電網公司針對互聯網企業投建光伏電站的應對策略
2022-03-08 09:23:14趙玉琢張延遲
上海電機學院學報 2022年1期
關鍵詞:用戶
趙玉琢,張延遲
(上海電機學院電氣學院,上海 201306)
能源互聯網概念的提出和電力市場的開放,促使更多的技術和資本涌入能源市場,其中大型互聯網企業參與能源行業跨界競爭的行為值得引起關注。隨著能源互聯網概念[1]的提出,各種新生事物不斷涌入能源市場,各大互聯網企業阿里巴巴、騰訊、百度等以及通信企業華為紛紛試圖進軍電力能源行業,參與能源行業跨界競爭。除了與電網進行合作以外,互聯網企業在其他能源領域也有大量布局。綜合來說,各大互聯網企業均有參與能源行業的趨勢及舉措,向“能源互聯網新業態”發展,促進自身的多元化,這些客戶導向思維的互聯網企業試圖向能源領域進軍。傳統的電網企業是典型的資產驅動型企業,隨著國民經濟的飛速發展,不斷衍生出多種新生事物,社會處于轉變發展方式、優化經濟結構的攻關期。目前,電網的發展面臨著能源技術發展的挑戰以及新業態的競爭。據國家統計局發布的國民經濟和社會發展統計公報,2014年以來,我國電力生產行業總發電量呈現穩步增長趨勢。2015年3月,《中共中央國務院關于進一步深化電力體制改革的若干意見》[2]的發布實施,標志著中國開始對新一輪電力體制改革進行全面部署[3]。此次改革以“管住中間、放開兩頭”為核心,發布6個核心配套文件,有序向社會資本放開配售電業務,并進行進一步的電力市場建設以及電價改革[4]。鑒于目前電網面臨形勢的變化,為保證電力公司體系的高效運轉,電網公司提出“三集五大”的大運行體系,建設大規劃、大建設、大運行、大檢修、大營銷五大體系[5]。改革在不斷推進,新能源技術以及新一代信息通信技術也在不斷發展。“能源”與“互聯網”融合的設想一經提出便引起了國內外研究者的高度關注,這一設想給中國能源產業帶來了重要的機遇與挑戰[6]。能源互聯網具備新型高效智能電網結構,由大量分布式能源應用單元組合而成,利用儲能設備及能源管理系統解決不穩定輸出的問題[7]。本文提出了一種電網公司應對互聯網企業跨界競爭的策略方法,其中包括建立基于Spark框架的電力服務平臺,利用近鄰傳播(Affinity Propagation,AP)聚類法[8]分析用戶行為,并基于遷移學習[9]進行負荷預測以增強用戶黏性。
1 互聯網企業投建光伏電站
能源互聯網以電為中心,利用電力電子技術及信息技術智能分配能量與信息,實現實時監管以及快速調度。圖1為能源互聯網結構圖。
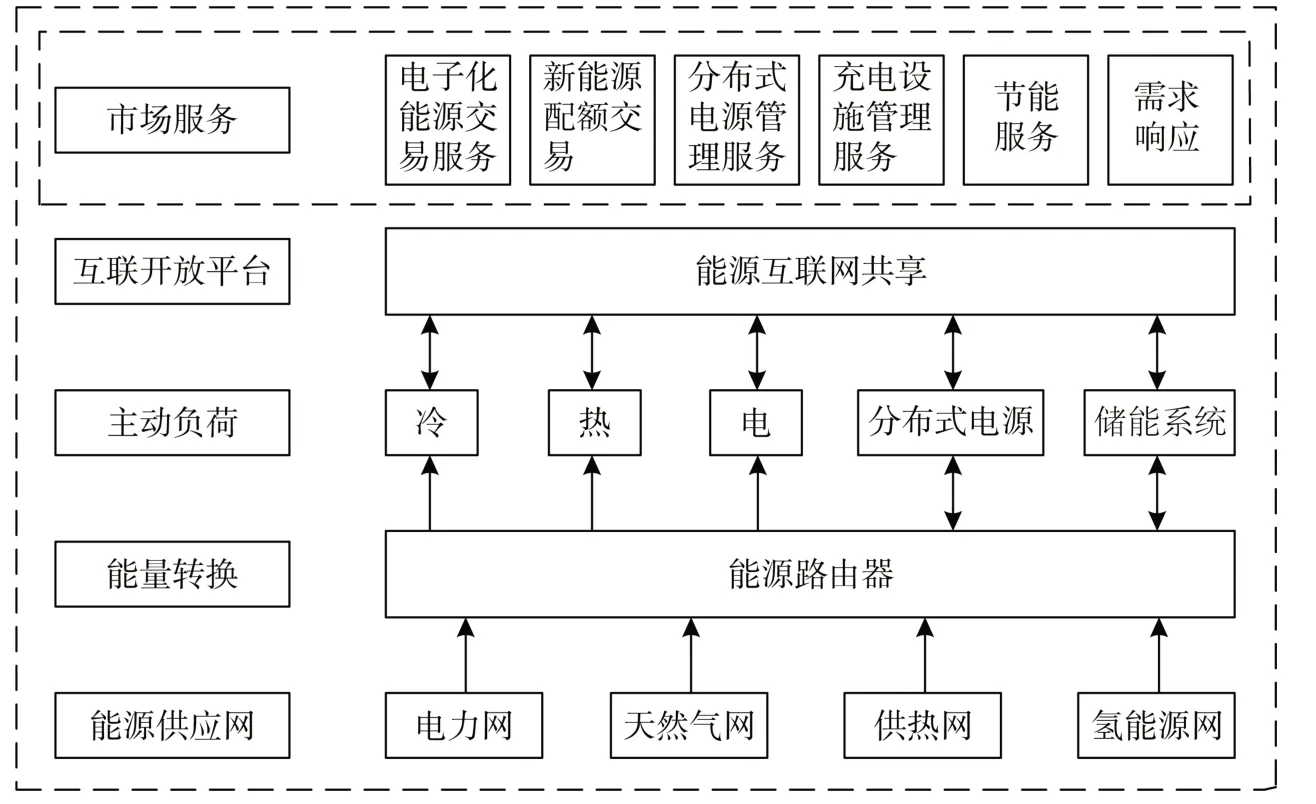
圖1 能源互聯網結構圖
目前,國內的互聯網巨頭阿里巴巴、百度、京東等主要投建了小范圍內的屋頂光伏電站。國外的亞馬遜電商在全球范圍內所投資的與新能源相關的項目已達206個,其中包括風電、光伏等項目[10]。光伏電站是通過接入主干電力網向電力網輸送電力的發電系統[11],能源企業對光伏電站的投資建設主要側重于項目的設計。相比能源企業,互聯網企業投建光伏電站的不同之處在于其切入點為數據和系統,將光伏產業與云端服務相結合,形成“互聯網+新能源電站”的運行模式。
1.1“互聯網+光伏電站”
互聯網企業的技術優勢在于云計算,大數據云計算服務能夠高效地處理、分析海量數據,具備數據的存儲和計算等功能[12]。以阿里巴巴在菜鳥物流園區投建的屋頂光伏電站為例,因其分布式的特點,數據會以一種離散的形式進行存儲。大量的數據分布在不同的存儲節點上,若任意存儲節點失效,利用其他存儲節點完成數據存儲的接力。通過極值過濾、異常值過濾、數據插值及校正等措施對實時數據進行數據監測處理,預測未來的數據。高預測精度且功能完備的功率預測系統對新能源電站的運行至關重要。對數據進行采集、存儲、監測、預測,可實現居民電力的可靠使用。圖2所示為增城物流園區屋頂光伏電站基于大數據的能源交易流程圖。
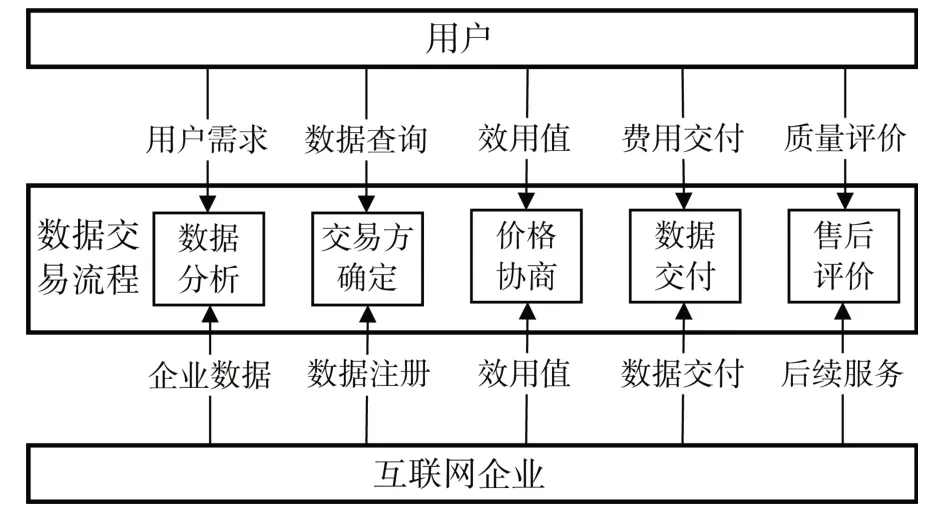
圖2 數據交易模型
用戶與互聯網企業通過價格協商進行數據交易,商業樓與居民樓的用電需求及對數據質量要求不同,需分析用戶的數據屬性特征并實施多屬性協商機制,交易對象為
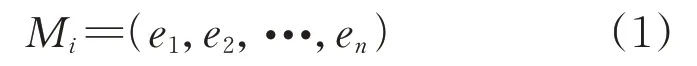
式中:Mi為數據價格協商的對象;(e1,e2,···,en)為屬性向量,n表示對象屬性數量。
在交易對象中,存在的n個屬性可表示為(E1,E2,···,En),其中的元素取值范圍是(Ei,min,Ei,max)。為體現不同交易方的滿意度,以效用值衡量,定義正屬性代表交易雙方均滿意,且取值越大,滿意程度越高;負屬性代表交易雙方不滿意,且取值越大,滿意程度越低。根據滿意程度制定合適的協商定價機制。
1.2 運營模式
分布式光伏具備就地消納,運輸成本低等特點[13]。目前,互聯網企業對光伏電站的投資多集中于屋頂分布式光伏。以阿里巴巴投建的菜鳥增城園區屋頂光伏電站為例,采用了“自發自用,余電上網”的并網方式,滿足了自身的用電需求,其并網方式如圖3所示。
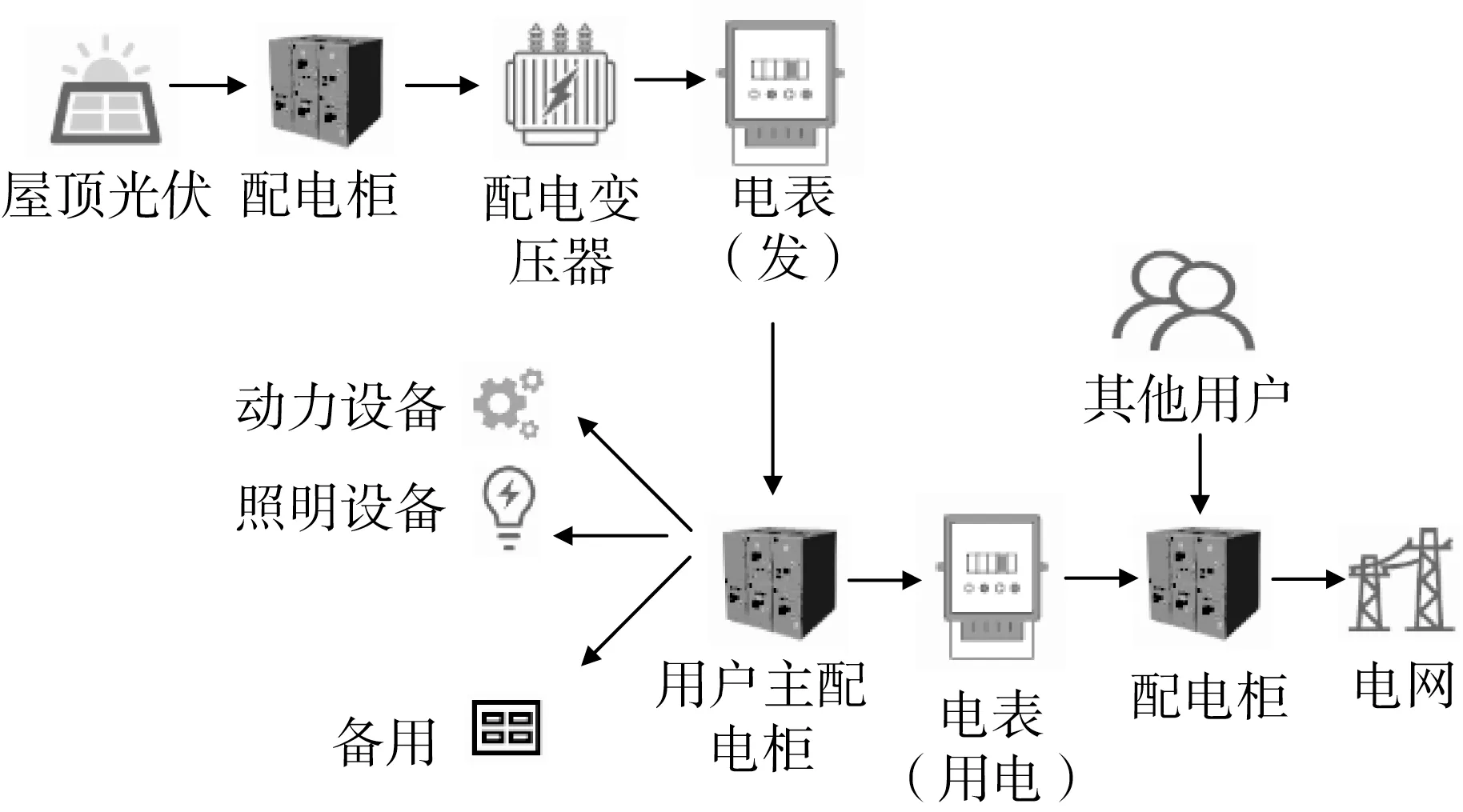
圖3 并網方式
所謂“自發自用,余電上網”,就是在光伏系統發電量滿足自身負荷需求后,將多余電量饋入電網[14]。這種模式可使投資商拿到較高電價,同時能將用不完的電量賣給電網,此外無論是自用部分還是上網部分均可享受政府財政補貼。
2 光伏電站營運對電網公司的競爭
以往電網公司處于壟斷地位,而如今隨著售電側放開[15],互聯網企業大規模進軍能源行業,對電網公司造成巨大沖擊。
2.1 大數據技術層面的競爭
在大量新能源不斷接入電網的趨勢下,每時每刻都產生著大量數據,不以大數據為基礎的預測技術很難滿足系統對于數據處理等的要求。大數據預測和傳統預測的對比情況見表1。
由表1可知,大數據技術在數據預測中的應用能夠有效提高預測精確度,從而減少損失,增加收益,維護安全穩定性。

表1 大數據預測與傳統預測的對比
2.2 對電網收益的影響
互聯網企業投建新能源電站“自發自用,余電上網”的模式對電網來說,一方面無法獲得用戶自發自用電量的購售電差價,對區域內電力公司造成實際損失;另一方面,給電網增加區域配網容量計算、管理電源點增加、用戶用電計量等額外的工作量。
2.2.1 屋頂光伏電站收益 對于“自發自用,余電上網”的運行模式,投資現金流入主要包括自用消耗部分帶來的收入、剩余電量饋入電網所獲得的收入和政府給予光伏電站投資商的補貼收入3個部分,增城區的分布式光伏補貼為0.15元/kWh。屋頂光伏電站年發電量為
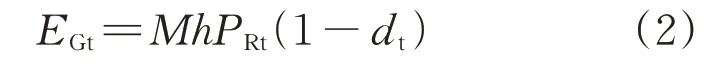
式中:M為裝機容量;h為年峰值日照小時數;PRt為屋頂光伏電站運行效率;dt為光伏縮減率。
根據北極星太陽能光伏網數據和美國航空航天局(NASA)數據庫,可知增城園區裝機容量為12 MW,經度113.83°,緯度23.29°,光伏發電系統最佳安裝傾斜角為20°,年峰值日照時間為1 153.4 h。在光伏系統運行過程中,地理位置、溫度條件、光伏組件匹配、并網逆變器及升壓變、交直流線纜造成的功率損耗分別為4%、3%、8%、5%、2.5%;其他雜項損耗為3%。因此,光伏系統運行效率為
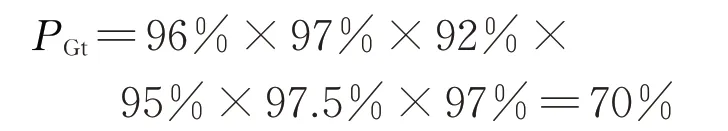
光伏縮減率為3%,根據以上計算可得出增城園區年發電量為

根據調研,夏季與非夏季的用電峰谷時段光伏發電量百分比及分時段電價見表2和表3。
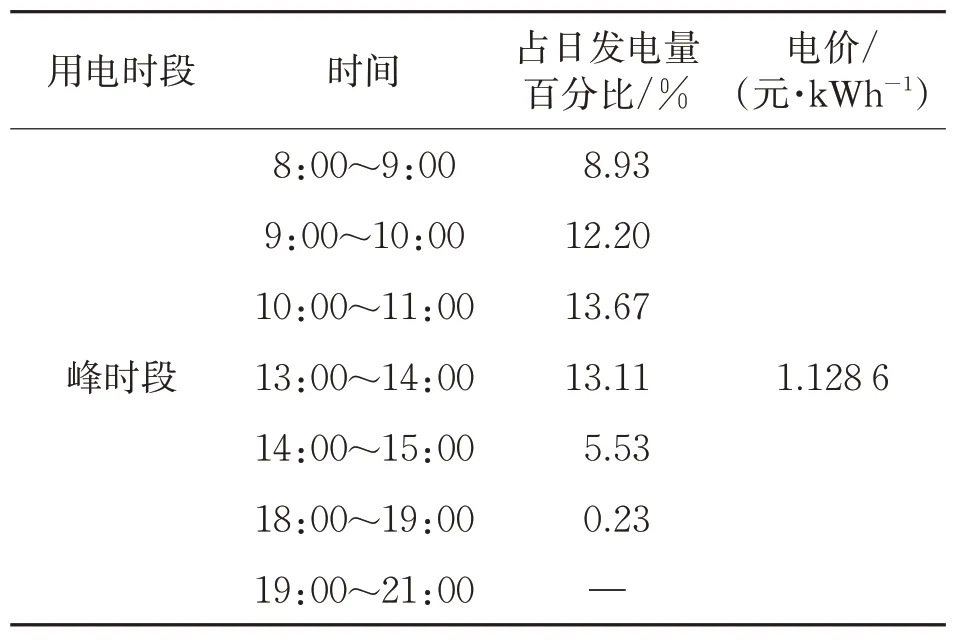
表2 夏季分時段發電量及電價
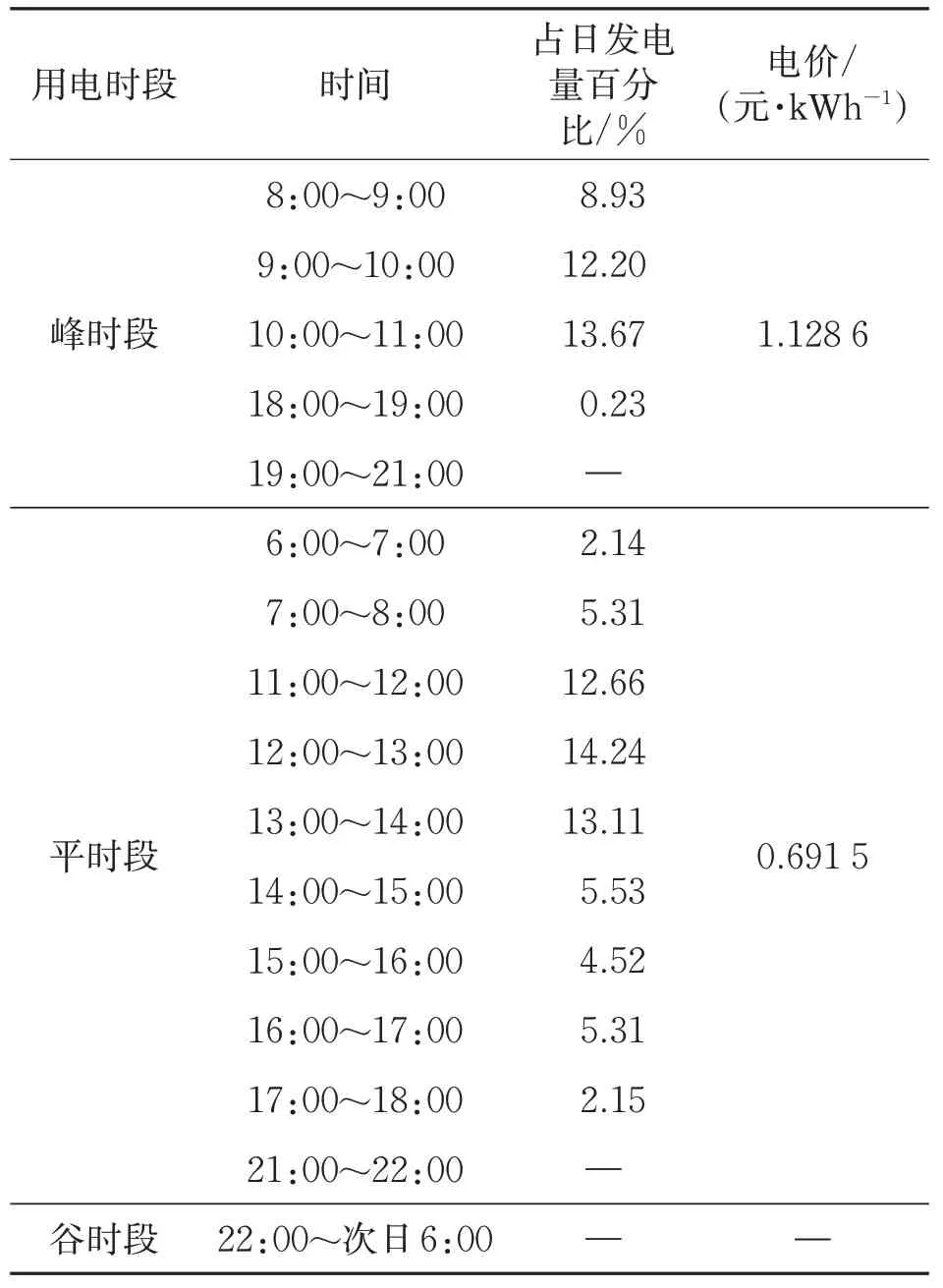
表3 非夏季分時段發電量及電價
按光伏夏季發電量占全年發電量60%,非夏季占40%計算,該屋頂光伏系統在高峰時段的發電比例為46.214%,平時段發電比例為53.786%,谷時段光伏系統無發電量。按40%自用以及60%余電上網的比例計算,廣州地方補貼為0.15元/kWh(5年內價格不變),上網電價為0.45元/kWh,則5年內增城園區光伏發電收益為
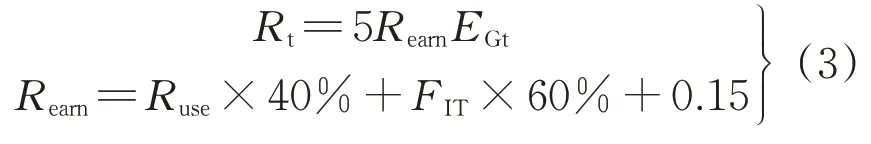
式中:Rt為現金流入;Rearn為平均每度電收益;Ruse為自用部分每度電收益;FIT為上網電價。通過計算可得5年內增城園區屋頂光伏發電收益為4 018.26萬元。運維成本按5萬元/MW計算,則此電站未來5年運維費用為25萬元。
2.2.2 電網收益損失 據調研,表4為廣州工商業峰谷電價表。

表4 廣州工商業峰谷電價表
增城園區在2020年的用電量約為10 GWh,用電高峰期約49.6%,平段期約41.3%,低谷期約9.1%。由于“自發自用,余電上網”模式為主的光伏電站入局新能源行業必然會搶占該領域的流量入口,使得原有電網公司用戶量流失,造成電網公司收益損失。通過以上數據可得,僅此物流園區未來5年內將給增城區電力公司造成4 430萬元的用電流量流失性損失收益。電網將迎來不小的沖擊,必須及時給出有效的應對策略。
3 應對策略及算例分析
為了增強電力用戶黏性,電網須滿足用戶多維度需求的服務。本節建立了基于Spark框架的電力服務平臺,分析用戶行為并進行負荷預測,篩選出應當努力爭取并留住的客戶。
3.1 基于Spark框架的電力服務平臺框架
Spark是具備大數據處理分析功能的引擎,具有快速性、易用性、跨平臺性等特點[16]。圖4為本文提出的基于Spark框架的電力服務平臺總體結構設計。整個服務平臺按照層次化結構設計,分為底層、中間層和頂層。其中,數據貼源層完成數據的采集、轉換和存儲,以具備典型主從式存儲管理結構的HBase列式存儲架構[17]為關鍵技術,通過多節點并發訪問提升服務平臺的數據吞吐率,且具有較高的容錯率;數據分析層對數據進行挖掘、預處理等操作,是整個服務平臺的核心,基于AP聚類法分析用戶行為,并基于遷移學習進行負荷預測,以MapReduce計算框架與HBase列式存儲架構配合使用,實現用戶分類以及電力負荷預測;業務實現層負責展示各種數據處理結果。
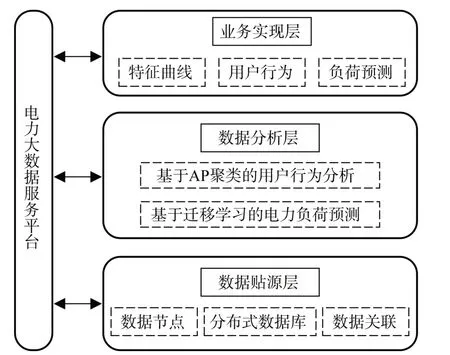
圖4 基于Spark框架的電力服務平臺
3.2 基于AP聚類的用戶行為分析方法
本文基于日負荷率、日平均負荷率、用電百分比、谷電系數以及峰值耗電率這5個指標對用戶行為進行聚類分析。計算方法如下:
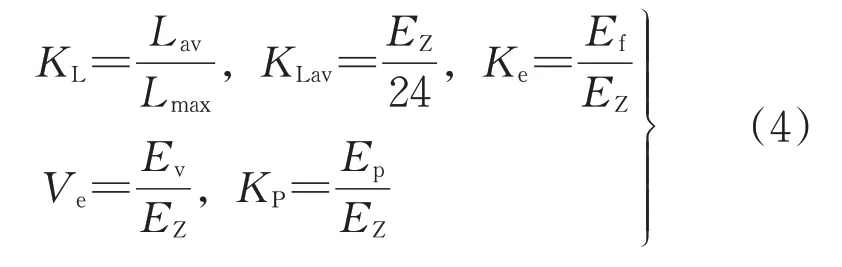
式中:KL、KLav、Ke、Kp分別為日負荷率、日平均負荷率、用電百分比和峰值耗率;Lav、Lmax為日平均負荷和日最大負荷;EZ、Ef、Ev、Ep分別為日總用電量、平段用電量、谷段用電量和峰段用電量;Ve為谷電系數。
由于用戶用電行為變異性大小各不相同,利用熵權法確定各指標的權重值,以提高指標權值的客觀性。假設5個指標的初始權值向量為
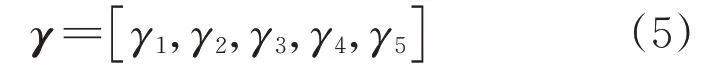
生成新的聚類中心后,統計這5個指標對聚類中心的貢獻程度,即
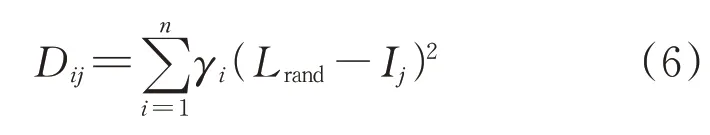
式中:Lrand為聚類中隨機選取的負荷值;n為聚類簇個數;Ij為聚類中所對應的指標值。
根據熵權法原理,計算第i個指標的權值為
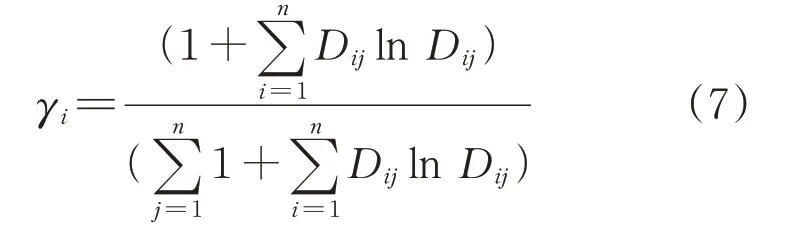
本文根據AP聚類法原理構建相似度矩陣,定義兩個數據點間的相似度為
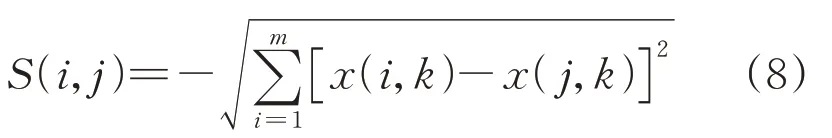
式中:x(i,k)、x(j,k)分別為第i個和第j個數據的第k個屬性值;m為屬性個數。
設置參考度,即相似度矩陣的對角線值,參考度越大,聚類結束后的質心個數就越多。AP聚類迭代過程如下:
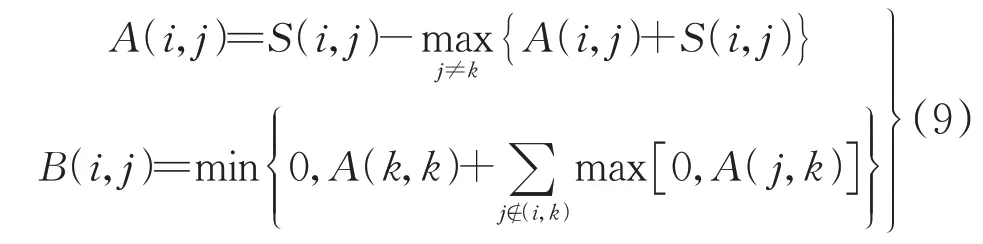
式中:A(i,j)、B(i,j)分別為i、j間的吸引度和歸屬度。
3.3 基于遷移學習的電力負荷預測方法
本文基于深度學習,引入遷移學習概念,以解決負荷預測過程中訓練數據不足的問題,同時保證預測精度。基于遷移學習的負荷預測方法,如圖5所示。

圖5 基于遷移學習的負荷預測方法
3.4 算例分析及仿真
本節選取某地150名工商業用戶進行各類數據采集,根據AP聚類結果,得出最佳聚類個數為3。將用戶日負荷曲線進行擬合聚類,如圖6~圖8所示。
由圖6~圖8可知,A類用戶在10:00~20:00期間是用電高峰期,說明該時段內工廠用電設備持續工作,負荷壓力較大,在9:00~10:00期間用戶用電量陡增,導致工廠大量設備進入生產狀態,這也是A類負荷波動率降低的主要因素;B類用戶整體用電量較低,用電高峰時段較短,曲線波動較為平滑,在8:00~18:00期間用電量先增后減,中午時段用電量最大;C類用戶負荷波動頻繁,但整體負荷等級較低,具備雙峰時用戶的典型特征,8:00~10:00和15:00~18:00是其用電高峰期。
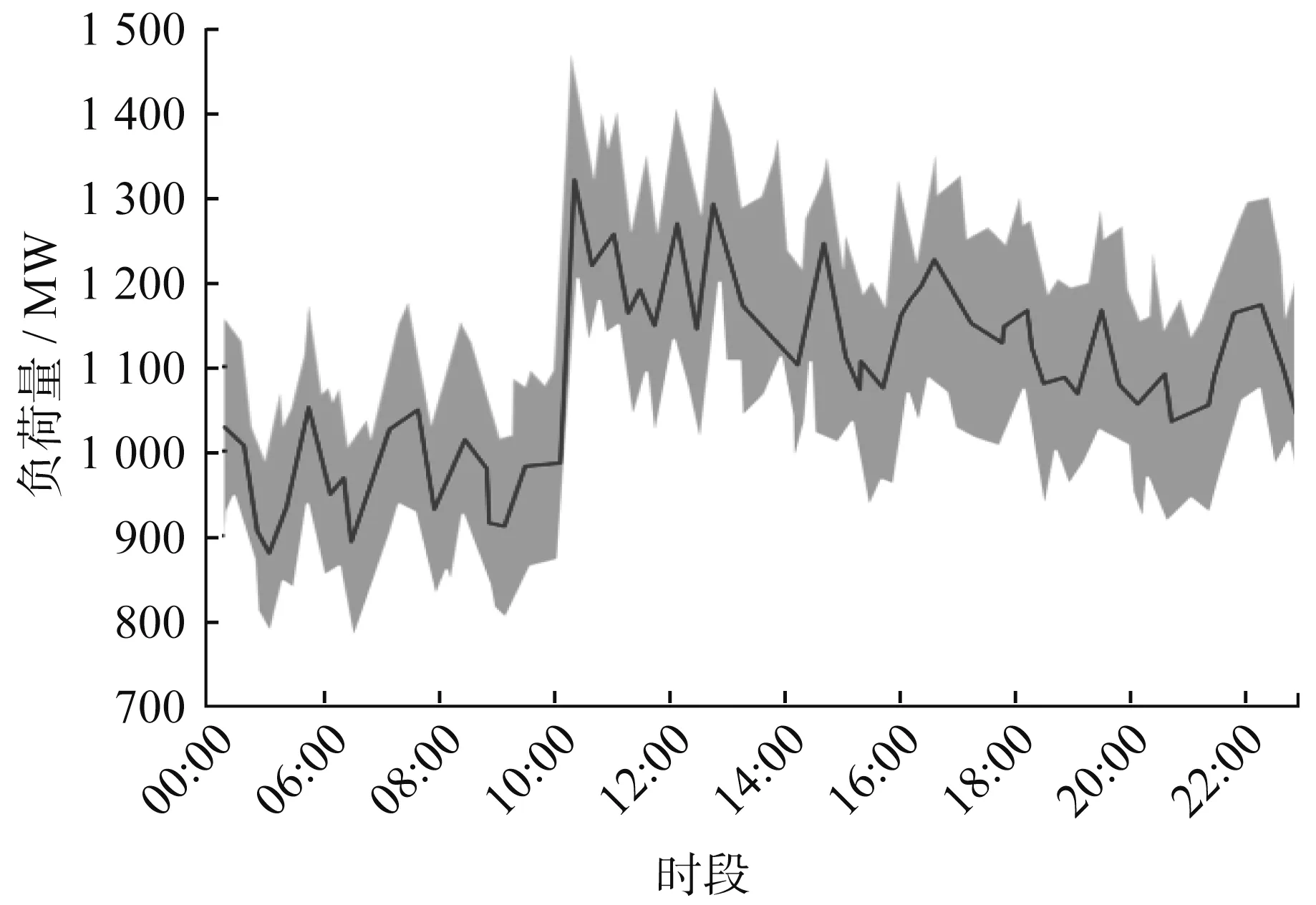
圖6 A類用戶日負荷曲線
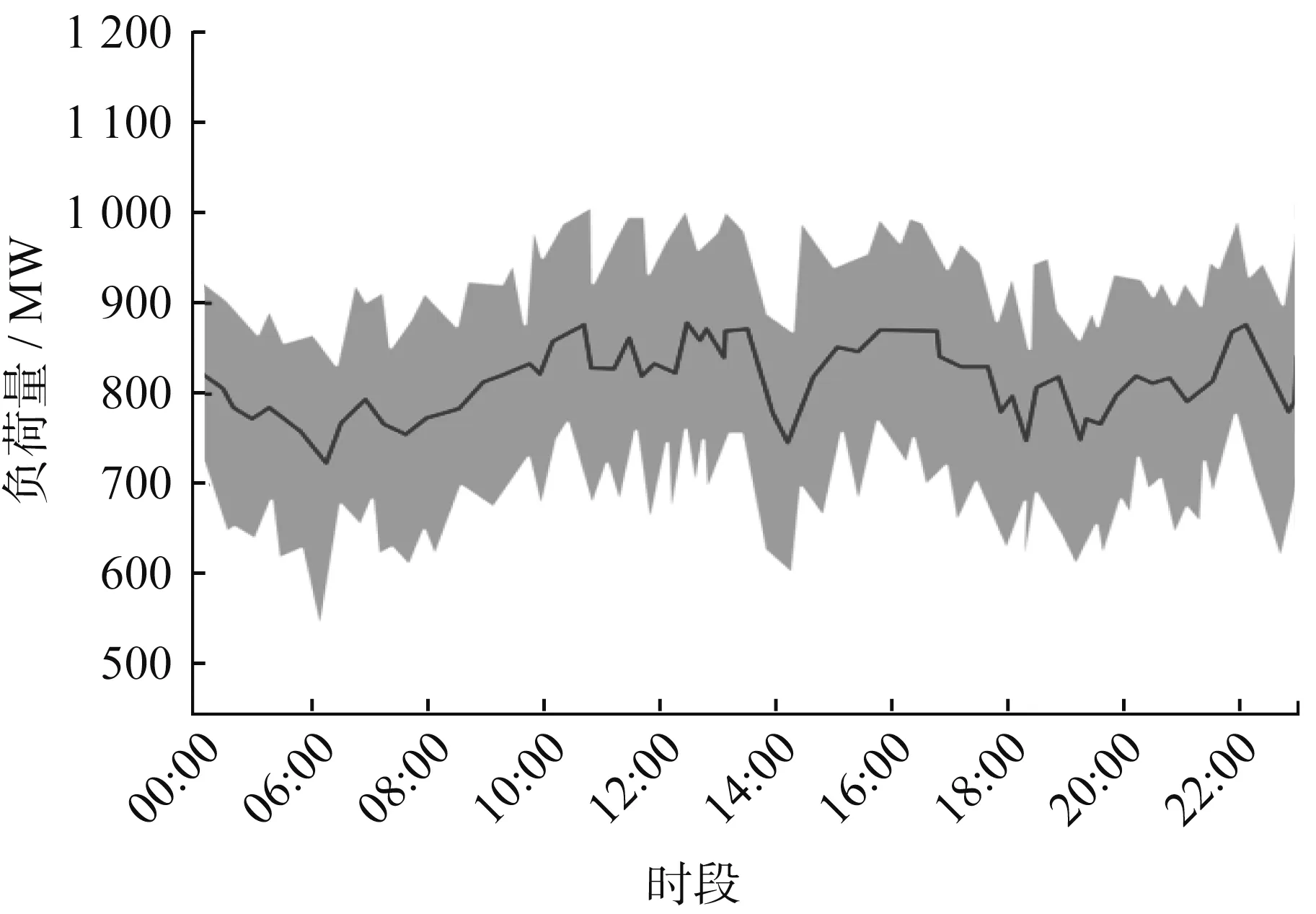
圖7 B類用戶日負荷曲線
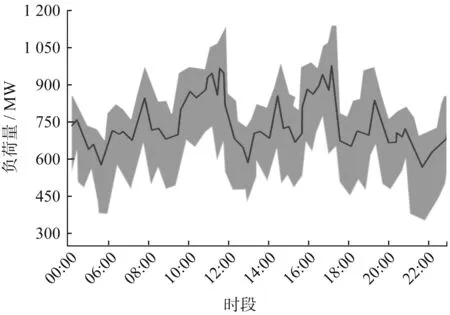
圖8 C類用戶日負荷曲線
通過數據搜集可獲得3類用戶于2015—2020年的月負荷曲線。根據遷移學習算法選取2018—2020年的負荷數據作為訓練集可以得到2021年上半年的月負荷量曲線,并與實際用電量曲線作對比,如圖9~圖11所示。

圖9 A類用戶電量預測結果
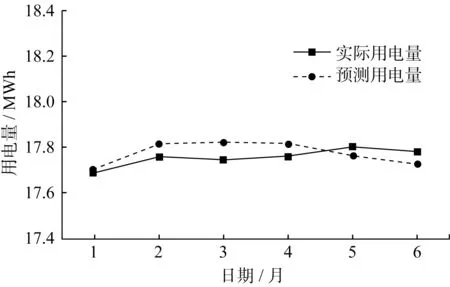
圖10 B類用戶電量預測結果
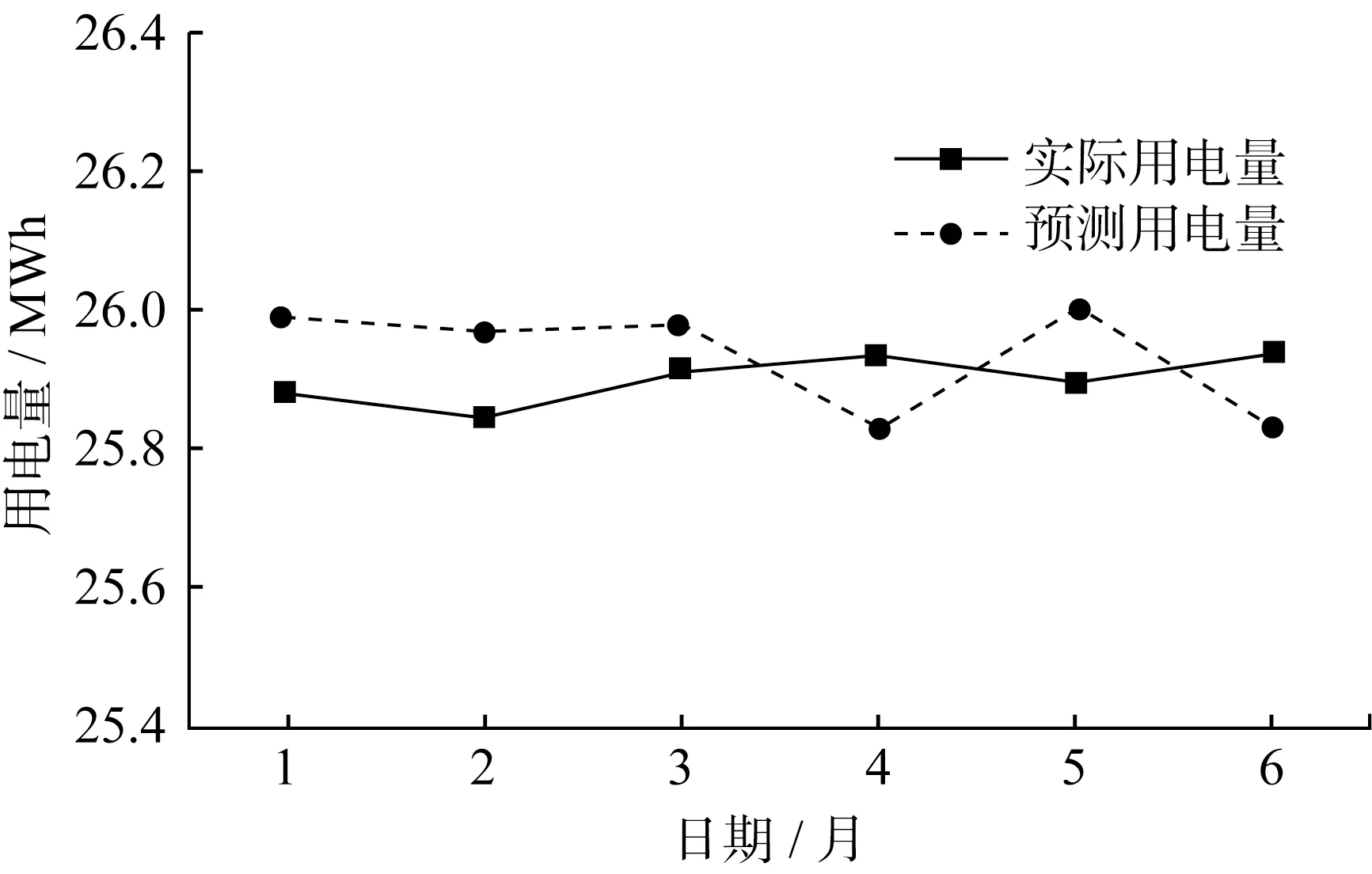
圖11 C類用戶電量預測結果
為驗證本文算法的優越性,以C類用戶為例,采用遞歸神經網絡(RNN)、粒子群-循環神經網絡(PSO-LRNN)兩種算法對相同數據集進行訓練,得到如圖12所示的預測結果。

圖12 不同算法的負荷預測結果
本文提出的模型訓練結果準確度較高,因此利用該模型對2021年下半年的用電負荷進行預測,如圖13~15所示。
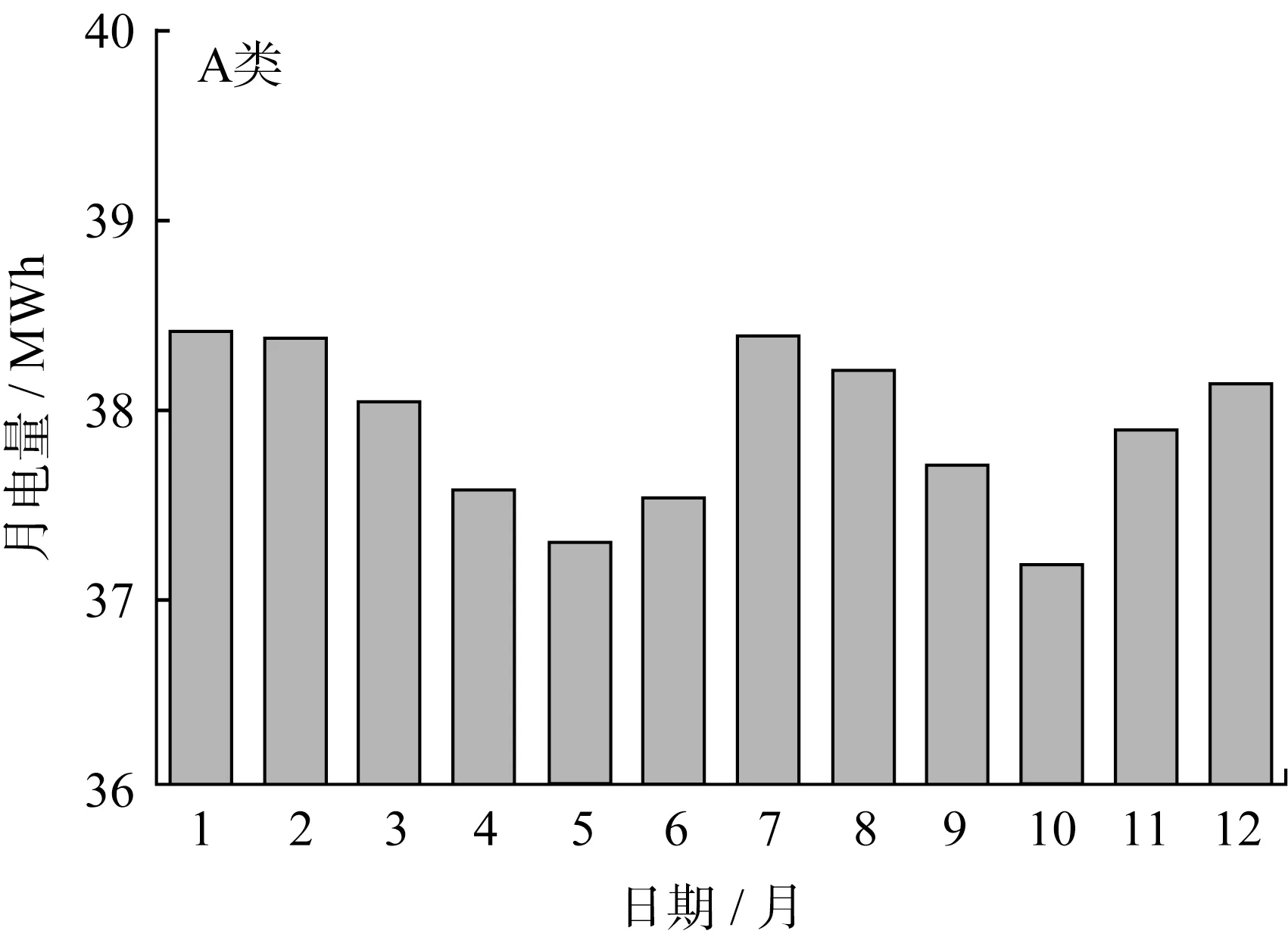
圖13 A類用戶2021全年負荷曲線
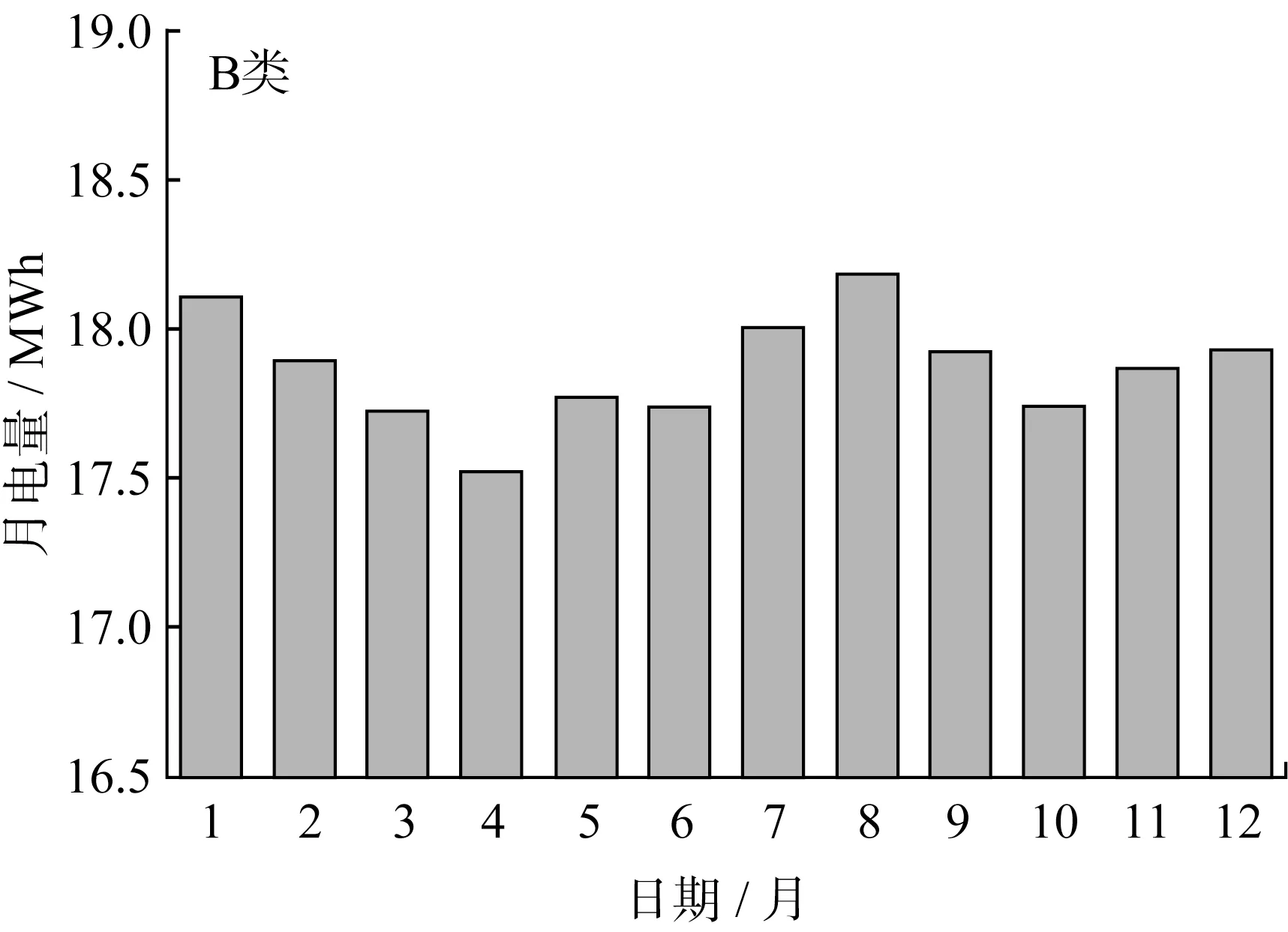
圖14 B類用戶2021全年負荷曲線
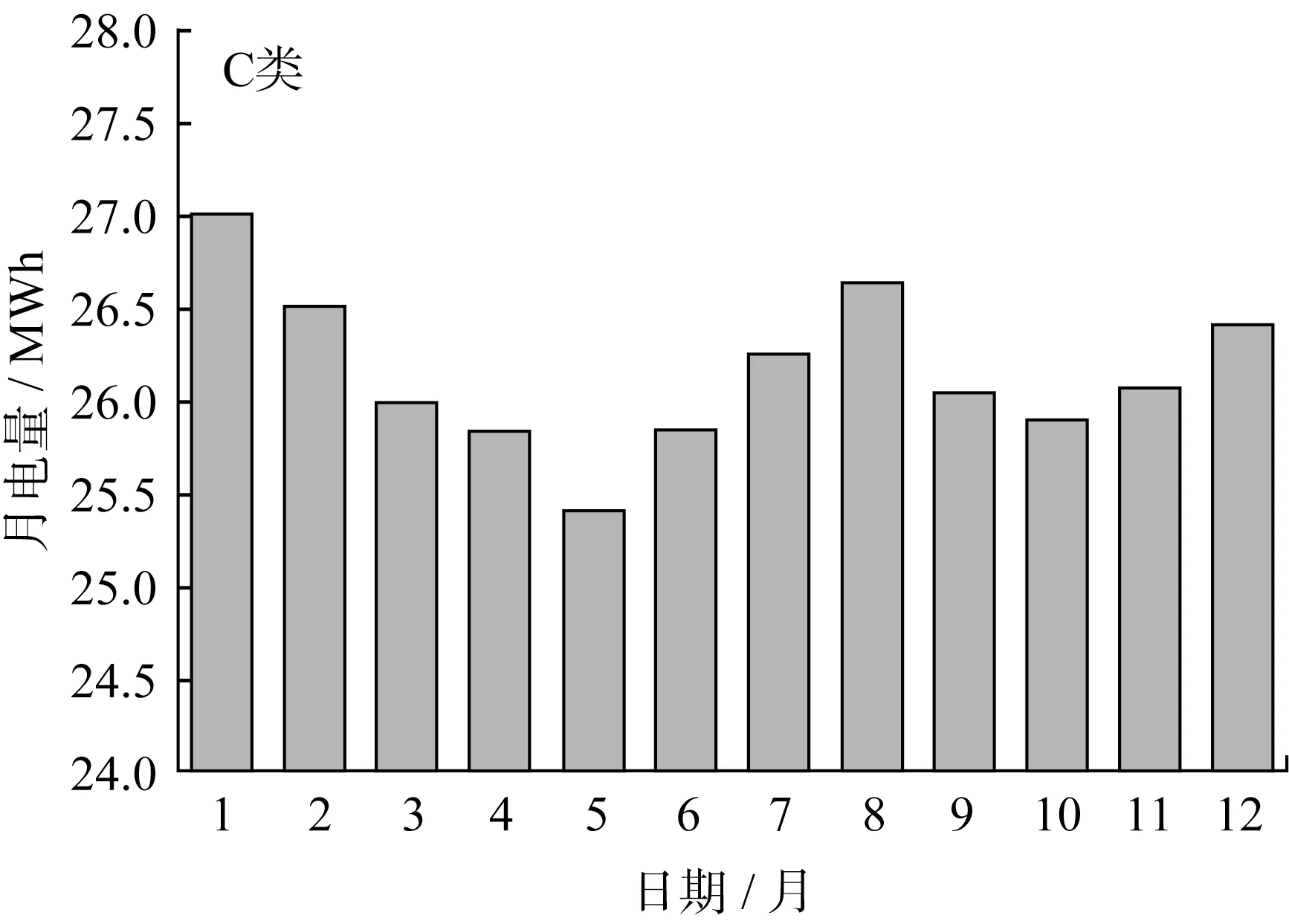
圖15 C類用戶2021全年負荷曲線
由預測結果可得表5中的數據。

表5 用戶用電量及購電增長率
由表5可知,C類用戶購買力雖然低一些,但購電增長趨勢最好,是電力公司應當努力爭取并留住的客戶。
4 結 語
本文研究了大型互聯網企業投建光伏電站的運行模式以及互聯網電站給電網帶來的競爭,據此給出電網的應對策略。以阿里巴巴投建的增城物流園區屋頂光伏電站為例,從大數據處理方式和“自發自用,余電上網”模式兩方面分析其運行模式;整合計算了該屋頂光伏電站未來5年內會給電網帶來的收益損失;從避免用戶大量流失的角度出發,建立了基于Spark框架的電力服務平臺,利用AP聚類分析用戶行為并基于遷移學習進行負荷預測,從而篩選出應當努力爭取并留住的客戶,增強電網用戶黏性。最終通過算例分析驗證了應對策略的有效性,得出電網公司需要努力爭取并留住的客戶類別。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
