基于文本挖掘的上市公司財務風險預警研究
2022-03-02 08:32:10梁龍躍
計算機工程與應用 2022年4期
梁龍躍,劉 波
1.貴州大學 經濟學院,貴陽550000
2.貴州大學 馬克思主義經濟學發展與應用研究中心,貴陽550000
隨著經濟全球化的發展,上市公司在實際運營中的競爭日益激烈,企業為了開辟新的利潤空間,選擇了多元化的投資經營方式,這在一定程度上促進了企業的持續發展。但在此過程中,一些公司缺乏財務風險的意識,使得發生財務危機的可能性增加。對于公司管理層來說,一旦公司發生財務危機,就會面臨無法償還債務、使得公司陷入破產的風險。對于投資者來說,公司發生財務危機會帶來巨大的投資風險。因此,能夠正確預測公司是否發生財務危機對于公司管理層和投資者來說具有重要的意義。一方面,公司管理層可以借此改變經營策略,防止公司陷入財務危機。另一方面,投資者可以了解企業的生存能力,及時規避投資風險。此外,正確預測企業財務危機,也有助于政府管理部門及時防范證券市場風險。
國內外學者先后使用不同的財務指標,針對不同的行業建立了不同的財務風險預警模型,但傳統的預警模型通常基于上市公司的財務指標數據,而沒有考慮財務文本與財經新聞等非結構化的文本數據,這些文本數據包含了大量的定性信息。Tennyson等[1]指出了財務文本信息對公司破產預測的重要作用,如上市公司年報中“經營情況討論與分析”和“審計報告”章節的部分文本內容確實可以為公司財務風險預測提供增量信息[2-3]。“經營情況討論與分析”一節對公司過去一年的經營情況做了一個總結性的陳述,同時對公司未來的發展做出了規劃,而“審計報告”內容能夠為政府和投資者了解企業真實的財務狀況和經營成果提供依據,但是如何從中抽取有助于財務風險預測的信息向來是一個富有挑戰性的難題。文本挖掘技術的發展,為分析文本信息提供了新的技術和方法。可以通過文本挖掘技術對文本數據中的定性信息進行量化分析,并將其轉化為財務風險預警模型可以識別的文本特征,用于財務風險預測,提高模型的預測能力。
基于此,本文提出一種基于BERT(bidirectional encoder representations from transformer)與自編碼器(autoencoder,AE)的文本特征提取融合模型,實現對上市公司年報中“經營情況討論與分析”和“審計報告”章節文本特征的提取,并將此文本特征用于財務風險的預測,擴展了文本特征在財務風險預測這一領域的研究。此外,本文研究結果表明,加入上市公司年報的文本特征后,財務風險預警模型的預測精度得到顯著提升,表明BERT-AE融合模型能夠提取出對財務預警有用的文本特征,在今后的研究中,可將其應用于其他領域的文本特征提取。
1 文獻綜述
1.1 基于財務指標的研究
上市公司財務風險預測一直以來備受業界關注,大多數學者都是基于財務指標數據對其進行研究。Altman[4]運用多元統計分析中的差異分析方法,選取5個財務指標構建Zeta 模型對財務風險進行預測。但建立Zeta 模型有一個假設前提,即樣本財務指標數據要呈正態分布,這與現實不相符合。Ohlson[5]以6 項財務指標為控制變量,建立了Logistic模型,其克服了Zeta模型的前提性缺陷并取得更好的預測效果,一度成為財務風險預測的主流模型。
隨著機器學習的發展與應用,神經網絡、支持向量機(support vector machine,SVM)、決策樹等方法也被用來分析財務指標對財務風險預測的影響。較早的研究中,有學者使用不同的財務指標,以基于人工神經網絡方法建立了財務風險預警模型,提高了財務風險預測的準確性[6-7]。最近3 年的研究中,方匡南等[8]選取90 個財務指標構建SGL-SVM 組合財務預警模型,同傳統的Logistic模型相比較,該模型擁有更優的預測性能。宋歌等[9]以2007—2016年A股上市公司財務數據為研究樣本,選取25個財務指標并使用深度學習模型建立上市公司違約預警系統,模型預測精度可以達到72%以上。Wang等[10]選取6 個財務指標,使用C50、CART 和隨機森林3 種決策樹模型建立財務危機預警系統,發現3個模型中隨機森林模型擁有良好的分類和預測能力。以上學者通過構建不同的財務預警模型對上市公司財務風險進行預測,使得財務風險預測領域的研究不斷取得突破,但研究都是以公司披露的財務指標數據為基礎,忽略了公司披露的財務文本信息。
1.2 文本信息在財務風險預警中的應用
財務文本信息作為公司信息披露的一部分,是對公司當前經營狀況以及未來發展前景的詳細說明,可以為預測公司財務風險提供增量信息[11]。通常使用文本挖掘技術對財務文本信息進行分析[12],通過文本挖掘技術提取相應的財務文本特征,用以預測公司未來財務狀況。現有研究主要從基于規則的統計方法和深度學習方法實現對財務文本特征的提取。
從基于規則的統計方法來看,國內外學者主要通過構建詞典、提取特定短語、詞頻統計的方法對財務文本進行處理。Hájek等[13]將公司年報中的文本與Hájek等[14]開發的金融字典進行比較,根據語義情緒對單詞進行分類,并計算出單詞類別的平均權重構建文本情緒指標,用以進行財務困境的預測。謝德仁等[15]參照Henry[16]、Loughran等[17]所使用的單詞列表,從所有詞語中手工選出正面和負面的情感詞語,構建上市公司業績說明會管理層語調,發現管理層語調能夠提供關于公司未來業績的增量信息。以上構建文本指標的方法均需要手工挑選情緒詞,難以適用于對大樣本的分析。陳藝云等[18]采用卡方檢驗的方法提取反映財務困境公司和正常公司的文本特征詞構建違約傾向指標,并將此指標加入財務變量中,提升財務預警模型預測精度。但使用卡方檢驗提取特征詞會產生低頻詞缺陷問題。
隨著文本挖掘技術的不斷突破以及公司財務風險預警研究領域的深入,有學者使用深度學習模型提取財務文本語義信息,并將其與財務指標數據結合起來用于財務風險預測,以提高模型預測精度。Matin 等[3]運用CNN 和基于注意力機制的RNN(recurrent neural networks)模型提取審計報告與管理層聲明的文本特征,發現加入文本特征后的財務風險預警模型取得更優的效果。Matin等使用了CNN-RNN模型對文本特征進行提取,但CNN-RNN 模型在特征提取時存在一些問題。RNN 從輸入文本的不同位置學到的同一特征無法共享,且其在進行反向傳播時因為傳播路徑過長容易導致梯度消失或者梯度爆炸。CNN的單層卷積核無法捕獲長距離特征,且池化層無法捕獲單詞的位置信息。這些問題均會使得文本信息丟失。此外,Matin 等的研究沒有考慮提取的文本特征維度大小問題,若提取的文本特征維度較高,則不易區分文本特征間的信息,同時在進行財務風險預測時會出現模型擬合速度慢、容易過擬合等問題。針對這些問題,提出了一種BERT-AE融合文本特征提取模型。
BERT模型[19]基于Transformer[20]結構構造了一個多層雙向的Encoder 網絡,Encoder 層中的參數量相較于CNN 和RNN 模型較少,優化了模型過擬合問題。多層雙向的Encoder網絡使得BERT模型擁有了獲取當前詞上下文的信息、語義語法信息的能力,解決了CNN 和ANN只能捕獲單一近鄰文本語句關系的問題。自編碼器(AE)[21]是一種無監督式學習模型,其泛化能力較強,不僅可以解決存在線性關系的數據降維問題,也可以解決存在非線性關系的數據降維問題,它能充分利用高維特征信息的同時解決高維特征所引入的“維數災難”問題[22]。BERT后接AE組成的BERT-AE融合模型不僅能提取出更為豐富的財務文本特征信息,還能在充分保留文本特征的同時將高維的文本特征降至低維,使得文本特征更容易區分,提高了模型的泛化能力。該模型提取的財務文本特征與Word2Vec-CNN-AE、Word2Vec-LSTM-AE 提取的財務文本特征相比較,結果表明,BERT-AE模型提取的財務文本特征使財務預警模型預測的AUC值的提升效果優于對比模型。
2 研究設計
財務風險預測能夠有效地降低風險和損失,國內外學者先后使用不同的財務指標、不同的模型進行預測,并通過對模型不斷優化,獲得了更好的預測效果。但是,有關此問題的研究仍然需要進一步的深入,例如獲取有效的財務文本特征用于財務風險的預測。對此,本文使用文本挖掘技術提取財務文本特征,并將此特征用于財務風險預測。研究設計包含四部分:(1)數據獲取;(2)文本特征提取;(3)財務預警模型構建;(4)對比實驗。在數據獲取中,本文將收集財務指標數據和文本數據,并對財務指標數據和文本數據進行預處理。在文本特征提取中,構建BERT-AE 融合模型提取財務文本特征作為財務指標數據的補充。在財務預警模型的構建中,以Logistic 回歸、XGBoost、ANN、CNN 模型為基礎,在財務指標中加入文本特征指標,比較加入文本特征前后模型的擬合效果。在對比實驗中,分別使用Word2Vec-CNN-AE和Word2Vec-LSTM-AE提取財務文本特征,然后將其加入財務指標中,比較加入文本特征前后財務預警模型的擬合效果。
2.1 數據獲取和預處理
2.1.1 財務指標數據獲取和預處理
目前國內對企業財務危機沒有客觀全面的判別標準,本文參照國內學者一般做法,將兩個會計年度財務狀況出現異常而被特別處理(ST)作為公司陷入財務困境的標志。同時,為了處理數據不平衡對實證結果穩健性的影響問題,以1∶2 的方式對ST 公司與非ST 公司進行配對,并且進行配對的每組3個公司都處于同一行業或相似行業。我國上市公司t年的年度報會在t+1 年公布,因此上市公司在t+1 年是否被特別處理與其在t年年報公布是同時發生的。此時,若使用公司被ST 前一年的數據來預測當年該公司是否會發生財務危機會夸大模型的預測精度,因此將公司發生危機前兩年的數據作為預測模型的輸入數據。按上述原則,本文選取了2019—2020年新增的177家被ST公司和354家非ST公司作為研究對象,并收集其在2017—2018 年的財務指標數據作為實證分析數據,所有財務指標數據均來自國泰安數據庫。
在文獻[3,23-24]基礎上,本文構建了5個一級財務指標,分別是償債能力指標、盈利能力指標、經營能力指標、發展能力指標、現金流量指標。在一級指標之下提供了25個財務指標。具體指標見表1所示。

表1 財務指標表Table 1 Financial index
由于各公司披露的財務指標不一致,造成有些公司的財務指標存在缺失值。對于部分缺失值,本文采取了均值插補法對缺失值做補值處理。針對財務指標缺失比較嚴重的樣本,本文樣本缺失閾值為30%,當一個樣本缺失值超過閾值時,就刪除這個樣本。統計結果表明樣本數據中沒有缺失值超過30%的樣本,故本文對所有含有缺失值的樣本做補值處理。
2.1.2 財務文本數據的獲取
本文從東方財富網上獲取2017年至2018年相對應的531家上市公司年報,使用正則表達式提取出年報中“經營情況討論與分析”與“審計報告”這兩章節的文本內容進行分析。提取出的財務文本數據為每家上市公司年報中“經營情況討論與分析”和“審計報告”兩個章節中各一條文本信息。其中,提取了“經營情況討論與分析”章節中“概述”一節的內容,而“審計報告”的內容則全部提取,共包含了531條“經營情況討論與分析”的文本數據和531條“審計報告”的文本數據。
2.2 文本特征提取
2.2.1 文本特征提取模型的構建
(1)基于BERT-AE的文本特征提取模型
基于BERT-AE 的文本特征提取模型如圖1 所示。首先通過BERT 模型提取出財務文本特征,再引入AE神經網絡對此文本特征進行降維。該模型在有效提取出財務文本特征的前提下,解決了文本特征維度較高問題。下面分別對文本特征提取模型中兩項關鍵技術(BERT和AE)進行詳細的闡述。

圖1 BERT-AE文本特征提取模型Fig.1 BERT-AE text feature extraction model
(2)BERT模型
BERT 模型采用了雙向Transformer 的Encoder 結構,并舍棄了Decoder 模塊,但模型結構比Transformer更深,這樣便自動擁有了雙向編碼能力和強大的特征提取能力。其結構如圖2所示。

圖2 BERT模型結構Fig.2 BERT model structure
BERT一大優點就是它是一個泛化能力較強的預訓練模型。其訓練主要由兩個階段構成:第一階段為預訓練階段,第二階段為Fine-tuning階段。預訓練階段是在大型數據集上根據一些預訓練任務訓練得到。Fine-tuning階段是利用預訓練好的語言模型,處理具體的下游文本任務,包括命名實體識別、文本分類等。BERT的第一個預訓練任務是Masked LM,其主要目的是讓模型更為全面地根據全文理解單詞的意思。BERT的第二個預訓練任務是NSP(next sentence prediction),其主要目的是讓模型能夠更好地理解句子間的關系。本研究關注的是利用預訓練階段的BERT 模型進行中文文本特征提取任務。在Vaswani 等[20]的論文中,研究者訓練了兩個BERT模型,分別是BERTbase與BERTlarget,二者的區別在于參數量的不同,BERT 發展至今已經增加了多個模型,本文使用了其中的中文預訓練模型,這也是唯一一個非英語的模型。
(3)自編碼器
自編碼器(AE)網絡結構圖如圖3 所示,它由輸入層、隱藏層和輸出層組成,主要包括了編碼(Encoder)和解碼(Decoder)兩部分。自編碼器試圖學習隱藏層中輸入數據的某種表示形式以重構輸出層中的輸入,因此它的輸出與輸入基本相同,是一種盡可能重現輸入信號的神經網絡。此外,自編碼器不需要用于學習特征的標簽,以無監督的方式廣泛用于特征提取,并且自編碼器可以通過編碼操作將高維度的輸入數據映射到低維度的特征編碼,達到降低數據維度的目的。

圖3 自編碼器結構Fig.3 AutoEncoder structure
如圖3 所示,從輸入層到隱藏層對應著編碼功能,它將輸入x映射到潛在表示空間h,其形式為:

其中,f是非線性激活函數,通常是Relu,W和b分別為編碼器的權重和偏置。

其中,g是解碼器的激活函數,W′是權重矩陣,b′是偏置矢量。
為了使解碼重構后的與輸入x一致,相應的損失函數為:

2.2.2 BERT-AE模型提取文本特征
本文財務文本特征提取步驟包括以下四部分,如圖4所示。

圖4 BERT-AE文本特征提取流程Fig.4 BERT-AE text feature extraction process
(1)刪除字母、數字、漢字以外的所有符號。
(2)利用jieba庫對文本進行分詞,然后使用詞頻-逆文檔頻度(term frequency-inverse document frequency,TF-IDF)算法提取反映公司經營情況的關鍵詞。因為BERT 的最大輸入的編碼向量長度為512,分詞以后的詞語較多,所以提取關鍵詞的長度應控制在512范圍內。
(3)使用中文預訓練BERT模型將提取過后的所有文本信息進行編碼,將得到的句子編碼和位置編碼一起作為特征輸入到BERT的雙向Transformer中,最終得到字向量序列S。將Si(Si是S中第i個向量輸出表示)作為全連接層的輸入,對文本信息進行提取,最終得到一個多維文本特征。
(4)為了解決上文提到的文本特征維度過高會引發的問題,本文使用自編碼器(AE)對文本特征進行降維得到最終特征。
關鍵詞提取就是從財務文本里面把跟這篇文本意義最相關的一些詞抽取出來,提取出這篇文本的關鍵詞,就可以大致了解文本要表達的意思。在步驟(2)中,本文使用基于統計的關鍵詞提取方法中最常用的詞頻-逆文檔頻率(TF-IDF)算法對關鍵詞進行提取,TF-IDF算法可以評估某個詞語對于一個語料庫中的某一段文本的重要程度。其中,詞頻(TF)表示某個詞在給定文本中出現的頻率,其表達式為:

其中,Mp,q為詞p在文檔q中出現的次數,Mq為文檔q的總詞數。某個詞的TF值越大,說明這個詞在文檔中出現的次數越多。但并不是一個詞出現次數越多越重要,有一些詞在所有文本中出現的頻率很高,如停用詞,這類詞對某一文本的代表性很差,對于此,引入逆文檔頻率(IDF)對每個詞分配一個“重要性”權重,IDF 表達式為:
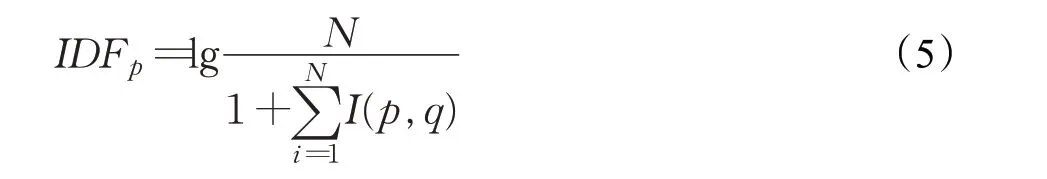
其中,N為所有的文檔總數表示包含某個關鍵詞的文檔個數。
將TF 和IDF 綜合考慮后,便可得到某一個詞在某個文檔中的表征性,TF-IDF定義如下:

TF-IDF算法兼顧詞頻與新鮮度,過濾一些常見詞,保留能提供更多關于公司經營情況的重要詞。本文參照Fan等[25]的做法,對提取的關鍵詞進行詞頻統計,以驗證提取出的關鍵詞能夠反映公司的經營情況。圖5 中(a)和(b)分別為提取的被ST公司和正常經營公司的詞云統計圖,每個詞語在圖中的字體大小與它在模型中出現的頻率成正比。表2為提取的被ST公司和正常經營公司的出現頻率排名前10的關鍵詞。

表2 出現頻率排名前10關鍵詞Table 2 Top 10 keywords in terms of occurrence frequency

圖5 關鍵詞詞云Fig.5 Keyword WordCloud
從圖5及表2可以看出,在被ST公司文本數據提取出的頻率排名前10 的關鍵詞中,出現了虧損、減少、下降等能反映公司出現問題的詞語,而正常經營的公司則出現了實現、增長、提升等能反映公司狀況良好的關鍵詞,這些關鍵詞能在一定程度上反映公司的經營情況。
在步驟(3)、(4)中,文本特征維度的選取對實驗效果至關重要。首先,本文使用BERT提取不同維度的文本特征,再通過自編碼器將不同維度的特征進行降維,同樣的,降維時也選取了幾個不同維度,兩個步驟設置的文本特征維度如下:D1∈{32,64,128,256},D2∈{1,3,5,7}。經過多次實驗比較,最終將D1設置為64,D2設置為1。
進行上述4個步驟的操作后,便可將財務文本數據轉化為富含語義的財務文本特征。以第一條文本為例,第一條文本為一家被ST 公司的財務文本數據,提取了“調整”“虧損”“利潤”“下降”等能夠反映公司經營情況的關鍵詞后,經過BERT-AE 模型便能提取出代表其語義的文本特征數據。提取出的文本特征數據結構如圖6所示,提取的第一條財務文本特征數值為0.678 4。所有文本特征數據的取值在-1和1之間。

圖6 文本特征數據結構示例圖Fig.6 Example of text feature data structure
2.3 數據標準化
將提取出的財務文本數據與財務指標相結合后,為更好了解特征變量分布情況,對特征變量進行描述性統計分析,如表3所示。

表3 特征變量描述性統計分析Table 3 Descriptive statistical analysis of characteristic variables
從表3 中可以看出,利息保障倍數、應收賬款周轉率、存貨周轉率、股東權益周轉率、凈利潤增長率、凈利潤現金凈含量、現金適合比率、營業利潤現金凈含量等指標數據差值較大,為了提高模型擬合速度和擬合精度需要對數據進行標準化處理。Z-score標準化可以將不同量級的數據統一化為同一個量級,使數據的均值為0,方差為1,保證了數據間的可比性,其計算公式如下。

其中,z值代表原始數據與原始數據平均值之間的距離,x為某一具體原始數據,μ為原始數據的均值,σ為原始數據的標準差。
2.4 財務預警模型構建
本文首先基于財務數據指標構建了Logistic 回歸、XGBoost、人工神經網絡(ANN)、卷積神經網絡(CNN)四個財務預警模型。然后分別將BERT-AE融合模型提取出的兩個文本段特征以及兩個文本段特征一起加入財務指標中,作為財務風險預測模型的輸入數據。下面分別對財務風險預警模型進行介紹。
2.4.1 Logistic回歸模型
Logistic 回歸以線性回歸作為理論支持,它可以將回歸的結果通過sigmoid 函數映射到0 和1 之間,因為Logistic回歸具有容易實現、訓練高效的特點,被廣泛運用于兩類分類任務中,其模型為:
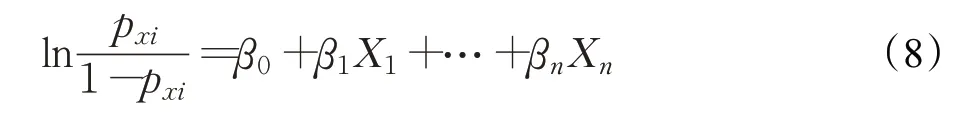
其中,pxi表示事件發生的概率,Xi表示解釋變量。
2.4.2 XGBoost
XGBoost是一種基于梯度提升樹的集成算法,它通過在數據上引入正則化損失函數構建若干個弱評估器,并把這些準確率較低的弱分類器整合為一個準確率較高的強分類器,不僅降低了模型過擬合的風險,還使得其分類表現比單個模型更好。由于XGBoost 使用了預排序、加權分位數、稀疏矩陣識別以及緩存識別等技術,故其擁有可以并行運算、算法的復雜度可控、泛化能力強的優點,其目標函數如下所示:

其中,l代表損失函數,yi表示第i個樣本xi的真實值,表示第i個樣本xi的預測值,fk表示第k棵樹的預測函數。
2.4.3 ANN
人工神經網絡(ANN)是由大量神經元組成的信息響應網絡拓撲,通常一個神經網絡由一個輸入層、多個隱藏層和一個輸出層構成,如圖7所示。

圖7 人工神經網絡結構Fig.7 Artificial neural network structure
Ji表示ANN神經元的輸出,其計算過程可表示為:

其中,wi表示第i個神經元的權重,xi表示第i個神經元的輸入。
2.4.4 CNN
卷積神經網絡與一般神經網絡不同之處在于其基本結構由卷積層、池化層、全連接層堆疊而成,它的結構如圖8所示。
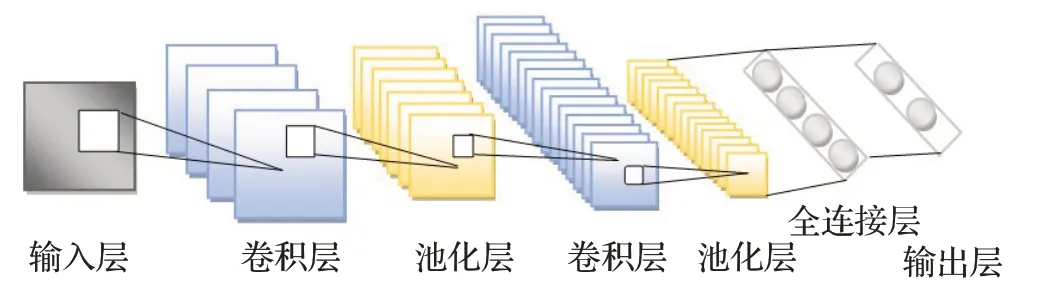
圖8 卷積神經網絡結構Fig.8 Convolutional neural network structure
卷積神經網絡輸入層讀入規則化的圖像后,每一層的每個神經元會抽取一些基本的視覺特征,并通過卷積操作獲得特征圖。卷積層后面連接池化層對卷積結果進行降采樣操作,在減少數據量的同時保留有用的信息。卷積層和池化層通常會交替使用以便獲取更多有用的特征圖,然后將特征圖傳輸到全連接前饋網絡層,實現對提取特征的分類識別。
2.5 對比實驗
采用了Word2Vec-CNN-AE和Word2Vec-LSTM-AE模型提取的文本特征作為對比:
(1)Word2Vec-CNN-AE文本特征提取模型:模型以Word2Vec 訓練詞向量,把詞向量輸入到CNN 中,CNN通過卷積核提取每條數據中詞語的信息,然后通過池化層和全連接層對文本特征進一步提取,最后通過AE 對文本特征進行降維。
(2)Word2Vec-LSTM-AE 文本特征提取模型:模型以Word2Vec 訓練詞向量,然后以LSTM 模型對文本數據再次進行特征提取,之后通過AE 對提取出來的文本特征進行降維。
將Word2Vec-CNN-AE 和Word2Vec-LSTM-AE 模型提取的財務文本特征分別與財務指標結合,驗證提取出的文本特征對財務預警模型的預測精度的貢獻率,并與BERT-AE模型提取的文本特征對財務預警模型的預測精度的貢獻率做對比。
2.6 模型超參數調節
模型的超參數設置能夠影響其預測精度及泛化能力,應根據不同模型的特點對其參數進行調節,找出最優的參數組合,進而得到最優預測結果。
對于Logistic 回歸模型,本文設置的參數為學習率和最大迭代次數。因為Logistic回歸利用最小二乘法求解,容易出現過擬合問題,所以本文引入了L1 與L2 正則化對最小二乘法進行優化,提高分類器的預測精度。對于XGBoost 模型,本文設置的超參數為弱學習器個數、正則化參數、學習率和樹的最大深度。對于ANN模型,本文設置的超參數為隱層節點數、優化器、批大小和epoch。對于CNN模型,本文設置的超參數為隱層節點數、卷積核個數、優化器、批大小和epoch。各模型備選參數如表4所示。

表4 模型備選參數Table 4 Model candidate parameters
對于Logistic 回歸與XGBoost,本文使用了網格調參法對加入文本特征前后模型的所有參數進行了調節,確定所有參數的最優組合。對于ANN 與CNN,先保持其他參數不變,對其中一個參數運用網格調參法進行參數調節,依次確定模型的最優參數。
2.7 模型評價指標
2.7.1 真正例率和假正例率
本文采用AUC 指標對模型進行評價,并繪制出模型的ROC曲線。在介紹ROC與AUC之前,先介紹真正例率(TPR)和假正例率(FPR)的概念。
在一個二分類問題中,可以根據真樣本數據真實所屬類別與模型結果組合分為真正例(TP)、假反例(FN)、假正例(FP)、真反例(TN)四種情況。令TP、FN、FP、TN分別表示其對應的樣例數,可得到如表5的混淆矩陣。

表5 混淆矩陣Table 5 Confusion matrix
有了混淆矩陣之后,可以定義真正例率(TPR)和假正例率(FPR)為:

2.7.2 ROC曲線和AUC值
ROC的全稱是Receiver Operating Characteristic曲線,其以FPR 為橫軸,TPR 為縱軸繪制而出。模型預測性能的好壞可以通過ROC 曲線表現出來,它越靠近左上角,表明模型的性能越好。如果有A模型和B模型,A模型的ROC 曲線能完全“包住”B 模型的ROC 曲線,則可斷言A 模型比B 模型擁有更好的泛化能力。但是兩個模型的ROC 往往是相交的,這時為了比較兩個模型的性能就需要用到AUC。AUC 的全稱是Area Under Curve,是ROC曲線和x軸(FPR軸)之間的面積。因為AUC 綜合考慮了分類器對正樣本和負樣本的分類能力,所以當樣本數據不平衡時,分類器仍然能夠做出合理的評價。
3 實證結果與分析
本文將531個樣本按7∶3的比例劃分訓練集和測試集,用訓練集訓練模型,最后在測試集上對模型進行驗證評估。本文首先使用了上市公司的財務指標數據作為模型輸入變量對財務風險進行預測,然后在財務指標數據中加入BERT-AE 提取的財務文本特征,并將加入文本特征后的實驗數據分為三組,分別放入模型之中進行財務風險預測。第一組為加入“經營情況討論與分析”文本特征的數據(F1),第二組為加入“審計報告”文本特征的數據(F2),第三組為加入兩個文本特征的數據(F1+F2),每組原始數據均為上述財務指標數據。同樣的,對比實驗也將進行上述的實驗流程。
3.1 特征重要性分析
為了分析文本特征對財務預警模型的預測精度是否會產生影響,本文以BERT-AE 提取的財務文本特征為例,使用XGBoost模型對加入文本特征前后的數據指標進行特征重要性分析,并作出XGBoost模型的特征重要度排序圖,如圖9 所示。其中,(I)為基于財務指標數據的特征重要度排序圖,(II)為加入“經營情況討論與分析”文本特征(F1)的特征重要度排序圖,(III)為加入“審計報告”文本特征(F2)的特征重要度排序圖,(IV)為加入兩個文本特征(F1+F2)的特征重要度排序圖。
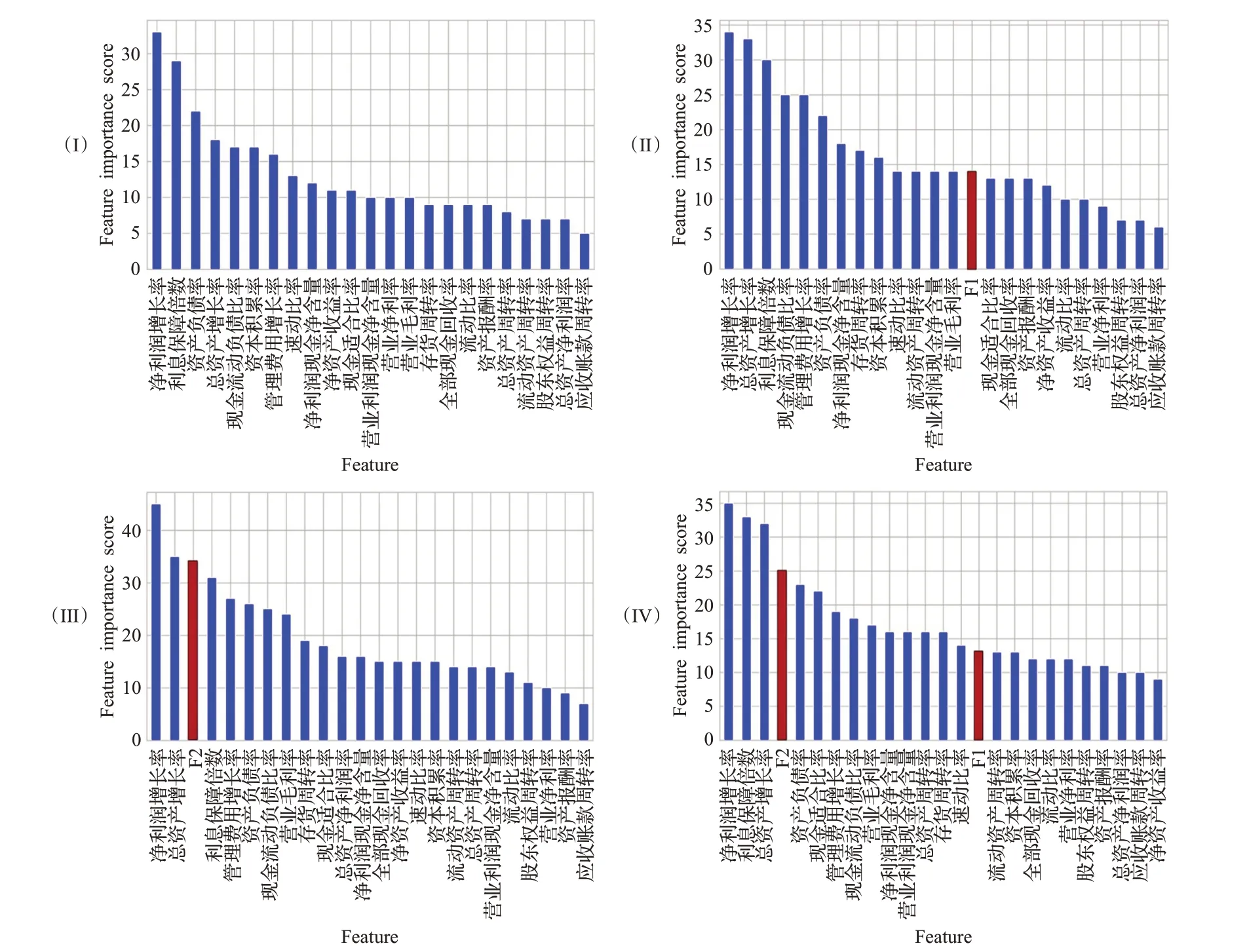
圖9 XGBoost模型的特征重要度排序Fig.9 Feature importance ranking of XGBoost model
從(II)、(III)、(IV)中可以看出,在包含“F1”的26個特征變量中,“F1”對預測結果的重要性位列第14;在包含“F2”的26 個特征變量中,“F2”對預測結果的重要性排名第3;在包含“F1”和“F2”的27 個特征變量中,“F1”與“F2”對預測結果的重要性排名分別為第4 和第15。以上結果表明本文提取的文本特征能夠對財務預警模型的預測精度產生影響。
3.2 財務預警模型實驗結果分析
為了進一步分析文本特征對財務預警模型預測精度的影響,本文基于財務指標數據,將加入文本特征前后財務預警模型預測的AUC 值進行比較。得到的3 個實驗具體的AUC值如表6所示,ROC曲線如圖10所示。

圖10 加入財務文本特征前后財務預警模型的ROC曲線Fig.10 ROC curves of financial early warning model before and after adding financial text features

表6 加入文本特征前后財務預警模型的AUC值Table 6 AUC value of financial early warning model before and after adding text features
3.2.1 基于財務指標數據預警模型結果與分析
通過將只放入財務指標數據的4 個預警模型在測試集上預測結果進行對比發現,Logistic 回歸模型得到的AUC 值最低,為0.829 4。在兩種深度學習模型中,ANN模型得到的AUC值優于CNN模型,為0.851 1。而XGBoost模型表現優于兩個深度學習模型和Logistic回歸模型,得到了最高的AUC值。
在基于財務指標的預警模型中可以發現,相對于深度學習模型而言,傳統機器學習算法XGBoost模型預測效果更好,原因可能是在樣本較少的情況下,傳統的機器學習算法預測性能更優。在大量的標注訓練數據下,
深度學習模型才能取到較好擬合效果,正如宋歌等[9]使用深度學習網絡構建預警模型時發現,財務數據樣本越多,模型預測準確率越高。
3.2.2 基于財務數據與財務文本預警模型結果與分析
由表6可以看出,BERT-AE模型提取的財務文本特征對4 個財務風險預警模型預測精度的貢獻度大于Word2Vec-CNN-AE和Word2Vec-LSTM-AE模型提取的文本特征的貢獻度。在4個財務預警模型中加入BERTAE模型提取的財務文本特征后,預測的AUC值提升最高,且4個財務預警模型的AUC提升值均大于1個百分點,其中CNN 的AUC 值提升均達到最大,分別為3.64個百分點、3.35個百分點和3.93個百分點。在BERT-AE模型提取的財務文本特征后加入財務指標的實驗中,XGBoost 模型仍得到最高的AUC 值,分別為0.895 0、0.893 6和0.896 1,由此可見,使用BERT-AE模型提取的財務文本特征作為輸入變量的XGBoost 模型具有更優的預測性能。
綜上所述,在三組對比實驗中,加入BERT-AE模型提取的財務文本特征后,預警模型的性能得到最好的增強。這表明使用BERT-AE融合模型能從公司年報中提取出有用的文本特征,將此特征用于公司財務風險預測模型中能夠顯著提高模型的預測精度。
3.3 加入文本特征后模型提升效果的橫向對比
在Matin等[3]的研究中,其使用CNN-RNN(用NN表示)構建神經網絡預測財務風險,然后將提取出來的審計報告文本特征、管理層聲名文本特征以及兩種文本特征與財務指標結合,分析文本特征是否會提升模型預測精度,最后結果如表7所示。表中,NN指無文本的神經網絡,NNaud指帶有審計報告文本特征的神經網絡,NNman指帶有管理層聲名文本特征的神經網絡,NNaud+man指帶有審計報告和管理層聲名文本特征的神經網絡。

表7 Matin等人財務預警模型實證結果Table 7 Empirical results of Matin et al’s financial early warning model
從表7中可以看出,NNaud、NNman、NNaud+man的AUC值提高了1.9 個百分點、1.1 個百分點和1.8 個百分點。而本文的CNN 模型加入BERT-AE 提取的三種文本特征后AUC 值的提升分別為3.64 個百分點、3.35 個百分點和3.93個百分點,再次表明本文構造的BERT-AE融合模型能更為有效地提取財務文本特征用于財務風險預測。
4 結論與啟示
本文在已有研究的基礎上對文本信息的提取進行了方法上的創新,使用BERT網絡提取上市公司年報中“經營情況討論與分析”和“審計報告”的文本特征,并利用AE 網絡對提取出的文本特征進行降維處理,最后將AE網絡輸出的結果加入財務數據之中對上市公司財務風險進行預測。研究結果顯示,相較于沒有引入文本特征的財務預警模型,帶有“經營情況討論與分析”“審計報告”以及兩種文本特征模型的AUC 值均有不同程度的提升,其中帶有兩種文本特征的CNN模型將AUC值提高了3.93個百分點,且帶有“經營情況討論與分析”的模型比帶有“審計報告”的模型擁有更高的預測精度,說明“經營情況討論與分析”比“審計報告”提供的信息更多。此外,通過對比實驗和與其他學者的研究相比較,本文使用BERT-AE模型提取的財務文本特征使得財務預警模型提升效果表現更優,表明本文構造的BERTAE融合模型能更為有效地提取財務文本特征用于財務風險預測。
在今后的工作中,可以引入更多的文本變量,如公司年報中其他章節的內容、公司研報、財經新聞、投資者評論等,更好地分析不同文本內容對上市公司財務風險預測的影響,提升模型的預測精度。此外,本文的研究方法不僅能夠在上市公司財務風險預測中得到更好的運用,也可將其運用于其他研究領域,如股價預測、信用反欺詐等之中。
猜你喜歡
現代企業(2021年2期)2021-07-20 07:57:18
現代經濟信息(2020年34期)2020-06-08 06:02:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
意林·全彩Color(2019年9期)2019-10-17 02:25:48
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
河南水利年鑒(2017年0期)2017-05-19 02:29:27
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
