改進(jìn)的多層圖注意力網(wǎng)絡(luò)在股價預(yù)測中的應(yīng)用
2022-02-24 12:39:08姜明華
計算機(jī)工程與應(yīng)用 2022年3期
姜明華,陳 赟
武漢紡織大學(xué) 數(shù)學(xué)與計算機(jī)學(xué)院,武漢 430200
預(yù)測股票走勢至今仍是一個難題,長期以來,無論是在工業(yè)界還是學(xué)術(shù)界,許多研究人員都對預(yù)測股市的未來趨勢表現(xiàn)出極大的興趣。專注于在歷史數(shù)據(jù)中發(fā)現(xiàn)盈利模式的研究人員,被稱為金融業(yè)的量化從業(yè)人員,他們越來越多地使用系統(tǒng)的交易算法來自動做出交易決策。盡管在學(xué)術(shù)界存在不少爭議,但大量研究表明,股市在某種程度上是可以近似預(yù)測的。價值投資者認(rèn)為,公司的股票價格應(yīng)該與公司的內(nèi)在價值相對應(yīng)。如果一家公司的目前的股票價格低于其內(nèi)在價值,投資者應(yīng)該購買該股票,因為它的價格將上升,并最終與它的內(nèi)在價值趨同。公司的基本面分析包括對公司業(yè)績和盈利能力的深入分析,公司的內(nèi)在價值取決于其產(chǎn)品銷售情況、員工價值、基礎(chǔ)設(shè)施和投資盈利能力的影響。對量化研究者來說,股票價格被認(rèn)為是一種具有復(fù)雜模式的典型時間序列數(shù)據(jù)。通過適當(dāng)?shù)仡A(yù)處理和建模,可以對模式進(jìn)行分析,從中提取有用的信息,用于技術(shù)分析的信息主要包括收盤價和成交量等,股票價格的波動是隨機(jī)和非線性的。
技術(shù)分析工作的重點(diǎn)是如何從原始數(shù)據(jù)中提取有意義的特征。在金融行業(yè),從這些數(shù)據(jù)中提取的特征稱為技術(shù)指標(biāo),包括自適應(yīng)移動平均數(shù)、相對強(qiáng)度指數(shù)、隨機(jī)性、動量振蕩等。提取有意義的技術(shù)指標(biāo)相當(dāng)于特征工程。許多研究表明,基于遞歸神經(jīng)網(wǎng)絡(luò)的股票波動預(yù)測模型是有效的。基于文本的股票預(yù)測方法試圖捕捉投資者對事件的看法,該類研究假設(shè)公司的股票價格等價于投資者對該公司意見的總和。近年來,計算機(jī)科學(xué)界對利用圖結(jié)構(gòu)數(shù)據(jù)非常感興趣。Agrawal等人[1]提出了利用公司關(guān)系數(shù)據(jù)進(jìn)行股市預(yù)測的方法;Bao等人[2]用LSTM自動編碼開發(fā)了一個更通用的框架;通過在公共知識數(shù)據(jù)庫中使用多種不同類型的關(guān)系,Bollerslev等人[3]還提出了一個能夠捕捉股票時間特征的GNN模型;Chen等人[4]建立了一個基于金融投資信息的公司網(wǎng)絡(luò),利用構(gòu)造的鄰接矩陣訓(xùn)練了一個GCN模型,并將其預(yù)測性能與傳統(tǒng)的網(wǎng)絡(luò)嵌入模型進(jìn)行了比較。LSTM是時間序列建模中應(yīng)用最為廣泛的一種框架結(jié)構(gòu),已有文獻(xiàn)將LSTM作為特征提取模塊,Chen等人[5]詳細(xì)描述了有關(guān)如何從原始價格數(shù)據(jù)中提取節(jié)點(diǎn)特征向量。Hool等人[6]基于一個可以表達(dá)節(jié)點(diǎn)平均可疑度的全局度量G,提出了Fraudar方法。從現(xiàn)有文獻(xiàn)來看,在圖表示方面考慮關(guān)系網(wǎng)絡(luò)和節(jié)點(diǎn)信息特征的方法并不多。傳統(tǒng)的方法首先根據(jù)圖的網(wǎng)絡(luò)信息輸入矩陣,比如利用經(jīng)典的PCA進(jìn)行降維,包括非線性降維LLE[7]、基于流行假設(shè)Laplacian算法[8],針對有向圖的方法[9]。LLE算法將每個節(jié)點(diǎn)表示為鄰近的節(jié)點(diǎn)線性加權(quán),給定一個鄰接矩陣,計算每個節(jié)點(diǎn)的重建權(quán)值矩陣,再轉(zhuǎn)換為特征值求解。Laplacian算法輸入圖的鄰接矩陣計算特征值,將最小的k個非零特征值對應(yīng)的特征向量作為圖表示,保證圖中相鄰節(jié)點(diǎn)被映射到降維后的空間位置。Gilmer等人[10]基于圖的學(xué)習(xí)視角為相關(guān)節(jié)點(diǎn)之間的信息進(jìn)行交換,通過將節(jié)點(diǎn)特征嵌入到矩陣分解中,使得節(jié)點(diǎn)表示學(xué)習(xí)過程中融入了關(guān)系信息和節(jié)點(diǎn)特征。文獻(xiàn)[11]則利用半監(jiān)督的學(xué)習(xí)方法將節(jié)點(diǎn)分類與圖表示任務(wù)相結(jié)合,但是該方法僅針對節(jié)點(diǎn)分類任務(wù)。目前的方法將關(guān)系數(shù)據(jù)集成到股市預(yù)測的模型中,但仍有較大的改進(jìn)余地。還沒有一種研究表明哪種類型的關(guān)系數(shù)據(jù)更有利于股票走勢的預(yù)測,也沒有找到一種有效的方法來選擇地聚集不同關(guān)系類型的信息,此外,以往的工作主要集中在節(jié)點(diǎn)分類上。節(jié)點(diǎn)分類和圖分類是基于圖學(xué)習(xí)的兩個主要任務(wù)。在股票市場網(wǎng)絡(luò)中,單個節(jié)點(diǎn)通常表示公司,預(yù)測個股未來走勢類似于節(jié)點(diǎn)分類任務(wù)。
本文認(rèn)為,圖分類任務(wù)中的模型可以用節(jié)點(diǎn)表示更新函數(shù)。在股市預(yù)測中如何有效利用基于圖的學(xué)習(xí)方法和關(guān)系數(shù)據(jù),使用不同類型的關(guān)系,并探討它們對公司股價變動的影響具有重要意義,只有包含重要的相關(guān)關(guān)系數(shù)據(jù)才對股票預(yù)測有用,一些不相關(guān)的信息會降低預(yù)測的準(zhǔn)確性。
本文借鑒文獻(xiàn)[12]的思路,采用類似于重新搜索節(jié)點(diǎn)分類任務(wù)的個股預(yù)測方法[13]和注意力分層機(jī)制[14],基于Tensorflow[15]平臺和維基數(shù)據(jù)庫[16],從融合關(guān)系網(wǎng)絡(luò)信息和節(jié)點(diǎn)特征的角度出發(fā),使用meta-path[17]方法,提出了一種新的多層節(jié)點(diǎn)圖注意網(wǎng)絡(luò)(FHAN)方法。實(shí)驗數(shù)據(jù)表明,本文的FHAN方法在股價預(yù)測能力相對于其他神經(jīng)網(wǎng)絡(luò)模型以及LSTM-attention[18]效果更好。
1 FHAN股價預(yù)測模型
1.1 預(yù)測模型總體框架
圖1為融合各種模塊的FHAN總體框架,可以有選擇性地聚合來自不同關(guān)系的信息,并將這些信息添加到公司的節(jié)點(diǎn)中。FHAN模型從原始節(jié)點(diǎn)出發(fā),使用LSTM從特征模塊中提取初始特征。本文首次將Fraudar算法嵌入在多層圖網(wǎng)絡(luò)中,目的是為了從公司節(jié)點(diǎn)特征之間抽取更精準(zhǔn)的關(guān)系數(shù)據(jù),剔除可疑度較高的那些公司,保留可疑度較低的公司節(jié)點(diǎn)數(shù)據(jù)進(jìn)入關(guān)系建模層,在隨機(jī)生成的游走路徑中,利用截斷的隨機(jī)游走從圖中生成大量路徑,將相鄰節(jié)點(diǎn)之間的信息進(jìn)行交換。同時注意力模塊是共享的,注意力分值的計算可以根據(jù)節(jié)點(diǎn)和元路徑并行計算,分層圖注意力網(wǎng)絡(luò)在每一層根據(jù)注意力權(quán)重打分,選擇重要信息后添加輸入到特定于任務(wù)的個股股價預(yù)測層,完成整股價預(yù)測過程。
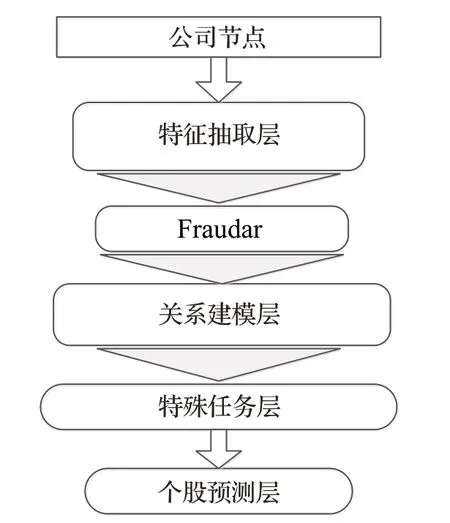
圖1 FHAN總體框架圖Fig.1 FHAN general framework
1.2 特征提取模塊
特征提取模塊用于基于歷史股價波動模式來表示企業(yè)當(dāng)前的狀態(tài)。在這項研究中,使用LSTM作為特征提取模塊的方法。LSTM模型用來處理時間序列問題,能充分利用整個序列信息,包括各個企業(yè)間的相互關(guān)系,并將這種關(guān)系用于對每個節(jié)點(diǎn)處理中。一個LSTM單元包含很多單元,每個單元包含一個輸入門、一個輸出門、一個遺忘門和一個記憶單元。設(shè)c為記憶單元,x為輸入門,f為遺忘門,h為輸出門。以企業(yè)局部特征{x1,x2,…,xn}作為輸入,激活記憶單元,獲取節(jié)點(diǎn)特征值如下:


其中,RELU為激活函數(shù),W代表LSTM權(quán)值矩陣,b代表位置偏移向量,α為sigmoid函數(shù),⊙表示逐點(diǎn)乘積。
1.3 Fraudar模塊
Fraudar常應(yīng)用于關(guān)系網(wǎng)絡(luò)反欺詐中,主要用來識別可疑的欺詐用戶。該算法定義了一個可以表達(dá)節(jié)點(diǎn)平均可疑度的全局度量G,在逐步貪心移除可疑度最小節(jié)點(diǎn)的迭代過程中,使G達(dá)到最大的留存節(jié)點(diǎn)組成了可疑度最高的致密子圖。定義公司節(jié)點(diǎn)集合數(shù)S,G(S)=F(S)/S,其中F(S)是節(jié)點(diǎn)可疑度的總和,G(S)可以理解為網(wǎng)絡(luò)結(jié)構(gòu)中每個節(jié)點(diǎn)的可疑程度。當(dāng)網(wǎng)絡(luò)中增加一個高可疑度的節(jié)點(diǎn)時,其帶來的F(S)增加百分比大于S帶來的增加百分比,G(S)增大;當(dāng)增加一個低可疑度的節(jié)點(diǎn)時,其帶來的F(S)增加百分比小于S帶來的增加,此時G(S)減小;所以G(S)是全局可疑度的一個有效表達(dá)。節(jié)點(diǎn)可疑度又是其所連接的邊的可疑度的總和。與節(jié)點(diǎn)連接的邊越多,其可疑度越小,即根據(jù)連接數(shù)降權(quán)。有效的邊可疑度計算公式為1/log(x+5),其中x是邊的數(shù)量,實(shí)際含義就是關(guān)系網(wǎng)絡(luò)信息越復(fù)雜的公司,其可疑程度較小。目的就是提取這些可疑度較小的公司節(jié)點(diǎn),一般這些公司為知名度較高的上市公司。同時剔除那些可疑度較高,與節(jié)點(diǎn)連接的邊較少的公司節(jié)點(diǎn),這些節(jié)點(diǎn)不利于預(yù)測股價,即所謂的噪音。
初始可疑度確定完畢后在模型迭代過程中,F(xiàn)raudar貪心的逐步移除圖所有可疑度最低的節(jié)點(diǎn)。但每一步迭代都遍歷全部節(jié)點(diǎn)來定位最小值,開銷非常大,為此構(gòu)建一棵優(yōu)先樹如圖2,讓父節(jié)點(diǎn)記錄其子節(jié)點(diǎn)中的最小值,這樣從根節(jié)點(diǎn)記錄的全局最小值出發(fā),可快速定位到該最小值對應(yīng)的葉節(jié)點(diǎn),然后將其刪除,同時更新網(wǎng)絡(luò)可疑度和優(yōu)先樹,剩余節(jié)點(diǎn)的全局平均可疑度G(*)逐步增大。當(dāng)全部節(jié)點(diǎn)迭代移除完畢后,回溯此過程使G(*)達(dá)到最大迭代。此時對應(yīng)的留存節(jié)點(diǎn)即目標(biāo)節(jié)點(diǎn),之間的關(guān)系網(wǎng)絡(luò)是整個網(wǎng)絡(luò)高致密子圖。

圖2 優(yōu)先樹Fig.2 Priority tree
1.4 關(guān)系建模模塊
在給定窗口大小k,在G上隨機(jī)生成的游走路徑中,如果節(jié)點(diǎn)v j出現(xiàn)在節(jié)點(diǎn)v i的鄰居窗口,則互為鄰居節(jié)點(diǎn),只要節(jié)點(diǎn)v i在k步內(nèi)達(dá)到v j即可。利用截斷的隨機(jī)游走從圖中生成大量路徑,從路徑中獲得每個相鄰節(jié)點(diǎn),利用圖神經(jīng)網(wǎng)絡(luò)的主要功能將相鄰節(jié)點(diǎn)之間的信息進(jìn)行交換。來自相鄰節(jié)點(diǎn)的信息被聚合,然后添加到每個節(jié)點(diǎn)表示中,對從不同節(jié)點(diǎn)和關(guān)系類型中收集的信息進(jìn)行有效地組合。每一層結(jié)構(gòu)網(wǎng)絡(luò)都是為了捕捉相鄰節(jié)點(diǎn)和關(guān)系類型的重要性而設(shè)計的。最終的節(jié)點(diǎn)表示將學(xué)習(xí)到的向量與其自身的節(jié)點(diǎn)特征相融合,將學(xué)習(xí)到的輸入向量作為圖表示,以下為圖表示的算法過程:
算法1節(jié)點(diǎn)關(guān)系建模算法
輸入:圖G(V,E)節(jié)點(diǎn)特征向量f i,隨機(jī)游走長度a1,滑動窗口大小a2,每個節(jié)點(diǎn)游走的次數(shù)a3,節(jié)點(diǎn)表示向量維度d,批量大小b,梯度更新步c;

1.5 特定任務(wù)模塊
在使用關(guān)系建模更新節(jié)點(diǎn)表示之后,節(jié)點(diǎn)表示將被反饋到特定任務(wù)模塊。節(jié)點(diǎn)表示可以用適當(dāng)?shù)哪P驮诓煌娜蝿?wù)中使用,在本研究中,對基于圖的學(xué)習(xí)任務(wù)進(jìn)行了實(shí)驗:個股預(yù)測。
FHAN:將特征提取模塊中的公司i在時間t上的f維特征向量表示為e ti∈Rf。可以在不同類型的關(guān)系之間定義邊。對于圖神經(jīng)網(wǎng)絡(luò),需要從每種關(guān)系型中知道目標(biāo)節(jié)點(diǎn)i和相鄰節(jié)點(diǎn)集。將關(guān)系型m中的鄰節(jié)點(diǎn)i表示為,同時將關(guān)系型m的嵌入向量表示為e r m∈Rd。d是關(guān)系型嵌入向量的維數(shù)。希望模型能夠過濾掉一些噪音,因為公司有很多不同類型的關(guān)系,有些信息與股價變動預(yù)測無關(guān)。
1.6 注意力機(jī)制層
注意力機(jī)制被廣泛應(yīng)用于對選擇的信息進(jìn)行權(quán)重分配。通過分層設(shè)計的注意力機(jī)制,本文的股票預(yù)測分層注意力網(wǎng)絡(luò)(FHAN)只在每個層次上選擇有價值的信息。如圖3所示,在第一層,F(xiàn)HAN從相鄰的節(jié)點(diǎn)中選擇相同關(guān)系類型的重要信息。注意力機(jī)制用于計算鄰節(jié)點(diǎn)當(dāng)前的不同權(quán)重。為了計算這些注意力的分值,將關(guān)系型嵌入向量e r m和節(jié)點(diǎn)表示i,j連接到一個向量中,將這個向量表示為,注意力分值的計算公式為:
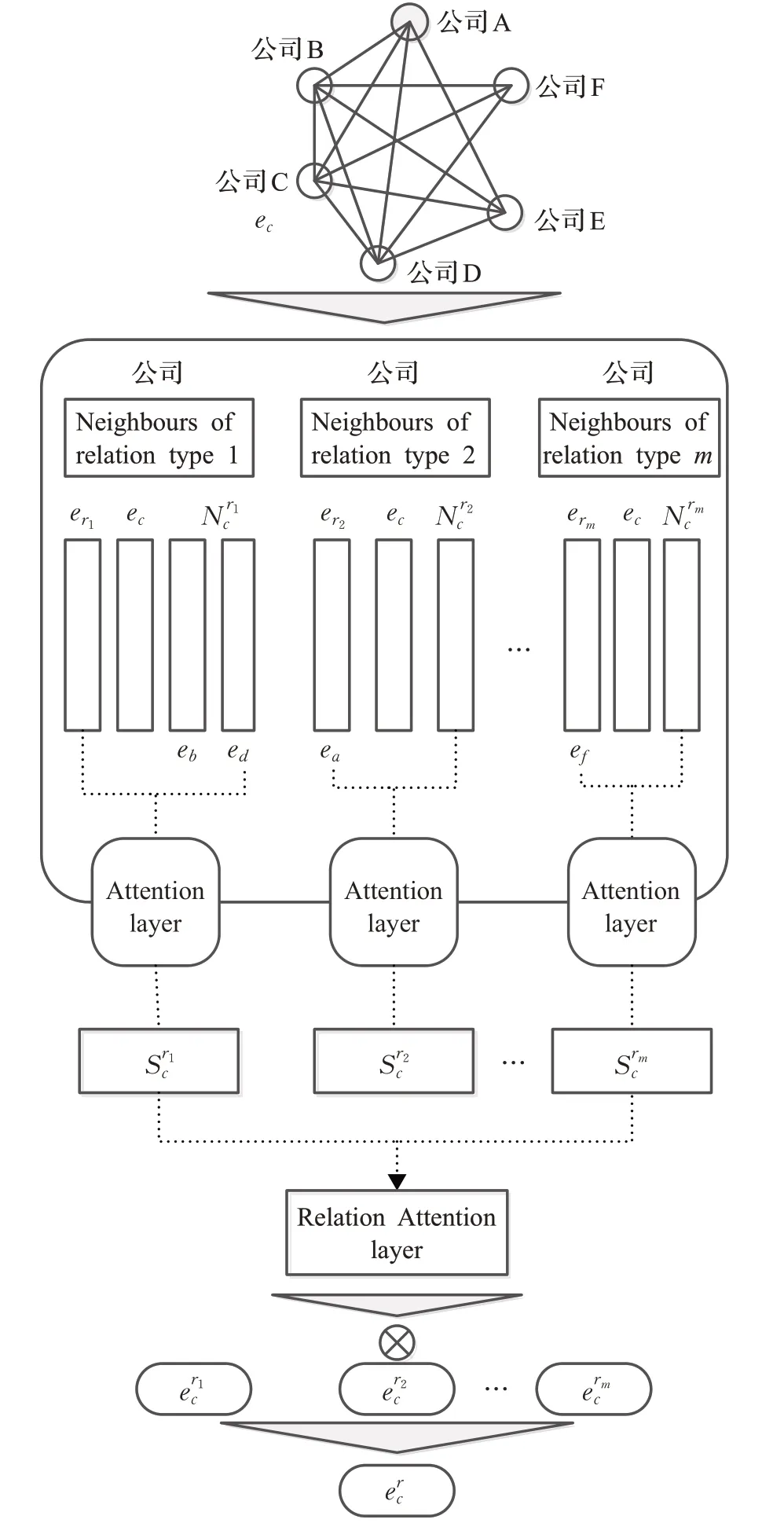
圖3 多層節(jié)點(diǎn)圖注意力網(wǎng)絡(luò)結(jié)構(gòu)Fig.3 Network of FHAN
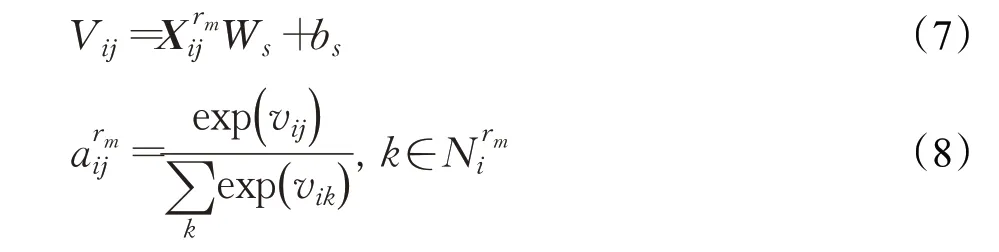
其中,Ws和b s是用于計算注意力得分的可學(xué)習(xí)參數(shù)。利用此公式計算注意力權(quán)重值,將所有加權(quán)節(jié)點(diǎn)表示結(jié)合起來計算出公司的關(guān)系向量表示m,計算公式如下:


Wr和b r是可學(xué)習(xí)參數(shù),每個關(guān)系型權(quán)重向量累計匯總成關(guān)系狀態(tài)表示如下:

1.7 個股預(yù)測層
將股價變動按以下兩種類型的標(biāo)簽進(jìn)行分類:上漲和下跌。對于個股預(yù)選任務(wù),添加了一個線性轉(zhuǎn)換層:


其中,Zu表示數(shù)據(jù)集中的所有公司,Yic代表具有股價變動的公司。
算法2基于FHAN模型的股價預(yù)測算法
輸入:個股代碼和初始價格
輸出:股價相對于初始價格是否上漲或下跌(1表示上漲,0表示下跌)
算法流程:
1.read data //個股代碼和初始價格
3.通過Fraudar算法剔除可疑度低的節(jié)點(diǎn)
4.從目標(biāo)公司相鄰節(jié)點(diǎn)中選擇相同關(guān)系類型的信息
5.連接關(guān)系型嵌入向量和節(jié)點(diǎn)表示為一個向量
6.計算注意力分值和相鄰節(jié)點(diǎn)的權(quán)重
8.將關(guān)系型嵌入向量輸入到第二個注意力層
9.累加節(jié)點(diǎn)表示和權(quán)重
10.通過交叉熵?fù)p失模型訓(xùn)練模型
2 實(shí)驗
2.1 實(shí)驗環(huán)境及數(shù)據(jù)集
本文所有實(shí)驗均基于Tensorflow平臺庫實(shí)現(xiàn),使用的CPU為英特爾I7處理器,GPU為NVIDIA RTX1080處理器,內(nèi)存16 GB,操作系統(tǒng)為Ubuntu。
本文以標(biāo)準(zhǔn)普爾500成分股為研究對象,從雅虎財經(jīng)網(wǎng)爬取這些目標(biāo)公司近六年股價的數(shù)據(jù)集,時間從2013/05/21至2019/05/20。本文采用金融行業(yè)常用的股價對數(shù)收益率作為原始特征輸入到特征提取模塊,公司的歷史股價對數(shù)收益率就是時間序列。從維基數(shù)據(jù)庫中收集美股公司自有的關(guān)聯(lián)數(shù)據(jù),如果公司實(shí)體之間有關(guān)聯(lián),就可以看作一條邊,單個公司實(shí)體就是一個節(jié)點(diǎn)。維基數(shù)據(jù)庫可以看作是一個擁有大量邊和節(jié)點(diǎn)的層次圖。一些公司之間聯(lián)系并不是十分緊密,使用層次圖中廣泛使用的meta-path方法,將這些公司節(jié)點(diǎn)連接起來,去除無關(guān)聯(lián)的公司后剩余430家公司,發(fā)現(xiàn)這些公司間有71種主要的關(guān)聯(lián)關(guān)系。研究目的就是探索這些目標(biāo)公司間的關(guān)聯(lián)數(shù)據(jù)在股價預(yù)測中是否起顯著的作用。
2.2 評估指標(biāo)
股價變動預(yù)測是一種特殊分類任務(wù),分別對每期的個股股價進(jìn)行預(yù)測,這里采用準(zhǔn)確率Acc和F1值兩個指標(biāo)來評估預(yù)測模型的性能,分值最后取平均數(shù)。表1根據(jù)FHAN預(yù)測類別組合劃分為真正例(TP)、假正例(FP)、真負(fù)例(TN)、假負(fù)例(FN)四種類型。計算公式如下:

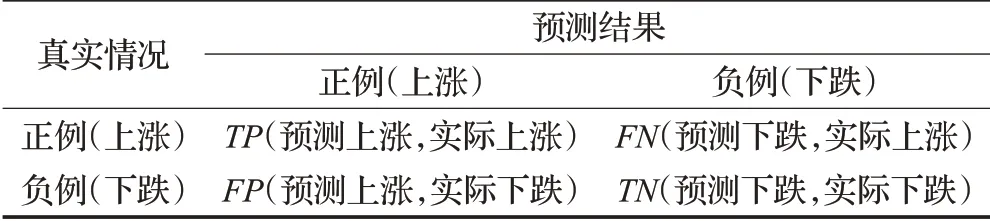
表1 評估指標(biāo)Table 1 Evaluation index

2.3 實(shí)驗結(jié)果與分析
為驗證FHAN模型的性能,將四種基線模型MLP、CNN、LSTM、GCN以及LSTM-attention模型與FHAN進(jìn)行比較。模型參數(shù)經(jīng)過多次實(shí)驗設(shè)置為表2,表3根據(jù)圖關(guān)系信息得到前五類關(guān)系型公司的F1分值,可見關(guān)系信息公開透明的大公司股價更能準(zhǔn)確地被預(yù)測。
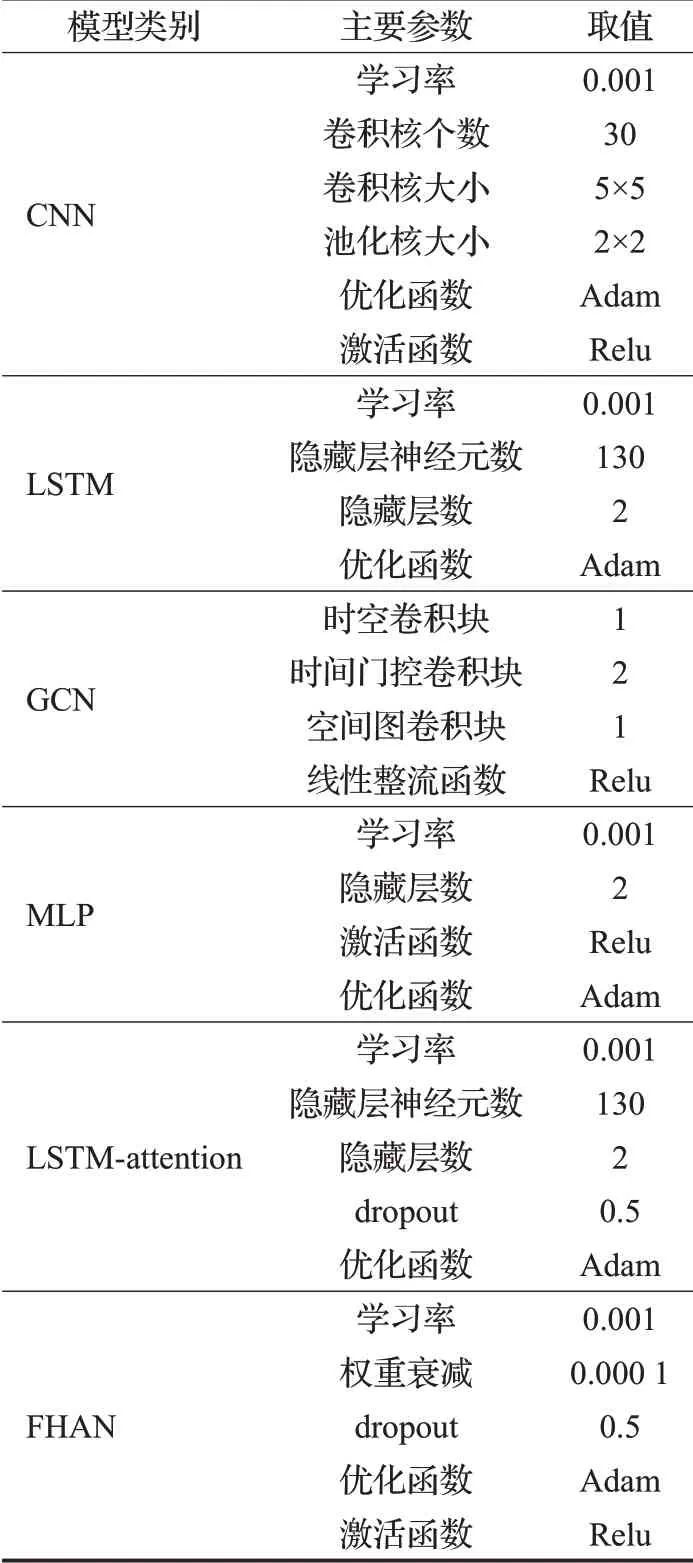
表2 模型參數(shù)設(shè)置Table 2 Parameter setting
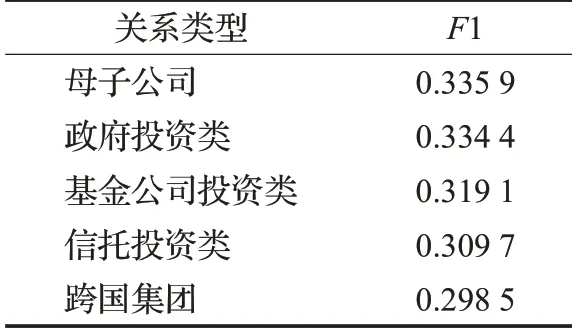
表3 關(guān)系類型的F1分值Table 3 F1 score of relation
為了保證實(shí)驗數(shù)據(jù)的準(zhǔn)確性和客觀性,將每個模型在同一訓(xùn)練集和測試集上分別運(yùn)行10次,求得精確率和F1值作為模型最終結(jié)果如表4所示。從表4可以看出,F(xiàn)HAN由于融入Fraudar算法,嵌入了圖結(jié)構(gòu)和節(jié)點(diǎn)特征信息,以及多層attention模塊,與其他模型相比,準(zhǔn)確率提升了約4%,最高提高約24%。但與目前較流行的LSTM-attention模型相比,精確度和F1分?jǐn)?shù)在測試集上僅小幅提升,主要原因在于兩者的注意力機(jī)制模塊都是共享的,在模型效果提升方面起到重要作用,本文雖嵌入Fraudar算法,但由于無法完全剔除噪音的干擾導(dǎo)致穩(wěn)定性還不夠高,因此對比模型效果后發(fā)現(xiàn)僅小幅提升。

表4 對比實(shí)驗結(jié)果Table 4 Comparative experiment
2.4 交易回測結(jié)果分析
實(shí)驗所設(shè)初始資金100萬元,從回測的結(jié)果圖4中表明,同期以黑色線標(biāo)準(zhǔn)普爾500指數(shù)為基準(zhǔn),F(xiàn)HAN、CNN、LSTM-attention策略均顯著高于該水平,超額收益阿爾法值均在20%以上。而FHAN策略不僅在年化收益率上高于CNN和LSTM-attention,而且在夏普比率等主要指標(biāo)上均優(yōu)于其他策略,說明在相關(guān)性很強(qiáng)的股票數(shù)據(jù)中,F(xiàn)HAN模型要比其他深度神經(jīng)網(wǎng)絡(luò)模型效果更好。

圖4 回測結(jié)果Fig.4 Result of return
3 結(jié)束語
FHAN模型的優(yōu)點(diǎn)如下:由于結(jié)合了Fraudar算法,可以處理網(wǎng)絡(luò)中多類型節(jié)點(diǎn)和關(guān)系信息,信息可以通過不同的關(guān)系從一種節(jié)點(diǎn)轉(zhuǎn)移到另一種節(jié)點(diǎn),利用FHAN可以使不同類型的節(jié)點(diǎn)相互融合,相互促進(jìn)和升級。注意力分值的計算可以基于節(jié)點(diǎn)和元路徑并行計算,總的復(fù)雜度與節(jié)點(diǎn)數(shù)量和基于元路徑節(jié)點(diǎn)的數(shù)量呈線性關(guān)系。Attention模塊是共享的,參數(shù)的數(shù)量不取決于層次圖的規(guī)模。模型對于學(xué)習(xí)節(jié)點(diǎn)具有較好的可解釋性。基于注意力分?jǐn)?shù),可以查看哪些節(jié)點(diǎn)或元路徑的貢獻(xiàn)度,有助于分析和解釋實(shí)驗結(jié)果。
從模型有效性來講,F(xiàn)raudar模塊有和其他無監(jiān)督算法如聚類共同的缺點(diǎn),即穩(wěn)定性較差,需要結(jié)合統(tǒng)計性指標(biāo)作出二次判斷。但專家判斷需要大量的人工干預(yù),且不具備泛化能力。例如當(dāng)從關(guān)系網(wǎng)絡(luò)中捕獲一些關(guān)鍵信息時,一些無關(guān)的信息也會被提取出來。當(dāng)然,為了增強(qiáng)模型輸出的可信度,可以先對圖做預(yù)剪枝處理,可以有效減少數(shù)據(jù)運(yùn)算量和時間。如本文中預(yù)先把所有無關(guān)信息網(wǎng)絡(luò)節(jié)點(diǎn)的公司剔除,只保留含有關(guān)系信息的節(jié)點(diǎn)集。
鑒于目前圖關(guān)系數(shù)據(jù)網(wǎng)絡(luò)方法運(yùn)用在股價預(yù)測中的不足,本文首次結(jié)合Fraudar算法提出改進(jìn)的多層圖注意力網(wǎng)絡(luò)模型。該模型在個股預(yù)測上效果明顯好于其他神經(jīng)網(wǎng)絡(luò)模型,實(shí)驗結(jié)果也證明了關(guān)系數(shù)據(jù)在股價預(yù)測中的重要性。但該模型仍有較大的改進(jìn)空間,本文是在整個上市公司數(shù)據(jù)的基礎(chǔ)上研究分類模型,針對性不夠,對具體行業(yè)的分析是未來的研究方向。本文只利用了單一的數(shù)據(jù)庫進(jìn)行研究,未來有興趣的讀者可以將新聞文本信息及多種數(shù)據(jù)庫融入關(guān)系網(wǎng)絡(luò),同時也可以嘗試對中國股市和大盤指數(shù)進(jìn)行深入研究,對我國金融行業(yè)深入研究具有借鑒意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學(xué)數(shù)學(xué)雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
