]的操作。來自悉尼科技大學Huang等[16]在2016 年提出了部位堆疊網絡(part-stacked CNN),在部位級別的定位過程中采用了全卷積網絡[17],引入全卷積網絡的好處在于特征圖可以直接作為部件的定位結果應用于分類網絡。Lin[18]提出的深度定位對齊分類網絡(deep localization alignment and classification, Deep LAC)使用同一個網絡進行部件定位、對齊和分類,并且提出了閥門連接函數(valve linkage function, VLF)用來優化定位和分類子網絡之間的連接。南京大學的魏秀參[19]在2017 年提出了 掩碼卷積神經網絡(mask CNN) ,該網絡利用全卷積網絡生成掩碼,用于局部定位和選擇深度描述符[20]構建圖像、頭部、軀干和對象的四流網絡,該網絡是第一個端到端的用于細粒度圖像分類網絡模型。盡管基于強監督信息的分類模型獲得了不錯的分類精度,但使用的部位級標注信息獲取困難且代價昂貴,使得這類算法的實際應用被局限了。
1.2 基于弱監督信息的方法
目前細粒度圖像分類的一個明顯趨勢是在模型訓練時僅使用圖像級別標注信息,而不再使用額外的部位級別標注信息。 2015年兩級注意力模型被提出,作者發現注意力機制對于細粒度圖像的局部特征有很好的提取效果。同年文獻[21]提出了多粒度卷積神經網絡,該模型包含多個獨立的CNN, 每個CNN內部有不同粒度的興趣域。2016年Liu Xiao提出了一種基于強化學習的全卷積注意力局部網絡[22]提出了一種基于強化學習的全卷積注意力局部網絡,這個網絡模擬人類視覺系統的識別過程,將相關區域放大處理進行進一步判斷。 Lin等[23]設計了 雙線性卷積神經網絡(bilinear CNN),該模型非常高效而且數學基礎扎實,其中的雙線性池化(bilinear pooling)[24]提供了比線性模型更精確的特征表示,并且可以端到端的進行優化,但是雙線性模型的維度太高,很難泛化使用。
1.3 DCL
破壞和重建學習網絡[25](destruction and construction learning, DCL)是一種新穎的細粒度圖像分類模型,該模型引入一個DCL流來自動從判別性區域中進行學習。 首先作者借鑒了自然語言處理中常用的打亂方法,提出區域混淆機制來劃分輸入圖像并隨機打亂它們,同時引入對抗性損失降低噪聲的影響,使網絡進行破壞學習,然后提出區域對齊網絡恢復原始區域布局,通過重建對局部區域間的相關性進行建模。文獻[25]的RCM部分將圖像分為N×N的局部區域,其中N被固定為7,這種情況下模型只能劃分固定尺度大小的局部區域 無法獲取到多種尺度的局部區域特征。本文將結合多粒度思想并參考DCL的RCM部分,將圖像分為不同粒度大小的局部區域,從而使模型關注到不同尺寸大小的判別性局部區域用于分類。
2 空間混亂模塊
在細粒度圖像分類任務中,局部細節往往比全局結構信息更加重要。多數情況下不同的細粒度類別具有相同的全局結構而只在具體的局部細節上不同。將圖像中的局部區域打亂,對細粒度識別不重要的一些不相關的區域就會被忽略,并且將迫使網絡學習到具有辨別性的局部細節,從而更好地對圖像進行分類。
在自然語言處理中,打亂句子中單詞的順序會迫使神經網絡聚焦有判別性的詞語,忽視無關詞語。同樣,將圖像分為多個局部區域,把局部區域看作自然語言處理中的單詞,然后進行隨機的打亂重組,神經網絡將更專注于從有判別性的局部區域學習分類的細節。為此,本文提出空間混亂模塊,對輸入圖像進行碎片化打亂重組。
如圖1所示,本文定義的局部區域隨機重組模塊將會對輸入圖像的局部區域進行打亂重組,得到新的局部區域無關聯性的圖像。這個模塊的輸入是一張圖片I,圖片的邊長n(輸入圖片應該為經過大小歸一化處理的正方形,故只需要邊長即可)和劃分粒度G,其中I是圖片的三維向量,n代表圖片的邊長,即圖片的尺寸是n×n像素,G代表將圖片劃分為G×G個子區域。首先,每個區域標記為R(k) ,k是將子區域劃分后的一維排序的序號, 1 ≤k≤G2,子區域也可以用R(i,j)表示,i和j分別表示行索引和列索引, 1 ≤i,j≤G。可以通過i,j來表示k,具體為
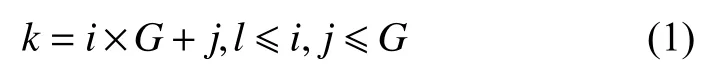
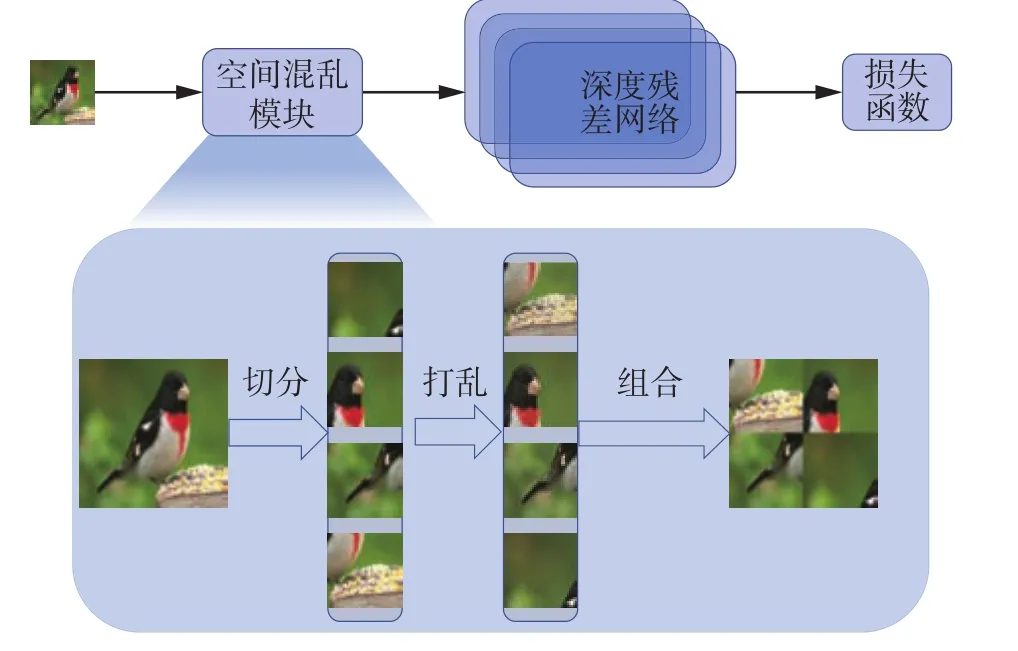
圖1 空間混亂模塊的流程Fig.1 Process of regions shuffle
圖片大小和粒度相除可得到子區域的邊長s,即子區域的尺寸是s×s。利用邊長s可以計算第i行第j列的子區域的圖片的三維向量,用d來表示向量的維度,具體為
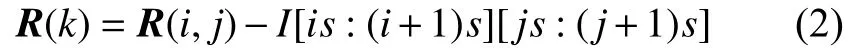
將劃分好的有序子區域進行隨機化,生成一個長度為G2的隨機向量q,第m個元素的值為r,其中 1 ≤m≤G2。向量q的元素取值r,服從U(1,G2)的均勻分布,即r的值在(1,G2)的區間內等概率隨機選取一個值,概率公式如式(3)所示,向量q的表示如式(4)所示。
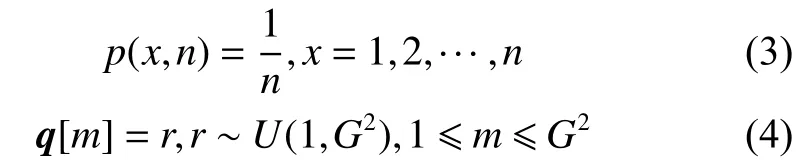
原來的子區域列表按照隨機向量q進行重新排列,得到新的子區域列表,然后按照對應位置進行拼接,得到重組后的完整圖像I:
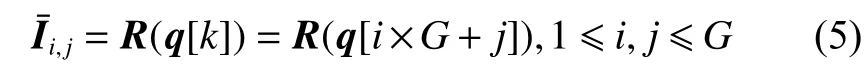
空間混亂模塊的流程如算法1所示:
算法 1空間混亂算法
輸入I,G,n,q
輸出
1)s←n/G
2) fori= 1,2,···,Gdo
3) forj= 1,2,···,Gfor j = 1,2,···,Gdo
4)R(i,j) ← I[is: (i+1)s][js: (j+1)s]
5)k←i×G+j
6)R(k) ←R(i,j)
7) end for
8) end for
9) fori= 1,2,···,Gdo
10) forj= 1,2, ···,Gdo
11)k←i×G+j
13) end for
14) end for
該模塊需要被添加在神經網絡的訓練初始階段,從而引導網絡去學習細粒度圖像的重要細節。經過該模塊處理后的局部區域混亂的圖片能迫使網絡尋找那些對分類有幫助的局部區域,并從這些局部區域中學習到相應的特征。
本模塊的粒度參數的設置和添加輪次的選擇將會在第4節實驗部分給予詳細說明。
3 融入多粒度思想
粒計算是一種粒化的思維方式及方法論,粒計算中的多粒度思想可以看作是用一種基于多層次與多視角的問題求解方法。 給神經網絡輸入的數據集中的原始圖片就可以看成最粗粒度的信息,本文第2節所述的空間混亂模塊從粒計算角度來看,是將圖像的粒度細化,得到更細粒度的信息的過程。
細粒度圖像分類數據集中的物體外形都是相似的,可能只有很小的部位不同。比如CUB200數據集中,不同鳥類可能只是眼睛顏色不同或者翅膀的形狀不同,能正確決定分類結果的就是一些有判別力的局部區域,但這些局部區域有大有小,比如翅膀相對眼睛是較大的,那么翅膀的形狀在粒度較大的局部區域容易被神經網絡所捕捉到,而眼睛在粒度較小的局部區域才會被網絡發現是具有判別力的特征。
前文所述的空間混亂模塊,是希望網絡忽視圖像的整體關聯性,專注于學習如何尋找具有判別力的局部區域,但是,具有判別力的局部區域可能并不都在一個粒度層次上。本文引入空間混亂模塊的作用其一就是希望網絡不會僅僅學習到原始圖像的最粗粒度的特征,也能學習到如何去尋找小的局部區域的有用特征。
由于圖像分辨率不同以及待分類物體在圖像中的占比大小不同,導致即使進行空間混亂模塊后,同一類別的圖像得到的局部區域代表的特征意義依然不同。如圖2所示,同一類別下的圖像中的物體由于大小和占比不同,經過空間混亂模塊后得到的局部區域代表的部位意義也是有所區別的,上面的圖片網絡明顯可以學習到頭部級別的信息,下面的圖片網絡更關注的會在眼睛和喙。如果能在此基礎上將圖片通過其他粒度的空間混亂模塊后,每個粒度做獨立的引導,那么模型可以在不同的粒度學習到更多信息,做決策時將更加魯棒。

圖2 同一類別下的不同圖片經過空間混亂模塊后的結果Fig.2 Results of two images from the same category after regions shuffle
綜上所述,對第2節中提出的空間混亂模塊融入多粒度思想進行改進。原始圖像是粒度最大的,網絡最容易從中學到整體輪廓這種物體級別的特征,但細粒度圖像分類的模型只學習到大體輪廓是難以獲取到較好的分類結果的。將空間混亂模塊的粒度參數設置為不同的值,隨著劃分粒度的增加,模型將能關注到越來越微小的局部區域信息。
圖3演示了當把空間混亂模塊的粒度參數分別設為2、4、7的時候,同一輸入的圖像所能獲得的不同粒度下的結果。圖3中的兩個原始圖像屬于兩個不同的子類別,兩個子類別細致的差異在于其中一個類別的鳥類面部是紅色的,而另一個是黑色的且頸部有不同,除此之外的體型輪廓、大致顏色都是相近的。通過不同粒度的劃分,可以明顯觀察到,經過粒度為2的空間混亂模塊的結果可以從頭部進行一定程度的區分,但差異性并不大,因為頭部形狀是相近的。但在經過粒度為4的空間混亂模塊后,左圖的第1行、第1列和右圖的第3行、第4列有明顯不同,可以區分,網絡學習到如何在這個粒度下找到這兩個判別性的區域將會對分類有非常大的幫助。這是單一粒度的空間模塊所不能實現的效果。
4 實驗與結果
本節將通過實驗闡述本文提出的技術的可行性和效果。具體包括使用本文提出的技術構建了一個模型,并且在3個標準細粒度圖像分類數據集上評估了模型的性能,與其他主流算法的效果進行對比,并添加消融實驗驗證各模塊的效果,實驗過程中沒有使用任何部位標注信息。
4.1 實驗數據集
本次實驗在3個細粒度圖像分類數據集進行。3個數據集分別是CUB-200-2011鳥類數據集[26]、FGVC Aircraft飛機數據集[27]和 Stanford Cars車類數據集[28]。表1展示了3個數據集的詳細信息。
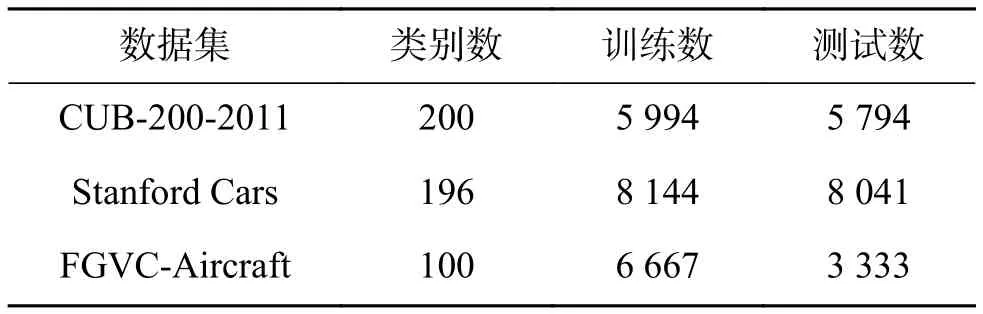
表1 細粒度圖像分類數據集Table 1 Fine-grained visual classification datasets
4.2 實驗細節
實驗環境:本文實驗所使用的深度學習框架是PyTorch,使用的顯卡是Tesla V100。
實驗參數細節:模型分別采用兩種骨干網絡,即 ResNet-50[29]和VGG-16[30],這兩個骨干網絡均采用ImageNet數據集進行預訓練。訓練所使用的唯一標注信息是圖像的類別標注信息。輸入圖片將被調整為512×512的固定大小,然后隨機裁剪成448×448。 圖像的數據增強操作包括隨機水平翻轉和隨機旋轉。 模型采用的優化器是隨機梯度下降法(stochastic gradient descent, SGD),其中動量參數設置為0.9,學習衰減率為0.000 1。訓練的最大迭代輪次(Epoch)設為180,小批量樣本數(mini-batch size)設為6,初始學習率設為0.001,并且每60輪衰減一次,衰減權重0.1。
多粒度空間混亂模塊參數設置:粒度層次為3,具體粒度分別為2、4、7。多粒度空間混亂模塊在第90輪開始加入到網絡中,前90輪不使用多粒度空間混亂模塊。測試階段不使用該模塊。
4.3 實驗結果
首先對于多粒度空間混亂模塊的參數設置都是經過實驗得出的,主要包括使用輪次選擇和多粒度空間混亂模塊的粒度選擇。多粒度空間混亂模塊不適用于所有輪次,會增加噪聲,不利于模型分類精度的提高,根據先整體后局部的思想和先局部后整體的思想分別進行了實驗,先整體后局部的思想的具體實施是前90輪次禁用該模塊,90~180輪次采用該模塊;先局部后整體的思想是前90輪次采用該模塊 ,90~180輪次禁用該模塊,最后得出最佳的方案是前90輪次禁用該模塊,90~180輪次采用該模塊。這說明模型先學習整體特征再學習局部區域特征是一種更有效的學習順序。進行粒度選擇分為粒度層次的選擇和粒度組合的選擇。粒度層次過多則模型復雜度會過大,并且隨著粒度層次的增加并不會帶來明顯的準確度提升,通過嘗試2層、3層和4層3種粒度層次,發現3層時效果最好。確定粒度層次后,還要選擇具體的粒度組合,實驗使用2、4、7、14這4種粒度進行組合,最大的粒度為14 ,因為更大的粒度將使圖片完全混亂,對網絡沒有幫助反而降低網絡的分類準確率。具體實驗結果如表2所示,采用數據集為CUB-200-2011。
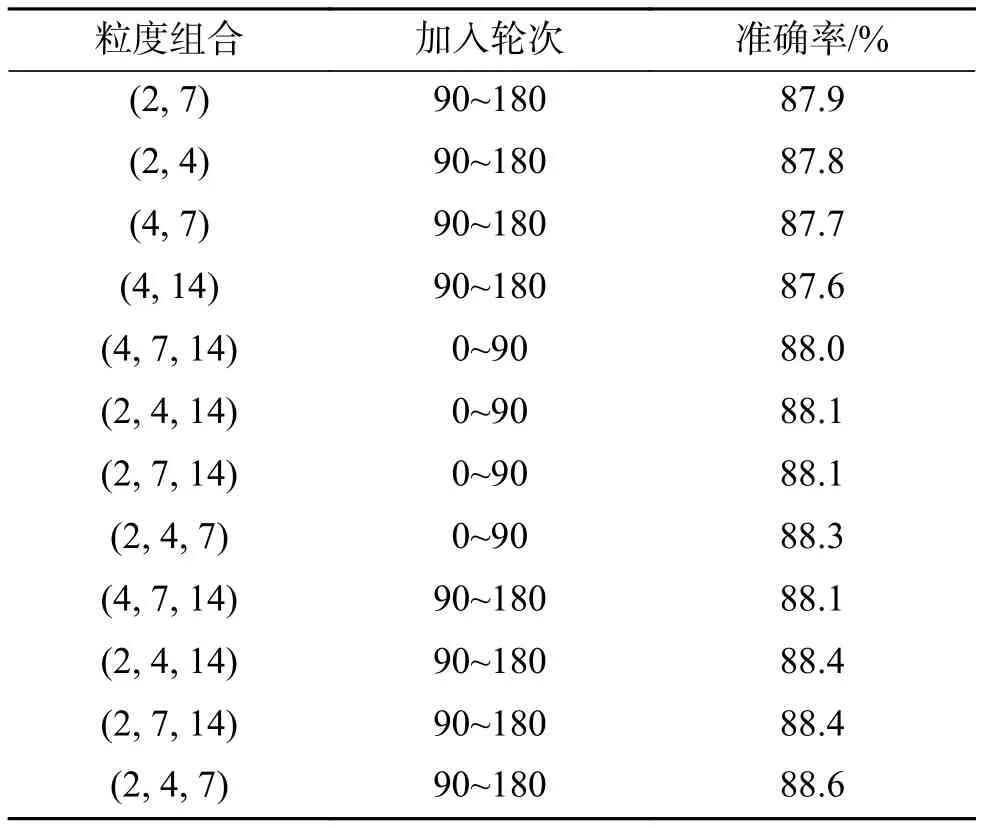
表2 不同粒度的結果Table 2 Results of different granularity combination
進行消融實驗,來體現多粒度空間混亂模塊對于模型分類準確度的貢獻,在加了粒度為4的空間混亂模塊后,網絡分類的準確率提高了2.0%,引入多粒度思想后,網絡分類的準確率提高了3.1% ,采用數據集為CUB-200-2011,如表3所展示。

表3 消融實驗Table 3 Ablation experiment
實驗采用的模型無需任何部位級別標注,相對于其他需要對物體或部位進行定位或者采用多級網絡的方法,空間復雜度和時間復雜度都有一定程度的降低,并且依然可以有較好的分類準確度。其中使用ResNet-50作為骨干網絡時的準確率優于其他算法,對比其他算法的準確率如表4所示。
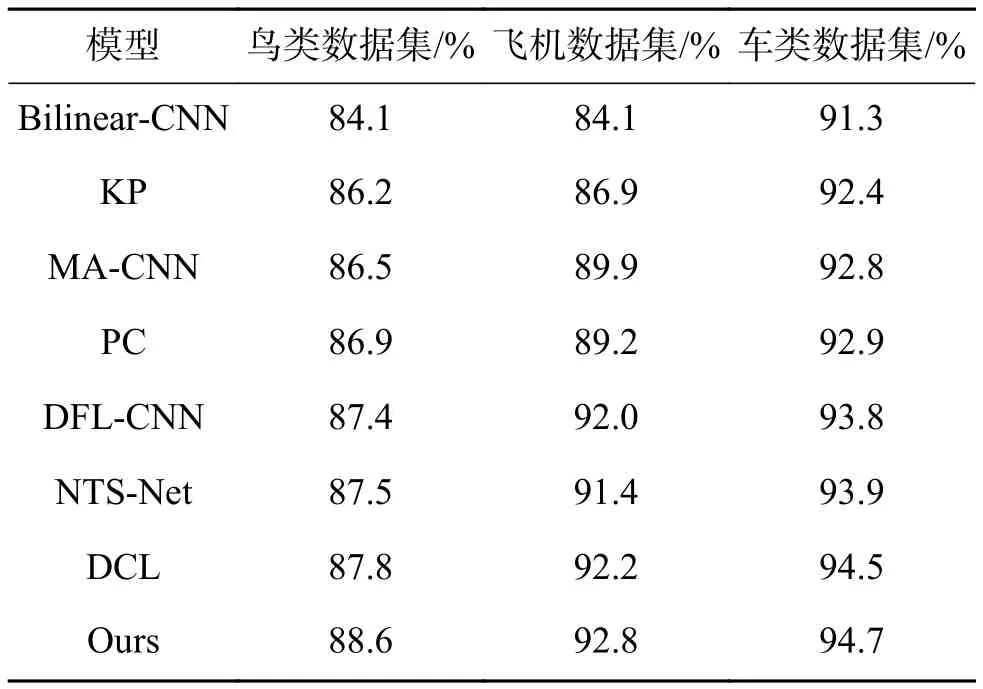
表4 對比結果Table 4 Comparison results
5 結束語
本文提出了多粒度空間混亂模塊。 多粒度空間混亂模塊是一個輕量級的模塊,不會引入過多開銷,但是可以通過引導網絡學習尋找不同粒度下的判別性區域,來提高網絡分類的準確率,是簡單且實用的。未來會考慮不只在原始圖像上進行隨機打亂重組的操作,也在網絡中的某一層的特征表示上進行一些混淆操作。.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
