基于特征權(quán)重的詞向量文本表示模型
2022-03-17 11:42:48蔣延杰李云紅蘇雪平張蕾濤賈凱莉陳錦妮
西安工程大學學報 2022年1期
蔣延杰,李云紅,蘇雪平,張蕾濤,賈凱莉,陳錦妮
(1.北京市組織機構(gòu)代碼管理中心,北京 100010;2.西安工程大學 電子信息學院,陜西 西安 710048)
0 引 言
文本表示是處理自然語言任務的前提,并且文本表示的質(zhì)量與任務處理結(jié)果的好壞密切相關(guān)。文本表示可以對單詞、短語、句子和文檔等任何文本單元進行處理[1-3]。傳統(tǒng)文本表示方法有詞袋模型(bag of word,BOW)、N元語言模型(N-Gram model,N-Gram)和向量空間模型(vector space model, VSM)等。BOW通過One-hot編碼將文本表示為高維稀疏向量,但卻存在忽視詞序、詞義及上下文之間的關(guān)系,不能有效地捕捉文本的語義和語境,導致維數(shù)災難等問題[4-5]。N-Gram作為詞袋模型的擴展模型,解決了BOW無法捕捉語序和上下文信息,但無法解決詞袋模型的維度災難[6-7]。文獻[8-10]提出向量空間模型,通過計算詞頻-逆文檔頻率(term frequency-inverse document frequency, TF-IDF)對文本中的某個特征詞的特征選擇作用的大小進行評估,得到文本表示,但同樣存在表示不充分和維度災難。文獻[11-12]提出基于三層神經(jīng)網(wǎng)絡(luò)的文本表示模型,解決了上述模型忽略了詞與詞之間的語義關(guān)系。文獻[13-15]提出基于淺層神經(jīng)網(wǎng)絡(luò)詞嵌入模型(Word2vec),它包含了詞向量CBOW和Skip-Gram模型,解決了傳統(tǒng)文本表示中捕捉細粒度的語義、句法規(guī)則,但忽視了詞序和統(tǒng)計信息的不足。Deps模型[14]作為Word2Vec的擴展模型,將Skip-Gram泛化為包含任意上下文,使用解析樹中的相鄰詞來學習單詞表示,可以很好地獲取對中心詞最具辨別力的上下文,但會導致語境缺失。文獻[16-18]提出Glove模型,該模型利用文本語料庫中的詞與詞的共現(xiàn)信息學習文本特征表示,可以捕捉到上下文信息,卻沒有考慮統(tǒng)計信息的影響,同時忽略了詞序特征,影響了文本表示性能。
針對以上文本表示存在忽略語義、詞序特征和存在維數(shù)災難等問題,本文建立將TF-IDF、N-Gram、Glove相結(jié)合的無監(jiān)督文本表示模型,在不增加計算復雜度的情況下,更好地對復雜文本特征進行表征,提升了文本分類的性能。
1 基礎(chǔ)理論
1.1 TF-IDF模型
TF-IDF模型包括詞頻(term frequency, TF)和逆文檔頻率(inverse document frequency, IDF)2個部分,即
(1)
式中:TI表示詞頻逆文檔頻率;文檔特征詞分別用t、v表示;t和v同時出現(xiàn)的次數(shù)用mt,v表示;Σimi,v為v中所有詞出現(xiàn)的總次數(shù);D為文本總數(shù);|v:wt∈dv|+1為特征詞wt出現(xiàn)的文本數(shù)。
從式(1)可知,TF-IDF模型依據(jù)特征詞在某一類文檔中出現(xiàn)的次數(shù)較多,而在其他類別的文檔出現(xiàn)的次數(shù)較少,從而過濾掉對某類文檔不重要的詞,但該算法忽視了語義信息及易受特征詞位置的影響,除此之外,還會將某一類文檔中出現(xiàn)次數(shù)較少的生僻字作為關(guān)鍵詞。綜上可知,用一種方法表示文本時,無法準確表達文本信息,影響分類任務的性能。
1.2 N-Gram模型
N-Gram模型是文本表示常用的模型之一,其定義為給定前n-1個標記后的第n個標記的條件概率,即
(2)
式中:S為1條有n個詞的語句,由d1,d2,…,dn組成;di為句子中的某一個詞;P(S)為S中n個詞出現(xiàn)的概率連乘,則
(3)
(4)
該計算方式雖然簡單,但會受詞與詞之間的相互影響。因此,提出n-1階馬爾可夫假設(shè),假設(shè)句子中的任意一個單詞dn的出現(xiàn)與前n-1個詞有關(guān),即
(5)
滿足式(5)的為N-Gram模型。n取值合理,若n太大,則參數(shù)過多的情況無法解決。
1.3 Glove模型
Glove模型通過詞共現(xiàn)概率比進行詞向量學習,即
(6)
(7)

(8)

(9)
經(jīng)過計算得
(10)
結(jié)合式(9),得
(11)
令式(11)中的F=exp(),得
(12)
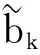
(13)
當式(13)中參數(shù)為零時,導致函數(shù)的發(fā)散情況,
令
ln(Xik)→ln(1+Xik)
它保持了X的稀疏性,同時避免了發(fā)散。除此之外,為了回避該模型存在對所有共現(xiàn)情況的權(quán)重相等,引入加權(quán)最小二乘回歸并在代價函數(shù)中引入加權(quán)函數(shù)f(Xij)。該模型的損失函數(shù),即
(14)
式中:V為詞匯量大小。其中f(x)為
(15)
式中:xmax取值為100;α值為3/4。
2 融合特征權(quán)重的詞向量文本表示模型
特征融合是以多種不同的角度從樣本中抽取特征,并將這些特征通過某些計算手段進行融合,得到一種新形式的特征文件。本文利用矩陣相乘與矩陣相加的計算方式,將不同特征進行融合,建立一種基于特征權(quán)重的詞向量文本表示模型。該模型的具體流程為Glove模型與TF-IDF模型進行矩陣相乘,得到TG文本表示模型,Glove模型與N-Gram模型矩陣相乘,得到NG文本表示模型,最后將TG與NG進行矩陣相加,得到最終融合的TN-Glove模型。其中,TG模型為給Glove詞向量增加TF-IDF特征權(quán)重,而NG模型為給Glove詞向量乘以N-Gram特征概率。文本表示模型通過給Glove詞向量增加特征權(quán)重,獲得新的文本表示。其中詞向量并不是模型任務的最終結(jié)果,而是在訓練過程中的附帶產(chǎn)物——權(quán)重矩陣。詞向量的維數(shù)是人為設(shè)定的固定值,百位級別的整數(shù)。Glove取值為300,即用300維的向量表示文本中的每個詞。用ti表示文本中的一個詞,則該詞的詞向量形式即
ti=(w1|ti,…,wn|ti)T
(16)
式中:n為詞向量的維數(shù),選取n=300;w1|ti為詞ti的第一維詞向量的值,依次類推,wn|ti為第n維詞向量的值。式(16)為文本中詞的表示方法,如果需要對語料庫中的所有詞進行表示,則需要將每個詞表示成向量,然后堆疊成矩陣形式。通常詞向量是針對文檔中不重復的特征詞,則詞向量W表示為
W=[t1,t2…,tn]
(17)
式中:W代表Glove詞向量矩陣,每個ti為n維的列向量,可記為W=(wij)n×n。
TG文本表示模型是在Glove詞向量的基礎(chǔ)上,結(jié)合特征選擇方法TF-IDF。具體計算方式即
TG=TIW
(18)
式中:TG表示Glove與TF-IDF融合后的詞向量矩陣;TI為通過TF-IDF模型計算的權(quán)重矩陣,記為TI=(TIij)m×n。TI和W的維度一樣。因此,只需要用特征權(quán)重矩陣乘以詞向量矩陣,則某一個語料庫的文本TG(簡記為TG)詞向量形式即
TG=(tgij)m×n
(19)
NG文本表示模型是將N-Gram與Glove相結(jié)合,具體計算方式即
NG=PW
(20)
式中:NG表示N-Gram與Glove分后的詞向量矩陣;P為通過N-Gram算法計算的概率矩陣,記為P=(pij)m×n。則某一個語料庫的文本NG(簡記為NG)詞向量形式即
NG=(ngij)m×n
(21)
最后將TG與NG相加融合,得到TN-Glove文本表示模型,即
TN=TG+NG
(22)
TN-Glove模型流程如圖1所示。

圖 1 TN-Glove模型流程圖Fig.1 Flow of TN-Glove model
從圖1可以看出:TN-Glove文本表示模型首先需通過訓練獲得Glove詞向量;然后,計算待分類文本的TF-IDF權(quán)重,并與對應的詞向量進行相乘,得到文本的TG表示;同時,通過給Glove詞向量乘以N-Gram概率得到NG文本表示模型;并將TG與NG進行相加融合,最后將TN-Glove文本表示模型表示輸入到SVM分類器實現(xiàn)文本分類。
Glove模型首先能很好地表達語料庫中的上下文信息;其次,該模型訓練的并不是共現(xiàn)矩陣的所有元素,而是其中的非零元素,提高了訓練速度,并且該模型能有效表達文本的語義和句法信息。將Glove模型與TF-IDF和N-Gram相融合,使TN-Glove文本表示模型擁有每種文本表示模型的優(yōu)點,融合特征權(quán)重的詞向量文本表示模型不僅考慮了語義和語序信息,而且通過詞頻信息保留文本中類別區(qū)分能力較強的特征詞,改善了文本分類效果。
3 仿真與分析
3.1 實驗數(shù)據(jù)
通過單標簽文本數(shù)據(jù)集20NewsGroup和5AbstractsGroup對改進的文本表示模型進行驗證。20NewsGroup數(shù)據(jù)集有多個不同的版本,是文本任務中經(jīng)常使用的標準數(shù)據(jù)集,有20個類別的新聞文檔,包含rec.autos、sci.space、misc.forsale等;5AbstractsGroup數(shù)據(jù)集為商業(yè)、人工智能、社會學、運輸和法律等5個不同領(lǐng)域收集的學術(shù)論文。

表 1 單標簽文本數(shù)據(jù)集信息統(tǒng)計
3.2 實驗設(shè)置
1) 參數(shù)設(shè)置。實驗在Linux系統(tǒng)中使用python語言實現(xiàn),在Tensorflow框架下完成對文本表示模型性能的測試。參照Glove文本表示模型進行參數(shù)設(shè)置,并通過實驗反復驗證,最終設(shè)置本文模型主要參數(shù)的取值,實驗參數(shù)設(shè)置見表2。

表 2 實驗參數(shù)設(shè)置
2) 評價指標。采用文本分類中常用的準確率P、召回率R、F1值對文本分類結(jié)果進行評價,其中TP、FP、TN和FN分別代表正陽性、假陽性、正陰性和假陰性的分類數(shù)量。各評價指標的計算為
(23)
針對不同維度的詞向量,分別對20NewsGroup和5AbstractsGroup 2個數(shù)據(jù)集進行實驗,并與文本表示模型TF-IDF、N-Gram、Glove進行對比,用SVM分類器驗證改進的模型性能。
3.3 模型性能驗證
實驗1使用數(shù)據(jù)集20NewsGroup對提出的改進文本表示模型進行驗證。20NewsGroup數(shù)據(jù)集不同維度分類結(jié)果對比見表3。

表 3 20NewsGroup數(shù)據(jù)集不同維度分類結(jié)果對比
從表3可以看出:針對20NewsGroup數(shù)據(jù)集提出的文本表示模型中,TN-Glove模型的分類效果最好,獲取文本隱藏信息的能力最強,TG模型次之,NG模型最差。分類效果會隨著詞向量的變化而變化,當利用TG模型對20NewsGroup數(shù)據(jù)集進行分類且詞向量維度為300時,分類準確率和F1值較高;用NG模型進行分類,當詞向量維度為300時,F(xiàn)1值略低于200維,其他指標都最高;用TN-Glove模型進行分類,當詞向量維度為300時,評價指標都相對較高,因此詞向量的維度取300。通過上述分析可得,TG、NG、TN-Glove模型可以有效地對文本信息進行表示,改善文本分類效果。
分別從TG、NG、TN-Glove 3種方案中選取300維詞向量的結(jié)果用于對比,20NewsGroup數(shù)據(jù)集不同模型對比見表4。

表 4 20NewsGroup數(shù)據(jù)集不同模型對比
表4為TF-IDF、N-Gram和Glove 3種文本表示方法與論文的TG、NG、TN-Glove模型的對比結(jié)果。通過對比,本文提出的TG、NG、TN-Glove 3種文本表示模型,對20NewsGroup數(shù)據(jù)集的分類結(jié)果均優(yōu)于常用的文本表示方法。因此,本文提出的TG、NG、TN-Glove模型可獲取文本中的隱藏信息,更好地表征文本特征信息,提高文本的分類結(jié)果。
實驗2使用數(shù)據(jù)集5AbstractsGroup驗證改進的文本表示模型。5AbstractsGroup數(shù)據(jù)集不同維度分類結(jié)果對比見表5。

表 5 5AbstractsGroup數(shù)據(jù)集不同維度分類結(jié)果對比
從表5可以看出,針對5AbstractsGroup數(shù)據(jù)集,本文提出的TG、NG和TN-Glove 3種模型中,TN-Glove模型分類效果最好。詞向量維度不同,分類效果也有稍許差距。當詞向量維度為300時,用NG和TN-Glove模型進行分類,評價指標都相對較高。而用TG模型分類,當詞向量維度為300時,指標召回率略低于500維,其他指標都為最高。通過數(shù)據(jù)分析發(fā)現(xiàn),本文提出的文本表示模型可以更好地學習文本特征信息,改善文本分類效果。
和實驗1采取一樣的對比方法,選取TG、NG、TN-Glove模型中性能較好的300維詞向量的實驗結(jié)果作為對比,5AbstractsGroup數(shù)據(jù)集不同模型對比見表6。

表 6 5AbstractsGroup數(shù)據(jù)集不同模型對比
從表6可以看出,對比TF-IDF、N-Gram和Glove 3種模型,本文提出的TN-Glove模型分類效果均優(yōu)于對比實驗。雖然TG、NG模型的準確率低于Glove模型,但召回率和F1值相對有所提高。可見本文表示模型對文本信息準確表征,改善了分類效果。
綜上可述,本文提出的TN-Glove文本表示模型,結(jié)合各種文本表示方法,對文本中隱藏特征進行了有效提取。
4 結(jié) 論
1) TN-Glove表示模型通過結(jié)合TF-IDF和N-Gram 2種文本表示的優(yōu)點,不僅能更好地捕捉詞與詞之間的關(guān)聯(lián)信息,獲取文本的語義和語序信息,還能通過詞共現(xiàn)矩陣掌握文本的全局信息,對類別區(qū)分能力較強的詞進行保留。
2) TN-Glove文本表示方法可對文本特征信息有效表達,但本文模型只是從詞一個方面獲取文本特征。在以后的研究中,在保證訓練速度的前提下,可從字符和詞2個角度對文本特征信息進行獲取,對RNN模型的文本表示性能進行研究。
