APP 用戶差評(píng)行為影響因素研究
2022-02-25 06:45:00丁文強(qiáng)
軟件導(dǎo)刊 2022年1期
丁文強(qiáng),苗 虹
(江蘇科技大學(xué)經(jīng)濟(jì)管理學(xué)院,江蘇 鎮(zhèn)江 212003)
0 引言
隨著信息技術(shù)的不斷發(fā)展,應(yīng)用程序(APP)如雨后春筍般出現(xiàn)在各大應(yīng)用市場(chǎng)中,APP 開(kāi)發(fā)者之間的競(jìng)爭(zhēng)異常激烈。應(yīng)用市場(chǎng)允許開(kāi)發(fā)者發(fā)布以及用戶購(gòu)買、下載、評(píng)論APP,用戶可以根據(jù)使用體驗(yàn)給APP 打出最低1 星、最高5 星的評(píng)分。Palomba 等[1]研究表明,星級(jí)評(píng)分和用戶評(píng)論對(duì)開(kāi)發(fā)團(tuán)隊(duì)的盈利有重大影響,低星級(jí)的APP 往往很難在應(yīng)用市場(chǎng)中生存下來(lái),大量?jī)?yōu)質(zhì)評(píng)論能使APP 獲得更高曝光度,負(fù)面評(píng)論則會(huì)使開(kāi)發(fā)者面臨損失。研究表明,當(dāng)評(píng)論數(shù)量達(dá)到一定規(guī)模時(shí),低認(rèn)知需求用戶受評(píng)論數(shù)量的影響較大,高認(rèn)知需求用戶受評(píng)論質(zhì)量的影響較大[2];而對(duì)于體驗(yàn)型產(chǎn)品而言,評(píng)論數(shù)量對(duì)用戶的影響更為明顯[3]。因此,開(kāi)發(fā)者通常會(huì)通過(guò)推出試用版本的方式積累原始用戶,通過(guò)擴(kuò)充功能、進(jìn)階增值服務(wù)等方式獲得盈利。
在互聯(lián)網(wǎng)時(shí)代,越來(lái)越多的用戶愿意通過(guò)在線評(píng)論的方式分享自身使用體驗(yàn),這些評(píng)論包含大量有價(jià)值的信息。潛在用戶除了通過(guò)開(kāi)發(fā)者介紹的信息了解APP 外,還會(huì)借助用戶評(píng)分進(jìn)行決策,在線評(píng)論成為其獲取信息的重要來(lái)源[4-5]。然而,不少消費(fèi)者都有過(guò)給出好評(píng)等級(jí)卻寫出負(fù)面評(píng)論的經(jīng)歷,消費(fèi)者擔(dān)心給出差評(píng)會(huì)受到賣家的報(bào)復(fù),從而違心給出正面評(píng)價(jià)[6]。評(píng)論星級(jí)與文本之間的不一致性使得高星級(jí)評(píng)論中也有著差評(píng)的存在,用戶的識(shí)別難度大大增加[7]。鑒于此,本文擬探究用戶是否會(huì)對(duì)開(kāi)發(fā)者在試用版本后推出增值收費(fèi)服務(wù)等營(yíng)利行為作出負(fù)面評(píng)價(jià),以及新版本軟件的功能、質(zhì)量與開(kāi)發(fā)團(tuán)隊(duì)推送頻率等對(duì)用戶差評(píng)意愿的影響。
1 相關(guān)研究
文本挖掘是從文本中提取出高質(zhì)量信息的過(guò)程,其應(yīng)用多集中在商品以及企業(yè)產(chǎn)品評(píng)價(jià)方面。目前,有許多學(xué)者面向APP 評(píng)論進(jìn)行文本挖掘研究,例如胡甜媛等[8]將評(píng)論體現(xiàn)的反饋定義為軟件滿足的需求、存在的問(wèn)題以及未達(dá)到的期望,通過(guò)構(gòu)建評(píng)價(jià)對(duì)象與評(píng)價(jià)觀點(diǎn)抽取規(guī)則,有效挖掘體現(xiàn)使用反饋的APP 用戶評(píng)論;呂宏玉等[9]針對(duì)APP 用戶特性,提出基于挖掘范圍識(shí)別和關(guān)聯(lián)規(guī)則的APP評(píng)論特征方法;張莉曼等[10]從APP 用戶需求表達(dá)狀態(tài)和表達(dá)過(guò)程出發(fā),剖析用戶需求的3 種表達(dá)形式,從用戶生成數(shù)據(jù)中聚合需求信息,生成高價(jià)需求情報(bào),然后再推送給需求者;Zhou 等[11]以亞馬遜生態(tài)系統(tǒng)為例,利用LDA 模型提取與客戶需求相關(guān)的主題,并使用KANO 模型對(duì)客戶需求進(jìn)行定量分類;Kim 等[12]利用LDA 模型對(duì)Twitter 用戶發(fā)布的信息進(jìn)行挖掘,從而更加高效地對(duì)用戶進(jìn)行好友推薦和內(nèi)容推送;王欣研等[13]提出學(xué)術(shù)APP 在線評(píng)論主題語(yǔ)義關(guān)聯(lián)研究方法,基于詞向量相關(guān)性獲得主題語(yǔ)義關(guān)聯(lián),構(gòu)建語(yǔ)義關(guān)聯(lián)圖譜,為APP 平臺(tái)運(yùn)營(yíng)者完善功能提供了參考依據(jù)。以上研究多從用戶需求和軟件特征的角度進(jìn)行文本挖掘。本文嘗試從開(kāi)發(fā)者的角度分析評(píng)論文本,通過(guò)開(kāi)發(fā)者將應(yīng)用免費(fèi)上架后再向用戶推送付費(fèi)版本這一行為,研究用戶作出負(fù)面評(píng)價(jià)的影響因素。
2 研究框架與方法
2.1 研究框架
本文研究框架如圖1 所示。首先采集APP 的用戶評(píng)論,對(duì)數(shù)據(jù)進(jìn)行預(yù)處理;然后從用戶評(píng)論集中人工篩選出500 條好評(píng)和500 條差評(píng),分為訓(xùn)練集和測(cè)試集,采用邏輯回歸模型進(jìn)行評(píng)論分類,篩選出差評(píng)文本。利用LDA 模型對(duì)差評(píng)集合進(jìn)行主題提取,生成文檔—主題矩陣詞匯—主題矩陣,并展示可視化結(jié)果。通過(guò)上述實(shí)驗(yàn)結(jié)果,驗(yàn)證開(kāi)發(fā)者在試用版本后推出增值收費(fèi)服務(wù)等營(yíng)利行為是否會(huì)得到用戶差評(píng),以及是否存在某些因素對(duì)此起到調(diào)節(jié)作用。

Fig.1 Research framework圖1 研究框架
2.2 LDA 模型
LDA 主題模型是包含文檔、主題、詞項(xiàng)3 種結(jié)構(gòu)的3 層貝葉斯概率模型[14],其利用概率統(tǒng)計(jì)思想對(duì)文檔進(jìn)行建模,能將文檔集中每篇文檔的主題以概率分布的形式給出,通過(guò)判斷文本的相似性進(jìn)行更深層次的語(yǔ)義挖掘,將文本中隱藏的主題挖掘出來(lái)。
LDA 模型的原理如圖2 所示。首先定義一個(gè)包含m 個(gè)文檔的文檔集合D(d1,d2…dm)、主題集合T,字典中有V個(gè)詞匯。已知每個(gè)文檔包含n 個(gè)詞匯,則Nm表示第m 篇文章中的詞匯量,Wm,n表示第m 個(gè)文檔中的第n 個(gè)詞。文本集中隱藏了k 個(gè)主題(T1,T2…Tk),Zm,n表示第m 個(gè)文檔中第n 個(gè)詞的主題。每個(gè)文檔都有各自的主題,服從Dirichlet分布,參數(shù)為α,則對(duì)于第m 個(gè)文檔,其主題分布θm 為Dirichle(tα)。主題中的詞匯服從Dirichlet 分布,參數(shù)為β,則對(duì)于任意一個(gè)主題K,其詞分布φk 為Dirichle(tβ)。α、β為模型中的超參數(shù),影響著模型主題分布與詞匯分布的平滑度。兩個(gè)隱含變量θ 和φ 分別表示文檔集D 中d 文檔對(duì)應(yīng)到不同主題的概率和主題集T 中k 主題生成不同單詞的概率,其中θ 為K 維向量,φ 為v 維向量。
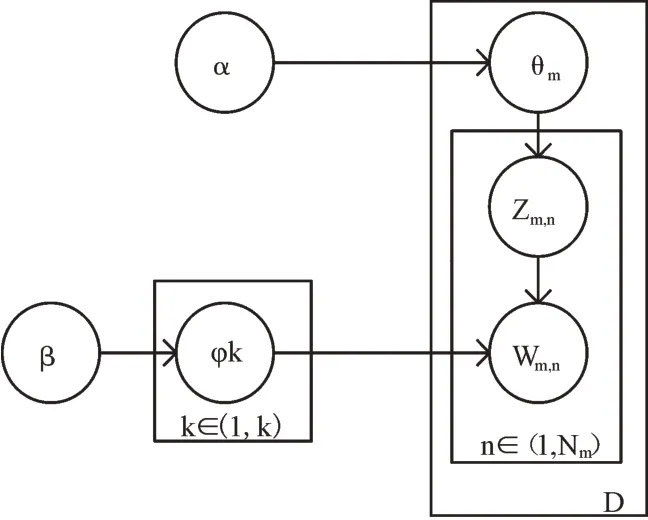
Fig.2 LDA model圖2 LDA 模型
LDA 的聯(lián)合概率計(jì)算方法如式(1)所示,式中w 為已知變量,先驗(yàn)參數(shù)可參考前人經(jīng)驗(yàn)確定;z 為某篇文章的所有主題,可由θ 確定。LDA 的訓(xùn)練過(guò)程主要為確定θ 和φ 值的過(guò)程,這些參數(shù)一旦確定,對(duì)于新加入的文檔,可以認(rèn)為主題詞—詞分布的φ 是穩(wěn)定的,參照Gibbs Sampling 公式確定θ 和φ。
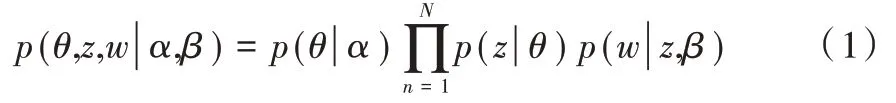
LDA 生成文本的步驟見(jiàn)表1。

Table 1 LDA model test generation steps表1 LDA 模型生成文本步驟
2.3 邏輯回歸模型
邏輯回歸模型[15]是一種經(jīng)典的分類算法,適用于對(duì)用戶評(píng)論數(shù)據(jù)進(jìn)行分類。其訓(xùn)練速度較快,且具有較好的分類效果,是使用最為廣泛的分類方法之一。該模型可根據(jù)一組自變量輸入計(jì)算出歸屬每種類別的概率,常使用二項(xiàng)邏輯回歸方法,即類別只有0 和1 兩種,其條件概率分布表示為:
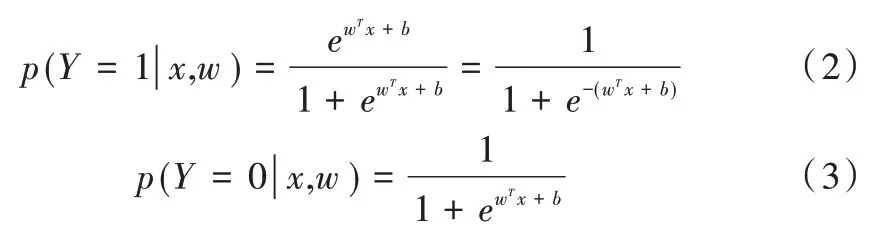
式中,x∈Rn 為輸入,稱為實(shí)例特征;Y∈(0,1)為輸出,兩個(gè)分類可以對(duì)評(píng)論是好評(píng)還是差評(píng)進(jìn)行判斷;w∈Rn 和b∈R為參數(shù);w 為權(quán)值向量,對(duì)應(yīng)每個(gè)輸入特征的權(quán)重;b為偏置。
3 數(shù)據(jù)采集與預(yù)處理
3.1 數(shù)據(jù)來(lái)源
APPexchange(https://APPexchange.salesforce.com/)是saleforce推出的應(yīng)用平臺(tái),現(xiàn)今已上架3 000多種APP,擁有上萬(wàn)在線用戶,旨在為用戶提供大量?jī)?yōu)質(zhì)APP。利用Python+Selenium 的方法采集APPexchange平臺(tái)中免費(fèi)APP的用戶評(píng)論數(shù)據(jù),共有14 290條,刪除非英文評(píng)論、無(wú)意義評(píng)論(“Waste Time”“Highly Recommended”)以及顯示異常評(píng)論等,得到14 068條有效評(píng)論。爬取的部分?jǐn)?shù)據(jù)內(nèi)容如圖3所示。

Fig.3 Partial test data display圖3 部分試驗(yàn)數(shù)據(jù)展示
3.2 數(shù)據(jù)預(yù)處理
由于用戶在平臺(tái)中的評(píng)論比較隨意,不可避免地會(huì)出現(xiàn)很多與研究主題無(wú)關(guān)的無(wú)效評(píng)論,因此對(duì)數(shù)據(jù)進(jìn)行預(yù)處理有助于提升模型效率,處理方法主要分為以下3 種:①分詞。進(jìn)行數(shù)據(jù)處理時(shí),計(jì)算機(jī)理解的最小處理單位為單詞,因此需要將語(yǔ)句拆分成有意義的單詞;②去除停用詞。分詞結(jié)果中通常會(huì)出現(xiàn)很多無(wú)意義的符號(hào),使用停用詞表刪除文本中的連詞、量詞、介詞等無(wú)意義詞語(yǔ),剔除無(wú)用標(biāo)點(diǎn),可以提高檢索效率、優(yōu)化內(nèi)存,文本處理時(shí)若遇到停用表中的詞,系統(tǒng)會(huì)停止處理,將其扔掉;③次干提取,詞形還原。去除相似單詞的詞綴,得到單詞詞根,否則主題模型會(huì)將這些單詞當(dāng)作不同的實(shí)體進(jìn)行處理,詞形還原則是利用上下文語(yǔ)境將單詞還原成詞根。
3.3 邏輯回歸分類
對(duì)采集到的評(píng)論信息進(jìn)行人工標(biāo)注,得到好評(píng)和差評(píng)各500 條。做好標(biāo)簽,正面評(píng)論用1 表示,負(fù)面評(píng)論用0 表示,采用空間向量表示預(yù)處理后的詞組,組成語(yǔ)料庫(kù)。將語(yǔ)料庫(kù)以7∶3 的比例劃分為訓(xùn)練集和測(cè)試集,利用邏輯回歸算法對(duì)訓(xùn)練矩陣進(jìn)行分類器訓(xùn)練,將訓(xùn)練好的分類器運(yùn)用到測(cè)試矩陣中進(jìn)行預(yù)測(cè),然后對(duì)模型效果進(jìn)行評(píng)估,最后調(diào)用訓(xùn)練好的邏輯回歸模型對(duì)采集到的評(píng)論進(jìn)行分類。
經(jīng)過(guò)訓(xùn)練,得到如圖4 所示的試驗(yàn)結(jié)果,可以看出各項(xiàng)模型評(píng)價(jià)指標(biāo)均大于0.9,說(shuō)明預(yù)測(cè)效果較為理想。使用訓(xùn)練好的分類器對(duì)用戶評(píng)論進(jìn)行分類,可形成用戶差評(píng)集合。
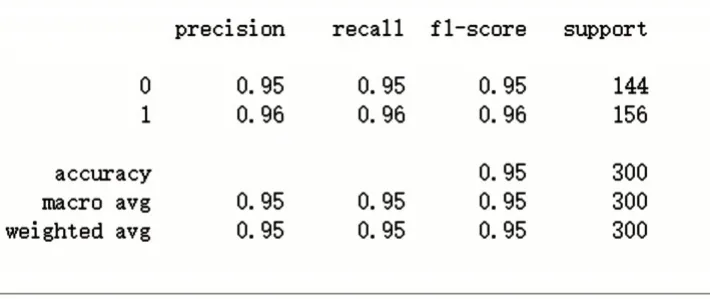
Fig.4 Logical regression model evaluation圖4 邏輯回歸模型評(píng)估
3.4 主題個(gè)數(shù)確定
LDA算法需要確定超參數(shù)α和β,以及主題數(shù)量k。實(shí)踐中常將超參數(shù)α和β值設(shè)置為0.1和0.01[16],本文亦是如此。
確定主題數(shù)量是構(gòu)建LDA 模型的難點(diǎn),主題數(shù)量影響著整個(gè)模型性能的優(yōu)劣。當(dāng)主題數(shù)目過(guò)多時(shí),會(huì)產(chǎn)生很多無(wú)明顯意義的主題;當(dāng)主題數(shù)目過(guò)少時(shí),主題粒度過(guò)大,一個(gè)主題包含多層語(yǔ)義。目前主題數(shù)量常基于困惑度和主題連貫性確定[17],由于困惑度依賴概率和詞頻,沒(méi)有考慮到詞匯在用戶評(píng)論中的上下文聯(lián)系,因此本文選擇后者確定用戶評(píng)論集的最佳主題數(shù)量[18]。通過(guò)Python 自帶的模型方法確定主題數(shù)量,根據(jù)LDA 提取的主題相似度計(jì)算相應(yīng)得分,得分越高,模型質(zhì)量越好。將主題數(shù)量分別設(shè)置為10、15、20、25、30,通過(guò)網(wǎng)格搜索法(Grid Search)進(jìn)行調(diào)參。由圖5(彩圖掃OSID 碼可見(jiàn))可以看出,當(dāng)主題數(shù)量為10 時(shí)效果最好,當(dāng)主題數(shù)量繼續(xù)縮小時(shí),評(píng)分仍會(huì)繼續(xù)上升,但主題數(shù)目過(guò)少時(shí)會(huì)造成一個(gè)評(píng)論包含多個(gè)主題的情況,不利于分析提取的主題。經(jīng)過(guò)多次試驗(yàn),最終設(shè)定主題數(shù)量為10。
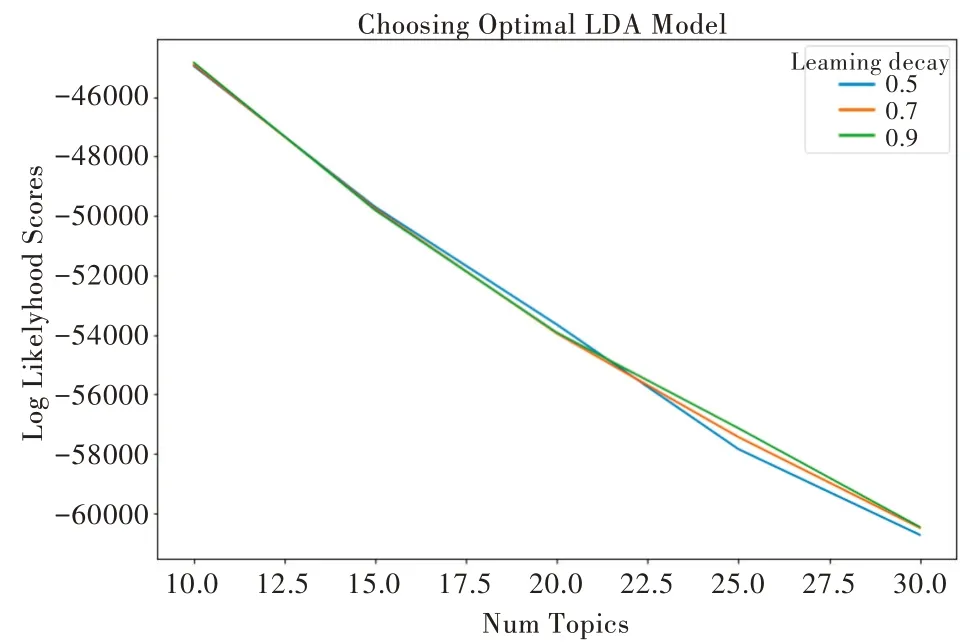
Fig.5 Number of themes圖5 主題數(shù)量
4 主題分析
通過(guò)LDA 模型對(duì)用戶差評(píng)集合進(jìn)行分析,得到文檔—主題矩陣和主題—詞匯矩陣。表2 為運(yùn)行LDA 模型后得到的主題—詞匯矩陣,展示了評(píng)論集合中出現(xiàn)的與10 個(gè)主題相關(guān)的特征詞。圖6 為主題4 包含的前30 個(gè)主題詞,特征詞“APP、free、pay”共現(xiàn)在部分軟件版本升級(jí)的差評(píng)集中,說(shuō)明確實(shí)存在開(kāi)發(fā)者先將APP 免費(fèi)上架,在限免一段時(shí)間后推送增值服務(wù)的情況,最終有用戶針對(duì)該現(xiàn)象給出了負(fù)面評(píng)價(jià)。由此證實(shí),將付費(fèi)APP 偽裝成免費(fèi)型上架,后期再推送付費(fèi)版本會(huì)對(duì)用戶差評(píng)行為產(chǎn)生影響。
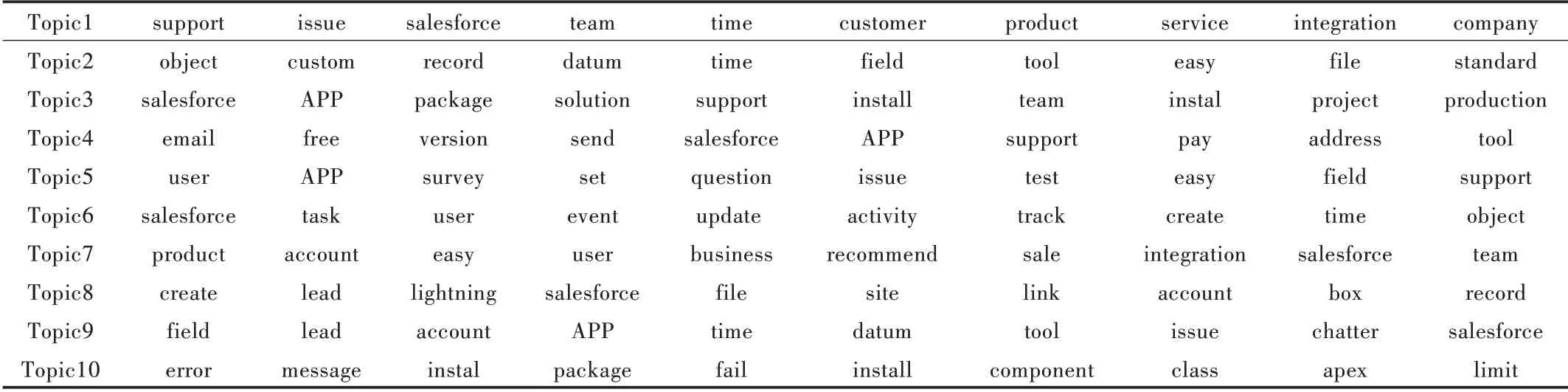
Table 2 Theme-vocabulary matrix表2 主題—詞匯矩陣
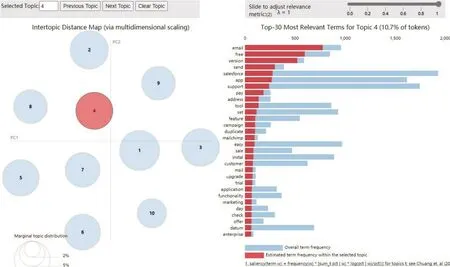
Fig.6 PyLDAvis visualization圖6 PyLDAvis 可視化圖
通過(guò)pyLDAvis 對(duì)主題進(jìn)行可視化,將圖6 中的關(guān)鍵詞導(dǎo)入到主題詞關(guān)聯(lián)圖中(見(jiàn)圖7),發(fā)現(xiàn)了關(guān)鍵詞“email、address、day”,說(shuō)明開(kāi)發(fā)者可能會(huì)通過(guò)電子郵件的方式向用戶推送營(yíng)銷信息,且較為頻繁。關(guān)鍵詞“pay、version、feature、upgrade”聯(lián)系緊密,說(shuō)明更新版本可能會(huì)增加新的功能適配用戶需求,如果用戶對(duì)新版本感到滿意可能會(huì)接受付費(fèi)行為,但當(dāng)升級(jí)版本沒(méi)有達(dá)到預(yù)期效果時(shí)會(huì)給出差評(píng)。
從提取的主題中可以看出,導(dǎo)致用戶差評(píng)行為的因素有很多,需要對(duì)這些因素的重要程度進(jìn)行比較。Pyldavis 左側(cè)面板展示了LDA 模型分類出的不同主題,主題氣泡大小可顯示主題強(qiáng)度,氣泡越大說(shuō)明該主題的重要程度越高,氣泡之間的距離表示兩個(gè)主題之間的相似程度。根據(jù)以上信息繪制圖8,可以看出,主題4 占比為10.7%,說(shuō)明付費(fèi)APP 偽裝成免費(fèi)APP 上架,后期進(jìn)行收費(fèi)的主題較為靠前,且與主題1 的12.5%較為接近。前3 個(gè)主題反映的是開(kāi)發(fā)團(tuán)隊(duì)的支持與服務(wù)、APP 的適配程度和程序包解決方案等問(wèn)題。后幾個(gè)主題解讀效果不是很好,主要為APP 的賬戶、插件、設(shè)置等出現(xiàn)的問(wèn)題以及對(duì)開(kāi)發(fā)團(tuán)隊(duì)的反饋。總體來(lái)說(shuō),開(kāi)發(fā)者將APP 上架于免費(fèi)專區(qū),后期進(jìn)行增值服務(wù)的行為容易造成用戶不滿,開(kāi)發(fā)者需提升更新后版本的質(zhì)量,達(dá)到物超所值的效果。
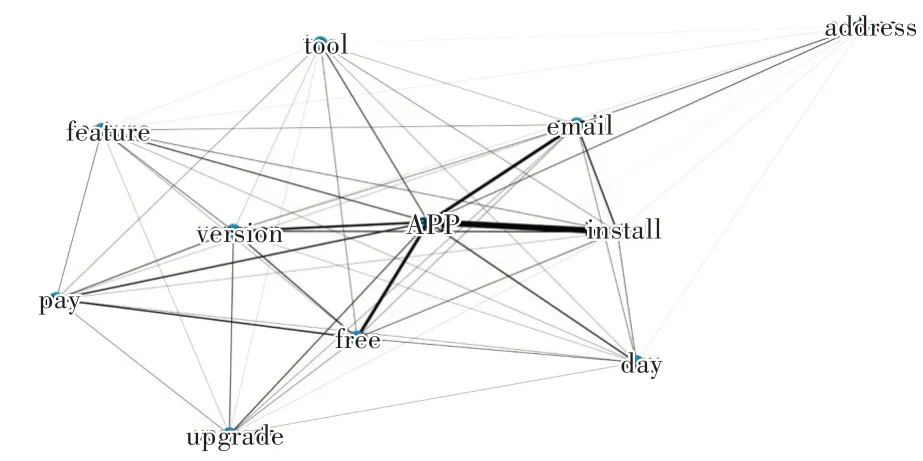
Fig.7 Keywords association chart圖7 關(guān)鍵詞關(guān)聯(lián)圖譜

Fig.8 Proportion of themes圖8 各主題占比
5 結(jié)語(yǔ)
本文基于邏輯回歸算法對(duì)APP 的評(píng)論集進(jìn)行分類,篩選出差評(píng)數(shù)據(jù),然后利用LDA 模型分析評(píng)論數(shù)據(jù),探究是否存在開(kāi)發(fā)者在試用版本后推出進(jìn)階收費(fèi)服務(wù)等營(yíng)利行為,以及這一現(xiàn)象與用戶差評(píng)行為的關(guān)系。實(shí)驗(yàn)結(jié)果表明,開(kāi)發(fā)者將應(yīng)用免費(fèi)上架后再向用戶推送付費(fèi)版本的行為是用戶作出差評(píng)的原因之一,尤其是當(dāng)開(kāi)發(fā)團(tuán)隊(duì)頻繁地對(duì)用戶推送付費(fèi)版本信息時(shí),更有可能導(dǎo)致用戶給予差評(píng);付費(fèi)版本的質(zhì)量和功能可能會(huì)對(duì)用戶差評(píng)行為起到調(diào)節(jié)作用。
當(dāng)使用免費(fèi)版本的用戶達(dá)到一定規(guī)模時(shí),開(kāi)發(fā)團(tuán)隊(duì)為獲取更高利潤(rùn),往往會(huì)推出付費(fèi)或高級(jí)版本進(jìn)行營(yíng)利行為,如果未做好營(yíng)銷推廣工作可能會(huì)導(dǎo)致用戶給予差評(píng),影響APP 下載量。開(kāi)發(fā)者應(yīng)合理制定價(jià)格策略,注重與用戶的溝通。如果付費(fèi)版本的功能與免費(fèi)版相比得到明顯提升,且價(jià)格合理,相信用戶樂(lè)意進(jìn)行付費(fèi)版本的嘗試。
本文研究方法仍存在一定局限性,根據(jù)實(shí)際需求調(diào)整pyldavis 中參數(shù)λ 的值可以得到更有意義的主題詞。此外,LDA 模型超參數(shù)的設(shè)定會(huì)影響主題模型的結(jié)果,因此在今后研究中將考慮更多參數(shù)對(duì)試驗(yàn)結(jié)果的影響,而不是參照其他文獻(xiàn)的推薦值,以便模型更加擬合試驗(yàn)數(shù)據(jù)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
