基于深度學習的中醫古籍缺失文本修復研究
2022-03-13 08:02:58盧彥杰
中華醫學圖書情報雜志 2022年8期
盛 威,盧彥杰,劉 偉,胡 為,周 沖
中醫古籍是中醫藥學傳承和發展的載體,既具有重要的學術價值,又具有文物價值,中醫藥古籍文獻中所收載的理法、方藥、養生保健知識是取之不盡、用之不竭的寶庫,具有極高的實用價值[1]。中醫古籍反映了中醫藥學在歷史上為中華民族的繁衍昌盛作出的偉大貢獻和取得的輝煌成就,更重要的是,它所蘊藏保存下來的民族文化遺產和智慧結晶必將在新的歷史時期為人類醫藥科學事業的發展作出不可估量的貢獻[2]。
但中醫古籍在長期的流傳過程中,不僅遭受自然的侵蝕,也會受到人為的損壞,同時中醫專業圖書館的古籍藏書可能由于沒有得到很好的保存,即使經過修復,仍存在破損的現象,而且圖書館的書庫環境欠佳、保護手段不足都可能導致中醫古籍的損壞[3]。因此對中醫古籍進行整理和修復是十分必要的,而目前的修復工作主要是由古籍修復專家通過專業手段手動修復,要求其對古漢語和中醫古籍有廣泛且深入的研究,非常耗時費力。
近年來,深度學習[4]技術快速興起,在自然語言處理[5]領域已經取得了顯著進展,而語言模型[6]作為最早采用神經網絡研究自然語言處理問題的技術,可以根據上下文信息自動填充句子或段落中缺失的部分,實現對中醫古籍缺失部分的修復。因此,將深度學習技術,特別是語言模型技術應用于中醫古籍修復,可以降低中醫古籍的修復難度。
1 數據來源
運用Python 爬蟲技術從公開資源中爬取自秦漢以來的包括《黃帝內經》《金匱要略》《傷寒雜病論》《神農本草經》等經典中醫古籍在內的608本中醫古籍文本,結合機器校對和人工校對方法對古籍進行整理,并使用Python 語言編寫文本清洗、去重、合并腳本,去除文本中多余的HTML 標簽、廣告等噪音信息,排除重復收集的文本,經過合并最終形成了一個83 032 043 字的全面的、高質量的中醫古籍文本語料庫。
2 研究方法與過程
本文將基于構建的高質量中醫古籍文本語料庫及語言模型,在經過語料庫劃分的《黃帝內經》語料庫訓練集、先秦兩漢語料庫訓練集上分別訓練N 元(N-gram)模型、長短期記憶(Long Short-Term Memory,LSTM)模型、雙向長短期記憶(Bidirectional LSTM,BiLSTM)模型和穩健優化的BERT 預訓練方法(A Robustly Optimized BERT Pre-training Approach,RoBERTa)模型,并在中醫古籍文本語料庫上單獨訓練RoBERTa 模型,對比篩選出最優模型,并將篩選出的最優模型運用到文本修復場景中,最終在表現效果最優的RoBERTa 中醫古籍模型輸出的前10 條預測中,有60.79%的幾率可以直接獲得正確的缺失內容,80.57%的幾率出現正確的預測。
2.1 語言模型
如果將自然語言視為一系列離散標記x1,…,xT,那么語言模型的任務就是要給出一個可以表示任意一個句子或序列出現的概率分布p(x1,…,xT)。利用貝葉斯公式,可以將p(x1,…,xT)分解為[7],也就是給定前面的詞,求后面一個詞出現的條件概率,這意味著可以將中醫古籍缺失文本修復的問題簡化為根據缺失內容的上下文信息預測所缺失內容的問題。在模型最終測試階段,向模型輸入一條以“
常用的語言模型分為以N-gram 模型[8]為代表的傳統統計語言模型和以NNLM 模型[9]、LSTM模型[10]為代表的神經網絡語言模型,以及由神經網絡語言模型發展來的以基于變換器的雙向編碼器表示技術(Bidirectional Encoder Representation from Transformers,BERT)[11]為代表的預訓練語言模型,如生成式預訓練模型(Generative Pre-Training,GPT)[12]、RoBERTa 模型[13]、廣義自回歸預訓練語言模型(Generalized autoregressive pretraining for language understanding,XLNet)[14]等一系列模型。其中RoBERTa 模型在BERT 模型的基礎上增加了大量訓練參數和訓練數據,在訓練過程中使用更大的單次訓練樣本,且在語言表征中使用了雙字節編碼,提高了詞匯表征的準確度和任務執行效率[15]。相較于傳統的統計語言模型和神經網絡語言模型,預訓練語言模型在大規模語料的處理上更具優勢,預訓練提供的模型初始化參數可以使模型在目標任務上有更好的泛化性能和更快的收斂速度,同時在小規模數據上也能避免過擬合現象的發生。雖然預訓練語言模型取得了很大成功,但目前大多數預訓練模型都是基于大量通用語料訓練的,在面對特定領域文本的自然語言處理任務時,其功能的發揮容易受限。由于古代漢語在語法、語義、語用上與現代漢語存在較大差異,即使是面向中文構建的Chinese-BERT 模型,在古漢語處理上也難以達到其在現代漢語通用語料上的性能,直接調用預訓練模型預測中醫古籍中缺失的文本,并不能取得較好的效果[16]。因此需要構建高質量的中醫古籍文本語料庫,在中醫古籍文本語料庫的基礎上訓練面向中醫古籍文本處理的預訓練語言模型,最終訓練得到的中醫古籍預訓練模型不僅可以用于中醫古籍缺失內容的預測,也可以在微調之后用于中醫古籍文本的命名實體識別、關系抽取、文本分類等下游任務。
本文使用PyTorch[17]深度學習框架分別訓練N-gram 模型、LSTM 模型和BiLSTM 模型[18],并基于Transformers 預訓練模型[19]微調RoBERTa 模型,從而訓練出中醫古籍修復的最優模型。
2.2 中醫古籍修復模型構建
中醫古籍缺失文本的修復模型構建流程如圖1 所示,主要包括數據收集與預處理、語料庫劃分、模型訓練、模型測試等環節。

圖1 中醫古籍修復模型實驗流程
2.2.1 語料庫劃分
為了研究語料庫的選擇對中醫古籍修復工作的影響,將中醫古籍文本語料庫劃分為《黃帝內經》語料庫、先秦兩漢語料庫,以及完整的中醫古籍文本語料庫。在劃分完成的3 個語料庫的基礎上分別對語料庫進行分割,將其中的80%作為訓練集、20%作為測試集。
2.2.2 模型訓練
在劃分完成的《黃帝內經》語料庫訓練集、先秦兩漢語料庫訓練集上分別訓練N-gram 模型、LSTM 模型、BiLSTM 模型和RoBERTa 模型,并在中醫古籍文本語料庫上單獨訓練RoBERTa 模型。最終訓練出了可以用于文本修復的N-gram《黃帝內經》模型和N-gram 先秦兩漢模型、LSTM《黃帝內經》模型和LSTM 先秦兩漢模型、BiLSTM《黃帝內經》模型和BiLSTM 先秦兩漢模型、RoBERTa《黃帝內經》模型和RoBERTa 先秦兩漢模型,以及RoBERTa 中醫古籍模型。
2.2.3 模型測試
訓練完成后,分別在對應的測試集上對訓練出的各模型進行測試。測試語料的設置模擬文本修復場景,對古籍文本中的某條語句隨機抹去其中的某一個字。圖2 為節選出的10 條《黃帝內經》測試語料,一行一條語句,用“

圖2 《黃帝內經》測試語料節選
2.2.4 中醫古籍修復模擬
為了評估模型在真實中醫古籍文本修復場景的應用效果,以《黃帝內經》為修復對象,在整個中醫古籍文本語料庫中剔除《黃帝內經》原文及和《黃帝內經》直接相關的古籍,將其命名為中醫古籍2.0 語料庫,并在這個語料庫上訓練并尋找最優模型,以《黃帝內經》的文本作為測試語料構建測試集進行測試。表1 為模型對圖2 中節選的10 條測試語料的輸出結果,如對第一條語料“征其脈不奪其

表1 模型預測示例
2.2.5 評價指標
模型的評價指標為“hit@k”,即在模型給出的前k 個預測中,正確預測占所有句子的百分比。如果模型輸出的正確預測排名越靠前,說明模型的性能越優秀。如表1 中共有10 條語料,模型的預測1 即為真實值,那么hit@1 即為100%。實際情況中,可能在第5 個甚至第10 個預測才會出現真實值,因此本文還會評估hit@5 和hit@10,表示模型前5 個和前10 個預測中出現真實值的輸出占測試語料總數的百分比。
3 結果與分析
表2 和表3 顯示了各模型在對應訓練集和測試集上的表現。對表2 和表3 的結果進行各模型間的橫向對比可以發現,RoBERTa 模型效果最優,BiLSTM 模型優于LSTM 模型,LSTM 模型明顯優于N-gram 模型;對表2 和表3 的結果進行各語料庫間的縱向對比可以發現,語料庫規模越大,模型的預測效果越優,說明當中醫古籍修復專家進行修復工作時,其研究的中醫古籍范圍越廣,程度越深,也就越能推測出中醫古籍中缺失的內容,古籍修復工作效果也就越好。

表2 各模型訓練集預測效果
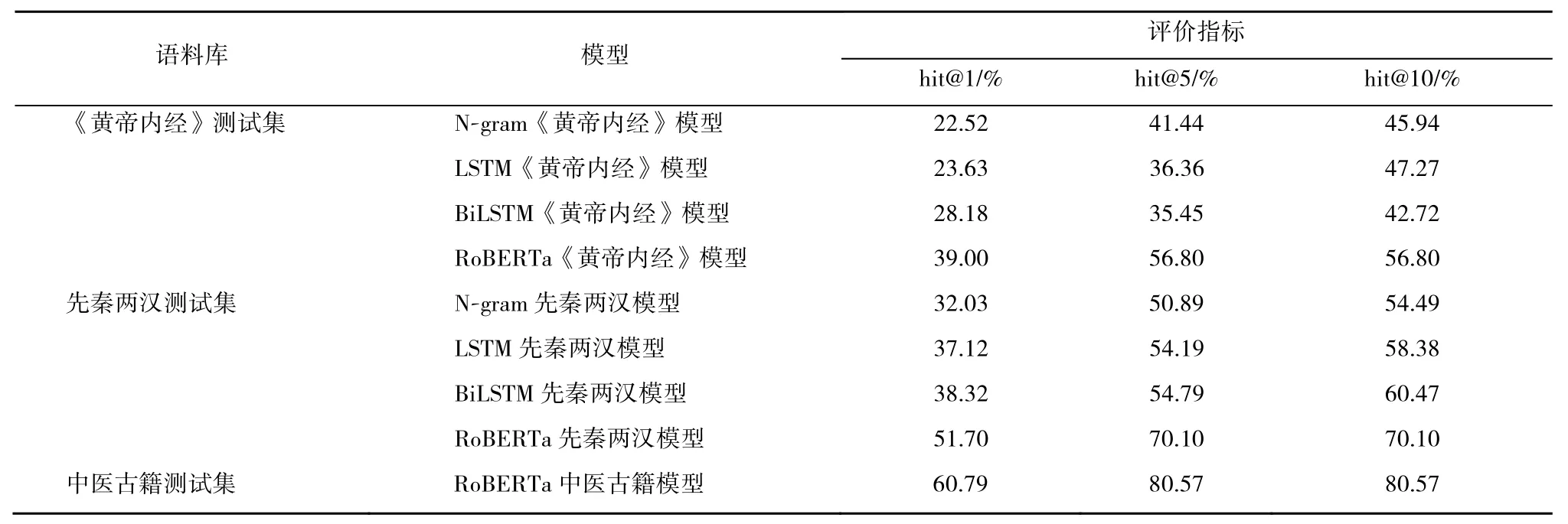
表3 各模型測試集預測效果
實驗結果證明,深度學習技術對中醫古籍的修復工作有很大的幫助,在表現效果最優的RoBERTa中醫古籍模型輸出的前10 條預測中,可以直接獲得正確的缺失內容的幾率為60.79%,出現正確預測的幾率為80.57%。
經過模型訓練和測試,篩選出了用于中醫古籍修復的最優模型,即RoBERTa 模型,在剔除《黃帝內經》原文及《黃帝內經》直接相關古籍的中醫古籍文本語料庫即中醫古籍2.0 語料庫上重新訓練RoBERTa 模型,將其命名為“RoBERTa 中醫古籍2.0 模型”,并在《黃帝內經》測試集上進行測試,最終達到了63.36%的hit@1,82.57%的hit@5 和hit@10,即隨機在《黃帝內經》中剔除一個字,模型有63.36%的概率在其第一個預測中就給出真實預測,有82.57%的概率在其給出中的前5 個或前10 個預測中出現真實預測。
實驗結果顯示,RoBERTa 中醫古籍2.0 模型的模擬修復效果與模型最終的測試效果相符合,說明了RoBERTa 中醫古籍2.0 模型的實用性。在沒有專業的中醫文本修復專家的幫助下直接去修復一本殘損的古籍,模型的預測是無法進行參照對比的,而《黃帝內經》的發行版本被廣泛接受認可,因此挑選了《黃帝內經》作為修復對象。
同時,在一些專家已經給出古籍中真實缺字預測的情況下,RoBERTa 中醫古籍2.0 模型也能給出和專家相近的預測。如1973 年長沙馬王堆出土的《五十二病方》中傷痙第六方為“冶黃芩、甘草相半,即以彘膏財足以煎之。煎之沸,即以布捉之,抒其汁,□傅□”,其中“□”代表缺字,模型對第一個“□”的預測為“以”“勿”“即”,第二個“□”的預測為“之”“訖”“頭”,而周一謀先生在《馬王堆醫書考注》中對第一個“□”也給出了“以”的預測[20],嚴健民先生在《五十二病方注補譯》中對第二個“□”同樣給出了“之”的預測[21];同樣于馬王堆出土的《足臂十一脈灸經》中臂少陽脈“出中指,循臂上骨下廉,湊耳。其病:產聾,□痛。諸病此物者,皆灸臂少陽之脈”,模型對此處“□”給出的預測為“脅”“耳”“頭”“頰”,周一謀先生在《馬王堆醫書考注》中認為此處的“□”應為“頰”。
實驗結果證明了本文構建的RoBERTa 中醫古籍2.0 模型對《黃帝內經》的適用性,同時也說明該模型具有推廣性,可以用于后續的新出土的殘損中醫古籍的修復,輔助中醫古籍修復專家進行中醫古籍修復工作。
4 結語
中醫古籍是中醫藥學術與文化的重要載體,大量傳世中醫古籍對回溯學術源流、傳承中醫學術、深入研究中醫藥學理論、提高臨床療效有著不可替代的重要價值[22]。因此,在中國特色社會主義新時代背景下,中醫藥學作為中國古代科學的瑰寶和打開中華文明寶庫的鑰匙,中醫古籍的修復工作具有非凡的歷史價值和文化價值。
本文收集了608 本中醫古籍文本,并按成書年代、古籍類別對古籍進行了分類,涵蓋了自秦漢時期以來的本草、方藥、婦幼、醫論、傷科、經絡、五官、針灸、經絡、醫案、醫經、四診各類中醫古籍,可形成高質量的中醫古籍文本語料庫;同時在中醫古籍文本語料庫的基礎上,訓練了各語言模型,篩選出了最優的RoBERTa 模型。將RoBERTa模型運用到中醫古籍文本修復場景中,RoBERTa模型的訓練結果顯示,評價指標hit@1 為63.36%,評價指標hit@5 和hit@10 均為82.57%,達到了訓練一個中醫古籍文本修復模型的預期目標,可為中醫古籍修復專家提供參考和支持,而且最終訓練出的中醫古籍2.0 預訓練模型不僅可以用于中醫古籍缺失內容的預測,也可以在微調之后用于中醫古籍文本的命名實體識別、關系抽取、文本分類等下游任務。
此外,本文也存在有待改進和完善的地方。如對中醫古籍文本的收錄還可以更加全面一些,同時模型的預測hit@1 的準確率也存在一定的提升空間。表2 顯示,將語料庫規模從《黃帝內經》語料庫擴大到先秦兩漢語料庫,各模型的預測準確率都得到了約10%的提升,RoBERTa 模型的準確率提升最為明顯,而語料庫規模從先秦兩漢語料庫擴大到中醫古籍文本語料庫,模型的預測準確率也得到了10%左右的提升,說明hit@1 準確率的提升和語料庫的質量是相關的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
