基于有向圖模型的旅游領域命名實體識別
2022-02-24 05:07:08崔麗平古麗拉阿東別克王智悅
計算機工程 2022年2期
崔麗平,古麗拉·阿東別克,王智悅
(1.新疆大學 信息科學與工程學院,烏魯木齊 830046;2.新疆多語種信息技術重點實驗室,烏魯木齊 830046;3.國家語言資源監測與研究少數民族語言中心哈薩克和柯爾克孜語文基地,烏魯木齊 830046)
0 概述
隨著信息化建設的加快,旅游逐漸成為人們休閑放松的重要方式。在旅游過程中,游客利用智能化的應用軟件解決出行問題,例如景點的智能線路推薦、景區的智能問答系統實現等,旅游領域的命名實體識別(Named Entity Recognition,NER)作為智能化服務,逐漸引起研究人員的關注。
NER 是自然語言處理的一項研究任務,是信息檢索、問答系統、機器翻譯等諸多任務的基礎。以往的NER 任務大多針對通用領域,近年來,NER 被應用在某些特定領域上,文獻[1]在生物醫學領域中利用支持向量機(Support Vector Machine,SVM)進行蛋白質、基因、核糖核酸等實體識別;文獻[2]在社交媒體領域中對微博中的實體進行研究;文獻[3]對電子病歷中的實體進行研究。此外,研究人員對一些實體(如化學實體[4]、古籍文本中的人名[5]等)研究較少。
旅游領域的NER 研究相對較少。文獻[6]提出基于隱馬爾科夫模型(Hidden Markov Model,HMM)的旅游景點識別方法,該方法首次在旅游領域上進行NER 任務,但未充分考慮到上下文信息,解決一詞多義的問題表現欠佳。因為很多實體在不同的語境中會代表不同的意思,例如“玉門關”在其他的文本中指的是地名,在旅游文本中指的是旅游景點玉門關。文獻[7]提出使用層疊條件隨機場(Conditional Random Field,CRF)識別景點名的方法,該方法過于依賴人工特征的建立,而且規則制定要耗費大量的人力,以致于不能廣泛使用。文獻[8]提出一種基于CNN-BiLSTM-CRF 的網絡模型,避免了人工特征的構建,但該方法是基于字進行識別,未能充分利用詞典信息。對于特定領域的NER 任務,詞典是十分重要的外部資源,尤其是旅游文本中存在許多較長的景點名,例如阿爾金山自然保護區、巴音布魯克天鵝湖等,可以利用詞典獲取這類詞匯信息進而提高NER 的準確率。
本文提出一種有向圖神經網絡模型用于旅游領域中的命名實體識別。將預訓練詞向量通過具有多個卷積核的卷積神經網絡(Convolutional Neural Network,CNN)提取字特征,基于詞典構建每個句子的有向圖,生成對應的鄰接矩陣,通過邊的連接融合詞特征與字特征,將詞向量和鄰接矩陣輸入圖神經網絡進行全局語義信息的提取,并引入CRF 得到最優序列。
1 相關工作
1.1 命名實體識別
NER 主要是基于規則和詞典、基于統計機器學習、基于深度學習的方法。基于規則和詞典的方法需要考慮數據的結構和特點,在特定的語料上取得較高的識別效果,但是依賴于大量規則的制定,手工編寫規則又耗費時間和精力。基于統計機器學習的方法具有較好的移植性,對未登錄詞也具有較高的識別效果。常用的機 器學習模型有SVM[9]、HMM[10]、條件隨機場[11]、最大熵(Maximum Entropy,ME)[12]等,這些方法都被成功地用于進行命名實體的序列化標注,然而都需要從文本中選擇對該項任務有影響的各種特征,并將這些特征加入到詞向量中,所以對語料庫的依賴性很高。
隨著深度學習在圖像和語音領域的廣泛應用,深度學習的眾多方法也被應用在自然語言處理任務中。文獻[13]提出基于神經網絡的NER 方法,該方法利用具有固定大小的窗口在字符序列上滑動以提取特征。由于窗口的限制,該方法不能考慮到長距離字符之間的有效信息。循環神經網絡(Recurrent Neural Network,RNN)的優勢在于它通過記憶單元存儲序列信息,但是在實際的應用中,RNN 的記憶功能會隨著距離的變長而衰減,從而喪失學習遠距離信息的能力。文獻[14]基于RNN 提出長短時記憶(Long Short Term Memory,LSTM)神經網絡,該方法利用門結構解決梯度消失的問題,然而3 個門單元增加了計算量。門循環單元(Gated Recurrent Unit,GRU)[15]只用了2 個門保存和更新信息,能夠減少訓練參數,縮短訓練的時間。由于單向的RNN 不能滿足NER 任務的需求,文獻[16]提出雙向LSTM模型(BiLSTM)用于序列標注任務,通過不同方向充分學習上下文特征。文獻[17]構建BiLSTM 與CRF結合的模型,用CRF 規范實體標簽的順序。因此,BiLSTM+CRF結構成為NER 任務中的主流模型[18-19]。
文獻[20]提出一種基于注意力機制的機器翻譯模型,摒棄之前傳統的Encoder-Decoder 模型結合RNN 或CNN 的固有模式,使用完全基于注意力機制的方式。由于Transformer 有強大的并行計算能力和長距離特征捕獲能力,因此在機器翻譯、預訓練語言模型等語言理解任務中表現出色,逐漸取代RNN 結構成為提取特征的主流模型。在NER 任務上,基于自注意力的Transformer 編碼器相較于LSTM 的效果較差,雖然自注意力可以進一步獲得字詞之間的關系,卻無法捕捉字詞間的順序關系,并且經過自注意力計算后相對位置信息的特性會丟失。位置信息的丟失和方向信息的缺失影響NER 的效果[21]。
在英文的NER 任務上主要使用基于詞的方法,但是在中文NER 任務中,由于中文存在嚴重的邊界模糊現象,基于詞的方法會產生歧義,進而影響NER結果。基于字的方法比基于詞的方法更適合中文NER 任務[22-23],然而基于字的方法存在無法提取詞匯信息的缺陷,這些潛在詞的信息對NER 任務十分重要。因此,構造字詞結合訓練的方法[24-26]成為研究熱點。
文獻[27]提出Lattice LSTM 結構,使用詞典動態將字詞信息送入LSTM 結構中進行計算,在多個數據集上取得了最好成績。RNN 的鏈式結構和缺乏全局語義的特點決定了基于RNN 的模型容易產生歧義,Lattice LSTM 結構如圖1 所示。“市長”和“長江”兩個詞共同包含“長”字,RNN 會嚴格按照字和詞匯出現的順序進行信息傳遞,因此,“長”會優先被劃分到左邊的“市長”一詞中[28],這顯然是錯誤的。針對這個問題,本文使用圖神經網絡進行信息傳遞,在每次計算時,每個節點都會同時獲得與其相連節點的信息,以削弱字符語序和匹配詞序對識別的影響。
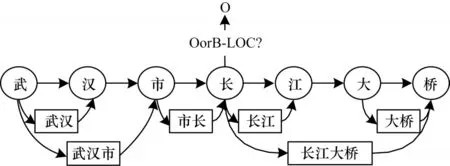
圖1 Lattice LSTM 結構Fig.1 Structure of Lattice LSTM
1.2 圖神經網絡
圖是由一系列對象(節點)和關系類型(邊)組成的結構化數據。文獻[29]提出圖神經網絡的概念。文獻[30]提出基于譜圖論的一種圖卷積的變體。圖神經網絡 包括圖注 意力網絡[31](Graph Attention Network,GAT)、圖生成網絡[32]等。圖神經網絡在自然語言處理領域的應用逐漸成為研究熱點,文獻[33]提出將圖卷積神經網絡(GCN)用于文本分類,文獻[34]利用依存句法分析構建圖神經網絡并用于關系抽取。
2 L-CGNN 模型
L-CGNN 模型的整體結構分為特征表示層、GGNN 層、CRF 層3 個部分。特征表示層的主要任務有:1)獲取預訓練詞向量并使用具有不同卷積核的CNN 提取局部特征,充分獲得每個字的局部特征;2)通過詞典匹配句子中的詞匯信息,構建句子的有向圖結構得到相應的鄰接矩陣用于表示字與詞匯的關系。GGNN 層接收特征表示層傳入的詞向量矩陣和鄰接矩陣,動態融合字詞信息獲得全局的語義表示。通過CRF 層進行解碼獲得最優標簽序列。L-CGNN 模型結構如圖2 所示。
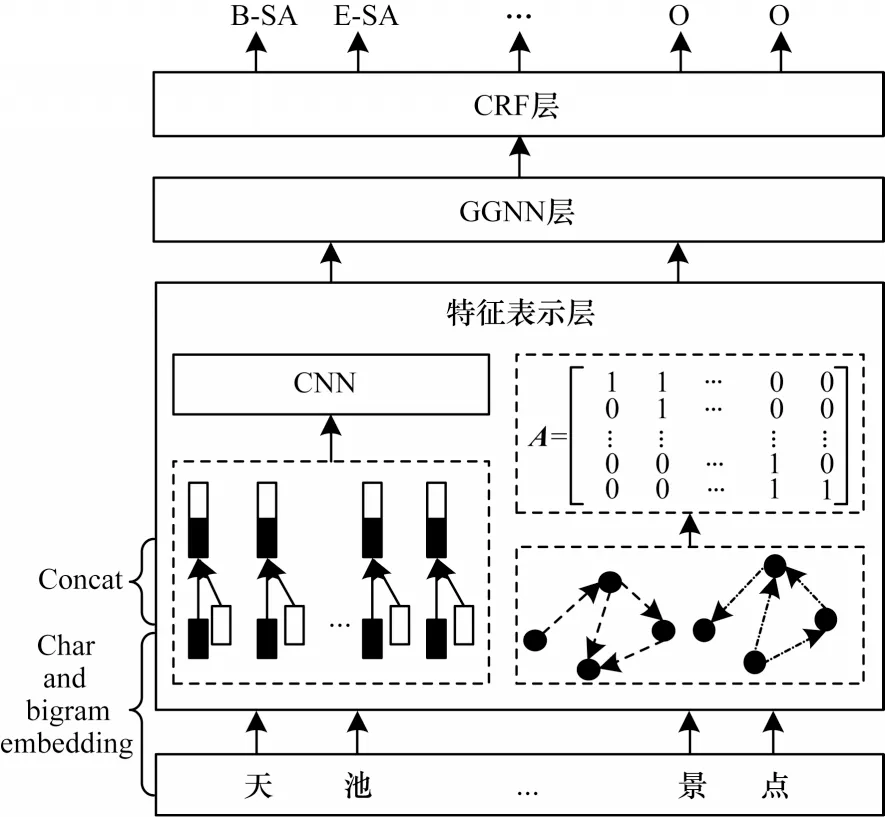
圖2 L-CGNN 模型結構Fig.2 Structure of L-CGNN model
2.1 特征表示層
特征表示層首先對文本進行詞向量表示,然后構建文本的圖結構。
1)詞向量
神經網絡的輸入是向量矩陣,因此先將字轉換成向量矩陣形式。詞向量給定包含n個字的句子S={c1,c2,…,cn},其中ci是第i個字,每個字通過查詢預訓練字向量表,轉換為基于字的詞向量,如式(1)所示:

其中:Ec為預訓練詞向量表。通過引入bigram 特征后得到的詞向量是由基于字的向量、前向bigram 詞向量、后向bigram 詞向量3 個部分組成,以提高NER效果[35-36]。加入bigram 的詞向量如式(2)所示:

其中:Eb為預先訓練的bigram 向量矩陣。因為旅游文本的實體名通常較長,并且嵌套現象嚴重,字向量和bigram 向量并不能很好表示局部信息。例如天山大峽谷是新疆著名景點,對于山字,除了字向量特征外,只能獲取到天山和山天的信息,導致天山可能被當作單獨的一個景點名被識別,然而這里的天山大峽谷是一個完整的景點名,需要更多的信息輔助識別。
卷積神經網絡逐漸被用于自然語言任務中提取局部特征。CNN 結構包含卷積層、激活層、池化層,由于池化層會削弱位置特征的表達,而位置特征對于序列標注任務十分重要,所以本文沒有使用池化操作,而是使用3 個不同大小的卷積核提取特征,對卷積核進行填充操作以獲得相同維度的表示。3 個卷積核的大小為k×w,其中k依次取1、3、5,對應w依次取d、d+2、d+4,d為詞向量xi的維度,局部特征提取流程如圖3 所示。
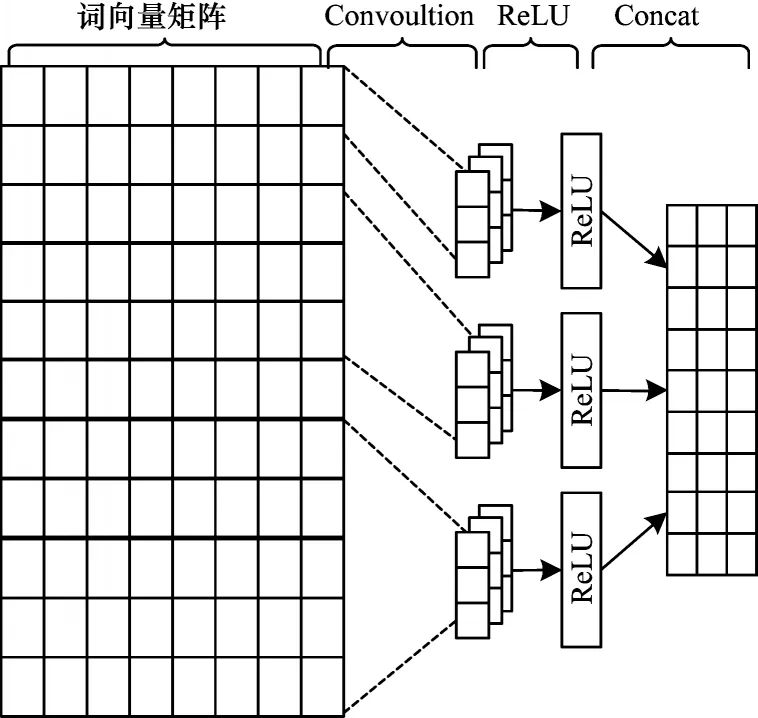
圖3 局部特征提取流程Fig.3 Extraction procedure of local feature
局部特征的提取如式(3)、式(4)所示:
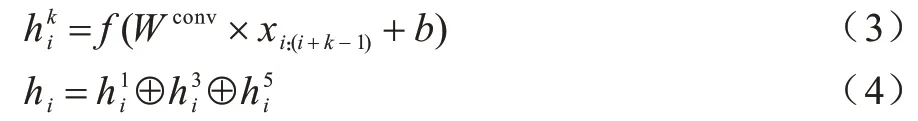
其中:Wconv∈?k×w;f為線性修正單元(ReLU);b為偏置項,將不同卷積核提取的局部特征拼接,得到最終的特征表示。
2)文本圖結構
對于一個有n個節點的圖,文本圖結構可以用形狀為n×n的鄰接矩陣表示。本文中圖結構的構建主要分為兩個步驟。給定包含n個漢字的句子S={c1,c2,…,cn},將句子中每個字作為圖的節點。首先連接所有相鄰的節點,由于信息傳遞的方向性對于序列標注任務具有重要意義,因此在句子的第i個字和第i+1 個字之間(ci,ci+1之間)都連接2 條方向相反的邊。其次連接詞匯邊,若i和j是第i個字從字典中匹配到詞的開始節點和結束節點,本文在這2 個節點之間連 接2 條方向相反的 邊,即 令Ai,j=1,Aj,i=1。字詞結合的有向圖如圖4 所示。

圖4 字詞結合的有向圖Fig.4 Directed graph containing word-character
從圖4 可以看出,如果一個節點在字典中匹配到詞匯數不止一個,則該節點和與之構成詞匯的所有節點之間都存在相應的邊,這樣在后續的傳遞過程中可以同時學習所有詞匯與字的信息,有效消除字或詞匯固有序列的影響。
2.2 基于門控機制圖神經網絡
門控圖神經網絡(GGNN)是一種基于GRU 的經典空間域消息傳遞模型[37],與GCN 等其他圖神經結構相比,GGNN 在捕捉長距離依賴方面優于GCN,更適合于中文的NER 任務。本文將特征表示層得到的詞向量和鄰接矩陣傳入GGNN 進行上下文語義學習。信息傳遞過程如式(5)~式(10)所示:
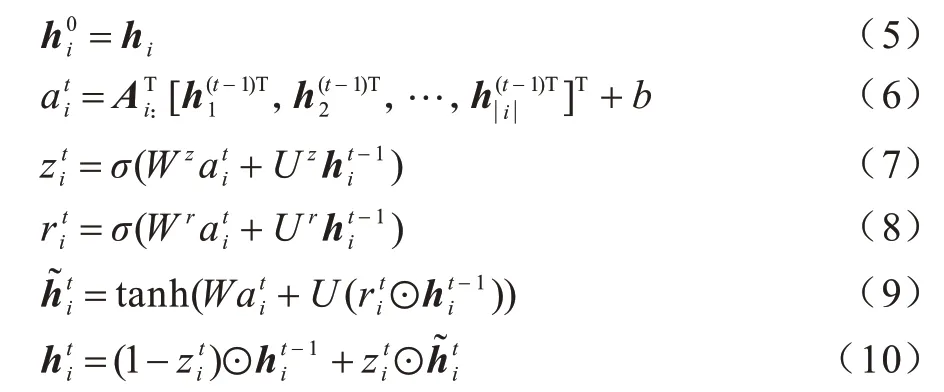
2.3 條件隨機場層
條件隨機模型可以看成是一個無向圖模型或馬爾科夫隨機場,用于學習標簽的約束,解決標簽偏置問題。對于給定的觀察列,通過計算整個標記序列的聯合概率的方法獲得最優標記序列。隨機變量X={x1,x2,…,xn} 表示觀察序列,隨機變量Y={y1,y2,…,yn}表示相應的標記序列,P(Y|X)表示在給定X的條件下Y的條件概率分布,則CRF 計算如式(11)所示:

其中:Y(x)為所有可能的標簽序列;f(yt-1,yt,x)用于計算yt-1到yt的轉移分數和yt的分數。最后使得P(y|x)分數最大的標記序列y,即句子對應的實體標簽序列如式(12)所示:

3 實驗
3.1 數據集
本文實驗的數據集包括旅游數據集和簡歷數據集。
Beats1作為一個綜合性的音樂信息傳播平臺,將音樂的電臺傳播和網絡傳播的特點綜合在一起,形成了具有實時性、主動性和社交性的全球網絡音樂電臺,加之自身運營平臺的大眾化優勢、傳播內容的專業化和覆蓋范圍的全球化,使其具備了成為世界性音樂電臺的基本條件。
1)旅游數據集,目前還沒有公認度較高的旅游領域數據集,本文從去哪兒網、攜程、馬蜂窩等旅游網站收集有關新疆的旅游攻略,經過去除空白行、空格、非文本相關內容等預處理操作,得到旅游領域文本1 200 余篇。旅游數據集使用NLTK 工具對預處理后的語料進行半自動化標注,之后進行人工校對、標注,構建用于旅游領域實體識別的訓練集、評估集和測試集,并通過高德地圖旅游景點數據和旅游網站檢索構造旅游景點詞典。
針對旅游領域實體類型的定義,本文參考文獻[7]的分類標準,將旅游領域實體分為地名、景點名、特色美食3 大類。考慮到新疆地域的特點,本文新增了人名、民族2 種實體類型,采用BIOES 標注體系進行實體標注,例如天山大峽谷位于烏魯木齊縣境內,按照采用的標注體系可以標記為“天/B-SA 山/I-SA 大/I-SA 峽/I-SA 谷/E-SA 位/O 于/O 烏/B-LOC魯/I-LOC 木/I-LOC 齊/I-LOC 縣/E-LOC 境/O 內/O”。旅游數據集訓練集合計4 176,驗證集合計541,測試集合計540。旅游數據集實體信息如表1 所示。
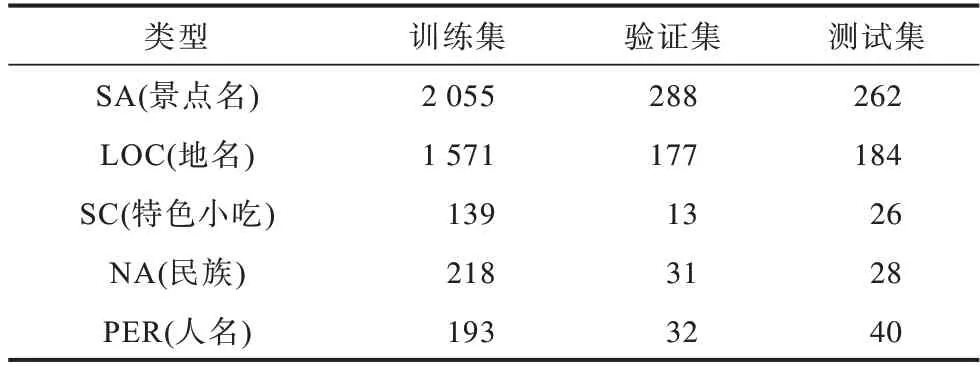
表1 旅游數據集實體信息Table 1 Entities information of tourism dataset
2)簡歷數據集,文獻[27]提出該數據集共有CONT(country)、EDU(educational institution)、LOC、PER、ORG、PRO(profession)、RACE(ethics background)和TITLE(job title)8 種不同的實體類型。
旅游數據集和簡歷數據集的數據統計如表2所示。

表2 旅游數據集和簡歷數據集的數據統計Table 2 Data statistics of tourism and resume datasets
實驗使用的預訓練詞向量表來源于文獻[38],通用的詞典來源于文獻[27],該字典包含704.4×103個詞,其中單個字有5.7×103個,2個字構成的詞有291.5×103個,3 個字構成的詞有278.1×103個,其他129.1×103個。
3.2 模型對比
為驗證模型的有效性,本文使用現有的應用于旅游領域NER 任務的機器學習方法和主流的深度學習模型進行對比。
1)HMM 模型[6],以HMM 算法為原理,用于旅游領域NER 任務;
3)BiLSTM+CRF 模型是NER 任務的經典模型;
4)BiLSTM+CRF(融 合bigram)模型為驗 證bigram 對NER 任務的作用,設計包含bigram 特征的BiLSTM+CRF 模型進行對比分析;
5)Transformer+CRF 模型[21],Transformer 具有強大的特征提取能力,在很多的自然語言處理任務中逐漸取代RNN 模型,所以本文加入該模型的對比;
6)ID-CNN+CRF 模型[24],膨脹卷積、空洞卷積主要是通過擴大感受域的方法獲得更廣泛的序列信息,在英文NER 任務上曾取得最佳成績;
7)Lattice LSTM 模型[27],該模型是字詞結合訓練的代表性方法,創造性地將字符和詞匯通過網格的方法融合在一起,并且在MSRA、Weibo、OntoNotes4、Resume 這4 個數據集上取得最好成績;
8)Bert+CRF 模型,Bert 作為一種預訓練模型,在自然語言處理的多項任務中逐漸成為主流模型。
3.3 實驗環境與參數設置
本文模型使用的GPU 為GeForce GTX 1080Ti,操作系統為Ubuntu18.04,編程語言為Python3.6,框架為PyTorch 1.1.0。為實體識別算法的一致性,本文設置初始化參數,預訓練詞向量維度為300,GGNN 神經元個數為200,丟碼率為0.5,初始學習率為0.001,衰減率為0.05。
3.4 評價指標
評價指標采用準確率(P)、召回率(R)和F1 值,如式(13)、式(14)所示:
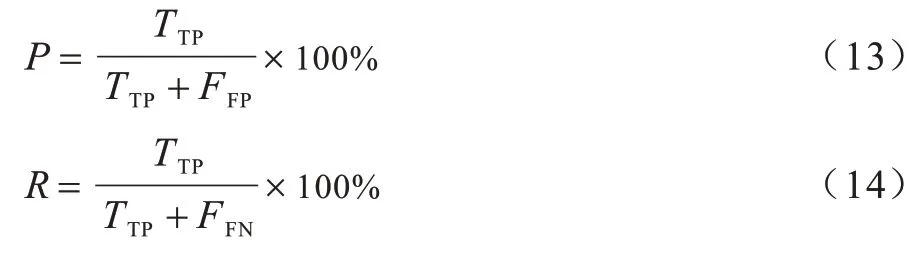
其中:TTP為正確識別的實體個數;FFP為識別不相關的實體個數;FFN為數據集中存在且未被識別出來的實體個數。
通常精確率和召回率的數值越高,代表實驗的效果好。一般精確率和召回率會出現矛盾的情況,即精確率越高,召回率越低。F1 值綜合考量兩者的加權調和平均值,F1 值如式(15)所示:

3.5 實驗結果分析
在旅游領域NER 數據集上,本文選擇HMM、CRF、BiLSTM+CRF、BiLSTM+CRF(融合bigram)、Transformer+CRF、ID-CNN+CRF、Lattice LSTM、Bert+CRF 等模型進行實驗。不同模型的實驗結果對比如表3 所示,*Dic 為自建詞典。
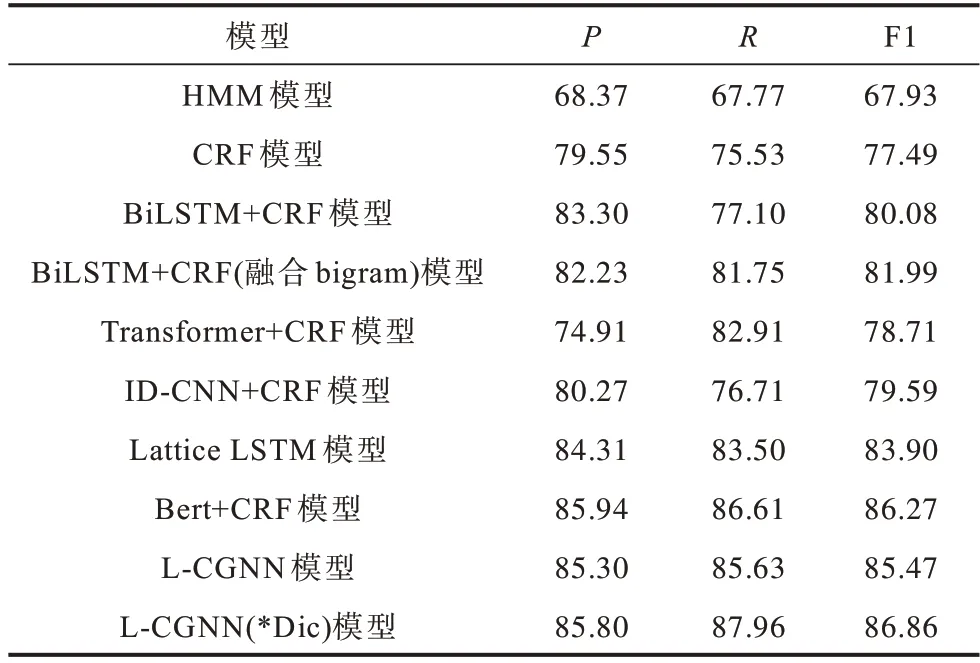
表3 在旅游數據集上不同模型的實驗結果對比Table 3 Experimental results comparison among different models on tourism dataset %
從表3 可以看出,HMM 和CRF 模型在旅游領域NER 任務上的P、R、F1 數值都低于其他深度學習模型,HMM 模型僅依賴于當前狀態和對應的觀察對象,序列標注問題不僅與單個詞相關,還與觀察序列的長度、單詞的上下文等相關。CRF 模型解決了標注偏置問題,識別效果相較于HMM 模型有很大程度的提高。由于CRF 模型不能充分捕捉上下文語義信息,因此在不規范的旅游文本上識別效果不佳。
與ID-CNN+CRF模型相比,BiLSTM+CRF模型的識別效果較優,BiLSTM 模型能夠獲得長距離依賴關系,加強對語義的理解,ID-CNN 模型雖然通過擴大感受域的方法加強距離關系的捕捉,但仍存在不足。BiLSTM+CRF 模型融合bigram 特征后,對實體識別的效果略有提升,表明加入bigram 特征可以提高NER 效果。
對比Transformer+CRF 與BiLSTM+CRF 模型,Transformer+CRF 模型在命名實體識別效果上低于BiLSTM+CRF模型。Transformer在方向性、相對位置、稀疏性方面不適合NER 任務。雖然Transformer對位置信息進行編碼,但在NER 任務上,效果仍然不理想。
Lattice LSTM 模型通過字典的方式融合詞匯信息與字符信息以提升NER 效果,由于其嚴格的序列學習特性,每次都會按照匹配詞出現的順序學習,因此會出現歧義現象。Lattice LSTM 模型實驗效果相較于L-CGNN 模型較差。
Bert+CRF 模型在該任務上的結果優于Lattice LSTM 模型。Bert 利用Transformer 編碼器提高特征提取能力,獲得充分的上下文信息。對于旅游領域,詞典是非常重要的外部資源,對于NER 等任務具有十分重要的意義。因此,L-CGNN(*Dic)模型在旅游數據集上識別效果優于Bert+CRF 模型。
本文提出L-CGNN 模型通過詞典構建有向圖結構,利用圖神經網絡獲得語義信息,不僅融合字符與詞匯信息,還可以利用圖特殊的結構進行傳遞。在每次計算時,L-CGNN 模型同時將節點匹配到與所有詞匯信息相融合,從而減少詞序導致的歧義現象。
為驗證L-CGNN 模型解決匹配詞先后順序對NER 效果的影響,本文在公開的簡歷數據集上進行實驗,實驗結果如表4 所示。
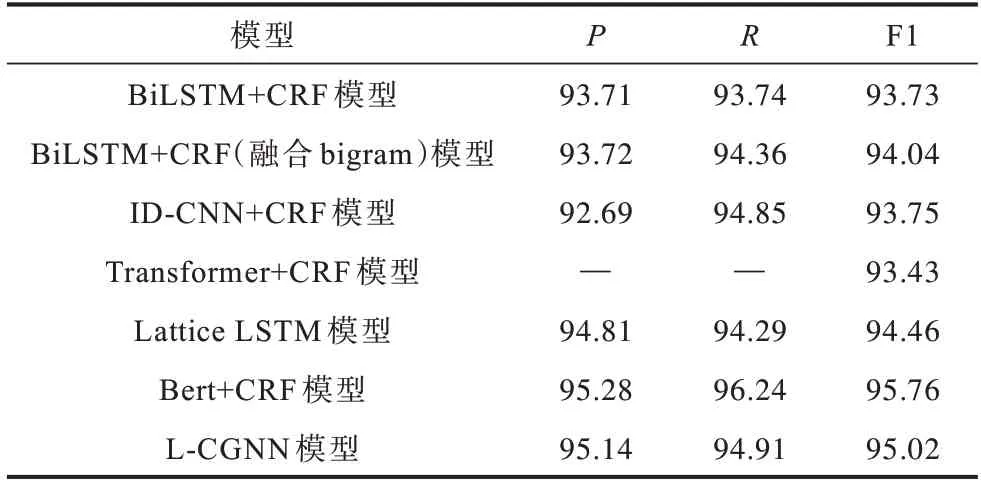
表4 在簡歷數據集上不同模型的實驗結果對比Table 4 Experimental results comparison among different models on resume dataset %
從表4 可以看出,Transformer+CRF 中的P、R沒有公布,所以未能獲取。與其他模型(除Bert+CRF模型外)相比,L-CGNN 模型在P、R、F1 值上的分數較高。本文模型略低于Bert+CRF 模型,主要是因為有向圖結果依賴于字典的質量,通用的詞典質量低于專有領域詞典,未能取得與旅游領域一樣高于Bert+CRF 模型的數值。這組實驗進一步表明L-CGNN 模型具有一定的泛化能力。
3.6 消融實驗
為探討不同特征對實驗結果的影響,本文分別去除某些特征進行命名實體的識別,實驗結果如表5所示。W/O 代表去除該特征,例如W/O lexicon 代表去除字典信息。
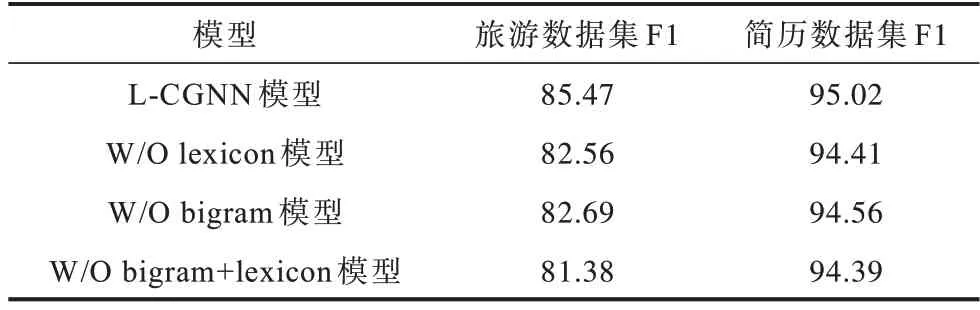
表5 不同特征對實驗結果的影響Table 5 Influence of different features on experimental results %
從表5 可以看出,在兩個數據集上,如果去除字典特征,最終的識別效果較差。同樣的,在去除bigram 特征的情況下,模型的識別效果也會被削弱。同時去除字典和bigram 兩個特征后,F1 值有了很大程度降低,說明加入的特征能夠改善最終的識別效果。
3.7 收斂速率與資源消耗對比
為進一步說明本文模型的性能,本文對比BiLSTM+CRF、Lattice LSTM 和L-CGNN 這3 種模型的收斂速度。不同模型的收斂曲線對比如圖5所示。
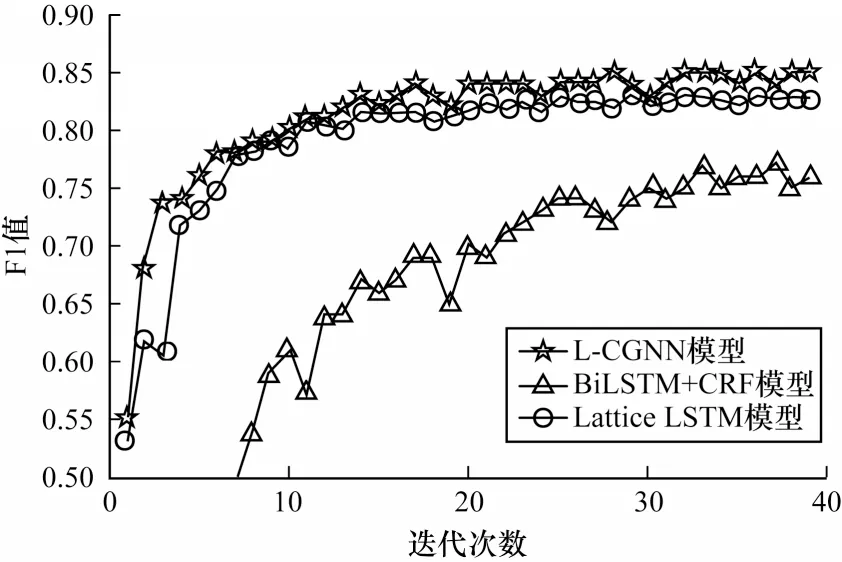
圖5 不同模型的收斂曲線對比Fig.5 Convergence curves comparison among different models
從圖5 可以看出,L-CGNN 模型的收斂速度優于其他模型。BiLSTM+CRF 模型通過雙向LSTM 學習,使得信息更新較慢,并且沒有包含任何詞匯特征,因此,識別速率提升較慢。Lattice LSTM 和L-CGNN 模型都包含字典外部信息,識別效果相對較好。在一段時間后,L-CGNN 模型識別效果明顯優于Lattice LSTM 模型,說明本文模型在融合詞匯方面具有較優的效果。
在資源消耗方面,本文從訓練時間上分別對HMM、CRF、BiLSTM+CRF、Lattice LSTM、L-CGNN等模型進行對比實驗,結果如表6 所示。

表6 在旅游數據集上不同模型的訓練時間對比Table 6 Training time comparison among different models on tourism dataset s
從表6 可以看出,HMM 和CRF 模型是基于機器學習方法,所以訓練速度較快,但識別效果欠佳。相比BiLSTM+CRF 模型,由于L-CGNN 模型構建鄰接矩陣,因此在訓練上的時間消耗略大。對比融合詞典的Lattice LSTM 模型,L-CGNN 模型的時間消耗較低,且具有最優的識別效果。
4 結束語
針對旅游領域的命名實體識別任務,本文提出基于字典構建文本的有向圖結構模型,通過卷積神經網絡提取字特征,利用詞典構建句子的有向圖,生成對應的鄰接矩陣,并將包含局部特征的詞向量和鄰接矩陣輸入圖神經網絡中,引入條件隨機場得到最優的標記序列。實驗結果表明,相比Lattice LSTM、ID-CNN+CRF、CRF 等模型,本文模型具有較高的識別準確率。后續將研究更有效的圖神經網絡,用于命名實體識別,進一步提高實體識別準確率。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
中外會展(2014年4期)2014-11-27 07:46:46
數學大王·低年級(2014年7期)2014-08-11 16:36:44
河南科技(2014年23期)2014-02-27 14:19:15
海外英語(2013年8期)2013-11-22 09:16:04
祝您健康(1987年3期)1987-12-30 09:52:32
