全局與局部模型交替輔助的差分進化算法
2022-03-12 05:55:58于成龍付國霞孫超利張國晨
計算機工程 2022年3期
于成龍,付國霞,孫超利,張國晨
(太原科技大學計算機科學與技術學院,太原 030024)
0 概述
隨著科學技術的快速發展,工農業生產、國防建設、醫療衛生、人民生活等各個領域對工程產品性能的要求不斷提高,工程優化問題也變得越來越復雜。元啟發式優化算法(包括進化算法和群智能優化算法)相比于傳統的單點迭代算法對目標函數無連續可微的要求,具有更大的概率找到全局最優解,且不一定需要有顯式的目標函數公式,在大型電力系統[1-2]、天線設計[3-4]、航空航天及汽車設計[5-6]等科學研究和工程優化中具有廣泛應用。然而,元啟發式優化算法在獲得最優解之前通常需要進行多次目標函數評價。因此,在目標函數計算費時的情況下,很難應用元啟發式優化算法來搜索問題的最優設計方案[7]。基于歷史數據建立代理模型用來輔助元啟發式優化算法,在評價次數有限的情況下搜索全局最優解是目前常用的求解計算費時問題的優化方法[8-9]。相比于計算費時的原優化問題的目標函數評價,訓練代理模型所需計算時間成本是低廉的,主要包括多項式回 歸(Polynomial Regression,PR)[10]、徑向基函數(Radical Basis Function,RBF)[11]、高斯過程(Gaussian Process,GP)[12]、人工神經網絡(Artificial Neural Network,ANN)[13-14]和支持向量回歸(Support Vector Regression,SVR)[15]等常見的代理模型。
元啟發式優化算法中根據模型的用途可以將代理模型分為全局代理模型和局部代理模型。在通常情況下,全局代理模型用于平滑原問題的局部最優解,并引導搜索算法快速定位到最優解附近。LIU等[16]提出一個求解中等規模費時優化問題的高斯過程輔助的進化算法。SCHNEIDER 等[17]采用高斯過程模型的貝葉斯優化以改進具有許多自由度的光學結構。TIAN 等[12]提出一個高斯過程輔助的進化算法(MGP-SLPSO),采用多目標填充準則的方式選擇真實評價的個體。YU 等[18]提出一種最優重啟策略代理輔助的社會學習粒子群優化算法(GORSSSLPSO),集成了重啟策略和全局RBF 代理模型以提供功能強大的優化器來解決計算耗時的問題。局部代理模型則用于較好地擬合原問題在某一個區域中的函數形狀,從而輔助算法在該區域中進行搜索,從而提高最優解精度。LIM 等[7]使用集成和平滑的局部代理模型同時進行局部搜索,共同生成可靠的適應值預測和搜索改進策略。適應值繼承是一種特殊的局部代理模型,SUN 等[19-20]基于同一代兄弟個體和父代個體提出一種新的適應值估計策略。全局和局部混合代理模型相比于使用單全局代理模型或者單局部代理模型在輔助優化算法搜索最優解時具有較好的搜索性能。WANG 等[21]提出基于主動學習的代理模型輔助的粒子群優化算法(CAL-SAPSO),結合全局和局部代理模型管理策略進行優化。SUN等[11]提出代理模型輔助的協同優化算法,利用RBF全局代理模型輔助社會學習微粒群算法進行全局最優解的探索,同時利用適應值估計策略輔助的微粒群算法進行局部開采,從而實現對高維計算費時優化問題的求解。YU 等[22]提出代理模型輔助的分層粒子群優化算法(SHPSO),與代理模型輔助的協同優化算法不同,在SHPSO 中,社會學習粒子群優化用于進行局部空間的開采,而粒子群優化用于在全局空間中進行探索,從而提高全局最優解的尋找性能。LI 等[23]提出一種求解高維費時問題的代理輔助的多種群優化算法(SAMSO),全局和局部代理模型分別輔助兩個種群進化,同時兩個種群通過相互學習來提高算法的搜索性能。LIAO 等[24]利用所有歷史樣本訓練全局代理模型,采用最優的若干樣本訓練局部代理模型,并通過多任務優化方法搜索兩個模型的最優解。
混合代理模型輔助的元啟發式優化算法能夠利用不同模型的優勢,相比于單代理模型能夠更好地輔助優化算法在評價次數或者計算資源有限的情況下找到較優解。本文基于已有的歷史數據,通過不同的樣本選擇策略建立全局代理模型和局部代理模型。對全局代理模型和局部代理模型進行最優解的交互搜索,通過對全局代理模型的搜索實現對原問題最優解的探索,模型最優解根據真實計算用于更新局部代理模型,使其能夠更好地擬合目前最優解附近的局部區域,通過對局部代理模型最優解的搜索提高獲得更優解的概率。
1 相關技術
1.1 徑向基函數網絡
徑向基函數網絡(Radial Basis Function Network,RBFN)是一種包含輸入層、隱藏層和輸出層共三層的神經網絡。RBFN 作為代理模型在輔助優化算法中具有較好的擬合效果,且其擬合效果對于問題維度的增加相對不敏感[25-26]。給定樣本庫{(xi,f(xi)),i=1,2,…,Na},Na表示樣本庫中初始樣本數量,RBFN 模型可表示如下:

其中:ω=為RBF 網絡的輸出權重;Nc為隱含層節點數;φ(·)為徑向基核函數;ci為第i個隱含節點徑向基函數的中心。常見的核函數有高斯核、線性核、多重二次曲面核、立方核等[27]。本文算法中徑向基核函數采用立方核函數。
1.2 差分進化算法
差分進化(Differential Evolution,DE)算法在許多優化問題上已被證明是一個簡單有效的進化算法[28-29],遵循進化算法的一般流程,即首先在問題決策空間中產生一個初始化種群{x1(t),x2(t),…,xN()t},其中,t=0,N為種群大小,xi=(xi1,xi2,…,xiD)表示第i個個體,D表示問題的維度。然后通過變異、交叉和選擇操作找到問題的最優解。在DE 算法中,常見的變異策略有DE/rand/1、DE/current-to-best/1和DE/best/1等[30]。本文算法中采用標準的DE/rand/1變異策略,即對于每一代t,隨機選擇3 個不同于當前個體i的個體,并通過以下公式得到變異后的向量vi(t):

其中:r0、r1和r2為[1,N]中3 個不同的隨機數;和表示當前種群中不同于個體xi的3 個個體;Fi稱為DE 的變異因子。
每個個體根據一定的概率在各個維度上進行交叉操作,通過式(3)的交叉方法得到交叉后的向量ui(t+1)=(ui1(t),ui2(t),…,uiD(t))。uij(t+1)的計算公式如下:

其中:CRj∈[0,1]為交叉概率;jrandint為[1,D]中隨機產生的一個整數。對每個向量ui(t+1)計算目標函數值,并與其父代個體進行適應值的對比,保留較優的個體作為下一代的父代個體,即:

2 全局與局部代理模型交替輔助的DE 算法
2.1 算法整體流程
算法1 給出了全局與局部代理模型交替輔助的差分進化算法AGL-DE 的偽代碼。首先,通過拉丁超立方體產生一定數量的初始樣本,對其使用真實的目標函數評價并將其存入數據集Arc 中。基于這些真實評價的個體確定當前最優解,記為gbest。然后,若沒有達到停止條件,即達到最大的評價次數,則循環執行以下操作:交替建立全局代理模型和局部代理模型并對模型進行最優解搜索,搜索到的最優解進行真實目標函數的計算,存入數據集Arc 中,并更新最優解gbest。最后,詳細介紹全局代理模型和局部代理模型的訓練(步驟6 和步驟10)及其優化。
算法1AGL-DE 算法


2.2 全局代理模型的訓練與優化
在代理模型輔助的進化算法中,為了保證算法的收斂性,通常選用適應值最優的若干個樣本來訓練模型,但是這樣會導致算法很快陷入局部最優,使得算法性能下降。本文選擇具有代表性的樣本建立全局代理模型,并通過在決策空間對全局代理模型最優解的搜索提高算法探索能力,防止算法陷入局部最優。文獻[31]表明全局代理模型并非一定需要與原函數精確擬合,其主要作用在于平滑掉局部最優,加速定位到全局最優解附近。為此,本文通過計算每個樣本xi和其最近鄰個體之間的擁擠度(記為C(xi))來選擇全局代理模型的訓練樣本。計算方式為對Arc 中個體按照目標函數值從小到大排序,對任意個體xi,其擁擠度為相鄰兩個個體的目標函數之差。顯然,擁擠度越大,說明該個體和其他個體之間的目標函數差值越大,擁擠度越小,說明和該個體的目標函數的相似度較大。為了更好地訓練全局代理模型,選擇擁擠度大且考慮估值小的樣本個體來訓練模型。通過-max 的方式將最大化擁擠度轉換成最小化問題,根據個體擁擠度和其適應值進行非支配排序,并從非支配排序后的第一層開始選擇該層的所有樣本放入訓練樣集,直到當加入第k層的所有樣本選擇出的樣本數大于預定樣本數時,在第k層隨機選擇樣本直到達到預定樣本數,并利用選擇出的所有樣本訓練全局代理模型。使用差分進化算法搜索模型的最優解,并對其進行真實的目標函數計算。需要注意的是對模型進行最優解搜索時,初始化種群中的個體來自:1)使用拉丁超立方體采樣技術得到的初始個體;2)數據集Arc 中適應值較優的若干個體。初始化種群中增加Arc 中適應值較優的個體是為了加快模型最優解的搜索速度。將經過真實目標函數計算的模型最優解存入樣本庫Arc 中并更新目前找到的最優解gbest。算法2 為算法1 中訓練全局代理模型的偽代碼。
算法2全局代理模型訓練算法


2.3 局部代理模型的訓練與優化
為快速找到更優解,利用數據集Arc 中的若干最優解建立局部代理模型。算法3 給出了訓練局部代理模型的偽代碼。與訓練全局代理模型類似,從數據集Arc 中選擇一定數量的訓練數據訓練局部代理模型。利用差分進化算法進行局部代理模型最優解的搜索。對找到的局部代理模型最優解使用真實的目標函數進行計算,存入數據集Arc 中并更新目前計算得到的最優解。
算法3局部代理模型訓練算法

3 實驗設計與結果分析
為評估AGL-DE 算法的性能,在7 個單目標基準問題[7,32]上進行測試,這7 個基準問題的函數名稱、全局最優值和函數特征如表1 所示。本節首先給出了AGL-DE 算法的參數設置,然后將其與近年來提出的求解費時問題的優化算法在測試函數上進行結果比較,最后對算法框架、參數進行敏感性分析。所有算法均獨立運行25 次,并通過顯著性水平為0.05 的帶有Bonferroni校驗的Wilcoxon 秩和檢驗方法[33]對25 次獨立運行結果進行顯著性統計檢驗。
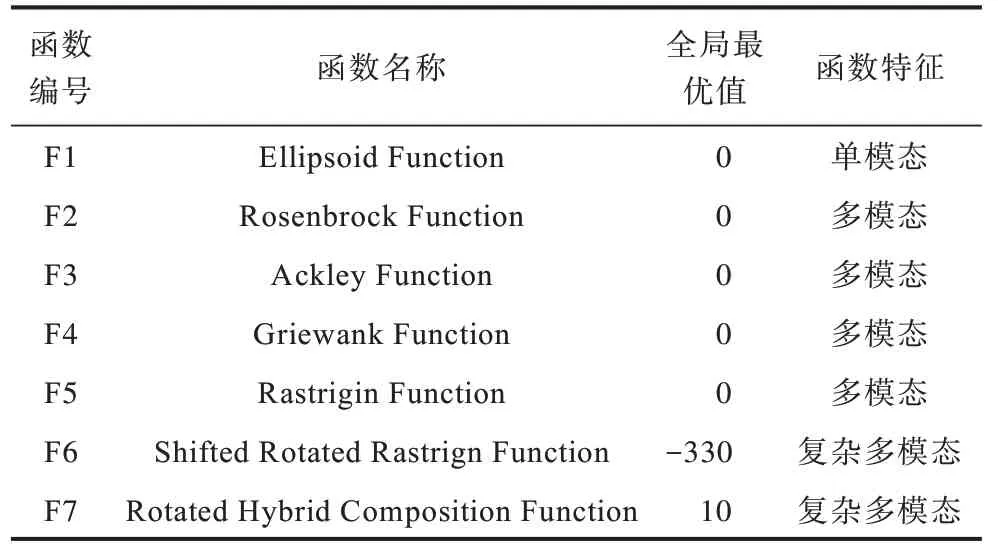
表1 基準函數特性Table 1 Characteristics of the benchmark functions
3.1 參數設置
在AGL-DE 算法中,不同的代理模型均可作為全局與局部代理模型,本文采用RBF 代理模型,主要原因在于RBF 代理模型對于高維問題具有較好的擬合效果[22]。訓練RBF 代理模型的最小樣本數為2×D。實驗中初始產生的樣本數為2×D,隨著評價次數增多,Arc 中真實計算的樣本數增多。若樣本過多,則訓練模型的速度會減慢,因此在實驗中設定訓練模型的最大樣本數為5×D,在每次模型訓練時訓練模型的樣本數為[2×D,5×D]中的一個隨機整數Nt。需要注意的是若產生的隨機整數Nt大于當前已有樣本數,則Arc 中所有樣本均參與模型的訓練,否則從Arc 中隨機挑選Nt個數據進行模型訓練。對于模型最優解的搜索,初始種群大小設置為50,從Arc中選擇的最優解個數為[40,50]中的一個隨機整數,剩余的初始解使用拉丁超立方體方法產生。迭代次數設置為[D,4×D]中產生的一個隨機整數。使用DE/rand/1 作為變異策略,二項式交叉作為DE 的交叉策略,變異因子設置為0.5,交叉概率設置為0.3。在實驗對比中,所有算法的終止條件均為達到最大的真實評價次數,在10、20 和30 維的低維測試問題上算法評價11×D次,在50 和100 維的高維測試問題上算法評價1 000 次。
3.2 與其他算法的實驗結果對比分析
表2 給出了AGL-DE 與GORS-SSLPSO[18]、CAL-SAPSO[21]、DDEA-SE[34]、SHPSO[22]算法在低維測試問題上的統計結果,其中,符號“+”、“-”和“≈”分別表示AGL-DE 算法相較于其他算法具有顯著性優、顯著性差和沒有顯著性差異,加粗數據表示該數據對應的算法找到的解是所有算法中最優的,最后一行的數字分別表示AGL-DE 算法相較于其他算法具有顯著性優的個數、顯著性差的個數和沒有顯著性差異的個數。SHSPO 算法在低維問題上只涉及了30 維,因此僅對SHPSO 算法在30 維問題上的結果進行比較。從表2 可以看出,除了F5 測試問題以外,AGL-DE 算法在F1~F4 這4 個測試問題上基本優于其他算法,雖然GORS-SSLPSO 算法在F4 上的結果略好,但是與AGL-DE 算法并沒有顯著性差異。

表2 AGL-DE 與GORS-SSLPSO、CAL-SAPSO、DDEA-SE、SHPSO 算法在低維測試問題上的統計結果Table 2 Statistical results of AGL-DE and GORS-SSLPSO,CAL-SAPSO,DDEA-SE,SHPSO algorithms on low-dimensional test problems
表3 給出了AGL-DE 與GORS-SSLPSO[18]、MGP-SLPSO[12]、DDEA-SE[34]、SHPSO[22]、SAMSO[23]算法在高維測試問題上的統計結果。從表3 中可以看 出,AGL-DE 算法相比于 GORS-SSLPSO、MDP-SLPSO、DDEA-SE、SHPSO、SAMSO 算法在高維問題上獲得了13/14、8/14、13/14、10/14 和9/14 的更好解。此外,還可以看出AGL-DE 算法在5/7 個100 維測試問題上獲得了比其他算法更優的結果,表明AGL-DE 算法對于高維問題具有較好的求解效果。

表3 AGL-DE 與GORS-SSLPSO、MGP-SLPSO、DDEA-SE、SHPSO、SAMSO 算法在高維測試問題上的統計結果Table 3 Statistical results of AGL-DE and GORS-SSLPSO,MGP-SLPSO,DDEA-SE,SHPSO,SAMSO algorithms on high-dimensional test problems
為更好地分析算法的收斂性能,圖1、圖2 分別給出了AGL-DE 算法和其他算法在低維和高維測試問題上的函數收斂曲線圖,橫坐標代表真實適應值的評估次數,記為T,為了能夠更加明顯地觀察收斂曲線圖的變化情況,縱坐標用25 次獨立運行得到的適應值的中值的對數表示,記為lg(F(xT)),其中xT為算法第T次真實適應值評估下找到的最優解,F(xT)為xT對應的目標函數值。

圖1 AGL-DE 與GORS-SSLPSO、CAL-SAPSO、SHPSO 算法在低維測試問題上的函數收斂曲線圖Fig.1 Function convergence curves of AGL-DE and GORS-SSLPSO,CAL-SAPSO,SHPSO algorithms on low-dimensional test problems

圖2 AGL-DE 與GORS-SSLPSO、MGP-SLPSO、SHPSO、SAMSO 算法在高維測試問題上的函數收斂曲線圖Fig.2 Function convergence curves of AGL-DE and GORS-SSLPSO,MGP-SLPSO,SHPSO,SAMSO algorithms on high-dimensional test problems
由于F6 測試問題的適應值可能是負值,因此在該測試問題的收斂曲線圖上沒有對適應值進行取對數操作。需要注意的是,DDEA-SE 算法是一種基于數據驅動的離線優化算法,在優化的過程中不會產生需要真實適應度評估的個體,故沒有給出其收斂曲線圖。
從圖1 可以看出,AGL-DE 在F1~F4 測試問題上都比其他算法具有更快的收斂速度,在低維的單模態和多模態問題上都展現了良好的性能。對于高維優化問題,從圖2 可以看出,本文所提AGL-DE 算法在大部分優化問題上具有較快的收斂速度。但是從圖2 也可以看出其容易陷入局部最優,如50 維的F2、F3、F5 和F7 測試問題,在搜索算法到達一定程度后不再繼續下降。由此分析其早熟收斂的主要原因在于初始樣本的選擇。從Arc 中選擇若干最優解作為DE 的初始種群,當這些解的差別較小時,初始種群的多樣性較差。這些解雖然能夠引導算法快速收斂到某一個解,但是很難跳出局部最優,從而導致了算法的早熟收斂。
3.3 全局與局部代理模型有效性分析
為驗證全局與局部代理模型交替輔助的有效性,將其與僅使用全局代理模型輔助進化算法(G-DE)和僅使用局部代理模型輔助進化算法(L-DE)進行實驗結果比較,在實驗過程中其他參數設置與3.1 節的設置相同。表4 給出了AGL-DE、G-DE 和L-DE 算法在10 維、20 維和50 維的F1、F3 和F4 測試問題上的統計結果。從統計結果上來看:AGL-DE 比G-DE 顯著性好3 個,顯著性差1 個,無顯著性差異5 個;AGL-DE 比L-DE 顯著性好3 個,顯著性差2 個,無顯著性差異4 個。統計結果表明:全局代理模型和局部代理模型交替輔助差分進化算法比單一模型輔助差分進化算法的效果好。
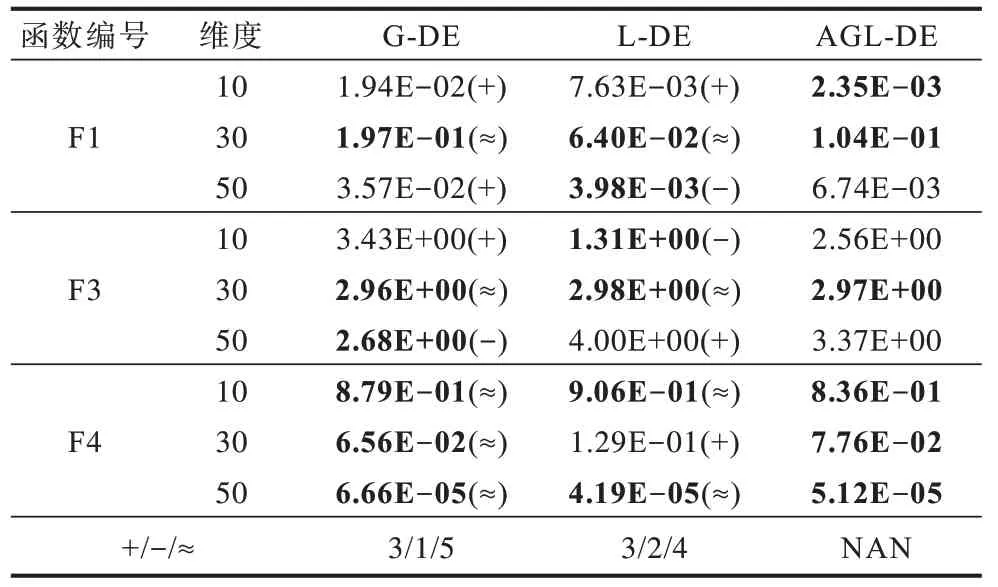
表4 AGL-DE 與G-DE、L-DE 算法在F1、F3 和F4 測試問題上的統計結果Table 4 Statistical results of AGL-DE and G-DE,L-DE algorithms on F1,F3 and F4 test problems
3.4 參數敏感性分析
為驗證在一定區間內隨機產生的訓練集樣本數Nt、種群迭代次數iter 和從Arc 中選擇的初始樣本數Na的有效性,在不改變其他參數設置的情況下,與固定這3 個參數的3 種策略進行比較,分別將它們固定為區間內的最小值、中值和最大值,即min-values、med-values 和max-values,具體參數設置如表5 所示。在這3 種策略上對50 維和100 維的F1、F2、F4 和F6 測試問題進行測試,表6 給出了AGL-DE 算法和這3 種策略的對比統計結果,可以看出在一定區間內隨機生成參數的AGL-DE 算法要比單純固定這些參數的3 種策略具有更好的性能。

表5 3 種策略的參數設置Table 5 Parameter settings of three strategies

表6 AGL-DE 算法與min-values、med-values、max-values策略在F1、F2、F4 和F6 測試問題上的統計結果Table 6 Statistical results of AGL-DE algorithm and min-values,med-values,max-values strategies on F1,F2,F4 and F6 test problems
4 結束語
本文提出一種全局與局部代理模型交替輔助的差分進化算法,通過對全局代理模型和局部代理模型最優解的交替搜索來更新數據集以及原費時優化問題的最優解,從而在計算資源有限的情況下獲得問題的更優解。實驗結果表明,相比于近年來提出的求解費時問題的優化算法,該算法在低維和高維測試問題上均獲得了較好的尋優效果,然而在某些高維測試問題上容易陷入局部最優,導致早熟收斂。因此在下一步工作中將考慮增強算法多樣性,以便跳出局部最優,從而在計算資源有限的情況下找到目標函數的更優解。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
