基于非對稱雙路識別網絡的步態識別方法
2022-03-02 08:31:48周瀟涵王修暉
計算機工程與應用 2022年4期
關鍵詞:特征
周瀟涵,王修暉
中國計量大學 信息工程學院,浙江省電磁波信息技術與計量檢測重點實驗室,杭州310018
步態是指人在行走過程中有規律的姿態變化,是一種行為生物特征。已有大量的醫學和物理證據表明每個人的步態都具有差異性。相較于其他生物特征,如面部和虹膜,步態更適合長距離和非合作的情形。但是步態也由于自身的局限性,對多種因素敏感,包括視角、衣服和攜帶物等。由于不同視角而引入外觀差異,其被稱為跨視角問題,是步態識別中的難點之一。
為了解決跨視角問題,研究者們嘗試過不同的步態模板。步態能量圖(gait engery image,GEI)[1]是沿時間維度的輪廓圖加和求平均的時空步態特征,可以減少輪廓噪聲,但會相應減少動態信息。與此相反,步態輪廓圖是許多幀人在行走時輪廓隨時間變化的圖片,輪廓圖很好地保存了步態的動態信息,但是受硬件條件限制,會受到采樣時的噪聲影響。在單一視角問題上,計算基于GEI 圖片的L2 距離經常能得到較優結果,然而在跨視角或多視角問題上,序列輪廓圖更有助于防止類內差距大于類間差距。
目前,步態識別領域的方法可分為基于模型和外觀兩個類別。基于模型的方法有:試圖重建人體的3D 模型[2],這通常依賴于多個高分辨率相機,成像距離也受約束,大大限制其潛在用途;其次是傳統的視角轉換模型,將步態模板從一個視角轉換至另一視角,如利用轉換一致性度量[3]和基于質量度量[4]的視角轉換模型,然而計算量大,轉化過程中無法避免噪聲的傳播,因此很難達到極好的識別效果。基于外觀的方法可以進一步區分成兩類:判別法和生成法。屬于判別法的模型有:Shiraga等[5]提出GEINet,使用GEI作為輸入,Softmax用于分類;Wu等[6]提出DeepCNN,直接學習一對GEI 或者輪廓序列之間的相似度;Feng等[7]提出一個結合非局部分塊特征的跨視角網絡,基于GEI圖片使用非局部注意力模塊增強局部信息;Wolf等[8]提出利用3D卷積捕捉步態序列中的時空信息,將步態輪廓序列作為網絡輸入;Tong 等[9]提出一個新型用于提取步態時空特征的深度學習網絡STDNN(spatial-temporal deep neural network);Chao 等[10]提出GaitSet,將輪廓序列看成一個集合,并增加多層全球通路(multilayer global pipeline,MGP)形成兩路網絡,得到不同的時空特征,使用三元組損失進行分類。生成式的方法通常將步態模型從不同的場景轉換到相同的場景,包括:He等[11]提出多任務生成對抗式網絡來學習具體角度下的特征表示;Yu等[12]提出步態生成對抗式網絡GaitGAN來模擬不同角度對步態特征的影響;Zhang等[13]提出GaitNet,基于自編碼-解碼器網絡分離出姿態和外形的特征,并用LSTM(long short-term memory)網絡產生姿態特征的時序動態信息。
上述方法的提出,雖然對步態識別的發展產生了較大的推進,但是大部分研究主要關注提取步態的全局時空特征,缺少針對步態輪廓圖中細粒度信息運用方法的研究。本文利用步態輪廓圖可以更好地保存人體步態的時空特征信息的優勢,使用卷積神經網絡(convolutional neural networks,CNN)進行步態特征建模,并針對步態全局特征和局部特征表現的不同,提出非對稱的雙路網絡結構。其中用于提取步態全局時空特征的網絡稱為全局通路,而用于檢測識別顯著性局部特征的網絡稱為局部通路。此外,在局部通路中插入顯著性特征檢測器模塊,以保證對步態中細粒度信息的有效提取和識別。最后,本文方法在CASIA-B 和OU-ISIR-LP 兩個公開步態數據集上進行了對比實驗。
1 方法
本文提出的非對稱雙路網絡的整體架構如圖1 所示,采用隨機抽樣的方式輸入幀數固定的步態輪廓圖,網絡整體框架總體上分為共享網絡和非對稱雙路網絡兩大部分。其中,共享網絡設置為7層,參數共享,具體參數如表1所列,用于提取一般步態特征。最后一層卷積層的通道數設置為k×classes,k為超參數,表示有效局部信息的個數,classes 為行人類別,從而使得提取的局部特征更具有邏輯上的針對性。卷積層后增加了歸一化操作,使得步態特征更穩定。
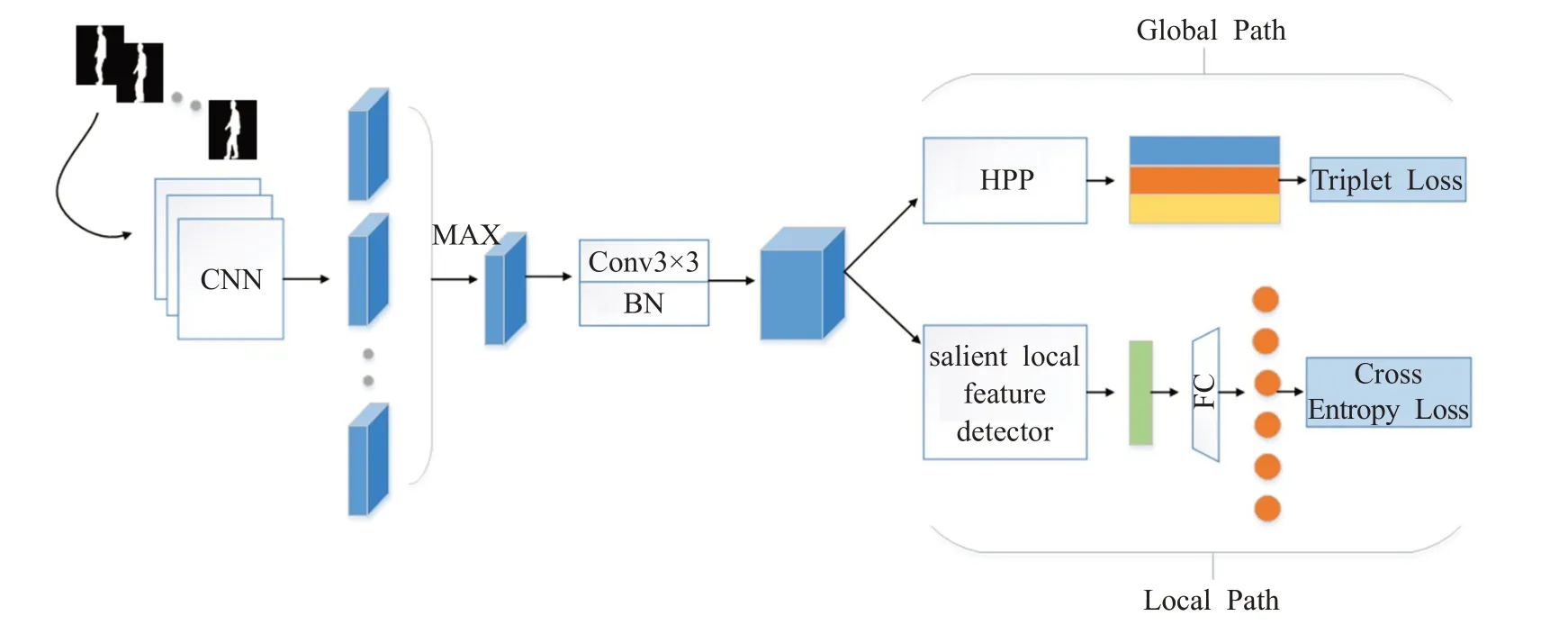
圖1 雙路網絡的整體框架Fig.1 Whole framework of two-path network

表1 共享CNN網絡Table 1 Shared CNN
經共享網絡提取出含有語義的步態特征,接著特征將進入非對稱雙路網絡。非對稱雙路網絡由全局通路(global path)和局部通路(local path)兩部分組成,網絡之間不共享參數。全局通路中使用了金字塔水平池化(horizontal pyramid pooling,HPP)[14],生成步態全局特征,配合三元組損失函數計算不同類別間特征的距離,確保類間差距更大;局部通路中設計顯著性特征檢測器,關注步態特征中的細粒度信息,生成步態局部特征,并結合交叉熵損失函數基于局部特征直接做分類,交叉熵損失會使得類內差距更小。最后,局部通路將輔助全局通路產生更具有判別力的全局特征。訓練階段將兩支網絡計算的損失值融合在一起,測試時僅使用全局通路輸出的全局特征。
1.1 雙路網絡結構
步態特征識別與一般分類識別不同點在于,步態特征既包含人物行走時的姿態變換特征,稱為全局時空特征(以下簡稱全局特征),又包含不同人體某些部位的特定形狀,稱為顯著性局部特征(以下簡稱局部特征)。一般地,基于輪廓圖的步態識別往往僅專注于全局特征的提取方法,僅有少數研究者開始重視步態的細粒度信息。因此,在局部特征的提取上受細粒度識別的啟發,可以通過設計模塊專注于一類物體的具有較大差別的細粒度信息,獲得具有判別力的特征。依據這一思路,本文設計出含有全局通路和局部通路的兩路網絡,具體結構如圖2。

圖2 雙路網絡結構Fig.2 Two-path network structure
全局通路中,HPP廣泛應用于步態行人重識別(ReID),原理如圖3,可以有效獲得多尺度下的全局信息;局部通路網絡用于檢測出步態特征中關鍵部位。步態細節識別與細粒度識別一大明顯區別在于,細粒度識別中顯著性區域建模的方法,大多要增加額外的標注,此種方式被稱為強監督學習方式[15],而步態識別僅有標簽,故屬于弱監督學習,此時顯著性區域檢測器的構造更重要。已有研究[16]在細粒度識別領域提出用于建模局部顯著特征的方法。本文在其基礎上,針對步態輪廓的特點構造了適用于步態圖片的顯著性區域檢測器,局部通路最后使用全連接層作為分類器,并增加BN層以減小過擬合,最終的分類將完全基于檢測器識別出的局部顯著性特征。在反向傳播時,由損失傳回的梯度繼而改變共享網絡的參數,會提高整個網絡提取特征的能力,使得全局特征更具有判別力。訓練時,網絡的損失為兩類損失的加權平均值。

圖3 水平金字塔池化Fig.3 Horizontal pyramid pooling
1.2 顯著性網絡檢測器
顯著性特征檢測器的內部,由兩個并行的獨立結構組成,第一層為一個3×3 卷積層,第二層為Mlpconv[17]層,最后一層分別設置全球平均池化和全球最大池化,輸入特征即可產生像素為1 的局部顯著信息。傳統意義上的卷積層結構為卷積加池化,即可使用具有局部感受野的神經元(如3×3卷積核)提取特征并由池化降維,同時獲得各通道上的顯著信息。但這種方法感受野大,提取的圖案模式粗糙,容易忽略掉步態特征圖中具有分辨力的細節。Mlpconv在傳統卷積后增加1×1卷積核和ReLU激活函數,從跨通道池化的角度來看,這樣等效于在一個正常的卷積層上實施級聯跨通道加權池化,使得模型能夠學習到通道之間的關系,對局部信息進行更好的建模,Mlpconv層公式如下:
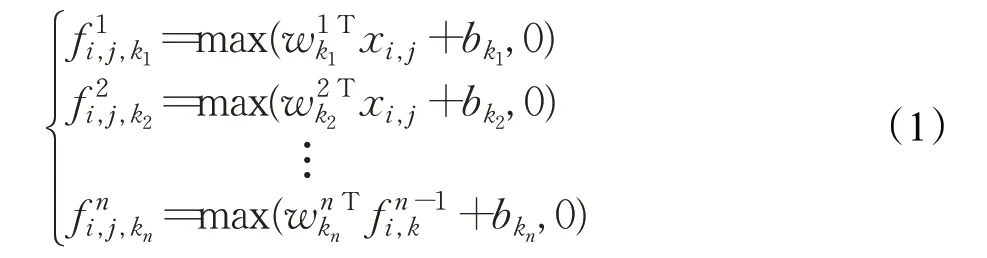
其中,(i,j)表示特征圖像素的索引,xi,j代表以位置(i,j)為中心的輸入塊,k用來索引特征圖的顏色通道,n表示多層感知器中的層數。由于本文步態識別使用的是連續的多幀圖片,步態的局部顯著性信息理應也處在連續多幀的動態變化中,跨通道學習因此理論上更適用于步態場景,1×1 卷積核感受野更小,也更易于捕捉步態中動態變化的細節信息。基于步態輪廓圖是灰度圖,具有樣式簡單等特點,本文建構的Mlpconv與原始結構不完全相同,如圖4所示,由Mlpconv提取的局部特征經過不同的池化,相疊加后送入分類器分類,這樣的好處一是減少了網絡參數,二是有效強化了局部特征。

圖4 顯著性特征檢測器Fig.4 Salient local feature detector
1.3 雙損失函數
本文采用兩種損失函數,一個是三元組損失函數,另一個是交叉熵損失函數。三元組損失函數使用Hermans等[18]提出的公式。隨機抽取P個人,K個不同場景下的樣本組成一個batch的內容,每個樣本取固定幀數f幀。對于batch內的每個樣本a,選擇關于它的所有正樣本和負樣本組成三元組,共有PK(PK-K)(K-1)個組合,具體公式為:

使用三元組損失函數用于保證類間差異大于類內差異。
交叉熵損失函數基于Softmax 函數和對數函數,Softmax 可將卷積網絡輸出的向量特征映射成取值在(0,1)之內的概率分布,會約束PK個樣本的局部顯著性特征對應到正確的類別,有助于減小類內差距,具體公式為:

使用不同的損失函數,用于針對不同的任務:三元組損失可以將屬于不同類別的相似樣本的距離拉大,更適合全局特征的形成;交叉熵會將特征向量直接映射成類別的概率值,理論上對特征向量的大小有限制,故更適合約束局部特征的形成。最終,訓練時網絡使用兩類損失的權重疊加,總損失的計算如下式所示:

其中,λ1和λ2為超參數。
2 實驗結果及分析
為了驗證本文方法的有效性,在CASIA-B[19]和OU-ISIR-LP[20]兩個數據集上進行了測試。
CASIA-B是目前步態識別最常用的數據集之一,共有124位行人的步態影像,分成3個場景,每個場景下的行人有11 個視角,視角為(0°,18°,36°,…,180°),在每個視角下,為每人拍攝10個步態序列,其中包括正常步行(NM)6個,攜帶背包(BG)2個,身穿外套(CL)2個,即每位行人含有11×(6+2+2)=110個序列。
OU-ISIR-LP 是目前人數最多的數據集之一,該數據集拍攝的對象年齡跨度廣泛,性別比例均衡。數據集提供同一場景下跨視角的人物行走序列,共設立4個觀測角度(55°,65°,75°,85°),每個對象的行走序列劃分為Gallery 和Probe。所有圖片均為輪廓圖,且統一歸一化處理成128×88大小。
實驗時,兩個數據集的序列輪廓圖在輸入網絡前經過對齊,并歸一化成尺寸為64×44大小的圖片,批量尺寸設置為128,訓練環節輸入幀數預置為30 幀,測試環節使用所有幀進行測試。優化器選擇Adam[21],兩損失所占比重設置為λ1=0.85,λ2=0.15,學習率設置為0.001,初始化權重采用Xavier 初始化方式,偏置初始化為0。在CASIA-B 數據集上,共享網絡最后一個卷積層的k設置為4,HPP的切塊數設置為3,三元組損失函數的邊距大小設置為0.2,訓練迭代100 000次左右;OU-ISIR-LP數據集的訓練迭代次數為80 000 次,其他參數設置類似。計算第一次命中率(Rank1)評判模型效果,實驗環境為一塊NVIDIA GeForce GTX TITAN X顯卡,代碼基于Pytorch深度學習框架編寫。
2.1 跨場景實驗對比結果
沿用Wu 等[6]提出的實驗設置,CASIA-B 數據將前74人設置為訓練集,剩余50人設置為測試集,在測試時NM#1-4用作Gallery集,后兩個序列用作Probe集;而針對跨場景下的模型測試,BG#1-2和CL#1-2皆用作Probe集。
表2 為各方法在CASIA-B 所有視角下的Rank1 識別率對比,對比方法有ViDP[22]、VTM-SVR[23]、C3A[24]、3DCNN[6]、CNN-集成[6]和GaitNet[13],其中前3 項為步態識別經典方法。經過實驗對比可以看出,深度學習方法在識別領域的明顯優勢。本文方法隸屬于深度學習,由數據反映其在0°~36°和144°~180°范圍內的識別效果顯著高于其他深度模型。表3、表4 為BG 和CL 場景下Rank1識別率對比,發現上述數據規律在不同場景下仍然適用。這說明本文網絡提取出的步態全局特征更具有判別性,可反映出不同場景下步態的關鍵要素,即針對不同環境更具魯棒性。對比僅含Global Path與完整Two-Path 的實驗數據,可以初步得出結論:局部通路網絡確實有助于整個模型生成更有判別力的步態全局特征。

表2 若干方法在CASIA-B數據集NM上全視角的Rank1識別率Table 2 Rank1 full-view accuracies of different methods under NM on CASIA-B dataset %

表3 若干方法在CASIA-B數據集BG上全視角的Rank1識別率Table 3 Rank1 full-view accuracies of different methods under BG on CASIA-B dataset %

表4 若干方法在CASIA-B數據集CL上全視角的Rank1識別率Table 4 Rank1 full-view accuracies of different methods under CL on CASIA-B dataset %
2.2 跨視角實驗對比結果
為了進一步展示模型在跨視角上的突出性能,繼續進行了不同視角差下的對比實驗。在OU-ISIR-LP 上,實驗將數據集中1 912 個角度齊全的子集分為2 份,其中956個ID用于訓練,另外956個ID用作測試。表5為不同方法在OU-ISIR-LP 數據集上的Rank1 識別率對比,對比實驗中傳統方法有WQVTM[4],深度學習方法有GEINet[5]、CNN-CGI[6]以及Non-Local[7],數據引自文獻[7]。和上述方法對比,Two-Path 的識別效果更優,且隨著視角變化識別率變化小。原因可能有二:一是輸入數據的形式不同,對比方法多以GEI 作為數據輸入,本文方法使用的輪廓圖數據量更大,可能帶來識別率提升;二是模型結構較上述方法更優。因此,為了消除第一個原因可能造成的影響,驗證模型的有效性仍然需要其他實驗。
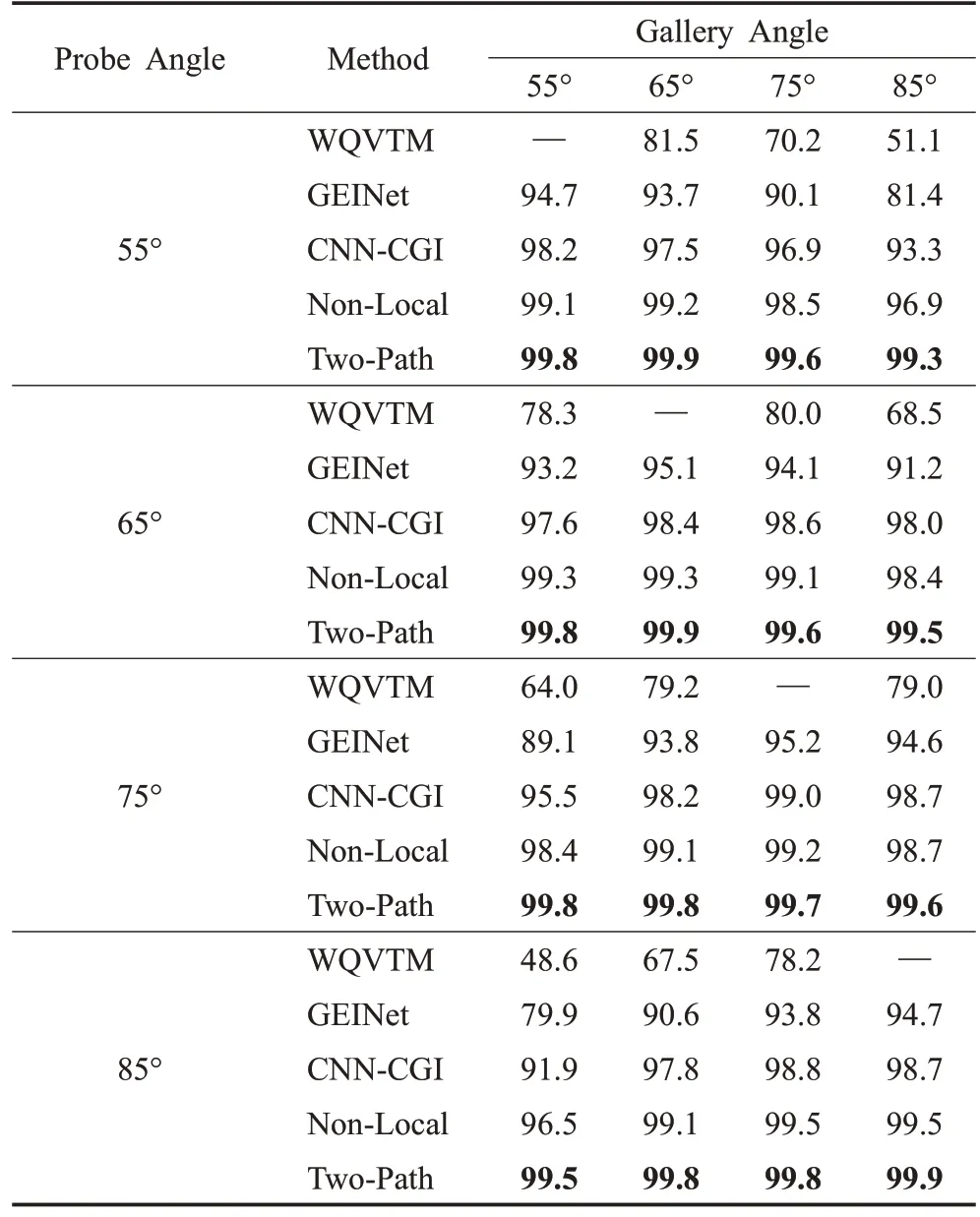
表5 不同方法在OU-ISIR-LP上跨視角的Rank1識別率Table 5 Rank1 cross-view accuracies of different methods based on OU-ISIR-LP %
在CASIA-B上進行跨角度實驗,實驗設置為100人訓練,余下24 人測試,場景固定為NM。表6、表7、表8分別展示了NM 場景下,視角差為18°、36°、54°時跨視角的Rank1 識別率結果對比。對比方法有3DCNN[6]、STDNN[9],數據輸入皆為輪廓圖,實驗數據引自文獻[9]。通過實驗數據可得,Rank1識別率不隨視角差的顯著增加而降低,變化穩定。這說明本文方法使用全局和局部兩條通路可以提取出更有效的步態特征,并且模型具有泛化性,對跨視角的魯棒性更好。

表6 基于CASIA-B不同方法在視角差18°時的Rank1識別率Table 6 Rank1 accuracies of different methods at angular difference of 18° based on CASIA-B %

表7 基于CASIA-B不同方法在視角差36°時的Rank1識別率Table 7 Rank1 accuracies of different methods at angular difference of 36° based on CASIA-B %

表8 基于CASIA-B不同方法在視角差54°時的Rank1識別率Table 8 Rank1 accuracies of different methods at angular difference of 54° based on CASIA-B %
3 結束語
本文為了更有效地提取步態特征,研究了步態中細粒度信息的有效利用方式,提出了非對稱的雙路結構,并設計了一個新型模塊顯著性檢測器用于局部顯著性特征的提取與識別。經過實驗得到驗證:通過設置合適的損失函數,增加神經網絡對步態輪廓圖細粒度信息的識別,有利于整個網絡提取出更具有判別力的全局特征。這在一定程度上探索了步態識別目前在深度學習領域,除設計直接提取全局特征的模塊外其他思路的可能性。另一方面,本文方法也是一次細粒度識別領域的研究思路向步態識別遷移的實驗,通過實驗數據可以得到較為客觀的結論:步態識別可以與細粒度識別方法相結合。但文中只做了初步的嘗試,今后還需后續更多深入的研究,以期未來將細粒度識別技術與步態識別深度結合。
本文使用多張輪廓圖作為步態識別網絡的輸入,模型參數的體量和訓練耗時仍需要進一步優化。此外,在不同場景下,模型在NM、BG、CL 上的識別率差別依然較大,說明模型的魯棒性仍然未達到理想狀態,模型精度仍有待提升,今后要繼續致力于步態識別模型在復雜場景下的應用研究。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
