基于改進語音處理的卷積神經網絡中文語音情感識別方法
2022-02-24 05:07:04陳章進屠程力
計算機工程 2022年2期
喬 棟,陳章進,2,鄧 良,屠程力
(1.上海大學 微電子研究與開發中心,上海 200444;2.上海大學 計算中心,上海 200444)
0 概述
語音情感識別作為人機交互領域的重要技術,能使機器理解人類的情感狀態,并使智能機器具有感知情感的能力。目前,語音情感識別越來越受到重視[1-3],語音信號中用于情感識別的特征包括能量、音高、過零率、共振峰、語譜圖[4-5]、梅爾倒譜系數等[6]。將這些低層特征以語音幀為單位進行提取,并把它們在語音段的全局統計特征值輸入到分類器中進行情感識別。傳統的語音情感識別方法通常使用人工選取的特征輸入淺層機器學習模型進行分類識別,例如高斯混合模型[7]、支持向量機[8]、隱馬爾科夫模型[9]等。支持向量機和隱馬爾科夫方法在機器學習中經常被使用,具有較高的確定性。而人的情感具有較強的復雜性和不確定性,因此在語音情感識別中表現較差。隨著機器學習技術的應用和發展,研究人員開始使用神經網絡分類器來執行各種語音情感識別任務,神經網絡在處理不確定和非線性映射問題方面具有獨特的優勢,并且可以檢測其他分類技術無法檢測到的規律和趨勢,是模式識別中使用最廣泛且最成功的多層前饋網絡。由于語料庫中沒有統一的標準,因此識別效果差異很大[10-12],人類情感信息的復雜性和不確定性導致卷積神經網絡識別中文語音情感的準確率仍然不高。
對標準的中文語音情感庫CASIA 而言,僅對卷積神經網絡進行改進的方法,其識別準確率不足60%[13]。在卷積神經網絡的基礎上,為緩解過擬合,有研究人員使用參數遷移的方法,并加入了數據增強[14],使其在CASIA 數據集上的識別準確率提高到了72.8%。文 獻[15]通過改進Lenet-5網絡,在CASIA 數據集上取得 了85.7% 的識別率[15]。文獻[16]在卷積神經網絡的基礎上加入循環神經網絡層,將CASIA 數據集上的識別準確率提升至90%左右[16]。
為進一步提高中文語音情感的識別效果,本文提出一種基于卷積神經網絡的中文語音情感識別方法。通過改進MFCC 特征提取方法以及加入高斯白噪聲進行數據增強,提高識別效率。同時,建立一種輕量化的Trumpet-6 卷積神經網絡模型用于中文語音情感識別,提高識別準確率。
1 語音情感識別的相關研究
1.1 語音的MFCC 特征提取
在語音識別領域,MFCC 是最常用的語音特征之一。通過對人類聽覺機制的研究發現,人耳對不同頻率的聲波具有不同的聽覺敏感性,低頻率的聲音往往會掩蓋高頻率的聲音,低頻段聲音掩蔽的臨界帶寬小于高頻段。因此,根據從密集到稀疏的臨界帶寬,從低頻到高頻設置一組梅爾帶通濾波器對輸入信號進行濾波[17],以梅爾帶通濾波器輸出的信號能量作為信號的基本特征,對語音的輸入特征進行處理。由于MFCC 特征不依賴信號的性質,對輸入信號沒有任何假設和限制,因此,該參數具有更好的魯棒性[18],更符合人耳的聽覺特性,在信噪比(Signal-to-Noise Ratio,SNR)降低的情況下仍具有良好的識別性能[17]。
MFCC 特征與頻率的關系可用式(1)近似表示:
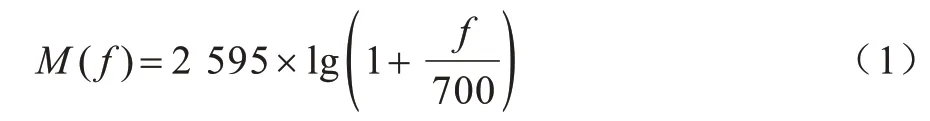
MFCC 特征的提取過程如圖1 所示。
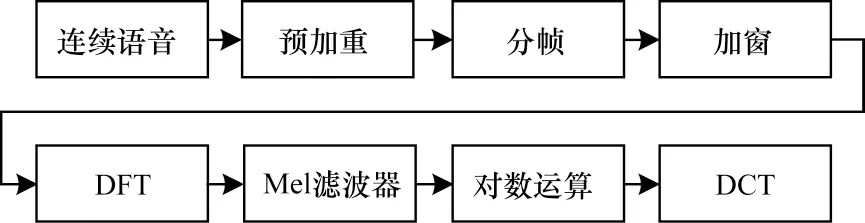
圖1 MFCC 特征提取過程Fig.1 MFCC feature extraction process
分幀操作把N個采樣點壓縮為1 個單位,即1 幀,對這1 幀加窗(漢明窗等)計算后,再進行后續處理。幀與幀之間有重疊部分,是為了使幀與幀之間平滑過渡,保持其連續性。由于預加重操作實際相當于高通濾波,因此分幀加窗后得到的數據能夠為后續時頻變換初始化數據。
1.2 高斯白噪聲
如果一個噪聲的功率譜密度為常數,即功率譜均勻分布,則稱其為白噪聲;若此白噪聲的幅度分布服從高斯分布,則稱其為高斯白噪聲。本文采用高斯噪音,是為了更好地模擬未知的真實噪音,因為在真實環境中,噪音往往不是由單一源頭造成,而是很多不同來源的噪音復合體[19]。假設把真實噪音看成非常多不同概率分布的隨機變量加合,并且每一個隨機變量均獨立,那么根據中心極限定理,其歸一化和則隨著噪音源數量的上升,呈現高斯分布[20]形態。因此,使用合成的高斯白噪聲為合理的近似仿真。
1.3 數據增強
在深度學習中,數據與模型均為影響最終訓練結果的重要方面。在神經網絡訓練之前對數據集進行數據增強,是有效緩解模型過擬合的方式。通過對輸入特征圖進行數據增強,可以讓網絡模型將經過處理后的同一幅圖片當成多幅圖片,擴充數據集的樣本數量[21-23]。通過給神經網絡模型輸入足夠的圖片,可以保證神經網絡模型能夠提取足夠多的有效信息。
數據增強的傳統方法包括對圖片進行旋轉、平移、翻轉等。由于在語音識別領域,圖片是提取語音信息后所得數值矩陣產生的圖像,因而具有一定的聲音特性。例如,對于圖像來說,橫軸和縱軸沒有實際意義,而對于MFCC 特征矩陣來說,橫軸代表時間,縱軸代表通頻帶上的濾波器編號。因此,傳統數據增強方法在處理圖像時所運用的圖像旋轉、平移、翻轉等破壞了語音信號的連續性,導致聲音特性出現混淆與丟失的現象,準確率難以提高[14]。而現階段的研究較少關注中文語音情感識別數據增強方法的改進。
2 基于卷積神經網絡的中文語音情感識別方法
2.1 改進的數據處理方法
本文使用的CASIA 數據集為短句形式,句子長度約為1~2 s,語音連續特征相對于長語音句較少,因此將語音信號轉化為圖片,并利用卷積神經網絡進行語音情感識別。
本文對語音情感數據集的MFCC 特征提取以及預處理方法進行了改進,主要包括分幀加窗的采樣點個數選取及高斯白噪聲數據增強這兩個方面。
2.1.1 分幀加窗的采樣點個數選取
分幀加窗對特征圖的影響如圖2 所示,將語音信號按S個采樣點取走分幀,經過后續加窗(漢明窗w(s))、快速傅里葉變換等操作,最終變為MFCC 特征圖中的一列,S的值不同,MFCC 矩陣的列數就不同。當S=512 時,橫軸L的長度為252;當S=2 048 時,L僅為63。
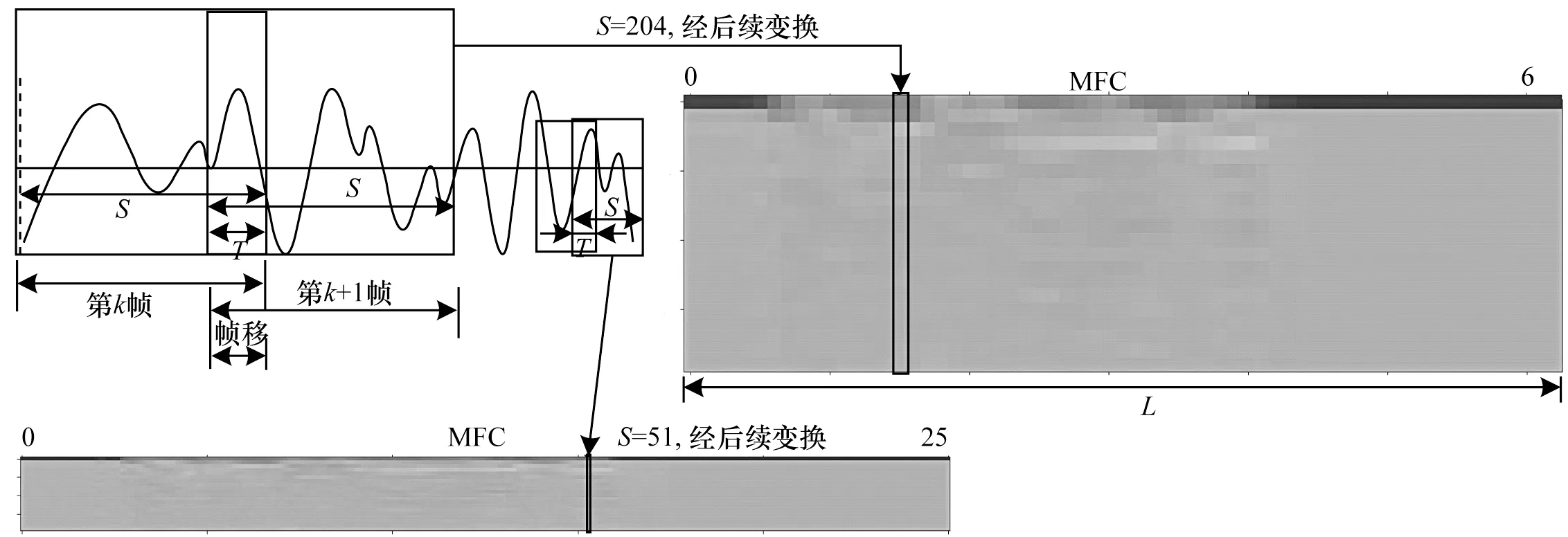
圖2 分幀加窗對特征圖的影響Fig.2 Influence of framing and windowing on feature map
分幀加窗直接影響特征圖大小,經過歸納,計算公式如式(2)所示:

其中:L為特征圖橫軸長度;D為語音信號總的采樣點個數,信號長度為2 s 時共有32 000 個采樣點;S為幀長;T為幀移。
對于分幀加窗的采樣點個數,以往傳統的方式習慣選擇2 的整數次冪,如256 或512。這種較少采樣點的設置會使生成的MFCC 矩陣的橫軸,即代表時間的軸過長,導致神經網絡輸入特征圖過大,而設置過多采樣點又會令特征圖上每個像素點所代表的壓縮后聲音特征不明顯,識別準確率下降。因此,本文經過實驗后,將采樣點確定為2 048,并視為單幀可容納采樣點的上限,將其作為幀長。同時,幀移設置為1/4 幀長,即512 個采樣點。將幀內語音信號y(s)與漢明窗w(s)疊加[23],得到分幀加窗后的信號y′(s),計算公式如式(3)所示:

將一段語音Y[D]分幀提取MFCC 特征的流程如算法1 所示。
算法1分幀加窗提取MFCC 流程算法


MFCC 矩陣縱軸的長度由MFCC 特征提取時設定的濾波器個數決定,一般設定為22~26 個。本文通過對比發現,將其取整設定為20 并無明顯性能下降,故最終選擇濾波器個數為20。最終,經過歸一化得到20 像素×63 像素的單通道特征圖。
2.1.2 高斯白噪聲數據增強
由于訓練數據較少,訓練出的模型往往泛化性差,容易過擬合,準確率不高。對原有1 200 條數據進行數據增強發現,傳統的數據增強方法會破壞聲音的連續特征,而高斯白噪聲則均勻疊加在原有音頻上,因此本文采用加入高斯白噪聲作為數據增強方法。此外,由于模型是在有噪聲的環境下進行訓練,因此得到的神經網絡模型具有一定的抗噪性。由于原有數據集的信噪比為35 dB,因此加入信噪比大于35 dB 的噪聲可認為沒有噪聲。所以,在加入高斯白噪聲進行數據增強時,需固定噪聲的信噪比,并使其小于35 dB,如此也便于分析加入不同信噪比與樣本數量的數據增強實驗效果。生成一個標準高斯隨機數較為容易,令該噪聲(設其聲音長度為N)乘以系數k即可得到一個固定信噪比的噪聲。計算語音信號的功率PS和生成的噪聲功率Pn1的計算公式如式(4)~式(5)所示:

給定固定信噪比X,求解k值,假設Pn為需要的信噪比的噪聲功率,則有:

對式(6)進行整理可得:

繼續整理,得到k值如式(8)所示:

高斯白噪聲數據增強過程如圖3 所示,將求出的不同信噪比對應的ki(i=1,2,…,N)乘以標準高斯噪聲,再和純凈音頻中提取的MFCC 特征圖進行線性疊加。由于高斯白噪聲為隨機值,疊加后的特征圖對應像素的值發生了非線性的隨機變化,因此可以當作完全不同的圖片。隨后,將加過噪聲的MFCC 特征圖與純凈MFCC 特征圖一同送入數據集[24]。
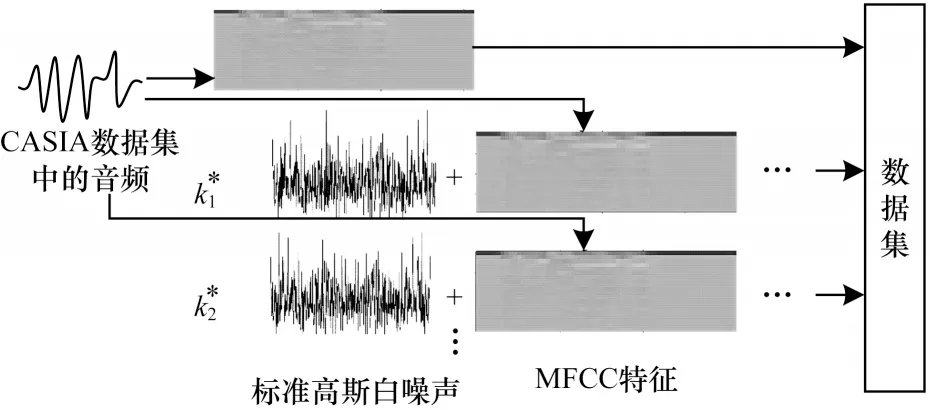
圖3 高斯白噪聲數據增強Fig.3 Gaussian white noise data augmentation
2.2 卷積神經網絡設計
卷積神經網絡一直是研究和應用的熱門技術。不同于傳統的全連接神經網絡,卷積神經網絡在進入全連接層進行標簽的配對之前要先經過若干個卷積層和池化層,并對輸入特征進行壓縮和提取,從而簡化訓練過程。卷積操作可以視作濾波,而完成特征提取的卷積核即為濾波器。直接卷積的計算公式如式(9)所示:
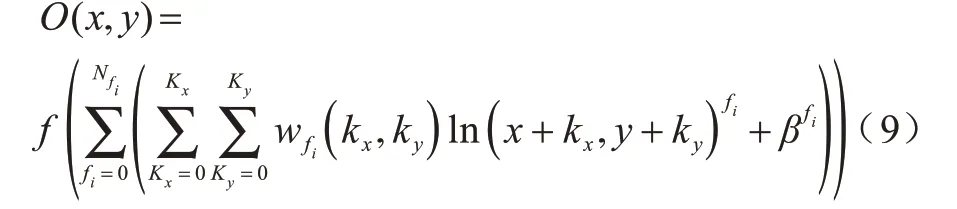
其中:f是非線性激活函數表示偏移值;O(x,y)表示輸入特征圖坐標(x,y)處的值;w(kx,ky)表示卷積核坐標(kx,ky)上的權重值;ln(x+kx,y+ky)表示輸出特征圖坐標(x+kx,y+ky)上的輸入值;kx、ky表示卷積核的尺寸;fi表示第i幅輸入特征圖;Nfi表示輸入特征圖的數目。
池化通常分為最大池化和均值池化,池化的作用是取局部區域內的某個值,將其他值舍棄,從而達到壓縮圖像的目的。本模型采用最大池化,其計算公式如式(10)所示:

其中:fout表示輸出圖像(i,j)位置的值;fin表示輸入圖像中(i,j)位置的值;p表示池化核的尺寸。
對神經網絡來說,理論上通過加深網絡的深度,同時選用較小的卷積核可以取得更好的訓練效果,但隨著卷積神經網絡的發展,3×3 大小的卷積核被驗證為較合適的尺寸,因此得到廣泛使用。本模型采用的卷積方式為二維卷積,卷積核尺寸均采用3×3,池化層采用最大池化,池化核的尺寸也為3×3。但是在卷積核已經很小的前提下,加深網絡深度會導致待訓練參數過多,存在過擬合的風險。
本文設計一種輕量級的Trumpet-6 卷積神經網絡模型,其處理流程如圖4 所示。

圖4 卷積神經網絡處理流程Fig.4 Processing flow of convolution neural network
傳統經典網絡,如Alexnet、MobilenetV2 等由于其本身用于圖像處理,因此存在輸入層卷積核較多、所采用滑動步長較大等特點。例如,Alexnet 的輸入層有96 個卷積核,步長為4,MobilenetV2 的輸入層步長為2,這兩者由于容易造成過擬合,因此均不適用于處理語音信息。但將圖像處理領域的經典神經網絡遷移至語音處理領域已經是常用方法。因此,有必要設計一個語音情感識別領域的網絡。根據語音的特性,在設計之初進行如下改進:1)由于MFCC特征圖尺寸相比圖像處理領域來說較小,因此輸入層選用較少卷積核;2)由于聲音特征具有連續性,因此將輸入層滑動步長設定為1,而后續圖像經過池化層壓縮后,才可以將滑動步長提高為3 來提升訓練效率。為了平衡準確率與訓練效率,將第1 次池化的插入位置選擇在第2 個卷積層之后,并通過實驗進一步確定網絡層數與具體超參數。
將提取到的MFCC 特征圖送入輸入層,卷積神經網絡模型的卷積層一般用于提取淺層特征,將全連接層來提取目標的深層次特征。卷積神經網絡模型的卷積層數初始設置為2,第1 個卷積層作為輸入層,這2 個卷積層均為32 個卷積核,目的是作為特征圖輸入并提取淺層特征。卷積神經網絡進行最大池化后為3 層卷積層,均使用64 個卷積核。隨后再次進入最大池化層進行壓縮,最后一層卷積層利用了128 個卷積核,能夠將之前的特征圖進行高層次提取。輸入的特征圖經過拉直層變為一維圖像后,最后輸入全連接層進行分類,全連接層有6 個神經元,對應6 種情感標簽。
卷積層感受野只與核大小和滑動步長有關,三者間的關系如式(11)所示:

其中:Ri是第i層卷積層的感受野;Ri+1是(i+1)層上的感受野;si是第i層卷積的步長;Ki是第i層卷積核的大小。這樣在卷積核大小已經確定的情況下,在第1 次池化后適當增大滑動步長可以增大感受野和提高訓練效率。另外,將卷積層和池化層均設置為全零填充,從而盡可能還原輸入特征圖的尺寸,保留原有信息。全連接層中所用的分類器是softmax 分類器[25-26]:

其中:oi為全連接層的輸出值;Pi是softmax 分類器的輸出值,共有i個,對應i個標簽的概率,本文中i取6,輸出值[P1,P2,P3,P4,P5,P6]為6 種情感分別對應的概率值,取出其中的最大值對應的情感標簽并輸出,便完成了一次識別。
此外,激活函數全部使用ReLU,將除輸入層外的所有卷積層均加入L2正則化,并以0.2的丟棄比例來緩解過擬合,損失函數使用交叉熵,采用Adam 優化器,學習率設置為0.001。經過計算,模型共有176 550個待訓練參數。網絡具體結構如表1所示。

表1 Trumpet-6 卷積神經網絡結構Table 1 Structure of Trumpet-6 convolutional neural network
3 實驗與結果分析
3.1 實驗條件
本課題的硬件實驗平臺為AMD Ryzen 7 3700x+NVDIA GeForce RTX2070 super,CPU 主頻為3.6 GHz,GPU 顯存為8 GB。使用Python 語言和TensorFlow 2.0的GPU 版本對神經網絡模型進行搭建。
本文在確定改進方向時設計了3 組實驗:第一組研究采樣點大小對訓練時間以及準確率的影響;第二組研究卷積結構對訓練效果的影響;第三組研究添加高斯白噪聲進行數據增強的方法與傳統方法進行數據增強對測試集準確率的影響。
CASIA 漢語情感語料庫由中國科學院自動化所錄制,共包括4 個專業發音人,包含生氣、高興、害怕、悲傷、驚訝和中性6 種情緒。該數據集錄制時采用16 kHz 采樣和16 bit 量化,在信噪比為35 dB 的純凈環境中錄制,本次實驗收集到1 200 條語句,其中包含了50 句相同文本。
對1 200 條的CASIA 數據集進行數據亂序。由于本文中所使用的CASIA 數據集數據量較小,初始為1 200 條,而加入數據增強后最多為4 800 條數據。因此,針對較小數據集(數據量在萬以下),主流的數據集劃分比例為訓練集與測試集7∶3,或訓練集、驗證集、測試集比例為6∶2∶2,其中,驗證集主要用于調節卷積核個數、卷積核大小等超參數。由于本文除第2 個實驗是探究卷積神經網絡結構對測試集準確率的影響外,第1 組和第3 組實驗主要是在同一平臺上進行縱向比較以確定最佳的改進方向,在這個過程中使用驗證集調節超參數無法控制單一變量,因此第1 組和第3 組實驗把數據集劃分為訓練集與測試集7∶3,而第2 組實驗數據集劃分為訓練集、驗證集、測試集6∶2∶2。
3.2 實驗結果
3.2.1 采樣點影響實驗
根據采樣點個數為2 的整數次冪的規則,分別采用了256、512、1 024、2 048、4 096、8 192 個采樣點進行分幀、加窗。僅對原有數據集進行實驗,得到的MFCC特征圖經過在2.2節中提出的Trumpet-6神經網絡識別,統計模型收斂時的迭代輪數,測試集準確率以及平均單個樣本的識別耗時,結果如表2 所示。

表2 采樣點影響實驗的結果Table 2 Result of experiment on the influence of sampling points
通過對比發現,采用256 個采樣點進行分幀的模型收斂速度最慢,約為50 輪,其他5 組相近,均在30~40 輪左右。經過統計,這6 次實驗的單個樣本訓練時間分別約 為310 μs、172 μs、101 μs、63 μs、52 μs、42 μs,可以看出,傳統的選用256 個和512 個采樣點進行分幀的訓練耗時遠大于選用1 024 個以上采樣點的分幀方法。繼續增大分幀時采樣點大小,如將采樣點設置為4 096、8 192,輸入特征圖尺寸會進一步縮小,進而減少訓練時間。但從表2 中可以看出,繼續增大采樣點個數為4 096、8 192,會使模型的準確率嚴重下降,即單幀可容納的采樣點到達了一個上限、同時識別速度提升不大。綜合考慮,選取2 048 個采樣點較合適。相比于傳統256 個采樣點分幀的單個樣本平均識別約310 μs 而言,2 048 采樣點只需63 μs 即可完成一次訓練或識別,處理效率提升了79.7%,準確率僅下降1.1 個百分點。
3.2.2 模型卷積結構實驗
本組實驗采用CASIA 原始數據集1 200 條,分幀采樣點選取2 048,特征圖尺寸為20×63,將數據集比例劃分為訓練集、驗證集、測試集6∶2∶2,來對比卷積層數對測試集準確率的影響。具體實驗方法為:建立3~10 層卷積結構的網絡模型,并通過驗證集調節超參數,找出其中測試集準確率最高的模型,統計測試集準確率和收斂時迭代輪數,模型的訓練結果如表3 所示。

表3 模型卷積結構實驗的結果Table3 Result of model convolution structure experiment
由表3 可知,6 層卷積結構的模型D 是相對而言更為優秀的網絡結構,繼續增加卷積層會使網絡模型變復雜,泛化能力變差,從而導致測試集準確率降低。為得到一個較為簡化的模型結構,將模型D 確定的超參數,如卷積核個數,向下取一個2 的整數次冪。經過調整的模型,迭代輪數為35,測試集準確率為70.2%,將其作為2.2 節提出的Trumpet-6 模型。
3.2.3 數據增強實驗
不加噪聲的MFCC 特征圖與加入信噪比為5 dB高斯白噪聲后的MFCC 特征圖對比如圖5 所示。由圖5 可知,加入噪聲后的MFCC 特征圖的語音特征雖然被噪聲淹沒,但仍保留了一部分肉眼可見的特征。

圖5 無噪聲與5 dB 噪聲的MFCC 特征圖Fig.5 MFCC feature maps of non-noise and 5 dB noise
本組實驗首先對4 種數據增強方法進行了對比,S1~S3 是傳統數據增強方法,S4 為添加高斯白噪聲的數據增強方法。S1組實驗對MFCC特征圖進行旋轉(旋轉角度為順時針旋轉15°);S2 組實驗對特征圖進行隨機平移(水平或豎直平移圖片寬度的0~10%);S3 組實驗對特征圖進行隨機縮放(縮放比例為0~10%);S4 組實驗對原音頻文件加入信噪比為5 dB 的高斯白噪聲。數據增強的擴充量與初始數據集相同,為1 200 條,即總共2 400 條數據,數據增強后的數據集劃分方式采用了與文獻[24]相同的方式,即擴充全部數據集后再將數據集劃分為訓練集與測試集7∶3。訓練結果如表4所示。

表4 數據增強方式對準確率的影響Table 4 Influence of data enhancement methods on accuracy
由表4 可知,高斯白噪聲進行數據增強的測試集準確率明顯好于平移、縮放等傳統數據增強方法。隨后,在原有1 200 條CASIA 數據集的基礎上,分別設置不加高斯白噪聲的1 200 條語音,與加入信噪比為5 dB 的噪聲進行數據增強的2 400 條語音、加入3 dB 和5 dB 噪聲共3 600 條語音和同時加入3 dB、5 dB、10 dB 噪聲的共4 800 條語音進行對比,訓練結果如表5 所示。

表5 高斯白噪聲數據擴充量對準確率的影響Table 5 Influence of Gaussian white noise data expansion on accuracy
由表5 可知,這4 組實驗的模型收斂后,測試集準確率分別約為70.2%、80.8%、90.2%和95.7%。在同時加入3 dB、5 dB、10 dB 噪聲進行數據增強后達到上限,此時共有4 800 條數據,繼續增強數據收效甚微,此時模型的測試集準確率與訓練集準確率基本吻合,有效緩解了過擬合。
3.3 本文方法有效性驗證及與其他方法的對比
使用2 048 采樣點分幀、加窗,輸入圖尺寸大小為20像素×63像素,并對初始1 200條CASIA 數據集加入3 dB、5 dB、10 dB 噪聲進行數據增強,共得到4 800 條數據,使用網絡模型Trumpet-6 作為最終的識別方法。最終在CAISA 數據集上效果如圖6 所示。
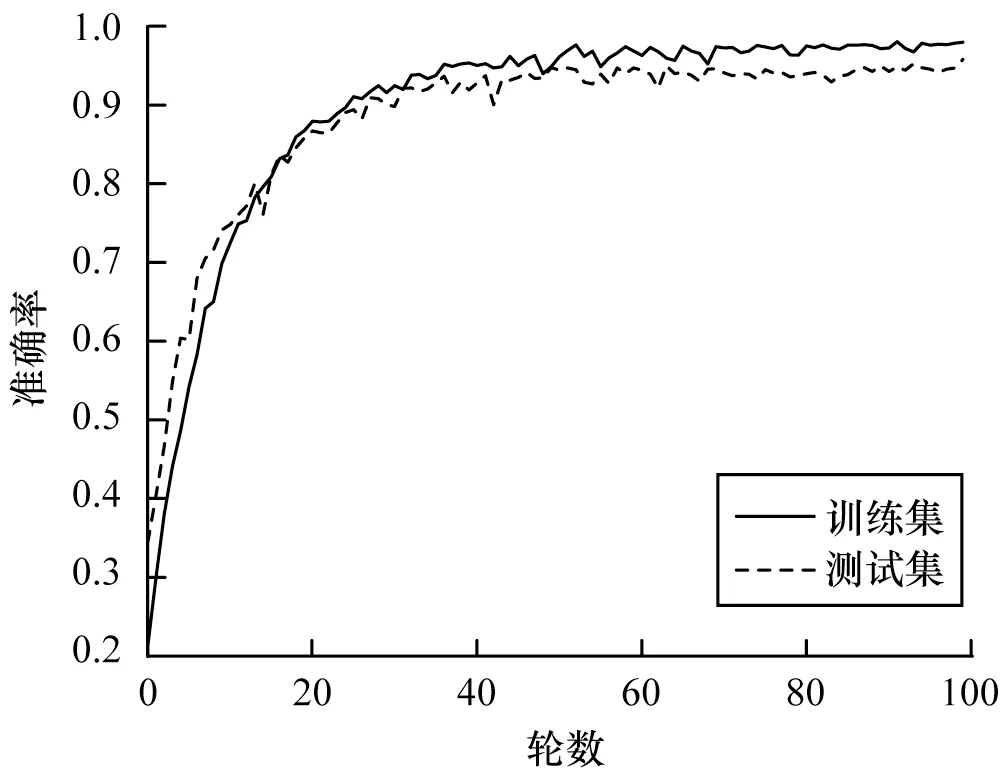
圖6 基于卷積神經網絡的中文語音情感識別結果Fig.6 Chinese speech emotion recognition results based on convolutional neural network
除了與在CAISA 數據集上進行測試外,為進一步驗證本文方法的有效性與泛用性,將本文方法分別在采用本小組錄制的中文語音情感庫與國際上通用的經典語音情感庫上進行實驗,并對比本文與其他方法在遷移至自建數據集和上經典語音情感數據集上的實驗結果。此外,將上述3 種庫混合,進行方法遷移實驗。由于混合庫的效果不易于與其他文獻所提方法效果直接比較,因此將本文方法與文獻所提方法盡量復現并對比,本部分的數據集劃分比例依舊為訓練集與測試集7∶3。
3.3.1 在CASIA 中文語音情感庫下的對比結果
由于復現文獻中的方法存在一定的困難與誤差,因此本節把本文方法與近年來針對CASIA 中文語音情感庫的識別方法,包括文獻[13-16]的結果直接進行對比。其中,文獻[13]為1 200 條數據,訓練集與測試集比例為8∶2,進行20 輪左右收斂;文獻[14]為1 200 條數據,經過數據增強后為3 600 條,訓練集、驗證集、測試集比例為8∶1∶1,未給出其最優方法模型收斂時迭代輪數,但文中模型收斂均在1 000 輪左右;文獻[15]為1 200 條數據,訓練集與測試集比例為9∶1;文獻[16]為7 200 條數據,訓練集、驗證集、測試集比例為6∶2∶2,且未給出模型收斂時迭代輪數,對比結果如表6 所示。

表6 不同方法在CASIA 中文語音情感庫下的效果對比Table6 Effect comparison of different methods in CASIA Chinese speech emotion database %
由表6 可以看出,文獻[13]所提識別方法在模型收斂時的迭代輪數最少且速度最快,但其準確率只有55.8%(文獻[13]中采用的指標為錯誤識別率,為44.2%)。本文所提識別方法的模型收斂速度略低于文獻[13]的方法,為50 輪,高于其他3 種,且準確率最高,達到了95.7%。
3.3.2 遷移至自建情感庫的對比結果
本小組成員共5 人,對中性、生氣、害怕、高興、悲傷5 種情感(CASIA 與EMO-DB 共有的5 種情感),每種錄制20 條,共500 條,建立了自建語音情感庫。錄制采樣率為44.1 kHz,在語音領域內,44.1 kHz的高采樣率不適宜進行機器學習方面的識別,需要經過采樣壓縮為16 kHz,并進行16 bit 的量化。由于語音情感識別方面的機器學習算法和語音特征提取方法種類繁多,且多數不易復現,因此本文在對比不同方法的實驗結果時,選用相對容易復現的深度學習方法,包括文獻[27-29]所提方法。本文方法與參考文獻中所提方法在自建情感庫的實驗對比結果如表7所示。

表7 不同方法在自建數據集下的效果對比Table 7 Effect comparison of different methods in self-built data set %
由表7 可知,本文作為針對中文語音情感識別的方法,在中文自建數據集上也保持了較高的測試集準確率,達到90.4%;文獻[28]所提方法利用了深度殘差神經網絡,有34 層之多,網絡結構復雜度較高,準確率僅次于本文方法且相差無幾,達到了90.1%;文獻[27]所提方法在卷積神經網絡基礎上加入了循環神經網絡,且輸入特征圖為三維特征圖,但準確率只有77.8%;文獻[29]基于循環神經網絡加入了更為復雜的長短期記憶網絡(Long Short-Term Memory,LSTM)算法,測試集準確率為86.3%。
3.3.3 遷移至EMO-DB 情感庫的對比結果
EMO-DB 數據集是由柏林工業大學錄制的經典開源德語情感語音庫,由10 位演員(5 男5 女)對10 個語句(5 長5 短)進行7 種情感(中性、生氣、害怕、高興、悲傷、厭惡、無聊)的模擬得到,共包含535 句語料,采樣率為16 kHz,進行16 bit 量化。本文方法在EMO-DB 數據集的實驗結果與文獻中的方法的結果對比如表8 所示。

表8 不同方法在EMO-DB 數據集下的效果對比Table 8 Effect comparison of different methods in EMO-DB data set %
由表8 可知,本文方法在德語的EMO-DB 數據集上的表現一般,測試集率為83.4%,僅高于文獻[27]利用三維卷積循環神經網絡的方法,與文獻[31]僅利用openSMILE 提取語音特征的方法相近。文獻[30]使用支持向量機分類器和深度卷積神經網絡兩種機器學習算法融合后進行的分類最準確,測試集準確率為95.1%。但由于文獻[30]方法為兩種機器學習算法的融合,參數眾多,尤其是支持向量機的詳細參數未給出,因此不容易進行復現,僅在本節利用文獻中的結論與本文方法在EMO-DB 數據集上的實驗結果進行了對比。文獻[28]利用深度卷積神經網絡ResNet34 的識別方法由于原本就是在EMO-DB 語音情感庫訓練得到的參數,因此得到了比3.3.2 節更高的識別準確率,為92.4%。
3.3.4 遷移至混合語音情感數據集的對比結果
將CAISA 數據集與自建語音情感庫進行混合,之后再加入EMO-DB 經典庫進行混合(混合時選取共有的中性、悲傷、害怕、高興、生氣5 種情感),分別通過實驗驗證本文方法在同語言下不同語料庫中的效果,和不同語言、不同語料庫中的效果,本文方法與參考文獻中的方法準確率如表9和表10 所示。

表9 不同方法在CASIA+自建數據集下的效果對比Table 9 Effect comparison of different methods in CASIA+self-built data set %

表10 不同方法在CASIA+自建數據集+EMO-DB 數據集下的效果對比Table 10 Effect comparison of different methods in CASIA+self-built data set+EMO-DB data set %
由表9 可知,本文方法在CASIA 數據集與自建數據集進行混合的中文跨語料庫中取得了較好的效果,但由于混合庫中包含并非專業人錄制的語音情感,因此總體結果不如在CASIA 數據集上理想,為93.3%。而通過表10 可知,加入EMO-DB 德語語音情感庫后,識別效果有了一定程度的下降,為88.7%,但因為跨語言、跨語料庫實驗的數據集中,德語樣本只占了大約1/4,所以仍舊能保持較高的識別準確率。從表9 和表10 可以看出,將文獻[28]與文獻[29]所提的兩種深度學習方法直接遷移過來并沒有對混合庫進行參數的調節,所以與在EMO-DB 數據集上的結果相比有所下降。但由于模型本身較復雜,參數更多,因此針對不同情況的處理結果穩定性較強。相比之下,文獻[27]所提方法在兩種混合庫中的效果依然較差。
3.3.5 對比實驗總結
通過3.3.2 節~3.3.4 節的遷移實驗可知,文獻[28]與文獻[29]的方法在整個遷移實驗過程中結果均比較穩定,其中文獻[28]方法在各個實驗中表現較好,但由于其采用了ResNet34 進行遷移訓練,因此網絡模型比較復雜,參數過多,不適宜針對性地完成某些任務。而文獻[27]與文獻[29]的方法在卷積神經網絡基礎上加入了循環神經網絡以及LSTM 算法,并沒有取得十分理想的效果。這可能是由于本次實驗所采用數據集的實驗樣本均為時長2~3 s 的短語音,并沒有發揮出循環神經網絡在時序預測方面的優勢。文獻[28,30]以及本文方法的實驗結果充分說明,在較短的時間跨度內使用卷積神經網絡的方法進行語音情感識別可行,且效果較好。
本文方法在處理中文語音情感識別時具有較高的識別準確率,但由于本小組錄制人員非專業,情感不飽滿,所以導致由CASIA 庫預訓練后遷移過來的Trumpet-6 模型并未達到和3.3.1 節同樣的效果,而在混合兩種中文語音情感庫后,訓練集變大,準確率有了一定的提升。此外,通過遷移至EMO-DB 庫(德語)的實驗結果與其他文獻所提方法的實驗結果對比后發現,本文方法在處理跨語言的語音情感識別方面存在不足,在混合庫中文樣本較多的情況下,相比于純德語有一定提高。雖然本文方法不如文獻[28]方法在各種情況下的識別結果穩定性強,但作為一種基于CASIA 數據集訓練而來的方法,針對于中文語音情感識別的方法具有一定的優勢,具體對比結果如表11 所示。此外,相比于ResNet34 深度殘差神經網絡而言,本文所改進的語音處理方法以及所設計的Trumpet-6 卷積神經網絡結構較簡單。

表11 文獻[28]方法與本文方法的對比Table 11 Comparison between the method in reference[28]and in this paper
4 結束語
針對中文語音情感識別效率和準確率低的問題,本文提出一種新型中文語音情感識別方法。通過在MFCC 特征提取過程中提高采樣點個數,并在改進語音處理方法的基礎上使用高斯白噪聲對數據集進行數據增強處理,從而提高處理效率及緩解訓練過程中的過擬合現象。通過建立Trumpet-6 卷積神經網絡模型并用于中文語音情感識別,提高識別準確率。在CASIA 數據集上的實驗結果表明,本文方法的識別準確率達95.7%,優于Lenet-5、RNN、LSTM 等傳統方法。本文網絡模型采用2 048 個采樣點,僅176 550 個待訓練參數,與采用DCNN 的ResNet34 和循環神經網絡模型相比,其結構較為優化,處理效率得到大幅提高。但經過遷移至其他語料庫訓練后發現,本文方法在處理不同語言、跨語料庫的情感識別時準確率有待提高,且網絡模型尚不能精確提取情感信息并舍去不必要的語言習慣。下一步將進行跨語料庫的泛化性研究,并豐富開源語音情感庫,促進語音情感識別領域的發展。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
