基于去中心化索引的IPFS數(shù)據(jù)獲取方法研究
2022-02-24 12:32:12石秋娥
計(jì)算機(jī)工程與應(yīng)用 2022年3期
石秋娥,周 喜,王 軼
1.中國(guó)科學(xué)院 新疆理化技術(shù)研究所,烏魯木齊 830011
2.中國(guó)科學(xué)院大學(xué),北京 100049
3.中國(guó)科學(xué)院 新疆理化技術(shù)研究所 新疆民族語(yǔ)音語(yǔ)言信息處理實(shí)驗(yàn)室,烏魯木齊 830011
隨著計(jì)算機(jī)技術(shù)的發(fā)展,數(shù)據(jù)的規(guī)模量級(jí)也不斷提高,去中心化數(shù)據(jù)存儲(chǔ)方式可以滿足大數(shù)據(jù)環(huán)境下的數(shù)據(jù)存儲(chǔ)需求。星際文件系統(tǒng)[1]創(chuàng)造了一個(gè)點(diǎn)對(duì)點(diǎn)(peerto-peer,P2P)的分布式文件系統(tǒng),升級(jí)了現(xiàn)有的網(wǎng)絡(luò)結(jié)構(gòu),實(shí)現(xiàn)了真正意義上的去中心化存儲(chǔ)。
每一個(gè)上傳到IPFS系統(tǒng)中存儲(chǔ)的文件,系統(tǒng)都會(huì)返回一個(gè)唯一的文件標(biāo)識(shí)符CID,但是資源請(qǐng)求者只有準(zhǔn)確提供CID才能下載IPFS中相應(yīng)文件。IPFS僅支持基于CID的數(shù)據(jù)獲取方式,制約了它的應(yīng)用。由于缺乏相應(yīng)的搜索功能,資源請(qǐng)求者很難通過關(guān)鍵詞或者其他描述信息獲取相關(guān)數(shù)據(jù)。研究IPFS的數(shù)據(jù)獲取方法,可以幫助用戶根據(jù)自身需求搜索數(shù)據(jù),有利于IPFS數(shù)據(jù)的共享與發(fā)現(xiàn),使IPFS滿足更多的應(yīng)用場(chǎng)景。此外,當(dāng)文件標(biāo)識(shí)符丟失或遺忘時(shí),可以通過其他方式獲取原來的數(shù)據(jù),避免數(shù)據(jù)的“失聯(lián)”。
在IPFS之上建立數(shù)據(jù)檢索層可以解決數(shù)據(jù)獲取問題。傳統(tǒng)的集中式索引雖然容易實(shí)現(xiàn)、便于管理,但是削弱了IPFS的去中心化程度,并限制IPFS網(wǎng)絡(luò)的可伸縮性。在為IPFS建立去中心化索引方面,已有研究實(shí)現(xiàn)的都是基于關(guān)鍵詞的索引,沒有充分考慮長(zhǎng)查詢和短查詢之間的區(qū)別,一般認(rèn)為三個(gè)以上關(guān)鍵詞的查詢屬于長(zhǎng)查詢[2],將長(zhǎng)查詢分詞為多個(gè)關(guān)鍵詞進(jìn)行搜索會(huì)對(duì)網(wǎng)絡(luò)造成更多的負(fù)擔(dān)。為使數(shù)據(jù)的獲取更加高效,引入了緩存機(jī)制,由發(fā)布搜索的節(jié)點(diǎn)緩存相關(guān)結(jié)果,卻忽視了搜索發(fā)布節(jié)點(diǎn)與相關(guān)結(jié)果存儲(chǔ)節(jié)點(diǎn)之間的距離,使網(wǎng)絡(luò)中存儲(chǔ)大量不必要的冗余數(shù)據(jù),未充分利用緩存空間。
基于此,本文針對(duì)緩存空間的浪費(fèi)問題,改進(jìn)了緩存存儲(chǔ)機(jī)制,降低其所占存儲(chǔ)空間。針對(duì)IPFS數(shù)據(jù)獲取問題,設(shè)計(jì)了一種去中心化混合索引,使得搜索在長(zhǎng)短查詢上都能有較好的表現(xiàn),對(duì)長(zhǎng)查詢語(yǔ)句,使用word2vec[3]建立句子索引,使語(yǔ)義內(nèi)容相似的句子索引能夠相鄰存儲(chǔ),以有效獲取IPFS系統(tǒng)數(shù)據(jù)。
1 相關(guān)工作
目前,關(guān)于IPFS的數(shù)據(jù)獲取這一方面的研究比較少,還沒有成熟的解決方案。IPFS-search[4]是github上的一個(gè)開源項(xiàng)目,該項(xiàng)目嘗試在IPFS上建立一個(gè)基于Elasticsearch的集中式搜索引擎,能為用戶提供關(guān)鍵詞搜索功能。然而集中式索引的服務(wù)器面臨著更多的攻擊,對(duì)存儲(chǔ)能力的要求也更高。文獻(xiàn)[5]提出為IPFS建立一個(gè)去中心化的搜索引擎,建立關(guān)鍵詞和CID的倒排索引,并使用DHT存儲(chǔ)索引文件,通過緩存層和過濾器加快搜索過程,該方法在較短的平均查詢時(shí)間內(nèi)取得了較好的緩存命中率,但是當(dāng)查詢語(yǔ)句有多個(gè)關(guān)鍵詞,對(duì)每個(gè)關(guān)鍵詞分別進(jìn)行搜索會(huì)增加網(wǎng)絡(luò)的通訊路由。Desema[6]是一個(gè)基于IPFS和區(qū)塊鏈的去中心化服務(wù)市場(chǎng),使用IPFS存儲(chǔ)數(shù)據(jù),并通過區(qū)塊鏈共享IPFS數(shù)據(jù)。雖然解決了區(qū)塊鏈存儲(chǔ)限制,但區(qū)塊鏈上實(shí)現(xiàn)的仍然是基于CID的數(shù)據(jù)獲取方式。Zhu等人[7]以去中心化的B+樹和HashMap為IPFS等去中心化存儲(chǔ)數(shù)據(jù)建立索引,實(shí)現(xiàn)了關(guān)鍵字搜索功能。基于DHT的索引結(jié)構(gòu)存在大量相關(guān)工作,文獻(xiàn)[8-9]結(jié)合向量空間模型(VSM)和潛在語(yǔ)義索引(LSI)將文檔表示為笛卡爾空間的向量,但是其計(jì)算過程中對(duì)文檔矩陣進(jìn)行SVD分解的計(jì)算代價(jià)太大,時(shí)間復(fù)雜度是O(N2),空間復(fù)雜度O(N3)。Reynolds等人[10]提出使用布隆過濾器和緩存加快DHT網(wǎng)絡(luò)中關(guān)鍵詞搜索過程,然而緩存也增加了大量的冗余數(shù)據(jù)。Hassanzadeh等人[11]提出了LANS和GLARAS方法,分別為節(jié)點(diǎn)分配地址及放置副本,使系統(tǒng)中每對(duì)節(jié)點(diǎn)之間的延遲對(duì)應(yīng)于其地址的公共前綴長(zhǎng)度,該方法提高了地址的位置感知能力,降低了搜索的端到端延遲及平均訪問延遲。Joung等人[12]使用超立方體索引關(guān)鍵字,相似關(guān)鍵字集的對(duì)象很可能被映射到彼此接近的點(diǎn),削弱了DHT的哈希映射方式對(duì)數(shù)據(jù)鄰近性存儲(chǔ)的破壞。Armada[13]和LIGHT[14]通過使用前綴哈希樹(PHT)分布其索引結(jié)構(gòu),在DHT上實(shí)現(xiàn)輕量級(jí)的范圍查詢。而Echo[15]則使用了一種新的分布式結(jié)構(gòu)TRT來擴(kuò)展前綴哈希樹(PHT),通過TRT提高范圍查詢的效率。Ngom等人[16]提出一種名為摘要前綴樹(SPT)的新結(jié)構(gòu)來解決DHT上關(guān)鍵詞超集搜索問題。董祥千等人[17]使用局部敏感哈希(locality sensitive Hashing,LSH)建立基于DHT的域索引,但主要是針對(duì)結(jié)構(gòu)化數(shù)據(jù)集的連接搜索問題,僅對(duì)結(jié)構(gòu)化數(shù)據(jù)開展了實(shí)驗(yàn)。雖然目前關(guān)于IPFS數(shù)據(jù)獲取的研究有了一定進(jìn)展,但是對(duì)長(zhǎng)查詢帶來的網(wǎng)絡(luò)負(fù)擔(dān)及搜索效率問題并沒有很好的解決方案。
因此本文為IPFS數(shù)據(jù)建立去中心化混合索引,并利用DHT網(wǎng)絡(luò)存儲(chǔ)索引文件,實(shí)現(xiàn)IPFS的數(shù)據(jù)獲取。主要工作如下:第一,將文件存儲(chǔ)在IPFS得到的CID值與文檔關(guān)鍵詞組合,構(gòu)成關(guān)鍵詞索引發(fā)布到DHT網(wǎng)絡(luò)中存儲(chǔ),然后計(jì)算文檔的句子索引并存儲(chǔ)在DHT網(wǎng)絡(luò)中;第二,節(jié)點(diǎn)對(duì)搜索結(jié)果緩存,加快后續(xù)相同查詢的搜索過程;第三,對(duì)長(zhǎng)查詢進(jìn)行句子搜索,可以在索引存儲(chǔ)節(jié)點(diǎn)的鄰近范圍搜索;對(duì)短查詢,提取關(guān)鍵詞后對(duì)每個(gè)關(guān)鍵字分別搜索。
2 相關(guān)技術(shù)
2.1 星際文件系統(tǒng)
IPFS系統(tǒng)并不是一個(gè)全新的技術(shù),而是集成并充分利用了BitTorrent、Git、P2P和密碼學(xué)等已有的技術(shù)[1]。IPFS系統(tǒng)中,以256 KB為塊大小對(duì)文件進(jìn)行分塊存儲(chǔ),每個(gè)分塊會(huì)分散存儲(chǔ)在IPFS網(wǎng)絡(luò)中的節(jié)點(diǎn)上,如果文件小于256 KB則直接存儲(chǔ)。如圖1所示,IPFS對(duì)文件分塊后,會(huì)計(jì)算每一個(gè)塊的哈希值,然后將所有塊的哈希值拼湊起來,再做一次哈希運(yùn)算,從而得到最終哈希值,即文件的唯一標(biāo)識(shí)符稱為CID。資源請(qǐng)求者只需要使用CID就可以在IPFS網(wǎng)絡(luò)中下載相應(yīng)文件[18]。

圖1 文件唯一標(biāo)識(shí)符的生成過程Fig.1 Generation process of unique content identifier
2.2 分布式哈希表
DHT是一種用于在分布式系統(tǒng)中存儲(chǔ)大量數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu),目前已經(jīng)得到了廣泛的應(yīng)用,P2P、IPFS、區(qū)塊鏈等系統(tǒng)使用DHT作為底層架構(gòu)。在DHT網(wǎng)絡(luò)中節(jié)點(diǎn)是動(dòng)態(tài)變化的,一個(gè)節(jié)點(diǎn)很難獲取并存儲(chǔ)全網(wǎng)節(jié)點(diǎn)的相關(guān)信息,因此采用每個(gè)節(jié)點(diǎn)僅負(fù)責(zé)維護(hù)部分路由信息的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)。DHT網(wǎng)絡(luò)使用哈希算法為每個(gè)節(jié)點(diǎn)分配一個(gè)節(jié)點(diǎn)地址(nodeID),為資源計(jì)算一個(gè)唯一標(biāo)識(shí)的鍵值,使節(jié)點(diǎn)nodeID和資源鍵值具有相同值域,將資源存儲(chǔ)在nodeID與資源鍵值相同或相近的節(jié)點(diǎn)。為了實(shí)現(xiàn)網(wǎng)絡(luò)中資源的快速查找和定位,需要借助能保證路由查詢收斂的路由算法。相關(guān)的實(shí)現(xiàn)算法有很多,例如CAN[19]、Chord[20]、Kademlia[21]。DHT網(wǎng)絡(luò)具有以下特性:
(1)魯棒性。DHT能夠支持節(jié)點(diǎn)頻繁地加入和退出網(wǎng)絡(luò),DHT具有良好的可擴(kuò)展性。
(2)負(fù)載均衡。DHT通過哈希運(yùn)算向網(wǎng)絡(luò)分配資源,能一定程度上實(shí)現(xiàn)負(fù)載均衡[22]。
(3)可用性。同一資源在多個(gè)節(jié)點(diǎn)存儲(chǔ),單點(diǎn)故障或節(jié)點(diǎn)退出網(wǎng)絡(luò)時(shí)保證資源的可用性。
(4)高效性。在具有N個(gè)節(jié)點(diǎn)的網(wǎng)絡(luò)中,DHT保證路由收斂,在有限跳數(shù)內(nèi)可以查找到目標(biāo)資源。
3 總體結(jié)構(gòu)設(shè)計(jì)
圖2為IPFS數(shù)據(jù)獲取方法IPFS-DDAM(IPFSdecentralized data acquisition method)的過程總覽圖。該方法主要包括:索引構(gòu)建、索引存儲(chǔ)、搜索過程、結(jié)果緩存等幾個(gè)過程。如圖2所示,步驟1~4為索引構(gòu)建和索引存儲(chǔ)過程,步驟a~e為搜索過程。
3.1 索引構(gòu)建及存儲(chǔ)
圖2中步驟1~4為索引構(gòu)建及索引存儲(chǔ)過程。首先,文件擁有者將文件上傳到IPFS系統(tǒng)中存儲(chǔ),IPFS會(huì)返回文件唯一標(biāo)識(shí)CID;然后,需要對(duì)文件建立兩種索引,一種是關(guān)鍵詞索引,對(duì)文件進(jìn)行關(guān)鍵詞提取,由這若干個(gè)關(guān)鍵詞與CID組合構(gòu)成若干個(gè)關(guān)鍵詞索引,另一種是句子索引,對(duì)提取出來的關(guān)鍵詞或文檔的中心句使用機(jī)器學(xué)習(xí)的方法構(gòu)建文檔的句子向量表示,由降維后的句子向量和CID構(gòu)成句子索引;最后,將生成的句子索引及關(guān)鍵詞索引發(fā)布到DHT網(wǎng)絡(luò)中存儲(chǔ)。IPFS網(wǎng)絡(luò)和DHT網(wǎng)絡(luò)只是邏輯上的劃分,物理上同一節(jié)點(diǎn)可以同時(shí)屬于兩個(gè)網(wǎng)絡(luò)。
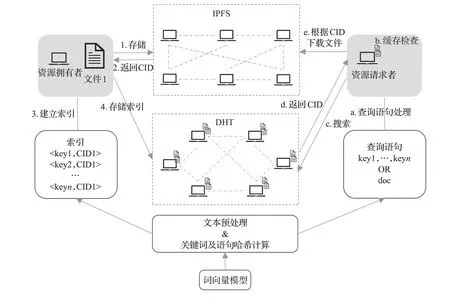
圖2 IPFS-DDAM過程總覽圖Fig.2 Overview of IPFS-DDAM
3.1.1 關(guān)鍵詞索引
本文為IPFS系統(tǒng)實(shí)現(xiàn)了基于關(guān)鍵詞的搜索功能,使用TF-IDF[23](term frequency-inverse document frequency)算法提取文檔的前n個(gè)或者權(quán)重大于閾值的關(guān)鍵詞(k1,k2,…,k n),每個(gè)關(guān)鍵詞經(jīng)過哈希運(yùn)算得到的關(guān)鍵詞哈希與文檔CID組成鍵值對(duì),即為關(guān)鍵詞索引。關(guān)鍵詞哈希與nodeID具有相同值域。每個(gè)索引存儲(chǔ)節(jié)點(diǎn)負(fù)責(zé)存儲(chǔ)與其nodeID相同或相近的關(guān)鍵詞索引。
3.1.2 句子索引
為了將句子索引存儲(chǔ)在DHT網(wǎng)絡(luò)中,句子索引一方面需要體現(xiàn)文檔的內(nèi)容,另一方面需要與DHT網(wǎng)絡(luò)的節(jié)點(diǎn)地址具有可映射性。為了使句子索引反映文檔內(nèi)容,本文提出了一種使用機(jī)器學(xué)習(xí)的方式計(jì)算句子索引——SICP(sentence index calculation process)。首先,提取文檔的中心語(yǔ)句,分詞后得到若干關(guān)鍵詞(k1,k2,…,k n),或者使用TF-IDF算法提取文檔的前n個(gè)或者權(quán)重大于閾值的關(guān)鍵詞;然后采用word2vec將關(guān)鍵詞轉(zhuǎn)為詞向量表示:

其中,dimt i(t=1,2,…,m)表示第i個(gè)詞向量的第t維,此時(shí)句子可表示為,將各個(gè)詞向量乘以其權(quán)重比后對(duì)應(yīng)維度相加,得到句子的向量表示:

其中,wi(i=1,2,…,n)表示第i個(gè)關(guān)鍵詞的權(quán)重值。
此時(shí),得到句子向量保留了文檔的內(nèi)容信息,句子之間的向量夾角反映了內(nèi)容的相似程度。然而句子向量是一個(gè)高維空間的向量表示,不能夠映射到DHT網(wǎng)絡(luò)的nodeID。為了滿足句子向量與nodeID之間的映射關(guān)系,本文使用minhash[24]對(duì)句子向量進(jìn)行降維。首先,選取N個(gè)隨機(jī)的哈希函數(shù);然后,對(duì)句子向量中的每個(gè)元素進(jìn)行哈希運(yùn)算,取其中的最小值;最后,重復(fù)N次上一步驟,得到代表句子向量的N個(gè)數(shù)值,即將句子向量降至N維。minhash是局部敏感哈希函數(shù)的一種,降維的同時(shí)可以保留高維度向量之間的相似性。使用minhash進(jìn)行降維的合理性,是基于對(duì)兩個(gè)集合隨機(jī)求最小哈希值相等的概率等于兩個(gè)集合的Jaccard系數(shù),公式表示如下:

其中,Jac(A,B)是集合A、B之間的Jaccard系數(shù),采用公式(4)計(jì)算:
將降維后的向量各維度拼接后得到160 bit的值與文檔CID組成鍵值對(duì),即為句子索引。句子索引的鍵值與nodeID具有相同值域。此外,句子索引保留了原內(nèi)容的相似性,則相似內(nèi)容的句子索引會(huì)相鄰存儲(chǔ)。用戶對(duì)同一對(duì)象的描述既具有差異性也具有相似性,因此無法精確匹配查詢對(duì)象時(shí),可以在索引存儲(chǔ)節(jié)點(diǎn)的鄰近范圍搜索。
使用SICP計(jì)算句子索引的復(fù)雜度,如表1所示。

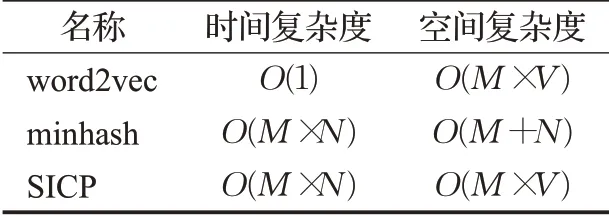
表1 計(jì)算復(fù)雜度Table 1 Computational complexity
表1中,M為詞向量維度,N為minhash過程中選取的哈希函數(shù)個(gè)數(shù),V為word2vec詞表的大小。其中,word2vec將關(guān)鍵詞轉(zhuǎn)為詞向量表示,本質(zhì)上就是利用哈希表查值,故其時(shí)間復(fù)雜度為O(1)。由表1可知,SICP的時(shí)間復(fù)雜度為O(M×N),空間復(fù)雜度為O(M×V)。
圖3展示了一個(gè)由中心語(yǔ)句構(gòu)建句子索引鍵值的示例。

圖3 句子索引構(gòu)造過程Fig.3 Process of building sentence index
3.1.3 索引存儲(chǔ)
索引使用去中心化的方式存儲(chǔ),利用DHT網(wǎng)絡(luò)存儲(chǔ)索引文件。本文中的DHT網(wǎng)絡(luò)基于Kademlia(KAD)算法實(shí)現(xiàn)。如圖4所示,DHT網(wǎng)絡(luò)中每個(gè)索引存儲(chǔ)節(jié)點(diǎn)都會(huì)存儲(chǔ)一個(gè)索引表及一個(gè)緩存表,并使用倒排表的結(jié)構(gòu)對(duì)索引進(jìn)行整合、存儲(chǔ)。DHT網(wǎng)絡(luò)中的節(jié)點(diǎn)提供索引存儲(chǔ)和搜索功能。

圖4 索引的存儲(chǔ)結(jié)構(gòu)Fig.4 Storage structure of index
3.2 搜索過程及結(jié)果緩存
當(dāng)網(wǎng)絡(luò)中的一個(gè)對(duì)等節(jié)點(diǎn)發(fā)起搜索時(shí),首先根據(jù)查詢語(yǔ)句的長(zhǎng)度判斷執(zhí)行句子索引或關(guān)鍵詞索引,還需要檢查緩存中的數(shù)據(jù),如果該節(jié)點(diǎn)自身緩存了搜索結(jié)果則直接返回結(jié)果并進(jìn)行緩存的更新;其次,在搜索消息路由過程中,如果其他對(duì)等節(jié)點(diǎn)緩存了該搜索的結(jié)果,則中斷搜索并返回結(jié)果,否則對(duì)搜索消息進(jìn)行轉(zhuǎn)發(fā)直到負(fù)責(zé)存儲(chǔ)該搜索結(jié)果的對(duì)等節(jié)點(diǎn);然后,如果是關(guān)鍵詞索引,需要精確匹配關(guān)鍵詞哈希,如果是句子索引,無法精確匹配的情況下,因?yàn)橄嗨苾?nèi)容的句子索引相鄰存儲(chǔ),在存儲(chǔ)句子索引的節(jié)點(diǎn)附近進(jìn)行搜索,搜索時(shí)會(huì)按照制定的規(guī)則添加搜索結(jié)果;最后,對(duì)搜索結(jié)果進(jìn)行整合過濾,結(jié)束搜索并返回結(jié)果,發(fā)起搜索的對(duì)等節(jié)點(diǎn)將此次搜索及相關(guān)結(jié)果加入到它的緩存中。
此外,由于緩存空間有限,并不是所有節(jié)點(diǎn)都會(huì)緩存搜索結(jié)果。發(fā)布查詢的節(jié)點(diǎn)在收到目的節(jié)點(diǎn)發(fā)送的搜索結(jié)果時(shí),會(huì)根據(jù)其與目的節(jié)點(diǎn)的距離決定是否對(duì)搜索結(jié)果進(jìn)行緩存,只有當(dāng)該節(jié)點(diǎn)的最近鄰節(jié)點(diǎn)或者若干路由跳數(shù)范圍內(nèi)的節(jié)點(diǎn)沒有相關(guān)數(shù)據(jù)才進(jìn)行緩存。如果緩存空間已滿,為了避免出現(xiàn)隨著緩存空間增大緩存的使用反而減少的情況,將采用最近最久未訪問算法對(duì)緩存結(jié)果進(jìn)行置換,保證對(duì)熱數(shù)據(jù)的快速搜索,同時(shí)減少緩存的空間開銷。
如圖5所示,網(wǎng)絡(luò)中的一個(gè)對(duì)等節(jié)點(diǎn)發(fā)起搜索的執(zhí)行過程如下:

圖5 搜索流程圖Fig.5 Flow diagram of querying
(1)對(duì)等節(jié)點(diǎn)發(fā)起查詢時(shí),對(duì)查詢語(yǔ)句進(jìn)行分詞,判斷是否執(zhí)行句子索引,若判斷為是,則執(zhí)行步驟(2);若判斷為否,執(zhí)行步驟(4)。
(2)使用SICP計(jì)算查詢語(yǔ)句的160 bit哈希值,判斷緩存中是否存儲(chǔ)相關(guān)查詢結(jié)果,若判斷為是,則執(zhí)行步驟(6);若判斷為否,執(zhí)行(3)。
(3)執(zhí)行句子索引,若在索引存儲(chǔ)節(jié)點(diǎn)無法精確匹配的情況下,因?yàn)橄嗨苾?nèi)容的句子索引相鄰存儲(chǔ),在存儲(chǔ)句子索引的節(jié)點(diǎn)附近進(jìn)行搜索,然后執(zhí)行步驟(6)。
(4)使用與建立關(guān)鍵詞索引同樣的哈希算法,計(jì)算查詢關(guān)鍵詞的160 bit哈希值,判斷緩存中是否存儲(chǔ)相關(guān)查詢結(jié)果,若判斷為是,則執(zhí)行步驟(6);若判斷為否,執(zhí)行步驟(5)。
(5)執(zhí)行關(guān)鍵詞索引,在索引存儲(chǔ)節(jié)點(diǎn)需要精確匹配存儲(chǔ)的關(guān)鍵詞哈希,然后執(zhí)行步驟(6)。
(6)發(fā)起查詢的對(duì)等節(jié)點(diǎn)得到搜索結(jié)果,更新緩存,結(jié)束查詢。
4 實(shí)驗(yàn)結(jié)果及分析
4.1 實(shí)驗(yàn)配置及數(shù)據(jù)集
用于實(shí)驗(yàn)的環(huán)境如下:操作系統(tǒng)為Windows 7旗艦版64位,Inter?Core?i5-3470 CPU@3.20 GHz,931 GB硬盤,12 GB內(nèi)存,peersim版本為1.0.5,IntelliJ IDEA版本為2020.2.2。
本文使用peersim軟件在兩個(gè)數(shù)據(jù)集上進(jìn)行了仿真實(shí)驗(yàn),一個(gè)是雅虎的匿名數(shù)據(jù)集[25],另一個(gè)是github上的數(shù)據(jù)集ChineseSTS[26]。雅虎數(shù)據(jù)集是對(duì)真實(shí)用戶的查詢進(jìn)行匿名處理后得到的。ChineseSTS數(shù)據(jù)集中每一行數(shù)據(jù)會(huì)有兩個(gè)句子和一個(gè)相似度值,相似度值取值范圍為[0,5],0表示語(yǔ)義相反或不相干,相似度值越大表示兩個(gè)句子的相似度越高。
4.2 句子索引分析
從ChineseSTS數(shù)據(jù)集抽取相似度值標(biāo)記為4和5的數(shù)據(jù),選擇其中分詞后詞數(shù)大于等于3的數(shù)據(jù),得到相似數(shù)據(jù)對(duì)1 190對(duì)。使用SICP計(jì)算相似數(shù)據(jù)對(duì)的句子索引,計(jì)算每個(gè)相似數(shù)據(jù)對(duì)句子索引的切比雪夫距離[27]。在執(zhí)行句子索引時(shí),會(huì)設(shè)置切比雪夫距離作為閾值,然后根據(jù)閾值在句子索引存儲(chǔ)節(jié)點(diǎn)的鄰近范圍搜索滿足條件的結(jié)果。圖6展示了相似數(shù)據(jù)對(duì)總數(shù)與切比雪夫距離的關(guān)系,其中91.34%的相似數(shù)據(jù)對(duì)的切比雪夫距離小于等于25。
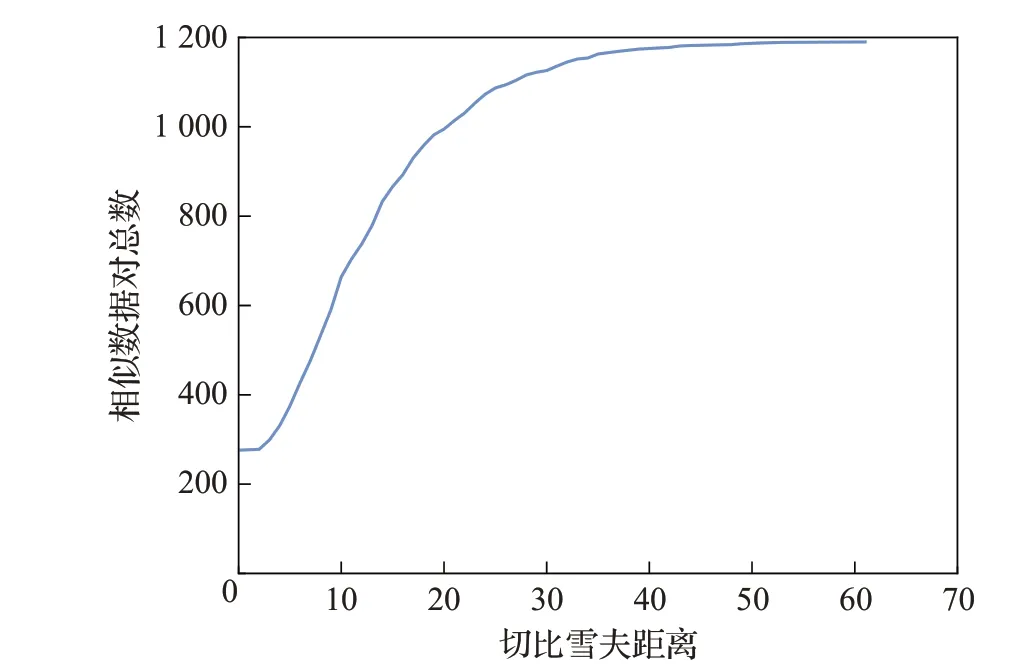
圖6 相似數(shù)據(jù)對(duì)總數(shù)與距離關(guān)系圖Fig.6 Total number of similar data variation with distance
將每對(duì)相似數(shù)據(jù)對(duì)拆分成兩部分,分別是用于存儲(chǔ)的數(shù)據(jù)及用于搜索查詢的數(shù)據(jù),而且數(shù)據(jù)對(duì)中存在多對(duì)相似的情況。將1 190條數(shù)據(jù)建立句子索引并存入DHT網(wǎng)絡(luò),另外1 190條數(shù)據(jù)用于搜索。首先,不使用句子索引,按照文獻(xiàn)[5]所述方法,將長(zhǎng)查詢語(yǔ)句分詞后,對(duì)每個(gè)關(guān)鍵詞分別查詢,設(shè)置并行搜索數(shù)目為3,搜索滿足要求的數(shù)據(jù)。統(tǒng)計(jì)查詢語(yǔ)句的關(guān)鍵詞個(gè)數(shù)及搜索的平均網(wǎng)絡(luò)跳數(shù),得到結(jié)果如圖7所示。

圖7 網(wǎng)絡(luò)跳數(shù)隨關(guān)鍵詞數(shù)變化Fig.7 Hop number variation with keywords number
查詢語(yǔ)句中有117條語(yǔ)句的關(guān)鍵詞數(shù)3,對(duì)應(yīng)的平均網(wǎng)絡(luò)跳數(shù)為19.78跳,當(dāng)查詢語(yǔ)句的關(guān)鍵詞數(shù)為5時(shí),對(duì)應(yīng)的平均網(wǎng)絡(luò)跳數(shù)為33.06跳,隨著關(guān)鍵詞個(gè)數(shù)的增加,搜索網(wǎng)絡(luò)跳數(shù)也不斷增加。
使用句子索引,設(shè)置切比雪夫距離為20,并行搜索數(shù)目為3時(shí),搜索滿足要求的數(shù)據(jù)。每個(gè)查詢語(yǔ)句的平均網(wǎng)絡(luò)路由為8.19跳。具體而言,在不同網(wǎng)絡(luò)跳數(shù)時(shí),能搜索得到的結(jié)果數(shù)如圖8所示。

圖8 搜索結(jié)果數(shù)對(duì)應(yīng)的網(wǎng)絡(luò)跳數(shù)分布Fig.8 Hop number distribution of search results
使用句子索引時(shí),無需關(guān)心查詢語(yǔ)句的關(guān)鍵詞數(shù),每個(gè)查詢語(yǔ)句的平均網(wǎng)絡(luò)路由為8.19跳,而不使用句子索引查詢,即使關(guān)鍵詞數(shù)僅為3,也需要19.78跳,可見句子索引加快了對(duì)長(zhǎng)查詢語(yǔ)句的搜索過程,減少了網(wǎng)絡(luò)負(fù)擔(dān),實(shí)驗(yàn)結(jié)果證明了本文提出的句子索引搜索方式的有效性。
4.3 關(guān)鍵詞索引及緩存分析
從雅虎數(shù)據(jù)集中抽取1 500 000條數(shù)據(jù),對(duì)其建立關(guān)鍵詞索引,并將其索引信息存入DHT網(wǎng)絡(luò)。為測(cè)試改進(jìn)存儲(chǔ)后的緩存所占空間進(jìn)行了如下實(shí)驗(yàn),從1 500 000條數(shù)據(jù)中抽取1 000條數(shù)據(jù),然后對(duì)這1 000條數(shù)據(jù)隨機(jī)采樣10 000次,構(gòu)成用于搜索的10 000條數(shù)據(jù),模擬重復(fù)查詢,其中數(shù)據(jù)的平均重復(fù)數(shù)為10。搜索結(jié)果如表2所示。
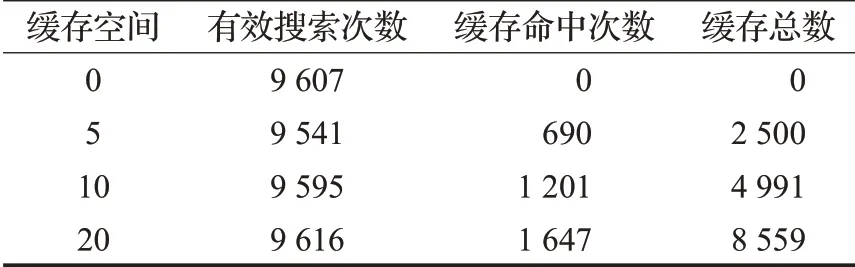
表2 在500個(gè)節(jié)點(diǎn)下的仿真實(shí)驗(yàn)結(jié)果Table 2 Results of simulation experiment with 500 nodes
緩存空間表示節(jié)點(diǎn)緩存搜索結(jié)果的能力,例如5表示節(jié)點(diǎn)可以緩存5條搜索結(jié)果。緩存總數(shù)是指DHT網(wǎng)絡(luò)中所有節(jié)點(diǎn)緩存搜索結(jié)果的總數(shù)。為盡可能地貼近真實(shí)情況,在指定范圍內(nèi)隨機(jī)選取干擾概率模擬節(jié)點(diǎn)的加入和退出網(wǎng)絡(luò)。因此在表2中,對(duì)10 000條數(shù)據(jù)進(jìn)行搜索,而對(duì)應(yīng)實(shí)際有效搜索次數(shù)卻低于10 000次。當(dāng)緩存空間設(shè)為20時(shí),DHT網(wǎng)絡(luò)所有節(jié)點(diǎn)的緩存空間為10 000,實(shí)際執(zhí)行的有效搜索為9 616次,按照文獻(xiàn)[5]及文獻(xiàn)[10]采用的緩存方式,此時(shí)緩存空間將使用9 616,而改進(jìn)緩存存儲(chǔ)機(jī)制后,緩存空間使用了8 559,緩存占用空間減少了10.99%,實(shí)驗(yàn)結(jié)果表明改進(jìn)后的緩存機(jī)制,緩存占用空間更少,可以緩存更多的查詢結(jié)果。
為說明緩存空間、數(shù)據(jù)的平均重復(fù)數(shù)、緩存命中之間的關(guān)系,進(jìn)行了如下實(shí)驗(yàn),從1 500 000條數(shù)據(jù)中抽取3 000條數(shù)據(jù),然后對(duì)這3 000條數(shù)據(jù)隨機(jī)采樣10 000次,構(gòu)成用于搜索的10 000條數(shù)據(jù),其中數(shù)據(jù)的平均重復(fù)數(shù)為3.3。得到搜索結(jié)果與表2的結(jié)果進(jìn)行對(duì)比,如表3所示。

表3 不同平均重復(fù)數(shù)的結(jié)果對(duì)比Table 3 Comparison results of different average duplicate data
平均重復(fù)數(shù)越大表示用于搜索的數(shù)據(jù)中重復(fù)查詢?cè)蕉啵磾?shù)據(jù)被頻繁搜索的次數(shù)越多。在表3中,緩存空間大小相同,數(shù)據(jù)平均重復(fù)數(shù)不同的,進(jìn)行了三次對(duì)照實(shí)驗(yàn)。無論緩存空間大小如何變化,平均重復(fù)數(shù)為10的緩存命中次數(shù)均約為平均重復(fù)數(shù)為3.3的實(shí)驗(yàn)緩存命中次數(shù)的3倍。實(shí)驗(yàn)結(jié)果表明緩存可以為被頻繁搜索的數(shù)據(jù)提供更好的搜索機(jī)制,可以保證對(duì)熱數(shù)據(jù)的快速搜索。實(shí)驗(yàn)中,隨著節(jié)點(diǎn)緩存空間的增大,緩存命中次數(shù)也隨之增大,而搜索會(huì)在緩存命中時(shí)中斷,無需將搜索消息轉(zhuǎn)發(fā)到最終目的節(jié)點(diǎn),因此,減少了消息轉(zhuǎn)發(fā)路由,加快了搜索過程。
5 結(jié)束語(yǔ)
本文鑒于目前在IPFS文件系統(tǒng)上缺乏有效的數(shù)據(jù)獲取方法,提出一種去中心化混合索引的IPFS數(shù)據(jù)獲取方法——IPFS-DDAM。實(shí)驗(yàn)結(jié)果表明,本文方法IPFS-DDAM在句子搜索和關(guān)鍵詞搜索上都能有較好的表現(xiàn),加快了搜索過程,對(duì)緩存機(jī)制的改進(jìn),降低了緩存所占存儲(chǔ)空間。在未來的工作中將探索能否改進(jìn)句子索引,使相似內(nèi)容的句子索引存儲(chǔ)相鄰這一特性更加明顯,進(jìn)一步提高搜索效率。
