
密度峰值聚類算法在管廊大數據挖掘中應用
2022-04-09 19:21:21馬福軍胡力勤
機電工程技術 2022年2期
馬福軍 胡力勤


摘要:為了準確、實時發現地下綜合管廊運行和維護中的風險,將密度峰值聚類算法分析應用到地下綜合管廊異常數據挖掘。密度峰值聚類算法分3個環節,離群數據的取舍、聚類中心的確定和以Voronoi圖單元為基礎的數據映射分配。通過實驗分析,成功實現地下綜合管廊環境中氧氣濃度的大數據聚類,并得到不同氧氣濃度數據聚類簇圖像,直觀地觀察到氧氣濃度的數據狀態,通過該算法得到的數據簇聚類效果非常具有工程實際意義,能準確、實時預測管廊風險。
關鍵詞:密度峰值聚類;地下綜合管廊;大數據挖掘
中圖分類號:TP311.1
文獻標志碼:A
文章編號:1009-9492f 2022)02-0094-04
0 引言
地下綜合管廊是指在地下空間設置專供各種公用事業管線敷設的隧道或溝道,如電力、燃氣、通訊、供水排水、熱力等各種管線。地下綜合管廊密閉空間內,各種管線的相互干擾,容易發生電纜火災、燃氣泄漏造成的爆炸等影響管廊安全運行和周邊環境的安全[1]。因此,挖掘管廊運維大數據中的異常數據,及早發出管廊運維的風險預警和報警具有非常重要的現實意義。目前,地下綜合管廊風險預警的研究比較少,研究成果的應用性不強。
張勇等[1]利用模糊數理論、專家權重法和貝葉斯網絡理論對管廊風險給出確定的風險概率。莊麗等[2]用耦合協調理論在地下綜合管廊風險評價中的研究,用管廊內風險因素之間的耦合度高低,用熵權法給風險因素客觀賦權,推斷管廊發生某一風險的大小。柴康等[3]提出模糊聚類方法和多災種耦合理論預測管廊風險概率,從而采取措施降低事故概率。本文提出用密度峰值聚類算法挖掘管廊大數據,發現管廊數據的異常變化,從而及時發現地下綜合管廊險情并預警。王新穎、尹文君等[4-5]提出了基于深度置信網絡深度學習的預測方法,可以實現城市燃氣管道的風險模式識別和大氣污染識別。王玉琪等[6]通過數值模擬研究提出綜合管廊燃氣泄漏時,在燃氣艙中燃氣濃度分布與艙室結構、時間、氣流等參數相關。Damodar Reddy等[7—8]報道了不同的聚類算法,一種基于Voronoi圖的新型聚類算法,利用最大的空Voronoi圓來定位由Voronoi頂點表示的更接近的點,然后通過迭代構造新的Voronoi圖來有效地合并這些原型所表示的點,從而產生所需的簇;一種基于截斷距離和自適應的聚類算法。
國內外對地下綜合管廊的運行風險研究是當前的熱點,但風險的預測基于有限的風險因素作為預測模型的輸入參數,導致風險預測的準確度受限;或基于風險的概率統計與分析,也同樣存在風險因素的設計不全面科學而導致預測結果失真。同時,所查閱到文獻描述方法,在風險預測的實時性方面沒有得到解決。本文通過有效的峰值密度聚類算法實現數據挖掘,提高風險預測的準確度,同時,通過對實時數據的挖掘,從而提高風險預測的實時性。
1 綜合管廊大數據密度峰值聚類算法
1.1 管廊設計運行數據聚類中心的確定
綜合管廊中各類運行大數據,都會有聚類中心,數據聚類中心代表管廊的運行狀態。管廊某監測指標(例如管廊空氣的氧氣含量)數據集合Oi聚類中心的確定需要數據的密度峰值p。在聚類中心數據集合Oi={Oj},Oi為管廊某一類傳感器采樣的數據點,是聚類中心數據集合的元素,j=1,2,…,n。在集合數據中,在管廊正常運行狀態下,必然存在數據Oij,數據Oij是管廊設計運行數據。本文采用k近鄰方法,計算數據集合Oi的數據密度。考慮k近鄰內數據點之間的距離,數據Oij與周圍數據點的距離與數據Oij密度p成反比例的數據關系。其關系式可表達為:
考慮管廊環境下傳感器數據的干擾度因素,數據集合Oi中數據呈現正態分布,該集合的聚類中心的密度是最大的。根據第k近鄰方法和密度p計算公式,計算數據集合Oi數據的密度,并將計算所得的密度數據放入集合Density0,再把集合Density0中的數據進行兩兩比對.直至得到聚類中心ClusterC。結合上述分析,給出管廊數據聚類中心的算法ClusterA (Oi,k):
1.2 離群點的判別與取舍
綜合管廊數據依據統計規律呈現正態分布,數據集合Oi={Oj}中數據的局部密度有大有小,按照數據的分布規律,離群點的數據其局部密度必定在整個集合數據的平均密度之下,因此,離群點數據的范圍是可以確定的。本文提出用Voronoi圖[9]進行離群數據點的查找。Voronoi圖以空間劃分作為基本數據結構,可以實現數據查詢查找,并且有明顯優勢。對于管廊數據集合Oi,可以生成許多Voronoi單元,數據OJ的Voronoi單元,可表示為VU(Oj)。Voronoi圖中的Voronoi多邊形稱為鄰接多邊形[10],鄰接多邊形的生成點稱為鄰接生成點。數據Oj的鄰接生成點可分為一級鄰接生成點和h(h≥2)級鄰接生成點。
管廊數據集合Oi,要對其中的離群點進行查詢判別和取舍可以按如下思路進行。先計算集合Oj數據的局部密度,從而得到所有數據的平均密度,刷選出比平均密度低的數據點,然后逐個判斷低于平均密度的數據點是否為離群點。離群點的判別與取舍算法oda0 (Oj,k)。
算法輸入:管廊數據集合
//如果數據集合中數據點的反向最近鄰是0,則該數據點是離群點;如果數據點的一級近鄰都是離群點,則該數據點是個離群點。
Step12. if (Oj is Outlier) then
Step13. odM←delete (Oj)
Step14. end if
Step15.end for
Step16.return Oj
1.3 非離群點(除聚類中心數據點)數據分配
通過上述1.1和1.2的分析,找到數據聚類中心,并且排除離群點數據后,還需要對其余的數據進行類簇分配。數據的類簇分配,本文利用Voronoi圖的性質,應用Voronoi圖進行數據分配。
Voronoi圖的性質:Voronoi圖中,Voronoi單元互不交疊,沒有公共區域;每一個Voronoi單元內數據與數據生成點的距離最近;Voronoi單元之間的邊界數據與鄰接生成點之間的距離相等。
通過數據點映射的方法,將非離群數據點映射到以初始聚類中心為生成點的Voronoi圖當中。另外,根據Voronoi圖的性質,在Voronoi單元之間的邊界數據可以分配到任意一個Voronoi單元中。
對于通過Voronoi圖獲得數據簇,如果數據簇相似,則必須進行合并。本文利用jaccard相似系數[11],比較兩個數據簇的相似性。對于兩個管廊數據集合A和B,對應兩個數據簇,則集合A和B的數據相似性可定義為: 式中:IAnBl為數據簇A和數據簇B,在k近鄰數據點與A和B數據中心為半徑的相交圓內的數據個數;|A ∪B|為兩個網的并集數據個數。
J(A,B)的值越大,說明兩個數據簇的相似性越大,則數據簇A和B應該合并。在實際應用中,可設置jacca-rd相似系數一個閥值盧。如果相似系數大于閥值盧,則兩個數據簇應該合并。
基于對聚類中心的算法處理和離群數據的算法處理,結合利用Voronoi圖數據分配(包括其中相似數據簇的處理),提出獲得最終數據簇的算法如下。
算法輸入:管廊數據集合
Oi={O1,O2,O3,…,On),近鄰參數k,閥值p。
輸出:數據簇ClusterD
//去除離群點數據
Stepl: Oi←oda0 (Oi,k)
//通過聚類算法獲取聚類中心ClusterC
Step2:
ClusterC←ClusterA( Oj,k)
Step3:依據初始聚類中心生成Voronoi圖
Step4:映射數據集合Oi到Voronoi圖
Step5:生成Voronoi單元VU
//依據jaccard相似系數,合并數據簇
Step6: fori=l to VU length do:
Step7:forj=l to VU length do:
If (jaccard (VUi,VUj)》β) then:
ClusterD← (VU,,VUj)
Step8:
end if
Step9: end for
Stepl0:其余不合并的數據簇放人ClusterD
Stepll: end for
Step12: return ClusterD
2 綜合管廊大數據密度峰值聚類分析實驗
地下綜合管廊在運行和維護中產生海量的數據,形成大數據。一是管廊本體的屬性數據和管廊本體的監測數據。二是管廊的附屬設施和環境監測數據,例如管廊的消防、通風、排水系統數據、管廊的環境數據如氧氣含量、甲烷含量、溫度濕度等。利用密度峰值聚類大數據挖掘能及早發現異常數據簇,并發出預警,從而降低災害損失。本文應用白行研究設計的管廊自學習綜合控制盤網絡平臺,進行管廊數據的峰值聚類分析。圖1所示為自學習綜合控制盤網絡平臺數據架構。圖中自學習控制盤通過前端傳感器收集管廊大數據,并通過網絡層將傳輸至數據中心存儲,配置和運維平臺可以讀取數據中心數據,進行峰值聚類分析。圖中白學習控制盤分布在管廊不同艙室空間,收集包括環境參數在內的各類管廊運行數據,同時通過環形CAN總線實現自學習控制盤之間的數據交換。
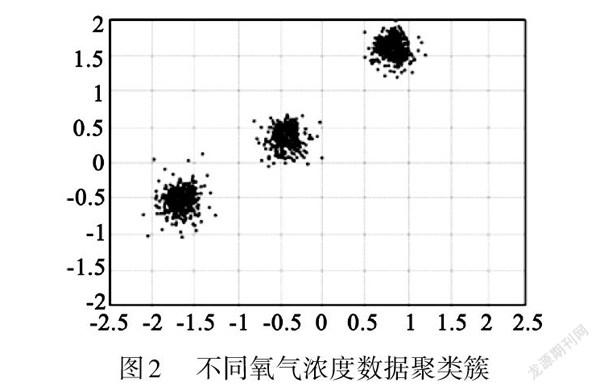
本次實驗數據分析對管廊氧氣濃度變化進行密度峰值聚類分析模擬實驗。在標準狀態下,空氣中氧氣的體積百分比為21.7%,用1.3節所述的數據分配聚類算法可得數據聚類簇圖形。隨后增加空氣中的氧氣濃度到多個穩定濃度如30%和50%,觀察數據聚類簇圖形發生變化情形。
本次實驗采用windows10系統,64位操作系統,系統內存16C,處理器Intel (R) Core (TM) i5-1035CICPU@1.00 CHz l.19 CHz,程序采用Java語言。每個穩定的氧氣濃度狀態,通過800個數據形成數據簇。實驗中Voronoi圖的算法實現參考文獻[12]。3個氧氣濃度狀態21.7%、30%、50%;從左到右對應3個數據聚類簇如圖2所示。實驗過程中針對不同的氧氣濃度,仿真圖像上顯示數據有較好的集中度,同時在實驗過程中氧傳感器由于受氣流的干擾,數據聚類過程中存在少量的發散,但這不改變整體數據的聚類分析。在工程實踐中,當確定一個標準的數據聚類作為正常數據后,可以設定不同的偏差作為異常數據的判定,不同的偏差等級可與不同的風險等級相對應。
3 結束語
通過對管廊內氧氣濃度變化的大數據密度峰值聚類算法實驗分析,可以得出本文所述數據挖掘方法是可行的,能有效監測地下綜合管廊運行的數據簇,解決了地下綜合管廊風險數據的實時監測難題,對依靠風險概率統計與分析的手段監測地下綜合管廊運行風險創新性的給出了新的解決方案。利用大數據密度峰值聚類算法對地下綜合管廊異常數據的監測,為后續建立管廊風險一措施行為模型研究做好準備,最終實現地下綜合管廊風險的實時發現和實時管控,最大化減少因風險引起的各種損失。
參考文獻:
[1]張勇,謝霞霞,王祥宇,等.基于BN-bow-tie的智慧城市地下綜合管廊運維在還分析[J].建設科技,2020(23):58-61.
[2]莊麗,馬婷婷。劉蘭梅,等.耦合協調理論下綜合管廊運維災害風險研究[J].佳木斯大學學報(自然科學版),2020,38(5):122-125.
[3]柴康,劉鑫.基于模糊聚類分析的綜合管廊多災種耦合預測模型[J].災害學,2020,35(4):206-209.
[4]王新穎,張惠然,張瑞程,等.基于深度學習的大數據管網風險評價方法[J].消防科學與技術,2019,38(6):902-904.
[5]尹文君,張大偉,嚴京海,等.基于深度學習的大數據空氣污染預報[J].中國環境管理,2015,7(6):46-52.
[6]王玉琪,戚承志,屈小磊,等.地下綜合管廊燃氣泄漏模擬研究[J].消防科學與技術,2018,37(10):1348-1353.
[7] Damodar Reddy.Prasanta K Jana. Intemational Journal of dataMining[J].Modelling and Management,2014(6):49-64.
[8]楊震,王紅軍,周宇.一種截斷距離和聚類中心自適應的聚類算法[J].數據分析與知識發現,2018,2(3):39-48.
[9]郝忠孝.空間數據庫理論基礎[M].北京:科學出版社,2013.
[10]張麗平,劉蕾,郝曉紅,等.障礙空間中基于Voronoi圖的組反K最近鄰查詢研究[J].計算機研究與發展,2017,54(4):861-871.
[11]張曉琳,付英姿,褚培肖.杰卡德相似系數在推薦系統中的應用[J].計算機技術與發展,2015,25 (4):158-161.
[12]張艷,李強.基于逐點插入法生成Voronoi圖的算法研究及實現[J].黑龍江工程學院學報,2016,30(5):22-24.
