突破算力瓶頸:異構計算和異構集成是兩大方向
2022-03-09 01:25:02綜合整理報道
海外星云 2022年19期
日前,由中國計算機學會主辦的“2022中國計算機學會芯片大會”中,英特爾中國研究院院長宋繼強分享許多半導體前沿技術。談到半導體兩大趨勢:突破算力瓶頸,以及墻算力同時要能控制功耗,宋繼強分享了英特爾對異構計算和異構集成兩大技術方向的看法。
是突破算力瓶頸,通過不同的方式解決多樣化數據的計算有效性; 第二,在提升算力的時候,還需要考慮到綠色計算,不能用很耗能的計算方式去解決問題,要想如何以能量優化的方式去解決未來的數據處理。
宋繼強指出,如果把數字經濟的基礎設施看成一個底座,如何更好地分配算力,進行調度以應對不同的應用,以及對延時、計算量、并發、不同加速類型、數據類型的要求,實際上是構成了一個很復雜的算力網絡。
中國近年來提出把計算和網絡融合起來,“東數西算”工程的推進是很重要的大方向。從技術方面來看,其實它就是在構造一個以能源、計算能效性為優先綜合布局的新型算力網。
東部的數據量很大,包括游戲、智慧城市、智能駕駛、交通等有非常多數據產生和使用。還有很多地區能效比高,很多自然能源可以使用,適合建立建數據中心。這個概念在上面看是一張算力網,通過網絡把它連接起來,當中的底層技術非常復雜,因為網絡有延遲,很多應用根據數據處理和應用的需求對延遲的敏感度不太一樣。
對于數據處理,無論是算力還是網絡構造,都很有獨特的要求。從數據量和質來看,傳統的單一計算架構肯定會碰到性能和功耗的瓶頸。因此,我們要朝兩方面邁進:第一,是突破算力瓶頸,通過不同的方式解決多樣化數據的計算有效性;第二,在提升算力的時候,還需要考慮到綠色計算,不能用很耗能的計算方式去解決問題,要想如何以能量優化的方式去解決未來的數據處理。
解決上述問題,異構計算和異構集成是未來的兩大方向。
何為異構計算?就是用不同的架構處理不同類型的數據,真正做到“用好的工具解決好的問題”。
何為異構集成?是以更好的集成組合方式,把不同工藝下優化好的模塊更好地集成到未來的解決方案當中,從而更加高效地處理復雜計算。

XPU,英特爾全面的硬件架構
在“解決問題”的這個思路下,首先我們要能夠在硬件的架構布局上“全面發展”,對不同的數據有不同的處理器架構,比如說CPU、GPU、IPU、FPGA、AI加速器,它們各自針對不同種類的數據流,包括數據處理的不同特點,可以進行定制。
再者,把不同架構組裝起來后,就需要有人根據應用的要求進行編程,釋放硬件的功能,把它調度好,這就需要有一個對應的很好的軟件框架,英特爾的oneAPI就在構造一個完整的異構計算體系,目的是未來寫一個軟件,只需要讓應用者指定它的功能,而不需要非常明確地指定哪些部分運行在CPU上,哪些部分運行在GPU上,哪些部分運行在人工智能加速器上。通過底層的軟件功能模塊和工具鏈,就可以把下面具體的實現分布在不同的硬件上,硬件發生變化,下面具體的實現也發生相應變化,但是上面的軟件開發代碼是不用變的。
英特爾在這一領域有非常全面的硬件架構布局,包括CPU、GPU、IPU、FPGA、人工智能加速器等領域都有很成熟的產品,在網絡上可蓋的領域很全面的,從終端側,到邊緣,再到服務器,都有不同級別的硬件對它們進行加速。
軟件框架也非常重要,必須具有開放性,因為我們現在不知道未來會有哪些新興硬件種類出現,但是我們要去構造一個能讓未來和現在的硬件都能很好地去工作的統一框架。
首先,最底層是硬件的抽象層,定義一些統一的描述方法,稱之為Level Zero,它可以把不同架構的硬件,以及來自不同廠商的硬件,都用統一的方式向上層開發人員給出一種描述,比如硬件如何被調用,有哪些功能,以及做不同工作的時候的延時和性能。
再上面是底層高性能庫,針對不同常用的計算內核分別做了相應的優化,這個優化一方面會針對這些計算負載的種類去做算法級的優化,同時會根據所面向的硬件種類進行優化,比如說oneMKL,它在CPU、GPU和AI加速器上運行的庫是不一樣的。
同時oneAPI也提供不同的語言,比如說DPC++、SYCL語言,都可以支持做并行編程,這兩層是oneAPI主要的工作。
目前oneAPI在全球都開始做開放式的合作,有很多企業、初創公司、研究機構加入,在中國,英特爾去年也和中科院計算所建立了中國首個oneAPI卓越中心。

oneAPI,開放統一的跨架構編程模型
當我們有了不同種類架構的芯片,有一些架構的硬件可以被很好的整合到同一制程下面的SoC里面去,而有一些是會成為不同的芯片,但是我們仍希望把它統一在同一個系統里,因此需要異構集成,也就是先進的封裝工藝。
先進的封裝工藝可以把不同制程節點的芯片封裝在一個大的封裝里,同時利用先進封裝帶來的尺寸、帶寬、功耗的優勢,讓它們不會像原來板級封裝一樣有很大的延遲和帶寬降低,還有可能造成面積、成本達不到要求。
實現這種異構集成,英特爾目前有兩項做的比較好的技術:
第一,嵌入式多芯片互連橋接:這是2.5D封裝技術。在這個技術框架下,把在平面上集成起來的芯片做很好的連接,可以把它們之間的凸點間距有效降低到50微米以下,未來有可能繼續降低到45微米、三十幾微米這個層面。
第二,Foveros:要提高整個封裝集成的密度,僅靠2.5D封裝是不夠的,需要往3D封裝的方向發展。Foveros可以把不同計算的芯粒在垂直層面上進行封裝,通過更高級的封裝層面的微縮技術,把封裝凸點的間距降到36微米,未來可繼續降到二十幾微米和十幾微米以下。這樣一來,封裝層級的連線密度就已經非常高了,并且速度也可以逐步接近在芯片里面連線的速率。
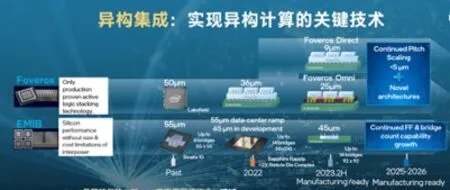
Foveros Omni和Foveros Direct就是英特爾在3 D 封裝上未來會使用的兩種技術。Foveros Omni是比較典型的,在上面是一個大的芯片,底下是幾個小芯片的時候,可以用一種通用的方法把不同芯片之間互連的接觸點間距微縮到25微米,同時還可以通過這種在邊上的比較粗的銅柱,直接給上層芯片供電,和EMIB相比有接近4倍的密度提升。

Foveros Direct技術是通過一種更高級的不需要焊料、直接讓銅對銅鍵合的技術,實現更低電阻的互連,進一步縮小凸點之間的間距,達到10微米以下。在3D堆疊的時候就可以把整個互連的密度直接提升到新的數量級。
把異構計算和異構集成的技術整合在一個產品里面,Ponte Vecchio是一個很好的例子。
Ponte Vecchio是英特爾目前在高性能計算GPU領域最復雜的SoC,當中共用了來自5個不同制程節點的47種不同晶片,有來自英特爾自己的,也有來自于臺積電的。
同時,在水平層面上用EMIB技術封裝,也在垂直方向上用Foveros技術進行封裝集成。通過這樣的構造做出了專門給高性能計算機的計算系統,當中包括了至強處理器和專門的基于Xe架構的Ponte Vecchio GPU,目前用于極光超級計算機。
下一代旗艦級數據中心GPU,則叫Rialto Bridge,它里面小的芯片采用了更新的制程節點,在封裝上也會采用最新的封裝技術。不同芯片之間互相合作,通過oneAPI編程實現它的計算功能。

針對推進摩爾定律,如何在制程、器件的級別上做創新,宋繼強也分享他的觀點。
制程工藝方面,首先工具很重要。英特爾率先使用下一代基于高數值孔徑的極紫外光刻機,可進一步降低整個制程工藝的復雜度,提高良率,易于將光刻的特征線寬降低下來。
在Intel 20A節點的時候,會開始產品化地使用RibbonFET這一新的晶體管結構。可進一步降低在平面上看到的晶體管所占面積,同時因為RibbonFET是用一個門去驅動好多個納米帶,可以有更快的驅動速度,驅動電流的強度也會較之前更好。
在給晶體管供電的層面,也會在Intel20A通過PowerVia技術實現底部給所有上層的功能邏輯部件供電,把供電層和邏輯層完全分開,可以更有效地使用金屬層,對繞線和能量消耗的減少而言都有很大的提高。

宋繼強也分享,未來四年英特爾會有5個節點的演進。今年英特爾已經在大量出貨Intel 7;下半年還會有Intel 4的產品開始使用EUV;Intel 3是明年產品化,在生產過程當中會更大量的使用EUV;進入2024年,上半年是Intel 20A,下半年會有Intel 18A。

CMOS晶體管3D堆疊層面,英特爾也持續投入研究,更將成果直接貢獻到GAA的RibbonFET產品技術當中,通過堆疊CMOS晶體管能夠實現30%~50%的微縮。
在晶體管層面上繼續做微縮有很多方法,像是使用一些新的材料,例如到Intel 20A、Intel 18A之后,選擇新的材料做它的接觸層、構造一些溝道可以進一步提升晶體管的效能。
同時,基于硅的CMOS基礎上,還可以進一步疊加新的晶體管材料和結構,給硅晶體管注入新的功能。比如說下圖左側,它展現的是增強模式的高K氮化鎵晶體管和硅的FinFET晶體管組合起來之后,可以提供更好的電源管理技術。這也是非常重要的一部分技術,把三代半導體和硅基的第二代半導體很好的組合起來,去產生新的晶體管層級的結構創新。
還有一些全新的利用量子效應做的一些器件,下圖左側采用的是磁電加上電子自旋軌道,把這兩種器件很好地組合在一起,構造出了MESO的邏輯器件。此前磁電自旋電子器件比較多的是用在存儲上,而英特爾的研究進一步把這種器件應用在邏輯計算上,這是一個非常重要的突破。
另外,未來神經擬態計算也是非常重要的一個方向,因為現在做人工智能大部分是依靠GPU、CPU或者是帶有非常多矩陣運算的加速器,消耗還是非常大的。而神經擬態計算一個很大的好處是它可以在算法層級和硬件結構設計層級上完全突破現在這種靠堆乘加器的方式來提供算力的模式,而是模擬人類神經元的形式去構造其中底層的計算單元,且大部分是存算一體化。
構造出這種芯片,再通過脈沖神經網絡的方式編程,實現人工智能的算法。通過這樣的方式,通常可以達到能效比千倍級的提升,也就是說做同樣一個人工智能任務,用神經擬態計算消耗的能量與傳統上用CPU或者GPU相比減少了一千倍以上,所以這是非常值得關注的。
英特爾的Loihi就是這個方向上代表性的實驗芯片,現在已經發展到了Loihi 2。Loihi 2是在Intel 4制程工藝上生產出來的,速度較上一代提升10倍,單個芯片里的神經元數量也提升了8倍。所以現在單芯片的神經元數量可以達到100萬,原來是13萬,且面積縮小50%。
