
基于CEEMD和LSTM-ARIMA的短期風速預測
2022-03-19 09:57:36李秉晨于惠鈞丁華軒劉靖宇
中國測試 2022年2期
李秉晨, 于惠鈞, 丁華軒, 劉靖宇
(湖南工業大學軌道交通學院,湖南 株洲 412007)
0 引 言
風能作為理想的可再生能源之一,在世界各國的應用都越來越廣泛,但風速本身具有隨機性和間歇性的特點,會使風電出現頻繁的波動,在進行大規模風電并網時,會對電網的正常運行和電能質量帶來威脅[1]。因此,準確預測風速有利于風電并網的調度,對電力系統的穩定運行有重要作用[2]。
目前,風速預測受到很多國內外研究人員的關注,采用多種模型對風速進行預測。風速預測常用的方法包括卡爾曼濾波法、自回歸差分平均回歸、人工神經網絡、支持向量機、經驗模態分解(empirical mode decomposition,EMD)等[3]。單一模型在預測風速時,往往存在精度不高的問題,越來越多的研究人員開始研究組合模型[4]。文獻[5]針對風速序列具有很強的波動性,提出基于VMD和ARIMA的超短期風速預測模型,利用改進經驗模態分解算法將風速序列從高到低逐次分解,然后對各分量分別建立ARIMA模型進行預測,結果表明模態分解法在風速預測有較大優勢。文獻[6]利用局域均值分解法將風速序列分解為若干分量,再對各分量分別采用ARMA算法進行建模預測,提出LMD和ARMA組合風速預測方法,提高了風速的預測精度。文獻[7]提出基于VMD和LSTM的超短期風速預測,用VMD將風速序列分解為多個子模態,對子模態進行預測并疊加得到預測結果。文獻[8]提出基于CEEMD和改進時間序列模型的超短期風功率多步預測模型,CEEMD算法在經驗模態分解算法上進行改進,能更好地將非線性時間序列分解為代表不同時間尺度上的局部特征的模態分量,能提高風速預測精度。
以上模型都考慮了將風速序列分解為不同頻率的高低頻模態分量,然后分別對高頻和低頻分量建立預測模型進行風速預測,但是沒有考慮算法對不同頻率子模態的適用性,只是采用同一種算法對高頻和低頻模態分量進行預測。本文在現有研究的基礎上,提出基于CEEMD和LSTM-ARIMA的短期風速組合預測模型,ARIMA模型對于低頻的平穩時間序列預測結果精確,而LSTM神經網絡能對高頻的非平穩時間序列取得較好的預測精度,采用CEEMD算法將LSTM與ARIMA模型結合起來,用LSTM網絡和ARIMA算法對經CEEMD算法分解的高頻和低頻的模態分量分別進行預測,以期提高風速預測精度。
1 算法原理
1.1 CEEMD原理
經驗模態分解算法(EMD)是一種常用于非平穩時間序列信號的數據處理方法,可將非平穩信號分解為一系列不同時間尺度的本征模態函數(IMF)分量,不過該方法存在模態混淆的現象。完備總體經驗模態分解(CEEMD)算法在EMD算法的基礎上進行改進,添加一組大小相等、符號相反的輔助白噪聲,然后再分別進行EMD分解,既抑制了EMD算法的模態混淆效應這一缺陷,又不會使得原始信號因白噪聲的添加而產生較大的影響。CEEMD主要步驟如下[9]:
1)在原始的序列x(t)中,添加一組符號相反的高斯白噪聲εi(t)序列,得到一組新的時間序列:
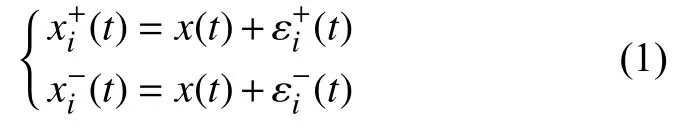
2)對式(1)中的每一個時間序列進行EMD分解,都會得到m個本征模態分量:

其中cij為第i次加入白噪聲后,經過EMD分解得到的第j個模態分量。
3)添加不同的高斯白噪聲,重復步驟1)、2)分別n次,得到n組本征模態分量(IMF)的集合,其中最后一組為趨勢項(Res)。
4)計算所有分量的集合平均值,得到最終的模態分量組ci(t)。
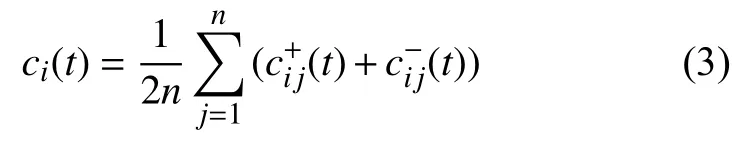
1.2 PE算法
排列熵(PE)算法是一種基于信息論的度量方法,通過相鄰值的比較來分析時間序列數據的復雜性。PE算法的計算方法如下:
首先,假設一個時間序列X(t)(t=1,2,···,T),對其進行相空間重構:
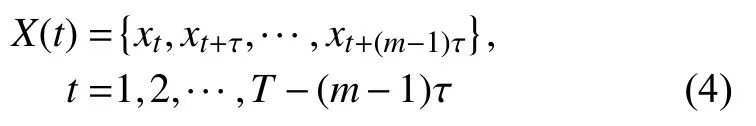
式中:m—— 嵌入維數;
τ 時間延遲。
然后,將X(t)中的元素按遞增順序重新排列:
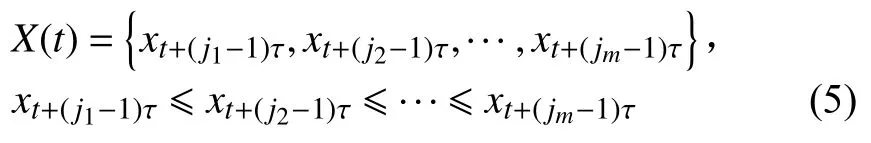
其中jm為排序后各元素的序號。
每種可能的排列表示為w={j1,j2,···,jm},m維序列可以存在m!種排列方式。每種排列的概率為p1,p2,···,pg。根據 Shannon 熵定義,排列熵歸一化可定義為:
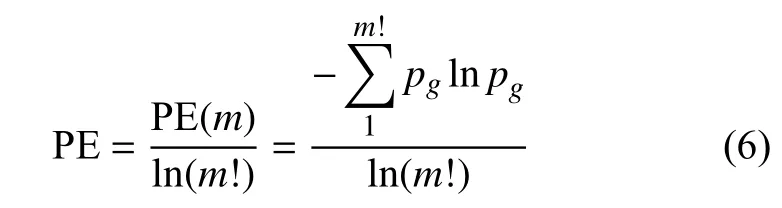
1.3 LSTM算法
長短期記憶網絡(LSTM)是在循環神經網絡(RNN)的基礎上進行改進的算法,LSTM模型能有效地自動從時間序列數據中學習特征,并且能夠學習長期依賴信息,避免了RNN訓練過程中存在的梯度爆炸和梯度消失的問題[10]。與RNN不同的是,LSTM模型通過獨特的門結構來增加一個細胞狀態,用來保存以前的數據狀態信息。LSTM模型結構如圖1所示,單元內部結構由輸入門、遺忘門和輸出門等組成,此外,tanh激活函數控制要更新輸入,Ct–1和Ct分別為t–1 和t時刻的細胞狀態,ht–1和ht分別為t–1和t時刻細胞的隱藏狀態。
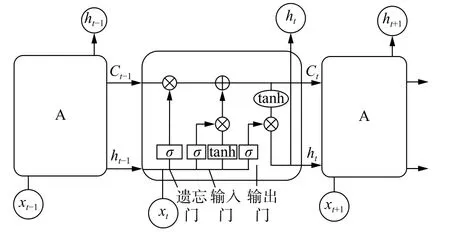
圖1 LSTM模型結構圖
LSTM模型的遺忘門用來確定t–1時刻的隱藏狀態ht–1和t時刻的輸入xt的信息保留程度。遺忘門的公式為:
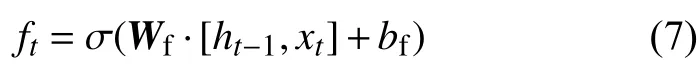
式中:W——f— 遺忘門的權重矩陣;
bf—遺忘門的偏置項;
σ 激活函數sigmoid。
LSTM模型的輸入門用來確定輸入變量xt中有多少信息可以保存到細胞狀態Ct中。輸入門的公式為:
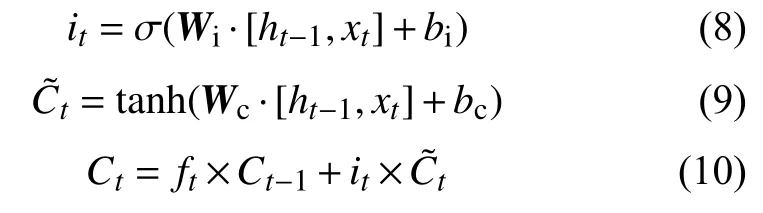
式中:Wi和Wc— 輸入門的權重矩陣;
在兩組實驗對象入組后,于次日在空腹狀態下抽取其外周靜脈血(3毫升)和動脈血(2毫升),采取ELISA法(酶聯吸附法)測定其IL—6、TNF—α水平,采取散射免疫比濁法測定其Hs—CRP水平,采取免疫發光法測定其BNP水平。本次實驗所用IL—6、TNF—α試劑盒為北京伯樂生命科學發展有限公司生產,IMMAGE全自動特定蛋白分析儀和AU5800全自動生化分析儀為貝克曼庫爾特公司生產。
bi和bc——輸入的偏置項;
σ和tanh 激活函數。
LSTM模型的輸出門用來輸出單元的隱藏狀態。輸出門的公式為:
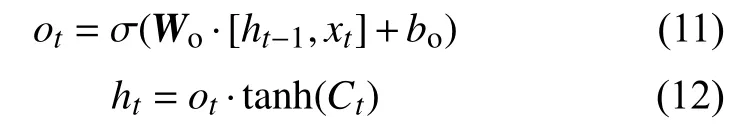
式中:ot—— —輸出門的輸出;
W——o輸出門的權重矩陣;
bo輸出門的偏置項。
1.4 ARIMA模型
自回歸差分移動平均(ARIMA)是一種分析預測變量的未來值和歷史值的線性函數關系的方法,ARIMA應用的時間序列應該是線性且平穩的。ARIMA(p,d,q)模型先對時間序列進行平穩性檢驗,如果不滿足平穩性的要求,對時間序列進行d階差分,然后再對序列進行自回歸移動平均(ARMA(p,q))建模[11]。ARMA方程為:
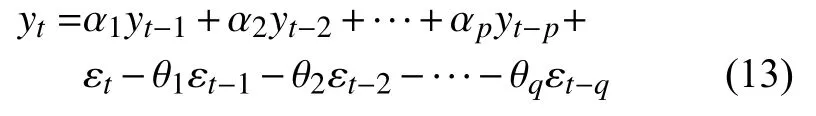
式中:yt——實際時間序列;
εt———t時刻的隨機誤差;
αp——自回歸(AR)模型的系數;
θq移動平均(MA)模型的系數。
p和q都是模型的階數,當q=0時,模型就簡化為p階AR模型AR(p)、當p=0時,模型就簡化為q階MA模型MA(q)。
2 基于CEEMD和LSTM-ARIMA組合預測模型
風速數據具有很強的非線性和非平穩性,采用CEEMD算法將功率序列分解為幾個不同頻率的子序列,采用PE對子序列進行計算,按照時間序列復雜度來選出高頻子序列部分和低頻子序列部分[12]。經CEEMD分解后的高頻子序列部分使用LSTM進行預測,LSTM神經網絡能對復雜度較高的時間序列進行有效預測;對于低頻子序列部分使用ARIMA進行預測,ARIMA對于平穩的時間序列有良好的預測效果。將兩種模型得出的預測結果進行疊加,最終得到風速的預測值。提出的基于CEEMD和LSTM-ARIMA短期風速預測模型建模步驟為:
1)利用CEEMD將原始風速序列分解為n個模態分量。
2)使用PE算法分別計算n個序列分量的排列熵,按照時間序列的復雜程度將模態分量分為高頻部分和低頻部分。
3)高頻序列部分采用LSTM進行預測,低頻序列部分采用ARIMA進行預測。
4)將高頻序列預測結果和低頻序列預測結果相加,得到風速的預測值。風速預測框圖如圖2所示。
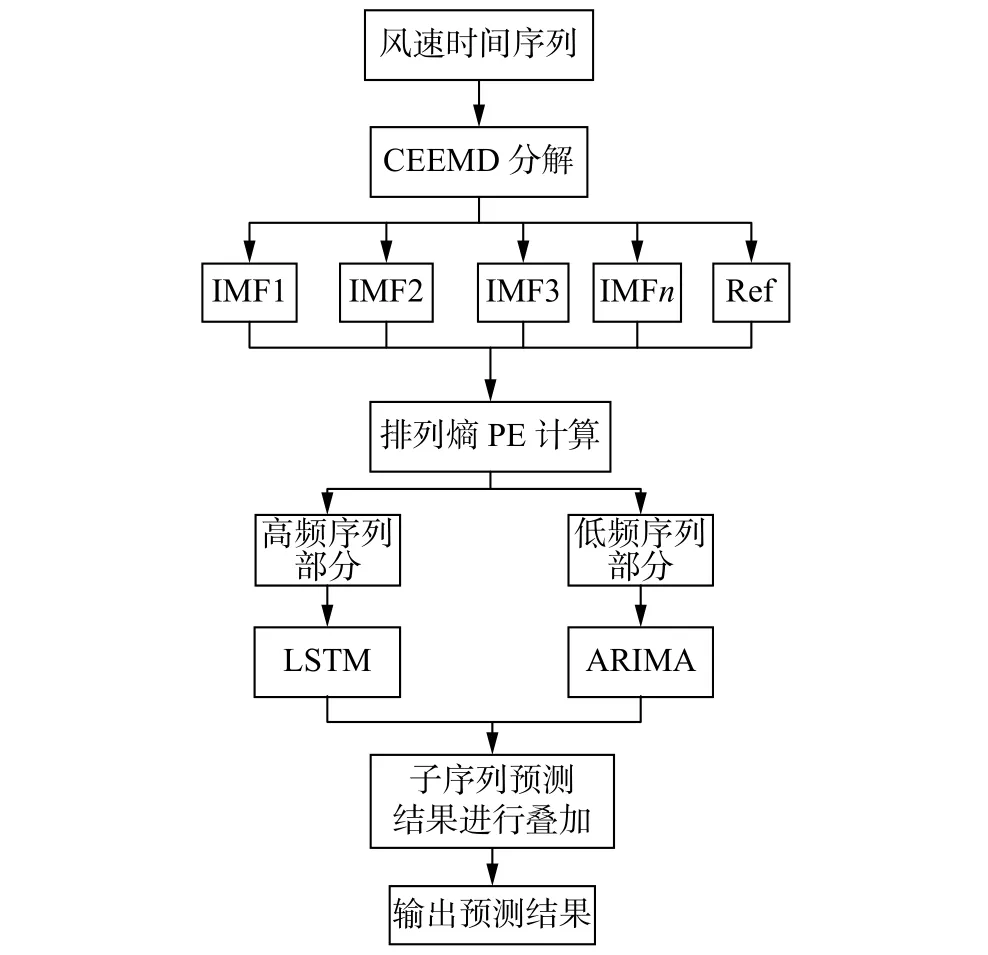
圖2 風速預測框圖
采用平均絕對百分比誤差(MAPE)和均方根誤差(RMSE)等性能指標來比較模型之間的預測性能水平。公式如下:
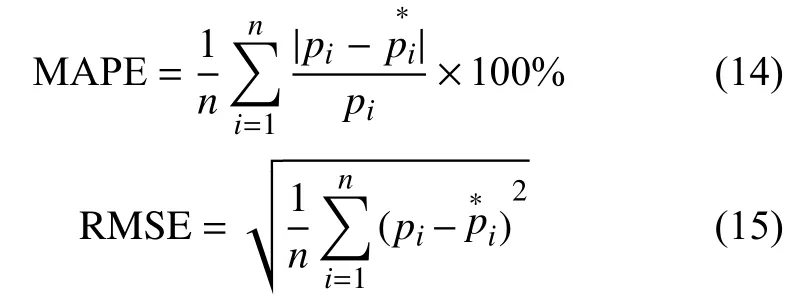
其中pi和分別為第i位的觀測值和預測值。
3 算例分析
本文選用2016年湖南省某風電廠實際采集數據,樣本的采樣周期為5 min,選取4月10日~4月19日共2 880個點作為樣本數據。原始風速數據如圖3所示,其中前2 592個點(4月10日~4月18日)的數據作為訓練樣本(按8∶1劃分訓練集和驗證集),后288個點(4月19日)的數據作為測試樣本。
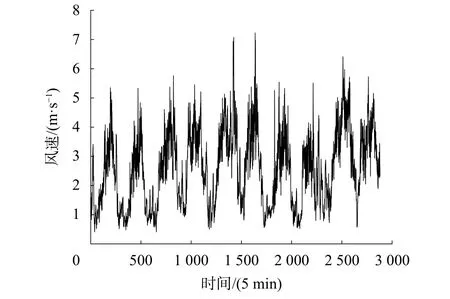
圖3 原始風速數據
從圖3可以看出風速數據具有明顯的非線性和非平穩性,預測難度較大。對原始時間序列進行CEEMD分解,將風速分解為幾個更容易預測的時間子序列,得到頻率由高到低的11組模態函數。CEEMD分解結果如圖4所示,可以看出IMF1至Res子序列的波動逐漸平緩,頻率越來越低。
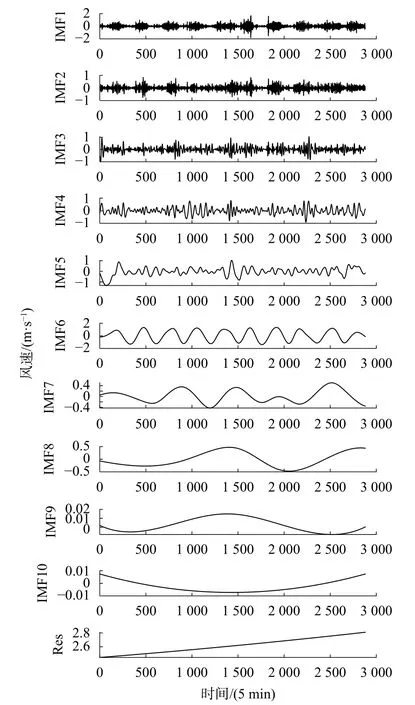
圖4 CEEMD風速分解結果
為量化分解后各子序列的頻率高低,采用PE算法計算各子序列的排列熵的值,具體結果如圖5所示。排列熵值從IMF1開始依次遞減,一直減到Res的排列熵值為0。對于ARIMA 模型來說,排列熵值越小,時間復雜度越低,模型的預測精度就越高。IMF5~IMF10及Res的子序列排列熵值均小于0.2,視為低頻序列,帶入ARIMA模型進行預測;IMF1~IMF4的排列熵值均大于0.2,將其視為高頻序列,帶入LSTM網絡模型進行預測。
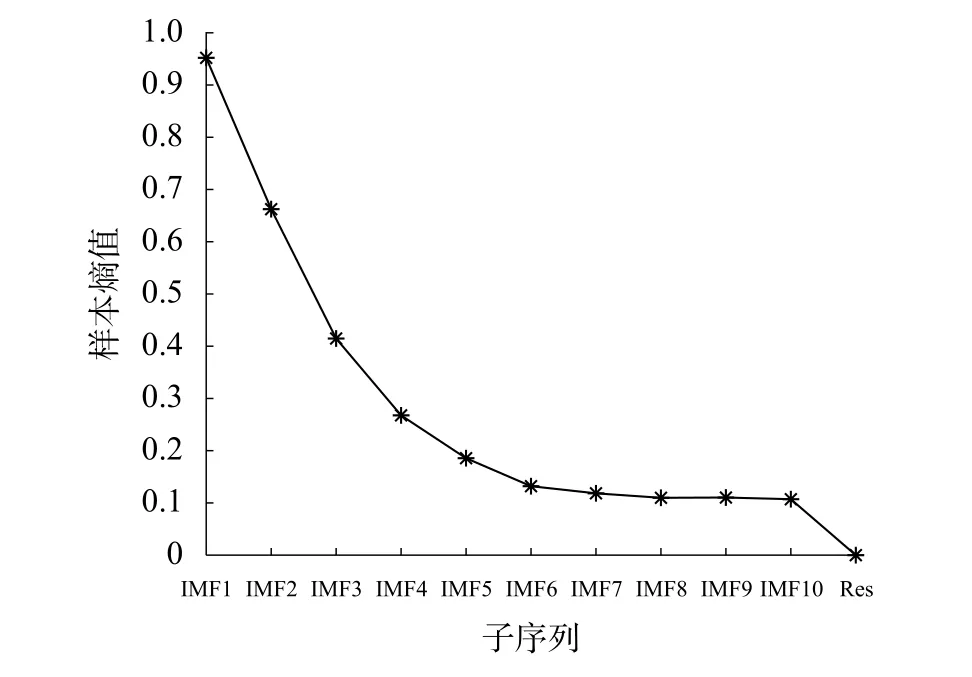
圖5 子序列的排列熵結果
將CEEMD分解后的各子序列分量帶入對應的算法進行預測,并將得到的預測值進行疊加,得到最終的風速預測數據。預測高頻部分建立的LSTM模型參數為:單元數130,激活函數為relu,迭代次數150,余弦學習率下降。預測低頻部分的ARIMA模型建立結果如表1所示。

表1 IMA模型階數
為驗證本模型對風速預測的有效性,與另外4種預測模型進行實驗仿真對比。對比的預測模型分別為:LSTM神經網絡預測模型、ARIMA預測模型和CEEMD-ARIMA預測模型。預測結果如圖6所示,各模型預測誤差比較如表2所示。
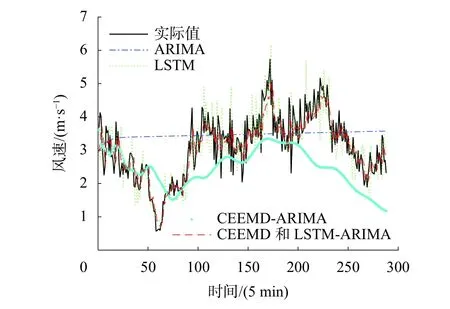
圖6 CEEMD-LSTM-ARIMA預測結果以及其他模型對比
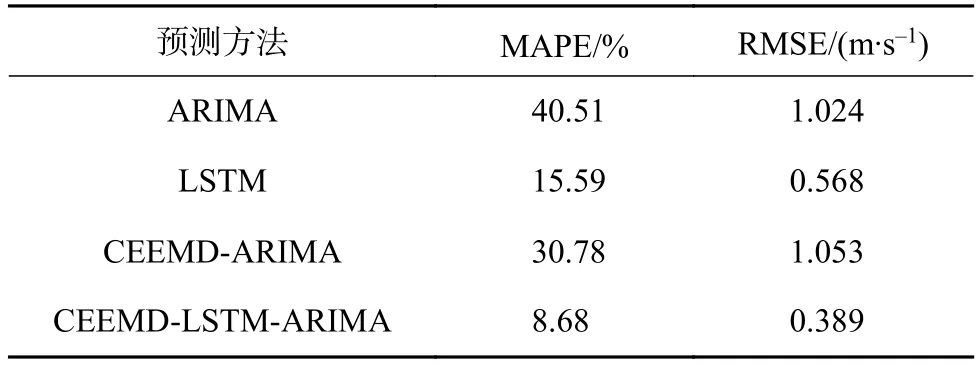
表2 各模型預測誤差比較
由圖6和表2可知,基于CEEMD和LSTMARIMA組合預測模型預測值與實際值最接近,MAPE為8.68%,比其他模型預測結果更精準。ARIMA模型預測近似一條直線,平均絕對誤差達到40%,預測效果在所有模型中最差,說明單一的ARIMA模型無法對于風速這種波動大的非平穩數據進行有效的預測。CEEMD-ARIMA模型比ARIMA模型預測的平均絕對誤差降低了10%,預測精度有所提高,說明CEEMD能有效對非平穩序列進行分解,提高了非平穩序列預測的精度。單一的LSTM模型預測精度較高,說明LSTM模型能對非平穩序列進行有效的預測,而基于CEEMD和LSTM-ARIMA組合模型比LSTM模型的預測誤差更小,說明了組合預測模型的建模思路是正確的,消除各個時間尺度特征之間產生的相互影響,對各個模態分別進行有效的預測,進而提升整體的預測精度。根據結論可知,本文提出的基于CEEMD和LSTM-ARIMA組合預測模型可有效提高風速的預測準確度。
4 結束語
本文采用CEEMD算法將風速序列分解為不同頻率的模態分量,達到降低了預測難度的目的。并分別采用LSTM和ARIMA模型對高頻分量和低頻分量進行預測,可實現對不同頻率的模態分量進行有效預測,提高了整體預測精度。通過與其他模型進行對比,本文所提基于CEEMD和LSTM-ARIMA方法具有更高的預測精度,表明提出的組合預測模型是一種行之有效的方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
電機與控制應用(2021年12期)2021-02-28 07:55:52
海洋通報(2020年5期)2021-01-14 09:26:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
西南交通大學學報(2016年4期)2016-06-15 20:29:37
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
電網與清潔能源(2015年3期)2015-02-28 16:03:31
上海電機學院學報(2015年4期)2015-02-28 14:30:00
