基于域名系統知識圖譜的CDN域名識別技術
2022-03-22 03:36:06閆志豪劉京菊郭兵陽
計算機工程與應用 2022年6期
閆志豪,劉京菊,郭 徽,郭兵陽
1.國防科技大學 電子對抗學院,合肥 230037
2.網絡空間安全態勢感知與評估安徽省重點實驗室,合肥 230037
網絡技術的飛速發展和用戶體量的急劇增長在給互聯網內容提供商(Internet content provider,ICP)帶來機遇的同時也帶來了巨大的挑戰。CDN技術的出現,極大地改善了由廣分布、大體量用戶訪問所帶來的網絡擁堵、服務器過載和高延遲等問題。目前全球CDN服務商在世界各地部署的數萬臺服務器在提供服務的同時也構成了互聯網基礎設施的關鍵部分。CDN的大范圍應用也給網絡空間帶來了新的安全挑戰,2019年Nguyen等人[1]發現了一種針對CDN的新型緩存系統中毒攻擊,2020年Li等人[2]提出了一種針對CDN的HTTP范圍請求放大攻擊。CDN域名識別作為檢測、防御針對CDN攻擊的第一步,同時也是網絡空間測繪的重要一步,對于了解CDN的體系結構、業務性能和技術演變至關重要。
目前國內外學者針對CDN域名識別提出的方法主要有:Huang[3]和Adhikari[4]等人使用規范名稱記錄(canonical name record,CNAME)的特征對采用指定服務商的CDN域名進行識別。Guo等人[5]使用服務器返回的HTTP錯誤消息來發現CDN節點。B?ttger等人[6]通過猜測CDN邊緣服務器的命名規則來構造主機名,并執行DNS探測以獲得更多的節點IP。這些方法雖然簡單有效,可以獲取一個或幾個特定CDN服務商的數據來衡量CDN的規模和性能,但它們的識別范圍非常有限,只能識別部分特定的CDN域名。
Chen等人[7]針對CDN域名和Fast-Flux(FF)域名區分困難的問題,基于長短期記憶網絡(long short-term memory,LSTM)網絡,根據域名特征、經驗信息、地理和時間相關特征對FF域名和CDN域名進行了區分。Li等人[8]根據域名系統記錄相關特征基于機器學習識別CDN域名,但需要多地域多節點對目標進行數據獲取,并手工識別大量CDN域名構建樣本集。
因此,如何以較低的代價對大規模的CDN域名進行識別仍是一個亟待解決的問題。由于CDN技術依托于域名系統實現,通過對域名系統的相關記錄和數據進行分析,能夠獲取CDN域名特征進而進行有效識別。域名系統作為互聯網重要基礎設施之一,數據和記錄類型多樣,網絡結構之間存在復雜的依賴關系,而知識圖譜(knowledge graph,KG)作為一種用圖模型來描述知識和建模世界萬物之間的關聯關系的技術方法,擅長對多源異構數據和復雜關系進行表征和利用。
因此,本文針對CDN域名識別的問題,引入知識圖譜構建、知識推理等關鍵技術,提出構建域名系統知識圖譜方案。旨在將涉及域名系統的多源異構數據通過知識圖譜進行統一利用和分析,進而在域名數據中尋找CDN服務特征并進行大規模CDN域名識別。
1 CDN特征分析
1.1 CDN系統概述
域名系統作為廣泛應用于互聯網的分布式名稱解析系統,提供了域名和IP地址之間的轉換服務。CDN技術基于域名系統,在其上采用分布式方式構建用于承載業務的服務器集群。通過中央平臺的負載均衡、內容分發調度等功能模塊,用戶可以就近獲取所需內容,降低內容擁塞,提高用戶訪問的響應速度和命中率[9]。
啟用CDN服務的域名解析結構如圖1所示。用戶請求訪問域名時,域名權威DNS會根據配置好的CNAME記錄,使其跳轉至CDN系統,轉而請求其CNAME記錄的IP地址。然后CDN系統會根據用戶位置,采用全局負載均衡技術返回距離用戶較近的緩存內容服務器的IP地址。
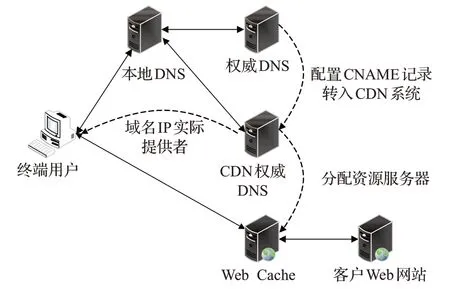
圖1 CDN服務結構Fig.1 CDN service architecture
因此CDN服務商通常維護著內容和DNS兩種類型不同的服務器。內容服務器復制了原始Web服務器上的內容,對客戶的請求進行響應。DNS服務器向客戶返回距離最近的內容服務器。
1.2 CNAME模式特征分析
CNAME是域名系統的一種記錄,用于將一個域名映射到另外一個域名,域名解析服務器遇到CNAME記錄時會以映射到的目標重新開始查詢[10]。
根據CDN域名使用CNAME記錄轉入CDN系統的特征,本文通過對Alexa前100萬域名及其“www.”子域名的CNAME記錄進行查詢獲取,根據實際數據統計分析其模式特征和對應用途,在其中尋找CDN服務特征。
1.2.1 子域名及其CNAME的主域分析
(1)子域名和其CNAME同屬一個主域
在共計93.3萬子域名中共有35.7萬域名擁有CNAME記錄,其中有26.1萬條記錄的子域名和CNAME同屬一個主域,且有24.9萬條將CNAME記錄設置為子域名的主域名。
該類型CNAME的設置主要是為了便于在同一個IP地址上運行多種服務的情況,例如,如果需要同時運行文件傳輸服務和Web服務,則可以使用CNAME記錄把ftp.example.com和www.example.com都指向example.com。后者擁有指向IP地址的A記錄,當需要更改時,直接更改example.com的A記錄便可修改整個服務對應IP地址的映射。
(2)子域名和其CNAME屬不同主域
在9萬多條子域名和其CNAME屬不同主域的記錄中,大于20個子域名的CNAME指向同一域名的記錄超過2.5萬條。表1中列出了被指向次數最多的10個域名。

表1 CNAME被指向次數最多的10個域名Table 1 Top 10 domains with CNAME record
此類型的CNAME記錄,主要目的是實現某種特定的功能。例如在使用Google企業套件和Google AppEngine時,如果要綁定自己申請的獨立域名,就需要將域名CNAME解析到ghs.google.com,因此出現6 795次的CNAME記錄指向域名ghs.google.com。
1.2.2 CNAME字符表現特征
針對子域名和其CNAME是否同屬一個域的情況,分別對子域名和CNAME域名中的字母、數字、點字符和連字符進行統計,其結果如表2所示。
為了更直觀地展現它們的區別,圖2中將平均數字個數和平均連字符個數放大了10倍。可以明顯得出同屬一個主域的情況下子域名和其CNAME的各類字符串統計特征無過大差別。但屬于不同主域時CNAME的各項字符統計特征均高于其他幾項。
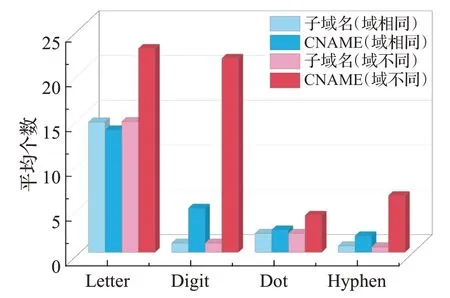
圖2子域名和CNAME字符統計特征Fig.2 Subdomain and CNAME character statistics feature
同屬一個域的情況下,有超過95%的CNAME記錄設置為域的主域名,因此子域名和CNAME的字符統計特征無異常。但在屬不同主域的情況下,CDN服務商維護著大量的服務器,域名采用CDN服務時,為了方便管理和映射,通常會特征化內容服務器域名。因此,內容服務器在域名構成上表現出與普通域名不同的特點,其域名部分包含了更多的字母、數字、點和連字符。該特征是判斷CDN域和CDN域名的一個重要特征。這種情況下也可細分為兩種特征化內容服務器域名的情況:
(1)基于子域名特征化內容服務器域名
根據子域名的字符特征,即使用子域名的部分或全部字符串作為內容服務器域名的前綴。如圖3所示,針對CDN服務商Cloudflare的CNAME記錄進行統計分析,發現子域名的字符長度表現特征和CNAME長度表現特征相同,原因為Cloudflare的內容服務器域名設置規則將子域名作為.cdn.cloudflare.net的前綴。例如查詢子域名www.shein.com的CNAME記錄為www.shein.com.cdn.cloudflare.net。
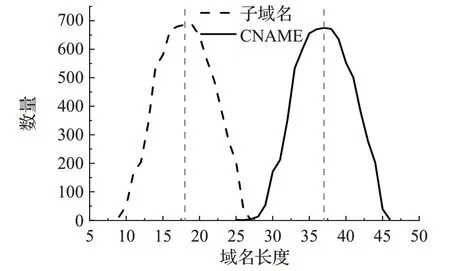
圖3 采用Cloudflare的子域名和CNAME域名長度Fig.3 Subdomain and CNAME domain length in Cloudflare
(2)隨機生成字符串作為內容服務器域名特征
部分CDN服務商使用隨機生成字符串作為內容服務器的前綴。如圖4所示,針對CDN服務商Incapsula的CNAME記錄進行統計分析,發現CNAME長度集中在20和22個字符上,原因是其設置CNAME的規則為隨機生成長度5或者7的字符串作為.x.incapdns.net.incapdns.net的前綴,例如子域名www.kooora.com的CNAME記錄為foosc.x.incapdns.net.incapdns.net。
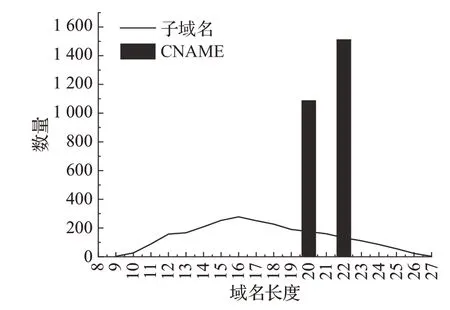
圖4 采用Incapsula的子域名和CNAME域名長度分布Fig.4 Subdomain and CNAME domain length in Incapsula
1.2.3 CNAME主域重合
由于域名是一種不可再生的有限資源,同時為了便于記憶和表現CDN服務商的特征,CDN服務商在采用特征化前綴的情況下,其CNAME域名后綴通常使用其擁有的特定域名。表3列出了CDN服務商Akamai和Amazon Cloudfront的CNAME設置常用后綴。因此,當CDN服務提供商為較多域名提供服務時,這些域名的CNAME記錄的后綴會集中到幾個主域上。該特征也是判斷CDN域和CDN域名的一個重要特征。
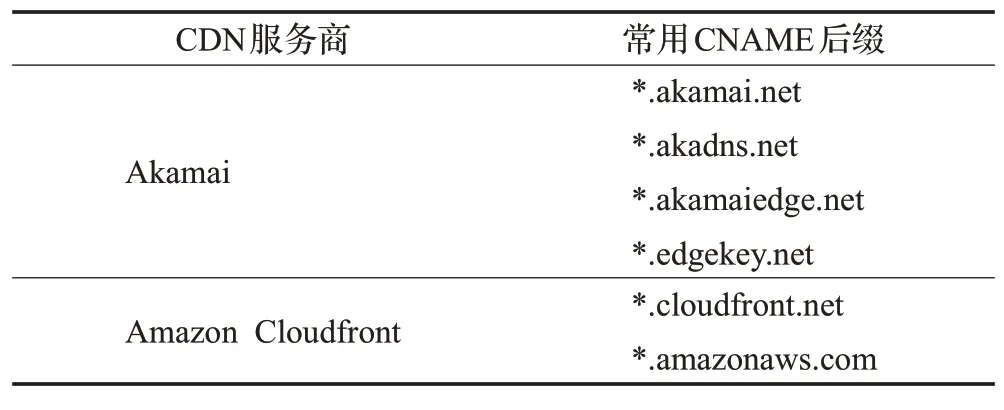
表3 Akamai和Amazon Cloudfront常用CNAME后綴Table 3 Akamai and Amazon Cloudfront CNAME suffixes
2 構建域名系統知識圖譜
2.1 知識圖譜構建過程
知識圖譜于2012年5月17日被Google正式提出[11],主要是為了提高搜索引擎的搜索能力,在搜索時增強搜索質量。知識圖譜由節點和邊組成,節點可以是實體或抽象的概念,邊表示實體的屬性或實體之間的關系。知識圖譜打破了不同場景下的數據隔離,為實際應用提供基礎支持[12]。
針對知識圖譜的覆蓋范圍也可分為通用知識圖譜和領域知識圖譜。
不同領域知識圖譜數據的來源、格式、應用和需求各不相同,因此沒有一套通用的標準和規范的構建方法。根據領域知識圖譜和通用知識圖譜的互通之處,其生命周期可以分為六個階段[13],如圖5所示。

圖5 領域知識圖譜生命周期Fig.5 Domain knowledge graph life cycle
知識建模是建立知識圖譜本體(Ontology)的過程。本體是指一種“形式化的,對于共享概念體系的明確而又詳細的說明”,本質上是對特定領域之中某套概念及其相互之間關系的形式化表達。知識建模通常有兩種構建方式[14]:一種是先從最頂層概念構建本體模型,逐步細化后添加實體的自頂向下(Top-Down)方法。另一種則是自底向上(Bottom-Up)的方法,即先對實體進行歸納,而后形成底層概念,并逐步向上抽象形成本體。
知識存儲是針對構建完成的本體指定底層存儲方式,根據領域特征選擇合適的存儲方案和存儲介質。而后針對不同來源的不同數據進行知識抽取,形成知識并進行存儲。最后將知識進行對齊、合并,形成統一的標識和關聯來提高知識圖譜的整體質量,進而形成最終的知識圖譜。
知識圖譜通過構建揭示實體之間關系的語義網絡,實現對現實世界的事物及其相互關系進行形式化的描述,提供了一種更好地組織、管理和理解互聯網海量信息的能力[15]。例如,賈焰等人[16]提出了一種構建網絡安全知識圖譜的實用方法。Najafi等人[17]通過構建DNS日志知識圖譜來檢測威脅。
因此針對域名系統構建知識圖譜可將多源異構數據構建成一個整體,進而對域名系統的多源數據和復雜網絡結構進行分析和利用。
2.2 本體構建
本文針對域名系統構建領域知識圖譜,因為域名系統涉及的實體和關系較為清楚,采用了自頂向下的方法:首先構建域名系統本體,基于構建的本體進行數據收集并從中抽取知識用以構建域名系統知識圖譜。本文參照斯坦福大學提出七步法[18]構建域名系統本體。
Syed等人[19]提出了一種統一的網絡安全本體(unified cybersecurity ontology,UCO),旨在支持網絡安全系統中的信息集成和網絡態勢感知。但是其抽象程度較高,側重點不在于域名系統,本文僅復用UCO的部分類和屬性。
隨后確定域名系統的實體類和屬性及其約束。針對域名系統所涉及的要素,考慮域名系統的解析流程和層次特性,創建如圖6所示本體模型,其中各字段所表達含義如表4所示。

表4 域名系統本體的節點和關系Table 4 Nodes and relationships of DNS ontology
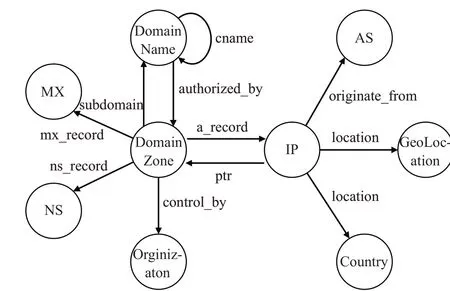
圖6 域名系統本體模型Fig.6 DNS ontology model
2.3 CDN域名推理規則
知識圖譜使用KG表示,定義KG={<E,R,P>},其中:
(1)E={ei|i=1,2,…,n},E是實體(Entities)的集合,如Country、Domain、Organization等。
(2)R={rij|i,j=1,2,…,n},R是關系(Relationships)的集合,rij表示從節點ei到節點ej的關系,如Control、OriginateFrom、Location等。
(3)P={<ei,pj,vk>},P是實體屬性(Properties)值對的集合。<ei,pj,vj>,表示實體ei的一項屬性pj的值為vk。
本文將CDN域名作為SubDomain節點的一種屬性進行表示,從而CDN域名的識別問題可以轉化為域名系統知識圖譜SubDomain節點的屬性推理問題。當SubDomain節點ei是CDN域名時,為其添加P={<ei,DomainClass,CDN>}。
對于CDN域名的判定,根據CDN服務特性,首先排除域名和其CNAME同屬一個主域的情況。其次根據CNAME主域重合的特征,識別出可能作為CDN服務商管轄的主域,進而根據CNAME的字符特征確定。
(1)CNAME主域重合特征,可分為三種情況如圖7所示。分別為:
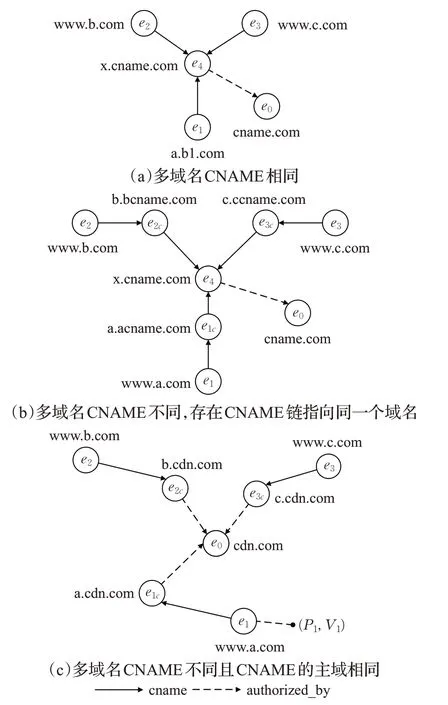
圖7 CNAME主域重合的三種情況Fig.7 Three situations of CNAME primary domains overlap
①多個域名的CNAME記錄指向同一個域名,該情況不屬于CDN域名特征。
②多個域名的CNAME記錄不同,但是存在CNAME鏈使其指向同一個域名,類比情況①不屬于CDN域名特征。
③多個域名的CNAME不同,且不存在CNAME鏈,CNAME的主域相同,該情況屬于CDN域名特征。
根據三種可能出現的情況,定義了CDN服務商主域的推理規則:
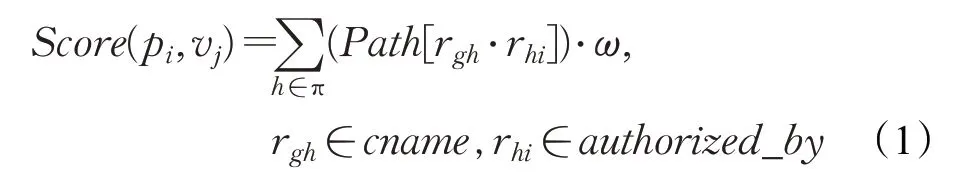
式中,pi,vj代表域名節點ei的屬性值對,針對Domain Zone節點ei,求所有通過authorized_by關系rgh到達節點ei的節點eh,同時要求eh是通過cname關系rhi被指向的cname域名。每存在這樣一條路徑便會增加節點ei是CDN域的可能性。π為所有通過關系authori zed_by可達ei的節點,ω是路徑帶來的可能性增量。如果Score(pij,vj)≥τ,τ為閾值,則判定節點ei是CDN域。判斷域名是否屬于CDN域名則判斷其CNAME記錄是否設置為CDN域下的子域名。
3 實驗分析
3.1 知識獲取
針對CDN服務的性質,個人和組織日常訪問頻次較多的域名開啟CDN服務的可能性較大,所以本文基于Alexa的前100萬域名進行數據獲取,實例化知識圖譜。初始化域名共包含91萬個主域名和2.4萬個子域名。其數據集中針對CDN域名一般開啟在子域名上的特征,本文將910 015個主域名進行擴展,加入其“www.”子域名。模型實例初始域名共包含91萬主域名和93.4萬子域名。
從初始域名開始,對DNS系統負責解析的域名服務器進行數據收集,主要包括A記錄解析Web服務器、NS記錄解析權威域名服務器、MX記錄解析電子郵件服務器。通過搭建本地域名服務器,使用dig命令對域名相關記錄信息進行查詢。
針對共93.3萬域名,對其A記錄進行查詢,共獲取48萬個唯一的IP地址,同時添加110萬條域名和IP對應A解析記錄的關系。
對于域名的名稱服務器,獲取NS記錄中所有的名稱服務器,并添加和權威域名服務器的關系。針對原始域名的91萬個域空間,共獲取到權威域名服務器11.4萬個,名稱服務器21萬個。添加權威域名到名稱服務器的關系84.9萬個。
對93萬個子域名進行CNAME記錄查詢,共發現35萬個域名存在CNAME記錄,其中子域名的主域和CNAME域名主域相同的有26萬條記錄,不同的有9萬條數據,將其CNAME添加為子域名節點,并添加CNAME關系。
MX記錄存儲電子郵件服務器的地址,對電子郵件客戶端向收件人發送電子郵件時提供IP解析記錄。對于每一個域,獲取其MX記錄,添加電子郵件服務器節點和域名到電子郵件服務器的MX解析記錄的關系。
自治域(autonomous system,AS)是自主決定內部網絡協議的IP網絡和路由器的集合。使用歐洲網絡協調中心(RIPE network coordination centre,RIPE NCC)的RIPEStat(Information about specific IP addresses and prefixes.https://stat.ripe.net/.)數據庫服務查詢IP所屬的AS自治域。對于每個AS,創建一個AS節點,并添加一條IP地址到AS自治域的originate_from關系。通過MaxMind公司的GeoIP(IP Geolocation and Online Fraud Prevention.http://dev.maxmind.com/.)數據庫,將國家和組織信息加入知識圖譜中。對每個IP查找其所屬組織和其地理位置,并通過地理位置和國家相關聯。
3.2 生成域名系統知識圖譜
針對域名系統的特征,主要對域名系統中的IP地址、DNS服務器、機構、地理位置等相關數據進行獲取和處理。由于網絡基礎設施和相關數據類型的確定性,涉及到的大多數據類型均為結構化數據采用基于規則與字典的方法進行實體抽取。
根據定義好的域名系統本體和收集分析得到的相關知識,進行域名系統知識圖譜構建。域名系統知識圖譜采用NoSQL數據庫Neo4j進行存儲,基于Neo4j實現的數據模型具有靈活可變的特性。模型擴展只是在數據模型中創建額外的節點、關系和屬性,不需要對模式進行更改或重新對數據庫進行規范化。圖形模式匹配查詢可以用Neo4j所具有的查詢語言(Cypher)表示。
如圖8所示,通過Neo4j圖數據庫查詢和baidu.com域相關的節點,共包含15個DNS域、4個NS域名服務器、3個MX域名服務器、7個子域名、2個IP地址等34個節點和68條關系。由此可見,域名系統相關數據類型較多,且關聯關系豐富,使用知識圖譜能夠較好地將各類數據進行統一建模表征,實現較好的展現效果和更快捷的查詢。

圖8 baidu.com域在知識圖譜中的展示實例圖Fig.8 DNS zone baidu.com in knowledge graph
3.3 識別CDN域名
針對Alexa前100萬域名構建的域名系統知識圖譜,在其之上進行CDN域名識別,共識別出CDN域名37 600個,涉及170個可能為CDN域名服務商的TLD,其中出現次數最多的10個主域名如表5所示。
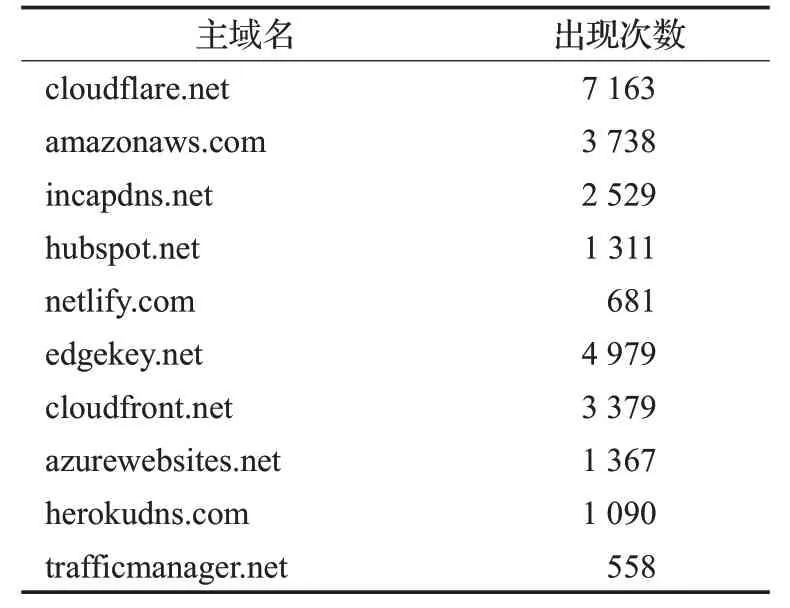
表5 出現次數最多的10個主域名Table 5 Top 10 DNS Zone
對識別結果的評價,為了兼顧測試集的多樣性和準確性,避免測試集中存在較多非CDN域名對實驗結果產生大幅度影響。
本文根據各種不同的類型,選取不同數量的域名構成樣本集。分別從算法識別出的CDN域名、沒有CNAME記錄的域名和擁有CNAME記錄且識別為非CDN域名中各隨機選取600、200和200個,共計1 000個域名構成測試樣本。
并通過參考第三方CDN識別網站和基于多地域Ping的人工識別的方式對測試樣本進行CDN域名識別,最終形成測試集。從而計算模型識別結果的準確率(Precision)、召回率(Recall)和F1值,結果如表6所示。

表6 識別結果Table 6 Recognition result
在構成的測試集中,識別的準確率、召回率和F1值均達到85%以上,證明了本文基于知識圖譜在大規模數據集上可以達到較好的識別結果。同時如表7所示,和其他方法進行對比,在不需要手工構建大量樣本集的前提下便可實現大規模不限定范圍的CDN域名識別。同時本文所有數據僅基于單節點的DNS記錄查詢,可以實現以更小的代價達到CDN域名檢測的目的。
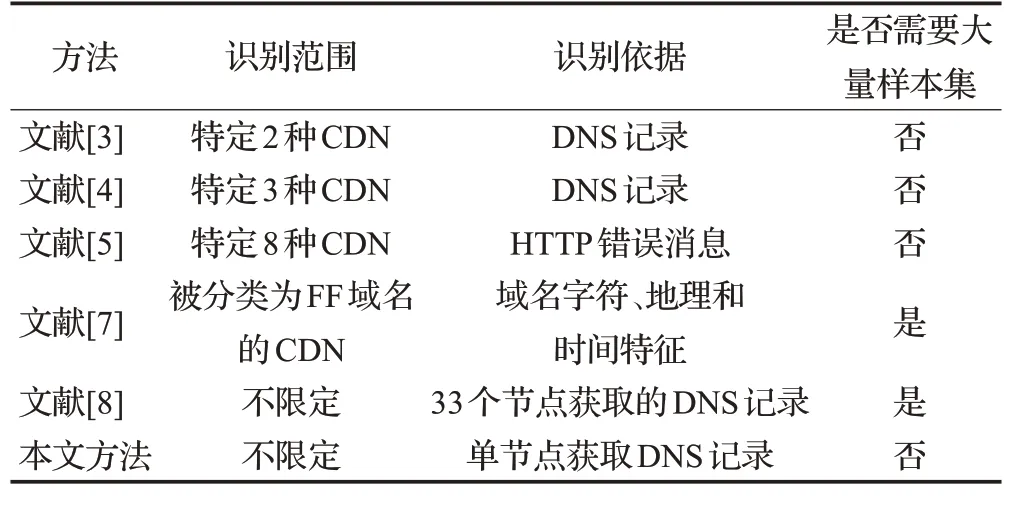
表7 方法對比Table 7 Method comparison
4 結束語
本文針對CDN域名大規模識別的問題,提出基于域名系統知識圖譜的CDN域名識別技術。通過知識圖譜可以對多源異構數據進行統一建模利用的特性,構建域名系統知識圖譜,針對域名系統相關數據進行深入分析尋找CDN域名特征,從而定義知識圖譜的屬性推理規則,達到識別CDN域名的效果。實驗表明,在構建的百萬節點規模的知識圖譜之上,可以達到較好的識別精度,并且能夠對CDN攻擊進行影響范圍的評估,用以針對性地進行防御。未來工作可以考慮將域名系統擴展到網絡空間基礎設施,構建覆蓋面更廣的知識圖譜,豐富知識圖譜和推理規則,以達到更精準的CDN域名識別和更深層次的知識挖掘。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
裝備制造技術(2019年12期)2019-12-25 03:06:46
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
