基于C5.0決策樹算法的電力營銷數據挖掘
2022-02-21 10:42:20卜曉陽蔡巖王宗偉趙郭燚
微型電腦應用 2022年1期
卜曉陽, 蔡巖, 王宗偉*, 趙郭燚
(1.國家電網公司,客戶服務中心,天津 300309;2.河北師范大學,軟件學院,河北,石家莊 050024)
0 引言
隨著我國信息產業的爆發式發展,各行業的企業都開始使用信息集成系統進行管理。如何對所產生的海量數據進行有效利用成為新時代人們最關注的問題之一[1]。電力企業作為直接影響社會民生的重要部門,在使用管理信息系統的過程中產生了大量的運行狀況和銷售數據[2],電力企業管理人員迫切需要合理的方式去處理這些海量數據,以便獲得有價值的信息[3]。
數據挖掘技術作為計算機領域的熱門方向,一直和社會實際應用緊密結合。使用合理的數據挖掘技術可以解決電力企業的數據分析問題,為管理人員提供有價值的決策支撐信息,從而提高電網運行的可靠性[4]。例如,劉建飛等[5]提出了一種基于電力側大數據挖掘的營銷效果評價方法,其中使用了C4.5決策樹算法。Victor D等[6]利用BP神經網絡對電力企業營銷數據進行快速挖掘。黃文思等提出了一種基于決策樹算法的電力客戶欠費風險預測。但是,上述方法采用的決策樹算法仍舊是ID3算法以及在其基礎上發展起來的 C4.5方法。而C5.0決策樹算法作為其后續的最新版本,綜合性能有了明顯提升。
因此,為了對電力企業提供更加準確、有效的營銷數據決策支撐,本文提出利用C5.0決策樹算法對電力營銷管理系統的營銷數據進行深層次分析。通過引入信息熵對原有的C5.0決策樹算法進行了改進,提高了其分類速度和精度。在UCI機器學習數據集和電力營銷數據集上的實驗結果表明,提出的改進C5.0決策樹算法具有良好的分類性能,能夠滿足電力營銷工作中的分類預測需求。
1 C5.0 決策樹算法原理
作為從ID3 決策樹算法發展出來的后續算法,Ross Quinlan提出了C4.5算法能夠將屬性視為連續型的[7],并提出了2個新的屬性:分離信息(Split Information)和信息增益率(Information gain ratio),可用于生成多分支決策樹。C5.0算法與C4.5算法的核心是一樣的,但是在內存管理等方面做出不少改進,更加適合商業應用。
1.1 分裂屬性的確定
本文假設S表示一個訓練樣本集,其樣本數量為s個,包括m個不同的種類xi(i=1,2,…,m)。D表示訓練樣本集S的一個屬性且取值范圍為[1,k]。vi表示屬于不同種類xi的樣本總數。
根據屬性D的不同,能夠將訓練樣本集S區分成k個小的子集。si為上述子集中的第i個子集,i=1,2,…,k,[Si]表示子集si中的樣本個數。
首先,信息增益Gain(S,D)的計算式[8]如式(1)。
Gain(S,D)=I(s1,s2,…,sk)-E(S,D)
(1)
其中,E(S,D)表示根據屬性D劃分出的k個子集的熵加權和,I(s1,s2,…,sk)則表示訓練樣本集S的熵。
I(s1,s2,…,sk)的計算式如式(2)。
(2)
其中,p(xi)表示種類xi出現的概率,滿足約束條件如式(3),
(3)
其次,分裂信息項Split_Info(S,D)的計算式[9-11]如下:
(4)
通過式(4)可以看出,分裂信息項Split_Info(S,D)其實就是訓練樣本集S關于屬性D的熵,該值越小則樣本分布在屬性D上的結果越不均勻。
因此,信息的增益比率GainRatio(S,D)的計算式是
(5)
1.2 分裂屬性的確定
在分裂屬性的選取過程中,C5.0決策樹算法會挑選出具有最高增益比率的屬性,并將其定義成分裂屬性[12]。
在確定分裂屬性后,C5.0決策樹算法會執行最佳分割點的確定步驟,組成了決策樹的k個分枝。當最佳分裂屬性是連續型變量時,會利用分箱策略設置劃分值,從而對大于該劃分值的樣本進行再劃分[13]。在循環執行分裂屬性的確定和最佳分割點的確定后,生成了一棵完整的決策樹。
2 改進的C5.0 決策樹算法
通過上節C5.0 決策樹算法原理分析,可以看出該決策樹算法需要根據每一個屬性在所有結點上,對信息的增益比率GainRatio(S,D)進行計算,以便為后續分裂屬性的確定做支持。但是式(4)中信息增益比率GainRatio(S,D)計算需要對數運算,因此計算時間較長且精度不夠理想[14]。因此,本文通過引入信息熵對原有的屬性選擇方式進行改進。
假設正例屬性的個數為p,且反例屬性的個數為n,則信息量的計算方式如式(6),
(6)
信息熵可以推導為式(7),
(7)
其中,
(8)
將式(8)代入式(7)得出式(9),
(9)
由于(n+p)ln2為常量,因此在重復循環過程中,可以使用式(10)進行結點屬性選取,
(10)
又因為pi/(ni+pi)和ni/(ni+pi)均小于1,因此
(11)
(12)
所以,最終的Split_Info′(S,D)可以使用式(13)計算得到,
(13)
從式(13)可以看出,計算過程僅包含簡單的加減和乘除運算,大大縮減了計算時間。
3 改進C5.0決策樹在電力營銷中的應用
3.1 數據模型設計
在將改進的C5.0決策樹應用于電廠管理信息系統中時,需要以售電量為中心,構建各部門數據庫表格之間的映射關系,本文構建的數據模型如圖1所示。
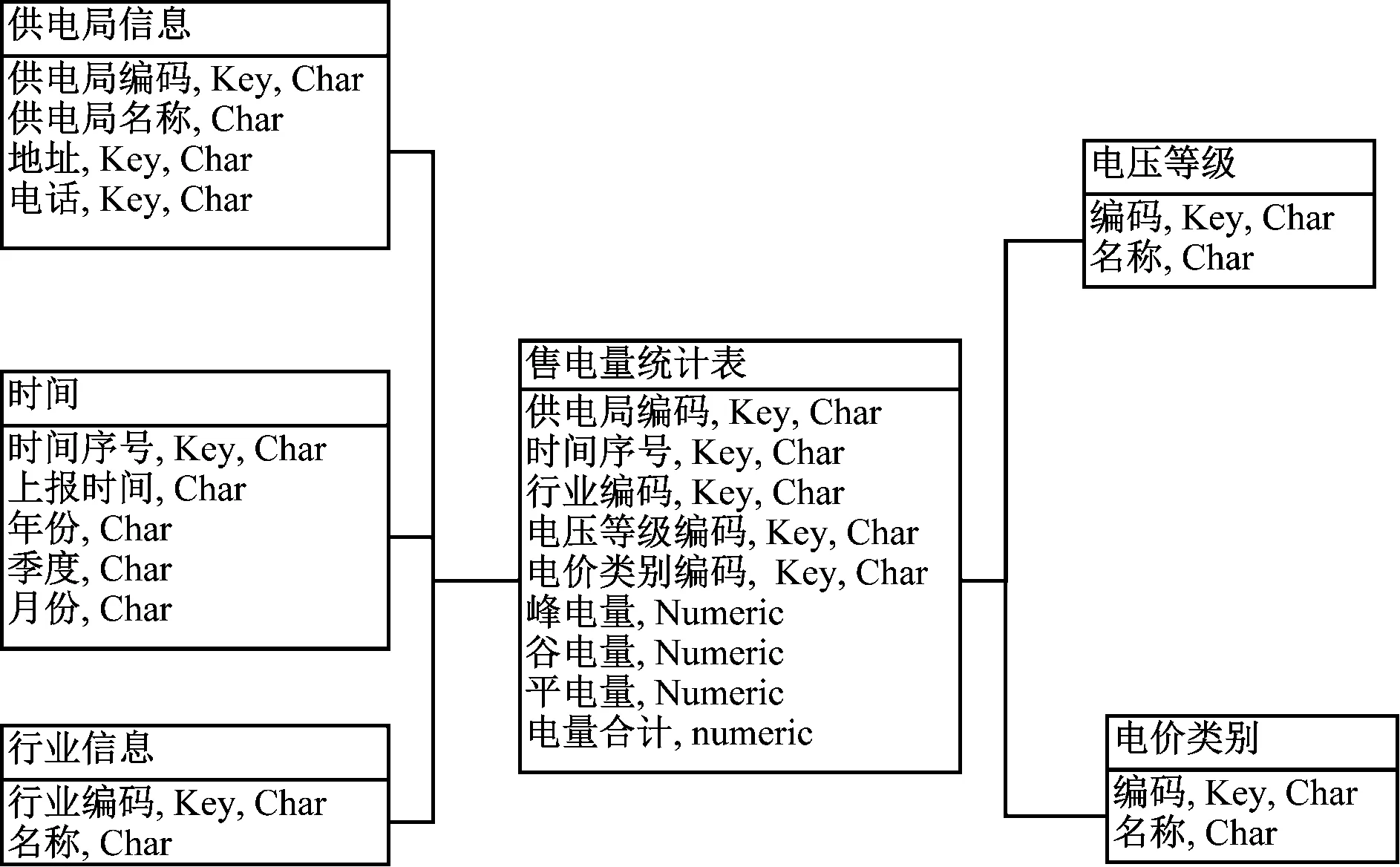
圖1 售電量關系模型
3.2 數據挖掘流程
改進C5.0決策樹在電力營銷中的數據挖掘流程如圖2所示。
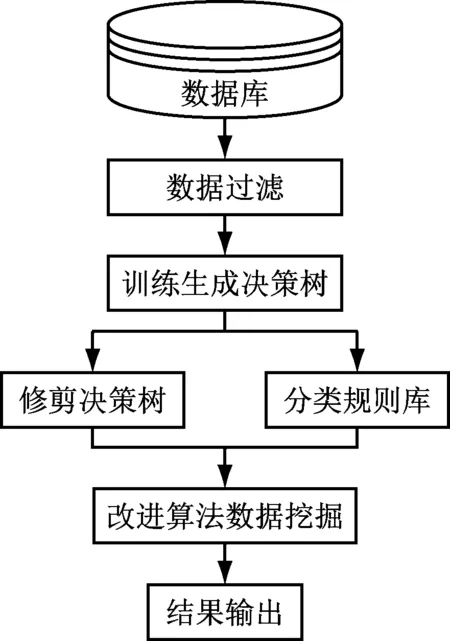
圖2 改進C5.0決策樹算法的挖掘流程
4 實驗結果與分析
4.1 實驗環境
為了對本文提出的視頻分類方法進行分析和驗證,進行具體實驗。實驗硬件環境:處理器為Intel Core i7 2.2 GHz,圖形圖像處理設備為GTX970@2G顯存,內存為8 G。實驗軟件環境:Windows 7操作系統、MATLAB 7.0仿真軟件。
4.2 改進算法性能驗證
為了驗證所提改進的C5.0決策樹算法的性能,用UCI機器學習數據集[15]進行了分類測試驗證。選擇20組小數據集,共2 400個樣本進行了測試。訓練樣本為隨機選取的1 000個樣本,其余為測試樣本。每組實驗重復10次并去平均值作為最終結果。標準C5.0決策樹算法和改進后C5.0決策樹算法的分類準確率對比和時間對比分別如圖3、圖4所示。

圖3 2種算法的分類準確率對比
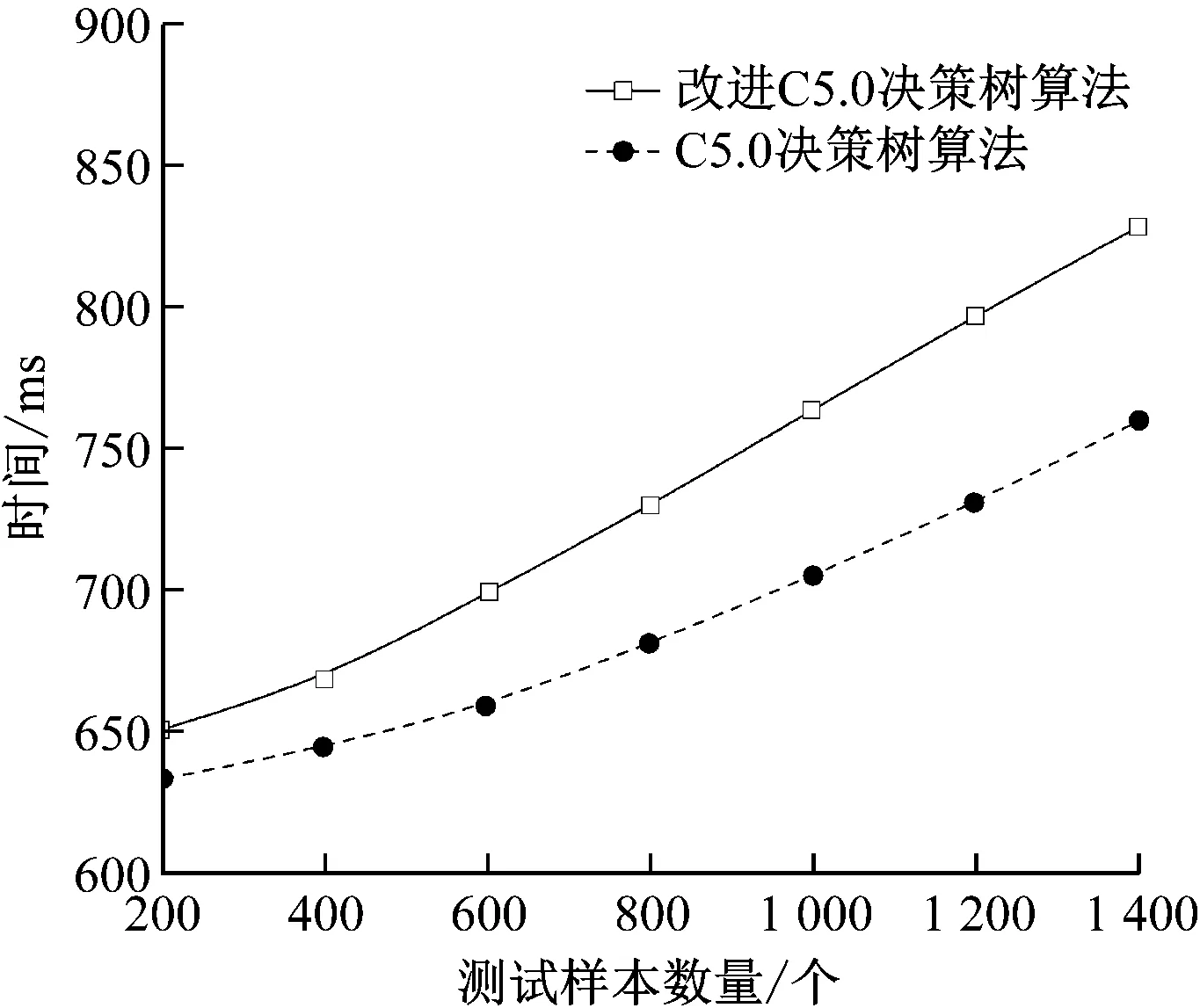
圖4 2種算法的分類時間對比
從圖3可以看出,隨著測試樣本數量的不斷增多,2種算法分類的準確率幾乎一致。從圖4可以看出,隨著測試樣本數量的不斷增多,2種算法分類的時間均有所增加,但是改進后C5.0決策樹算法所需的時間明顯更少,分類效率更高。
4.3 電力營銷應用結果
以某電力企業的2019年期間營銷數據為測試數據集,對改進后C5.0決策樹算法進行實際案例分析。該電力營銷測試數據集共包括100名不同地區、不同年齡和不同崗位的用戶用電樣本數據。隨機選取其中50個樣本作為訓練樣本,如表1所示。
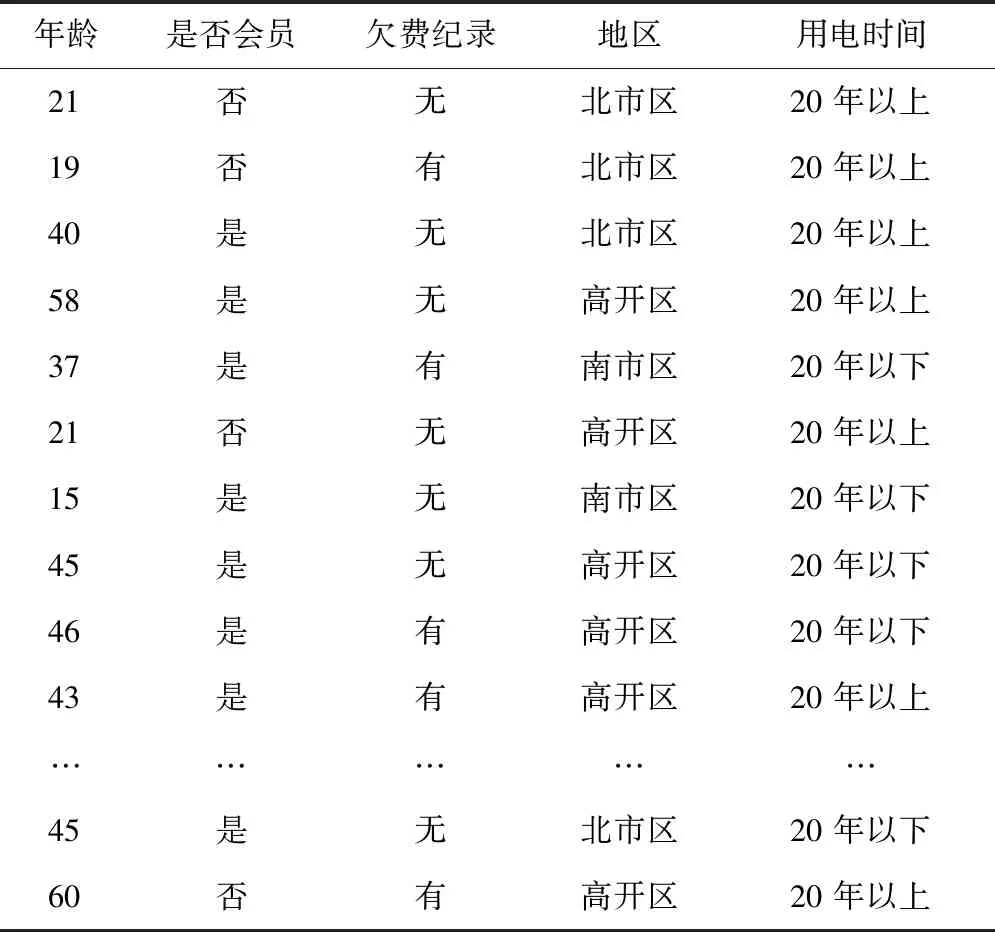
表1 訓練樣本集
利用改進的C5.0決策樹算法,選擇具有最大信息增益屬性值作為葉節點,循環上述決策樹執行步驟,最終產生客戶分類決策樹及其分類規則,然后在電力營銷數據集的測試樣本中對得到的分類決策樹模型進行驗證。此外,為了對比分析,還使用了BP神經網絡和ID3.0決策樹分別建立分類模型。各種分類模型結果比較如表2所示。
從表2可以看出,相比于BP神經網絡、ID3.0決策樹,C5.0決策樹和改進的C5.0決策樹算法在分類準確率方面提升較為明顯,C5.0決策樹最優(87.6%),改進C5.0決策樹算法次之(86.5%)。而在分類效率方面,改進C5.0決策樹算法表現較為突出,僅需1.86 s。綜合來看,改進C5.0決策樹算法在客戶及時準確分類應用中具有最佳的綜合分類性能,可以有效滿足實際的電力營銷工作需要。
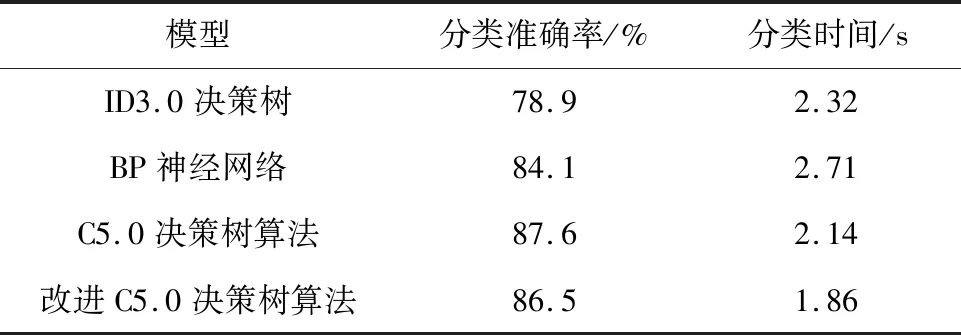
表2 各種分類模型結果比較
5 總結
本文提出了一種基于改進C5.0決策樹算法的電力營銷數據挖掘技術。通過引入信息熵對原有的屬性選擇方式進行改進,提高了信息增益比率計算的速度。此外,根據設計的售電量關系模型進行對電廠管理信息系統中的數據進行挖掘。數據集和實際案例應用結果均驗證了提出改進算法的有效性和可行性。但是電力營銷訓練和測試樣本集中用戶屬性的數量(維度)較少,后續將考慮增加更多的屬性,來進一步驗證C5.0決策樹算法的性能。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
