行人屬性識別:基于元學習的概率集成方法
2022-04-02 02:55:46王文龍張譽馨吳曉富張索非
計算機技術與發(fā)展 2022年3期
王文龍,張 磊,張譽馨,吳曉富,張索非
(1.南京郵電大學 通信與信息工程學院,江蘇 南京 210003;
2.南京郵電大學 物聯網學院,江蘇 南京 210003)
0 引 言
行人屬性識別(pedestrian attribute recognition,PAR)的目的是在行人圖像中挖掘目標人物的屬性信息。傳統的行人屬性識別方法通常側重于從人工生成的特征、強大的分類器或屬性關系的角度來獲得更魯棒的特征。在過去的幾年里,深度學習在利用多層非線性變換進行自動特征提取方面取得了令人矚目的成績,特別是在計算機視覺、語音識別和自然語言處理等方面。基于這些突破,研究者提出了幾種基于深度學習的屬性識別算法,如ACN[1]、DeepMAR[2]。雖然行人屬性特征的提取由于卷積神經網絡的應用得到大幅的提升,但行人屬性識別的性能在實際應用中仍不能滿足需求。該任務的困難在于PAR中不同類別的屬性所屬的粒度不同,如發(fā)型、顏色、帽子、眼睛等信息只是局部圖像塊的低層屬性信息,而年齡、性別等信息卻是全局的高層語義信息。并且,在視角、光線等信息變化時,采樣到的圖像變化可能很大,但這些屬性信息卻不會改變。最近不少研究者試圖利用屬性間的空間關系和語義關系來進一步提高識別性能,所提出的方法可分為三個基本類別:
基于語義關系的方法:利用語義關系來輔助屬性識別。Wang等人[3]利用屬性間的依賴性和相關性提出了一個基于CNN-RNN的框架。Sudowe[1]提出一個整體的CNN模型來共同學習不同的屬性。然而,這些方法需要人工定義規(guī)則,如預測順序、屬性組等,在實際應用中很難確定。
基于注意力機制的方法:利用視覺注意機制來提高屬性識別。Liu等人[4]提出了一種多方向注意模型,用于行人多尺度注意特征的學習分析。雖然識別精度有所提高,但這些方法都是屬性不可知的,沒有考慮到屬性的具體信息。
基于局部特征提取的方法:利用行人的身體部位特征來提高屬性識別。Zhu等人[5]將整個圖像分割成15個Rigid塊,融合不同塊的特征。Yang等人[6]利用外部姿態(tài)估計模塊定位身體部位。
以上這些方法從語義關系、特征提取、注意力機制等角度來提升模型的性能。該文主要從集成學習的角度來提高行人屬性識別性能。不同于該領域中廣泛應用的多模型集成方案,該文從單個模型的屬性預測輸出概率入手,利用少量數據訓練元學習器的集成規(guī)則,最終通過概率集成的方式獲得性能上的提升。通過對比最新的行人屬性識別算法,如RDEM[7]、VAC[8]、ALM[9],PEM算法均能夠獲得可觀的性能提升。
1 文中算法
1.1 算法思想
整體的算法流程如圖1所示。該算法需要有監(jiān)督數據對元學習器進行訓練,因此將訓練數據分割為訓練集和驗證集。訓練集用于基本分類器的訓練,驗證集用于元學習器的訓練。實驗結果表明數據集的較佳分割比例為4∶1(見2.4)。
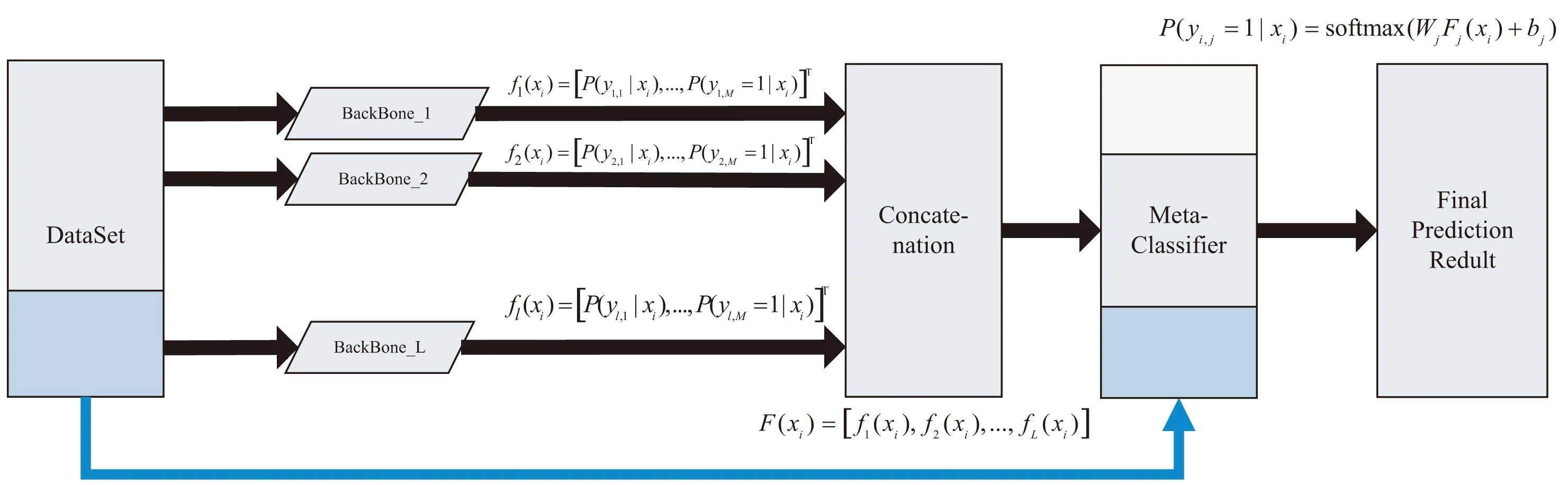
圖1 算法流程
PEM算法首先通過RDEM算法[7]的框架,用不同的模型結構得到L個基本分類器,然后將各個分類器的輸出概率進行拼接。F(xi)是基本分類器預測概率拼接的結果,它是一個L×M的向量,M代表屬性的個數。元學習器會對F(xi)中各個分類器的輸出概率賦予不同的權重和偏置,經過優(yōu)化器的調優(yōu)后得到最佳的參數,最后將該參數用于加權集成得到最終的預測概率。
1.2 分類器疊加
給定一個數據集:
D={(xi,yi),yi∈{0,1}M,i=1,2,…,N}
(1)
其中,yi表示第i張圖片的正確的標簽,而N,M分別表示訓練的圖像個數和屬性個數,xi表示第i個行人圖片。行人屬性識別是一個多標簽識別任務,對給定的行人圖片xi要求判斷屬性yi是否存在。在標簽向量y和預測向量yi中,對應位置的0或1代表了該屬性是否出現在行人圖片當中。
在對屬性進行預測時,將每個屬性都看作一個二分類的問題,那么其二元交叉熵損失函數可以用式(5)來表示,其中wj(yi)=eyi,j(1-rj)+(1-yi,j)rj是樣本的權重,用來緩解樣本不平衡分布帶來的問題[10-11]。rj表示第j個屬性的正樣本率。
給定L個基本分類器,其中對M個屬性進行預測的第l個分類器的預測概率表達式如下:
fl(xi)=[P(yi,1|xi),…,P(yi,M=1|xi)]T=
(2)
通過將每個屬性分類器的Softmax層的輸出堆疊為長度為M的列向量,最終的疊加概率特征可以表達為如下形式:
F(xi)=[f1(xi),f2(xi),…,fL(xi)]
(3)
1.3 元分類器
將fl(xi),l=1,2,…,L作為最終的概率特征向量,由元學習器(或集成學習器)將不同的預測結果進行擬合,得到最終的預測。該文提出的元分類器采用最簡單的單層全連接網絡,使用F(xi)作為輸入,通過一個全連接層、Softmax層輸出最終預測,也即:
P(yi,j=1|xi)=softmax(WjFj(xi)+bj)
j=1,2,…,M
(4)
其中,Wj和bj是權重和偏置。以上參數的獲得需要通過一些有標注的訓練數據進行訓練獲得,因此需要對訓練集進行分割。對于訓練集的分割,應當將其分割成為兩部分:一部分用于模型各自分類器的訓練,另一部分用于元分類器的訓練。
2 實 驗
2.1 數據集
實驗所使用的數據集來自于PRCV2020大型行人檢索競賽數據集RAP[12]的子集,RAP數據來源是從一個室內購物中心的高清晰度(1 280×720)監(jiān)控網絡中采集的。RAP數據集涵蓋了2 589個行人身份標簽。該數據集中關于行人屬性識別的數據共由68 071張圖片組成,其中42 085張用于訓練(訓練集+驗證集),25 986張用于測試。對于每個樣本都標注了72個細粒度屬性,例如性別發(fā)型、鞋子類型以及附屬物類型等,其中54個屬性用于本次競賽。54個屬性標簽大致可分為七大類,分別為:人物屬性、頭部、上衣、下衣、鞋子、附屬物、行為,具體如下:
(5)
·人物屬性:性別、年齡16、年齡30、年齡45、年齡60、體型微胖、體型標準、體型偏瘦、顧客、店員。
·頭部:光頭、長發(fā)、黑色頭發(fā)、戴帽、眼鏡。
·上衣:襯衣、毛衣、馬甲、T恤、棉服、夾克、西服、衛(wèi)衣、短袖、其他。
·下衣:長褲、裙子、短裙、連衣裙、牛仔褲、包腿褲。
·鞋子:皮鞋、運動鞋、靴子、布鞋、休閑鞋、其他。
·附屬物:雙肩包、單肩包、手提包、箱子、塑料袋、紙袋、購物車、其他。
·行為:打手機、交談、聚集、抱東西、推東西、拉拽東西、夾帶東西、拎東西、其他。
據統計,人的屬性數量在4到26之間,平均值為12.2。此外,大多數二元屬性類別中,RAP具有嚴重的不平衡分布。如表1所示,用正樣本占整個數據集的比例來衡量,正樣本率較少(小于10%)的屬性數量占到了總數量的60%,這使得開發(fā)高質量的識別算法成為一個具有挑戰(zhàn)性的問題。

表1 正樣本率分布
2.2 評測指標
對于行人屬性識別任務,將每個屬性看作一個二分類問題,并將識別結果分為以下四種情況:TP(True Positive),識別正確的正樣本;FP(False Positive),識別錯誤的負樣本;TN(True Negative),識別正確的負樣本;FN(False Negative),識別錯誤的正樣本。
評價屬性識別算法的第一個性能指標是平均準確度[13](mA)。考慮到屬性分布的不均衡性,對于每個屬性,mA分別計算正樣本和負樣本的分類精度,然后取它們的平均值作為屬性的結果。之后,mA取所有屬性的平均值作為最終結果。計算方式如下:
(6)
其中,L表示第L個屬性;Pi和Ni分別為當前屬性總的正、負樣本數。
評價屬性識別算法的第二個性能指標是F1值[14](F1-score),它是精準率和召回率的調和平均數,公式如下:
(7)
式中,Prec(Precision)是準確率,可以反映模型僅返回相關圖片的能力,Rec(Recall)是召回率,可以反映模型識別所有相關圖片的能力。其計算方式為:
(8)
(9)
從公式的計算方式可以看出,準確率和召回率會相互影響。一般情況下當準確率越高時,召回率就越低,反之亦然。
2.3 實驗結果
本實驗中,待集成的模型分類器的獲取來自于RDEM框架[7]。該方法用PyTorch實現,并進行了端到端的訓練。該文采用多個網絡(例如ResNet、OSNet等)作為主干提取行人圖像特征。將行人圖像調整為256×192,并對其采用隨機水平鏡像的處理。訓練優(yōu)化器采用隨機梯度下降(stochastic gradient descent,SGD),動量為0.9,權重衰減為0.000 5。初始學習率等于0.01,批次大小設置為64。訓練的總迭代次數為30次。
實驗主要集中于PRCV2020的競賽數據集RAP上,將其中的8 417張圖片固定為測試集。對于該方法,將剩余的33 668張圖片按比例拆分成訓練集和驗證集,拆分比例為4∶1(見2.4)。訓練集用于訓練多個模型的基本分類器,驗證集用于訓練元分類器。由于對比算法不包含元分類器,且輸出概率為單模型的輸出,因此將分割后的訓練集和驗證集全部用于訓練其所用模型的分類器。最終的實驗結果如表2所示。
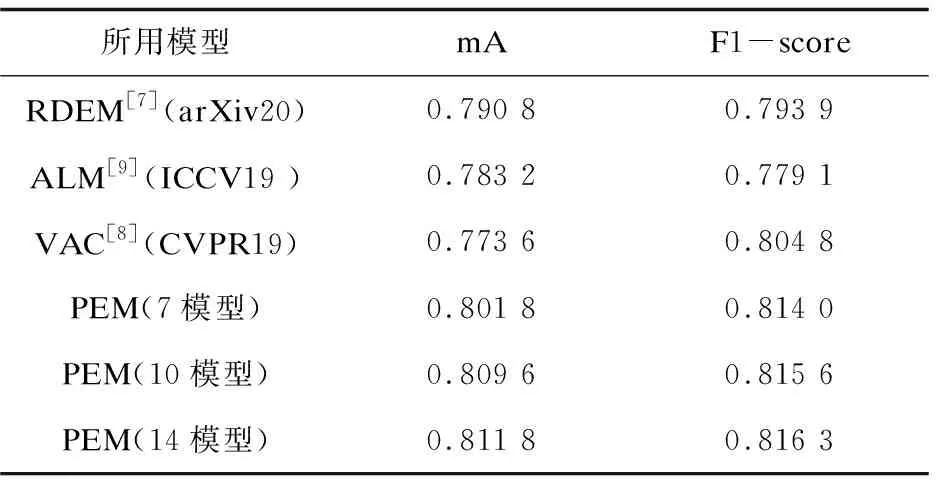
表2 實驗結果
實驗選取了一些主流的網絡結構,包括:ResNet[15]、OSNet[16]、EfficientNet[17]、DenseNet[18]、Inception[19]、Xception[20]等(包括其改進結構),以上模型的部分改進結構命名規(guī)則如下:SE(Squeeze-and-Excitation Networks)表示該網絡采用了SE模塊[21],該模塊能夠調整通道間的權重,并將重要特征強化,以取得更好的效果;ibn表示該網絡采用了Instance-batch Normalization(IBN)模塊[22],該模塊將Instance Normalization(IN)和Batch Normalization(BN)組合使用,提高了模型的范化能力。它有兩種結構:ibn-a和ibn-b,區(qū)別在于IN的位置有所不同。對于EfficientNet而言,其網絡配置參數為b0-b8(該文采用b0和b4的配置),不同配置的網絡,其寬度、深度、Dropout參數均不相同。對于ResNeXt網絡[23],它是ResNet網絡的升級,使用一種平行堆疊相同拓撲結構的blocks代替原來 ResNet 的三層卷積的block,能夠在不明顯增加參數量級的情況下提升模型的準確率。PEM算法各個配置所使用的模型如下:
·PEM(7模型):由ResNet50,SE-ResNet101-ibn-a,ResNet101-ibn-a,OSNet-x1.0,OSNet-ibn-x1.0,EfficientNet-b0,DenseNet161等模型組成。
·PEM(10模型):在7模型的基礎上新增了以下模型:DenseNet201, EfficientNet_b4, Inceptionv4。
·PEM(14模型):在10模型的基礎上新增了以下模型:ResNet152,SE-ResNet50,SE-ResNeXt50-32x4d,Xception。
從表2中可以看出,通過增加基本分類器的個數,其性能也在不斷的上升。對比RDEM算法,14個模型的堆疊使得其在mA評測中上升了1.17%,在F1值評測中上升了2.24%。對比ALM算法和VAC算法,該方法在mA上各自提升2.86%和3.82%,在F1值上各自提升了3.72%和1.15%。
2.4 對比實驗
2.4.1 數據集分割對比實驗
該算法需要對數據集進行分割,其分割比例不可避免地會對訓練過程產生影響。為了探究不同分割比例對于模型最終性能的影響,采取了三種不同的分割比例(訓練參數與PEM算法的實驗參數保持一致),并在7模型集成結果中進行了展示。表3給出了三次實驗的分割比例和數據集總圖片數的對應關系,測試圖片為固定的8 417張圖片。
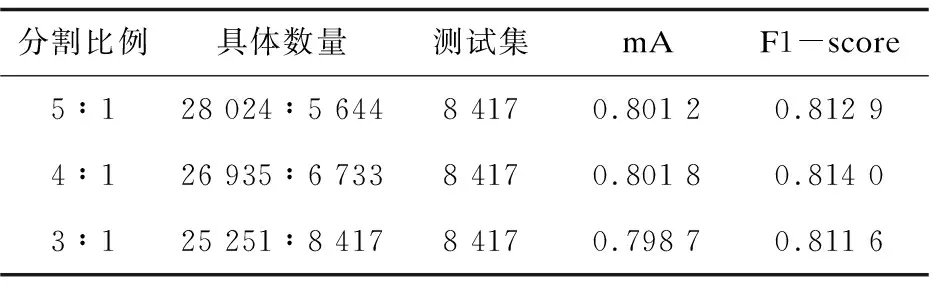
表3 數據集的分割與實驗結果
從表3的集成結果上來看,數據集的分割比例保持在4∶1是一個較優(yōu)的分割選擇,在此分割比例下,模型在最終的兩項評測中均優(yōu)于其他分割比例。
2.4.2 集成方式對比實驗
在行人屬性識別任務中,目前尚未有集成方法的提出。PEM算法作為基于元學習的概率加權集成算法,其實質是一個非等概加權的過程,另一種容易想到的加權方式為等概加權集成,為了探究兩種方式在集成性能之間的不同,對兩種方式分別進行了實驗。
在等概加權集成(equal weight ensemble,EWE)實驗中,將集成方式更改為等概加權方式。實驗中,PEM算法與EWE算法所使用的基本分類器相同,在得到最終預測結果時,PEM算法將多個基本分類器預測結果進行非等概加權,加權參數則是利用部分訓練集訓練得到;EWE算法則直接將基本分類器預測結果相加后平均。注意,為了保證公平對比,等概加權集成實驗的訓練數據為分割后的訓練集加驗證集。最終其實驗結果如表4所示。
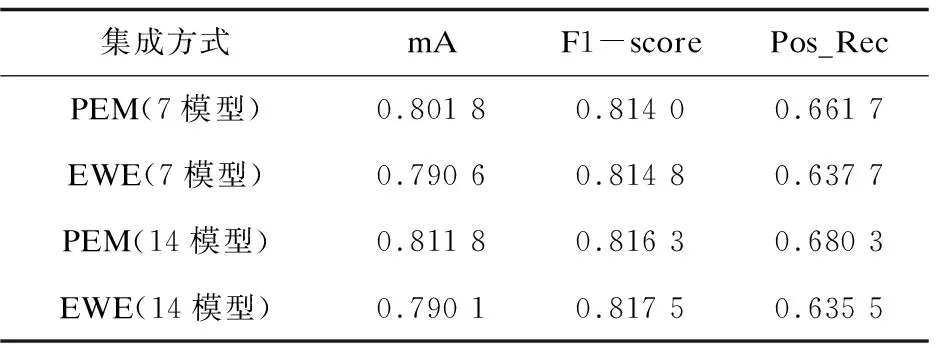
表4 集成方式對比結果
通過表4的結果可以看出,EWE方法在mA評測中大幅落后于PEM算法,在F1值的評測領先PEM算法。為了探究該現象產生的原因,又對正樣本召回率(Pos_Rec)進行了測試,結果表明PEM算法具有更好的正樣本識別能力。
從表4中可知,在14模型的集成實驗中,EWE算法在正樣本召回率評測中落后PEM算法約6.59%,根據mA的計算公式不難得出如下結論:EWE算法相對于PEM算法,無法更加有效地辨別正樣本,從而導致mA評測始終無法提升。由于RAP數據集具有嚴重的不平衡分布(正樣本率過低),即使出現模型預測全部為負樣本的情況,其總體準確率依舊很高,而正樣本識別能力的增強雖然會提高召回率(Rec),但由于正樣本數量過少,其提升對F1值評測貢獻有限,進而使得EWE算法在F1值評測上略高于PEM算法。
綜上所述,PEM算法在保證F1值評測的情況下,大幅提升了對正樣本的識別能力,克服了EWE算法無法提升mA評測的困難。
3 結束語
該文提出了一種行人屬性識別的概率集成算法(PEM),通過元學習器對多個模型的輸出概率進行擬合,最終在行人屬性識別數據集RAP上獲得了更好的行人屬性預測結果。在此基礎上,該文進一步對數據集分割比例、模型數量對算法性能的影響進行了研究,實驗結果表明:對于RAP數據集而言,數據集分割比例在4∶1時較為合適;PEM算法隨著集成模型的有效個數增多性能得到穩(wěn)步提升,表現出優(yōu)異的模型集成能力。最終該算法在PRCV2020大規(guī)模行人檢索競賽行人屬性識別任務中獲得第三名(具體見網址:https://lsprc.github.io/leaderboard.html)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
