基于深度強化學習的農田節點數據無人機采集方法
2022-03-09 01:55:00張亞莉望夢成蘭玉彬張植勛
農業工程學報 2022年22期
關鍵詞:深度
胡 潔,張亞莉,王 團,望夢成,蘭玉彬,張植勛
·農業航空工程·
基于深度強化學習的農田節點數據無人機采集方法
胡 潔1,3,張亞莉2,3※,王 團1,望夢成1,蘭玉彬1,3,張植勛2
(1. 華南農業大學電子工程學院,廣州 510642;2. 華南農業大學工程學院,廣州 510642;3. 國家精準農業航空施藥技術國際聯合研究中心,廣州 510642)
利用無人機采集農田傳感器節點數據,可避免網絡節點間多次轉發數據造成節點電量耗盡,近網關節點過早死亡及網絡生命周期縮短等問題。由于相鄰傳感器數據可能存在冗余、無人機可同時覆蓋多個節點進行采集等特點,該研究針對冗余覆蓋下部分節點數據采集和全節點數據采集,對無人機數據采集的路線及方案進行優化,以減輕無人機能耗,縮短任務完成時間。在冗余覆蓋下部分節點數據采集場景中,通過競爭雙重深度Q網絡算法(Dueling Double Deep Q Network,DDDQN)優化無人機節點選擇及采集順序,使采集的數據滿足覆蓋率要求的同時無人機能效最優。仿真結果表明,該算法在滿足相同感知覆蓋率要求下,較深度Q網絡(Deep Q Network,DQN)算法的飛行距離縮短了1.21 km,能耗減少27.9%。在全節點數據采集場景中,采用兩級深度強化學習聯合(Double Deep Reinforcement Learning,DDRL)方法對無人機的懸停位置和順序進行優化,使無人機完成數據采集任務時的總能耗最小。仿真結果表明,單節點數據量在160 kB以下時,在不同節點個數及無人機飛行速度下,該方法比經典基于粒子群優化的旅行商問題(Particle Swarm Optimization-Traveling Salesman Problem,PSO-TSP)算法和最小化能量飛行控制(Minimized Energy Flight Control,MEFC)算法的總能耗最少節約6.3%。田間試驗結果表明,相比PSO-TSP算法,基于DDRL的數據采集方法的無人機總能耗降低11.5%。研究結構可為無人機大田無線傳感器節點數據采集提供參考。
無人機;數據采集;深度強化學習;節點感知冗余;DQN;DRL
0 引 言
各種農業傳感器在農業生產中起著監測作物生長環境、協助精準灌溉和施肥及病蟲害防治等作用[1-2]。在網絡基礎設施缺乏的部分邊遠地區,農田無線傳感器節點的數據采集存在困難[3-4]。因此,利用各種移動設備采集田間無線傳感器節點數據成為一種解決措施[5-6]。相比地面移動設備,無人機具有不受限于地面環境、不破壞地面作物、信號傳輸所受阻擋小等優勢,是采集傳感器節點數據的有利途徑[7]。目前農業無人機普遍采用牛耕法的方式進行噴藥、撒播等作業,然而當采集隨機布置的傳感器節點數據時,相鄰節點間的數據可能存在冗余[8-9],且無人機在一個懸停點可能覆蓋多個節點[10],因此需要對無人機數據采集的路線及方案進行優化,以減小無人機能耗、縮短任務完成時間。
針對無人機采集傳感器節點數據的方法,國內外學者開展了相關研究,大部分優化方案主要集中在降低能耗[11-12]、任務完成時間最短[13]、軌跡距離最小[14-17]等。Luo等[11]提出了一種智慧農場的數據采集方案,根據傳感器節點的接收信號強度(Received Signal Strength Indication,RSSI)確定簇和簇頭,采用改進的Dijkstra和遺傳算法(Genetic algorithm,GA)尋求最佳軌跡。Ben等[12]提出了一種使用無人機從無線傳感器網絡節點采集數據的解決方案,可以同時減小通信與無人機飛行能耗。Just等[14]針對無人機采集大面積節點數據,使用時隙概念結合飛行禁止列表,將無人機路徑與每個節點的激活周期進行同步,大大縮短了飛行距離和飛行時間。Zhang等[15]提出了一種基于分層深度強化學習(Hierarchical Deep Reinforcement Learning,HDRL)算法解決可充電多無人機數據采集場景的路徑規劃問題,最大限度地縮短無人機的總飛行時間。蔣寶慶等[16]提出了一種基于Q學習的無人機輔助采集小規模無線傳感器節點數據,減少了無人機的任務完成時間和有效數據量,提高了無人機能效。Yi等[17]研究了一種基于深度強化學習(Deep Reinforcement Learning,DRL)的無人機輔助物聯網采集最優信息年齡(Age of Information,AoI)數據,得到最優的無人機飛行軌跡和傳感器節點的傳輸調度方案。文獻[15-18]采用強化學習算法研究無人機數據采集問題,無人機通過與環境進行交互得到反饋,通過自主學習獲得最優數據采集策略。上述研究大多針對無人機的飛行距離進行優化,忽略了節點數據量大小和通信范圍等因素。
作者在無人機果樹噴藥的研究中發現,懸停能耗對無人機整體能耗的影響更大,需綜合考慮懸停時間和飛行時間。因此,針對能量受限的農業無人機不同數據采集場景,本文基于深度強化學習算法,在考慮傳感器節點冗余覆蓋的情況下,研究如何對無人機進行調度,有選擇地采集部分節點數據及規劃采集順序,使數據采集在滿足覆蓋率要求的同時達到無人機能效最優,在需要采集全部傳感器節點數據的情況下優化無人機的懸停位置和采集順序,使無人機能耗最小。
1 作業場景及相關模型
1.1 冗余覆蓋下部分節點數據采集場景
在布設傳感器時,為了對整個作業區域進行全面覆蓋,傳感器之間往往存在感知范圍交叉重疊的情況,這種情況在隨機布設傳感器的環境中尤其明顯。無人機受限于自身能量和續航時間,在采集傳感器數據時需要對傳感器進行甄選,對飛行路徑進行優化,以求在感知覆蓋率要求和無人機能耗之間獲得最佳平衡。
假定農田隨機分布的傳感器節點總數為,每個節點的感知范圍是以節點為中心的圓(本文假設所有節點的感知半徑相同),如圖1所示。在采集數據過程中無人機懸停在節點的正上方,在一個懸停位置只采集一個節點的數據,傳感器節點在收到無人機的信標信息后被喚醒并向無人機發送數據,無人機采集完該節點數據后飛向下一個被選擇的節點。數據采集過程中,假設無人機可以獲知各節點的位置及當前自身能量。無人機以固定高度飛行,為簡便表示,后續統一采用平面二維坐標表示無人機的懸停位置。
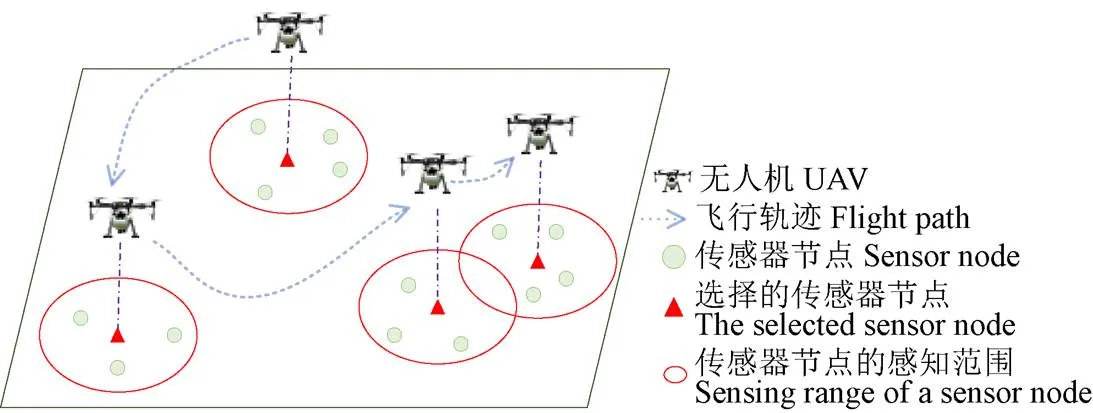
圖1 冗余覆蓋下部分節點數據采集場景
1.2 全節點數據采集場景
農業生產中,有些情況下需要采集田間所有傳感器節點的數據,若每采集一個節點數據都要懸停,懸停點過多,無人機會有巨大的能量消耗。由于無人機的通信區域是以懸停點在地面投影為中心的圓,在這個范圍內的節點都可以與無人機進行數據傳輸,通過合理選擇無人機的懸停點位置和采集順序,讓無人機在每個懸停點時采集其通信范圍內的傳感器節點數據,達到減少無人機懸停次數及能耗的目標,最終完成所有傳感器節點的數據采集。
如圖2所示,假設田間有個無線傳感器節點,每個節點都有準確定位(配備GPS或北斗天線),每個傳感器都具有相同的通信范圍和數據緩沖區大小。無人機在飛行高度固定為的情況下,在某個懸停點可正常通信的是圖2中圓形區域內的傳感器節點,設該區域的半徑為(通過信道傳輸模型計算得出),區域中的傳感器節點以單跳方式與無人機進行通信。假設無人機勻速飛行,飛行高度固定,通過對懸停位置選擇及飛行路徑規劃,使無人機在采集完所有傳感器節點數據時總能耗最小。為簡便表示,后續統一用平面二維坐標表示無人機的懸停位置。
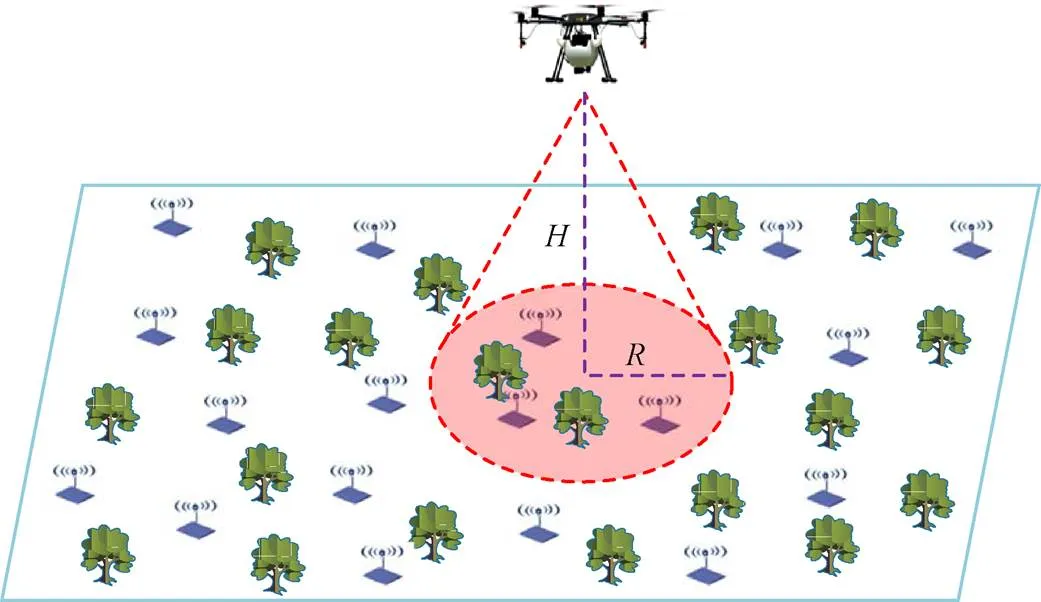
注:H為無人機飛行高度,m;R為無人機在某個懸停點可與傳感器正常通信的區域半徑,m。
1.3 信道傳輸模型
無人機懸停采集田間節點數據,其懸停時間與數據傳輸速率相關,而數據傳輸速率受信道損耗和衰落的影響。
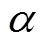
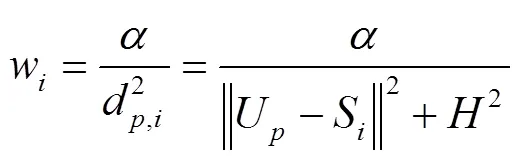
假設在通信過程中傳感器節點的發射功率為,根據香農定理可得位置的無人機與節點間的數據傳輸速率R,i(bit/s)為
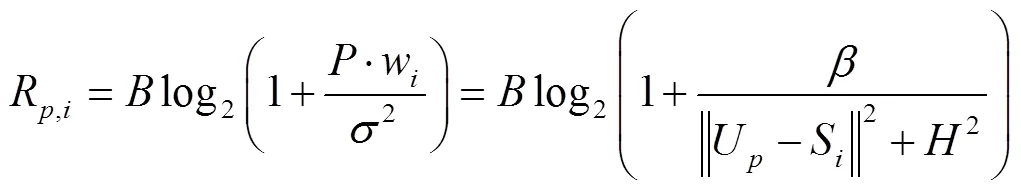
從式(2)可以看出,在其他參數不變的情況下,無人機與節點的距離越遠,數據傳輸速率越慢,則無人機懸停時間越長。
1.4 無人機能耗模型
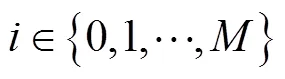
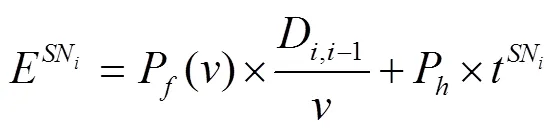
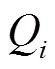
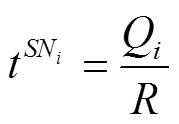
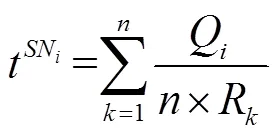
本文采用Zeng等[19]的旋翼無人機功率模型:
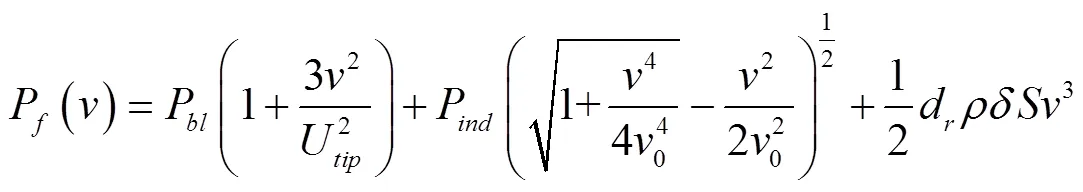
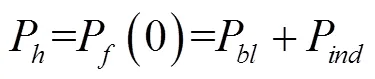
由式(3)~(4)、式(6)~(7)可知,在冗余覆蓋下部分節點數據采集場景中,無人機從SN-1起飛到結束SN的數據采集所消耗的能量(kJ)為
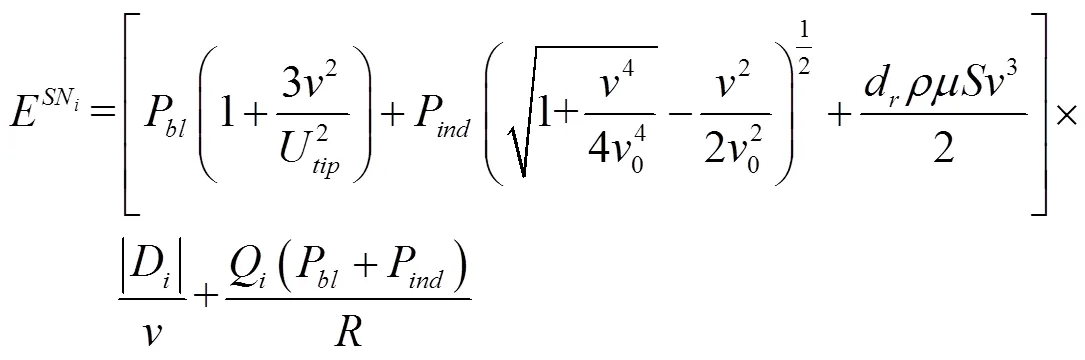
同理,在全節點數據采集場景中,從SN-1起飛到結束SN的數據采集所消耗的能量(kJ)為
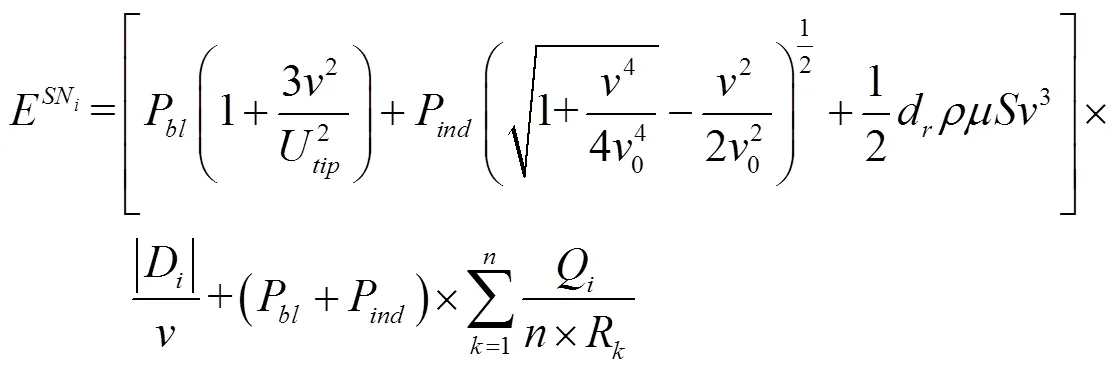
最終,無人機完成個懸停位置的數據采集任務所需要的總能耗E(kJ)為
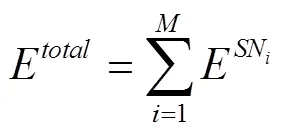
2 基于DRL的節點數據采集方法
2.1 深度強化學習DRL
強化學習是一類特定的機器學習方法,可解決關于序列決策的相關問題[20]。深度強化學習(Deep Reinforcement Learning,DRL)將深度學習的感知能力和強化學習的決策能力相結合[21-22],通過深度學習對環境狀態信息進行特征提取,傳遞給智能體進行決策并執行動作,執行動作后得到由環境反饋的獎懲信號以及環境狀態的改變,促進智能體進行下一步的動作。智能體通過與環境迭代交互選取一系列動作以最大化累積獎勵,即在有限反饋中實現序列決策的優化[23]。田間節點數據采集本質上是在多種影響因素變化情況下對無人機懸停位置的選擇和采集時序的安排;每采集一個節點數據,或會帶來相鄰節點數據的效用變化,或會帶來去往其余節點的距離成本變化,這可以轉化為序列決策問題。本文基于DRL方法,針對前述2個場景設計了競爭雙重深度Q網絡(Dueling Double Deep Q Network,DDDQN)及兩級深度強化學習(Double Deep Reinforcement Learning,DDRL)算法。
2.2 冗余覆蓋下基于DDDQN的部分節點數據采集方法
2.2.1 任務環境
設農田為一個矩形區域,如圖3所示,無人機按照虛線所示的路線采集節點數據。采集節點a數據時,無人機獲取的數據覆蓋范圍增量是以a為中心的整個圓范圍;采集節點b數據時,數據覆蓋范圍增量是以b為中心、去掉陰影區域1的剩余圓;采集節點c數據時,數據覆蓋范圍增量是以c為中心、去掉陰影區域2的剩余圓;而采集節點d的數據覆蓋率增量只有陰影區域3的范圍,節點d與已采集的節點間數據冗余比例高,無人機根據獎勵函數(公式(12))確定當前動作,可能會將節點d舍棄。
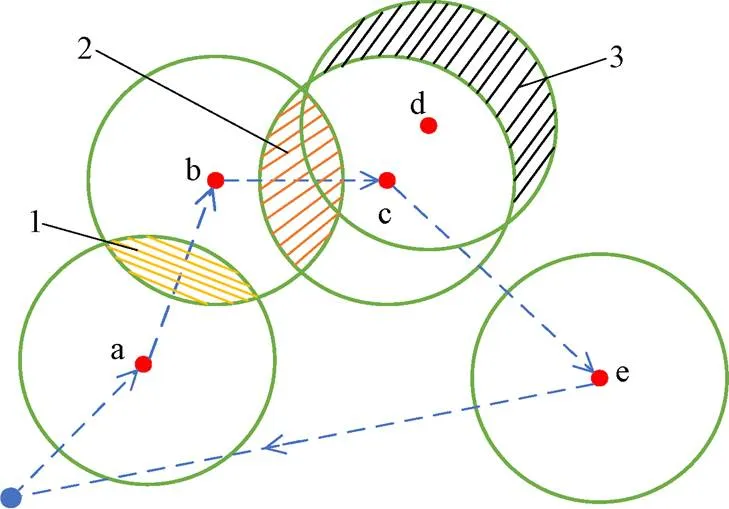
注:a~e為傳感器節點;1為節點a與節點b的冗余覆蓋部分;2為節點b與節點c的冗余覆蓋部分;3為節點d帶來的數據覆蓋率增量。
2.2.2 DDDQN算法
DDDQN算法將雙重深度Q網絡(Double DQN)[24]與競爭深度Q網絡(Dueling DQN)[25]相融合。圖4為DDDQN算法框架[26]。該算法結合了2種算法的優勢,將DQN算法存在的網絡值估計過高的問題與網絡的結構同時進行優化。
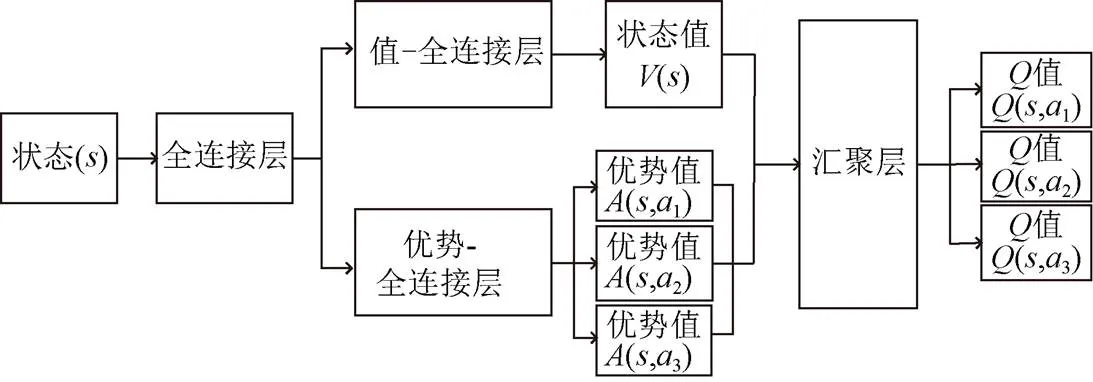
注:s為無人機當前狀態;V(s)為在狀態s下通過神經網絡得到的狀態值;A(s,a)為在狀態為s下執行動作a時通過神經網絡得到的優勢值;Q(s,a)為在狀態值V(s)和優勢值A(s,a)的總和。
在冗余覆蓋場景中,無人機強化學習模型中的狀態-動作-獎勵框架如下:
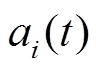
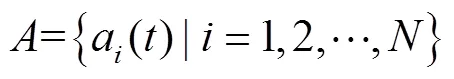
3)獎勵函數:考慮到無人機續航能力有限,需要盡可能快地從分散的傳感器節點采集數據,避免花費大量時間和能耗采集冗余覆蓋部分數據。因此,在建立獎勵函數時需要兼顧正向和負向獎勵,定義如下:
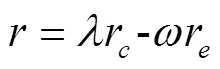
2.3 基于DDRL的全節點數據采集方法
2.3.1 任務環境
全節點數據采集與部分節點數據采集的區別是:(1)要求采集所有節點的數據;(2)懸停位置不局限在節點的正上方;(3)在一個懸停位置可以采集多個在通信范圍內的節點數據。
全節點數據采集示意圖如圖5所示,設農田為矩形區域,為定位無人機的懸停位置,將農田區域離散為×個小柵格,每個小柵格中心是無人機可選的懸停點。柵格越小,對懸停位置的優化程度越高,但算法復雜度越高。圖中三角形代表某個飛行策略確定的懸停采集點,虛線代表飛行路徑。無人機在懸停點2采集傳感器b和c的數據,在懸停點3采集傳感器d和e的數據。
針對全節點數據采集場景,若直接采用DQN算法對系統進行建模,會導致系統狀態空間維數爆炸、模型訓練困難,無人機甚至難以完成數據采集任務。本文提出一種基于兩級深度強化學習(DDRL)的數據采集策略,將該問題分解為2個子問題進行研究,以簡化模型,避免出現直接采用DQN算法產生的問題。分解后的2個子問題為:1)選擇無人機最優采集區域,采用深度Q網絡(Deep Q Network,DQN)算法;2)在得到的最優采集區域內,采用n步深度Q網絡(Option n-step Deep Q Network,OnDQN)算法選擇懸停位置以及確定遍歷順序。
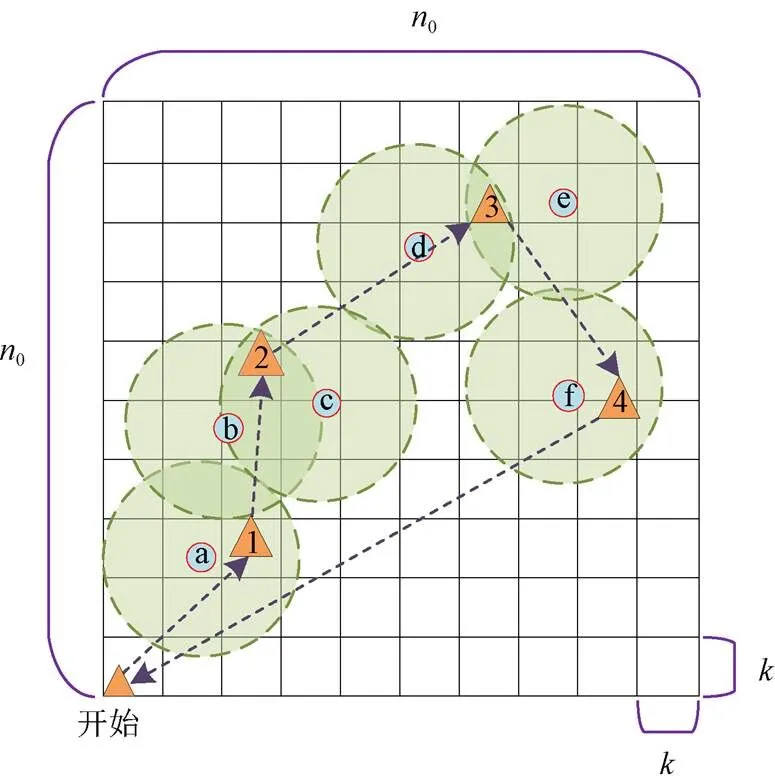
注:n0為矩形區域長度;k為小柵格長度;f為傳感器節點;1~4為無人機懸停采集點。
2.3.2 基于DQN的最優采集區域選取
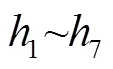
3)獎勵函數:獎勵函數由3個部分組成,其中能量效率表示當前動作執行后采集的傳感器節點數增量與當前動作執行所消耗的能量之比,如式(13)所示。
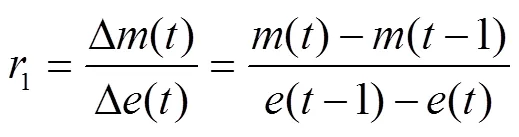
注:1~7是根據傳感器節點通信范圍交疊情況劃分的子區域。
Note:1-7is a sub-region divided by overlapping communication ranges of the sensor nodes.
圖6 數據采集子區域的劃分示意圖
Fig.6 Schematic diagram of data collection subarea division
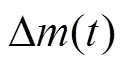
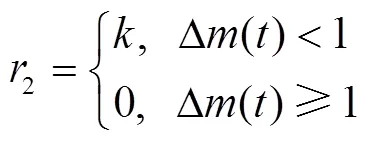
式中為負常數。
另外,為避免無人機耗盡電量,在數據采集過程中,若無人機出現電量不足的情況也給出懲罰:
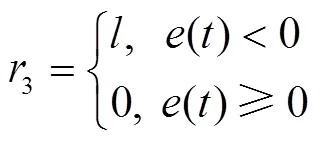
式中為負常數。
2.3.3 基于OnDQN的最優航跡規劃
無人機懸停點距離傳感器位置越遠,數據傳輸速率越低,懸停時間就越長。選定無人機的最優采集子區域后,需對子區域的采集順序和懸停位置進行決策,以平衡無人機的飛行距離與懸停時間,從而最大限度地減少無人機能耗。在該問題中,無人機動作空間包括飛向某一子區域、懸停在子區域某個位置、數據采集3個動作,本文采用基于選項(option)的分層強化學習思想來解決該問題[15,27],將狀態空間、動作空間、獎勵函數以及option建模如下:
當獎勵函數為稀疏獎勵時,可能會導致算法學習效率低,甚至難以收斂[28]。本文采用n-step回報代替1-step回報來加快算法迭代速度[29]。定義n-step回報函數為
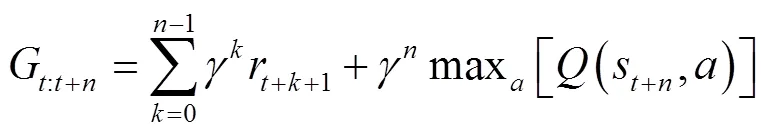
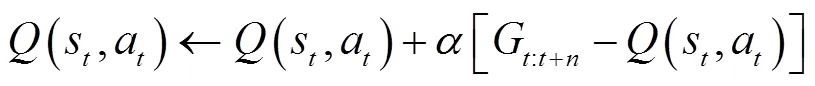
需要說明的是,本文的研究基于一些假設前提:假定無人機勻速飛行,沒有考慮從懸停到起飛以及飛行到懸停的速度變化過程的能量消耗變化;假定無人機從一個位置到另一個位置是直線飛行,實際應用中還需考慮無人機的轉向問題。
3 仿真分析
為驗證節點數據采集算法的有效性,分別在冗余覆蓋下部分節點數據采集場景和全節點數據采集場景進行仿真試驗,試驗在windows10系統下進行,處理器為AMD Ryzen 5 2500U,頻率為2.0 GHz。網絡架構使用谷歌的開源Tensorflow模塊構建,利用Python搭建深度強化學習仿真環境。表1為旋翼無人機的功率模型參數。

表1 旋翼無人機參數
3.1 冗余覆蓋下部分節點數據采集場景的仿真分析
仿真假設在640 m×640 m的農田隨機均勻部署20個無線傳感器節點,每個節點的感知覆蓋半徑均為80 m,無人機飛行速度為5 m/s,飛行高度為10 m,每個傳感器存儲的數據為160 kB。經平衡運算復雜度和優化結果,將農田離散為40 m×40 m的網格,共計256個網格單元。以覆蓋率和有效覆蓋平均能耗評估算法性能,定義如下:
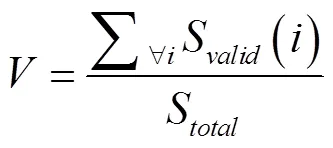
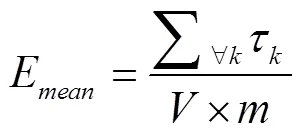
根據式(12)設置獎勵函數,在實際訓練過程中發現,負向獎勵的取值范圍遠大于正向獎勵,導致正向激勵幾乎不起作用。為此使用對數函數變換對原始獎勵計算結果進行歸一化處理:
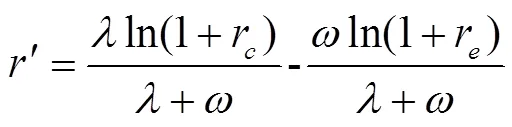
圖8為以最佳配置4作為獎勵函數調節因子時,DDDQN算法與DQN算法的學習差異。DDDQN的學習過程比DQN更穩定,在學習結束時獲得更高的周期獎勵。在調節因子配置4下DDDQN算法每個episode可獲得12的累積獎勵,而DQN最多只能獲得9的累積獎勵。

表2 調節因子配置
注:,為獎勵函數的調節因子,2為調節因子配置組編號。
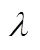
圖7 不同調節因子配置下的覆蓋率與有效覆蓋平均能耗

圖8 DDQN和DQN算法的訓練獎勵值對比
圖9為采集節點覆蓋率超過80%時DDDQN和DQN算法的無人機數據采集方案。經計算,DDDQN算法的飛行距離為3.13 km,相比DQN算法的4.34 km,無人機能耗減少了27.9%,飛行距離縮短1.21 km。根據式(19)~(20)計算可得,DDDQN相比DQN的有效覆蓋平均能耗降低了26.3%。
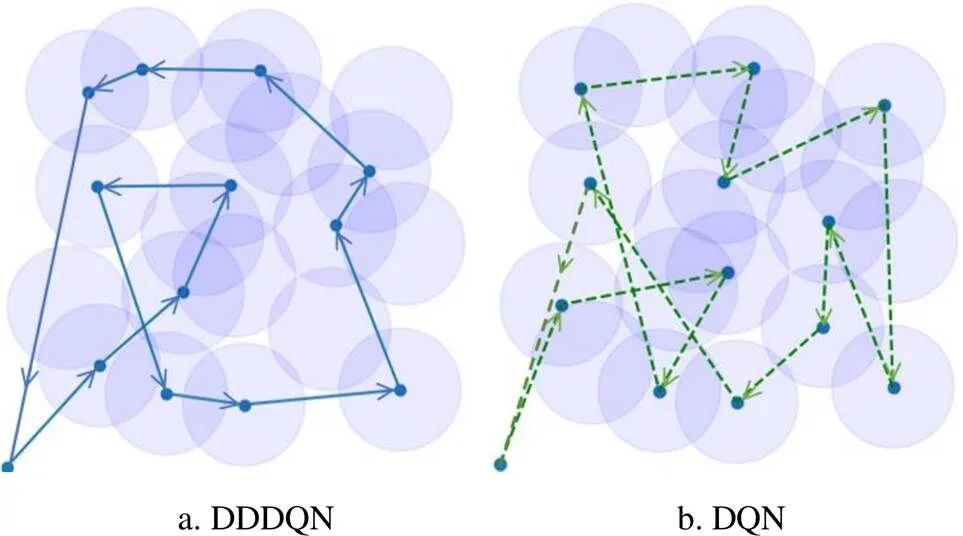
圖9 DDDQN和DQN算法的數據采集方案
3.2 全節點數據采集場景的仿真與結果分析
在仿真中,假設無線傳感器節點隨機分布在600 m×600 m的矩形區域內,將該矩形區域劃分為15 m×15 m的網格。設置矩形區域左下角為無人機的飛行起點,飛行高度為10 m;無人機與傳感器節點間單位距離(1 m)的信噪比=34 dB;通信帶寬=10 kHz。
圖10是不同條件下本文DDRL算法與經典PSO-TSP算法的結果對比。PSO-TSP算法是在Chen[30]等提出的IGA方法的基礎上提出來的。PSO-TSP算法要求無人機遍歷每個節點,在每個節點正上方懸停采集數據。
圖10a是無人機的飛行速度對總能耗和總工作時間的影響。在仿真中設置20個傳感器,每個傳感器儲存的數據為160 kB,通信半徑為80 m。對于2種算法來說,飛行速度的增加都會減小無人機的總能耗和工作時間。在相同速度下,DDRL算法比PSO-TSP算法的能耗更低,當速度較低時DDRL算法優勢更明顯,無人機飛行速度為5 m/s時,相比PSO-TSP,采用DDRL算法的無人機總能耗減少7.8%,工作時間減少9.2%。
圖10b為節點數據負載量對無人機能耗的影響。仿真中傳感器節點數設置為20個,傳感器的通信半徑分別設為60 和80 m。從圖10b中可以看出,本文DDRL算法在節點數據量較少(少于160 kB)的情況下比PSO-TSP算法的能耗低;通信半徑60 m時DDRL算法的優勢較80 m更明顯。節點數據量變大后,相比PSO-TSP算法在節點正上方采集數據(距離近采集時間短),DDRL算法在每個懸停點采集多個節點數據,由于有些節點的距離遠導致采集時間延長,導致懸停時間和能耗加大,總能耗超過PSO-TSP算法,通信范圍大時更加明顯。隨著節點數據量增加,無人機飛行能耗占比減少,這是因為無人機懸停能耗增加。同等數據量前提下,DDRL算法的飛行能耗占比比PSO-TSP算法低,節點通信距離80 m時的飛行能耗占比比60 m時低,即懸停能耗占比高。
圖10c是飛行速度對無人機懸停采集時間的影響。設置節點的水平通信距離為80 m,節點數據量為160 kB。由于PSO-TSP算法中無人機懸停在每個傳感器正上方采集數據,數據傳輸距離近,故其懸停采集時間最低且不受飛行速度影響。而在DDRL算法中,懸停采集時間隨著飛行速度的增加而減少,這是因為DDRL算法通過懸停點選擇和采集順序決策來優化總能耗,飛行速度增加,飛行能耗變小,此時懸停能耗成為影響總能耗的主要因素。
圖10d為水平通信距離60 m、節點數據量160 kB時傳感器節點個數對總能耗的影響。將本文DDRL算法與PSO-TSP及MEFC(Minimized Energy Flight Control)算法[31對比可知,MEFC算法考慮了無人機的飛行速度與轉彎角度對能耗的影響,找到最優飛行速度并優化了飛行軌跡,將懸停點規劃在傳感器傳輸范圍邊緣,使無人機以低能耗完成數據采集。從圖10d中可以看出,PSO-TSP的無人機總能耗最大,這是因為無人機需要飛到每個傳感器節點正上方采集數據,由于飛行路徑增加使其飛行能耗大大增加。MEFC算法規劃的懸停點均在傳感器傳輸范圍邊緣,且未考慮傳輸范圍重疊的情況,雖然減少了飛行距離和飛行能耗,但增加了懸停點的數據傳輸時間,即增加了懸停時間和懸停能耗。隨著節點數量的增加,3種算法的總能耗都增加。因此在數據量不大的情況下,本文DDRL算法的總能耗較另兩種算法更具優勢。
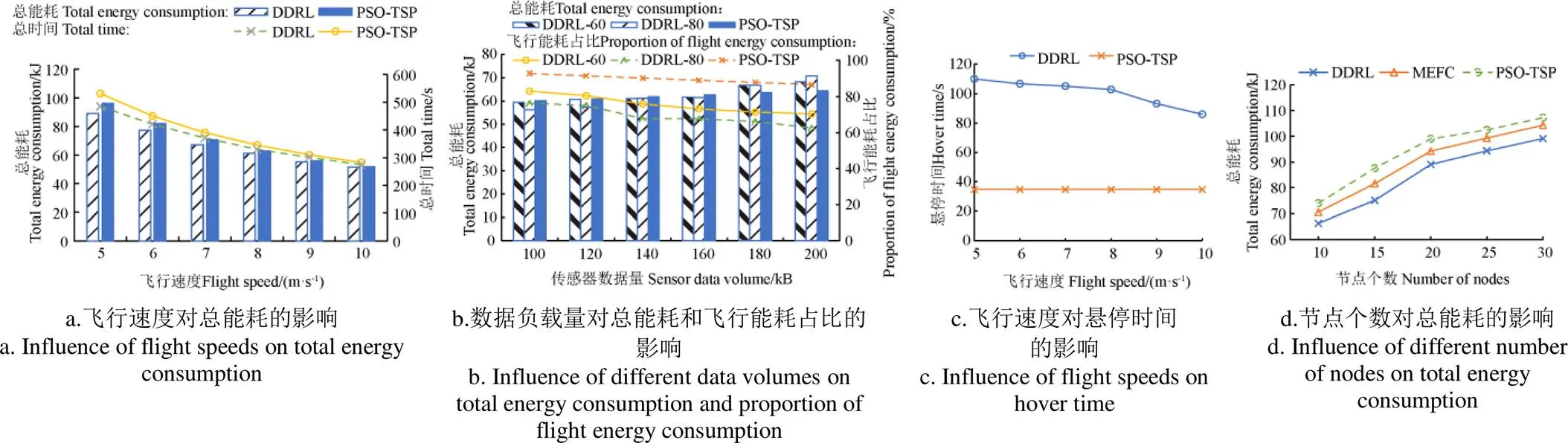
DDRL: Double Deep Reinforcement Learning; PSO-TSP: Particle Swarm Optimization-Traveling Salesman Problem; MEFC: Minimized Energy Flight Control; 60,80: Horizontal communication distance, m.
4 全節點數據采集算法的田間試驗與結果分析
針對全節點數據采集場景,本研究通過田間試驗對所提方法進行評估并驗證其可行性。試驗在廣州華南農業大學增城教研基地開展,采用自制的四旋翼無人機在210 m×400 m的平坦農田中進行測試,無人機飛行高度為5 m。為了驗證無人機接收數據的丟包率,同時對田間的通信路徑損耗進行估測,以更精確地計算無人機懸停時間,利用2個DRF1609H型Zigbee模塊測試無人機接收模塊與地面數據發送模塊之間的丟包情況和接收信號強度值,其中地面數據發送模塊由Zigbee通信模塊與單片機STM32組成,DRF1609H型Zigbee模塊的發送功率為22 dbm。
如圖11所示,無人機從地面節點正上方開始,每隔10 m水平距離,到與節點水平距離120m為止,當地面節點接收到無人機的數據請求后,發送200個數據包,每個數據包的長度為0.5 kB,丟包率測試結果如表3所示。接收信號強度值取每個位置采集10次數據的接收信號強度平均值。

圖11 田間試驗
從表3中可以看出,在水平通信距離80 m以外,隨著測試距離的增加,丟包率增加,80 m以內范圍滿足數據傳輸穩定性要求。
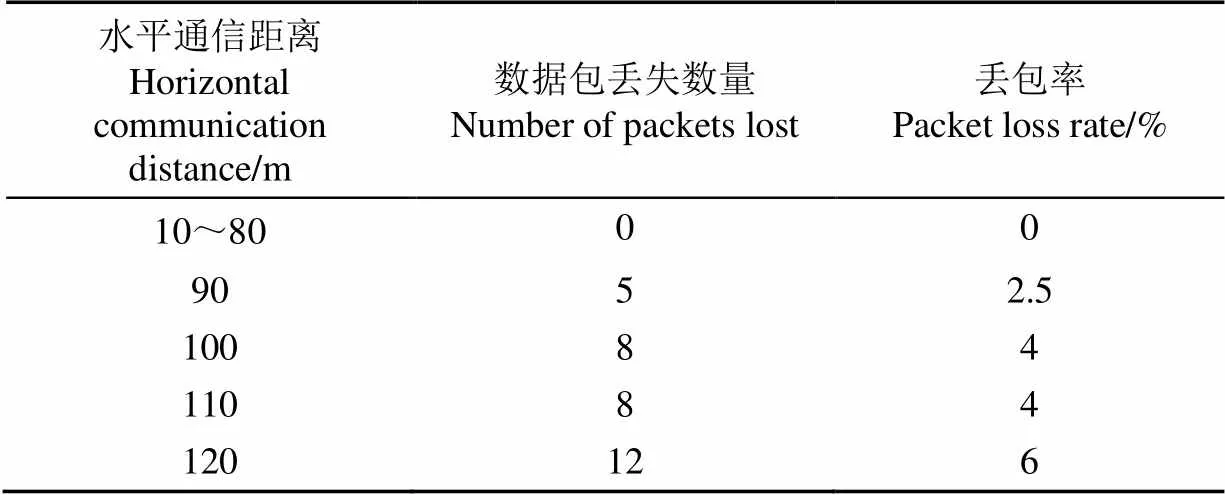
表3 水平通信距離對丟包率的影響
采用MATLAB中的曲線擬合方法對路徑損耗模型進行評估,確定水平通信距離與接收信號強度值之間的關系。如圖12所示,經過多次試驗發現,指數函數的擬合效果最佳,田間ZigBee傳輸的接收信號強度值RSSI與水平通信距離的關系為

為了進一步評估所提算法對無人機能耗優化的效果,在無人機上配備電流計模塊獲取瞬時電流并計算無人機能耗。首先測試無人機的飛行功率和懸停功率,測試方案如下:無人機以5 m/s速度和5 m高度進行勻速直線飛行100 m,利用每隔0.1 s獲取的瞬時電流和電壓計算無人機的飛行功率。同理,計算單位時間內無人機的懸停能耗。經過實際測試,本試驗所采用的四旋翼無人機的平均飛行功率為746.38 W,平均懸停功率為771.86 W,無人機電池的最大容量為22 000 mAh。
最后,在田間隨機布置11個Zigbee模塊模擬節點,結合田間路徑損耗模型,運行算法得到DDRL算法及PSO-TSP算法規劃的懸停點、懸停時間及采集順序,然后令無人機按照規劃方案進行數據采集試驗。設置節點數據量為160 kB,數據包長度為0.5 kB,無人機飛行高度5 m,飛行速度5 m/s。圖13a為PSO-TSP算法的飛行路徑;圖 13b為本文算法DDRL優化的懸停點和飛行路徑。最終的試驗結果表明,DDRL算法的無人機總能耗為354.56 kJ,飛行距離為1 189.23 m,丟包率為0.28%;PSO-TSP算法的總能耗為400.83 kJ,飛行距離為1 556.21 m,丟包率為0.15%。相比PSO-TSP,DDRL算法的總能耗減少了11.5%,飛行路徑減少了366.98 m;DDRL算法的丟包率略高于PSO-TSP算法,這是因為DDRL算法的規劃方案中無人機懸停采集點不在節點正上方,且在一個懸停點采集多個節點數據,而PSO-TSP算法的規劃方案中無人機懸停在節點正上方采集數據,丟包概率降低。
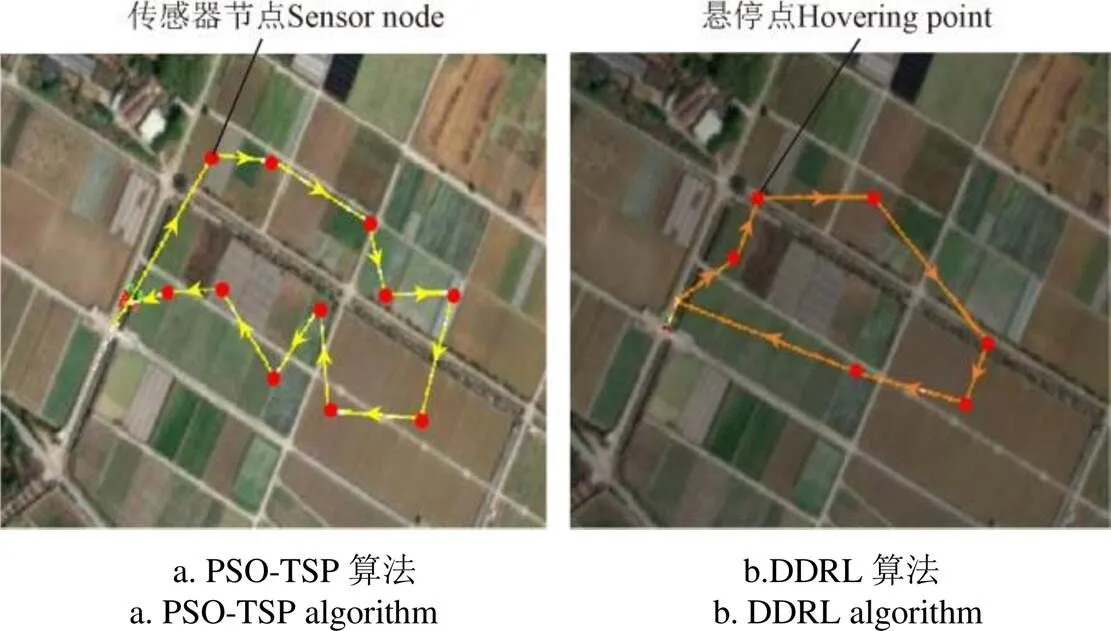
圖13 PSO-TSP和DDRL算法無人機懸停點及數據采集順序示意圖
5 結 論
利用無人機采集田間無線傳感器節點數據,能克服農田無網絡基礎設施及節點多跳轉發數據耗電快、網絡生命周期短的問題。本研究將節點采集的情況分為感知冗余覆蓋下部分節點數據采集及全節點數據采集兩個場景,基于深度強化學習規劃無人機的節點選擇、懸停位置及采集順序,以節省無人機能耗縮短任務完成時間。感知冗余覆蓋下部分節點數據采集方案適用于節點間冗余覆蓋面積比例比較高,無人機能量無法完成所有節點的數據采集任務,以及對數據的完整性要求不高的應用場景;全節點數據采集方案適用于對數據有完整性要求的應用場景。通過對研究結果的分析,得到以下結論:
1)在考慮感知冗余覆蓋下部分節點數據采集場景中,采用競爭雙重深度Q網絡(DDDQN)算法選擇采集節點及規劃采集順序,提高了無人機的能效和減少了冗余數據的采集。仿真驗證了在相同配置下,DDDQN算法比DQN算法的覆蓋率和平均能耗更優,算法性能更加穩定;在相同的覆蓋率要求下,DDDQN算法比DQN算法的飛行距離縮短了1.21 km,能耗減少了27.9%。
2)在全節點數據采集場景中,提出了兩級深度強化學習(DDRL)算法對無人機的懸停位置及采集順序進行優化,減少了無人機完成任務時的總能耗。本文從傳感器不同數據負載量、無人機飛行速度、傳感器節點數量對DDRL與PSO-TSP及MEFC算法的總能耗、總時間、飛行能耗占比、懸停采集時間進行仿真對比,結果證明無人機采用DDRL算法采集數據的總能耗最低。最后,通過田間試驗測試了四旋翼無人機的飛行功率與懸停功率,并對DDRL算法及經典PSO-TSP算法的采集方案進行了實際田間飛行試驗。結果表明,DDRL算法能同時考慮飛行距離與數據傳輸時間兩個因素,在采集相同的數據情況下較PSO-TSP算法能耗降低了11.5%。
[1] García L, Parra L, Jimenez J M, et al. DronAway: A proposal on the use of remote sensing drones as mobile gateway for WSN in precision agriculture[J]. Applied Sciences, 2020, 10(19): 6668.
[2] 宋成寶,柳平增,劉興華,等. 基于HSIC的日光溫室溫度傳感器優化配置策略[J]. 農業工程學報,2022, 38(8):200-207.
Song Chengbao, Liu Pingzeng, Liu Xinghua, et al. Optimal configuration strategy for temperature sensors in solar greenhouse based on HSIC[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(8): 200-207. (in Chinese with English abstract)
[3] Bandur D, Jaksic B, Bandur M, et al. An analysis of energy efficiency in Wireless Sensor Networks (WSNs) applied in smart agriculture[J]. Computers and Electronics in Agriculture, 2019, 156: 500-507.
[4] Polo J, Hornero G, Duijneveld C, et al. Design of a low-cost wireless sensor network with UAV mobile node for agricultural applications[J]. Computers and Electronics in Agriculture, 2015, 119: 19-32.
[5] Zhang B T, Meng L Y. Energy efficiency analysis of wireless sensor networks in precision agriculture economy[J]. Scientific Programming, 2021, 2021: 8346708.
[6] Huang S C, Chang H Y. A farmland multimedia data collection method using mobile sink for wireless sensor networks[J]. Multimedia Tools and Applications, 2017, 76(19): 19463-19478.
[7] Singh P K, Sharma A. An intelligent WSN-UAV-based IoT framework for precision agriculture application[J]. Computers and Electrical Engineering, 2022, 100: 107912.
[8] Yemeni Z, Wang H, Ismael W M, et al. Reliable spatial and temporal data redundancy reduction approach for WSN[J]. Computer Networks, 2021, 185: 107701.
[9] Kumar S, Chaurasiya V K. A strategy for elimination of data redundancy in internet of things (IoT) based wireless sensor network(WSN)[J]. IEEE Systems Journal, 2018, 13(2): 1650-1657.
[10] Rezende J D V, da Silva R I, Souza M J F. Gathering big data in wireless sensor networks by drone(dagger)[J]. Sensors, 2020, 20(23): 6954.
[11] Luo C W, Chen W P, Li D Y, et al. Optimizing flight trajectory of UAV for efficient data collection in wireless sensor networks[J]. Theoretical Computer Science, 2021, 853: 25-42.
[12] Ben Ghorbel M, Rodríguez-Duarte D, Ghazzai H, et al. Joint position and travel path optimization for energy efficient wireless data gathering using unmanned aerial vehicles[J]. IEEE Transactions on Vehicular Technology, 2019, 68(3): 2165-2175.
[13] Gong J, Chang T H, Shen C, et al. Flight time minimization of UAV for data collection over wireless sensor networks[J]. IEEE Journal on Selected Areas in Communications, 2018, 36(9): 1942-1954.
[14] Just G E, Pellenz M E, Lima L A D, et al. UAV path optimization for precision agriculture wireless sensor networks[J]. Sensors, 2020, 20(21): 6098.
[15] Zhang Y, Mou Z Y, Gao F F, et al. Hierarchical deep reinforcement learning for backscattering data collection with multiple UAVs[J]. IEEE Internet of Things Journal, 2021, 8(5): 3786-3800.
[16] 蔣寶慶,陳宏濱. 基于Q學習的無人機輔助WSN數據采集軌跡規劃[J]. 計算機工程,2021,47(4):127-134.
Jiang Baoqin, Chen Hongbin. Trajectory planning for unmanned aerial vehicle assisted WSN data collection based on Q-Learning[J]. Computer Engineering, 2021, 47(4): 127-134. (in Chinese with English abstract)
[17] Yi M J, Wang X J, Liu J, et al. Deep reinforcement learning for fresh data collection in UAV-assisted IoT networks[C]//IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). Toronto, ON, Canada: IEEE, 2020: 716-721.
[18] 付澍,楊祥月,張海君,等. 物聯網數據收集中無人機路徑智能規劃[J]. 通信學報,2021,42(2):124-133.
Fu Shu, Yang Xiangyue, Zhang Haijun, et al. UAV path intelligent planning in IoT data collection[J]. Journal on Communications, 2021, 42(2): 124-133. (in Chinese with English abstract)
[19] Zeng Y, Xu J, Zhang R. Energy minimization for wireless communication with Rotary-Wing UAV[J]. IEEE Transactions on Wireless Communications, 2019, 18(4): 2329-2345.
[20] Padakandla S. A survey of reinforcement learning algorithms for dynamically varying environments[J]. ACM Computing Surveys, 2021, 54(6): 127.
[21] 陳佳盼,鄭敏華. 基于深度強化學習的機器人操作行為研究綜述[J]. 機器人,2022,44(2):236-256.
Chen Jiapan, Zheng Minhua. A survey of robot manipulation behavior research based on deep reinforcement learning[J]. Robet, 2022, 44(2): 236-256. (in Chinese with English abstract)
[22] Fenjiro Y, Benbrahim H. Deep reinforcement learning overview of the state of the art[J]. Journal of Automation, Mobile Robotics and Intelligent Systems, 2018, 12: 20-39.
[23] 張自東,邱才明,張東霞,等. 基于深度強化學習的微電網復合儲能協調控制方法[J]. 電網技術,2019,43(6):1914-1921.
Zhang Zidong, Qiu Caiming, Zhang Dongxia, et al. A coordinated control method for hybrid energy storage system in microgrid based on deep reinforcement learning[J]. Power System Technology, 2019, 43(6): 1914-1921. (in Chinese with English abstract)
[24] Zhang W Y, Gai J Y, Zhang Z G, et al. Double-DQN based path smoothing and tracking control method for robotic vehicle navigation[J]. Computers and Electronics in Agriculture, 2019, 166: 104985.
[25] Wang Z Y, Schaul T, Hessel M, et al. Dueling network architectures for deep reinforcement learning[C]. //In Proceedings of the 33rd International Conference on International Conference on Machine Learning. New York, NY, USA: ICML, 2016: 1995-2003.
[26] Kumar H, Mammen P M, Ramamritham K. Explainable AI: deep reinforcement learning agents for residential demand side cost savings in smart grids[J]. arXiv e-prints, 2019: 1910. 08719.
[27] 趙銘慧,張雪波,郭憲,等. 基于分層強化學習的通用裝配序列規劃算法[J]. 控制與決策,2022,37(4):861-870.
Zhao Minghui, Zhang Xuebo, Guo Xian, et al. A general assembly sequence planning algorithm based on hierarchical reinforcement learning[J], Control and Decision, 2022, 37(4): 861-870. (in Chinese with English abstract)
[28] 楊惟軼,白辰甲,蔡超,等. 深度強化學習中稀疏獎勵問題研究綜述[J]. 計算機科學,2020,47(3):182-191.
Yang Weiyi, Bai Chenjia, Cai Chao, et al. Survey on sparse reward in deep reinforcement learning[J]. Computer Science. 2020, 47(3): 182-191. (in Chinese with English abstract)
[29] Hernandez-Garcia J F, Sutton R S. Understanding multi-step deep reinforcement learning: A systematic study of the DQN target[J]. arXiv e-prints, 2019:1901. 07510.
[30] Chen J, Ye F, Li Y B. Travelling salesman problem for UAV path planning with two parallel optimization algorithms[C]//2017 Progress in Electromagnetics Research Symposium-Fall(PIERS-FALL). Singapore, 2017: 832-837.
[31] 吳媚. 工業物聯網環境下面向能耗優化的無人機飛行規劃系統設計與實現[D]. 南京:東南大學,2019.
Wu Mei. Energy Efficient UAV Flight Planning System for the Industrial IoT Environment[D]. Nanjing:Southeast University, 2019. (in Chinese with English abstract)
UAV collection methods for the farmland nodes data based on deep reinforcement learning
Hu Jie1,3, Zhang Yali2,3※, Wang Tuan1, Wang Mengcheng1, Lan Yubin1,3, Zhang Zhixun2
(1.,,510642,; 2.,,510642,; 3.,510642,)
Unmanned Aerial Vehicle (UAV) has been widely used to collect data from the wireless sensor node in fields. Some problems can be solved in this case, such as no network infrastructure in farmland, fast power consumption of multi-hop data forwarding, premature death of nodes near the gateway, and shortened network life cycle. However, the multiple nodes overlapping can often occur during UAVs collection at the same time, due to the possible redundancy of adjacent sensor data. In this study, a UAV data collection method was proposed to plan the node selection, hovering position, and collecting order using improved deep reinforcement learning. The UAV data collection from the sensor nodes was then divided into two scenarios: data collection from the partial nodes under perceptual redundancy coverage, and data collection from all nodes. The optimization was made to save the UAV energy consumption in less mission completion time. The data collection of partial nodes under perceived redundancy coverage was suitable for the relatively high proportion of redundant coverage area among nodes. The UAV energy also failed to complete the data collection tasks of all nodes, indicating the low requirements of data integrity. By contrast, the all-node data collection fully met the high requirement of data integrity. In the scenario of partial node data collection with perceived redundant coverage, the Dueling Double Deep Q Network (DDDQN) was used to select the collection nodes and then plan the collecting order, indicating the high energy efficiency of the UAV with the less redundant data. Simulation results show that the DDDQN presented greater data coverage and lower effective coverage average energy consumption than the Deep Q Network (DQN) under the same configuration. The training process of DDDQN was more stable than that of DQN, particularly for the higher returns at the end of learning. More importantly, the flight distance and energy consumption of the DDDQN were reduced by 1.21 km, and 27.9%, respectively, compared with the DQN. In the scenario of all-node data collection, a Double Deep Reinforcement Learning (DDRL) was proposed to optimize the hovering position and UAV collection sequence, in order to minimize the total energy consumption of the UAV during data collection. A comparison was made on the DDRL with the classical PSO-TSP and MEFC. A systematic evaluation was made to clarify the impact of the UAV flight speed on the total energy consumption and total working time, the impact of different node data loads on the UAV energy consumption, the impact of different flight speeds on the UAV hover collection time, and the impact of the number of sensor nodes on the total energy consumption. The simulation results show that the total energy consumption of the improved model was at least 6.3% less than that of the classical PSO-based Travel Salesman Problem (PSO-TSP), and the Minimized Energy Flight Control (MEFC) under different node numbers and UAV flight speeds, especially at the data load of a single node less than 160 kB. Finally, the flight and hover powers of the quadrotor UAV were tested to determine the packet loss rate and received signal strength of the UAV in the field experiments. The actual field flight experiments were carried out on the DDRL and the data collection of the classical PSO-TSP. Field experiment results show that the DDRL-based data collection was reduced by 11.5% for the total energy consumption of UAV, compared with the PSO-TSP. The DDDQN and DDRL approaches can be expected to provide the optimal energy consumption for the UAVs' data collection of wireless sensor nodes in the field.
UAV; deep reinforcement learning; node data collection; perceptual redundancy; DQN; DRL
10.11975/j.issn.1002-6819.2022.22.005
S126;S-3
A
1002-6819(2022)-22-0041-11
胡潔,張亞莉,王團,等. 基于深度強化學習的農田節點數據無人機采集方法[J]. 農業工程學報,2022,38(22):41-51.doi:10.11975/j.issn.1002-6819.2022.22.005 http://www.tcsae.org
Hu Jie, Zhang Yali, Wang Tuan, et al. UAV collection methods for the farmland nodes data based on deep reinforcement learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(22): 41-51. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.22.005 http://www.tcsae.org
2022-07-21
2022-10-27
高等學校學科創新引智計劃項目(D18019);國家自然科學基金項目(32271997);廣東省重點領域研發計劃項目(2019B020221001);廣東省科技計劃項目(2018A050506073)
胡潔,博士,副教授,研究方向為農業人工智能,農業物聯網。Email:hjgz79@scau.edu.cn
張亞莉,博士,副教授,研究方向為農業航空傳感器技術與農產品產地環境監測。Email:ylzhang@scau.edu.cn
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
