SPSS在進口鐵礦產地品牌識別中的應用
2022-03-25 07:32:34陳永欣李慈進吳國境何龍涼
大眾科技 2022年1期
關鍵詞:模型
陳永欣 周 山 李慈進 吳國境 何龍涼
SPSS在進口鐵礦產地品牌識別中的應用
陳永欣1周山2李慈進1吳國境1何龍涼1
(1.中華人民共和國防城海關,廣西 防城港 536000;2.廣西柳州鋼鐵集團有限公司,廣西 防城港 538001)
文章介紹了建立進口鐵礦產地品牌識別模型的方法。利用X射線熒光光譜法、紅外吸收法、發射光譜法等常規方法測定所收集的進口鐵礦樣品中的主次元素含量,選擇其中Al2O3、SiO2、Fe、K2O、Cr、CaO、MgO、V2O5、TiO2、MnO、Na2O、P、As、S、Ni、Zn、Pb共17種元素進行含量分析。在大量檢測數據的基礎上,分別采用SPSS軟件中4種算法對元素和產地品牌的關聯程度進行計算,建立不同進口鐵礦產地品牌識別模型,并利用測試樣本評估不同模型的準確性和可靠性。測試結果顯示,判別分析和多層感知器神經網絡能實現對鐵礦石產地與品牌的識別。所建立的模型可應用于常見進口鐵礦的產地品牌識別,對于維護貿易公平、保障礦石質量安全將起到積極的作用。
鐵礦石;神經網絡;判別分析;產地;品牌
引言
鐵礦石是鋼鐵生產的重要原材料,是重要的國際大宗商品,由于受地質、環境等因素影響,不同產地鐵礦石的主次元素含量存在某些區域特征。中國是世界上最大的鐵礦石需求國,2020年中國累計進口鐵礦石11.7億噸,同比增加9.5%。雖然進口量不斷增加,但品質卻難以得到保障。少部分鐵礦供應商采取了降低品質、以次充好的做法,甚至出現原產地造假,以擴大出口規模,騙取最惠國關稅,謀求更大的經濟利益。由于不同產地的鐵礦品質、應用范圍不盡相同,國內鐵礦使用企業在冶煉時就需要制定不同的混料配比。偽冒鐵礦原產地不僅直接損害了鋼鐵企業的利益,同時也嚴重擾亂了我國進口鐵礦的市場秩序和進口貨物海關監管,因此對于識別進口鐵礦產地品牌就變得極為重要。
以已知國別鐵礦石樣本X 射線熒光光譜無標樣分析數據為基礎,武素茹、張博等[1,2]采用逐步判別法、逐步判別-Fisher判別分析法等建立進口國別的判別模型,識別進口鐵礦石產地及品牌,準確率為74.6%以上。劉倩[3]應用波長色散-X射線熒光光譜無標樣分析法,選擇 O、Al、Mg、 Si、S、P、K、Ca、Cu、Fe、Ti、Ag、As、Pb、Mo、Zn和Mn 共17種元素含量作為變量,結合 F-score 篩選變量用于 BP 神經網絡模式識別可以實現對銅精礦的國別識別。較多方法是應用無標樣半定量方法確定元素含量,但不同儀器、不同實驗室之間所得到的成分含量不盡相同,甚至相差較大,會影響到方法適用性[4-6]。
大數據應用為量化管理提供便利的同時,也需要全面掌握數據統計分析技術與方法。SPSS 是世界上最早采用圖形菜單驅動界面的統計軟件[7],由于其操作簡單,已經在各個領域發揮了巨大作用。本文對798份防城口岸進口鐵礦進行準確成分分析,并應用SPSS對所獲得監測數據進行統計分析,分析出進口鐵礦中各元素含量與產地品牌間的關系,利用不同統計方法建立礦石組分含量—產地品牌的“大數據”識別模型。該模型直接應用于進口鐵礦的產地鑒別,不僅有利于保護我國進口鐵礦貿易相關方的經濟利益和保障進口鐵礦的質量安全,而且對于維護國家外貿秩序穩定也將起到一定作用。
1 實驗部分
1.1 樣品收集
根據GB/T 10322.1-2014《鐵礦石取樣和制樣方法》從防城口岸采集并制備來自8個國家21個品牌的進口鐵礦化學分析樣品,共798批次樣品。采集的樣品分布地域廣,容量大,具有一定的獨立性和代表性,包含了我國進口鐵礦的主要來源國。
1.2 方法
所收集的樣品采用以下方法對其中17種主次含量進行分析:SN/T 0832-1999 《進出口鐵礦中鐵、硅、錳、鈣、鈦、磷、鋁和鎂的測定——波長色散X射線熒光光譜法》、GB/T 6730.61-2005《鐵礦石碳和硫含量的測定高頻燃燒紅外吸收法》、GB/T 6730.76-2017《鐵礦石鉀、鈉、釩、銅、鋅、鉛、鉻、鎳、鈷含量的測定電感耦合等離子體發射光譜法》。
通過采集來自全國主要銅精礦進出口口岸的澳大利亞、巴西、秘魯、南非、烏克蘭、毛里塔尼亞、伊朗、智利8個國家798批進口鐵礦代表性樣品,選擇17種元素含量用于判別分析與神經網絡建模,對比了一般判別、逐步判別、多層感知器神經網絡、徑向基函數神經網絡對鐵礦石產地品牌識別的適用性,討論不同方法的差異,通過建模樣品驗證、交叉驗證以及預測樣品驗證,可確保不同模型的準確性和適用性。
1.3 數據處理
1.3.1 判別分析
在分類確定的條件下,根據某一研究對象的各種特征值,判別其歸屬類型問題的一種多變量統計分析方法,稱為判別分析,又稱“分辨法”。其基本原理是根據一定的判別準則,建立相關判別函數,用研究對象的相關數值確定判別函數中的待定系數,并計算判別指標。據此即可確定某一樣本屬于何類。判別方法可分為參數法和非參數法,也可以分為定性資料的判別分析和定量資料的判別分析。常用方法有最大似然法、距離判別、Bayes判別和Fisher判別等4種。SPSS軟件具有其中一般判別和逐步判別兩種判別分析的算法。一般判別分析是根據已知變量數據來判別某些樣本未知類別的方法。逐步判別分析則是篩選出跟要判別的類別相關性較強的變量指標來判別類別,而與類別相關性不強的指標,則給予剔除。
應用SPSS軟件,采取兩種不同方式對全部個案進行分析,分析個案處理摘要如表1所示,共有7.6%的個案排除在外,一般判別通過變量共提取了17個函數;而逐步判別通過變量共提取了16個函數,在每個步驟中,將輸入可以使總體威爾克Lambda最小化的變量,最大步驟數為34,要輸入的最小偏F為3.84,要除去的最大偏 F為2.71。

表1 分析個案處理摘要表
1.3.2 神經網絡
近年來興起的人工神經網絡學科(ANN- artificialneuralnetworks)是集數學、計算機科學、神經學等學科為一體的綜合性交叉學科。神經網絡是由大量的稱為神經處理單元的自律要素及這些要素相互作用形成的網絡。神經網絡分為一個輸入層、若干個中間隱含層和一個輸出層三個部分。神經網絡分析法能夠從未知模式的大量復雜數據中發現其規律。神經網絡分析過程是一種自然的非線性建模過程,無需分清樣本數據間存在的何種線性、非線性關系,克服了傳統數據分析過程的復雜性及選擇適當模型函數形式的困難,極大方便了樣本數據建模與分析。目前應用的神經網絡包括BP神經網絡、RBF(徑向基)神經網絡、感知器神經網絡、線性神經網絡、自組織神經網絡、反饋神經網絡等。SPSS軟件中具備兩種神經網絡算法:多層感知器神經網絡和徑向基函數(RBF)神經網絡。
多層感知器神經網絡是一個具有單層計算神經元的神經網絡,網絡的傳遞函數是線性閾值單元;主要用來模擬人腦的感知特征,采取閾值單元作為傳遞函數,適合簡單的模式分類問題。徑向基函數(RBF-Radial Basis Function)神經網絡具有單隱層的三層前饋網絡。模擬了人腦中局部調整、相互覆蓋接收域的神經網絡結構,是一種局部逼近網絡,它能夠以任意精度逼近任意連續函數,特別適合于解決分類問題。
應用SPSS軟件中多層感知器和徑向基函數兩種方法,均使用樣品798個,其中多層感知器訓練數561(70.3%),檢驗數237(29.7%);徑向基函數訓練數546個(68.4%),檢驗數252(31.6%)。兩種算法的輸入層是一致的(17個),隱藏層同為1個,隱藏層中單元數和激活函數不一樣,輸出層中因變量和單元數一致,但激活函數和誤差函數不一致。具體如表2所示。
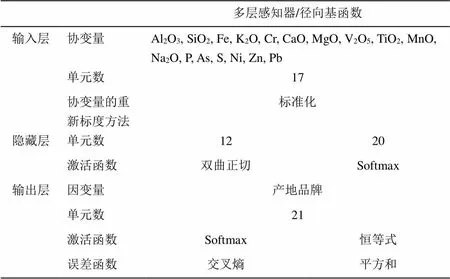
表2 神經網絡算法網絡信息
2 結果與討論
2.1 判別方式
2.1.1一般判別
算法共提取的17個函數,可以解釋100%的方差,其中函數1~7累計方差已經達到98.8%的方差,如表3所示,函數1~5的典型相關性在0.9以上,而函數8驟降到0.656,可以看出函數1~7尤為重要。如表4所示,顯著性小于0.05時,具有統計意義,提取的函數有效,可以使用。同時可以看出函數15~17的顯著性0.102~0.810之間,遠大于0.05,證明這三個函數并非十分必要。從一般判別函數分類合并圖(圖1)也可以明顯看出,不同產地的類別質心分散性較好,同一產地的質心較為接近,說明不同國家的品質能相互區別開;“澳大利亞中信精粉”與其它1~6種類相對分散,“巴西英美資源精粉”與其它8~11種類相對分散,說明這兩種精粉與其它礦種區別較大;“伊朗精粉”和“智利CMP Atacama精粉”同一分類個案與質心重疊性不佳,說明這兩個礦種的品質波動性較大。
一般判別算法的典則判別函數(1~7):
Y1=0.834X1+1.349X2+2.925X3-17.913X4+31.749X5-47.571X6-112.321X7-0.477X8-0.378X9-1.031 X10+6.907 X11+8.652 X12-20.157X13+85.507X14+49.007X15+54.327X16+36.478X17-92.686
Y2=-2.598X1-1.184X2+3.123X3-13.273X4-74.445X5+25.191X6-256.347X7+1.141X8+2.230X9-1.186 X10+6.396 X11+3.731X12+145.100X13+53.416X14+20.687X15+20.157 X16+16.861X17+85.437
Y3=0.346X1+0.445X2+5.171X3+5.014X4-180.998X5-40.140X6+102.434X7-0.626X8+12.007 X9+5.409X10+4.626X11+5.189X12+136.779X13-111.468 X14-35.050X15-60.722X16+18.044 X17-29.018
Y4=1.110X1-0.014X2+7.043X3+26.716X4+74.267X5+65.584X6-411.206X7+1.188X8+3.897X9+5.016X10+1.363X11+1.922X12-65.319X13+218.019X14-6.783X15-2.949X16+22.142 X17-9.514
Y5=0.963X1+0.517X2-7.653X3+35.977X4-61.525X5-151.645X6+346.439X7+1.878X8+1.114X9+2.561X10+2.609X11+4.908X12+17.352X13-183.264X14+10.463X15+15.537 X16-41.913 X17-44.150
Y6=1.405X1+2.308X2+0.366X3+49.243X4+273.704X5-41.850X6-266.263X7+4.322X8-5.095X9-3.836X10+0.961X11+0.746X12-72.016X13-2.415X14-9.586X15-21.251X16+51.709X17-160.526
Y7=0.842X1+2.112X2+3.389X3-35.118X4-235.823X5+100.148X6+4.097X7+4.948X8+7.367X9+7.270X10-1.019X11-0.886X12+98.242X13-3.557X14-18.662X15-4.440X16-42.033X17-142.793
為達到更高的識別準確率,筆者選擇使用全部17個函數來建立判別模型,所建立的模型具有很好的識別效果,可準確地對94.4%個原始已分組個案進行分類,正確地對93.9%個進行了交叉驗證的已分組個案進行了分類。

表3 一般判別函數特征值
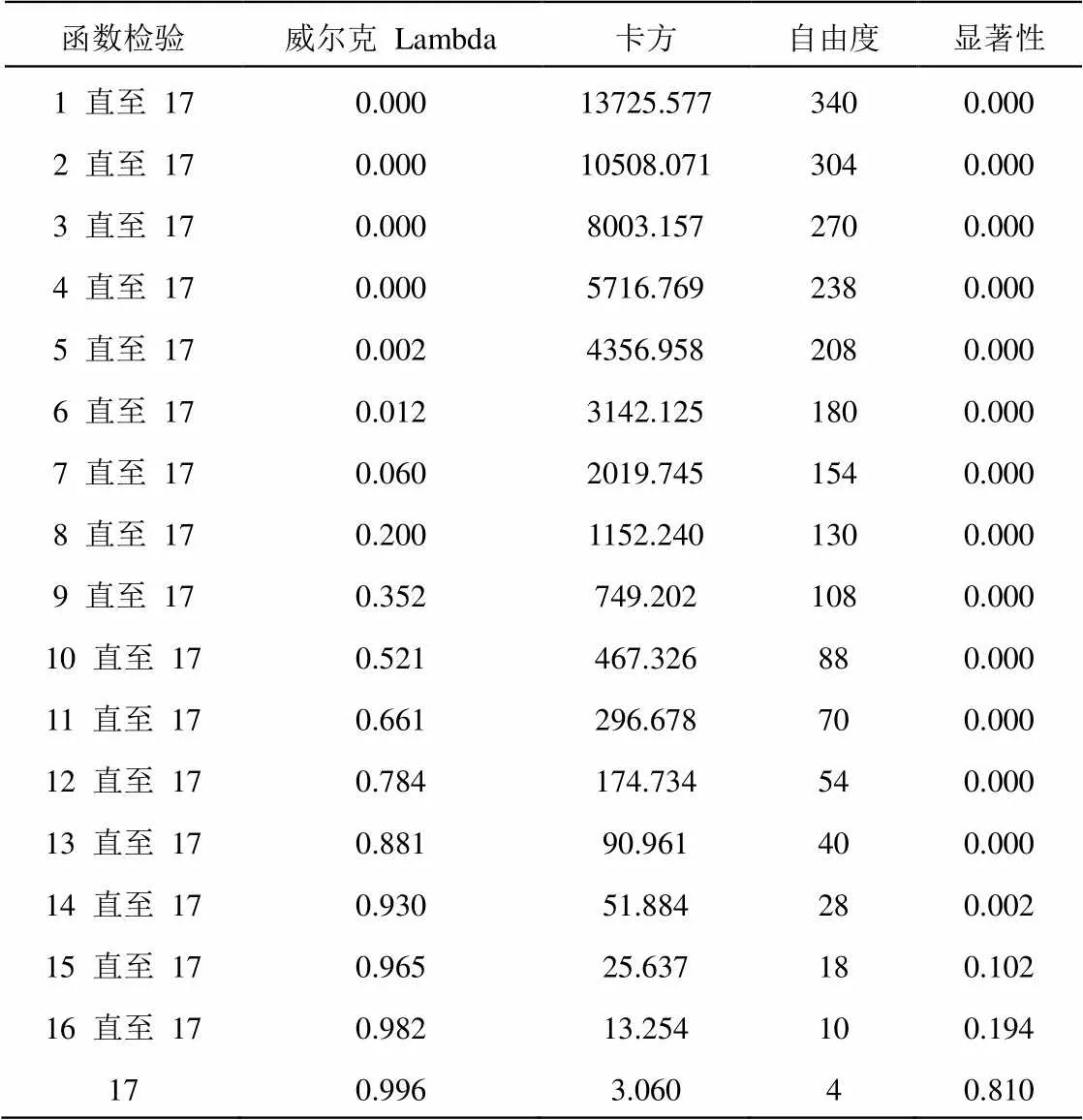
表4 一般判別函數威爾克 Lambda
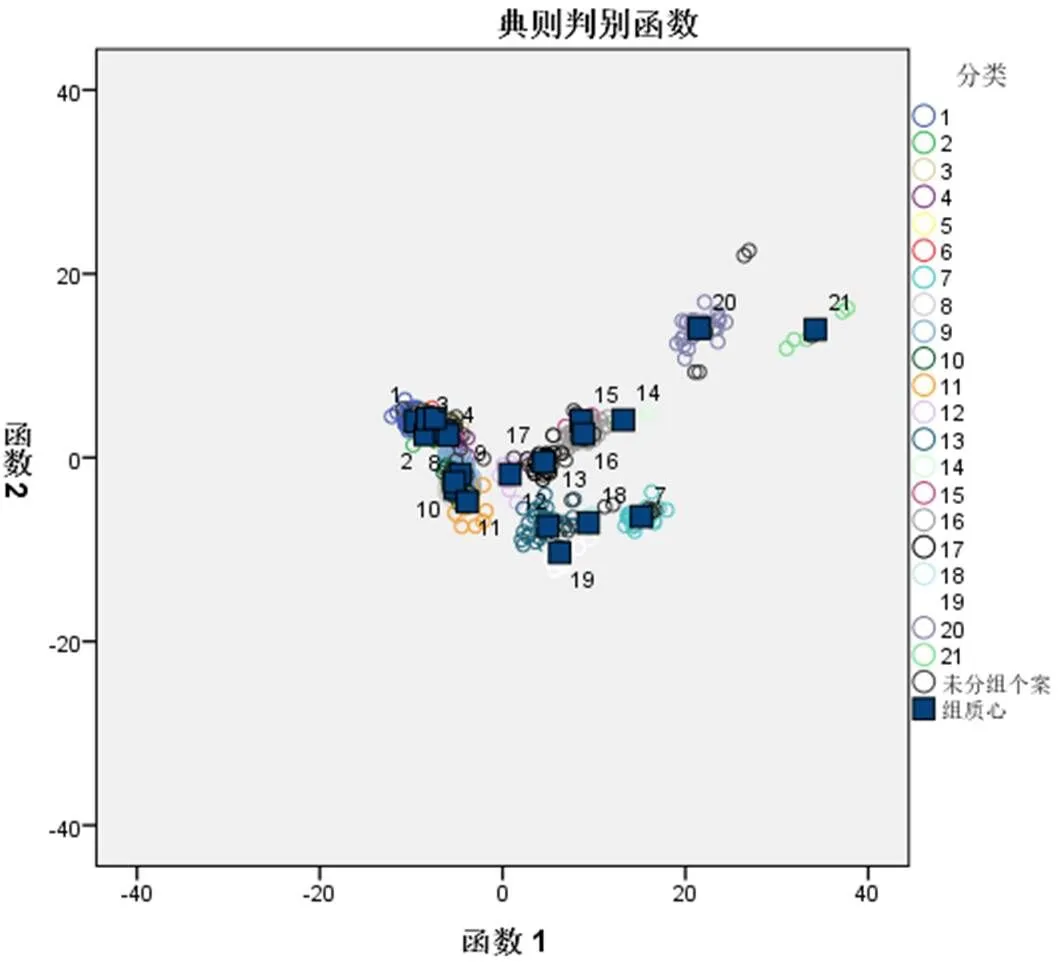
(1-澳大利亞BHP金布巴粉,2-澳大利亞必和必拓麥克粉,3-澳大利亞必和必拓紐曼粉,4-澳大利亞必和必拓紐曼混合塊,5-澳大利亞力拓PB粉,6-澳大利亞力拓PB塊,7-澳大利亞中信精粉,8-巴西CSNIOC6粉,9-巴西淡水河谷BRBF混合粉,10-巴西淡水河谷SSFG粉,11-巴西托克SSFS粉,12-巴西英美資源精粉,13-毛里塔尼亞SNIM TZFC粉,14-秘魯精粉,15-南非阿斯芒粉,16-南非庫博標準粉,17-南非庫博塊,18-烏克蘭INGGOK 精粉,19-烏克蘭KRIVOY ROG 精粉,20-伊朗精粉,21-智利CMP Atacama精粉)
2.1.2 逐步判別
算法所提取的16個函數可以解釋100%的方差,函數1~7累計方差已經達到98.9%的方差。函數特征值(表5)顯示函數1~5的典型相關性在0.9以上,而函數8驟降到0.644,可以看出函數1~7尤為重要。威爾克 Lambda表(表6)可以看出函數16的顯著性0.077,證明這個函數重要性可以忽略。從逐步判別函數分類合并圖(圖2)也可以明顯看出,與2.1.1一般判別圖1的情況一致。
逐步判別算法的典則判別函數(1~7):
Y1=0.833X1+1.349X2+2.928X3-17.919X4-44.595X5-84.204X6-0.478X7-0.370X8-1.025X9+6.907X10+8.653X11-19.222X12+ 85.571X13+48.969X14+54.268X15+36.426 X16-92.706
Y2=-2.597X1-1.186X2+3.105X3-13.263X4+18.345X5-322.260X6+1.146X7+2.185X8-1.212X9+6.387X10+3.718X11+142.654X12+53.521X13+20.851X14+20.423X15+16.962X16+85.591
Y3=0.341X1+0.439X2+5.174X3+5.044X4-57.163X5-59.228X6-0.614X7+11.990X8+5.380X9+4.659X10+5.205X11+132.183X12- 111.851X13-34.839X14-60.458X15+18.509X16-28.619
Y4=1.107X1-0.016X2+7.036X3+26.597X4+72.658X5-345.183X6+1.179X7+3.920X8+5.039X9+1.353X10+1.918X11-63.116X12+218.292X13-6.813X14-2.925X15+21.706X16-9.328
Y5=0.970X1+0.528X2-7.664X3+36.293X4-157.876X5+292.529X6+1.902X7+1.066X8+2.520X9+2.622X10+4.917X11+ 15.293X12-183.992X13+10.479X14+15.454X15-41.379 X16-44.947
Y6=1.410X1+2.332X2+0.476X3+48.994X4-13.373X5-29.268X6+4.348X7-5.035X8-3.785X9+0.912X10+0.688X11-64.542X12+ 1.769X13-10.087X14-21.673X15+51.007X16-162.053
Y7=0.828X1+2.083X2+3.361X3-35.848X4+76.913X5-202.548X6+4.920X7+7.409X8+7.328X9-1.012X10-0.872X11+92.772X12-6.651X13+18.287X14-3.973X15-41.739 X16-140.838
為追求更高的識別準確率,還是選擇使用全部16個函數來建立判別模型,該模型正確地對94.2%個原始已分組個案進行了分類,正確地對93.4%個進行了交叉驗證的已分組個案進行了分類。

表5 逐步判別函數特征值

表6 逐步判別函數威爾克 Lambda

(1-澳大利亞BHP金布巴粉,2-澳大利亞必和必拓麥克粉,3-澳大利亞必和必拓紐曼粉,4-澳大利亞必和必拓紐曼混合塊,5-澳大利亞力拓PB粉,6-澳大利亞力拓PB塊,7-澳大利亞中信精粉,8-巴西CSNIOC6粉,9-巴西淡水河谷BRBF混合粉,10-巴西淡水河谷SSFG粉,11-巴西托克SSFS粉,12-巴西英美資源精粉,13-毛里塔尼亞SNIM TZFC粉,14-秘魯精粉,15-南非阿斯芒粉,16-南非庫博標準粉,17-南非庫博塊,18-烏克蘭INGGOK 精粉,19-烏克蘭KRIVOY ROG 精粉,20-伊朗精粉,21-智利CMP Atacama精粉)
2.1.3 兩種判別方式的比較
從上述2.1.1和2.1.2可知,雖然算法不一樣,激活函數、誤差函數不盡相同,逐步判別所提取的函數比一般判別少1個,但從兩個模型的參數評估來說,在鐵礦石產地和品牌模型的建立上,一般判別與逐步判別沒有明顯差異,函數1~7的累計方差達到了98%以上,函數1-13的顯著性為0.000,重要的是兩者準確性都較為理想,超過93%。
2.2 神經網絡
2.2.1 敏感性
敏感性分析,主要是通過對神經網絡各個參數的敏感性進行分析,比較出對網絡模型的輸出決策幾乎不起作用或無影響的連接或輸入結點,然后進行網絡裁剪,從而達到網絡結構簡化的目的。從曲線下方的區域數值(表7)可以看出,多層的敏感性比徑向基的要好,曲線下方的區域,多層感知器的數值大于0.998,而徑向基的為0.873~0.998之間。
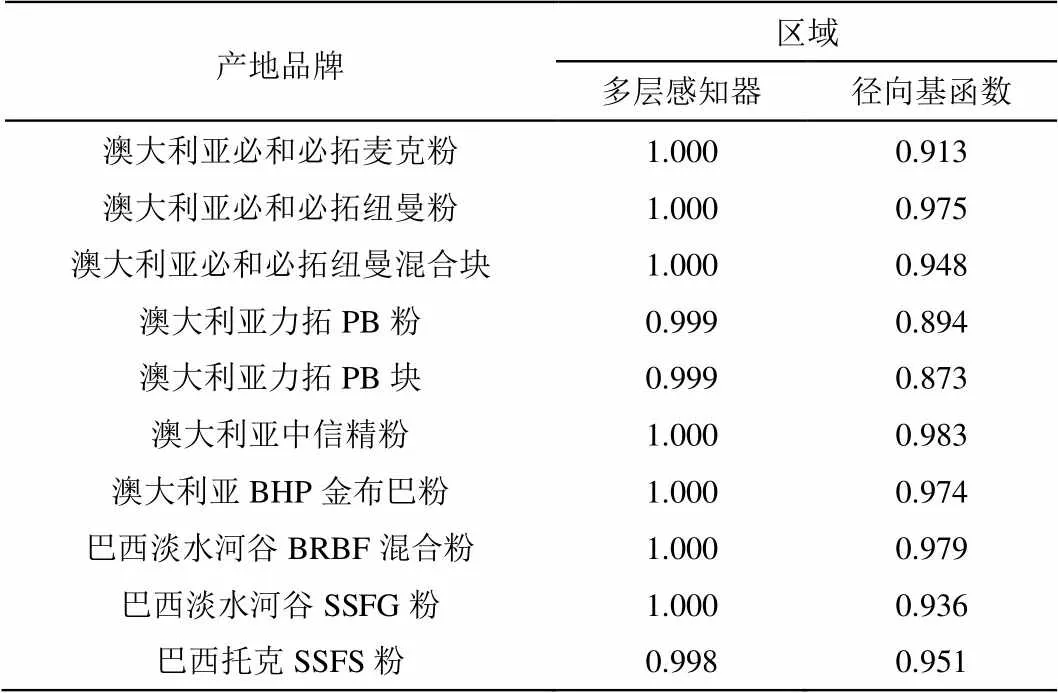
表7 不同特異性-敏感性曲線下方的區域
續表7

巴西英美資源精粉1.0000.996 巴西CSNIOC6粉(分類12)0.9990.974 毛里塔尼亞SNIM TZFC粉1.0000.992 秘魯精粉1.0000.986 南非阿斯芒粉1.0000.967 南非庫博標準粉1.0000.996 南非庫博塊1.0000.939 烏克蘭INGGOK 精粉0.9990.976 烏克蘭KRIVOY ROG 精粉1.0000.985 伊朗精粉1.0000.998 智利CMP Atacama精粉1.0000.998
2.2.2 增益及效益
兩種方法在增益和效益指標方面差異較大,具體見圖3至圖6。(1)多層感知器:當使用10%樣本量計算時,增益就在60%以上,大部分產地品牌的增益接近100%;當使用20%樣本量計算時,全部增益接近100%。也就是說,只用到10%左右的樣本就可以篩選出來自同一產地品牌的樣本。這也從效益圖中也得到印證。(2)徑向基函數:相比于多層感知器,增益就沒有那么明顯,當使用20%樣本量計算時,尚有不少產地品牌增益尚未達到90%;當使用70%樣本量計算時,“澳大利亞力拓PB塊”增益才90%。

圖3 多層感知器增益圖
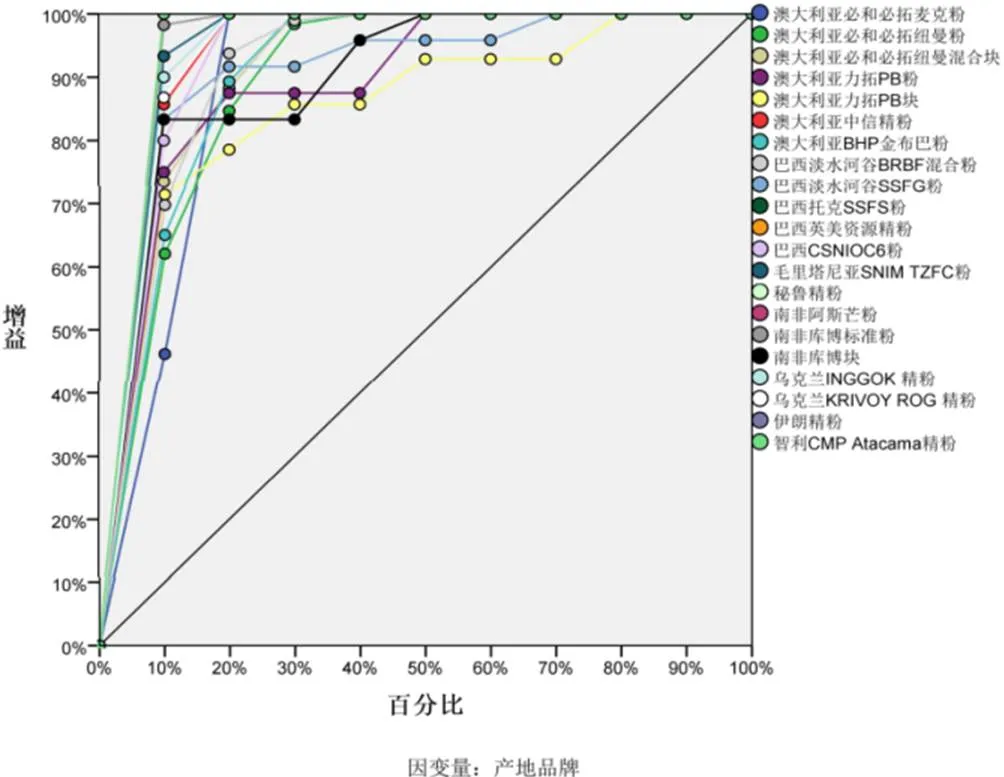
圖4 徑向基函數增益圖
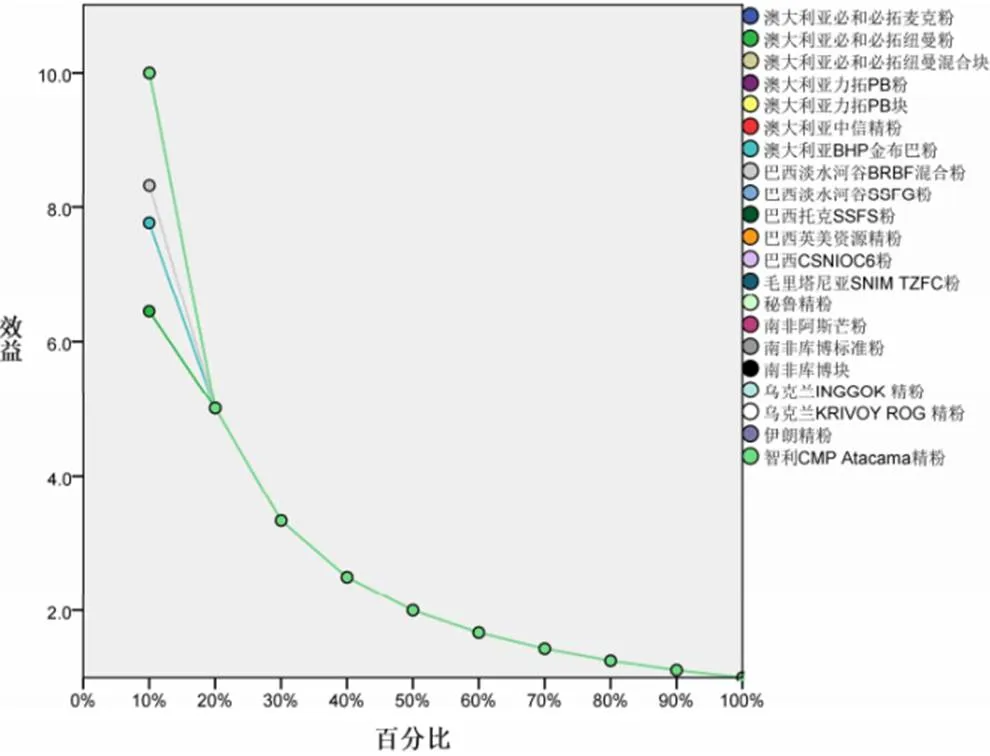
圖5 多層感知器效益圖
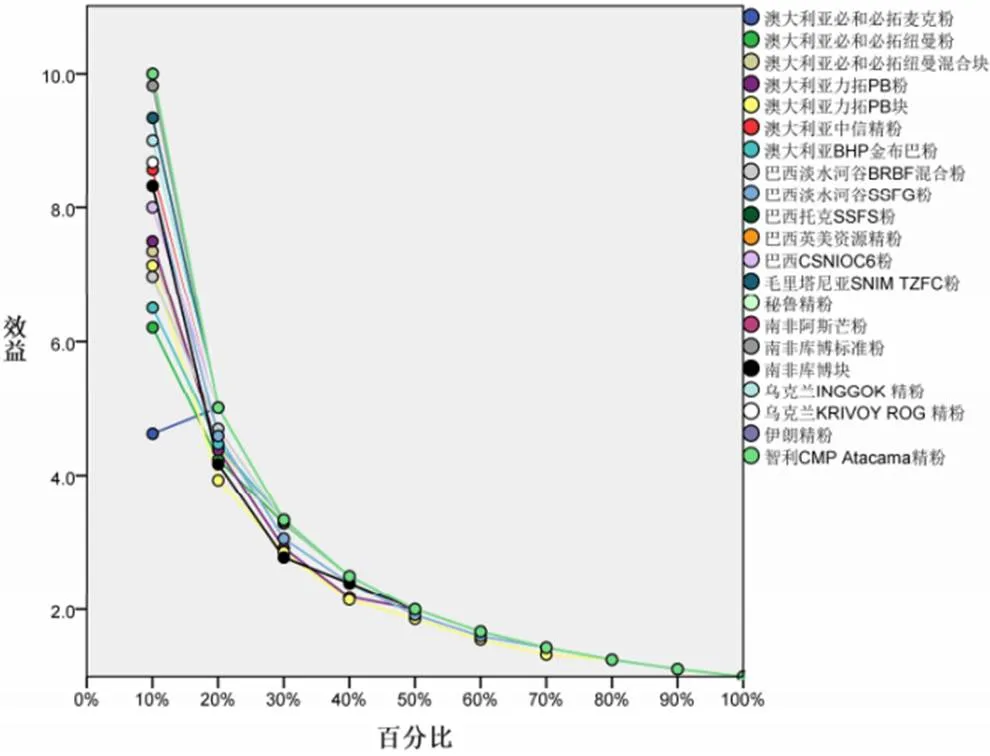
圖6 徑向基函數效益圖
2.2.3 自變量正態化重要性
對17個自變量正態化重要性進行分析,多層感知器模型中各變量重要性在0.020~0.099之間,前五的因變量分別為SiO2(100%)、Al2O3(84.0%)、K2O(69.8%)、Na2O(66.6%)、TiO2(65.2%);徑向基模型中各變量重要性在0.038~0.076之間,前五的因變量分別為MgO(100%)、V2O5(89.2%)、S(89.0%)、Na2O(87.7%)、MnO(85.6%)。兩者前五因變量中只有Na2O一個相同,從另一方面證明兩個算法有較大區別,模型的權重完全不一樣。具體數值如表8所示。
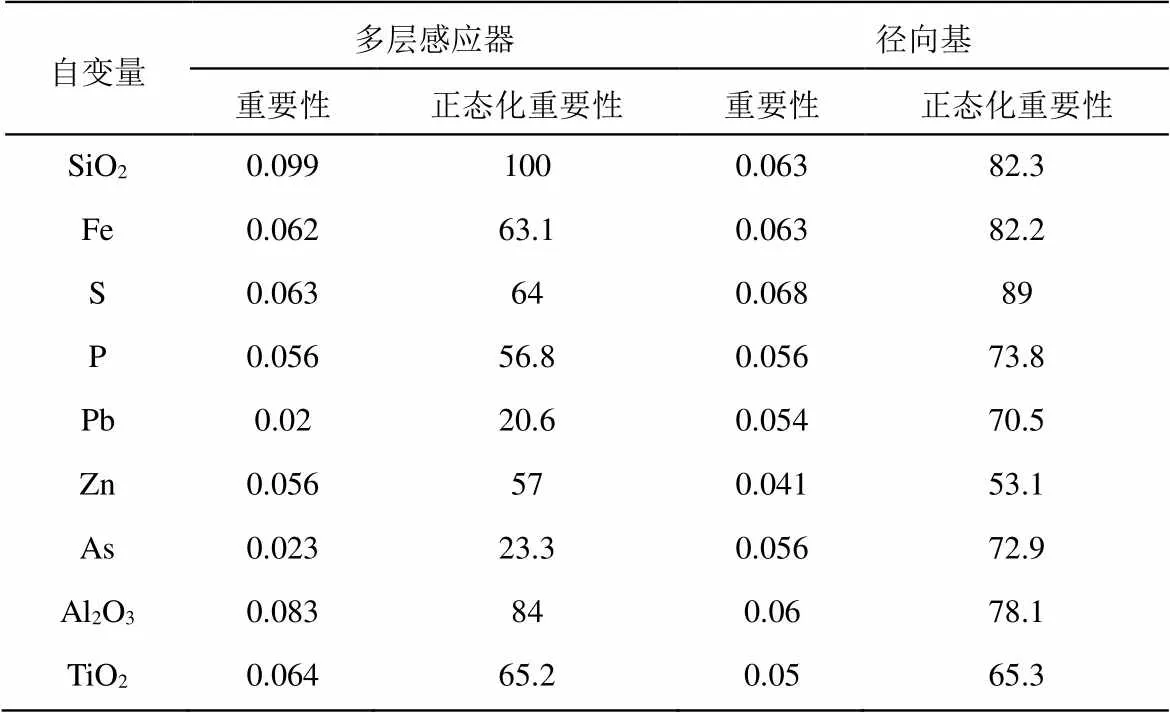
表8 自變量重要性
續表8

MnO0.05555.30.06585.6 CaO0.05555.90.05977.3 MgO0.06610.076100 Ni0.05656.90.03849.2 Cr0.05353.80.05268.2 V2O50.0661.20.06889.2 K2O0.06969.80.06483.7 Na2O0.06666.60.06787.7
2.2.4 準確性
(1)多層感知器:訓練中使用的中止規則為“誤差在1個連續步驟中沒有減少”,交叉熵誤差為34.068,不正確預測百分比為1.6%;在檢驗計算時,交叉熵誤差為31.641,不正確預測百分比為4.2%。多層感知器分類結果,訓練集中3個澳大利亞樣品、4個巴西粉礦樣品、1個烏克蘭精粉被識別為同一國家別的品牌,1個毛里塔尼亞SNIM TZFC粉被識別為烏克蘭INGGOK 精粉。訓練集中“烏克蘭INGGOK 精粉”的準確性最低為80%,高達14個品牌的準確性達100%;檢驗集中,共有13個品牌的準確性達100%,“南非阿斯芒粉”和“智利CMP Atacama精粉”準確性僅為50%,總體準確性為95.8%。經過訓練之后可以達到很好的精度和較高的學習效率。收斂速度很快,可以在一定情況下逼近給定的任意精度。
(2)徑向基函數:訓練中平方和誤差103.893,不正確預測百分比為27.7%;在檢驗計算時,平方和誤差56.179,不正確預測百分比為34.5%。徑向基函數分類結果較為不理想,訓練集中,共有8個產地品牌樣本準確性為0,準確性最高的為澳大利亞BHP金布巴粉,總體準確性僅為72.3%;檢驗集中,同樣共有8個產地品牌樣本準確性為0(品牌與訓練集一致),總體準確性僅為65.5%。
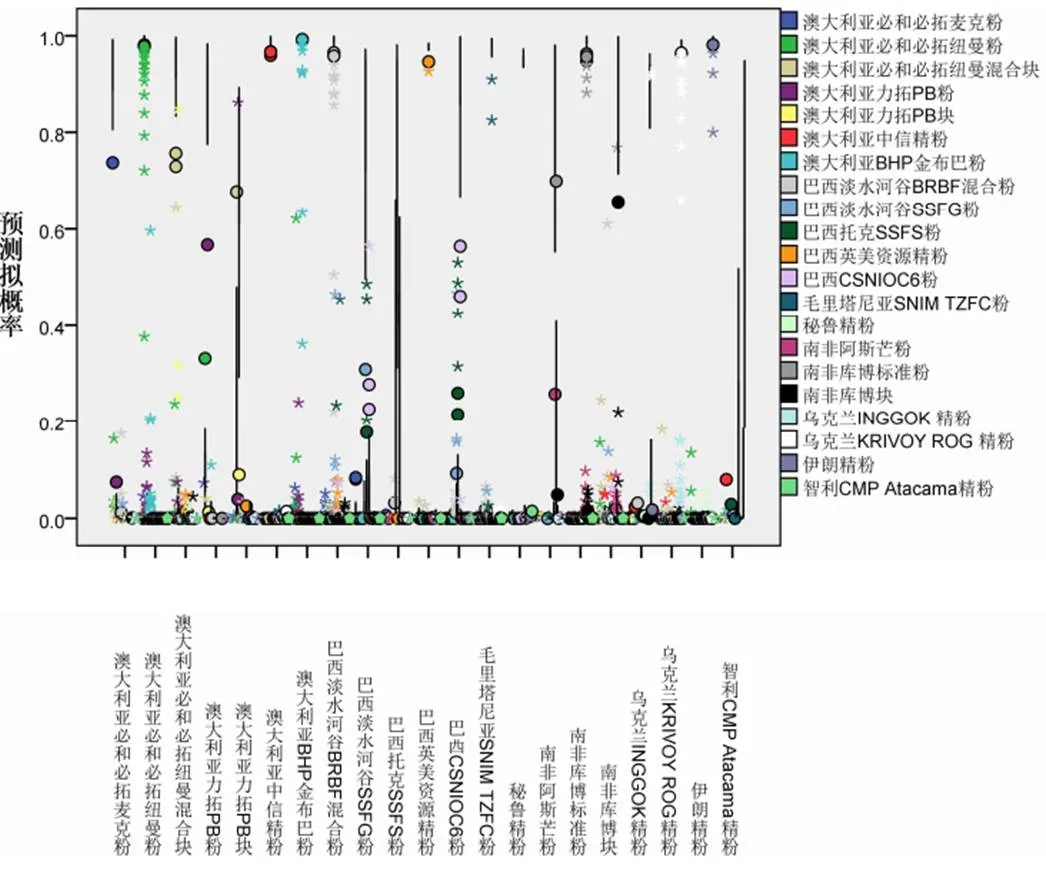
圖7 多層感知器預測擬概率

圖8 徑向基函數預測擬概率
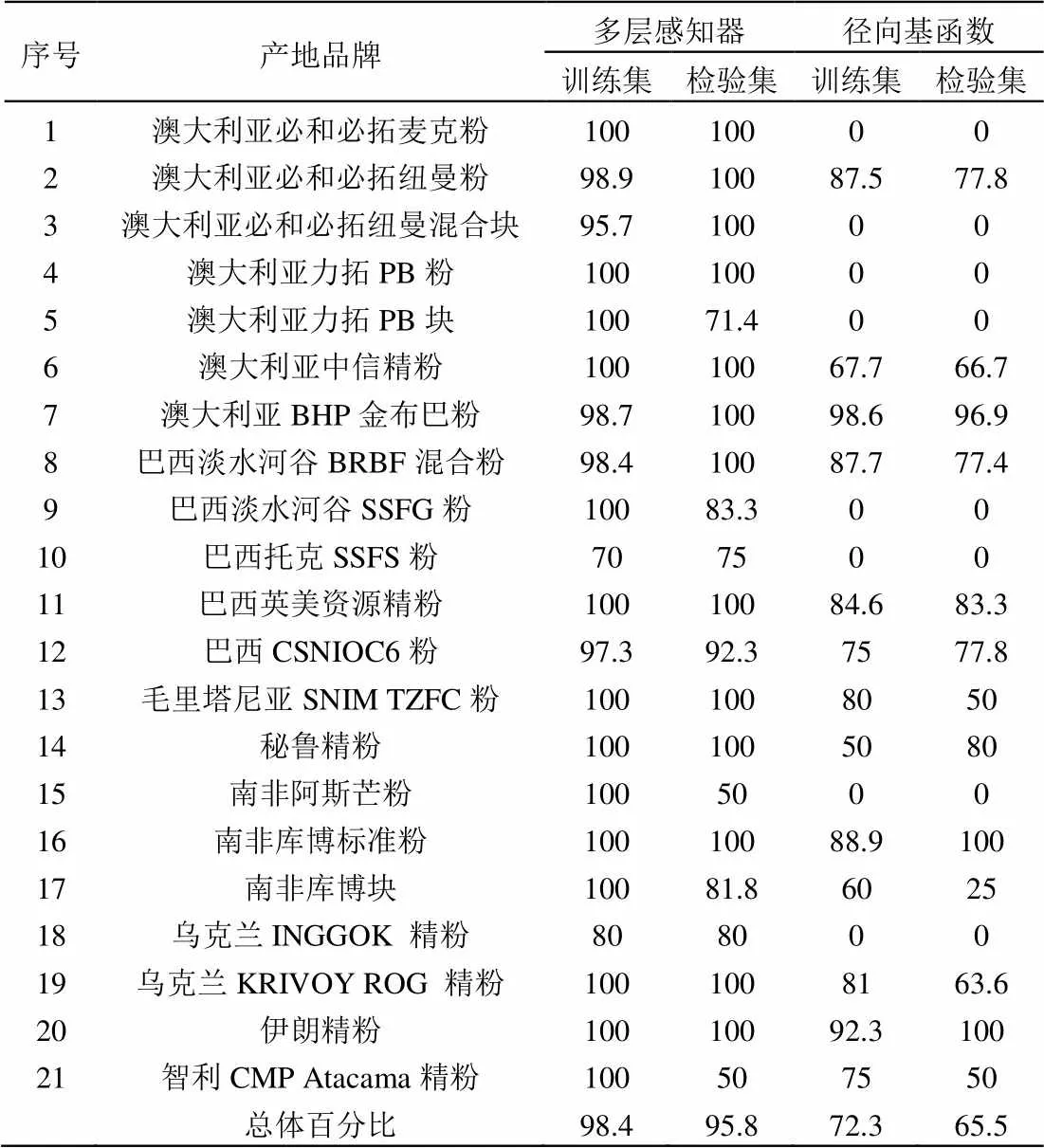
表9 兩種方法的正確百分比
3 結論
比較4種模型的結果,徑向基函數神經網絡模型中多個產品品牌無法正確識別,總體準確性僅為65.5%,無法在實際中獲得應用;一般判別、逐步判別、多層感知器神經網絡模型識別結果很好,三者的總體準確性高于90%,可以進行很好的預測和分類,在綜合信息成礦信息預測中具有特征提取的作用和好的泛化能力(推廣性),即有效逼近樣本蘊含的內在規律。模型樣品原產地及建模樣品數量與模型識別的準確率存在很大關系,隨著后續樣品收集數量增加,該模型數據庫還可繼續豐富,模型的穩定性將得到進一步的提升。
[1]武素茹,谷松海,宋義,等. 進口鐵礦產地鑒別模型的建立[J]. 計算機與應用化學,2014,31(12): 1543-1546.
[2]張博,閔紅,劉曙,等. X 射線熒光光譜結合判別分析識別進口鐵礦石產地及品牌[J]. 光譜學與光譜分析,2020,40(8): 2640-2646.
[3]劉倩,秦曄瓊,劉曙,等. X 射線熒光光譜結合 BP 神經網絡識別進口銅精礦產地[J]. 光譜學與光譜分析,2020,40(9): 2884-2890.
[4]紀雷,林雨霏,孫健,等. 我國進口鐵礦石有害元素含量代表值估計及整體特征分析[J]. 分析試驗室,2007,26(6): 58-61.
[5]孟海東,殷躍,孫家駒,等. BP神經網絡在礦產資源分類識別中的應用[J]. 西部探礦工程,2012,24(8): 137- 139,145.
[6]陰江寧,克炎,李楠,等. BP神經網絡在化探數據分類中的應用[J]. 地質通報,2010,29(10): 1564-1567.
[7]吳占福,馬旭平,李亞奎. 統計分析軟件SPSS介紹[J].河北北方學院學報(自然科學版),2006,56(6): 23-25.
Application of SPSS in Brand Recognition of Imported Iron Ore Origin
This paper introduces the method of establishing the brand recognition model of imported iron ore origin. The contents of primary and secondary elements in the collected imported iron ore samples were determined by conventional methods such as X-ray fluorescence spectrometry, infrared absorption spectrometry and emission spectrometry. A total of 17 elements including Al2O3, SiO2, Fe, K2O, Cr, CaO, MgO, V2O5, TiO2, MnO, Na2O, P, As, S, Ni, Zn, Pb were selected for content analysis. Based on a large number of test data, four algorithms in SPSS software are used to calculate the correlation degree between elements and origin brand, establish brand recognition models of different imported iron ore origin, and use test samples to evaluate the accuracy and reliability of different models. The test results show that discriminant analysis and multilayer perceptron neural network can recognize the origin and brand of iron ore. The established model can be applied to the origin brand identification of common imported iron ore, and will play a positive role in maintaining trade equity and ensuring ore quality and safety.
iron ore; neural network; discriminant analysis; origin; brand
TF52
A
1008-1151(2022)01-0005-07
2021-11-15
2020年防城港市技術研究與開發財政補助項目(防科AD20014029)。
陳永欣(1981-),男,中華人民共和國防城海關工程師,從事進口礦產品監管工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
