基于調整方向感知的中文命名實體識別
2022-03-31 08:18:40陳伯琪
江蘇師范大學學報(自然科學版) 2022年1期
陳伯琪, 陳 彬
(江蘇師范大學 數學與統計學院,江蘇 徐州 221116)
0 引言
命名實體識別(named entity recognition,NER)是自然語言處理的重要基礎任務,是信息提取、問答系統、句法分析、機器翻譯等自然語言處理任務的重要基礎工具.基于深度學習的命名實體識別方法,在一定程度上克服了傳統機器學習特征表達能力較弱和文本信息獲取能力欠缺的問題,并運用神經網絡的優勢提升了特征提取的準確度和模型的學習能力,達到了更優的識別效果.Collobert等[1]利用多層感知器(multilayer perceptron,MLP)和卷積神經網絡(convolutional neural networks,CNN)來避免使用特定的特征處理不同的序列標記任務,如詞性和NER等.循環神經網絡(recurrent neural network,RNN)有著很強的時序性,被廣泛應用于自然語言處理任務中.目前,雙向長短期記憶網絡(bidirectional long short-term memory,BiLSTM)[2]是應用最廣泛的RNN結構之一.由于BiLSTM在學習上下文表示方面的強大能力,大多數NER模型將其作為編碼器[3-5].
Transformer編碼器[6]采用全連接的自注意力結構對上下文進行建模,在語義特征提取、長距離特征捕獲和綜合特征提取等方面均優于RNN.由于Transformer具有更好的并行能力,因此被廣泛應用于機器翻譯、語言建模、情感分析和預訓練模型等自然語言處理任務中.但Transformer使用的正弦位置嵌入可以獲取距離信息,不能獲取方向信息.同時,在使用Transformer的過程中,距離信息會在一定程度上丟失.然而,方向信息和距離信息在命名實體識別任務中都很重要,一個實體是連續的字跨度,對距離信息和方向信息的獲取可以幫助某個字或者詞更好地識別它附近的字或者詞.為了使Transformer具有方向和距離感知能力,Yan 等[7]提出了一種改進相對位置編碼的方法,該方法使用更少的參數,性能更優.為了提高基于Transformer的模型在中文命名實體識別任務中的性能,本文在Yan等[7]提出的TENER模型的基礎上,結合方向感知和距離感知,提出一種基于調整函數動態調整方向感知的中文命名實體識別(Chinese named entity recognition based on adjusted direction-aware,C-ADA)模型,并進一步銳化注意力分布.通過與已有模型在MSRA[8]、Weibo[9]、Resume[10]3個中文NER數據集上對比, C-ADA模型效果更好.
1 相關模型
1.1 TENER模型
TENER模型[7]是基于Transformer編碼器結合條件隨機場構建的字符級和詞級特征的命名實體識別模型,它利用相對位置編碼,減少了參數數量,比基于BiLSTM的模型性能更好.通過改進注意力得分的計算方式,TENER模型可以區分不同的方向和距離,并結合方向感知、距離感知和非縮放的注意力,使得Transformer結構在NER任務上的性能大幅提升.
1.2 Transformer 編碼器架構
Transformer編碼器[6]由多個相同的基本層搭建而成,每一個基本層都由注意力層和前饋神經網絡層兩個子層組成,在兩個子層中使用一次殘差連接和標準化.將詞向量輸入到Transformer編碼器中,經過編碼器處理的結果輸入到相對應的解碼器中.Transformer是完全基于注意力機制的模型,編碼器結構中大量使用多頭注意力機制.縮放點積注意力是多頭注意力機制的核心,輸出公式為
Q,K,V=HWq,HWk,HWv,
其中:A(·)為注意力函數;s(·)為softmax函數;Q、K、V分別為查詢向量矩陣、鍵向量矩陣和值向量矩陣;矩陣H∈Rl×d,l為序列長度,d為輸入維度;Wq、Wk、Wv∈Rd×dk是3個可學習的矩陣;dk為超參數.
多頭注意力是Transformer模型中的重要組件.在不同語義場景下,字語義向量之間的融合是多種多樣的,因此,多頭注意力機制提出在獲取增強語義向量時采用不同的自注意力(self-attention)模塊,在參數量總體不變的情況下,關注輸入的不同部分,將查詢、鍵、值3個參數進行多次拆分,并將各組拆分參數映射到不同子空間中計算注意力權重,然后輸出多個向量的線性組合.多頭注意力機制采用多組Wq、Wk、Wv,經過多次并行計算,來提高注意力機制的性能,計算公式為
Qi,Ki,Vi=HWq,i,HWk,i,HWv,i,
hi=A(Qi,Ki,Vi),
Hmulti(H)=(h1,h2,…,hn)Wo,
其中:hi為第i頭注意力,i=1,2,…,n為(h1,h2,…,hn)的索引;Hmulti(·)為多頭注意力函數;Wo∈Rd×d為可學習參數.多頭注意力的輸出[6]由前饋神經網絡進行處理,公式為
NFF(x)=R(xW1+b1)W2+b2,
其中:NFF(·)為前饋神經網絡函數;R(·)為Relu函數;W1∈Rd×df,W2∈Rdf×d,b1∈Rdf,b2∈Rd,df為超參數.
1.3 位置嵌入
為了解決自注意力無法捕捉語言順序特征的問題,Vaswani等[6]提出使用不同頻率正弦函數產生的位置嵌入,第t個位置嵌入表示為

其中:t為目標索引,j為上下文標記索引.
2 C-ADA 模型
2.1 調整方向感知
在方向感知過程中,不同位置的sinx和cosx只能在[-1,1]上進行周期性波動.但在實際問題中,實體的方向信息并不是完全不變的周期性波動.本文提出利用調整函數對方向感知過程中的周期性波動進行動態調整,使方向感知上的波動程度發生變化.同時,使用銳化參數m進一步銳化注意力.
利用函數1-|tanhx|對方向感知進行動態調整,公式為
Q,K,V=HWq,HWdk,HWv,
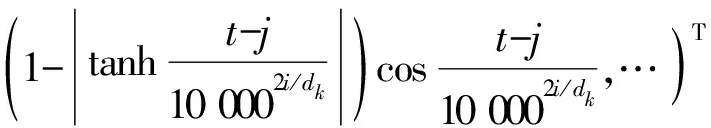
(1)
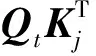
由于1-|tanhc0t|)sinc0t為奇函數,在偏移量為t時,前向相對位置編碼和后向相對位置編碼是相反的,因此Rt-j可以區分不同的方向和距離.調整函數1-|tanhc0t|,可使方向編碼隨著位置的改變產生波動幅度的變化.
性質1方向信息的集中性即尾部壓縮性.

證由于
f(x)=1-|tanhx|

則
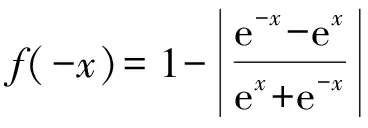
即f(x)為偶函數,且|f(x)|≤1=f(0).
當x∈(0,+∞)時,
f′(x)<0,
(2)
當x∈(-∞,0]時,
f′(x)>0,
(3)
故f(x)在x∈(0,+∞)上單調遞減,在x∈(-∞,0]上單調遞增,值域為(0,1].
記g(x)=f(x)sinx,由sinx為奇函數知g(x)為奇函數.由(2)、(3)及sinx的周期性知,當|x|→∞時,|g(x)|波動趨于0.f(x)、g(x)的圖像如圖1所示.調整函數f(x)使方向編碼的波動程度在正方向和負方向均為下降趨勢,同時,將方向編碼的尾部取值壓縮至接近0.當|x|=π時,g(x)的取值接近0.可見,模型獲取的絕大部分方向信息集中在(-π,π).

圖1 f(x)與g(x)的函數圖像Fig.1 Function graph of f(x) and g(x)
2.2 條件隨機場
考慮到標簽之間的依賴性,在序列建模層上使用條件隨機場(conditional random field,CRF).CRF是在給定隨機變量序列的前提下,輸出與輸入變量序列相關聯的一組隨機變量序列的條件概率模型.中文命名實體識別任務可以簡化為根據一組輸入隨機變量序列X={x1,x2,…,xm-1,xm}預測輸出隨機變量Y={y1,y2,…,ym-1,ym}的過程.條件隨機場公式[11]為
其中:F(Y,X)=(f1(Y,X),f2(Y,X),…,fK(Y,X))T,表示全局特征向量;w=(w1,w2,…,wK)T為權重向量.
3 實驗分析
3.1 標注策略與評價指標
命名實體識別又稱為序列標注任務,常用的標注策略有BIO、BMES、BIOES 等.本文中MSRA、Weibo、Resume 3個數據集都采用BIOES標注策略,其中:B標簽代表一個實體的開始,I標簽代表一個實體的內部,E標簽代表一個實體的結束,O標簽代表一個非實體,S標簽代表一個單獨的詞作為一個實體.評價模型的優劣采用精確率、召回率、F1得分表示[12],混淆矩陣如表1所示.

表1 混淆矩陣Tab.1 Confusion matrix
3.2 實驗環境及實驗參數
實驗訓練過程環境配置如表2所示.模型具體參數設置如表3所示.在實驗中,銳化參數m經過多次調整.可以看出,與MSRA和Weibo數據集相比,Resume數據集的銳化參數更小,即注意力銳化程度更高.

表2 環境配置Tab.2 Environment configuration
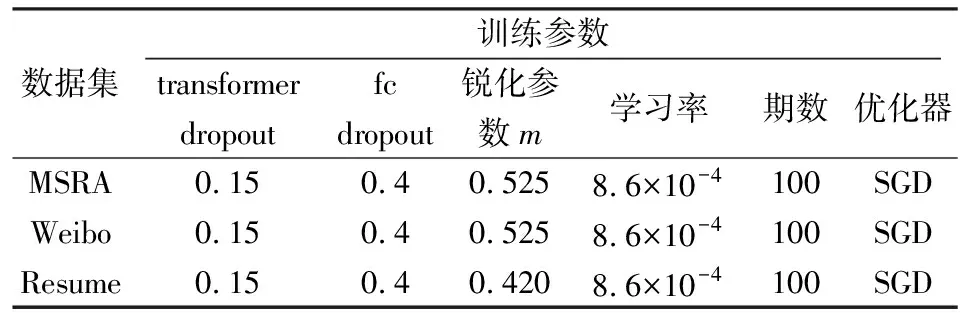
表3 模型參數Tab.3 Model parameters
3.3 模型結果對比

圖2 C-ADA模型與TENER模型在MSRA數據集上的精確率和召回率Fig.2 Precision and recall rates between C-ADA and TENER on MSRA

圖3 C-ADA模型與TENER模型在Weibo數據集上的精確率和召回率Fig.3 Precision and recall rates between C-ADA and TENER on Weibo
比較C-ADA模型與TENER模型在MSRA、Weibo和Resume 3個中文NER數據集上的訓練效果(圖2—圖4),可以看出,本文提出的C-ADA模型在3個中文數據集上的精準率和召回率都比TENER模型有了一定提升,且精確率的提升更為顯著.
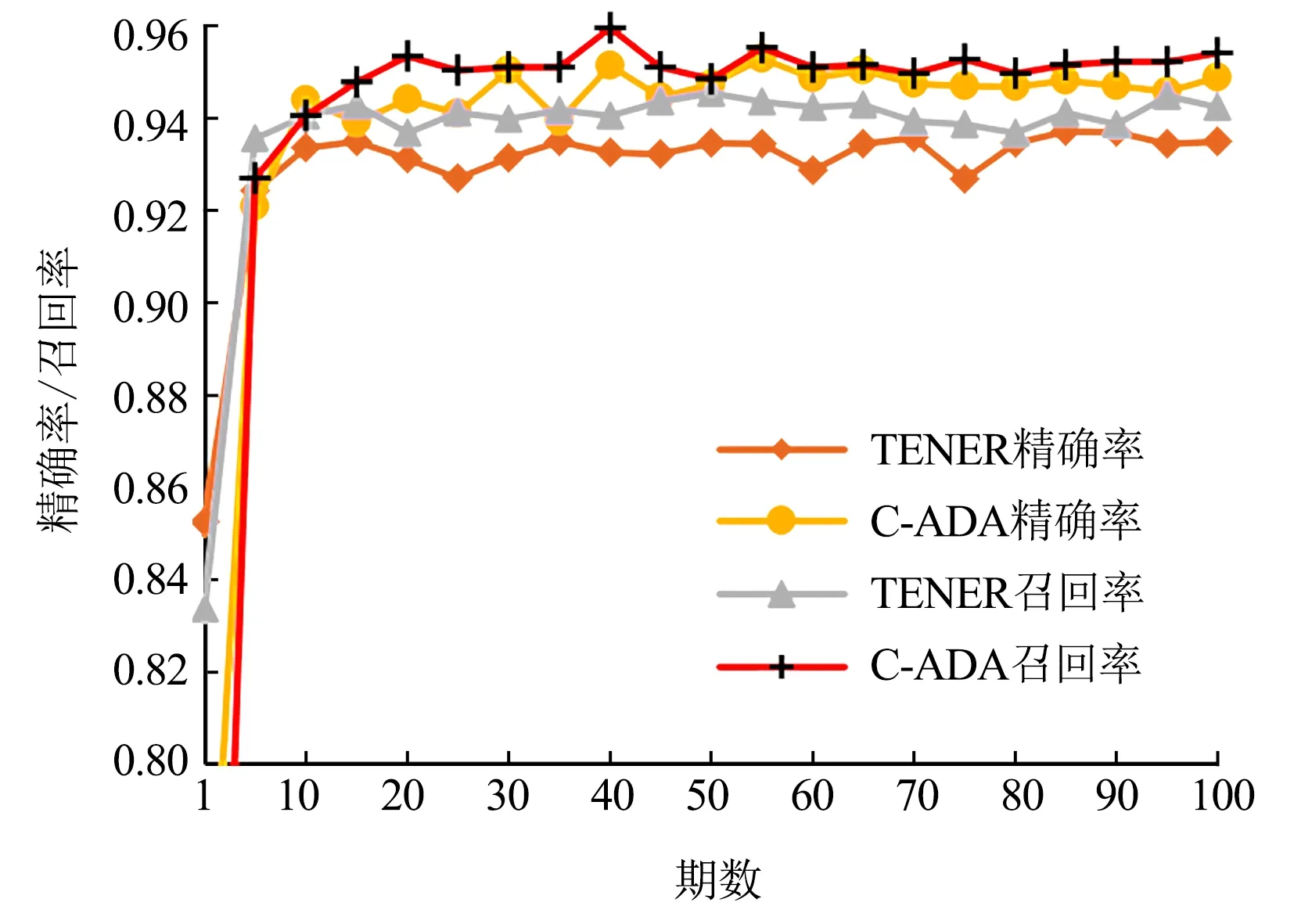
圖4 C-ADA模型與TENER模型在Resume數據集上的精確率和召回率Fig.4 Precision and recall rates between C-ADA and TENER on Resume
通過與BiLSTM,ID-CNN、Transformer、TENER 4類模型在3個中文NER數據集上進行對比(表4)發現,本文提出的C-ADA模型的F1得分均最高.其原因在于調整函數對方向感知過程中的周期性波動進行動態調整,使模型對于方向的感知更加敏感.

表4 各模型在測試集上的F1得分Tab.4 F1 score of each model on the test set
4 總結
本文在Yan 等[7]提出的TENER模型基礎上利用調整函數對方向感知進行了改進,通過調整函數使方向感知在不同的位置不僅保持了相對的波動程度,同時增加了整體上的變化趨勢,使方向感知更加敏感.在命名實體識別任務中,具有整體變化趨勢的方向感知能夠更好地捕捉位置不同和實體多樣性帶來的方向變化.另外,本文在實驗的基礎上,利用參數m使得注意力更加銳化.在Weibo、Resume、MSRA 3個中文NER數據集上的實驗結果表明,本文提出的C-ADA模型效果優于BiLSTM,ID-CNN、Transformer、TENER模型.不足之處在于,本文使用的銳化參數m對注意力的銳化作用僅在3個中文數據集上進行了驗證.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
計算機應用(2022年2期)2022-03-01 12:33:42
計算機應用(2022年1期)2022-02-26 06:57:42
計算機應用(2021年4期)2021-04-20 14:06:36
計算機應用(2021年3期)2021-03-18 13:44:48
計算機應用(2021年1期)2021-01-21 03:22:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
