面向端到端的情感對話生成研究綜述
2022-02-23 10:02:48王春喻馬志強杜寶祥賈文超王洪彬寶財吉拉呼
計算機與生活 2022年2期
王春喻,馬志強,2+,杜寶祥,賈文超,王洪彬,寶財吉拉呼
1.內蒙古工業大學 數據科學與應用學院,呼和浩特010080
2.內蒙古工業大學 內蒙古自治區基于大數據的軟件服務工程技術研究中心,呼和浩特010080
人機對話系統的研究最早追溯到1950 年圖靈提出的“圖靈測試”,采用人機交互的方式驗證機器智能。此后,人機對話研究引起了學術界與工業界的高度關注。對話系統的研究主要面向任務型對話和非任務型對話。早期任務型人機對話是基于模板與規則構建的,隨著深度學習的發展,越來越多的研究者將深度學習技術應用于對話系統的研究中。當前任務型對話系統的構建主要使用基于流水線的方法和基于端到端的方法。基于流水線的方法構建靈活,而基于端到端的方法能夠學習數據的特征,且避免了人為因素的影響。任務型對話的主要應用場景為虛擬個人助理、網站客服,并且有著明確的目標,目的是通過較少的對話輪數幫助用戶完成預定任務。非任務型對話系統則面向開放領域,主要通過基于檢索的方法和生成式的方法構建,主要應用場景為閑聊機器人、智能客服以及個性化推薦等,回復內容具有主題一致性、語言多樣性以及個性化的特點。在開放域對話系統的研究中,基于檢索的方法回復語句流暢且易于評價,而基于生成式的方法能夠更多地考慮上下文的影響,且回復內容多樣,能夠更好地模擬人類的正常交流。近年來,隨著大規模語料庫的出現,計算機計算能力的提升,開放域下的對話生成研究成為了學術界研究的熱點。面向開放域對話的各種語音助手、閑聊機器人以及智能音響逐漸走入大眾的生活中,成為人們工作和生活娛樂的一部分。
然而人類在交換信息的過程中,不僅包含語法和句法信息,還包含著情感信息與情感狀態。人工智能的長期目標是使機器能夠理解情緒和情感,現有的研究表明,在對話系統中加入情感信息會提高用戶的滿意度,并且情感信息有助于機器和人之間的交流更加自然。因此,如何處理用戶的情感信息,并且設計能夠與用戶進行正常情感交互的對話系統非常重要。情感對話生成最初的研究是基于模板與規則的方法構建的,其中情感語句使用基于模式的方式生成,但是這種方法構造難度大且不易拓展,難以進行廣泛的應用。受到神經模型在機器翻譯等領域成功應用的啟發,基于端到端的神經網絡模型被廣泛應用于生成式對話研究中,旨在提高語句的語言質量,包括句法、多樣性以及主題關聯性等。為了使生成式對話模型具備感知和表達情感的能力,許多研究者將各種端到端的神經模型作為情感對話生成模型的基礎,并通過情感分析、情感嵌入等技術對模型進行改進,實現了在對話生成中情感的表達。
由于基于端到端的情感對話生成研究時間較短,現有的綜述未能針對最新的研究進行及時而全面的總結。李赟等人簡要概述了情感對話生成的目標,從情感向量以及深度學習技術兩方面梳理了情感對話生成研究中的解決方案。Pamungkas對企業化建立情感聊天機器人的方法進行了回顧,但是沒有針對現有情感對話生成研究涉及的問題進行描述。Ma 等人重點關注移情對話系統的研究,將情感意識作為移情對話系統的一部分,情感對話生成的研究未能詳細介紹。莊寅等人面向情感對話系統中的對話情緒感知和情感對話生成兩個任務開展綜述,但是并未對當前情感對話生成研究涉及的模型及其改進方面開展敘述。本文將基于端到端的情感對話生成作為研究對象,歸納并詳細描述了基于端到端的情感對話生成研究涉及的關鍵問題以及當前研究的主要任務,同時重點闡述了端到端的基本模型及每種模型的研究應用,最后聚焦于情感對話生成未來的發展方向,并且給出了詳細的未來研究思路。
1 情感對話生成任務描述

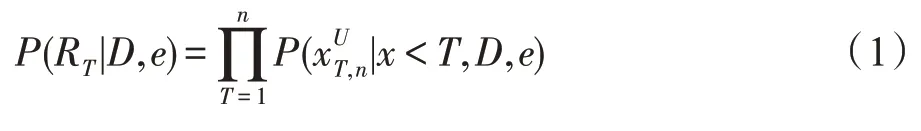
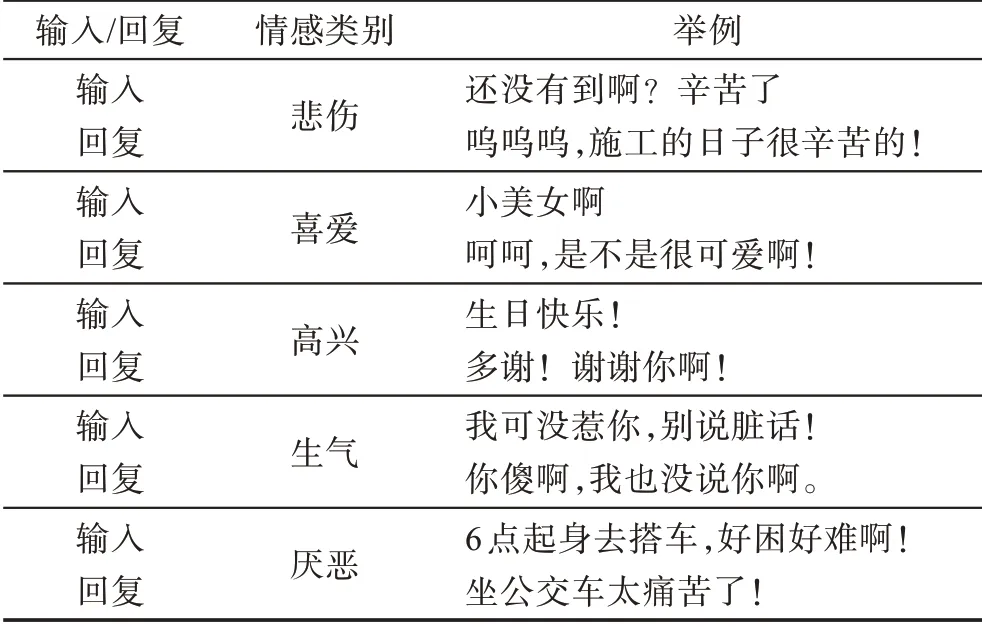
表1 情感對話生成示例Table 1 Example of emotional dialogue generation
1.1 問題定義
根據對情感對話生成任務以及情感對話生成現狀的研究,當前情感對話生成的問題主要集中于對話生成中情感的回復問題,而該問題則包括三方面:對話中的情感一致性問題、回復生成情感恰當性問題以及情感通用性回復問題。
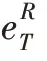
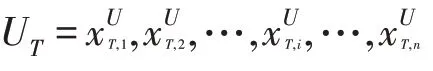

當前情感對話生成研究面臨的問題貫穿于情感對話生成的研究進展中。從生成指定情感類別的情感語句,到生成符合人類交流恰當的情感語句,再到生成多樣性以及情感豐富的情感語句,這項研究將會沿著擬人化表達的方向不斷發展。
1.2 任務框架
根據對現有研究的整理,情感對話生成任務框架如圖1 所示,情感對話生成主要完成以下任務:情感嵌入編碼任務、回復情感控制任務以及情感回復解碼任務。以此解決情感對話生成中的問題:對話中的情感一致性問題、回復生成情感恰當性問題以及情感通用性回復等問題。而實現的方式則包括:(1)情感對話數據集的收集。以數據驅動為主的情感對話生成模型對大規模、高質量的情感對話數據集有很高的要求。(2)情感對話生成模型的構建。面向不同的任務,研究者采取不同的基礎模型,針對存在的問題進行模型的構建。(3)情感對話生成模型的評價。選取合適的評價指標對構建的模型生成質量進行評價,可以檢驗模型是否成功。
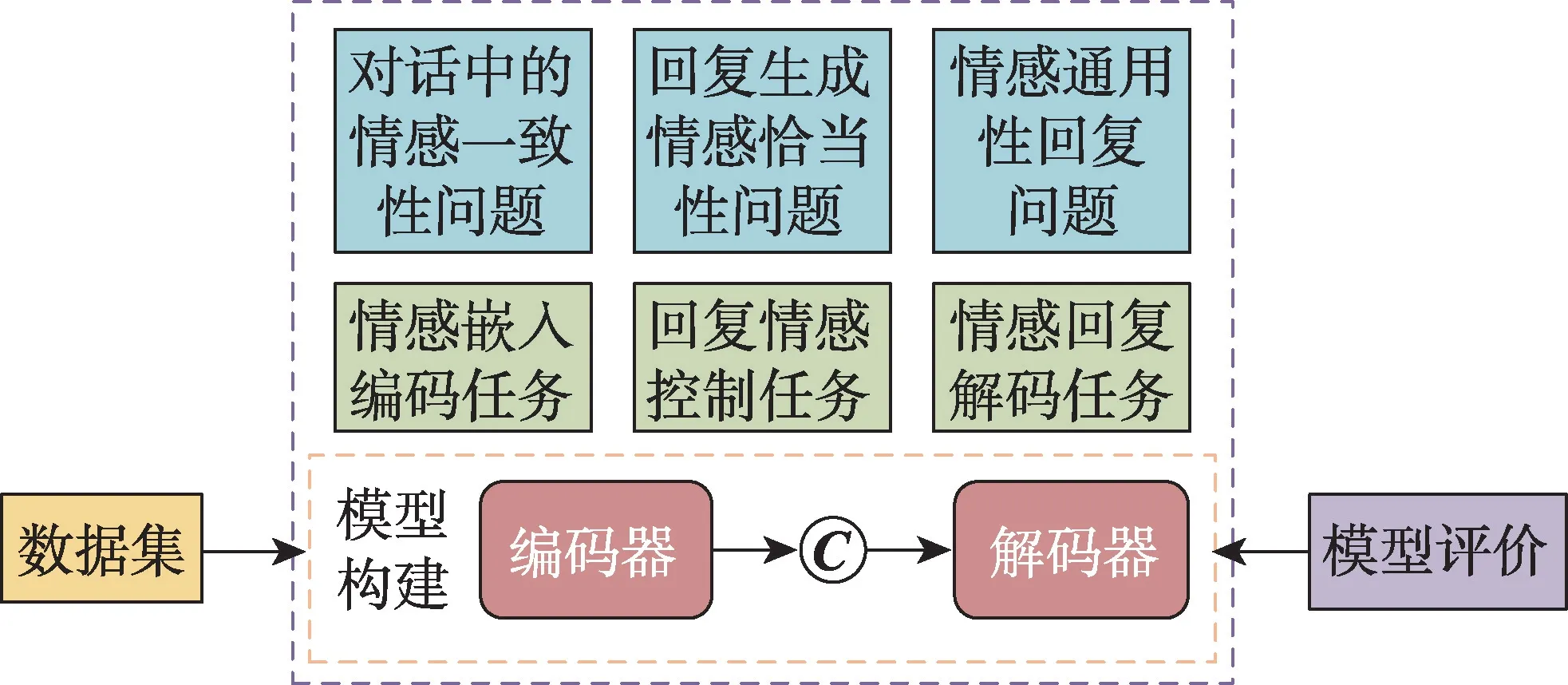
圖1 基于端到端的情感對話生成任務框架Fig.1 Task framework based on end-to-end emotional dialogue generation
2 數據集
早期的對話系統基于手工制定規則的方式構建,因此不需要數據集訓練。而當前情感對話生成模型以數據驅動的方式訓練得到,因此大規模且高質量的情感對話數據集的收集與整理是構建情感對話生成系統的關鍵。
當前許多研究者收集并整理了大量的情感對話數據集,對這些開源的數據集進行預處理之后,可以在情感對話生成模型的訓練中使用。根據整理發現,當前情感對話數據集只有兩種語言,英語和漢語。表2 為具有代表性的情感對話數據集。

表2 情感對話數據集Table 2 Emotional dialogue dataset
根據對現有的情感對話數據集的分析,可以發現:(1)中文數據集來源于論壇評論,數據集質量不高,對于情感對話模型的訓練來說,每種情感類別的分布不均,會造成情感語句生成時的情感不可控。因此使用中文情感對話語料構建的模型在情感一致性、情感恰當性等方面存在的問題較多。(2)英文數據集來源廣泛,既有對論壇評論的收集,也有來自于電影臺詞的整理,更適合用作模型的訓練,使用英文數據集訓練的模型更多地為了提高情感生成內容方面的效果。
3 情感對話生成模型
受到統計機器翻譯的啟發,Ritter 等人提出一個短文本的回復生成概率模型,激發了研究者對于生成式概率模型的研究。Shang等人、Mou等人、Wu 等人、Li 等人在大規模數據上訓練的神經模型為對話生成的研究提供了基礎,之后各種神經模型被廣泛地應用于對話生成研究中。根據對現有基于端到端的情感對話生成模型的研究,本文將對主流的序列到序列模型(sequence to sequence,Seq2Seq)、層級編解碼器模型(hierarchical recurrent encoderdecoder,HRED)、變分自編碼器(variational autoencoder,VAE)和基于Transformer的對話生成模型以及與每種模型相關的情感對話生成模型的應用進行介紹。
3.1 基于Seq2Seq 的情感對話生成模型
序列到序列模型(Seq2Seq)是由Sutskever等人提出的一種神經網絡模型,最初的工作是在機器翻譯上進行的。之后Bengio 等人提出注意力機制,進一步提高了機器翻譯的效果。Cho 等人成功地將Seq2Seq 模型應用于對話生成中,成為了開放域對話生成研究的主流模型。Seq2Seq 模型包括三部分:編碼器、解碼器和中間向量。經典的Seq2Seq模型如圖2所示。
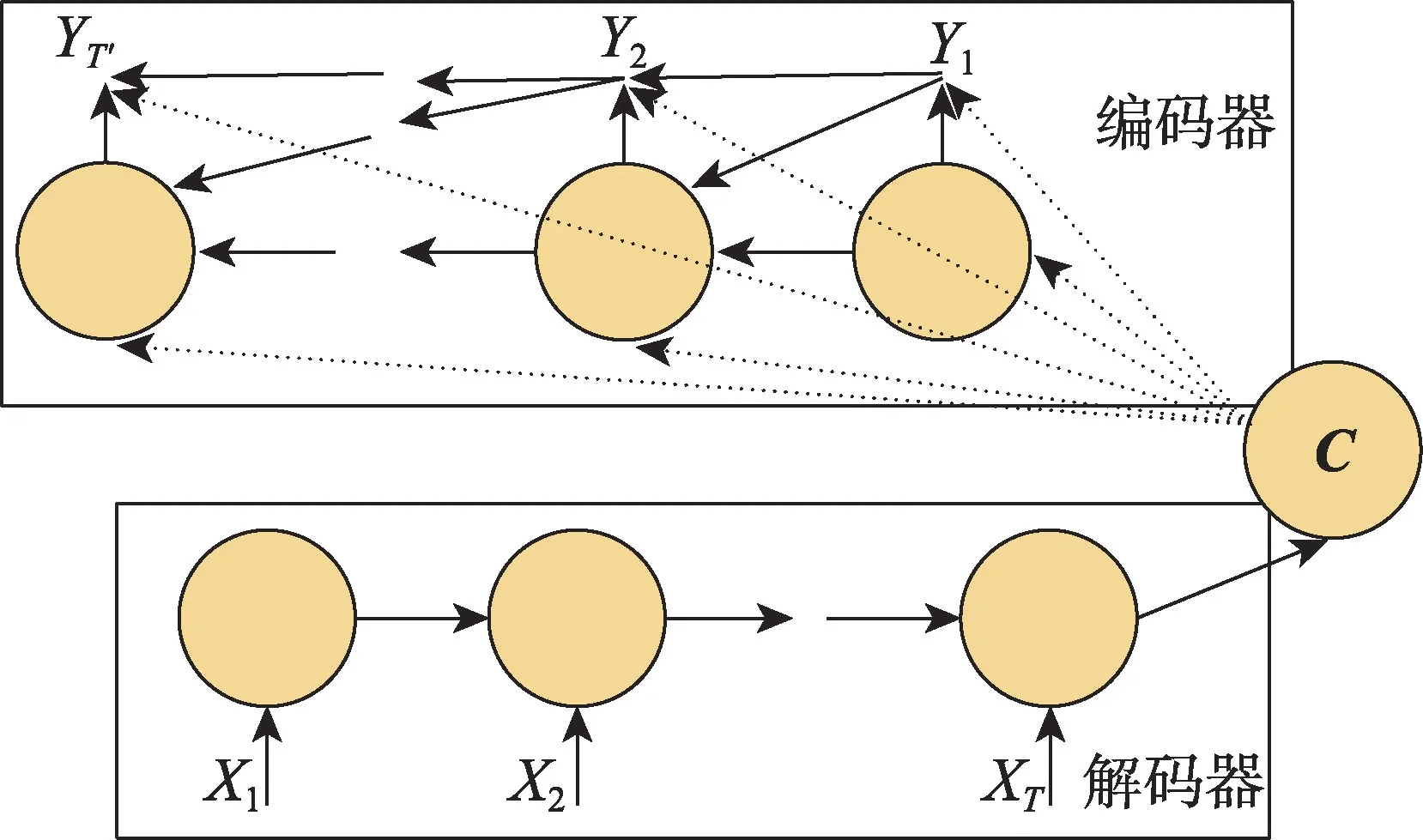
圖2 Seq2Seq 模型結構Fig.2 Structure of Seq2Seq model
編碼器與解碼器通常以循環神經網絡(recurrent neural network,RNN)、門控循環單元(gated recurrent unit,GRU)以及長短期記憶網絡(long shortterm memory,LSTM)為基礎。給定一個包含個詞的消息序列=,,…,x,…,x,目標是生成一個包含個詞的回復=,,…,y,…,y。模型不斷調整參數,得到最理想的輸出序列。編碼器能夠將當前輸入編碼成中間向量,其計算方式如式(2)所示。

其中,h是編碼器編碼形成的中間隱藏狀態,對每一時刻的隱藏狀態聯合起來進行變換可以形成中間向量,為了方便計算,將最后一個時刻的隱藏狀態看作中間語義向量。 x代表當前輸入。解碼器解碼過程剛好與編碼過程相反,在解碼階段,生成的輸出是利用編碼器生成的中間語義向量和上一時刻解碼器解碼的輸出共同生成當前輸出,計算概率分布,預測下一時刻輸出的詞:
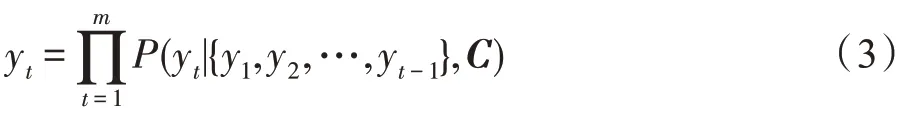
Seq2Seq 功能強大,易于擴展,在單輪對話生成方面取得了很好的效果,但是對于多輪對話中較多的對話記錄,模型回復生成的效果不佳。
鑒于Seq2Seq 模型在對話生成方面的良好表現,許多研究者選擇該模型作為情感對話生成模型的基礎。
研究者基于Seq2Seq 模型針對情感嵌入編碼任務開展了大量的研究:Zhou 等人首次提出了基于Seq2Seq 模型的情感聊天機(emotional chatting machine,ECM),ECM 使用情感類別嵌入模擬情感表達,實現情感向量的編碼,對解碼器進行改進,實現情感語句的生成。Shantala 等人在一個Seq2Seq 模型上調節回復情緒,以類似于單詞嵌入的方式訓練情緒嵌入。在回復生成階段,系統不僅可以生成內容恰當的語句,而且還可以生成期望的情感語調和話語。Huang 等人在學習的過程中將期望的情感與輸入連接起來,實現了情感的表達。Yuan 等人應用Seq2Seq 框架,以給定的消息和分配的情緒標簽生成情感回復。為了產生一致情緒的回復,使用情感嵌入指導情感化過程。Sun 等人應用一個Seq2Seq 框架,并且通過使用一系列轉換來改變模型的輸入解決對話生成的情感因素。Zhou 等人在Seq2Seq 的基礎上應用了一種注意力機制,捕捉上文的情緒并將其整合到回復生成中。Huang 等人對Seq2Seq 框架進行改進,能夠在傳達給定情感的同時自動生成回復。Wei 等人在Seq2Seq 框架的基礎上增加了一個情感偏置回復生成器,解決生成回復中忽視情感信息的問題,同時對消息中的語義和情緒進行編碼,產生更智能的回復,并恰當地表達情緒。Song 等人對Seq2Seq 框架以基于詞典的注意力機制進行擴展,確保特定的情感詞插入文本中,以顯式或隱式地表達期望的情感。Guo 等人提出了一種基于Seq2Seq 框架的動態情感對話生成模型,結合了基于詞典的注意力機制,提高了對話生成質量。Chen 等人對Seq2Seq 框架擴展,增加了情感感知生成器,從而提高了情感回復的恰當性。Zhou 等人在Seq2Seq 框架的基礎上,結合了基于詞典的注意力機制,該機制鼓勵用情感詞典中的同義詞來替換單詞。Ma 等人提出了一個情感和上下文敏感的對話生成Seq2Seq 模型。在模型中對話語的編碼增加了詞級和話語級的情感信息,增強了情感的模型表征能力,生成滿足語境的情感語句。
為了對回復中的情感進行控制生成,大量的研究者基于Seq2Seq 框架開展了回復情感控制任務研究:Colombo 等人基于Seq2Seq 框架使用連續的情感表征,能夠按照可控的方式生成有情感的回復。Ma 等人基于Seq2Seq 框架提出了一個由情感通道和詞級注意力組成的控制單元框架,獲得了更好的情感回復。Asghar 等人將情感控制理論(affect control theory,ACT)引入到Seq2Seq 框架中,產生了情緒一致的回復,并考慮了交互者的身份。Sun等人提出了一種基于Seq2Seq 框架的對話內容生成模型,使用強化學習的方法,生成了更有意義的情感回復。Li 等人將Seq2Seq 框架與生成式對抗網絡(generative adversarial networks,GAN)相結合,生成了更高質量的情感回復。
情感回復內容的好壞也是研究者的關注點,因此情感回復生成解碼任務成為了情感對話生成研究的熱點:Asghar 等人基于Seq2Seq 框架使用情感維度方法對情感建模,能夠將情感的多樣性融入到解碼器的生成回復中,解決了在對話生成中的情感內容回復問題。Zhong 等人基于Seq2Seq 框架使用情感維度方法標注嵌入詞,解碼生成的回復不僅符合語法和語義,還具有豐富的情感。Liu 等人提出了一個基于Seq2Seq 框架的情感自然語言回復模型,將對話的情感狀態編碼為分布式嵌入到回復生成過程中。Peng 等人提出了一個基于Seq2Seq 框架的話題增強情感對話生成模型,使用動態情感注意力機制自適應地輸入與文本相關的情感信息,產生了豐富的情感回復。Sun 等人將GAN 網絡的機制應用到Seq2Seq 模型中,推動系統生成最接近人類對話的語句。Sun 等人提出一種基于Seq2Seq 框架的多階段雙向異步解碼器,該解碼器充分利用語法約束,保證回復的流暢性和語法性。
為了更清晰地描述基于Seq2Seq 框架的情感對話生成模型的研究現狀,本文根據模型涉及的三個子任務、解決的問題、使用的數據集、涉及的評價指標以及模型的性能對這一類情感對話生成模型的研究現狀進行了梳理,如表3~表5 所示。在評價指標方面,A.E 代表自動評價,M.E 代表人工評價。A.E 主要包括困惑度(perplexity,PPL)、BLEU、ROUGE、Embedding、Distinct、EC(emotional consistency)以及Accuracy。M.E 使用人工的方式對內容(content)、情感(emotion)、語義連貫性(syntactic coherence)、自然(natural)、情感恰當性(emotional appropriateness)、語法正確性(grammatical correctness)、上下文連貫性(contextual coherence)、邏輯性(logic)等方面對模型的性能進行打分。
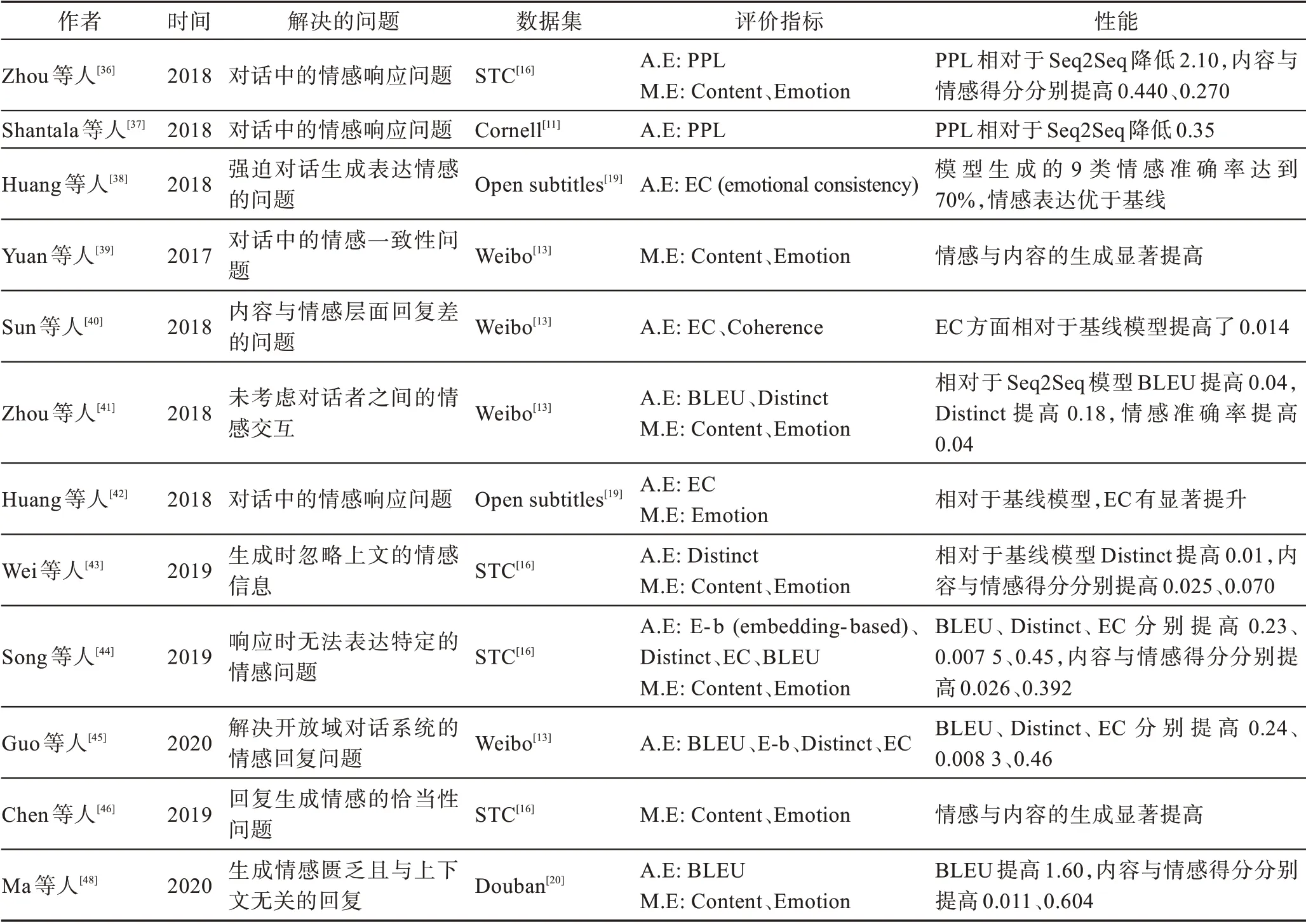
表3 情感嵌入編碼任務研究Table 3 Research on emotional embedding encoding task
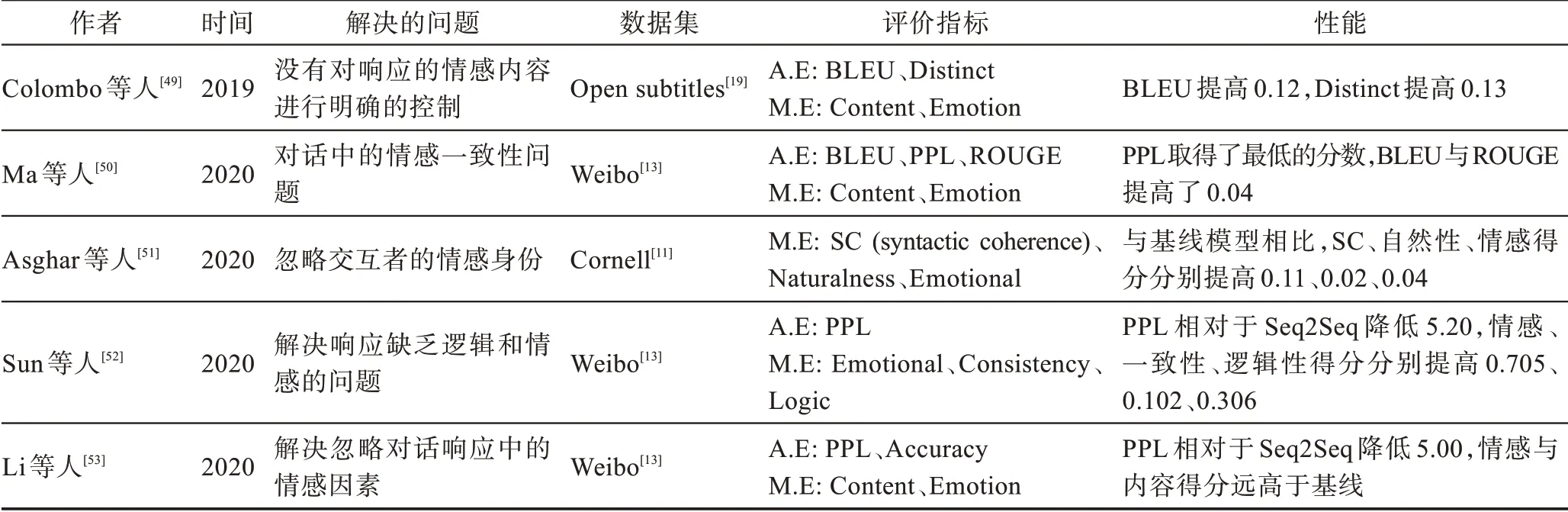
表4 回復生成情感控制任務研究Table 4 Research on emotional control task of responsive generation
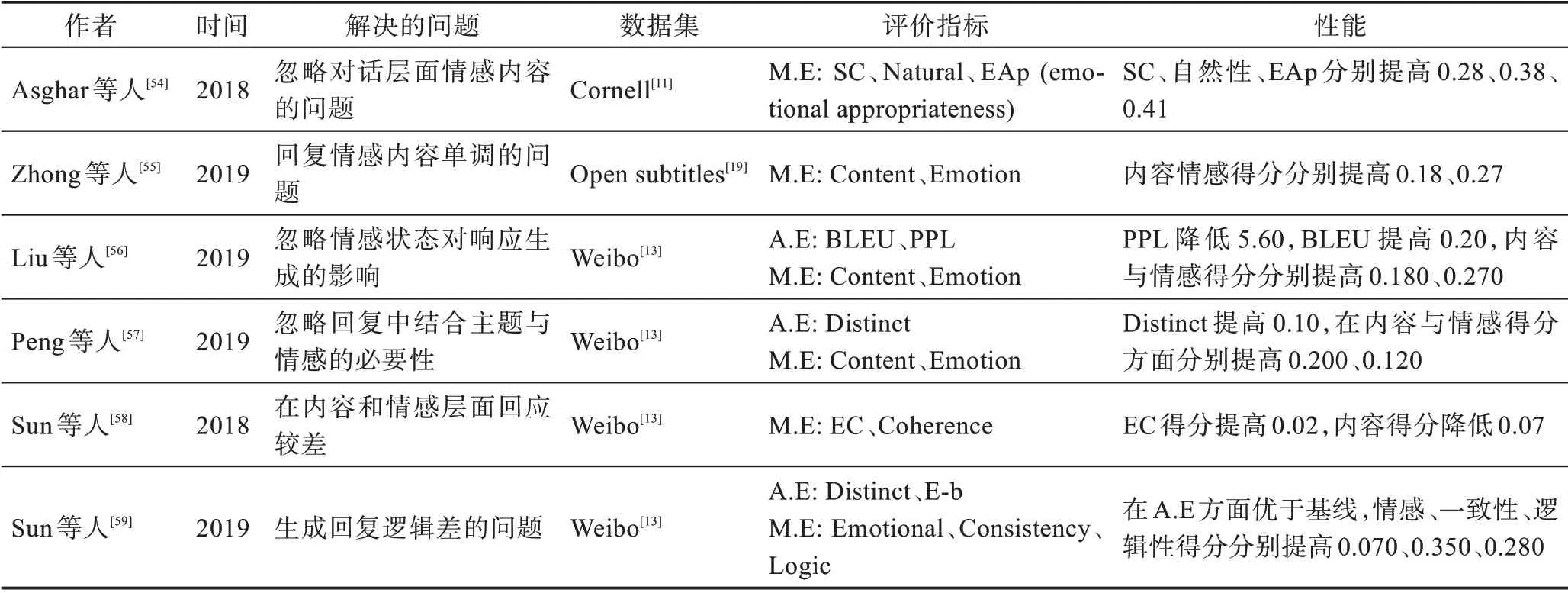
表5 情感回復生成解碼任務研究Table 5 Research on decoding task of emotional response generation
3.2 基于HRED 的情感對話生成模型
為了解決Seq2Seq 模型對于上下文依賴差的問題,Serban 等人提出了層級編解碼器模型(HRED),并且取得了很好的效果。如圖3 所示,該模型由話語級編碼器、話語間編碼器以及響應生成器三個網絡組成。首先話語級編碼器將每個話語中的詞序列向量表示轉換為話語的向量表示,以此捕捉每個話語的語義信息。然后,話語間編碼器將多個話語的序列表示轉換為對話上下文的向量表示,并提高對話上下文間的相關性。最后響應生成器獲取話語間編碼器的隱藏狀態,預測下一個話語中的概率分布,生成過程中的預測取決于話語間編碼器的隱藏狀態。
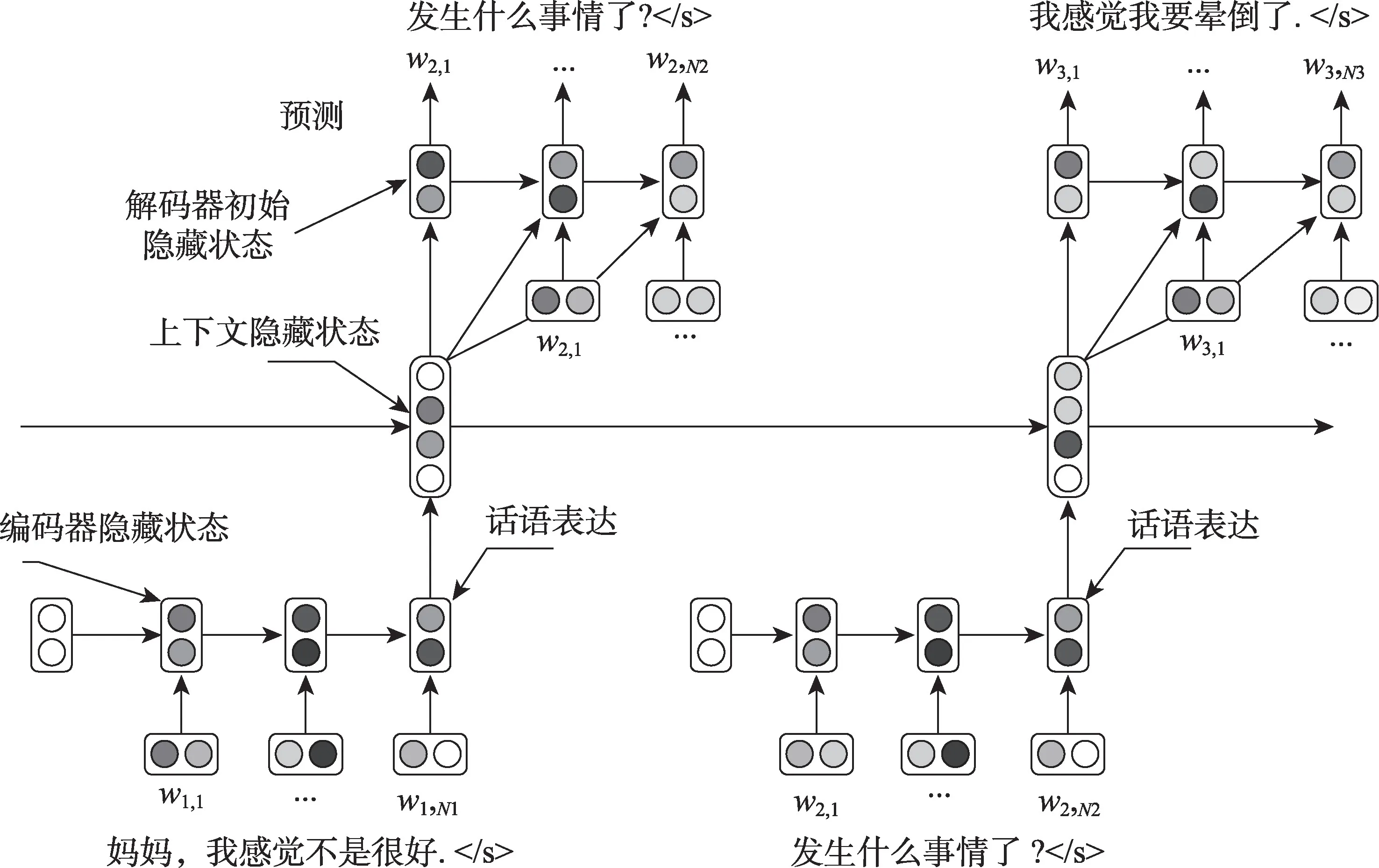
圖3 HRED 模型結構Fig.3 Structure of HRED model
由于HRED 模型可以更好地關注于上下文信息,提高對話上下文的關聯性,也被研究者應用在情感對話生成的研究中。例如:Xie 等人對HRED 框架進行改進,構建了一個多輪情感對話系統。通過額外的情感向量對話語建模,并且增加了一個學習數據集中情感交流的情感編碼器,使得多輪對話系統能夠識別和產生情感上恰當的回復。Lubis 等人擴展了HRED 模型,并增加了一個情感編碼器,以捕捉對話的情感背景,上文中的情感將對回復的生成產生影響。本文將基于HRED 框架的情感對話生成研究以及涉及的問題、任務、數據集、評價指標以及模型的性能進行梳理,如表6 所示。

表6 基于HRED 模型的情感對話生成研究Table 6 Research on generation of emotional dialogue based on HRED model
根據對現有的基于HRED 框架的情感對話生成研究現狀的整理,可以發現:基于該模型的研究,一方面關注于上文中的情感背景對于回復生成的影響,另一方面關注對話互動者之間的情感變化,因此HRED 框架相對于Seq2Seq 框架的優勢在這兩個問題上比較明顯。除此之外,正因為HRED 模型提高了對上文的關注,用來構建多輪情感對話系統也是一個很好的基礎模型。
3.3 基于VAE 的情感對話生成模型
由于變分自編碼器(VAE)可以將給定輸入的每個潛在特征表示為概率分布(|),這樣的表示方法特別適合表示對話中上下文的內部狀態,也可以表示對話上文中的情感狀態。因此許多研究者將VAE 應用到情感對話生成研究中,并且取得了很好的效果。如圖4 所示,VAE 由編碼器與解碼器兩部分組成,VAE 利用神經網絡建立了兩個概率分布模型:一個用于原始輸入數據的變分推斷,生成隱變量的變分概率分布,稱為推斷網絡;另一個根據生成的隱變量變分概率分布,還原生成原始數據的近似概率分布,稱為生成網絡。因此,VAE是一種生成模型。它引入統計思想在自編碼器中加入正則約束項,使得潛在特征滿足概率分布,并從中自動生成數據。條件變分自編碼器(conditional variational auto-encoder,CVAE)是在變分自編碼器之上再加一些額外信息為條件的一類模型,模型如圖5 所示。
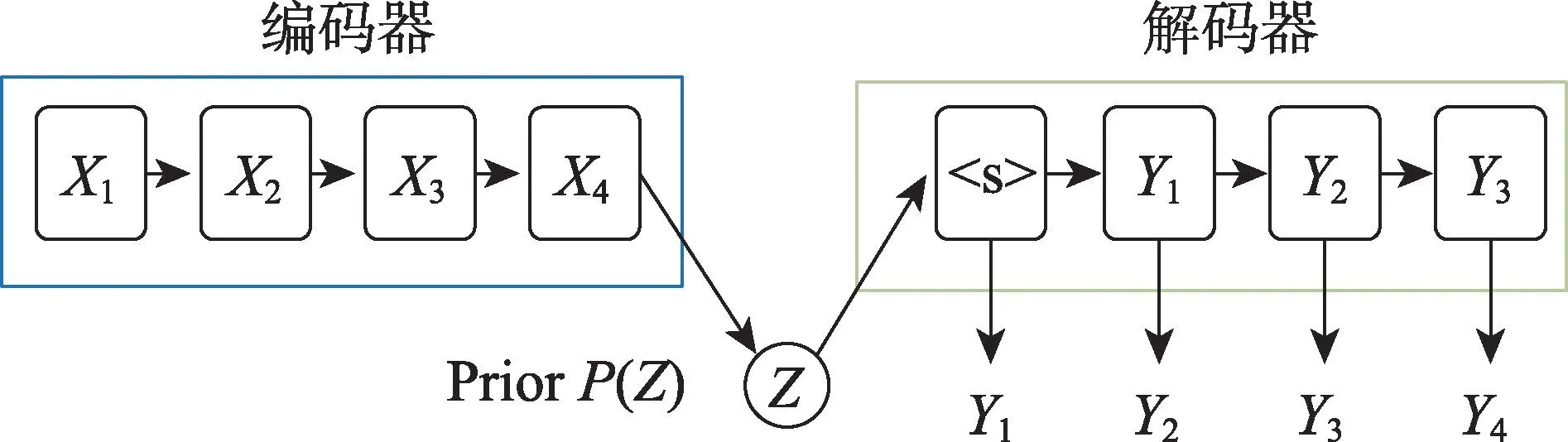
圖4 VAE 模型結構Fig.4 Structure of VAE model
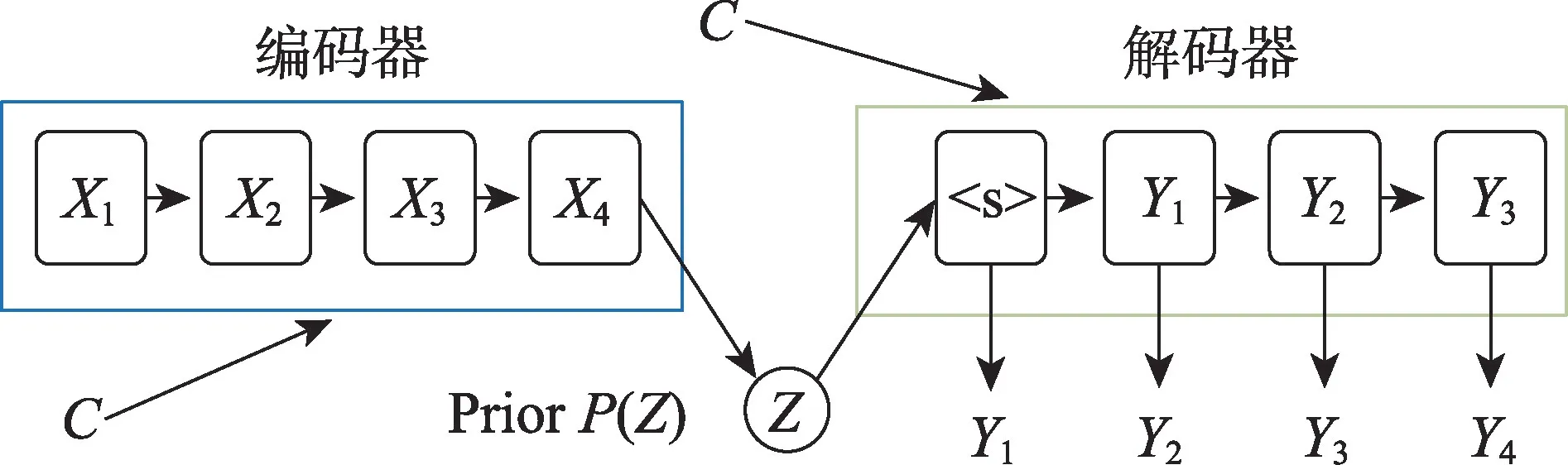
圖5 CVAE 模型結構Fig.5 Structure of CVAE model
由于CVAE 可以捕捉對話上文中的潛在變量,而情感對話生成中的情感狀態正好符合這個特性,許多研究者應用CVAE 實現情感回復生成,并且取得了不錯的效果。Gu 等人將CVAE 中的潛在變量分成情感和內容兩部分。然后進一步迫使潛在情緒策略預測目標情緒概率分布。通過使用隱式和顯式情感策略,新設計的解碼器結合了豐富的控制信息來解碼生成回復。Xu 等人提出了生成情緒回復的多任務雙注意力框架。利用雙重注意力機制結合CVAE,解碼基于CVAE 的輸出和給定的情感標簽生成情感回復,在保證回復多樣性的同時控制了回復的情感傾向。Kong 等人提出了結合CVAE 與Seq2Seq 模型的情感回復模型,將情感上下文回復和采樣的隨機潛在變量連接作為輸入并生成回復。顯式控制情感回復的方式,提高了生成內容的質量。Yao 等人基于CVAE 模型,引入了情緒門控機制和情緒引導機制,幫助模型基于相同的輸入生成多個情緒和語法正確的回復,生成的情感在多樣性方面取得了很好的效果。Peng 等人在CVAE 的基礎上,使用判別器來約束中間潛在變量,使得該變量能夠更好地編碼原始文本的情感特征信息,最終生成包含情感的對話文本。Huo 等人在解碼結構中配置了一個基于CVAE 的情感感知模塊來控制情感句子的生成,并配置一個用于增強主題相關性的主題感知模塊,該模型不僅能準確地生成期望的情緒回復,而且在話題關聯性方面表現良好。Deng 等人提出了一種基于CVAE 的情感回復生成模型,其中CVAE 中的潛在變量被用于促進對話的多樣性,使用雙重情感框架控制回復的情感,提高了情感回復的連貫性。基于CVAE 的情感對話生成研究如表7 所示。
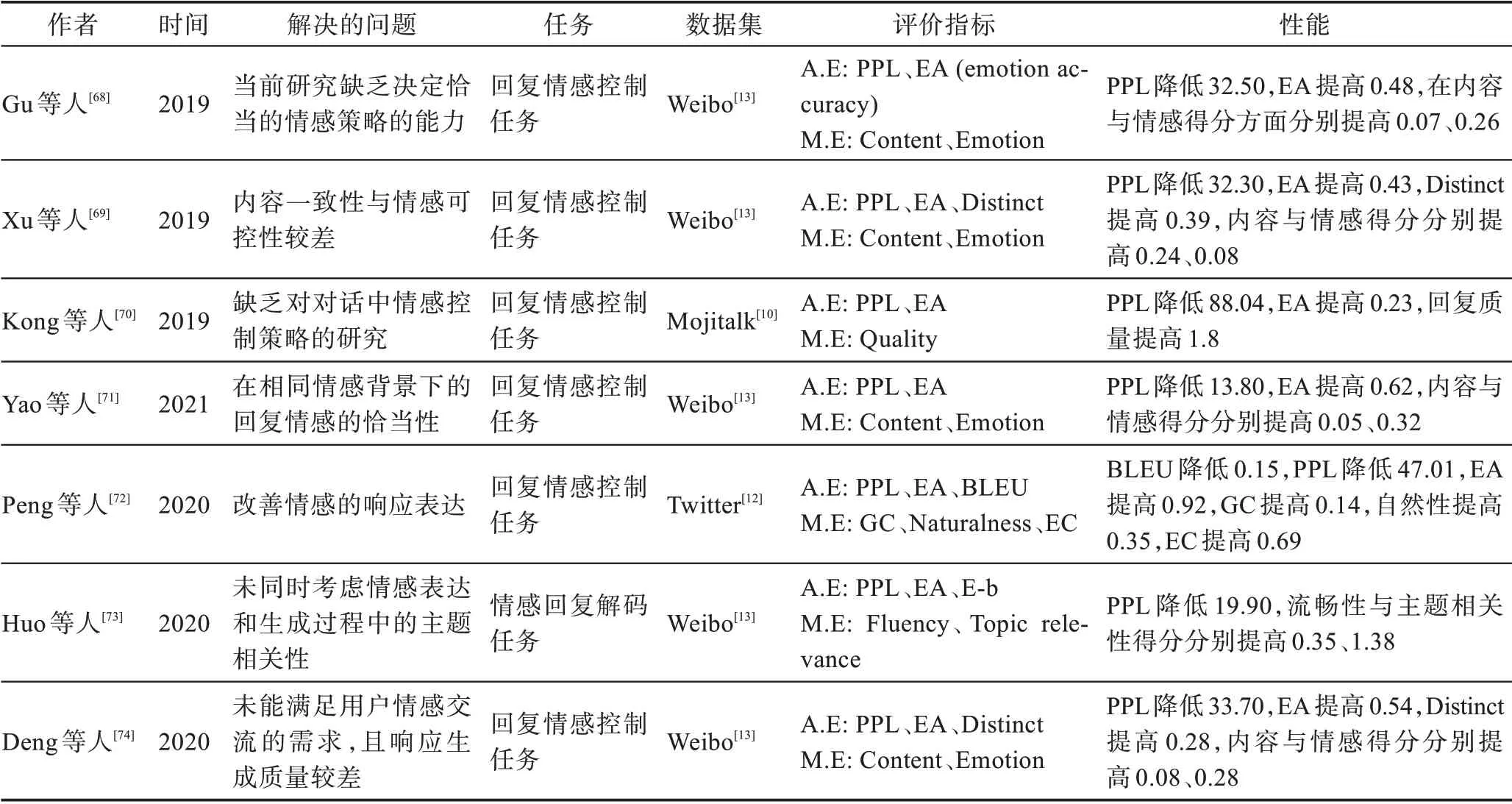
表7 基于CVAE 模型的情感對話生成研究Table 7 Research on generation of emotional dialogue based on CVAE model
通過對現有的應用CVAE 模型進行情感對話生成研究的整理,可以發現CVAE 模型在情感對話生成中有很高的應用價值。一方面,它可以很好地解決情感對話上文中難以捕捉的情感狀態問題,并且可以進行情感引導以及情感控制方面的研究;另一方面,CVAE 將潛在變量表示為概率分布而不是普通的編碼向量,因此將概率分布與情感向量結合進行解碼,不僅可以生成指定的情感,也可以提高生成的多樣性。
3.4 基于Transformer的情感對話生成模型
雖然Seq2Seq 模型與HRED 模型在對話生成方面取得了不錯的效果,但是基于RNN 的Seq2Seq 模型與HRED 模型對于長句以及多輪對話的生成效果卻不盡人意。為了解決這個問題,2017 年,Vaswani等人提出一種基于注意力機制的Transformer 模型,該模型引入多頭注意力機制,不僅關注當前詞,而且更多地關注整個句子中的詞,從而獲取到上下文的語義,有效解決了長句子文本以及多輪對話效果不佳的問題。
如圖6 所示,Transformer 模型也由編碼器和解碼器兩部分組成,對模型進一步細化后可以發現模型是由6 層編碼器和6 層解碼器組成的。每層編碼器包含多個子層,其結構都是相同的,且每一層都是由多頭注意力(multi-head attention)和前饋神經網絡層(feed forward neural network,FFN)構成。多頭自注意力層由自注意力機制構成,其主要目的是使當前節點不僅關注當前的詞,而且要對整個句子中的詞進行關注,從而獲取到句子中的上下文語義。前饋網絡層的目的是為增加多頭注意力層中輸出的向量的非線性變換。
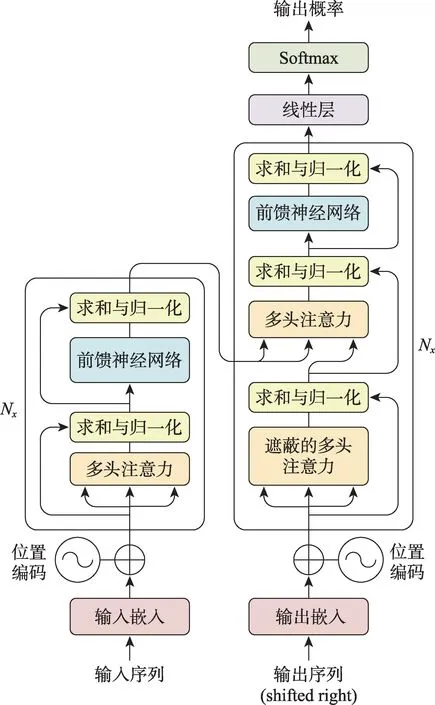
圖6 Transformer模型結構Fig.6 Structure of Transformer model
對于Transformer 模型的每層解碼器來說,結構也是相同的,與編碼器不同之處在于,解碼器在編碼器結構的基礎上增加了一層交叉多頭注意力機制層,其主要目的是使編碼器的輸出向量與當前解碼器中輸入的向量進行內容對齊,這與Seq2Seq 模型原理類似。除此之外,解碼器不再使用編碼器中的多頭注意力層,而使用遮蔽多頭注意力(masked multihead attention)層,其目的為幫助當前節點獲取到當前需要關注的重要內容,遮蔽的內容是真實標簽序列中當前節點之后的標簽。
Olabiyi 等人提出基于Transformer 的對話生成模型,更好地捕捉對話中的長期依賴,模擬了上下文的聯合分布,該模型相比其他多輪對話模型,性能有顯著提高,對于長句子生成也有很好的效果。鑒于Transformer 模型在多輪對話以及長句子生成方面的優越性,今后以Transformer 模型為基礎的對話生成模型將成為一大熱點。
由于Transformer 能夠關注全局信息,許多研究者將其引入情感對話生成研究。Sun 等人提出了一種基于貝葉斯深層神經網絡的情感對話生成模型,利用Transformer 中自注意力充分捕捉整句話前向與后向的信息,使模型在解碼過程中得到充分約束,生成高質量的文本。并且引入常識知識,生成了情感豐富、主題明確、句子多樣的回復。Li 等人提出一個新的變分模型來產生恰當的回復,可以引發用戶的特定情緒。該模型將回復后的下一輪話語整合到后驗網絡中以豐富語境,并在預先訓練的Transformer 模型的幫助下,將單個潛在變量分解成多個連續變量來指導回復生成。基于Transformer 的情感對話生成研究如表8 所示。

表8 基于Transformer模型的情感對話生成研究Table 8 Research on emotional dialogue generation based on Transformer model
通過對Transformer 應用于情感對話生成研究的整理,可以發現Transformer 改進了注意力機制,解決了RNN 存在的長時間依賴問題,可以關注于整句話的影響,對于對話中的上下文語境有著更好的關注。另外,相對于Seq2Seq 模型,Transformer 模型生成語言文本質量較高,更適合作為情感對話生成研究的基礎模型。
4 評價方式
基于端到端的情感對話生成回復的質量需要合適的評價指標進行評價,主流的評價方式包括自動評價與人工評價。
4.1 自動評價
在自動評價中,研究者采用機器翻譯的方法對模型生成回復與目標回復進行比較用于評價模型的質量,例如BLEU,但是由于這種方法與人類判斷的相關性較低,文獻[63]認為該方法不適合評價對話生成任務。本文面向情感對話生成中存在的回復生成質量、回復多樣性、語義相關性以及情感一致性問題,對相關的自動評價指標進行了梳理。
為了評價模型生成回復質量的好壞,研究者將ROUGE和困惑度(perplexity,PPL)作為衡量情感對話生成模型回復質量的評價標準。
ROUGE 指標是一種通過統計n-gram、詞序列和詞對重疊等單位來衡量生成摘要質量的指標,包括ROUGE-N、ROUGE-L 以及ROUGE-W。其中ROUGE-L 計算候選句與目標句之間的最長相同子序列(longest common subsequence,LCS),因此被用于對話生成任務中。ROUGE-L 計算公式如下所示:
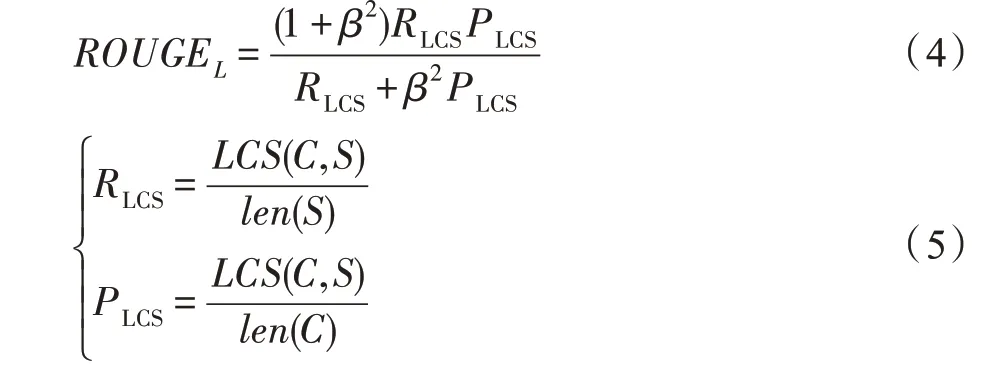
其中,和分別代表候選句和目標句序列,()和()分別代表候選句和目標句長度,代表超參數常量。
是基于模型自身,衡量語言模型好壞的指標。句子概率越大,語言模型越好,困惑度越小。計算方法主要是根據每個詞來估計一句話出現的概率,并用句子長度作標準化,公式為:
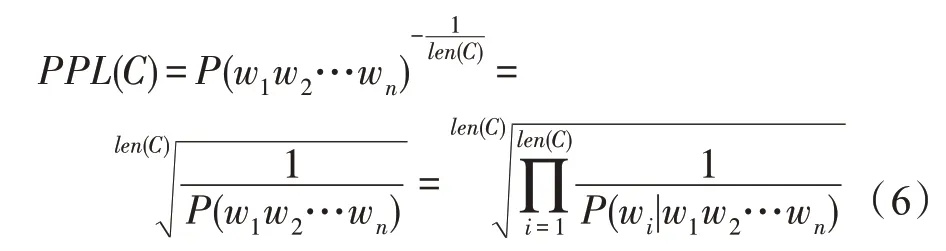
式中,代表候選句,()是句子長度,(w)是第個詞的概率。第一個詞就是(|),而是START,表示句子的起始,是個占位符。
然而研究者在評價回復生成質量的同時,也需要針對回復的多樣性展開評價。為了評價回復的多樣性,Distinct指標已被研究者所接受。其中文獻[63]使用生成回復中不同的Distinct-1 與Distinct-2 的數量計算候選回復中的多樣性成為了評價生成模型回復多樣性的重要依據。Distinct的計算公式如下:
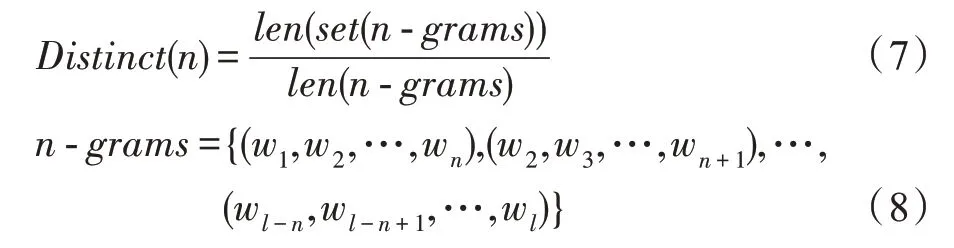
其中,()表示回復中不重復的數量,表示回復中詞語的總數量。()越大表示生成的多樣性越高。
為了捕捉生成的回復語句和目標語句之間的語義層面相關性,文獻[63]提出基于向量嵌入指標:貪婪匹配法(greedy matching)、向量均值法(embedding average)與向量極值法(vector extrema)。它們將回復映射到向量空間并計算余弦相似度,這幾種方法被廣泛應用于對話生成語義相似度計算中。
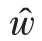
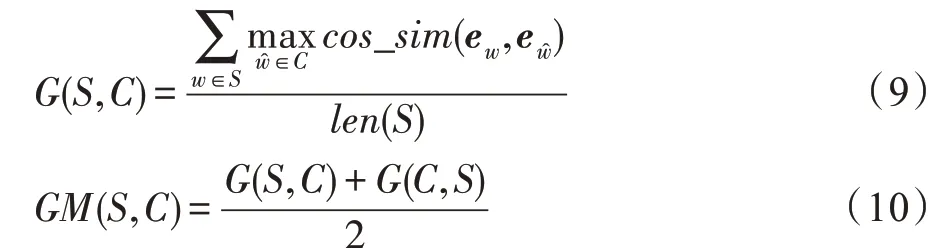
向量均值的計算方式:通過對句子中所有的詞向量求均值計算句向量的方法,計算句向量的公式如式(11)所示。

向量極值的計算方法:選擇句子中每個詞向量的最大維度和最小維度作為句向量的維度表示,極值計算公式如式(12)所示。
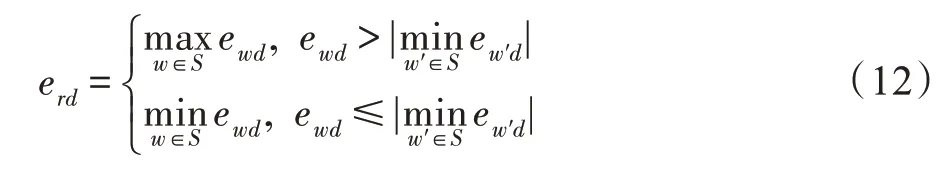
其中,代表一個向量的維度,e是的詞向量的第維。min 函數指如果最小負值的絕對值大于最大的正值時,取負值。
情感對話生成的關鍵在于生成帶有情感色彩的回復語句。當前主要針對回復生成一致性的情感的評價方式展開研究,衡量回復生成中情感的準確表達。根據文獻[44]的工作,研究者設計了基于情緒的度量標準,情緒a。情緒a 是通過構建基于神經網絡的情感分類器衡量預測的標簽和原始標簽之間的情感一致性。情感一致性(EC)計算公式如下:

其中,代表情感類別的數量;y代表如果預測標簽與原始標簽相同則為1,反之為0;代表語句的數量;代表情感類別索引;e代表目標句指定的情感類別索引。
4.2 人工評價
人工評價涉及人類的判斷來評價情感對話生成模型的性能。按照文獻[36]的工作,首先隨機取樣測試數據集中的100 個輸入句子。對于每個輸入句子,隨機化每個模型生成回復的順序。對于每個回復,需要5 個人工注釋者評估兩方面:內容和情緒。他們通過3 級評分(0,1,2)和2 級評分(0,1,2)分別從內容層面以及情緒層面評估每個回復。從內容層面評估一個回復是否連貫和對上下文有意義。從情感層面評估決定了一個回復是否揭示了期望的情感屬性,例如情感一致性、情感多樣性等,具體分值的含義如表9 所示。當然評分標準并不唯一,文獻[57]則使用分級評估量表對生成的回復進行評分,其中0=非常糟糕,1=差,2=邊緣,3=不差,4=好,5=驚訝。使用人工評價對本文的模型以及基線模型進行對比,比較模型性能的好壞。

表9 情感對話生成人工評價標準Table 9 Standard of emotional dialogue generation manual evaluation
通過對當前情感對話生成模型評價指標的整理,可以發現:一方面,對話生成中的自動評價指標主要延續機器翻譯的評價方式,針對候選句與目標句的匹配衡量對話生成回復質量的好壞顯然是不合適的。因此,針對情感對話生成自身的特點,設計衡量回復生成多樣性、回復內容邏輯性、情感恰當性等問題的自動評價指標是必要的。另一方面,當前的人工評價方式主要通過人為的方式進行衡量,這樣的方式經濟成本高,且不易普及。因此,如何對人工評價方式進行改進,將成為情感對話生成面臨的一大難題。
5 未來展望
通過對現有研究的梳理,本文對基于端到端的情感對話生成研究方向進行了展望。
(1)構建高質量的情感對話數據集。現有的對話數據集分別是從社交媒體或者影視資料中獲得,因此存在大量的錯誤以及噪音,適合情感對話生成模型訓練的高質量情感對話數據集相對匱乏。未來,可以參考對偶學習的方式,使情感對話模型實現自我對話,收集對話內容作為情感對話數據集。
(2)控制情感對話模型的回復邏輯。對話生成模型回復語言的邏輯性一直以來都是困擾研究者的一個重要問題,情感對話模型增加了情感信息使得這一問題尤為突出。數據驅動的情感對話生成模型的回復質量會受到數據集質量的影響。因此,一方面,引入文本推理技術對對話邏輯推理展開研究,可以作為未來研究者的研究方向;另一方面,使用知識圖譜的技術提高對話上下文中的指代,加強主題、情感與知識三者之間的聯系,生成符合主題邏輯、指代準確且情感豐富的語句,可以更好地模擬人類的交流方式,生成更有意義的語句。
(3)考慮個性化的情感回復生成。當前已經有許多研究者針對角色以及個性化的對話生成開展了研究,但是這些研究更傾向于學習角色的對話風格,在真實的對話場景中,不同的角色表達情感的方式是不同的。因此未來研究者應該面向角色與情感結合的對話生成建模,引入不同角色的情感表達方式以及表達風格,例如溫文爾雅的角色在表達情感時是含蓄的,而性格直爽的角色表達情感是直接的。這樣的研究可以使對話生成研究更符合人類的表達習慣。
(4)在情感對話中加入情緒引導機制。當前的情感對話生成研究中的情感回復生成大多數針對指定情感進行回復生成,這與真實的人類對話場景存在差異。為了使情感聊天機器人走入人類的日常生活,構建能夠隨著用戶情感變化而生成恰當情感回復的情感撫慰機器人是必不可少的,因此在情感對話生成中構建符合心理學邏輯的情感引導機制是未來可行的一項研究。
6 總結
隨著深度學習技術的發展,情感對話生成模型已經被越來越多的研究者關注,構建符合人類正常表達的情感對話系統是研究者努力的方向。因此,情感對話生成模型不僅僅要實現情感的表達,而且對于生成語言質量以及對話邏輯有著更高的要求。本文面向基于端到端的情感對話生成研究開展綜述,首先對現有的研究進行整理并總結了情感對話生成研究的任務組成,并對解決的問題進行了定義和總結;其次對現有研究所需的情感對話數據集進行了總結;然后針對基于端到端的情感對話生成研究涉及的基礎模型,分別從原理以及研究現狀進行了梳理;最后對當前研究中模型的評價方式進行了總結。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
