基于改進SSA-BP神經網絡的復烤水分和溫度預測
2022-04-06 05:14:20王浩陳婷陳興侯陳明高興宇馬顯滔范振宇
農業與技術 2022年6期
王浩陳婷陳興侯陳明高興宇馬顯滔范振宇
(1.昆明理工大學機電工程學院,云南 昆明 650504;2.云南煙葉復烤有限責任公司麒麟復烤廠,云南 曲靖 655000)
引言
打葉復烤是初烤后的再加工過程,煙葉經過復烤,理化性質進一步發生變化,內在品質提高,有利于長期貯存和適應卷煙工業的使用需要。所以復烤作為卷煙加工中必不可少的環節,其技術的提升對煙葉加工有著重要意義。隨著技術的不斷發展,復烤生產線利用模糊控制、電控系統、先進控制算法和多策略復合控制等技術實現了生產線加工的自動化,如今復烤企業要求提高,自動控制也正向著智慧控制的方向發展。其中一個重要問題就是加工一致性問題,即在傳統加工中由于人工經驗不同,導致復烤設備設置的加工參數不一樣,使得成品煙葉水分和溫度不同,從而影響煙葉品質,造成品吸感覺不同。基于此,許多學者進行了研究。
有學者從化學成分方面入手,分析煙葉化學成分,從而得出應該采用的工藝參數。馬亞萍[1]等研究了復烤對四川涼山地區煙葉多酚含量的影響,得出煙葉香氣感官質量最優的打葉復烤參數:一潤出口溫度為60℃、復烤一區溫度為50℃、復烤二區溫度為79℃、復烤三區溫度為67℃、復烤四區溫度為70℃、醇化時間12個月;胡靜宜[2]等研究了復烤后不同尺寸煙葉化學成分差異;李慶祥[3]等研究了不同工序對煙葉糖堿比的影響。也有學者通過直接實驗的方法,明確參數設置依據。白萬明[4]通過單因素實驗,對加料比例、閥門開度等進行實驗,確定了料機內的蒸汽閥門開度40%和60%較為合適。朱貝貝等[5]利用均勻設計方法,經過試驗分別得出了上、中、下部煙感官質量最高時的干燥區溫度。還有學者從煙葉物理特性出發,研究均質化加工和物理特性關系。王戈[6]引入顏色特性和光譜特性作為調控因子,分析了不同調控模式下復烤的均質化效果。
總的來說,這些研究雖然從不同角度都促進了復烤技術的提升,但是都存在一些不足之處。其都是針對復烤的某個環節,是從局部而不是整體考慮技術的提升;都需要進行實驗,對復烤企業有負擔且不方便,甚至有的是針對特定產地煙葉,因此不具有普適性和推廣性;最重要的是,并沒有直接給出參數和質量指標之間的關系。綜上所述,將參數設置依據轉化為具有普適性并且可以量化的標準依然是一個亟待解決的問題。
建立預測模型反映輸入輸出關系,可以在復烤之前預測結果,并且不必專門實驗,以平常加工中得到的數據即可分析,能較為直觀地為參數設置提供可靠依據。復烤中存在許多非線性問題,且數據之間沒有明確數學關系,運用神經網絡可以較好地解決該問題。
人工神經網絡無需知道輸入和輸出的數學方程,通過訓練即可得到期望的輸出。其中BP神經網絡是應用最廣泛的神經網絡之一,其具有優良的多維函數映射和非線性映射能力,適合運用到尋找復烤參數的輸入數據與輸出數據的映射關系。基于此,本文提出用改進的麻雀搜索算法優化初始權重和閾值,建立BP神經網絡預測模型,找到復烤輸入參數和輸出結果的映射關系,為輸入參數設置提供依據。最后以麒麟復烤廠某個批次的加工數據作為研究對象,將預測模型運用到其中,驗證效果。
1 工藝分析
復烤技術由國外傳入國內,20世紀60年代開始掛桿復烤轉變為打葉復烤,如今隨著技術和工藝的不斷發展,已經逐步實現全面機械化和自動化加工。復烤是一個復雜的過程,涉及多種物理和化學變化,現簡要分析復烤的部分工藝階段,并選擇了研究的工藝參數和控制指標。
1.1 流程分析
復烤車間流水線可粗略分為潤葉、風分、干燥、冷卻和回潮5個階段,流程如圖1所示。其中,從倉庫到風力除雜等步驟為預備階段,煙葉從煙筐中轉移到鋪葉臺,然后經過人工篩選將煙葉中的非煙物質初步去除,接著機器把大片煙葉切斷,再通過機器二次風力除雜,流量稱可以檢測流水線上煙葉的重量,保證加工時煙葉的量在機器承受范圍內。預備階段處理是為了后續更好的加工。
從打葉風分開始,為復烤主要階段。打葉風分主要涉及的是煙葉物理形態變化(煙葉葉片和梗的分離),就不作為分析對象。復烤廠現在逐步采用“直接復烤”技術,即煙葉在干燥段被加工到指定水分含量和溫度,經過冷卻就符合要求,不用回潮,因此減少了回潮段的蒸汽使用量,大幅度節約成本,所以回潮段也不作為分析對象。綜上,選擇潤葉、干燥以及冷卻3個階段數據建立預測模型。
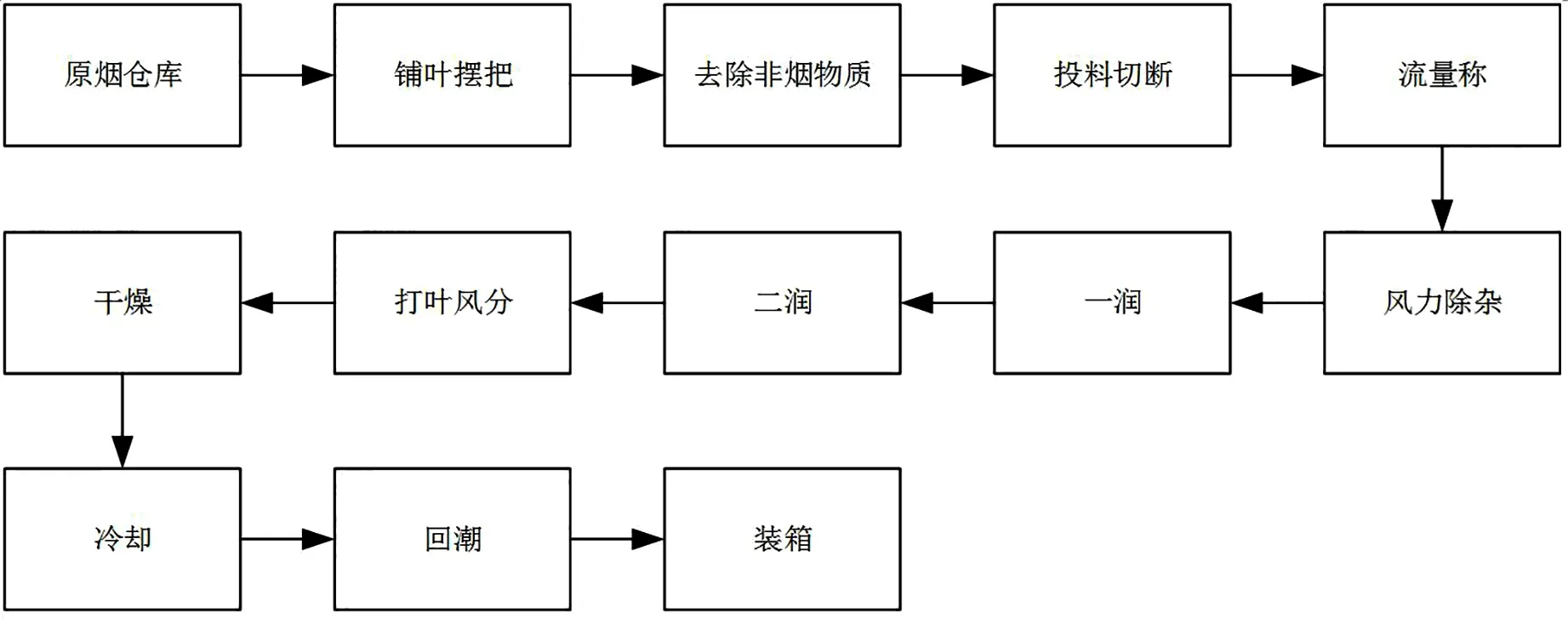
圖1 復烤工藝流程
1.2 材料選擇
煙葉材料選自麒麟復烤廠2020年某個批次加工數據,選取經過工業分級后的普洱(墨江)C3F單打煙葉,數據由加工時復烤設備記錄,真實可靠。
1.3 控制指標
復烤加工時,每個階段開始和結束都會測量煙葉的含水量和溫度,這2項指標在復烤時至關重要[12]。水分過大時,不利于煙葉的儲存,容易霉變;水分過低,則會增加煙葉脆性,導致碎煙率上升、大中片率降低等一系列問題。溫度不僅會影響煙葉水分,還與煙葉化學成分(如pH值[13]、煙堿值[14]等)變化密切相關,而煙葉化學成分直接決定了其內在品質。所以將出口溫度和水分這2項數據作為模型的控制指標,復烤廠對其要求如表1所示。因為要對整個復烤環節進行研究,探究每個階段的參數對于最后成品的含水率和溫度影響,所以中間過程就不予考慮,只將最后階段的葉片含水率和溫度作為模型的期望輸出。
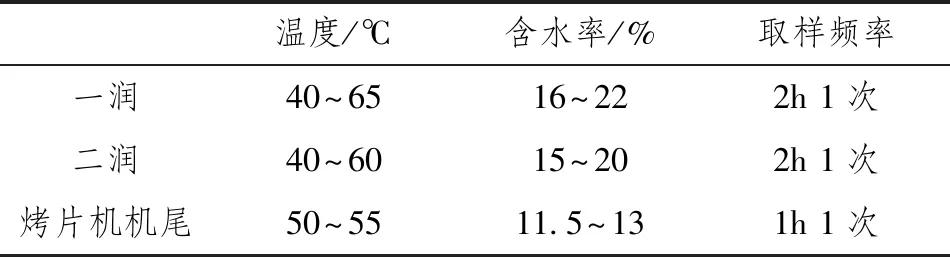
表1 質量要求
1.4 工藝參數選擇
從流程分析可確定研究階段為潤葉、干燥和冷卻,根據每個階段各特點和復烤廠實際需求選擇特征輸入,即選擇流量稱實際值、一潤熱風溫度、一潤回風溫度、一潤散熱蒸汽壓力、二潤散熱蒸汽壓力、二潤熱風溫度、二潤回風溫度、烤片機一區加水量、烤片機二區加水量、烤片機三區加水量、冷卻區溫度、冷卻區水分、干燥一區溫度、干燥二區溫度、干燥三區溫度、烤片機入口溫度、烤片機入口水分17個作為工藝參數。
需要特別說明的是,烤片機是加工的最后階段,入口的水分和溫度與出口水分和溫度密切相關,所以烤片機入口溫度和水分也作為輸入變量;工藝參數太多,不好一一列舉,故只展示部分,部分參數指標如表2所示。
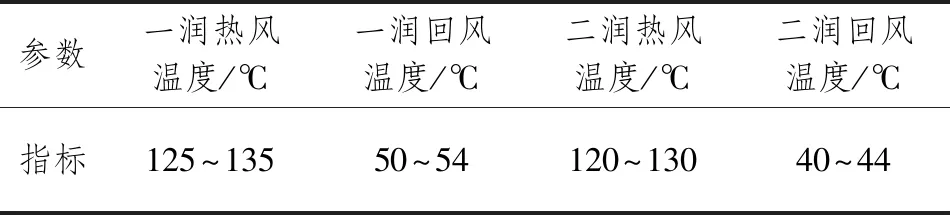
表2 部分工藝參數指標
2 模型建立
人工神經網絡通常也被稱為平行分布式處理模型,具有高度自適應性和容錯性,并且其優越的非線性模擬能力也很突出,使得在預測、控制等方面有很多應用。復烤環節工藝參數眾多,與控制指標之間沒有明確數學模型,建立神經網絡模型能有效根據輸入預測輸出。
2.1 神經網絡原理
人工神經網絡是一種旨在模仿人腦結構及其功能的由多個非常簡單的處理單元彼此按某種方式相互連接而形成的計算機系統,BP神經網絡亦是如此,其學習過程由信號的正向傳播與誤差的反向傳播2個過程組成。正向傳播時,輸入樣本從輸入層傳入,經隱層逐層處理后,傳向輸出層。若輸出層的實際輸出與期望輸出不符,則轉向誤差的反向傳播階段。誤差的反向傳播是將輸出誤差以某種形式通過隱層向輸入層逐層反傳,并將誤差分攤給各層的所有單元,從而獲得各層單元的誤差信號,此誤差信號即作為修正各單元權值的依據[7-14]。BP網絡由輸入層﹑輸出層和隱層組成,結構如圖2所示。
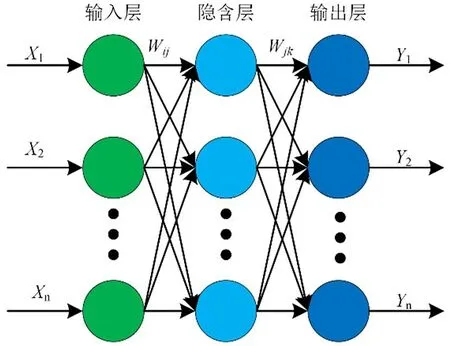
圖2 BP神經網絡結構
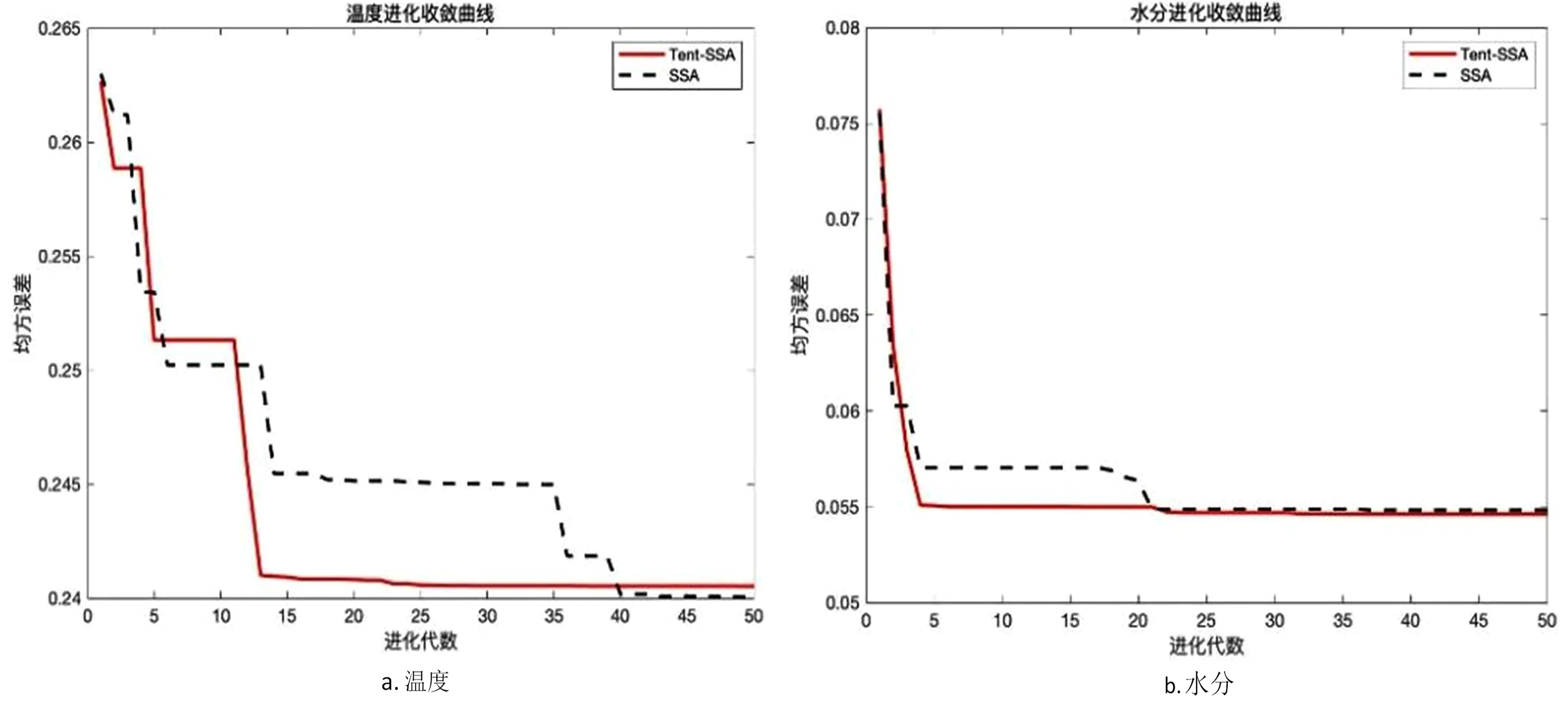
假設輸入層的節點個數為n,隱含層的節點個數為l,輸出層的節點個數為m。輸入層到隱含層的權重為wij,隱含層到輸出層的權重為wjk,輸入層到隱含層的偏置為aj,隱含層到輸出層的偏置為bk。學習速率為η,激勵函數為g(x)。隱含層的輸出Hj:
(1)
輸出層的輸出:
(2)
令期望Yk為期望輸出,記ek=Yk-Ok,網絡總誤差:
(3)
其中,i=1…n,j=1…l,k=1…m。權值更新公式:
(4)
2.2 訓練網絡
將總樣本數中的3/4數據作為訓練集,1/4為測試集。以工藝參數作為特征輸入,以控制指標作為期望輸出。設置學習速率為0.01,訓練最小誤差為0.0001,迭代次數為1000次。
隱含層節點數根據經驗公式(5)確定:
(5)
式中,h為隱含層節點數;r和e分別為輸入層和輸出層節點數;s為1~10常數。根據經驗公式(5)計算得隱含節點最大、最小值,然后通過試驗,求每一個節點數下訓練集均方誤差,取均方誤差最小的隱含節點數作為神經網絡隱含節點數。
訓練步驟如下。Step1:初始化網絡的權值和閾值;Step2:導入訓練樣本;Step3:前向傳播計算;Step4:誤差反向傳播計算并更新權值;Step5:迭代,用新的樣本進行步驟3和4,直至滿足停止準則。
流程如圖3所示。
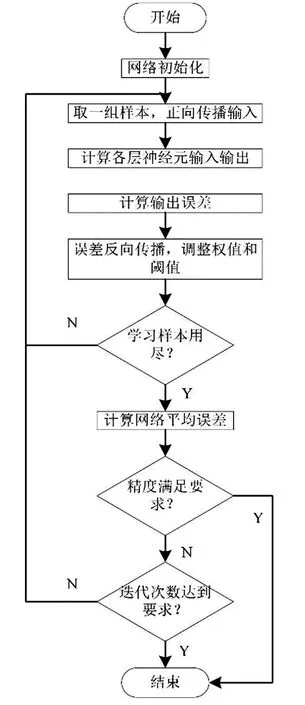
圖3 神經網絡訓練流程
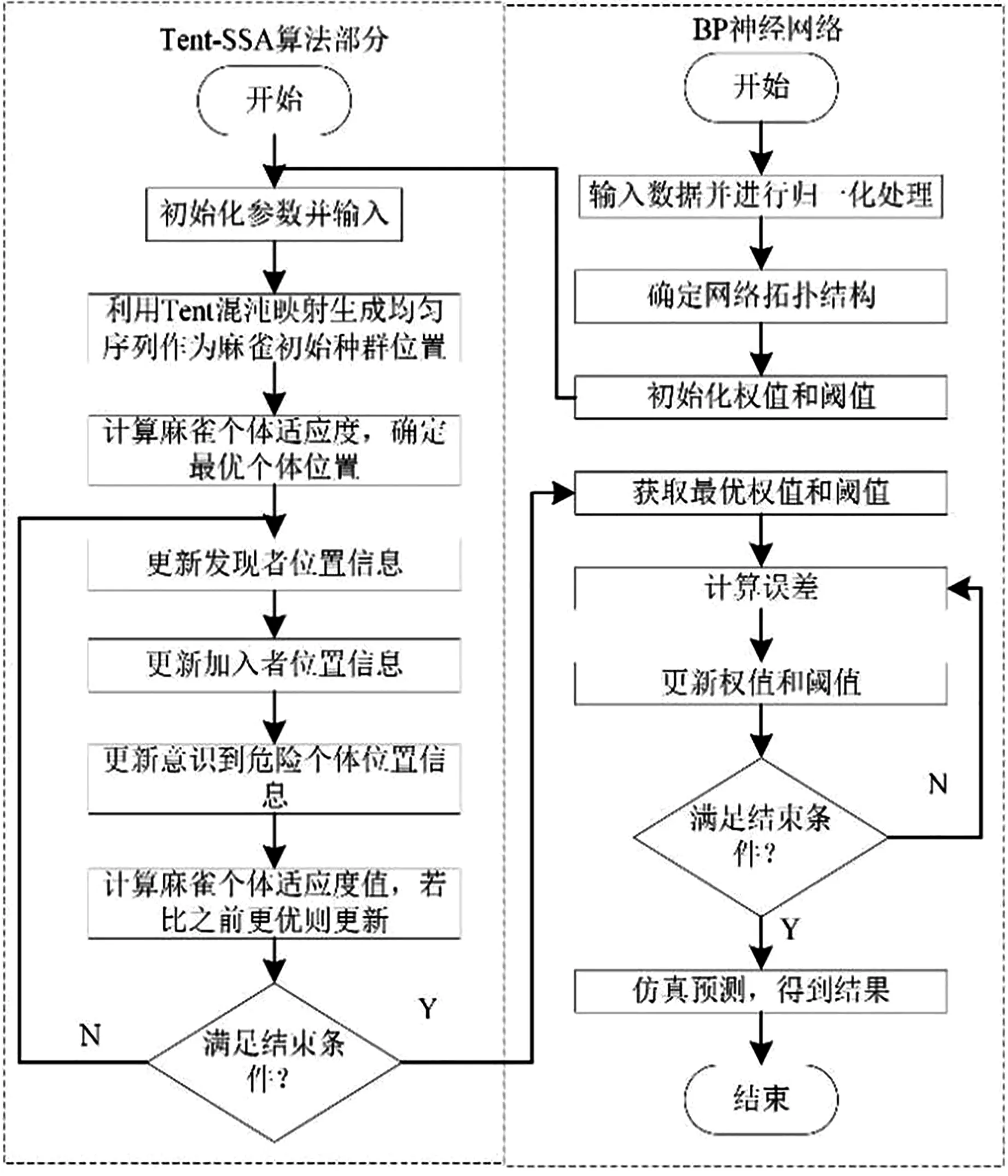
3 優化算法
麻雀搜索算法(Sparrow Search Algorithm,SSA)[15]是一種新型的群智能優化算法,主要是受麻雀的覓食行為和反捕食行為的啟發。麻雀種群在覓食過程中分為發現者與加入者2部分,分別負責提供種群覓食的方向以及追隨并獲取食物。當麻雀種群意識到危險時,則會發生反捕食行為并更新種群位置。
3.1 算法原理
麻雀搜索算法具有良好的局部尋優能力和穩定性,其實現原理如下。初始由n只麻雀組成的種群表示形式:
(6)
式中,d表示待優化問題變量的維數;n為麻雀的數量。則所有麻雀的適應度值表示形式:
(7)
式中,f表示適應度值。在SSA中,具有較好適應度值的發現者在搜索過程中會優先獲取食物。發現者的位置更新描述如下:
(8)
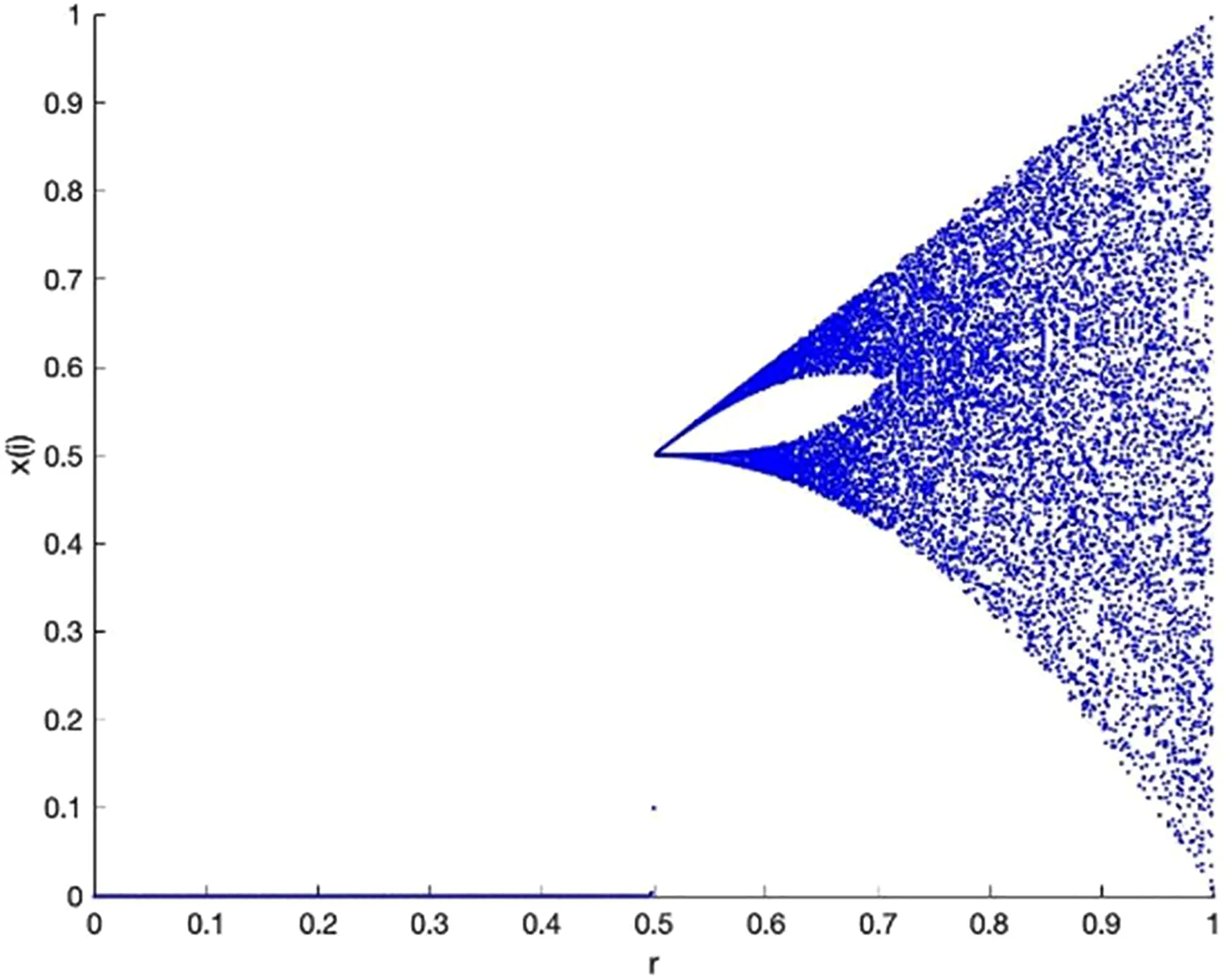
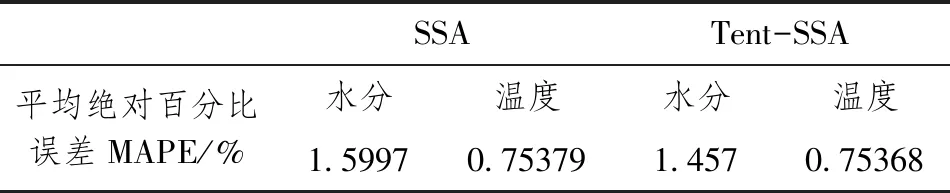
式中,t代表當前迭代數;j=1,2,3,…,d;itemmax是一個常數,表示最大的迭代次數;Xi,j表示第i個麻雀在第j維中的位置信息;α∈(0,1]是一個隨機數;R2(R2∈[0,1])和ST(ST∈[0.5,1])分別表示預警值和安全值;Q是服從正態分布的隨機數;L表示一個1×d的矩陣,其中該矩陣內每個元素全部為1。當R2 (9) 式中,XP是目前發現者所占據的最優位置;Xworst表示當前全局最差的位置;A表示一個1×d的矩陣,其中每個元素隨機賦值為1或-1,A+=AT(AAT)-1。當i>n/2時,表明適應度值較低的第i個加入者沒有獲得食物,處于十分饑餓的狀態,此時需要飛往其它地方覓食,以獲得更多的能量。反捕食行為,更新麻雀種群的位置如下: (10) 式中,Xbest是當前的全局最優位置,也是十分安全的;β作為步長控制參數,是服從均值為0,方差為1的正態分布的隨機數;K∈[-1,1]是一個隨機數,表示麻雀移動方向同時也是步長控制;fi是當前麻雀個體適應度;fg和fw是當前全局最佳和最差適應度;ε是常數,避免分母為零;當fi>fg表示此時的麻雀正處于種群的邊緣,極其容易受到捕食者的攻擊;fi=fg時,表明處于種群中間的麻雀意識到了危險,需要靠近其它麻雀以盡量減少其被捕食的風險。 算法步驟如下。Step1:初始化種群、迭代次數、初始化捕食者以及加入者比列;Step2:計算適應度值并且排序;Step3:利用式(8)更發現者者位置;Step4:利用式(9)更新加入者位置;Step5:利用式(10)更新警戒者位置;Step6:計算適應度值并更新麻雀位置;Step7:是否滿足停止條件,滿足則退出,輸出結果;否則,重復執行Step2~6。 從上述可知,麻雀搜索算法的初始種群位置是隨機的,這種方式生成的種群多樣性較差,可能導致算法陷入局部最優解,影響收斂速度和精度[16,17]。混沌是一種確定的系統中出現的無規則的運動,將其引入算法中,能較好解決該問題。 本文采用Tent混沌映射函數,其具有分布均勻、不可重復、不確定性和遍歷性等特點。Tent映射混沌分岔圖如圖4所示。當系統的參數不斷連續變化時,每跨過一點復雜程度都會成倍增加,直到一點系統突然變得不規律,即系統跨入混沌。此時將Tent映射生成的數據作為初始麻雀種群的位置信息既能保持多樣性,從而避免局部最優解,也能提高收斂速度和全局搜索能力[18,19]。 圖4 分岔圖 3.2.1 Tent混沌序列 單梁[20]等研究表明,Tent映射可以作為產生優化算法的混沌序列,并且其遍歷均勻性和收斂速度優于Logistic映射,其表達式: (11) 經過貝努利位移變換后: zi+1=(2zi)mod1 (12) (13) 相應的貝努利位移變換式為: (14) 式中,NT為混沌序列內的粒子個數;rand(0,1)為[0,1]之間的隨機數。 3.2.2 改進流程 改進的步驟如下。Step1:初始化麻雀搜索算法的參數,包括種群數量、預警值、安全值等;Step2:利用Tent混沌映射函數生成均勻分布于整個解空間中的混沌序列,即種群初始位置;Step3:計算每只麻雀的適應度值,確定解空間中適應度值最優和最差的麻雀個體的位置;Step4:確定麻雀種群中發現者的數量,根據公式(8)計算其更新過后的位置;Step5:確定麻雀種群中加入者的數量,根據公式(9)計算其更新過后的位置;Step6:確定麻雀種群中意識到危險的個體數量,根據公式(10)計算其更新過后的位置;Step7:計算每只麻雀的適應度值,與之前的適應度值進行比較,若新的適應度值更優則更新;Step8:如果達到算法的最大迭代次數,則輸出全局適應度值最優的麻雀的位置信息;否則轉到第4步繼續執行。 在BP神經網絡中,初始權值和閾值是在一個固定范圍內隨機產生的,初始權值的選擇對于局部極小點的防止和網絡收斂速度的提高均有一定程度的影響,如果初始權值范圍選擇不當,學習過程一開始就可能進入“假飽和”現象,甚至進入局部極小點,網絡根本不收斂。本文采用改進的麻雀搜索算法就是通過計算得到最優的初始權值與閾值,提高BP神經網絡的收斂速度和精度,以達到期望的效果,優化流程如5所示。 圖5 優化流程 本文的實驗數據來自麒麟復烤廠,經過篩選共得到480組數據,前360組作為訓練集,后120組作為測試集。17個工藝參數作為神經網絡的輸入,水分和溫度作為輸出。 均方誤差是反映預測量和被預測量之間差異的一種度量,其越小說明預測效果越好,計算公式: (15) 表3 試驗結果 為了證明所提算法的優越性,還使用了粒子群算法(Particle SwarmOptimization,PSO)、遺傳算法(Genetic Algorithm,GA)進行優化,最后對比結果,為了保證公平,同一參數設置相同,而關鍵參數設置如表4所示。 表4 對比算法參數選擇 設置好參數后,將數據導入到標準BP模型、Tent-SSA模型、GA-BP模型和PSO-BP模型中,進行精度和穩定性分析。 4.2.1 改進前后對比 圖4為SSA-BP模型和Tent-SSA-BP的進化曲線圖。從圖中可以看到,使用Tent混沌映射產生大量的初始原子,從中選出適應度最佳的若干個原子作為初始種群,從而改進的SSA算法比改進前的SSA算法收斂速度加快。 圖6 收斂曲線對比圖 平均絕對誤差百分比描述的是模型真實值和預測值之間的誤差百分比,計算公式: (16) 表5 精度對比 4.2.2 算法對比 為了突出算法的優勢,與其它算法優化結果進行對比,表6為對比結果。由表6可知,水分預測值的均方誤差小于溫度預測值,但是平均絕對誤差百分比卻大于溫度,說明水分預測值比溫度預測值離散程度更小,但是溫度的預測比水分更精確;在水分的預測上,改進后的麻雀搜索算法的均方誤差和平均絕對誤差百分比都有明顯減小,并且相比其它算法這2項數據都更小,所以精度更高;對于溫度的預測,雖然對比遺傳算法和粒子群算法提升效果并不明顯,但是對比優化前,精度是有明顯提升。 由于數據較多不方便觀察,就選取部分數據作圖進行對比,預測值和真實對比以及誤差對比如圖7、圖8所示。從圖中可以看出,對比其它方法,無論是在水分還是在溫度方面,改進后的SSA-BP模型誤差波動性更小更加接近期望值,性能更好。 圖7 預測值和真實值對比 圖8 誤差對比 表6 不同優化方法的結果比較 本文針對煙葉復烤階段工藝參數設置問題,分析了現階段研究的情況與不足,提出了運用BP神經網絡預測水分和溫度為參數設置提供依據。運用麻雀搜索算法對BP神經網絡的初始權值和閾值進行優化,提升了BP神經網絡的性能;并引入了Tent混沌映射產生混沌序列,對麻雀搜索算法的初始種群位置進行了優化,對比算法改進前既能保持多樣性,從而避免局部最優解,也能提高收斂速度和全局搜索能力。同時,還與遺傳算法和粒子群算法優化效果進行了對比,結果顯示所提算法的預測精度和穩定性都更好。綜上所述,本文提出的基于Tent混沌映射改進的SSA-BP神經網絡算法預測效果更好。3.2 改進策略
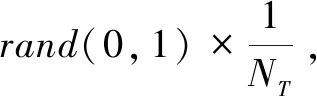
3.3 優化BP神經網絡
4 結果分析與算法對比
4.1 模型參數選擇
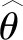


4.2 結果分析
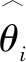
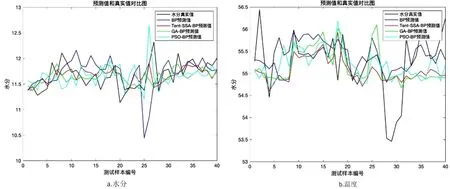
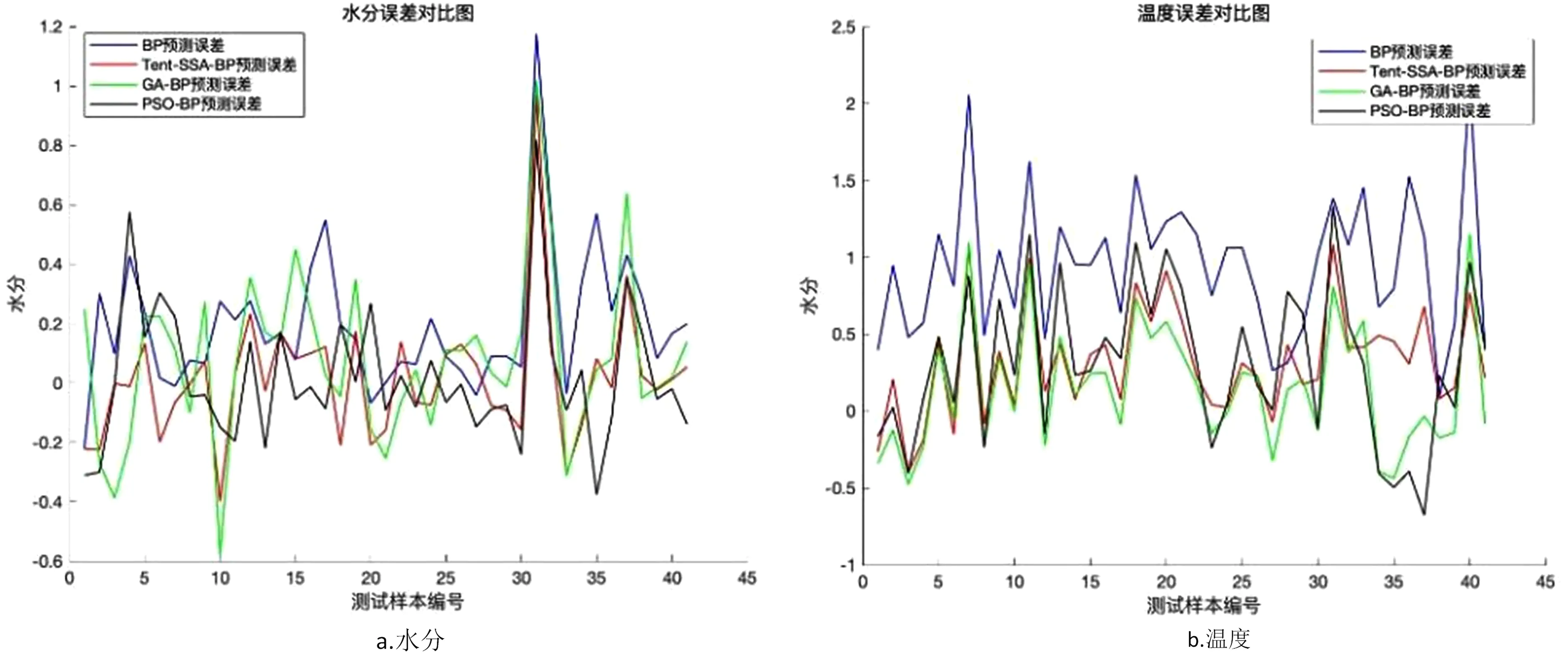

5 結論
