基于輕量型網絡的唇紋識別算法研究
2022-03-06 11:56:02周洪成
鹽城工學院學報(自然科學版) 2022年4期
周洪成 ,韋 靜,2,牛 犇
1.金陵科技學院 電子信息工程學院,江蘇 南京 211169;2.鹽城工學院 機械工程學院,江蘇 鹽城 224002
唇紋除了作為身份識別工具和法庭證據外,還可以用于刑事偵查,作為生物特征識別信息的來源[1]。唇紋特征信息豐富,包括直線型、曲線型、分叉型、網狀型和不規則型等紋理特征,而且唇紋隱蔽性好,不易被復制和仿造,具有唯一性、永久性和穩定性的特點,是人類身份識別的重要生物特征。唇紋識別作為新興的生物特征識別技術,與其他的生物識別技術相比具有識別率高、識別時間短、用戶接受度高、非接觸式采集等優勢[2]。
在科學技術不斷創新和發展的背景下,唇紋識別技術得到了快速發展,國內外學者相繼提出了唇紋識別算法。Bhattacharjee 等[3]提出了一種統計分析方法,將測試樣本數據集和參考樣本數據集與閾值進行比較和匹配,獲得了96%的識別率。Wrobel等[4]通過提取嘴唇截面進行比較的方法來進行唇紋識別,對45張唇紋圖像進行實驗得到85.1%的識別率。2015 年Wrobel 等[5]又提出基于唇紋分叉分析的識別方法,在120 張唇紋數據集上獲得了77%的識別率。許穎[2]提出基于改進Gabor特征提取的唇紋識別方法。2018年Wro?bel 等[6]引入唇紋皺紋分析,建立基于唇紋皺紋模式的分類識別,在350 張唇紋圖像上得到了92.73%的識別率。Sandhya 等[7]構建了基于機器學習算法的唇紋識別系統,采用支持向量機、K 近鄰、集成分類器和神經網絡等分類算法進行實驗,最終集成分類器在120 張圖像數據集上取得了97%的識別率。上述識別算法雖已獲得了較好的識別效果,但算法中存在圖像預處理過程復雜、特征提取算法效率較低等問題,導致識別周期較長,識別率較低。
隨著信息技術的發展,深度學習逐漸受到廣大研究者的關注,卷積神經網絡得到了快速發展,并成功地應用于計算機視覺和自然語言處理等領域。近年來,基于卷積神經網絡模型的圖像識別方法在各類生物特征識別領域都取得了較大的成功和快速的發展,如人臉識別[8]、掌紋識別[9]、指紋識別[10]、步態識別[11]等,所以將卷積神經網絡模型應用于唇紋識別技術領域是未來研究的重點。
1 卷積神經網絡
卷 積 神 經 網 絡(convolutional neural net?works, CNN)是一種包含卷積運算且具有深度結構的前饋神經網絡,網絡結構包括卷積層、池化層和全連接層。作為深度學習代表算法之一,卷積神經網絡具有表征學習能力,能夠按照其階層結構對輸入圖像進行平移不變分類,并可應用于圖像分類任務的圖像特征提取,不需要再設計復雜的算法提取特征。通過卷積運算操作進行圖像特征提取,池化層進行下采樣操作,降低數據維度,減少網絡訓練參數,全連接層則用于解決分類問題。
1.1 卷積層
普通神經網絡的結構包括輸入層、隱藏層和輸出層。隱藏層的神經元之間以全連接的形式連接,這樣會造成網絡訓練時參數量過多,網絡訓練效果不佳。卷積神經網絡與普通神經網絡的區別在于,其卷積層中一個神經元與部分的鄰層神經元連接。卷積層具有局部連接和共享權值的特性,大幅降低了網絡訓練參數。網絡訓練過程中卷積核與輸入圖像的不同區域作卷積運算,通過學習得到合理的權值并不斷更新,最后提取到不同的特征信息。卷積層的核心是使用不同尺寸的卷積核對圖像進行卷積運算,提取圖像中的特征信息,常用的卷積核大小包括3×3、5×5和7×7。
1.2 池化層
當卷積層提取了圖像的特征信息,下一步是利用這些特征信息進行分類識別。理論上能夠直接使用所提取的特征來訓練分類器,但會面臨大量參數計算的挑戰,并且網絡模型容易產生過擬合現象。為解決這個問題,在卷積層的下一層使用池化層處理卷積層的輸出結果,即計算圖像一個區域上某個特定特征的最大值或平均值,也稱下采樣操作。常見的池化操作包括平均值池化、最大值池化、重疊池化和空金字塔池化。由于最大值池化操作的表現較好,所以在深度卷積神經網絡中使用較多,圖像區域的大小由下采樣窗口的大小決定,常用的有2×2和3×3。
1.3 全連接層
通過使用若干個卷積層和池化層交替連接,完成特征提取的工作,使得卷積神經網絡的訓練參數大幅度降低,不僅減少了參數計算量,還能夠縮短訓練時間、提高特征的魯棒性。全連接層的作用是連接提取的所有特征,全連接層將卷積層和池化層提取特征后輸出的特征圖中的特征信息進行整合,映射為固定長度的一維特征向量,該特征向量包含了輸入圖像的所有特征組合信息,再將特征向量輸出至分類器用于圖像分類。
2 基于LNet-6的唇紋識別算法
2.1 Softmax分類器
實驗涉及多分類問題,因此所選取的分類器為Softmax,將其放在卷積神經網絡的全連接層作為網絡結構的一部分。Softmax 層的工作原理是針對全連接層輸出的一維向量x,計算該向量屬于第j類的概率值,再將其歸一化處理,保證概率值和為1,輸出結果即表示x屬于某一類的最大概率值。Softmax 函數如式(1)所示,將輸入圖像所屬類別的最大概率值輸出。
式中,xj表示分類器上一層輸出單元的輸出;j表示類別數;k為總的類別數;而fj(x)表示當前元素的指數與所有元素指數和的比值。經過公式計算將多分類輸出數值轉化為相對概率,計算出一維向量x屬于第j類的概率值,并在指數域歸一化映射為[0,1]之間的概率值,最大的概率值輸出就是所屬的類別。
2.2 基于LNet-6的識別算法
2012 年Krizhevsky 等[12]提出的AlexNet 網絡在ImageNet 大賽上獲得了冠軍,使得深度學習受到了廣泛關注。為提升網絡模型的實用性,本文借鑒了該網絡結構,搭建一個輕量型卷積神經網絡LNet-6(lightweight network-6),它包含6 個卷積層(C1~C6)、5 個池化層(M1~M6)、2 個全連接層(FC1、FC2)和一個Softmax 層。在卷積層與池化層之間添加了批量歸一化層,使訓練和測試數據同分布,提高模型的泛化能力和穩定性。使用ReLU激活函數解決梯度消失和梯度爆炸的問題,加快網絡的訓練收斂速度,使用該網絡模型對唇紋數據集進行特征提取和分類識別。與經典的深度卷積神經網絡模型相比,該模型具有參數計算量少、模型文件小和可移植性強等特點,其網絡結構如圖1所示。卷積層和池化層交替連接構成特征提取器,采用5×5大小的卷積核,池化層的下采樣窗口大小設置為2×2,通道數就是卷積核的數量,也是輸出結果特征圖的個數。該網絡結構的各層詳細參數如表1所示。
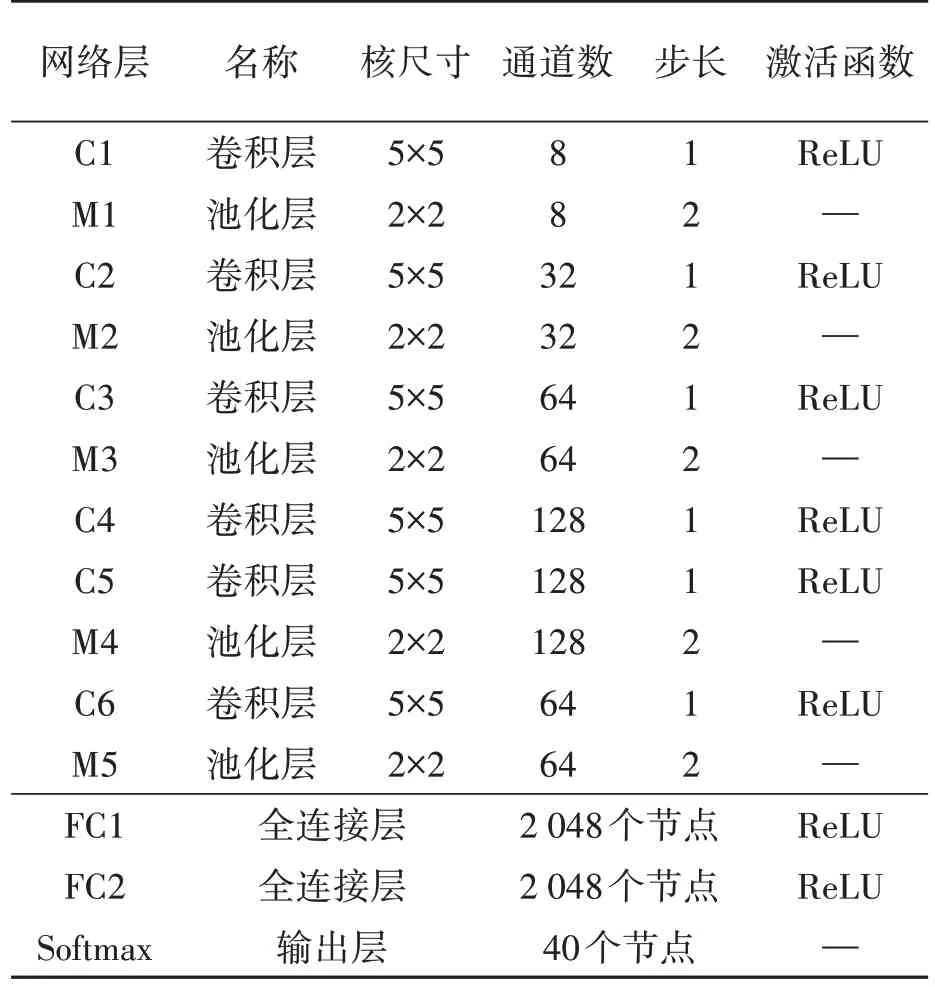
表1 網絡各層結構信息Table 1 Information on the structure of each layer of the network
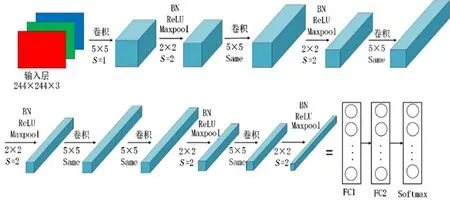
圖1 LNet-6網絡結構Fig. 1 LNet-6 network structure
基于LNet-6的唇紋識別算法詳細描述如下:
由于采集的圖像均是RGB 三通道的彩色圖像,卷積運算過程是多通道卷積,固定輸入圖像大小為244×244。
C1層使用8個5×5大小的卷積核,以步長為1滑動卷積核窗口計算,提取圖像的特征信息,得到8 張240×240 的特征圖;M1 層使用最大值池化操作對圖像特征信息進行數據處理,降低網絡訓練參數,保證特征的尺度不變性,提高算法的性能和魯棒性,下采樣的窗口大小為2×2,以步長為2 從左往右、從上往下的順序滑動采樣窗口,該過程既不參與權值更新也不改變通道數,輸出結果為8 個120×120 的特征圖;卷積層與池化層輸出特征圖的計算過程分別如下式所示:
式中,O1、O2分別表示卷積層和池化層的輸出大小;I表示輸入大小;K為卷積核大小;P為填充值;S為步長;Ps則是下采樣窗口的大小。可以根據公式計算每一層的輸出結果。
C2層則使用32個5×5大小的卷積核,設置邊緣填充方式為Same,經過卷積運算后輸出32 張120×120 的特征圖;M2 層的下采樣操作與M1 層處理過程相同,將卷積層的輸出結果映射為32個60×60 的特征圖;C3 層增加了卷積核數量,使用64 個5×5 大小的卷積核,以步長為1、邊緣填充方式為Same進行卷積運算,輸出64個60×60的特征圖;M3層將卷積層提取的特征映射為64張30×30的特征圖。不斷增加卷積核數量,使網絡能夠提取更多的唇紋特征信息;C4 層和C5 層各項參數相同,都采用128 個5×5 大小的卷積核,輸出結果都是128 個30×30 的特征映射;M4 層則是以2×2的采樣窗口將卷積層的輸出結果轉換為64張15×15的特征圖;而C6層使用了64個卷積核,邊緣填充方式為Same,也得到了64 張15×15 的特征圖;通過M5層的下采樣操作,以步長為2滑動采樣窗口,將上一層輸出的特征圖映射為一個7×7×64的二維特征矩陣。
全連接層FC1將上一層輸出的二維特征矩陣平鋪成一個7×7×64 的一維特征向量,采用Drop?out方法[13]隨機丟棄了部分神經元,使其中的一部分神經元失活,將其中的2 048 個神經元進行一個全連接,即輸出特征圖單元數為2 048。FC2 層輸入的神經元個數為2 048,輸出2 048 個特征圖單元。使用Softmax 分類器作為輸出層,將2 048個節點映射為40個分類標簽對應的概率值。
3 唇紋分類識別實驗
3.1 實驗環境與數據集
實驗基于TensorFlow 框架,在Pycharm 2020平臺上運行,所用硬件設備的系統版本為Win?dows 10,處理器則是Intel? Core(TM) i7-7500U,顯卡為NVIDIA GeForce 930MX,運行內存8 GB。由于接觸式采集方法的用戶接受度較低,且獲取的圖像質量取決于按壓力的大小和方向,易受人為因素影響,對識別結果會產生一定程度的影響。因此,實驗使用的唇紋數據集是由作者拍攝的,采用了非接觸式采集方式獲取圖像,每張圖像都是在自然光照條件下拍攝的。該數據集來自40 位志愿者,每名志愿者采集了30 張唇紋圖像,分別保存至帶有分類識別標簽的文件夾下。通過簡單的數據增強方法如旋轉、加噪聲、鏡像、模糊和改變圖像亮度等,擴充該數據集。實驗采用了旋轉、鏡像、加入高斯噪聲和增加圖像亮度的方法,將1 200 張唇紋圖像擴充為8 000 張的數據集,每個志愿者都有200 張圖像。訓練集將用于訓練唇紋識別模型,而測試集則用于檢測模型的識別率。圖2 所示為該數據集的部分唇紋圖像。

圖2 部分唇紋圖像Fig. 2 Part of the lip-print images
3.2 網絡模型訓練實驗
實驗將8 000 張唇紋圖像按照一定的比例隨機地分為訓練集和測試集,并在數據集輸入網絡訓練前,統一將唇紋圖像等比例縮小為244×244大小。分類識別標簽使用one-hot編碼格式,隨機打亂標簽數據。然后將已建立的唇紋數據集輸入LNet-6網絡,使用Adam 優化算法訓練,設置網絡中的各項參數進行網絡模型訓練和測試。數據集的劃分和學習率的選取都將會影響模型的識別效果,多次調整網絡的參數訓練模型,并使用可視化函數繪制出測試集識別率的分布圖,觀察分析實驗結果以達到預期的識別率。因此,研究各因素對模型識別性能的影響,進行了如下實驗。
3.2.1 學習率對模型識別性能的影響
在使用梯度下降算法優化網絡訓練時,學習率是一項重要的參數,實驗將固定其他各項參數,設置不同的學習率進行訓練,分析學習率對識別性能的影響,最終得到最佳的識別模型。考慮硬件設備的內存資源,避免輸入數據太大降低訓練速度,將數據集以8∶2 的比例隨機分為訓練集和測試集。網絡訓練迭代次數epoch 設置為50,批量大小batch 設置為80,即每一步將輸入80張圖片進行訓練,保持其他各項參數。選擇不同的學習率進行訓練,得到如表2所示的結果,訓練時間為完成一次訓練所用的時間,識別時間則是模型每一步預測的時間,識別率是使用模型預測的最后10次迭代的識別準確率計算的平均值。
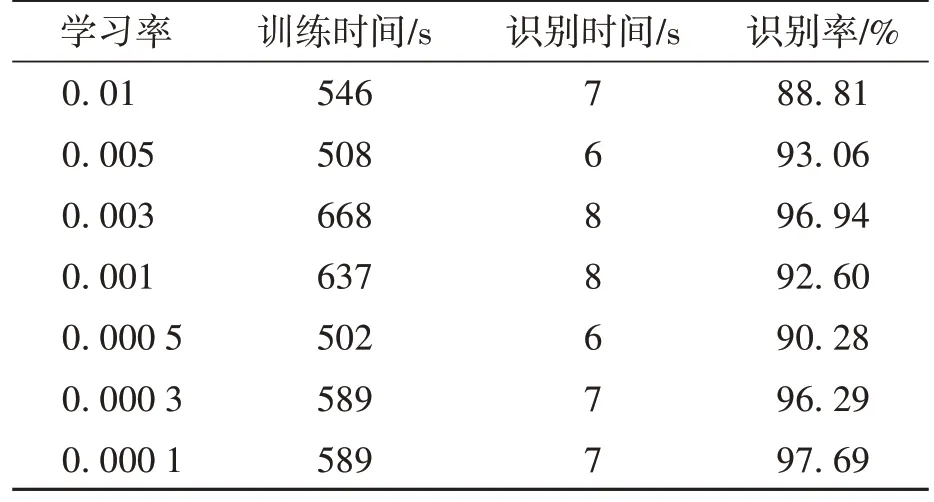
表2 不同學習率的識別結果Table 2 Recognition results with different learning rates
3.2.2 數據集的劃分對模型識別性能的影響
為研究數據集的劃分對模型的識別性能的影響,按照不同的比例劃分數據集,分別使用常用的9∶1、8∶2 和7∶3 的比例劃分為訓練集和測試集。學習率設置為0.000 1,訓練次數為50,batch大小為80且保持其他參數不變,將不同大小的數據集輸入網絡進行訓練。識別率選取最后10 次預測準確率的平均值,得到的實驗結果如表3所示。
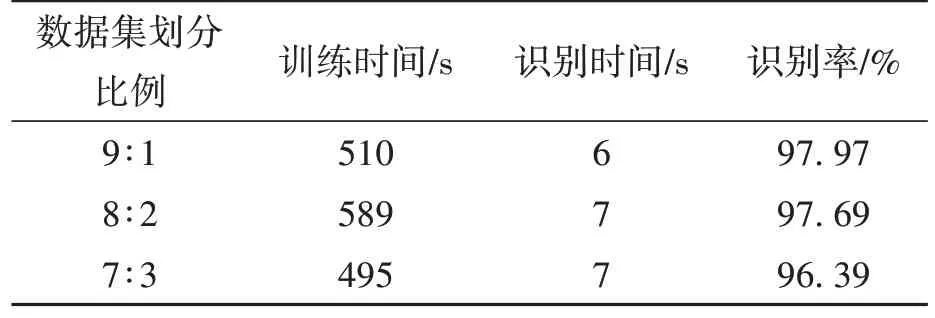
表3 不同比例劃分數據集的識別結果Table 3 Recognition results for different scaled data sets
3.2.3 比較不同卷積神經網絡的識別效果
比較不同網絡結構對唇紋數據集的識別性能,實驗選取了AlexNet、VGG[14]、GoogLeNet[15]和ResNet[16]等經典的深度卷積神經網絡,使用9∶1劃分的數據集訓練識別模型,將學習率的大小設置為0.000 1,訓練次數為50,batch 大小為80,其余各項參數保持不變。輸入數據集進行網絡模型訓練,加載模型并輸入測試集識別,識別率選取最后10次預測準確率的平均值,不同網絡的識別結果如表4所示。
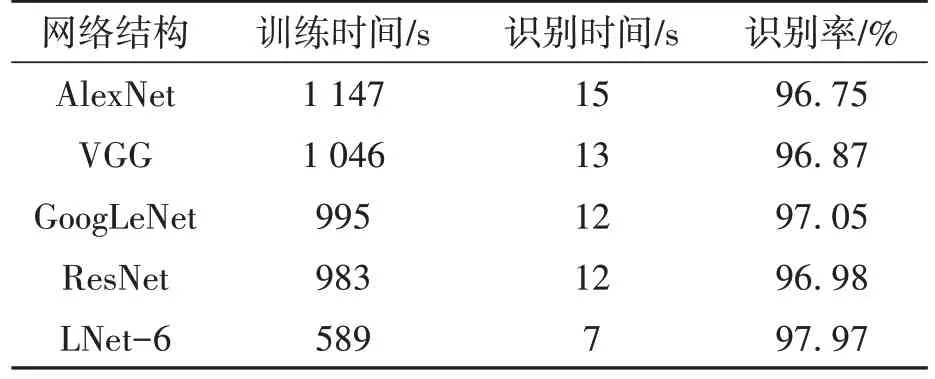
表4 不同網絡的預測識別結果Table 4 Prediction recognition results of different networks
3.3 實驗結果分析
由表2 和表3 的實驗結果可以看出,不同的學習率對模型識別效果影響較大,當使用較大學習率時,測試集的準確率都有所下降,模型泛化能力較低且不穩定;不同的比例劃分數據集對模型的識別效果影響甚微,當數據集以9∶1 比例劃分和學習率為0.000 1 時識別效果達到了最佳,在測試集數據中獲得了97.97%的平均識別率。
從表4 中可以看出,與其他深度卷積神經網絡模型識別結果相比,基于LNet-6 網絡的訓練和識別時間較短,模型文件較小,模型的平均識別率較高。通過比較不同網絡模型的識別效果發現,深度卷積神經網絡對唇紋數據集的識別率相對較低,且耗費了大量的計算資源,難以將模型應用到實際的終端設備。
通過分析上述實驗結果發現,基于LNet-6 的識別模型對唇紋圖像的識別效果較好,不僅簡化了唇紋圖像前期預處理過程,還避免了設計復雜的特征提取算法,結合特征提取和分類過程,實現了自動地提取唇紋特征和分類。
4 結論
本文提出的基于卷積神經網絡的唇紋識別算法,為唇紋識別技術提供了一種新的思路,與傳統的識別算法相比,其優勢在于可以直接輸入采集的原始唇紋圖像,簡化了圖像預處理過程;實現了自動提取唇紋特征信息,克服了人工設計算法進行特征提取困難的問題;通過網絡訓練獲得輕量型唇紋識別模型,解決存儲空間的限制,滿足速度的要求,提升網絡的實用性,精簡復雜的深度學習模型使其能夠高效地在移動端運行;實驗設置了不同的學習率進行網絡訓練,分析和對比學習率對識別性能的影響,最終在測試集上獲得了97.97%的識別率。進一步的研究將會從以下幾個方面進行:(1)采集唇紋圖像,建立包含更多人的數據集;(2)結合遷移學習的優勢,使用預訓練模型對數據集分類識別,提升識別效率;(3)進一步改進算法和優化網絡結構,提高模型的泛化能力和識別率,并使用高性能GPU 訓練識別模型,縮短模型預測識別的時間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
