基于弱監督學習的醫學圖像分割方法研究
2022-03-12 10:03:12程舸帆何良華
電腦知識與技術 2022年3期
程舸帆 何良華



摘要:為提升針對醫學圖像的弱監督語義分割性能,本文從種子線索的生成出發,在CAM網絡訓練中引入多空洞卷積率的空洞卷積,以從圖像級別的標注中產生密集位置預測,擴大響應范圍。實驗證明本文提出的分割模型在CAMELYON16數據集上能得到10個百分點的提升,并通過實驗結果圖證明本文模型可在僅有圖像及標簽已知的情況下為醫生的診斷提供參考。
關鍵詞:弱監督學習;語義分割;乳腺癌數據集;卷積神經網絡;空洞卷積
中圖分類號:TP311? ? ?文獻標識碼:A
文章編號:1009-3044(2022)03-0007-03
開放科學(資源服務)標識碼(OSID):
隨著科學技術的快速發展,計算機性能的飛速提升,近年來智能醫療得到了長足的發展。其中,醫學圖像分割能夠自動化地實現影像數據的組織、病灶等區域的劃分,能夠為醫生提供參考,一定程度上緩解了目前醫生人才短缺的問題。而基于弱監督學習的醫學圖像分割方法研究,實現了人工制作標簽和分割性能之間的平衡,僅利用圖像級標簽就能夠實現像素級的預測,大大消除了人工制作標簽的繁瑣,推動了醫學圖像分割領域的發展。
如今大多數弱監督語義分割網絡框架是在由 Alexander Kolesnikov等人[1]提出的SECNet的基礎上衍生而來的,雖然SECNet在Pascal voc2012[2]數據集上的表現優于傳統弱監督語義分割方法,如CCNN[3],EM-Adapt[4]等,但是其還是存在存在分割區域不完整、分割結果不準確等問題。對于特異性較強的數據集如醫學圖像數據集,SECNet的局限性就會更明顯。
為了解決SECNet無法精準地定位像素級目標區域以得到高質量的目標邊緣的問題,我們從種子標簽的生成出發,引入多擴張率的空洞卷積使目標響應區域增大。這樣偽像素級標簽能夠更好地貼近圖像本身病灶區域,使其分割性能得到明顯提升。
1 相關工作
1.1 類激活映射圖
在分類網絡訓練中,類激活映射圖(class activation map)[5]可以幫助我們了解到網絡關注圖片的哪塊區域,可以實現對圖片前景區域的初步定位。CAM的主干網絡可以為任意一種常用的卷積神經網絡模型如ResNet、VggNet等,但是用了GAP(global average pooling)[6]來代替網絡的全連接層,這不僅能大大減少參數量,也使每個特征通道與其權重一一對應,實現了定位能力。
1.2 條件隨機場
條件隨機場(conditional random filed)[7]經常用作對語義分割網絡的輸出做后處理,使分割結果更為精細。CRF中的一元勢能由分割網絡給出的類別概率得到,二元勢能取決于圖像上每兩個像素點間的相似性,具體由像素點的距離與顏色決定。隨著CRF的多輪迭代,可以對深度神經網絡的輸出進行細節補充。
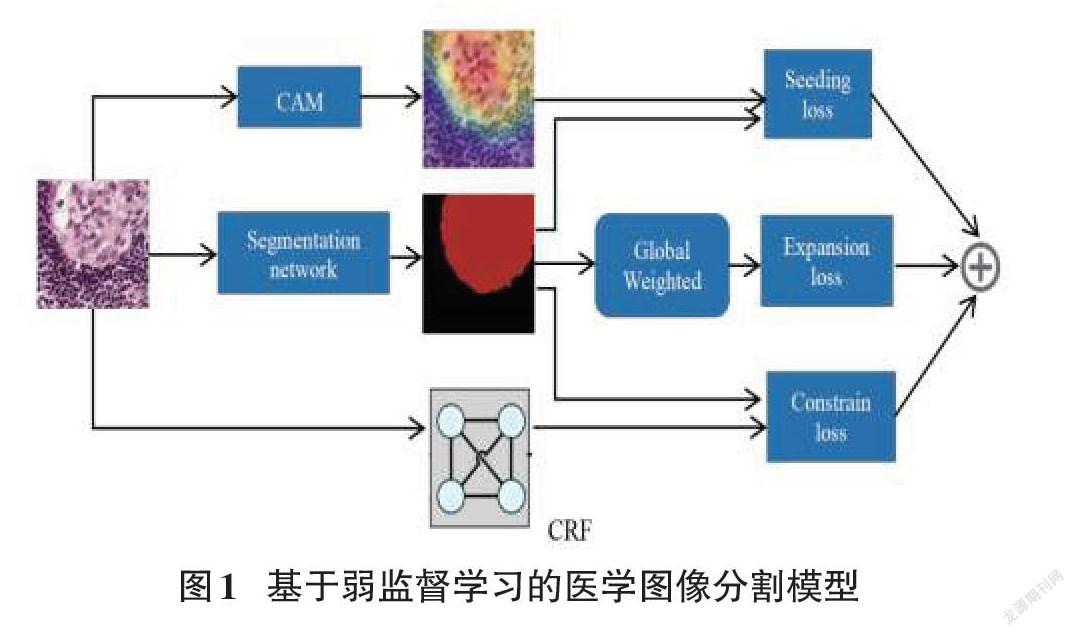
2 基于弱監督學習的醫學圖像分割模型
本論文提出的弱監督語義分割模型以SECNet為基礎,為了提升性能,引入了不同空洞率的空洞卷積,使CAM圖的初始定位更加準確。具體模型結構如圖1所示:
2.1 使用多空洞卷積率的CAM
弱監督圖像分割最大的挑戰在于如何精準地定位像素級目標區域以得到高質量的目標邊緣,而使用基礎3*3卷積的CAM在分割大的目標時在目標物體處不集中,其不足以從圖像級別的標注中產生密集位置預測。為了解決這個問題,我們在特征提取網絡最后一層引入空洞率分別為2,4,6的空洞卷積(如圖2所示),不同空洞率的空洞卷積不但可以擴大核的感受野,更重要的是還能將環境的判別信息推廣轉換至類別不明確的區域。
我們使用[H0]和[Hi] (i = 1...n,n為空洞卷積率)代表分別由標準卷積與不同卷積率卷積得到的定位圖,最終的定位圖由以下公式得到:[H=H1+1ndi=2ndHi]
如圖3所示從左至右依次是普通卷積得到的種子線索、采用多卷積率并平均后的種子線索、ground_truth,可以看到引入不同空洞卷積率后定位像素級目標區域準確率大幅提升。
3 實驗與結果分析
3.1 實驗數據
本論文實驗均基于CAMELYON16數據集[8]。此數據集由CAMELYON16比賽提供,在本篇論文中我們使用此數據集來進行乳腺癌圖像的弱監督語義分割。該數據集由270張被蘇木素伊紅染色的全片乳腺癌病理圖像(whole-silde images,wsi)組成.由于全片病理圖像屬于超大分辨率圖像,每張圖片大小超過2GB,每張癌癥圖像上也包括多個癌癥像素點區域。為了將圖像能夠送入網絡處理,我們需要對WSI圖像進行預處理,即利用數據集中專家給出的像素級標簽——xml文件來對每張圖片進行切割。利用xml文件中癌癥區域與非癌癥區域的中心點坐標將原始超大圖像切割成若干大小為512*512的圖像。經過切割與篩選,最終我們得到癌癥圖像與正常圖像各900張,我們隨機選取其中800張為訓練數據,100張為測試數據。然后對訓練數據集進行水平旋轉,垂直旋轉,水平加垂直旋轉、[90°]? 、[180°]? ? 以及? [270°]? 六種操作,將數據集擴大至原來7倍。
3.2 訓練流程
本文實驗主要考慮原SECNet模型與經過本文改善的模型SECNet+Atrous,下面的訓練流程對兩個模型均一致:
本文實驗基于python3.8環境與pytorch1.0框架,顯卡為NVIDIA GEFORCE 1080Ti。使用像素準確率(PA),Miou與Dice三種評價指標進行模型評測。所有訓練圖像的大小均為512*512,batchsize為15。優化算法為動量為0.9,學習率為0.001的SGD優化算法。在訓練CAM得到初步種子線索時,分類網絡框架使用VGG16,并把網絡最后的全連接層修改為GAP層,分割網絡模型框架使用deeplabv3+,CRF的迭代次數設置為10。除此以外,實驗還進行了全監督對比實驗,采用FCN[9]全監督模型,對實驗數據集進行全監督語義分割訓練,并與弱監督語義分割結果進行對比。
3.3 結果分析
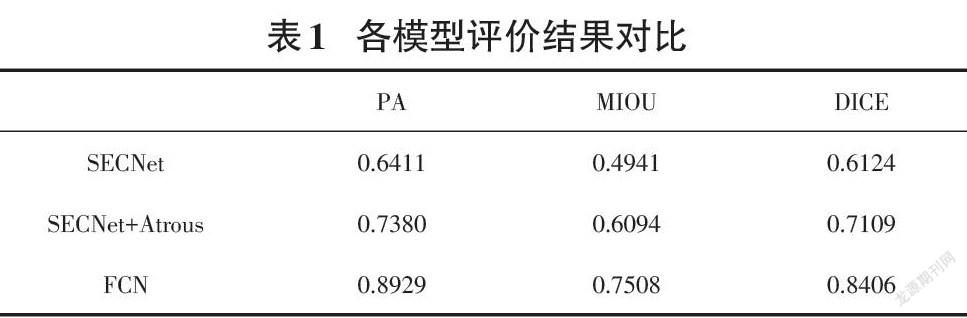
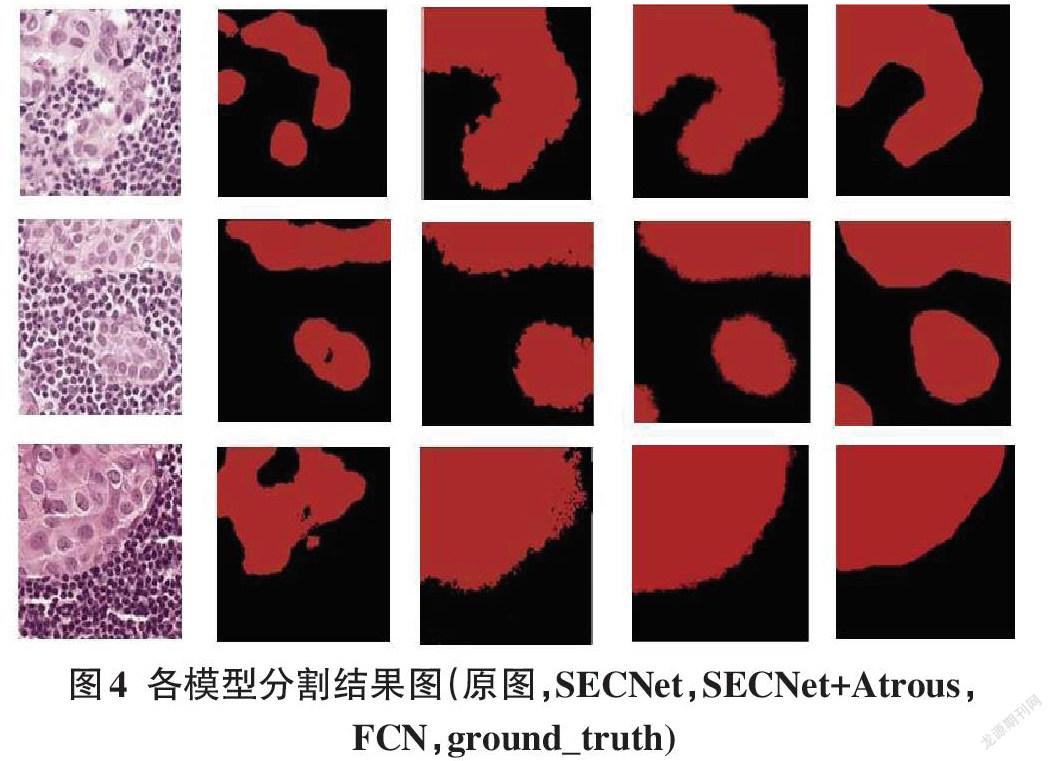
由表1和圖6分析可得,將CAM網絡中普通卷積改為多空洞卷積后,響應區域能適當擴大,變得更完整,性能提升顯著,MIOU提高了10個百分點左右。雖然弱監督語義分割的性能距離全監督還有較大差距,但是他們的已知條件就不是同一層次的,全監督訓練所需的像素級標簽需要耗費巨大的精力才能得到。故在已知條件有限的情況下,弱監督語義分割能為醫生的診斷提供參考。
4.結論
本文提出的基于弱監督學習的醫學圖像分割模型,在種子線索的生成中引入多卷積率的空洞卷積使分割結果中病灶區域更完整,更準確地對每一像素點進行分類。并通過對比實驗證明了本文方法的有效性。
參考文獻:
[1] Kolesnikov A,Lampert C H.Seed,expand and constrain:three principles for weakly-supervised image segmentation[C]//Computer Vision - ECCV 2016,2016.
[2] Everingham M, Winn J. The pascal visual object classes challenge 2012 (voc2012) development kit[J].Pattern Analysis,Statistical Modelling and Computational Learning, Tech. Rep,2011,8.
[3] Pathak D,Kr?henbühl P,Darrell T.Constrained convolutional neural networks for weakly supervised segmentation[C]//2015 IEEE International Conference on Computer Vision (ICCV).December 7-13,2015,Santiago,Chile.IEEE,2015:1796-1804.
[4] Papandreou G,Chen L C,Murphy K P,et al.Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation[C]//2015 IEEE International Conference on Computer Vision (ICCV).December 7-13,2015,Santiago,Chile.IEEE,2015:1742-1750.
[5] Zhou B L,Khosla A,Lapedriza A,et al.Learning deep features for discriminative localization[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:2921-2929.
[6] Lin M,Chen Q,Yan S.Network In Network[J].Computer Science,2013.
[7] Krhenbühl, Philipp,? Koltun V . Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials[J].Curran Associates Inc,2012.
[8] Camelyon 2016. 2016. https://camelyon16.grand-challenge.org
[9] Shelhamer E,Long J,Darrell T.Fully convolutional networks for semantic segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(4):640-651.
【通聯編輯:梁書】
