基于注意力門控神經網絡的社會化推薦算法
2022-04-09 07:03:24邵雄凱王春枝
計算機工程與應用 2022年5期
邱 葉,邵雄凱,高 榕,王春枝,李 晶
1.湖北工業大學 計算機學院,武漢 430068
2.武漢大學 計算機學院,武漢 430072
隨著信息時代的不斷發展,人們獲取信息的數量也不斷增長。如何在呈幾何式增長的數據里找到所需要的數據,推薦系統為此提供了一種可能的解決方案,利用用戶的歷史數據進行個性化推薦[1],節約時間成本的同時也更加符合當今時代的需求。事實上,如果用戶通過推薦獲取了感興趣的內容,即為推薦模型增添數據,利于企業更加精準刻畫用戶畫像,進而實現更精確的推薦。
但是,不斷發展的推薦系統同樣面臨著數據稀疏的難題。網絡時代使人們的生活方式從線下轉向線上,社交關系不斷發展。迅速增長的社交數據在一定程度上為解決數據稀疏問題提供了可能。近年來,社會化推薦成為學者們趨之若鶩的研究熱點,層出不窮的算法和實驗結果都充分彰顯了社會化推薦的有效性及其所具有的現實意義。
盡管研究者們在此方面開展了許多工作[2-3],但仍有以下問題尚未解決:
(1)在采用用戶信息和輔助信息進行推薦建模時,由于數據來源不同,所表達的信息不同,導致兩者不能很好地融合。尤其在社會化推薦中,因為數據異構而不能很好融合,從而降低了用戶偏好推薦的準確性[4-6]。
(2)先前的研究將不同朋友在不同方面的影響都一視同仁地看待。在現實場景中,用戶與不同朋友擁有不同相似興趣。如圖1所示,用戶B有兩個朋友,B與A同時喜歡打排球,與C同樣偏好唱歌。顯然,在進行室外活動時,B更考慮A的建議;進行室內活動時更考慮C的建議,且唱歌和打排球給予用戶的影響程度不同。對此Chen等人[7]提出SAMN算法,旨在利用注意力機制來解決問題。然而普通注意力僅考慮朋友重要性,忽視了在不同方面朋友影響的重要性,例如在用戶對于進行室內或室外活動舉棋不定時,由于C在唱歌方面對用戶B的影響更大,B更可能進行室內活動。
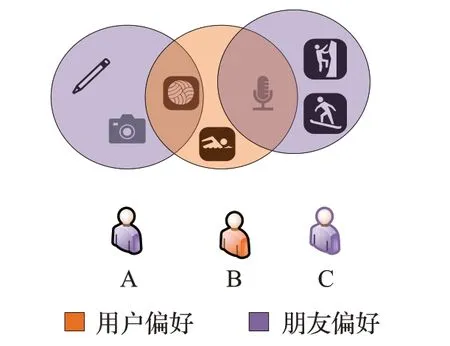
圖1 用戶與朋友興趣偏好Fig.1 Preferences of user and friends.
因而,本文提出了一種新的推薦算法——MAGN(multi-head attention gated neural network),即基于多頭注意力門控神經網絡的社會化推薦算法。首先,利用門控神經網絡對輸入的用戶和朋友用戶對做融合,獲得豐富的交互嵌入表示。將得到的融合嵌入通過注意力記憶網絡,獲得朋友在不同方面對于用戶的影響。其次,采用多頭注意力機制來調節朋友之間的影響力大小。最后,基于用戶本身的興趣愛好,利用門控網絡融合朋友影響,得到綜合用戶興趣表示。在公開數據集的實驗表明,本文提出的方法優于主流先進的社會化推薦算法。
本文研究工作的貢獻如下:
(1)為了在考慮用戶本身興趣的基礎上更好融合其社交影響,更好模擬了現實場景,本文采用門控網絡來建模用戶與朋友之間的復雜交互關系及其非線性交互關系。
(2)為了在進行社會化推薦全面考慮朋友影響,本文利用多頭注意力機制,不僅突出了不同朋友對于最終推薦結果的影響,也深層次彰顯了在某一方面給出重要建議朋友對于最終推薦結果的重要影響。
(3)在兩個真實數據集上的實驗表明,本文的方法優于主流先進的社會化推薦算法。
1 相關工作
在這個部分將回顧與多頭注意力門控神經網絡社會化推薦相關的發展情況。分為兩個部分:注意力機制與社會化推薦,基于融合策略的推薦算法。
1.1 注意力機制與社會化推薦
由于網絡交流方式的興起,線上社交成為了人們生活中不可或缺的一部分,從而給推薦系統的發展帶來了新思路。而隨著文獻[8]的發表,研究者們開始考慮利用注意力機制來對現有相關社會化推薦算法進行改善,并進行了卓有成效的研究工作[9],驗證了注意力機制在各種社會化推薦任務中的良好效果。
Pei等人[10]考慮到現有推薦假設用戶項目交互歷史中所有時間步都與推薦具有同等相關性,在真實場景中并不適用,同時許多研究都是對用戶和項目分別進行動態建模,而沒有考慮兩者交互的影響。因而提出交互注意門控遞歸網絡,采用注意力機制來度量時間步的相關性。柴玉梅等人[11]發現現有研究都局限地處理項目評分與評論,忽略了評論文本所蘊含的信息,從而提出基于雙注意力機制和遷移學習的跨領域推薦模型。通過將注意力機制添加到詞的上下文關系中,來提升對文本中重點信息的關注度。Ji等人[12]考慮到原本的轉換器中,自注意力部分是一個沒有關系偏好的方法,導致先前的工作在采用轉換器來解決問題的時候有所限制。基于此他們提出為轉換器中自注意力里的值添加一個潛在空間,并利用這個潛在空間,從推薦任務的關系中對上下文進行建模。Tay等人[13]提出潛在度量學習算法來學習用戶和項目之間的自適應關系向量,通過嘗試在每個交互對之間找到最優的轉換向量,來對隱式數據進行協同過濾和排序。
1.2 基于融合策略的推薦算法
近幾年,深度學習在計算機視覺、語音識別和自然語言處理等許多領域取得了巨大的成功。一些研究人員還嘗試利用不同的神經網絡結構來提高推薦性能。Lu等人[14]為了融合豐富的異構信息,在社會化影響注意力神經網絡中設計了注意力特征聚合器,學習節點級和類型級上的用戶和項目表示。同時,利用一個社會影響耦合器來獲取朋友推薦的影響。吳賓等人[15]考慮社會化推薦中物品之間的關聯關系,提出了一種度量物品關系關聯程度的方法,融合關聯關系以及社會關系,構建了聯合正則化的矩陣分解推薦模型。Ma等人[16]考慮到現如今推薦系統依然存在的數據稀疏問題,以及混合異構數據的困難,提出了一種門控式自動編碼器算法,該算法能夠通過一種神經門控結構來學習物品內容和二進制等級的融合隱藏表示。基于融合表示形式,算法利用項目之間的相鄰關系來幫助推斷用戶的偏好。Xia等人[17]提出了一種混合式深度協同過濾算法來同時學習評分和評論特征,其中兩個嵌入層用于學習用戶和項目的特征,兩個基于注意力的門控循環網絡從用戶和商品評論中學習上下文感知。
本文提出的MAGN算法在如下幾個方面與前人的研究工作[10-17]有很大不同。首先,文獻[10-13]的工作僅僅將普通注意力機制應用在基于機器學習方法實現推薦建模的過程中,從而突顯用戶及各種輔助信息等對最終推薦結果的影響。但是,少有工作研究利用更加多頭注意力機制建模探索用戶及各種輔助信息在社會化推薦建模中對于推薦結果的深層次影響。其次,文獻[14-17]基于異構數據融合的艱巨性,提出了幾種簡單的融合策略,缺乏建模推薦過程用戶及朋友的深層次的復雜交互關系以及非線性交互關系。相對比,本文提出的MAGN算法是一個基于門控網絡和多頭注意力機制的社會化推薦算法。與上述方法存在如下不同:(1)本文采用多頭注意力機制而不是普通注意力機制,實現了更加全面且多方面建模不同朋友的重要程度,有效減少了不同朋友對于最終社會化推薦結果的影響偏差;(2)本文在社會化推薦建模融合過程中采用了少有的門控神經網絡,利用門控神經網絡具有的深層次非線性網絡結構,及其強大的學習數據本質特征的能力,獲取了用戶和朋友的深層特征表示,成功實現了用戶及其朋友之間的復雜交互及其非線性交互的建模。
2 MAGN算法
在這個部分將詳細介紹所提出的多頭注意力門控神經網絡(MAGN)算法。算法的目標是基于用戶社交關系和隱式反饋來做推薦。對于給定的輸入:用戶表示,項目表示和用戶朋友關系,將輸出一個帶有來自不同朋友在不同方面影響的用戶興趣特征表示。總體分為三個部分:注意力記憶網絡部分,將用戶和用戶朋友對進行處理得到用戶及其朋友之間的偏好關系,即用戶與其朋友在哪一個部分具有相似的偏好;多頭注意力部分,在基于得到的與朋友在不同方面的偏好,得出各個不同朋友的重要程度從而計算出帶有不同朋友影響的特征表示。最后,根據得到的不同朋友在不同方面的影響,尤其考慮到權重更大的朋友對用戶的影響,將朋友影響向量和用戶自身所具有的興趣點進行融合,得到總體的用戶特征表示。結構圖如圖2所示。其中多頭注意力將在2.3節中展示詳細圖示。
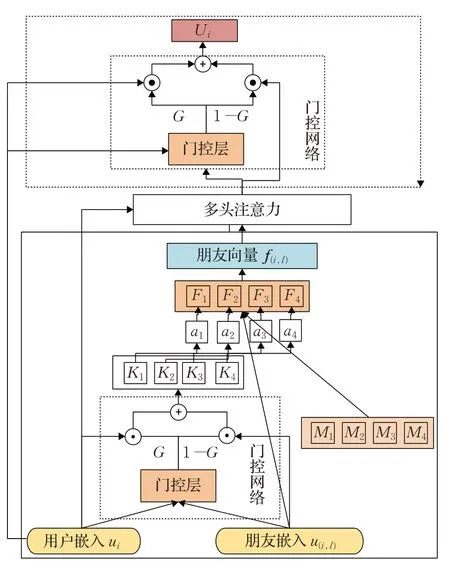
圖2 多頭注意力門控神經網絡算法Fig.2 Multi-head attention gated neural network algorithms
2.1 嵌入
對于給定的用戶和用戶朋友對,首先要獲得其嵌入表示。在此算法中,采用如下公式(1)、(2)得到融合特征向量,得到更好的特征表達。
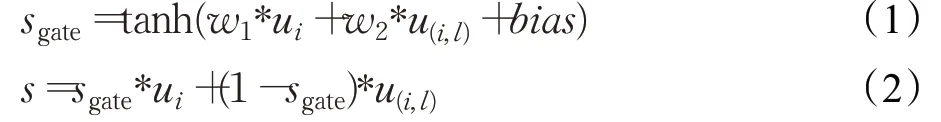
其中,tanh為激活函數,w1和w2、bias分別為門控網絡的權重參數和偏置,ui和u(i,l)表示用戶及用戶朋友對。利用門控網絡將用戶嵌入和用戶朋友嵌入做特征融合得到融合嵌入向量表示s。
2.2 注意力記憶網絡
用戶與社會關系中的朋友各自有其興趣愛好,并在大多數情況下,用戶擁有多方面的興趣,與其朋友只是在某些方面擁有相同的偏好。然而,在現實場景中,并不能確定用戶和朋友的相似興趣方面,即用戶朋友對之間的關系并不能反映出用戶和朋友是在哪一方面具有共同的興趣。對此,本文采用了文獻[9,18]中基于注意力的記憶模塊,來學習用戶及其朋友之間的關系向量。模塊的記憶矩陣記為M,其中d為用戶和項目嵌入的維度,n為記憶片的大小。在記憶矩陣M里,把每一個記憶片記為Mj。在這一模塊中對于輸入的用戶和朋友嵌入,輸出能夠代表用戶和朋友共同興趣偏好的向量。
在得到融合嵌入向量s后,從注意力權重矩陣K中學習注意力向量。注意向量a的每個元素被定義為:

其中,Ki∈Rd。然后,使用softmax函數對a進行歸一化,得到最終的結果:

朋友嵌入u(i,l)首先經由記憶矩陣M擴展到矩陣:

式中,⊙表示向量的元素積。矩陣F表示不同潛在方面中的朋友偏好。
最后,為了生成朋友向量表示,使用注意力分數來計算F的加權表示:

輸出是一個特定的關系向量f(i,l),可以看作是用戶i的第l個朋友對此用戶偏好的影響向量。設f(i,1),f(i,2),…,f(i,l)為注意力記憶模塊生成的用戶i的朋友關系向量。
2.3 多頭注意力
注意力機制被廣泛應用于各個領域,在計算機視覺、機器翻譯和推薦系統均獲得了令人滿意的成果。
而對于每一個用戶,此部分致力于獲得與其相關性最高或聯系緊密能給予用戶更高影響的朋友,并輸出在不同方面對用戶更有影響的幾個朋友向量。給定輸入為朋友對用戶的影響f(i,l),普通注意力機制即為朋友分配不同權重,且當用戶使用不同交互方式進行交互時權重會發生變化。
然而在真實場景中,用戶并非將每一朋友建議都同等對待,與用戶關系更加親密,或者在某方面更加專業的朋友顯然能給予用戶更精準的建議。因而,采用多頭注意力極大滿足了用戶對朋友建議的有所側重。因此,本文利用多頭注意力機制從目標對象中選擇多個信息,考慮輸入信息的不同部分來獲得在不同方面對用戶的重要程度。結構圖如圖3所示。

圖3 多頭注意力Fig.3 Multi-head attention
對于每一個用戶(Query),將其與從上層得到的輸入朋友向量(Key)進行比較,得到不同朋友的分數,公式如下:

在本文中將K和V設為同一個變量f(i,l),表示需要計算的是朋友對用戶的影響。
多頭注意操作將業務嵌入f(i,l)作為輸入并將其饋送到不同的頭注意層,其結果被進一步連接為最終輸出:

每個融合嵌入f(i,l)是通過比較權重得出的朋友重要性,權重越大代表此朋友對于用戶的影響就越大。
2.4 門控網絡
利用從上述兩個模塊中獲得的朋友影響向量,將此向量與用戶本身興趣相融合,得到用戶綜合興趣偏好。受長短時記憶網絡中門控機制的影響,門控G和最終得到的用戶在受不同朋友的不同方面影響之下的綜合興趣Ii的計算公式為:
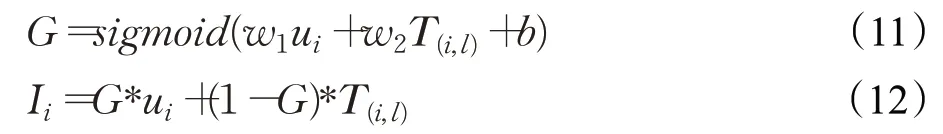
其中T(i,l)、w1、w2分別表示朋友影響向量以及門控層中的權重參數。
2.5 融合學習
基于矩陣分解技術本文的最終預測部分,評級預測和建模隱式反饋的公式如下:

其中,Rij是對各個項目的預測分數。而本文旨在研究隱式反饋,為此,本文利用BPR標準成對學習目標,對于每個正用戶項目對(表示用戶對當前項目表示明顯喜好)<ui,vj>,從用戶未觀察到的項目中隨機抽取一個負樣本(即用戶對該項目并未展現喜好),記為vk,損失函數如下:
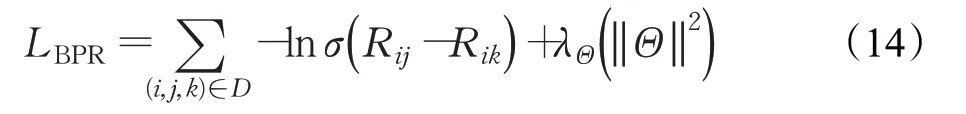
其中,σ(x)=1/(1+exp(-x))是邏輯sigmoid函數,D表示成對訓練實例的集合,同時用它控制正規化的強度。在本文中,考慮小批量Adagrad[19]可以自適應學習速率,因而使用作為優化器。
3 實驗
3.1 數據集
在這個部分,基于兩個公開數據集進行實驗,分別為Delicious[20]和Epinions[21]。Delicious(https://grouplens.org/datasets/hetrec-2011/)是一個社交書簽網絡,允許用戶查看和共享其他用戶的書簽信息。數據集約有兩千個用戶數據,包括社交網絡、資源消耗(網頁書簽和音樂藝術家收聽)和標簽信息,在本文中僅僅使用社交網絡和資源消耗(即用戶書簽)信息。Epinions(http://alchemy.cs.washington.edu/data/epinions/)是一個提供項目評估和評論服務的在線社交網絡,可將其他用戶添加到自己的信任列表,表示對此用戶的評分和評論的認可。該數據集包含用戶給予項目的評分列表,以及用戶與信任用戶之間的社交關系。對于數據預處理,本文將去除所有少于五個評分的項目,并將用戶評分小于4的用戶評分設為0,將用戶評分大于等于4的用戶評分設為1(作為隱式反饋)。表1給出了數據集的統計詳細信息。

表1 數據集統計Table 1 Dataset statistics
3.2 評估標準
為評估所使用算法的性能,本文選擇兩種在推薦中經常使用的評估指標——Recall@K(召回率)和NDCG@K(歸一化折損累計增益),其中K為推薦列表的長度。其計算公式為:

其中,relj表示在推薦列表中排名j的項目是否在測試集中,表示用戶u在測試集中評分的項目數。IDCG表示通過理想排名獲得的最大DCG。在本文實驗中,對于Recall@K和NDCG@K,設置K=10,20,50來評估算法性能。
3.3 算法比較與實驗設置
為了證明所提算法的有效性,從多個角度對本文提出的算法進行測試。
(1)與主流先進算法進行對比,驗證本文所提出算法的高效性與先進性;(2)與注意力機制進行對比,驗證采用的多頭注意力機制的有效性;(3)潛在維度因子分析,基于不同潛在維度因子測試不同情況下的有效維度,驗證本文提出算法的魯棒性。
首先,選定四個近幾年提出的社會化推薦算法進行對比:
(1)NFM[22]。這是最近提出的神經分解機,它是最先進的深度學習方法之一,使用雙向交互層將功能和歷史反饋信息集成在一起。在本文中,通過將用戶社交關系設為特征,將優化功能更改為BPR以適應本文的任務。
(2)NCF[23]。一個最近提出的基于深度學習的最新框架,該框架結合了矩陣分解(MF)和多層感知模型(MLP)進行項目排行。
(3)SNCF。通過調整NCF[22]來模擬社交關系,將用戶好友插入到輸入的特征向量中,并利用特征向量和用戶id進行連接,將此改進模型稱為SNCF。
(4)SAMN[7]。是一種最新的深度學習方法,利用注意力機制為社會化感知推薦建模方面和朋友級別的差異。
其次,將無注意力、自注意力[14]以及多頭注意力機制進行對比,驗證本文采用的多頭注意力的有效性。最后,本文測試了在不同潛在維度下對于此算法的影響,驗證了本文所采用的潛在維度所展現的算法魯棒性。
按照70%、20%、10%的概率隨機將數據集分為訓練集、驗證集和測試集。其中驗證集用來調整超參數,通過訓練集得出預測數據與測試集比對得到最終結果。算法的學習率均在[0.01,0.05,0.1]之間調整,批次大小在[64,128,256]之間調整,隱含層皆在[16,32,64,128,256]之間調整,記憶片在[8,16,32,64]之間調整,多頭數量在[4,8,16,32]之間調整。
3.4 實驗分析
3.4.1 主流先進算法對比分析
在兩個數據集上所有對比算法的實驗結果如圖4和5所示。由兩個評估指標Recall和NDCG的實驗結果,本文可以得出:
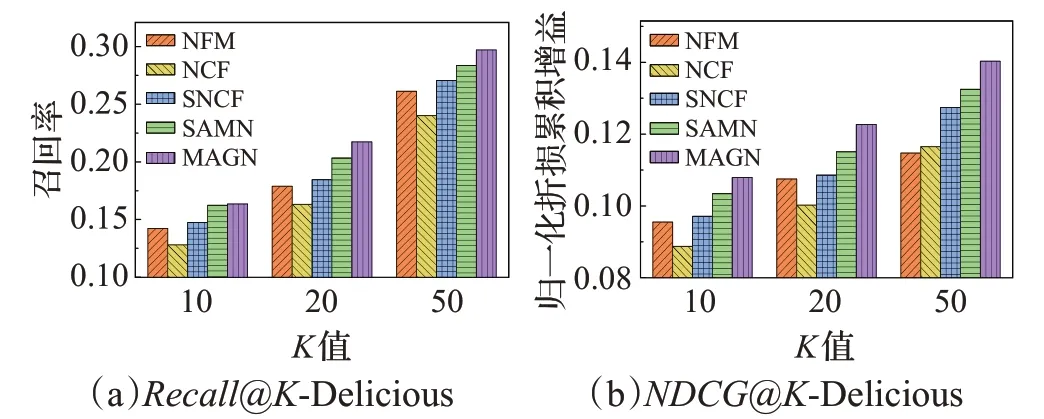
圖4 基于Delicious數據集MAGN與其他主流先進算法對比Fig.4 Comparison between MAGN and other mainstreamadvanced algorithms based on Delicious dataset
(1)在兩個數據集上,NFM、SNCF、SAMN及MAGN算法效果比NCF良好,可見社交關系信息對于推薦的有效影響。
(2)在基于社會化推薦的算法中,SAMN效果比NFM及SNCF算法表現更好,則表明在社會化推薦中,僅考慮單純的社交關系信息還遠遠不夠,更需考慮豐富的社交關系對用戶帶來的影響。
(3)MAGN比SAMN效果更加顯著,這意味著在考慮用戶和項目的特征融合時,利用門控神經網絡能達到更好效果。且顯而易見的,在社交影響基礎上,采納更重要的朋友,并考慮不同方面影響的方法獲得了更大的進步。
(4)在兩個數據集上,本文提出的基于注意力門控神經網絡的社會化推薦算法的性能優于其他對比算法,驗證了本文提出算法的有效性。
(5)在所有的評價指標上,所有對比算法在Delicious數據集上的效果比Epinions數據集效果要好。這是由于相對于Delicious數據集,Epinions數據集更加稀疏。
3.4.2 注意力機制對比分析
為了驗證有無注意力機制以及不同注意力機制對算法帶來的不同影響,本文進行了實驗與對比分析。實驗結果如圖6、7所示,其中None指代無注意力機制,Self指代自注意力機制,Multi-head指代多頭注意力機制。
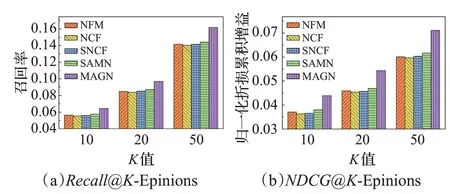
圖5 基于Epinions數據集MAGN與其他主流先進算法對比Fig.5 Comparison between MAGN and other mainstream advanced algorithms based on Epinions dataset
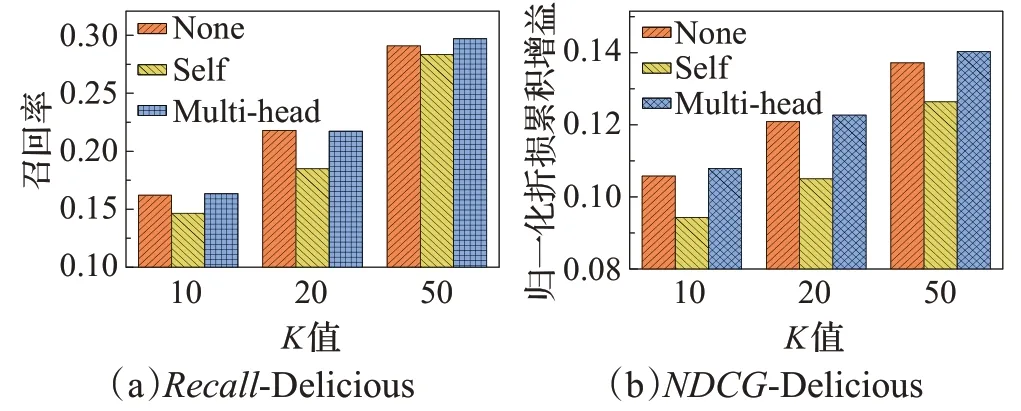
圖6 基于Delicious數據集的不同注意力對比Fig.6 Comparison of different attention based on Delicious dataset
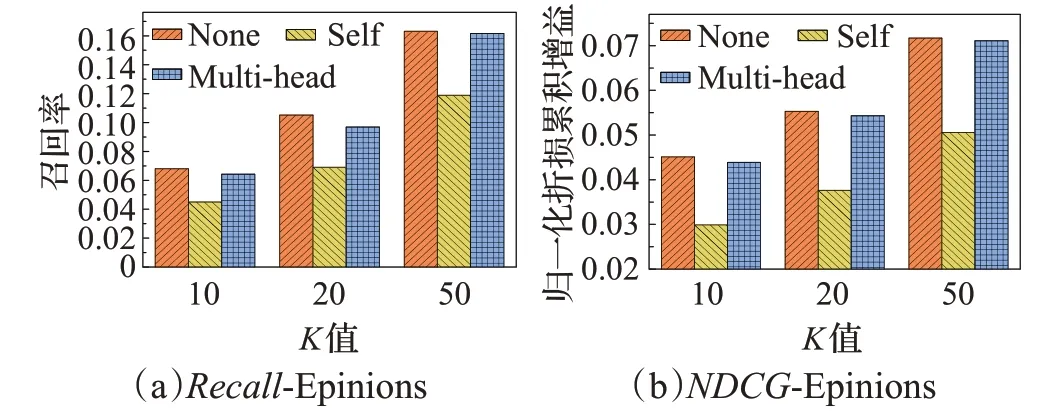
圖7 基于Epinions數據集的不同注意力對比Fig.7 Comparison of different attention based on Epinions dataset
首先,在兩個數據集中,MAGN都表現出更良好的性能。且無注意力會比自注意力機制效果稍好,一種可能的解釋是,自注意力的網絡結構反而導致了過擬合,以至于效果表現欠佳。多頭注意力比自注意力效果更好也驗證了上述所提,對用戶進行推薦時,著重考慮在不同方面朋友對用戶的影響,而非考慮朋友之間的相互影響更加合適的想法。最后,多頭注意力對于無注意力并未展現明顯差距,一種可能的解釋是,類似于自注意力機制,多頭注意力的網絡結構同樣會產生過擬合。
3.4.3 潛在維度分析
潛在維度的變化同樣對實驗結果存在一定程度的影響,對此進行對比分析,觀察不同潛在維度對于算法的適應性。實驗結果如圖8所示。
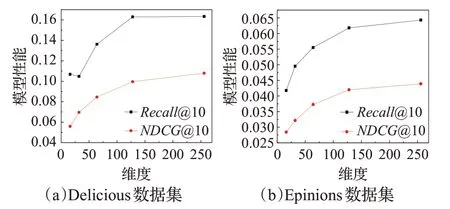
圖8 基于Delicious和Epinions數據集的MAGN算法潛在維度分析Fig.8 Analysis of potential dimensions of MAGN algorithms based on Delicious and Epinions datasets
由實驗結果可得,維度越大時,效果也愈加明顯,而相對的,在增大潛在維度時,會增加對于內存的使用率和運算時間。更為明顯的是,在潛在維度增加到一定程度時,算法的效果提升會趨于平穩。因而可見本文所采用的潛在維度256是綜合考慮之后的最好選擇。
4 結束語
社交信息為提高推薦系統的精確度做了一個非常好的鋪墊。因而,本文充分利用了這一優勢,基于用戶可能會考慮不同朋友的意見,并受到不同程度影響的現實情況,首先考慮用戶擁有一定影響的朋友數目,在此基礎上利用多頭注意力更加全面考慮朋友在不同方面給用戶帶來的影響力,深層次地突出了相關重要朋友在某一個方面的重要影響。同時,利用門控網絡進行融合,提高了最終推薦的準確率。而在兩個真實數據集上的實驗則驗證了本文所提出的算法優于主流先進社會化推薦算法。在將來,本文將進一步考慮如何基于圖模型更加精確地得到朋友對用戶的影響,并不斷提升當前算法的可解釋性。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
文苑(2018年21期)2018-11-09 01:23:06
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年9期)2015-11-10 03:11:12
創業家(2015年5期)2015-02-27 07:53:25
