如何挖掘HPA數據庫中研究數據并生成結果表達圖
2022-02-23 10:24:34蘇永發陳金圖
實驗與檢驗醫學 2022年5期
關鍵詞:頁面
蘇永發,陳金圖
(福建醫科大學附屬泉州第一醫院檢驗科,福建 泉州 362000)
蛋白質是人體一切器官、組織、細胞甚至亞細胞的重要組成成分。解決人類所有蛋白質在器官、組織、細胞和亞細胞水平上的空間分布,將進一步增加我們對人類健康和疾病生物學的理解。
隨著眾多公共數據庫的建立和開放,越來越多的研究者可以從中直接獲取大數據,方便研究者的后續工作。HPA數據庫是一個用于癌癥和正常基因表達譜分析和交互分析的web服務器,幫助臨床科研愛好者更高效的利用公共數據資源。本文通過初步介紹HPA數據庫公共網頁各個模塊的功能,讓HPA網頁式的交互界面使用更簡單。
1 H P A簡介與檢索方法
1.1 簡介 HPA數據庫官方網站:www.proteinatlas.org利用各種組學技術致力于提供全部24000種人類蛋白質的組織和細胞分布信息。地圖集被定義為提供全面信息的、可視化的地圖或圖表的集合。HPA采用該種方法,將人類蛋白質圖譜分為六個獨立的部分:組織圖譜[1-2]顯示了蛋白質在人體所有主要組織和器官中的分布,細胞圖譜[3]顯示了蛋白質在單細胞中的亞細胞定位,病理譜譜[4]顯示了蛋白質水平對癌癥患者生存的影響。HPA的第19個版本新增了三個模塊:大腦圖譜,血液圖譜和代謝圖譜(圖1)。

圖1 HPA首頁界面及搜索結果界面
1.2 方法HPA提供兩種不同的方式訪問該頁面。最直接的方法是直接搜索功能,可用于自由文本的搜索,比如通過基因名稱、EnsEM BLe基因編號和抗體編號等進行查詢。以CCNB1為例進行搜索(圖1),我們獲得3個搜索結果。HPA網站還可以提供更精確的搜索。Fields提供多項選擇,我們可以按照需要目的性地進行搜索。比如通過蛋白質表達水平和蛋白質分類信息等進行高級查詢。它不僅能夠包含(或排除)定位于特定組織或細胞器的蛋白質,而且還可以通過結合多種標準(例如添加依賴于細胞周期的標準)來優化搜索亞細胞表達和RNA表達。搜索結果將會生成一個以基因為中心的結果列表并提供更全面的信息。通過在頁面上相應的縮略圖,我們可以在不同的子圖譜上進行切換。
第二種方法是通過登錄頁面(圖2A),其提供了蛋白質組的交互式知識章節。如圖顯示,組織圖譜和細胞圖譜的登入頁面包含有許多可點擊的圖像和表格等,其包含對組織/細胞器的簡要說明。登入頁面的一個關鍵性就是交互性,每個圖像、數字或圖解都是可點擊的,直接鏈接到相應基因列表、特定組織或細胞圖像。
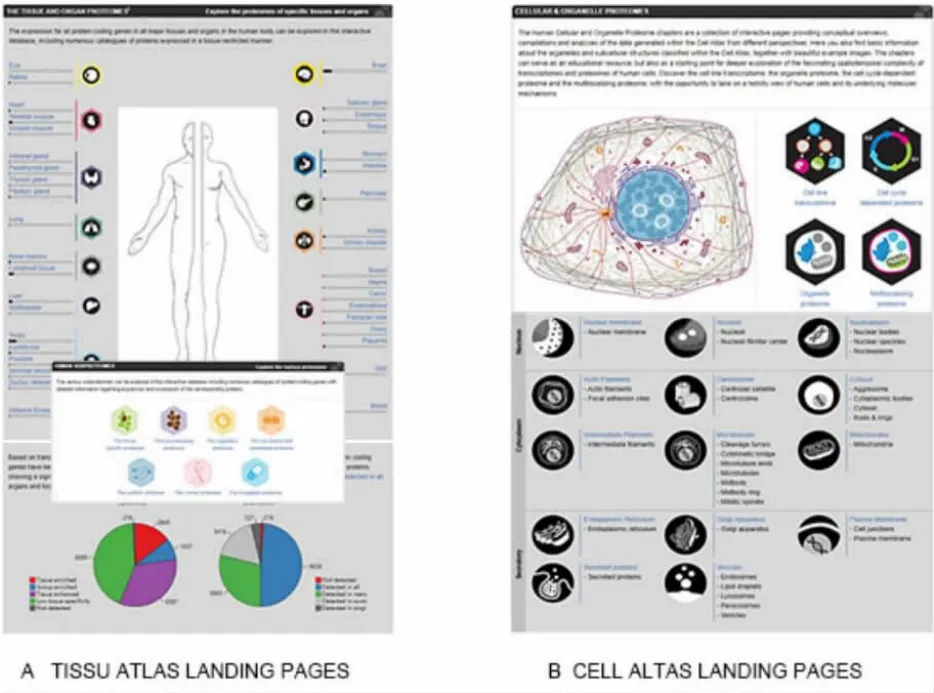
圖2 組織圖譜登陸界面及細胞登陸界面
2 圖譜分類與數據下載
2.1 組織圖譜 在主要的圖集中我們可以查到相關的RNA-Seq數據,組織圖譜上的每個基因頁面都進行了全面的信息總結,包含相應的mRNA和蛋白質表達水平[1]。針對76種不同的細胞類型、對應于涵蓋人體所有主要部位的44種未患病的人體組織類型進行了分析,數據以基于組織的蛋白質表達水平注釋的形式呈現。GENERAL INFORMATION從Ensembl、蛋白質分類、預測定位和轉錄水平等方面對基因信息進行了總結(圖3A)。Show more可提供更多基因信息,并且“i”符號都能夠進行點擊,它提供了簡短的描述幫助用戶進行理解。Human Protein Atlas Information針對HPA生成的RNA-Seq數據、GTEx數據庫[5]和FANTOM5數據庫[6]進行描述。根據表達模式,HPA將所有人類蛋白質編碼基因進行分類,包括全部表達、組織富集、組織增強、混合表達和未檢測到等[7]。此外,其他欄目還提供相關詳細信息。根據共同的功能特征,將被分析的組織分為13個不同的組,每組都可以單擊以訪問包含的組織列表(圖3B)。圖3C顯示了在不同組織中蛋白質的表達水平和mRNA的表達水平。單擊組織名稱或豎狀條,可訪問詳細數據頁面。
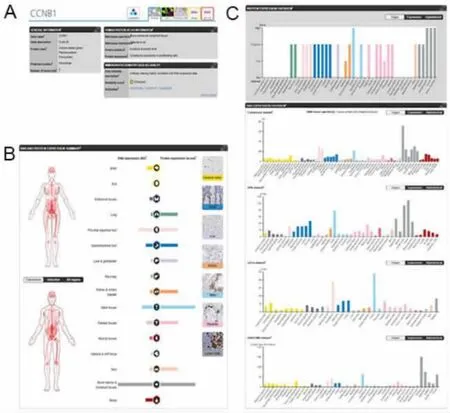
圖3 以CCNB1基因為例的組織圖譜頁面布局
每個組織都有一個提供詳細數據的獨立頁面,顯示了染色圖像以及被分析的細胞類型的表達水平。此處用睪丸作為示例,實驗中使用的三種不同抗體各顯示三張圖像(圖4A),該蛋白質的表達在在輸精管的細胞亞群中高度表達,而在間質細胞中未檢測到。所有圖像均可被單擊放大成高分辨率視圖(圖4B),允許在鄰近細胞的背景下對蛋白質表達進行可視化觀察。圖4C提供RNA表達數據的詳細信息。TESTIS-HPA RNA-seq提供了組織切片圖像,包括樣本中存在的細胞類型的估計分值。這使用戶有可能評估和進一步了解基于不同細胞類型混合的RNA表達數據,并將信息與細胞類型特定的蛋白質表達譜進行比較。HUMAN SUBPROTEOMES提供一個亞蛋白質組登入頁面,其概述了某些功能性基因組,如可用藥蛋白質組和癌癥蛋白質組等(圖2A)。進入亞蛋白質組鏈接頁面的網絡圖顯示了不同組織中富集基因之間的分布。紅色節點代表組織富集基因的數量,橙色節點代表組織富集的基因數量(圖5)。 紅色和橙色節點的大小與節點內顯示的基因數量有關。每個節點都是可進行點擊的,并產生所有富集基因的列表。
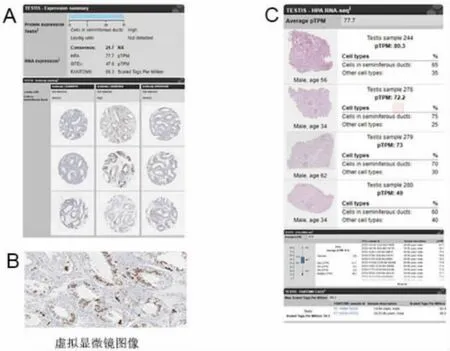
圖4 以CCNB1為例的組織圖譜詳細數據
2.2 病理圖譜 目前的《癌癥圖譜》包含20種最常見的蛋白質表達數據,與組織圖譜相一樣,在組織芯片基礎上使用進行免疫組化染色。在《病理圖譜》中,在癌癥基因組圖譜的全基因組表達數據的基礎上,采用系統水平方法對人類基因組的臨床結局進行分析。來自HPA的RNA序列數據和8000名個體癌癥患者(包括20種主要癌癥類型中的17種)被用于確定每種癌癥類型中每個基因的RNA表達水平與總生存時間之間的相關性。有超過500000個Kaplan-Meier圖無偏倚地對預后基因進行鑒定。預后基因被分為有利基因(RNA高表達與較長的生存時間成正相關)和不利基因(RNA高表達較長的生存時間成負相關)。與其他癌癥相比,研究者可以識別某些癌癥類型中升高的基因。研究還表明,個體腫瘤的基因表達模式存在較大差異,可能超過不同腫瘤類型間的差異。這些數據可用于為癌癥患者生成個性化的基因組級代謝模型,以識別與腫瘤生長有關的關鍵基因。PROGNOSTIC SUMMARYi呈現了與癌癥類型相關的預后基因Kaplan-Meier繪制(圖6A)。RNA EXPRESSION OVERVIEW顯示了17種癌癥的mRNA表達水平(圖6B)。PROTEIN EXPRESSIONi展示了免疫組化染色的癌癥組織的圖像,并總結了使用免疫組化分析的不同癌癥類型的蛋白表達水平(圖6C)。每個癌癥組織都有一個詳細的數據頁,提供生存分析數據和每個患者的RNA表達水平(圖6D),以及可點擊的免疫組織化學癌癥組織的圖像(圖6E)。以MKI67癌基因為例,如圖顯示該基因的高表達與肝、腎和胰腺癌的預后有關(圖6F)。
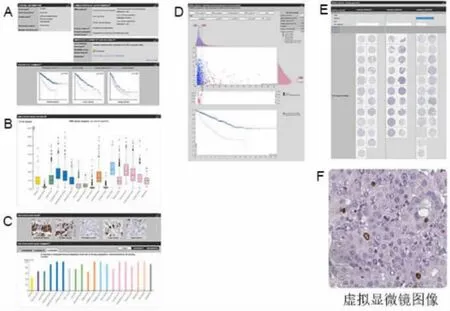
圖6 以CCNB1為例的病理圖譜頁面布局
2.3 細胞圖譜 細胞圖譜包含了12,003個蛋白質的空間分布,這些蛋白質被定位到32個亞細胞結構,進而對13個主要細胞器蛋白質組進行描述。IF圖像的高分辨率允許檢測單個細胞之間的信號變化。這些細胞間的變化可能是信號強度的變化,表明不同細胞中蛋白質的豐度不同,或者蛋白質的定位在不同的細胞中是不同的。HPA使用兩種不同的方法來尋找蛋白質表達的細胞周期依賴性:首先,在U-2 OS FUCCI細胞系[8-9]中對選定的蛋白質進行染色。第二種方法是基于微管和核的特征解析細胞周期位置的創新計算模型。這些細胞按標準方法進行染色,抗體用綠色表示,紅色表示微管,黃色表示內質網,藍色表示細胞核。Human Protein Atlas INFORMATIONi一欄匯總了實驗生成的數據,包括基于細胞系中TPM值的RNA表達類別(以與RNA組織類別相同的方式計算)和單細胞變異等。自定義數據是Cell Atlas新增的功能之一。它們鏈接到附屬的研究項目,并提供正常細胞圖譜數據之外的其他信息。
圖7A/B顯示了56種細胞系中CCNB1基因的mRNA表達情況,利用12種顏色來區別這些條狀圖區分不同器官來源。將鼠標懸停在一個細胞株上,將顯示RNA-Seq的結果和關于該細胞株的詳細信息。此處,高分辨率IF圖像顯示了不同細胞系中蛋白質的亞細胞定位。細胞圖譜所使用的細胞系是根據RNA表達水平從22個系中選出的,但始終以U-2 OS作為參考。IF染色主要采用多聚甲醛固定步驟,利用激光共聚焦掃描顯微鏡上對細胞手動或自動成像[10]。圖像包括四個通道(感興趣的蛋白、細胞核標記、微管和ER),可以自由進行開關。此外,還有一些信號強度通道,它們顯示細胞面積和細胞周期位置。研究者可以同時選擇三個圖像進行比較。可以通過單擊復選框或拖放大圖上的縮略圖選中,所有圖片也可以點擊放大查看,如圖7C所示。圖8顯示U-2 OS FUCCI細胞系中的IF染色情況。G1期的Cdt1(紅色)和S與G2期的Geminin(綠色)(圖8A)顯示CCNB1表達在S/G2期(圖8B)達到峰值。The organelle proteome的登錄頁是所有細胞器和亞結構蛋白質組的摘要,它們在細胞圖譜中被描述。由于大多數蛋白質是在兩個或兩個以上的細胞器中被檢測到的,因此有一個登陸頁專門介紹這種多位點蛋白質組。
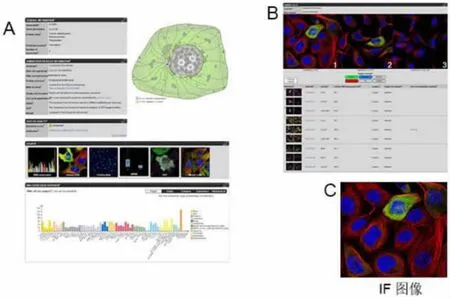
圖7 以CCNB1基因為例的細胞圖譜頁面布局
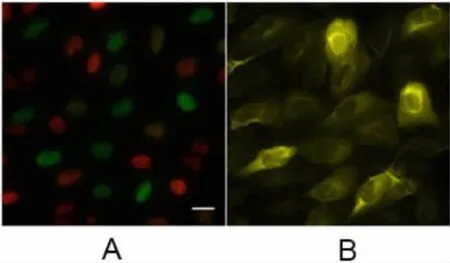
圖8 U-2 OS FUCCI細胞系中的IF染色情況
2.4 大腦圖譜 《大腦圖譜》通過整合三種哺乳動物物種(人、豬和小鼠)的數據探索了哺乳動物大腦中的蛋白質表達。圖9A顯示了CCNB1在人、豬和小鼠大腦不同區域的表達情況。我們可以從中獲得一系列大腦樣本的mRNA表達數據,這些樣本來自10個大腦主要區域,包括垂體和視網膜等。該圖集分析了來自整個小鼠大腦切片上的271個基因,從中我們可獲得高分辨率的免疫熒光圖像,探索蛋白質在小鼠大腦中的位置。我們可以通過點擊組織名稱或條狀圖訪問樣本數據。以NECAB1基因(神經元鈣結合相關蛋白)為例,神經元亞群在整個大腦中顯示出明顯的體樹突狀免疫反應性。圖像9B顯示了老鼠大腦海馬區神經元亞群的蛋白質位置。
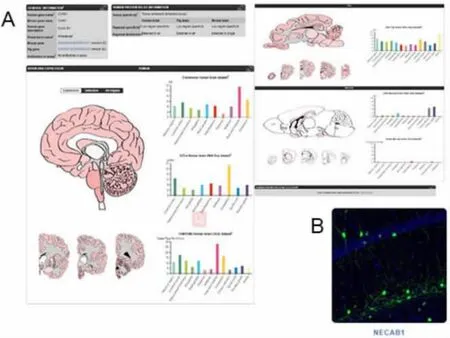
圖9 CCNB1在人、豬和小鼠大腦不同區域的表達情況
2.5 血液圖譜 《血液圖譜》提供了有關人類血液的細胞類型和蛋白質組的數據,提供了通過細胞分選分離出的18種單血細胞類型的轉錄組學數據,包括各種B細胞和T細胞等。血液蛋白質組由基于質譜的蛋白質組學和/或基于抗體的免疫分析確定的血液蛋白質濃度數據表示。此外,該圖集還對人類分泌體進行了分類,并對人類預測的分泌蛋白進行了注釋,試圖確定哪些基因會積極地分泌到人類血液中,哪些基因在諸如消化系統等。圖10A顯示血細胞類型表達概述顯示了來自三個不同來源的RNA-seq數據:HPA數據、Monaco scaled和Schmiedel scaled生成的數據,其顏色編碼是基于血液細胞類型譜系。我們可以通過單擊組織名稱或欄訪問詳細的數據頁。
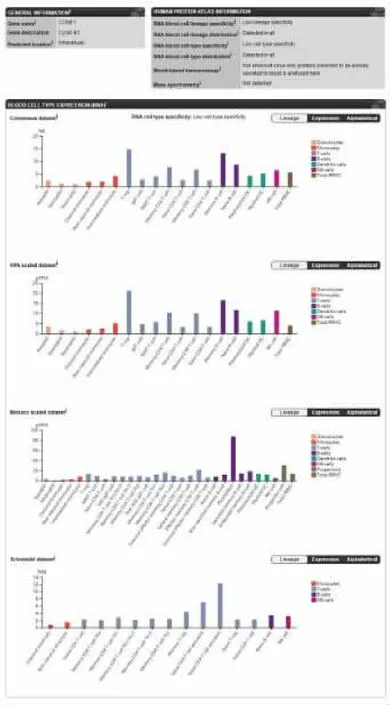
圖10 血液圖譜的頁面布局
2.6 代謝圖譜 組織圖譜的內容已擴展到代謝圖譜,從而能夠在人類代謝網絡的背景下探索蛋白質功能和基因表達。代謝圖譜可用于超過120種不同的代謝途徑或子系統,每個圖都描繪了蛋白質與所涉及的生化反應之間的聯系。每個通路圖都伴隨著一個熱圖,詳細描述了37種不同組織類型中所有參與代謝通路的蛋白質的mRNA水平。如圖11A所示代謝通路圖是由個別路徑組織的,以方便代謝區域的可視化,更多的細節和完全互動的路徑圖可以在metabolicatlas.org上找到。圖11B描述了代謝圖譜中完整的通路詳細列表和每個通路中涉及的酶的數量。
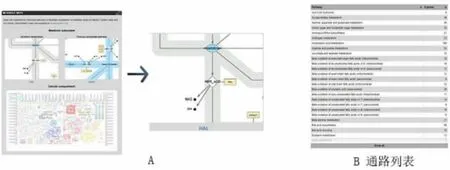
圖11 代謝圖譜的頁面布局
2.7 數據下載 在搜索頁面上列出的數據與當前搜索結果相對應的基因可以以不同的格式下載,包括XML、RDF和TAB。HPA還提供不同的可下載文件,包含來自組織的完整初級蛋白質數據,病理和細胞圖譜等,以及組織和細胞中的RNA表達水平。所有可下載的文件都可以在www.proteinatlas.org/about/download網站找到。
3 討論
目前,生命科學和醫學已進入大數據驅動的革新時代。基因表達譜在生物學、醫學等多個領域發揮著重要作用。網絡上的分子生物學數據庫種類多及涉及面廣。HPA網站有著數以百萬計的高分辨率圖片,從該網站下載下來的數據可作為參考數據集進行大規模生物信息學分析。本文初步介紹了HPA網站的基本功能。隨著更多感興趣的研究者的使用,我們相信HPA的更多功能會被挖掘,以便于研究者的使用,從而減輕科研工作者壓力,提高工作效率。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
電腦愛好者(2022年3期)2022-05-30 10:48:04
工業設計(2016年1期)2016-05-04 03:58:09
通信技術(2012年4期)2012-02-15 07:10:35
電腦愛好者(2011年11期)2011-06-22 08:20:18
網絡安全技術與應用(2011年3期)2011-03-14 06:44:46
赤峰學院學報·自然科學版(2010年11期)2010-09-21 11:30:50
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
