一種基于逆近鄰和影響空間的DBSCAN聚類分析算法
2022-02-19 11:16:48劉宏凱張繼福
計算機應用與軟件 2022年2期
劉宏凱 張繼福
(太原科技大學計算機科學與技術學院 山西 太原 030024)
0 引 言
作為數據挖掘和機器學習的主要研究分支之一,聚類分析是一種廣泛使用的無監督學習技術。聚類分析[1]在沒有使用任何先驗知識情況下,側重于將數據集中的數據對象聚到簇中,目的是使簇內的數據對象相似性最大,并使不同簇間的數據對象相似性最小。基于密度的聚類算法[2]是一種典型聚類分析方法,其具有處理和識別噪聲的能力,發現具有任意形狀的簇和自動識別簇的能力等優點,并廣泛地應用于化學[3]、模式識別[4]、圖像處理[5]、機器學習[6]和生物學[7]等領域。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)作為一類有代表性的密度聚類分析方法,具有聚類速度快、預設參數對聚類結果的影響小和有效識別噪聲對象等優點[8]。但其在聚類簇擴展過程中,由于核心對象的K近鄰與逆近鄰并集中包含的其他核心對象[8]可能屬于不同密度的相鄰聚類簇,并將原本屬于不同密度簇的核心對象聚到同一個聚類簇中,從而造成在聚類簇擴展過程中,無法區分不同密度的相鄰聚類簇,未能有效地體現真實的數據分布。本文采用逆近鄰和影響空間相結合的思想,提出了一種密度聚類分析方法。該方法利用了逆近鄰和影響空間形成聚類簇,數據對象與其影響空間中其他核心對象的鄰域關系是對稱的,從而保證了同一影響空間中核心對象屬于同一密度的聚類簇,能夠較好地估計鄰域密度分布,并識別出不同密度的相鄰聚類簇。
1 相關工作
聚類分析是數據挖掘、機器學習等領域中主要研究內容之一,可劃分為基于統計[9]、基于分層[10]、基于模型[11]、基于密度、基于網格[12]和基于子空間[13-16]的方法等。基于密度的聚類分析是將密度大于預設閾值的區域定義為密集區域,并通過連接密集區域形成聚類簇。
密度聚類作為一類聚類分析方法,具有能夠發現任意形狀的聚類簇,可以很好地描述真實的數據分布特征,不需要預先設置要形成聚類簇的數量,數據集中數據對象的順序與聚類結果無關等優點。Ester等[17]提出了著名的DBSCAN算法。此算法在聚類簇的密度不均勻、簇間距相差大時,聚類質量較差;對于高維數據,存在“維數災難”問題。Vadapalli等[18]提出了RECORD算法。該算法無須輸入任何預設參數,可以很好地反映數據集分布特征,但當一個離群點距離兩個聚類簇的距離相等時,此算法對離群點簇標簽的分配是不確定的。王晶等[19]提出了密度最大值聚類算法(MDCA)。其使用密度而不是初始數據對象作為考察簇歸屬情況的依據,能夠發現任意形狀的聚類簇并且不依賴初始數據對象的選擇,但此算法需要在聚類前確定密度閾值;不適合數據集密度差異較大或整體密度基本相同的情況。夏魯寧等[20]提出了可以自動確定Eps和minPts參數的SA-DBSCAN算法,但其對于密度不同的相鄰聚類簇聚類效果較差。Cassisi等[21]提出了ISDBSCAN算法。此算法進行離群點檢測階段會錯誤地將核心對象識別為噪聲對象除去,并且引入了第二個參數,降低了聚類精度。He等[22]提出了MR-DBSCAN并行算法,此算法在嚴重偏斜的數據環境中也能實現理想的負載平衡。Rodriguez等[23]提出了密度峰值聚類算法(DPC),其能快速發現任意數據集的聚類簇中心,并能高效地進行聚類與離群點去除,但該算法在數據集規模小時,主觀選擇的截斷距離對聚類結果影響較大。Lü等[24]提出了ISBDBSCAN算法。其在ISDBSCAN算法的基礎上,提出了非核心對象聚類的方法,但當兩個核心對象到一個非核心對象的距離相等時,此算法對非核心對象簇標簽的分配是不確定的。Bryant等[8]提出了RNNDBSCAN算法,該算法只需要一個預設參數,但由于采用K近鄰與逆近鄰的并集進行聚類簇擴展無法識別不同密度的相鄰聚類簇,降低了聚類精度,并且聚類簇擴展過程中占用內存過大,降低了聚類效率。Parmar等[25]提出了基于殘差的密度峰值聚類算法(REDPC),采用殘差計算來測量鄰域內的局部密度,為聚類簇質心的識別提供了更好的決策圖。
綜上所述,密度聚類分析方法存在著當數據集大時,時間復雜度高;“維度災難”,無法適用于高維數據集;識別邊界點的簇標簽不確定;當各個聚類簇的密度不均勻或聚類簇間的距離相差很大時,未能有效地識別或區分不同密度的相鄰聚類簇等缺點,從而影響了聚類分析的精度和效率。
2 相關定義
2.1 K近鄰與逆近鄰
K近鄰[26]是一種基本分類與回歸方法,其目的是查找數據對象在數據集D的K密度聚類個最近鄰數據對象。K近鄰可以應用于分類、聚類、離群點檢測、模式識別和入侵檢測等領域中。逆近鄰是在K近鄰的基礎上提出來,其含義就是在數據集D中找出將給定數據對象y作為其K近鄰的數據對象集合。數據對象的逆近鄰是基于全局的角度來檢查它的鄰域,數據分布的改變會導致每個數據對象的逆近鄰發生改變,并且不會像K近鄰一樣隨著維數的增加會出現“維數災難”問題。
定義1(K近鄰) 數據對象x的NNK(x)表示為距離x最近的K個數據對象的集合,其滿足以下條件:
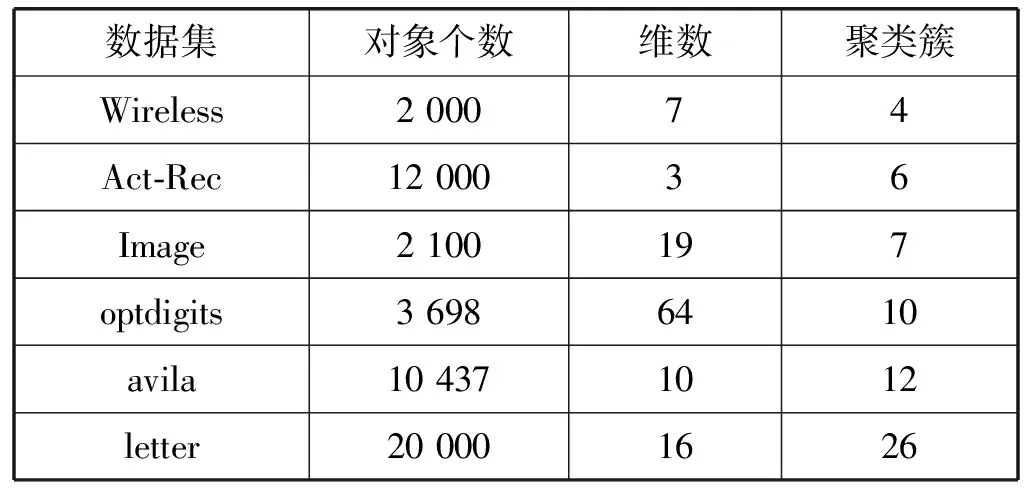
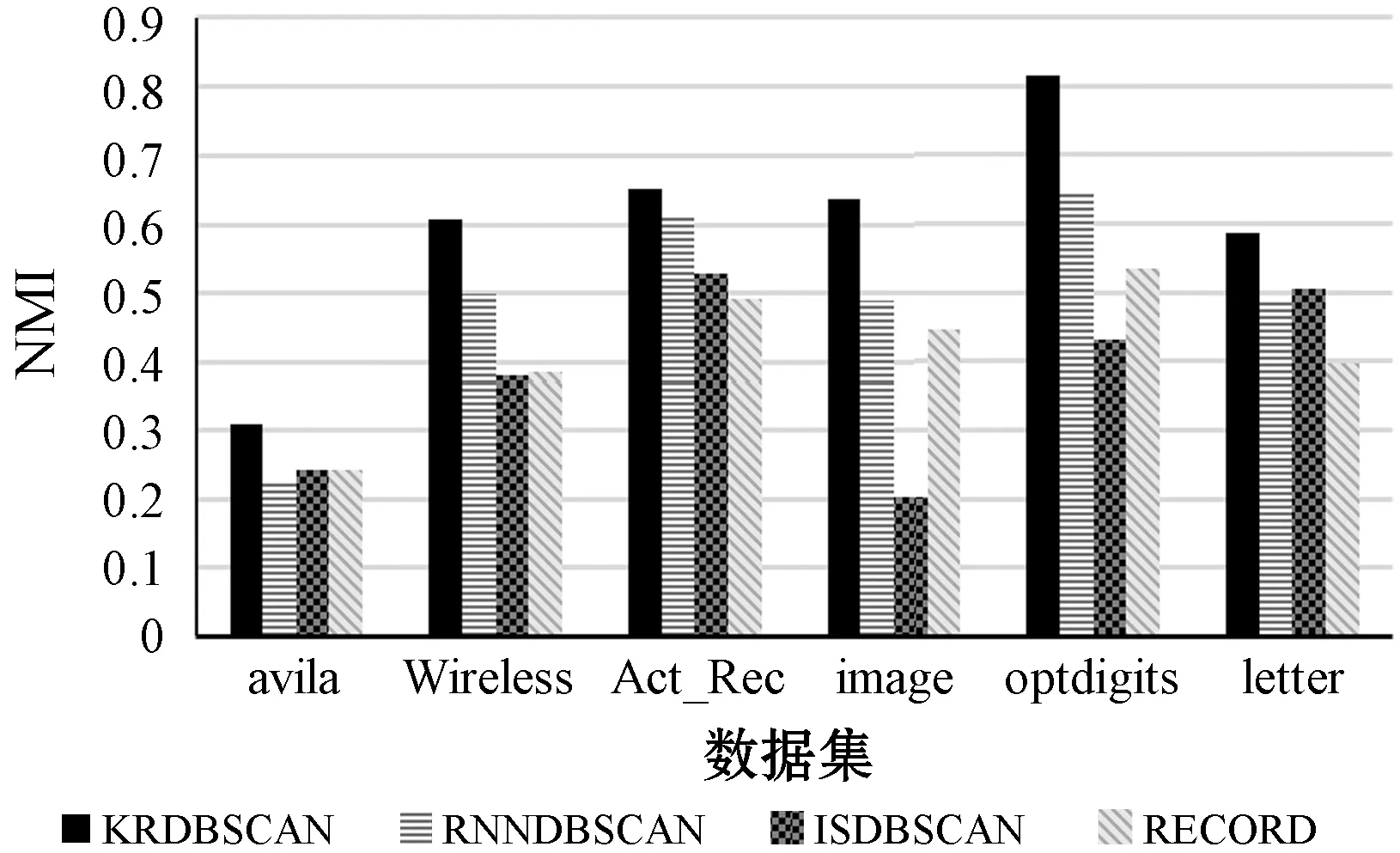
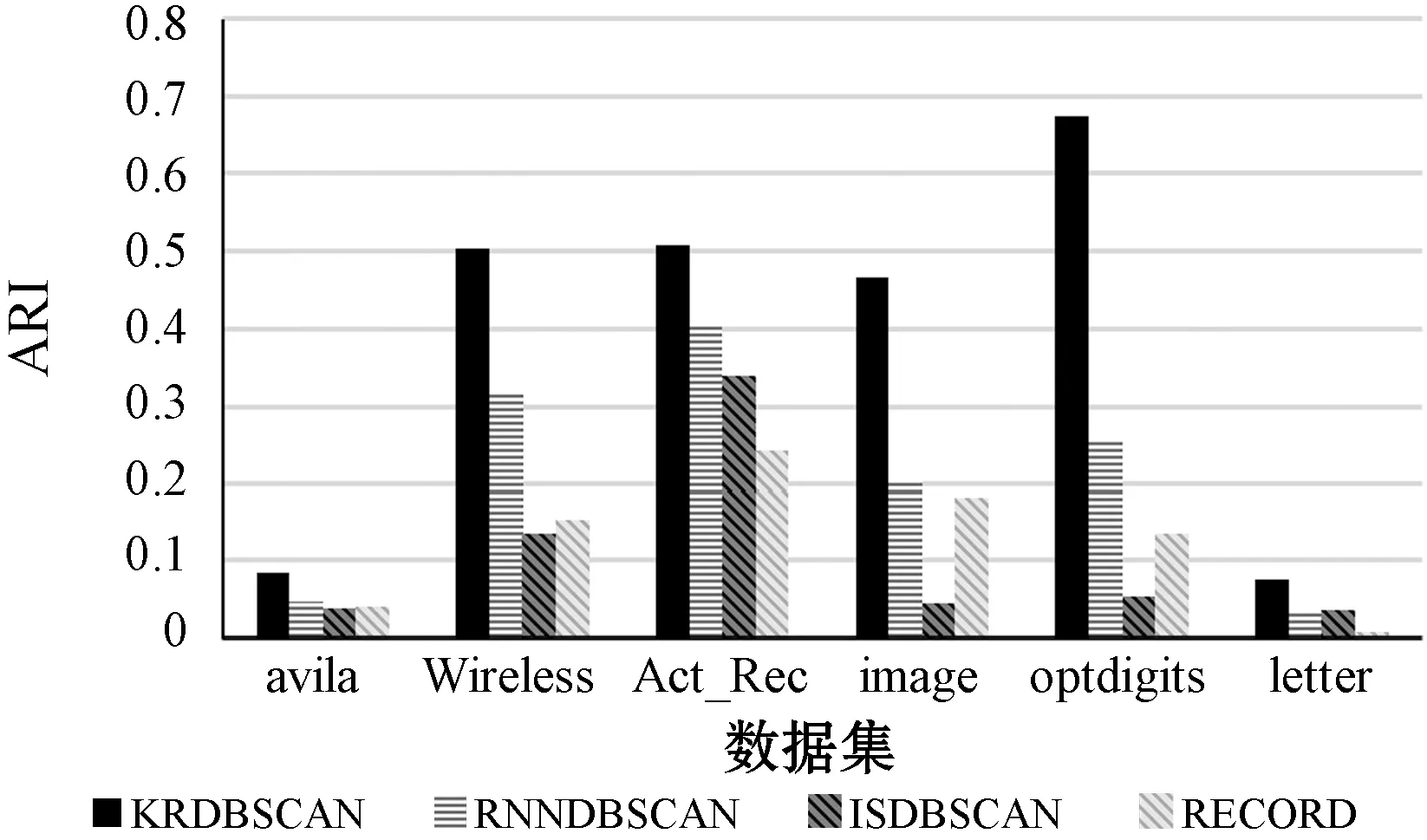
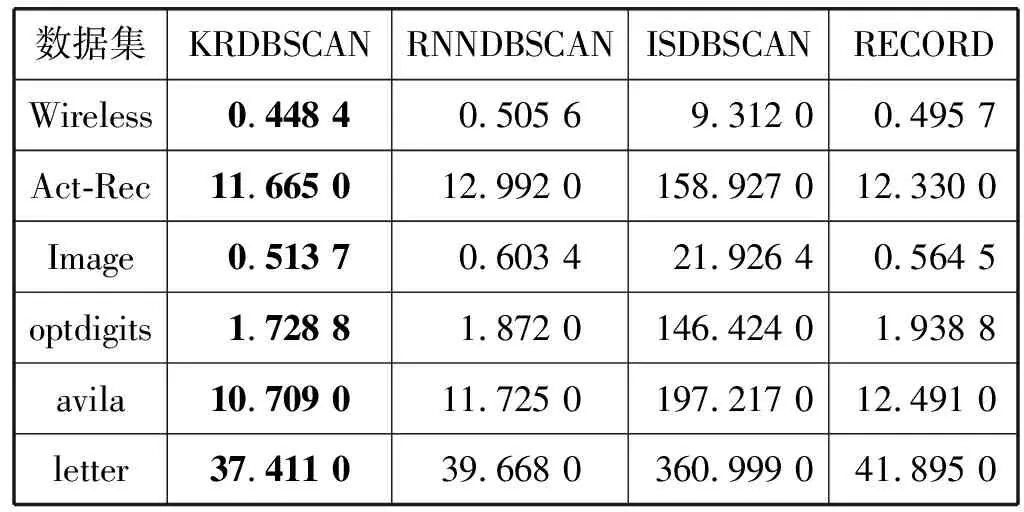
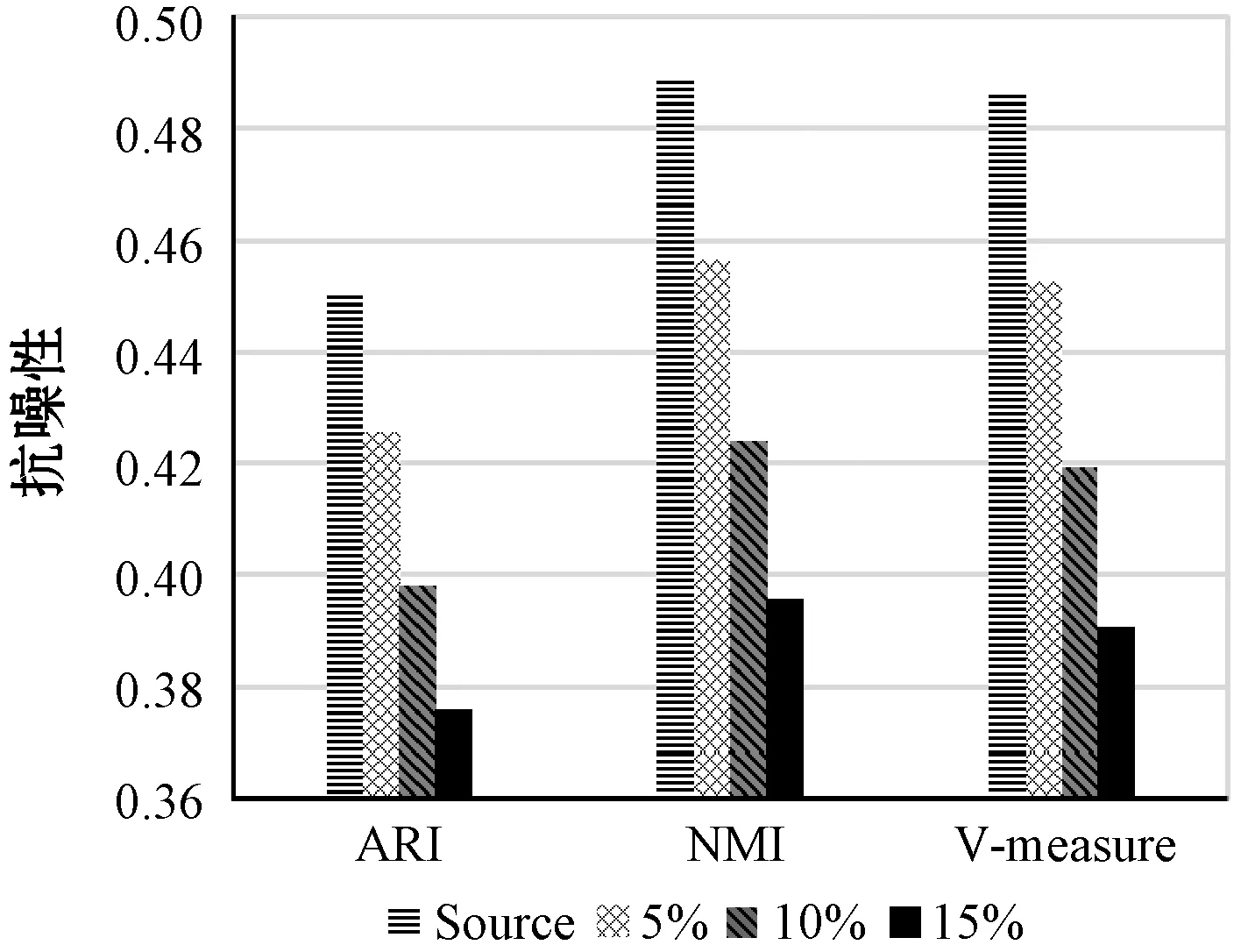
?y∈D/{x,NNK(x)},z∈NNK(x):dist(x,z) 定義2(逆近鄰) 數據對象x的RNN(x)表示為某些數據對象的K近鄰中包含數據對象x的數據對象集合,其滿足以下條件: ?x,y∈D:x∈NNK(y),y∈RNN(x) 對于任意給定數據集D,其所包含的數據對象數為n=|D|,任意數據對象x∈D含有d維屬性,RNN(x)表示數據對象x的逆近鄰集,NNK(x)表示數據對象x的K近鄰集,dist(x,y)表示數據對象x和y之間的歐氏距離。參照文獻[8],相關概念定義如下: 定義3(相似性距離度量) 在數據集D中,數據對象x和y的相似性度量dist(x,y)定義如下: (1) 定義4(核心對象、邊界對象、噪聲對象) 在數據集D中,如果數據對象x的逆近鄰|RNN(x)|≥K,則稱x為核心對象。如果數據對象x的逆近鄰|RNN(x)| 定義5(直接密度可達性) 如果數據對象y直接密度可達數據對象x,則其滿足以下條件: ?x,y∈D:x∈NNK(y)Λ|RNN(y)|≥K 因為數據對象的K近鄰集關系是非對稱的,所以核心對象之間的直接密度可達性是非對稱的。因為核心對象與非核心對象之間的直接密度可達性也是非對稱的,所以非核心對象不具有直接密度可達性。 定義6(密度可達性) 密度可達性是直接密度可達性的擴展,如果數據對象y密度可達數據對象x,則其滿足以下條件:存在數據對象序列x1,x2,…,xm,xm可由xm-1直接密度可達,其中: ?x1,x2,…,xm:x1=yΛxm=xΛ|RNN(y)|≥K 定義7(密度連接) 如果存在數據對象z,使得數據對象x和y可從數據對象z密度可達,則數據對象x和y是密度連接的。密度連接對于所有的數據對象都具有對稱性。 定義8(聚類簇) 如果數據集D中存在非空聚類簇C,則滿足條件:(1) 對于數據對象x和y,若數據對象x∈C且x密度可達數據對象y,則數據對象y∈C;(2) 對于數據對象x和y,有x∈C,y∈C,則x是密度連接于y。 定義9(影響空間[18]) 在數據集D中,將數據對象x∈D的逆近鄰集RNN(x)與K近鄰集NNK(x)的交集定義為x的影響空間IsK(x),且滿足以下條件: IsK(x)=RNN(x)∩NNK(x) 在文獻[8]中,RNNDBSCAN算法采用了K近鄰與逆近鄰的并集進行擴展聚類簇。由定義1和定義2可知,由于數據對象K近鄰的鄰域關系和逆近鄰的鄰域關系都不具有對稱性,因此,數據對象與其K近鄰和逆近鄰并集中數據對象的鄰域關系也不具有對稱性。由定義5可知,數據對象與其K近鄰和逆近鄰并集中數據對象的直接密度可達性是非對稱的,不能保證數據對象與其K近鄰與逆近鄰并集中的數據對象同屬于相同密度的聚類簇。在密度聚類分析中,采用K近鄰與逆近鄰的并集進行聚類簇擴展無法區分不同密度的相鄰聚類簇,從而造成聚類效果無法真實地反映數據對象的分布特征。 由定義5可知,因數據對象的K近鄰關系是非對稱的,則數據對象間的直接密度可達是非對稱的。由定義9可知,任意數據對象x∈D與其影響空間中的其他數據對象間互為K近鄰,則數據對象x與其影響空間中數據對象的鄰域關系具有對稱性。存在數據對象y∈D為核心對象(|RNN(y)|≥K),由于核心對象y與其影響空間中的任意核心對象間互為K近鄰,使其K近鄰關系具有對稱性,保證了核心對象y與其影響空間中核心對象的直接密度可達具有對稱性。由定義7和定義8可知,核心對象y∈D的影響空間中任意數據對象是密度連接的,保證了核心對象和其影響空間中其他的核心對象屬于相同密度的聚類簇。因此,數據對象x∈D可進行聚類簇擴展,應滿足的條件重新描述如下: |RNN(x)|>kΛIsK(x)≠NULL (2) 在文獻[8]中,RNNDBSCAN算法利用數據對象的K近鄰和逆近鄰的并集進行聚類簇擴展,因該并集中的數據對象可能屬于不同密度的相鄰聚類簇,造成了聚類算法無法識別不同密度的相鄰聚類簇這一問題。在使用影響空間進行聚類簇擴展過程中,對于核心對象y的影響空間IsK(y),若IsK(y)=NULL,由式(2)可知,y不滿足聚類簇擴展的條件,因此無法從核心對象y進行聚類簇擴展,可暫且將核心對象y標識為“候選噪聲對象”,并在噪聲處理過程中,利用其K近鄰關系將其與真正的噪聲對象區分開;若IsK(y)≠NULL,由式(2)可知,y滿足聚類簇擴展的條件。由定義9可知,因核心對象y與其影響空間IsK(y)中的任意核心對象互為K近鄰,保證了核心對象y與其影響空間IsK(y)中的任意核心對象屬于相同密度的聚類簇,提高了聚類算法區分不同密度簇的能力和聚類精度。由定義9可知,影響空間是K近鄰和逆近鄰的交集,影響空間中數據對象數明顯少于RNNDBSCAN算法進行聚類簇擴展中使用的K近鄰和逆近鄰的并集,有效地降低了聚類算法在聚類簇擴展中對內存的壓力,提高了聚類效率。 綜上所述,式(2)給出的聚類簇擴展條件,避免了候選噪聲數據對象參與到聚類簇擴展過程之中,有效地克服了RNNDBSCAN算法無法區分不同密度的相鄰聚類簇問題,提高了密度聚類分析精度和效率。 根據3.1節,利用逆近鄰和影響空間的思想,給出一種新穎的密度聚類算法KRDBSCAN。其聚類分析的基本步驟為:首先,為全部數據對象添加未聚類標簽,并計算數據對象的K近鄰NNK和逆近鄰RNN;其次,從數據集中隨機選擇一個數據對象x∈D,如果數據對象x的逆近鄰|RNN(x)| 算法1KRDBSCAN(KNN-RNN-DBSCAN) 輸入:數據集D,近鄰個數K。 輸出:聚類簇CLUSTERS。 1.?x∈D:x=UNCLASSIFIED; //添加未聚類標簽 2.cluster=1; //初始化簇標簽 3.NNK(?x∈D),RNN(?x∈D) //計算K近鄰與逆近鄰 4.FOR(?x∈D) DO //隨機選取數據對象x 5.IFx=UNCLASSIFIEDTHEN 6.IF EXPANSION(x,K,NNK(x),RNN(x),cluster) THEN 7.cluster=cluster+1; //聚類簇擴展過程 8.END IF 9.END IF 10.END FOR 11.PROCESSING-NOISE(x,K,NNK(x)); //噪聲處理 12.returnCLUSTERS; //輸出聚類簇 13.END KRDBSCAN 算法2EXPANSION(x,K,NNK(x),RNN(x),cluster) 輸入:任意數據對象x∈D,近鄰數K,簇標簽cluster,K近鄰集NNK(x),逆近鄰集RNN(x)。 輸出:TRUE/FALSE 1.IsK(x∈D)=NNK(x∈D)∩RNN(x∈D); //計算數據對象x的影響空間 2.IFRNN(x∈D) 3.x=NOISE; //噪聲對象(有可能是邊界對象) 4.return FALSE; 5.ELSE 6.queue=NULL; //初始化隊列 7.IFIsK(x)=NULL THEN 8.x=NOISE; //候選噪聲對象 9.returnFALSE; 10.ELSE 11.queue.enqueue(IsK(x)); //將影響空間進隊 12.assign[x+queue]=cluster; //添加簇標簽 13.WHILEqueue≠? DO //廣度優先遍歷過程 14.y=queue.dequeue(); 15.IFRNN(y∈D)≥KTHEN 16.FOR(z∈IsK(y)) DO 17.IFz=UNCLASSIFIED THEN 18.queue.enqueue(z); 19.z=cluster; 20.ELSE IFz=NOISE;THENz=cluster; 21.END IF 22.END FOR 23.END IF 24.END WHILE 25.return TRUE; //聚類簇擴展完成 26.END IF 27.END EXPANSION 在KRDBSCAN中,其算法的時間復雜度主要依賴于K近鄰和逆近鄰的求解。在算法1中,計算數據集中每個數據對象的K近鄰,其時間復雜度是O(k×n2);其次,計算數據集中每個數據對象的逆近鄰,其時間復雜度是O(n2);在算法2中,隨機選擇一個數據對象,采用影響空間進行聚類簇擴展,其時間復雜度是O(n2);在算法3中,利用K近鄰進行噪聲處理,其時間復雜度是O(n)。因此,KRDBSCAN算法的時間復雜度是O(k×n2+n2+n2+n)≈O(k×n2)。 實驗環境:Inter Core i5-7300HQ 2.50 GHz,16 GB內存,Windows 10操作系統,開發平臺為Eclipse和Rstudio。使用Java語言和R語言實現了KRDBSCAN算法。實驗數據采用UCI真實數據集和人工數據集。 為了驗證KRDBSCAN算法聚類精度和聚類效率,實驗采用Wireless、Act-Rec、Image、optdigits、avila和letter UCI真實數據集。UCI數據集如表1所示。 表1 UCI數據集 為了驗證KRDBSCAN算法抗噪性,實驗采用了Ari1、Ari2和Ari3人工數據集。Ari1是維度30、數據量為20 000條的高維數據集,其分為3個聚類簇,每個簇的方差為1.0、10.0和4.0。Ari2是維度50、數據量為50 000條的高維數據集,其分為4個聚類簇,每個簇的方差為1.0、5.0、6.0和10.0。Ari3是維度為40、數據量為30 000條的高維數據集,其分為5個聚類簇,每個聚類簇的方差為1.0、3.0、8.0、14.0和17.0。人工數據集如表2所示。 表2 人工數據集 為了驗證KRDBSCAN算法的聚類精度與聚類效率,實驗采用了標準化互信息(NMI)、調整蘭德指數(ARI)和V-Measure度量指標。NMI是衡量聚類結果與真實簇標簽間一致性的重要指標,能客觀地評價出聚類結果與真實標簽相比的準確度。ARI是衡量聚類結果和真實簇標簽之間相似性的函數,忽略了聚類結果的排列順序。V-measure是同質性和完整性之間的調和平均值。簇的同質性是指聚類結果中的數據對象都來自真實簇標簽中單個聚類簇的數據對象的指數。簇的完整性是指能夠將真實簇標簽中屬于相同聚類簇的數據對象聚為相同簇的指數。 為了實驗驗證本文算法KRDBSCAN在聚類精度、聚類效率和抗噪性的優越性,采用了當前具有代表性的密度聚類方法RNNDBSCAN[8]、ISDBSCAN[18]和RECORD[15]作為本文的對比算法。 在采用相同參數的情況下,標準化互信息的比較實驗結果如圖1所示,在UCI數據集中,KRDBSCAN算法的標準化互信息要高于其他密度聚類算法。KRDBSCAN算法在擴展聚類簇過程中使用了核心對象的影響空間,因為核心對象與其影響空間中的其他數據對象具有相互直接密度可達性,并且影響空間中數據對象是密度連接的,所以確保了核心對象與其影響空間中的其他數據對象屬于相同密度的聚類簇,能夠更好地估計鄰域密度分布,顯著提高了聚類結果的精度和質量。其中KRDBSCAN算法明顯優于RECORD算法。其原因可能是RECORD算法引入了第二個預定參數,增加了人為因素對于聚類結果的影響,并對噪聲對象的判斷過于嚴格。在采用相同參數的情況下,調整蘭德指數的比較實驗結果如圖2所示,在低維數據集Wireless和高維數據集optdigits中,KRDBSCAN算法的調整蘭德指數要遠遠優于RNNDBSCAN、ISDBSCAN和RECORD算法,說明KRDBSCAN算法同時適用于高維數據和低維數據。其原因是在聚類簇擴展過程中引入了影響空間,而不是只考慮了K近鄰,有效避免了在高維數據中易發生的“維數災難”問題。在采用相同參數的情況下,V-Measure的比較實驗結果如圖3所示。在UCI數據集中,KRDBSCAN算法的V-Measure要遠遠優于ISDBSCAN和RECORD算法,并略高于RNNDBSCAN算法。其原因是KRDBSCAN與RNNDBSCAN算法使用數據對象的逆近鄰識別核心對象。逆近鄰是基于全局的角度來檢查它的鄰域,數據分布的改變會使每個數據對象的逆近鄰發生改變。其可以更好地反映數據的分布特征。KRDBSCAN與RNNDBSCAN算法都采用一個預設參數,減少了人為因素對聚類結果的影響。 圖1 標準化互信息 圖2 調整蘭德指數 圖3 V-Measure 為了驗證KRDBSCAN算法的聚類效率,實驗在UCI數據集上將KRDBSCAN算法與RNNDBSCAN、ISDBSCAN和RECORD算法進行運行時間的比較。為了保證評估的準確性,實驗采用5次運行時間取均值的方法進行聚類效率的比較,其實驗結果如表3所示。KRDBSCAN算法的聚類效率略高于RNNDBSCAN和RECORD算法,并且其聚類效率遠遠高于ISDBSCAN算法。KRDBSCAN算法雖然需要計算影響空間,但其在聚類簇擴展過程中因減少了入隊的數據對象而大大縮短了運行時間。而RNNDBSCAN算法在聚類簇擴展過程中需將數據對象的K近鄰與逆近鄰的并集入隊,增加了算法的運行時間。總體上,KRDBSCAN算法的運行效率要優于RNNDBSCAN、ISDBSCAN和RECORD算法。 表3 聚類效率比較 單位:s 為了驗證KRDBSCAN算法的抗噪性,實驗中采用EXCEL工具中的數據生成器,生成噪聲對象集,并在Ari1、Ari2和Ari3人工數據集上添加5%、10%和15%的噪聲對象,實驗比較標準化互信息、調整蘭德指數和V-measure的變化情況。由圖4、圖5和圖6可知,隨著人工數據集中噪聲對象數比例的增大,標準化互信息、調整蘭德指數和V-measure都呈現降低的趨勢。其原因是隨著噪聲對象的增多,KRDBSCAN算法將一部分噪聲對象當作邊界對象聚到聚類簇中,造成了評估指標的降低。但KRDBSCAN算法在數據集中每增加5%的噪聲對象,評估指標降低約0.02到0.05之間,噪聲對象對聚類結果影響并不大,KRDBSCAN算法在有噪聲的數據集下依然具有很高的聚類質量,說明KRDBSCAN算法具有良好的抗噪性。 圖4 Ari1抗噪性 圖5 Ari2抗噪性 圖6 Ari3抗噪性 針對密度聚類算法RNNDBSCAN中存在的無法識別不同密度的相鄰聚類簇問題,本文給出一種新的基于逆近鄰和影響空間的密度聚類算法KRDBSCAN,與傳統的基于密度的算法相比,KRDBSCAN算法在三個方面都優于當前流行的密度聚類算法。首先,數據對象的逆近鄰是基于全局的角度來檢查它的鄰域,數據分布的改變會導致每個數據對象的逆近鄰發生改變,該算法采用逆近鄰能真實地反映數據集中數據的分布特征。其次,KRDBSCAN算法采用逆近鄰與影響空間相結合的思想,重新描述了聚類簇擴展的條件(|RNN(x)|>K∩Isk(x)≠NULL),并在其擴展過程中,采用了影響空間中的數據對象,實現聚類簇的迭代擴展;由于影響空間中數據對象的直接密度可達性是對稱的,保證了數據對象與其影響空間中的數據對象,同屬于相同密度的聚類簇,因而可有效地區分不同密度的相鄰聚類簇,使KRDBSCAN算法對局部密度變化高度敏感,能夠更好地估計鄰域密度分布,提高了聚類精度。最后,KRDBSCAN算法可以隨機選擇數據對象進行聚類,聚類結果與選取數據對象的順序無關。實驗結果表明,KRDBSCAN算法具有良好的聚類精度、聚類效率與抗噪性,并能很好地適用于高維數據集的聚類問題。下一步的研究工作是使用Spark平臺并行化KRDBSCAN算法,使其適用于大數據分析。2.2 密度聚類
2.3 影響空間
3 基于逆近鄰和影響空間的密度聚類
3.1 影響空間與聚類簇擴展
3.2 KRDBSCAN聚類分析算法
3.3 KRDBSCAN算法效率分析
4 實驗與結果分析
4.1 聚類精度
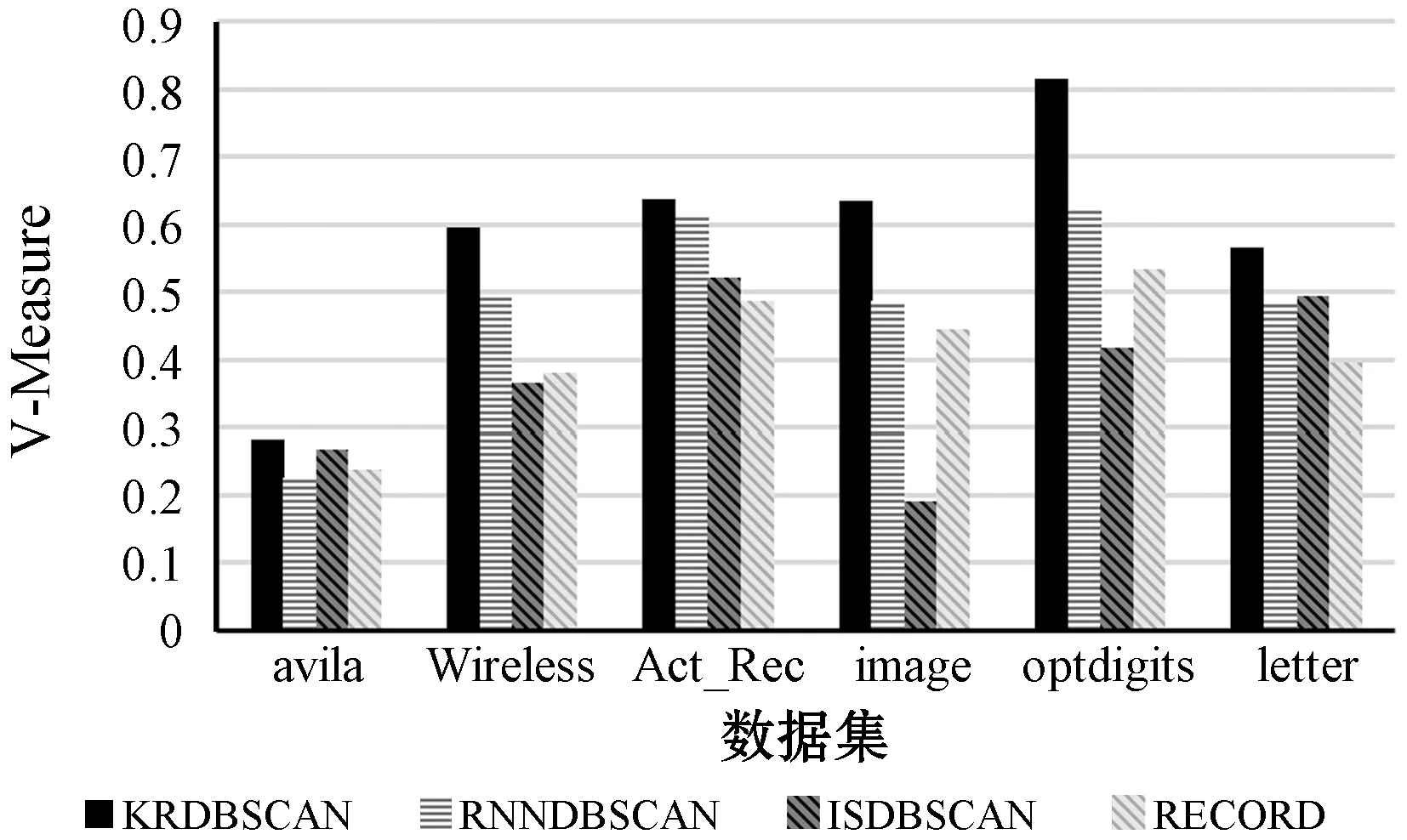
4.2 聚類分析效率
4.3 抗噪性
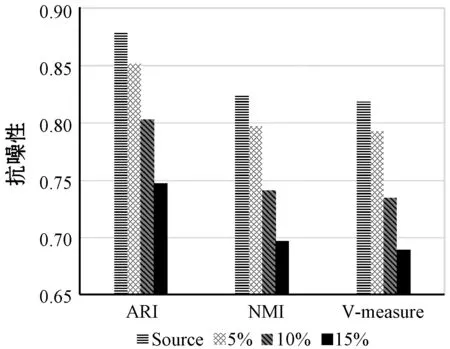
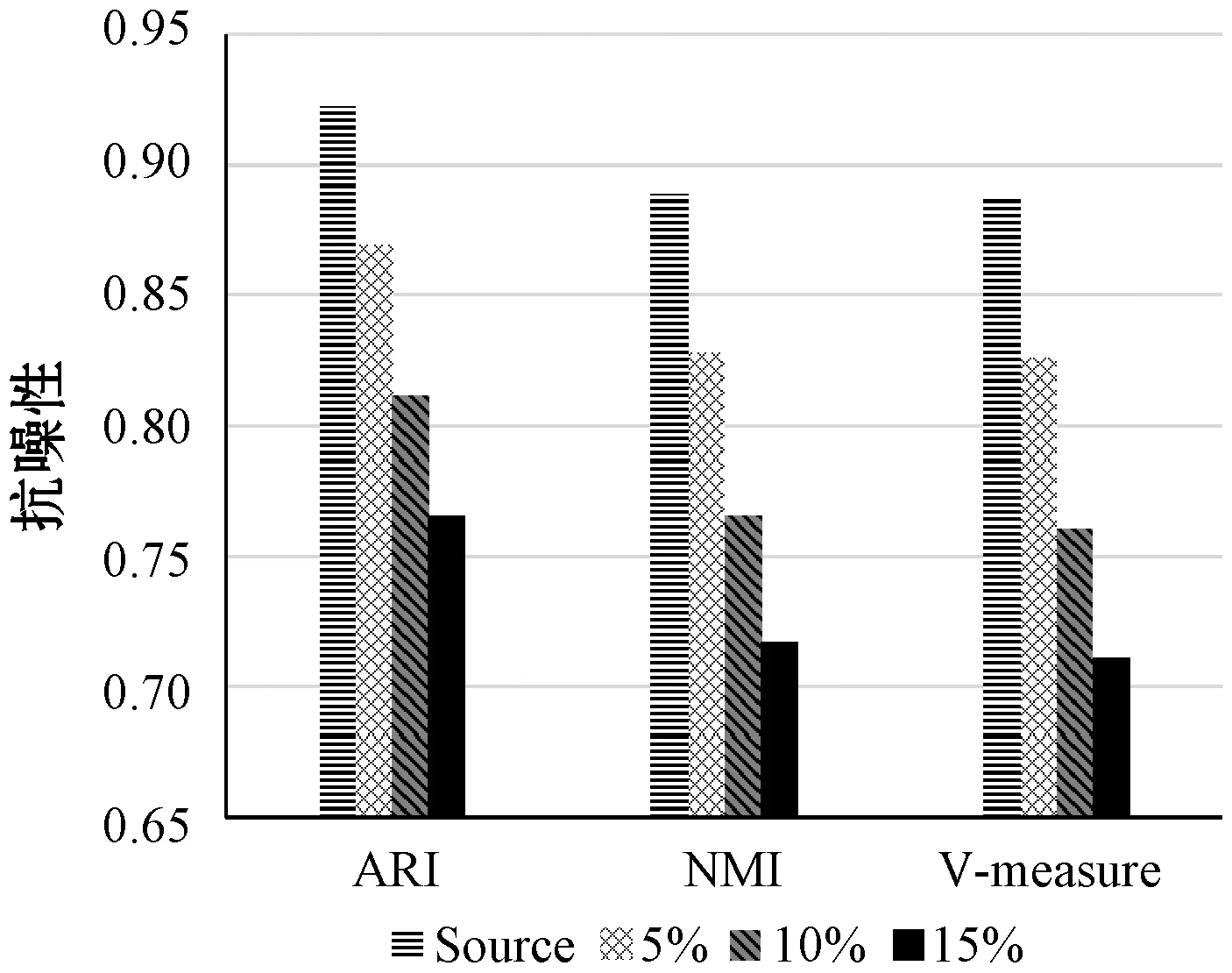
5 結 語
猜你喜歡
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08當代陜西(2021年2期)2021-03-29 07:41:24海峽姐妹(2020年9期)2021-01-04 01:35:44VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26媽媽寶寶(2017年3期)2017-02-21 01:22:28中國塑料(2016年3期)2016-06-15 20:30:00通信電源技術(2016年3期)2016-03-26 07:13:38山東青年(2016年1期)2016-02-28 14:25:25當代修辭學(2014年3期)2014-01-21 02:30:44公務員文萃(2013年5期)2013-03-11 16:08:37
