基于BERT和層次化Attention的微博情感分析研究
2022-04-09 07:03:52傅兆陽
計算機工程與應用 2022年5期
趙 宏,傅兆陽,趙 凡
1.蘭州理工大學 計算機與通信學院,蘭州 730050
2.甘肅省科學技術情報研究所,蘭州 730000
隨著互聯網的迅猛發展,Twitter、微信、微博等社交網絡正潛移默化地改變著人們的生活方式。越來越多的人愿意在網上表達自己的態度與觀點,使得互聯網用戶逐漸由信息接收者轉變為信息創造者,并由此迸發出海量帶有情緒色彩的文本數據,尤其是微博,已經成為廣大網民發表觀點和交流信息的熱門平臺。分析微博評論中蘊含的情感可以獲取網民對某一特定話題的觀點和看法,實現網絡輿情的實時監測。例如:通過分析網民對二胎政策、退休年齡等熱門話題的評論,可以幫助政府了解民意,掌握民眾情緒;通過分析網民對一些負面消息的評論,可以幫助政府制定相應的引導策略,維護社會的長治久安。
相較普通文本,微博文本更簡短、更口語化,網絡流行語、表情符層出不窮,呈現稀疏、不規則的特點,使得微博文本情感分析更具挑戰性。因此,如何能夠快速準確地提取出微博文本中蘊含的情感,對網絡輿情的實時監測具有重要的意義[1-2]。
文本情感分析自2004年由Pang等[3]提出后,受到高度關注。早期的研究主要基于規則和基于傳統機器學習算法[4]。基于規則的方法主要依靠人工構建情感詞典,對文本進行情感詞的規則匹配,通過計算情感得分得到文本的情感傾向。該方法實現簡單,但受限于情感詞典的質量,需要語言學家針對某個領域構建高質量詞典,工作量大,且對新詞的擴展性差。基于傳統機器學習的方法需要人工構造十分復雜的特征,利用支持向量機(support vector machine,SVM)、樸素貝葉斯(Na?ve Bayes,NB)、最大熵(maximum entropy,ME)等分類器進行有監督學習,然后,對文本蘊含情感的極性做出判斷[5]。基于傳統機器學習在小規模數據集上取得了較好的效果,但隨著數據量的增大和各種特殊情景的出現,該方法的準確率快速下降,影響使用。
近年來,深度學習快速發展,被研究人員廣泛應用于文本情感分析領域[6]。深度學習通過模擬人腦神經系統來構造網絡模型對文本進行學習,從原始數據中自動提取特征,無需手工設計特征,面對海量數據的處理,在建模、遷移、優化等方面比機器學習的優勢更為明顯。常見的深度學習模型有卷積神經網絡(convolutional neural network,CNN)和循環神經網絡(recurrent neural network,RNN)等。Kim[7]最早提出將CNN用于文本情感分析,在預訓練的詞向量上使用不同大小卷積核的CNN提取特征,在句子級的分類上較傳統機器學習算法有明顯提升。劉龍飛等[8]分別將字級別詞向量和詞級別詞向量作為原始特征,采用CNN進行特征提取,在COAE2014語料上提高了準確率。但CNN只能提取局部特征,無法捕獲長距離依賴。Mikolov等[9]提出將RNN應用到文本情感分析中。相比CNN,RNN更擅于捕獲長距離依賴。RNN每個節點都能利用到之前節點的信息,因此更適用于序列信息建模。但隨著輸入的增加,RNN對早期輸入的感知能力下降,產生梯度彌散或梯度爆炸問題。隨著研究的深入,長短期記憶網絡(long short-term memory,LSTM)[10]和循環門控單元(gated recurrent unit,GRU)[11]等RNN的變體被提出。田竹[12]將CNN與雙向GRU結合,用于篇章級的文本情感分析,提高了模型的魯棒性。Tang等[13]為了挖掘句子間的關系,提出采用層次化RNN模型對篇章級文本進行建模。
傳統深度學習模型將所有特征賦予相同的權重進行訓練,無法區分不同特征對分類的貢獻度,Attention機制通過聚焦重要特征從而很好地解決了這一問題。Bahdanau等[14]將Attention機制用于機器翻譯任務,通過Attention機制建立源語言端的詞與翻譯端要預測的詞之間的對齊關系,較傳統深度學習模型在準確率上有了較大提升。Luong等[15]提出全局和局部兩種Attention機制,在英語到德語的翻譯上取得了很好的效果。Yang等[16]提出層次化Attention用于情感分析任務,進一步證明了Attention機制的有效性。
以上CNN與RNN以及Attention機制相結合的混合模型雖然取得了很好的效果,但大多使用Word2Vector或GloVe等靜態詞向量方法,不能很好地解決一詞多義問題。同一個詞在不同的上下文語境中往往表達出不同的情感,例如“這款手機的待機時間很長”和“這款手機的開機時間很長”兩句評論中的“很長”分別表示積極和消極的評價。2019年,Devlin等[17]提出BERT(bidirectional encoder representations from transformers)預訓練語言模型。該模型通過雙向Transformer編碼器對海量語料進行訓練,得到動態詞向量,即同一個詞在不同的上下文語境中生成不同的向量表征,大大提升了詞向量的表達能力。
綜上,在詞向量表征層面,現有微博情感分析模型一般使用分詞技術結合Word2Vector或GloVe生成靜態詞向量,不能很好地解決一詞多義問題,且分詞固化了漢字間的組合形式,容易產生歧義,例如“高大上海鮮餐廳”會被分詞為“高大/上海/鮮/餐廳”。為解決此問題,本文采用BERT預訓練語言模型,對微博文本逐字切割,生成動態字向量,不僅避免了分詞可能造成的歧義,同時能夠結合上下文語境解決一詞多義問題;在特征提取層面,現有微博情感分析模型普遍使用單一的詞語層Attention機制,未能充分考慮文本層次結構的重要性。本文認為Attention機制不應該只關注文本中重要的詞語,還應該區分不同句子間的重要性。例如一段文本整體表達的是消極情感,模型應該給包含積極情感詞語的句子賦予較低的權重,從而區分不同句子對整體情感傾向的影響。因此,本文采用層次化Attention機制,從字和句子兩個層面綜合判斷微博文本的情感傾向。
針對以上問題,本文提出BERT-HAN(bidirectional encoder representations from transformers-hierarchical attention networks)模型用于微博情感分析,該模型首先通過BERT預訓練語言模型生成蘊含上下文語意的動態字向量,然后通過兩層BiGRU(bi-directional gated recurrent unit)分別得到句子表示和篇章表示,在句子表示層引入局部Attention機制捕獲每句話中重要的字,在篇章表示層引入全局Attention機制區分不同句子的重要性,最后,通過Softmax對情感進行分類。
1 模型設計
1.1 BERT預訓練語言模型
BERT是Google的Devlin等[17]于2018年10月提出的預訓練語言模型,一舉刷新了11個NLP任務的榜單。如圖1所示,該模型采用雙向Transformer編碼器獲取文本的特征表示。其中E1,E2,…,EN表示輸入字符,經過多層雙向Transformer訓練后生成相應的向量表征T1,T2,…,TN。

圖1 BERT模型結構Fig.1 BERT model structure
Transformer編碼器是一個基于Self-Attention機制的Seq2Seq(sequence to sequence)模型[18],模型采用Encoder-Decoder結構,摒棄了傳統的CNN和RNN,僅使用Self-Attention機制來挖掘詞語間的關系,兼顧并行計算能力的同時,極大地提升了長距離特征的捕獲能力。BERT僅采用Transformer的Encoder部分,其結構如圖2所示。由于Self-Attention機制并不具備對輸入序列的位置信息進行建模的能力,而位置信息體現了序列的邏輯結構,在計算中起著至關重要的作用,因此在輸入層加入位置編碼。融合了位置信息的向量首先經過多頭注意力(Multi-Head-Attention)機制層,實質是將Self-Attention重復多次操作,從不同角度學習信息,達到豐富語義的目的。之后將結果輸入前饋神經網絡層,增加非線性變化,最終得到向量表示。Transformer還引入殘差連接和層規范化[19],殘差連接用于規避信息傳遞中出現的記憶偏差,層規范化用于加速模型的收斂。
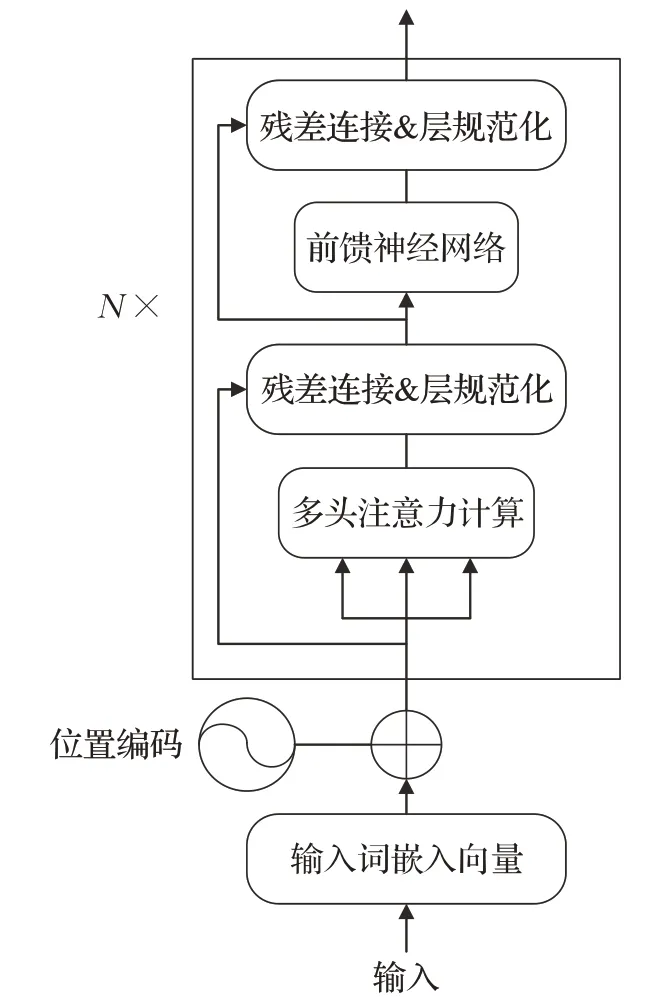
圖2 Transformer Encoder模型結構Fig.2 Transformer Encoder model structure
BERT的輸入由字嵌入(token embedding)、段嵌入(segment embedding)和位置嵌入(position embedding)三部分相加構成,每句話用CLS和SEP作為開頭和結尾的標記。BERT采用遮擋語言模型(masked language model,MLM)和下一句預測(next sentence prediction,NSP)來進行訓練。MLM隨機遮擋一定比例的字,強迫模型通過全局上下文來學習被遮擋的字,從而達到雙向編碼的效果。NSP可以看作是句子級的二分類問題,通過判斷后一個句子是不是前一個句子合理的下一句來挖掘句子間的邏輯關系。
1.2 BiGRU
GRU是RNN的變體,由Dey等[20]提出,其獨特的門控結構解決了傳統RNN梯度彌散和梯度爆炸的問題。GRU由更新門和重置門構成,前一時刻隱層輸出對當前時刻隱層狀態的重要程度由更新門控制,更新門的值越小代表前一時刻的輸出對當前的輸入影響越小;重置門用于控制前一時刻隱層狀態被忽略的程度,重置門的值越大代表前一時刻信息被遺忘越少,具體結構如圖3所示。

圖3 GRU網絡模型Fig.3 GRU network model
其中,xt表示t時刻的輸入;zt表示t時刻的更新門;rt表示t時刻的重置門;ht-1表示上一時刻隱層的輸出;σ表示Sigmoid函數;表示t時刻的候選隱層狀態;ht表示t時刻的隱層狀態。具體計算過程如式(1)~式(5)所示:
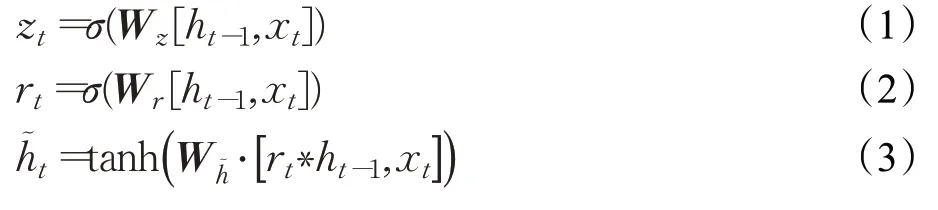

其中,Wz是更新門的權重矩陣;Wr是重置門的權重矩陣;Wo是輸出門的權重矩陣;Wh~是候選隱層狀態的權重矩陣;·表示矩陣相乘。
BiGRU由向前和向后的GRU組合而成,可以同時捕獲正向和逆向的語義信息,結合上下文來深層次提取文本所蘊含的情感特征。
1.3 Attention機制
Attention機制就是一種在關鍵信息上分配足夠的關注度,聚焦重要信息,淡化其他不重要信息的機制。它通過模擬大腦的注意力資源分配機制,計算出不同特征向量的權重,實現更高質量的特征提取。Attention機制的基本結構如圖4所示。
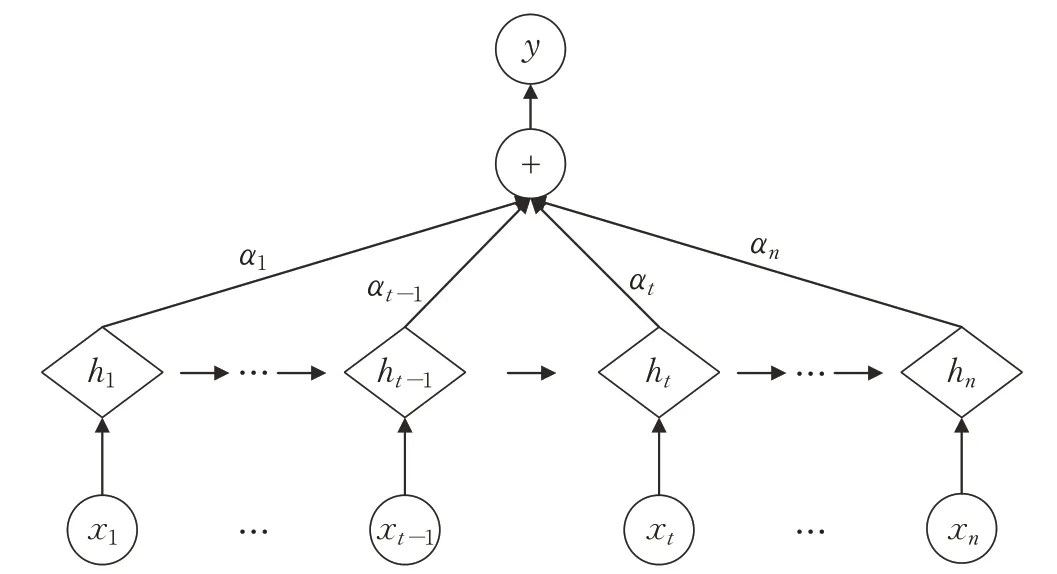
圖4 Attention機制基本架構Fig.4 Attention mechanism basic structure
Attention機制的具體計算過程如式(6)~式(8)所示。

hi表示隱層初始狀態,ei表示hi所具備的能量值;Vi、Wi表示權重系數矩陣;bi表示偏置向量;αi表示hi對應的權重。
1.4 模型結構
本文在上述基礎上提出融合BERT和層次化Attention的BERT-HAN微博情感分析模型,如圖5所示,主要由以下部分組成:
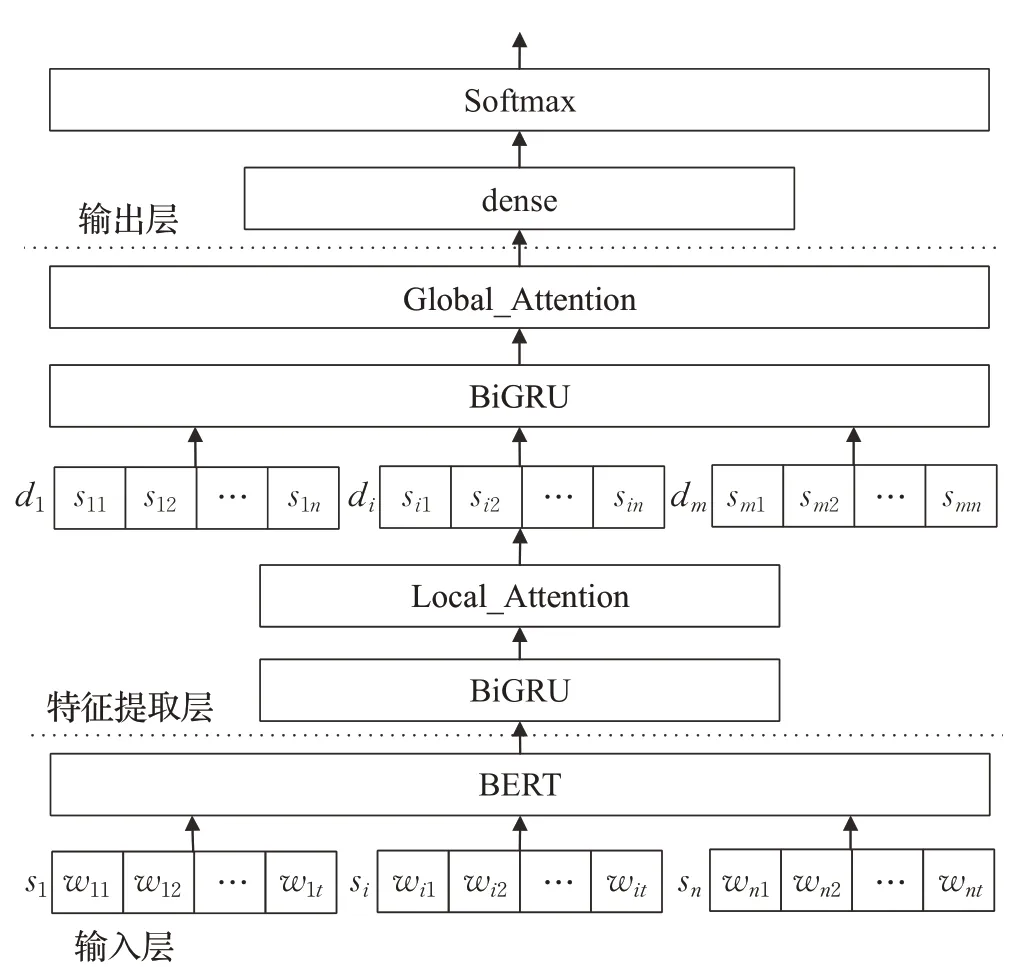
圖5 BERT-HAN模型結構Fig.5 BERT-HAN model structure
(1)輸入層。即文本向量化輸入層,將微博文本轉換成BiGRU能夠接收并處理的序列向量。本文采用SMP2020微博情緒分類測評數據集,對其進行全角轉半角、繁轉簡、去除url和email及@等預處理。另外數據集中存在以“[]”標記的文字表情符,具有明確的情感表達,需要保留該類型數據,結合上下文語義進行分析。考慮到微博書寫較為隨意,存在大量音似、形似錯字,調用pycorrector中文文本糾錯工具進一步優化數據集。文本d由n個句子組成,即d={s1,s2,…,sn},每個句子由t個字組成,第i個句子si可以表示為si={wi1,wi2,…,wit},其中w代表字。通過BERT預訓練語言模型得到每個字的向量表示,即xit表示第i句話的第t個字。
(2)特征提取層。特征提取層的計算主要分四個步驟完成:
①將向量化的句子序列xi1,xi2,…,xit作為BiGRU的輸入,進行深層次特征提取。BiGRU由正向GRU和反向GRU兩部分組成,通過上文和下文更全面地對句子語義進行編碼。計算過程如式(9)~式(11)所示:

②對上一層的輸出施加局部Attention機制,目的是捕獲一個句子中情感語義貢獻較大的字。首先選取長度為L=[pi-D,pi+D]=1+2D的滑動窗口,其中pi表示中心字,D表示設定的上下文窗口大小,通過計算窗口內中心字與其余字的相似度得到每個字的權重αit,具體計算過程如式(12)~式(14)所示:
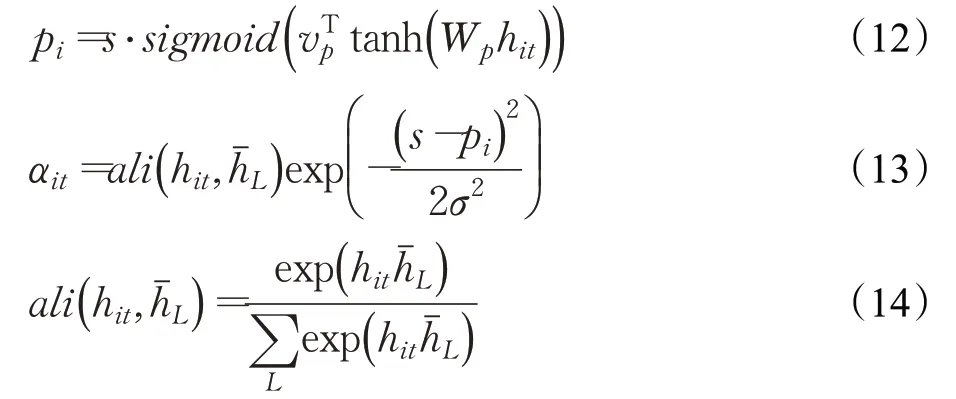
其中,s表示句子的長度,vp和Wp是用來預測位置的模型參數表示上下文窗口內除中心字外的隱層狀態。最后,將每個字的向量表示hit和相應的權重αit加權求和得到最終的句子表示Si,具體計算過程如式(15)所示:

③篇章由句子構成,將句子向量Si輸入BiGRU網絡,深層次挖掘句子間的邏輯關聯,實現整段文本信息的特征提取,計算過程如式(16)~式(18)所示:

④對上一層的輸出施加全局Attention機制,目的是突出整段文本中重要的句子。首先由單層感知機得到Gi的隱含表示Hi,然后通過計算Hi和上下文向量Us的相似度得到每個句子的權重αi。上下文向量Us通過隨機初始化得到,并作為模型的參數一起被訓練。最后將每個句子的向量表示Si和相應的權重αi加權求和得到最終的篇章表示D,計算過程如式(19)~式(21)所示:

其中,Ws表示權重矩陣,bs表示偏置。
(3)輸出層。通過Softmax函數進行情感分類,計算過程如式(22)所示:

其中,D表示特征提取層的輸出向量,W表示權重矩陣,b表示偏置。
2 實驗與分析
2.1 數據集
本文使用的數據集是由中國中文信息學會社會媒體處理專委會主辦,哈爾濱工業大學承辦的SMP2020微博情緒分類技術測評比賽提供的4.8萬余條微博數據。該數據集包含兩大類主題,分別是通用(usual)與疫情(virus),每個主題被標記為happy、angry、fear、sad、surprise和neutral六類情感。數據集分布如圖6所示,其中happy、angry、neutral占數據的主要部分,其余類別數量較少。

圖6 數據集分布Fig.6 Data set distribution
部分樣例如圖7所示。對原始數據整理、合并后,按8∶2劃分訓練集和測試集,使用五折交叉驗證法進行多次實驗,取平均值作為最終實驗結果。

圖7 部分樣例數據Fig.7 Part of sample data
2.2 實驗環境
實驗環境如表1所示。
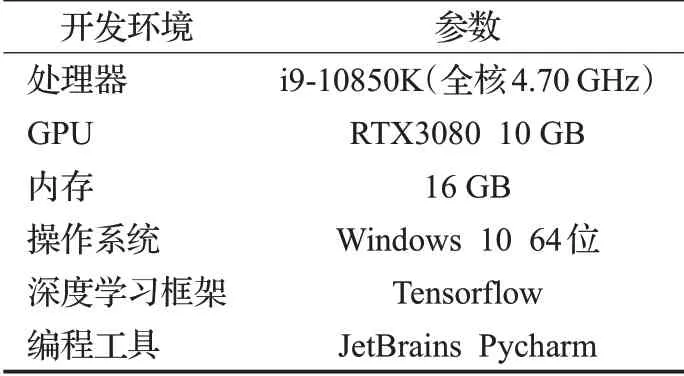
表1 實驗環境Table 1 Experimental environment
2.3 參數設置與評價標準
本文模型BERT-HAN涉及眾多參數設置。輸入層采用Google發布的預訓練好的中文模型“BERT-Base,Chinese”,該模型采用12層Transformer,隱層的維度為768,Multi-Head-Attention的參數為12,激活函數為Relu,模型總參數大小為110 MB。特征提取層主要由BiGRU和Attention構成,兩個BiGRU的隱層節點數均為128,局部Attention機制的上下文窗口D取5。
模型訓練方面,設置批次大小為32,學習率為1E-5,最大序列長度為140,優化器為Adam,防止過擬合的dropout率為0.6。
采用Macro F1和Micro F1作為模型評價標準。
2.4 實驗分析與討論
本文設計了2組對比實驗來驗證BERT-HAN模型的有效性。
第1組 不同詞向量模型的對比實驗。為了驗證BERT預訓練模型具有更好的向量表征能力,本文與其他三種詞向量模型在相同的實驗環境下以SMP2020作為數據集進行對比分析,實驗結果如表2所示。
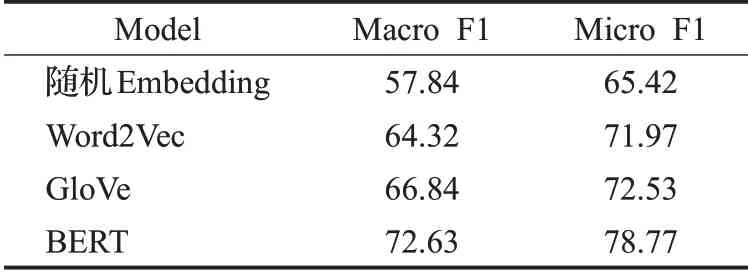
表2 不同詞向量模型的性能對比Table 2 Performance comparison of different word embedding models %
從表2可以看出,相比隨機Embedding、Word2Vec、GloVe,使用BERT預訓練模型可以明顯提高Macro F1和Micro F1值,分析其原因,BERT可以根據上下文語境動態地生成字向量,不僅解決了一詞多義問題,還避免了分詞可能造成的歧義,從而得到更符合原文語義的向量表征。
第2組 不同特征提取方法的對比實驗。為了驗證本文方法BERT-HAN在微博情感分析上的有效性,在相同的實驗環境下以SMP2020作為數據集,與4個常見模型進行對比分析,實驗結果如表3所示。

表3 不同模型的性能對比Table 3 Performance comparison of different models %
(1)BERT-LSTM:使用BERT生成字向量,送入LSTM網絡提取特征,用Softmax進行情感分類。
(2)BERT-BiLSTM:使用BERT生成字向量,送入BiLSTM網絡提取特征,用Softmax進行情感分類。
(3)BERT-BiGRU:使用BERT生成字向量,送入Bi GRU網絡提取特征,用Softmax進行情感分類。
(4)BERT-BiGRU-Attention:使用BERT生成字向量,送入BiGRU網絡提取特征,引入一層Attention機制對特征分配權重,用Softmax進行情感分類。
(5)BERT-HAN:使用BERT生成字向量,通過兩層BiGRU分別得到句子表示和篇章表示,在句子表示層引入局部Attention機制,在篇章表示層引入全局Attention機制,最后,通過Softmax進行情感分類
從表3可以看出,本文提出的BERT-HAN模型在Macro F1和Micro F1上的表現均優于其他四種模型。對比實驗1和2可以看出,BERT-BiLSTM模型較BERTLSTM模型的Macro F1和Micro F1分別提升了3.37個百分點和4.17個百分點,說明雙向LSTM可以結合上文信息和下文信息進行特征提取,提升了分類效果。對比實驗3和4可以看出,引入Attention機制可以對提取的特征進行權重分配,從而突出重要信息,進一步提升了模型的分類性能。對比實驗4和5,層次化Attention機制較單一的詞語層Attention機制,Macro F1和Micro F1分別提升了4.84個百分點和2.62個百分點。分析其原因,單一的詞語層Attention機制只能捕獲整段評論中的關鍵字,而層次化Attention機制加強了模型對文本層次結構的關注,不僅能夠捕獲每句話中的關鍵字,還能捕獲整段評論中的關鍵句子,從字和句子兩個層面綜合判斷文本的情感傾向,從而在微博情感分析上擁有更好的表現。對比各實驗結果,本文提出的BERT-HAN模型在Macro F1和Micro F1兩個評價指標上較其他模型分別平均提高8.71個百分點和7.08個百分點,具有較大的實用價值。
3 結束語
針對現有微博情感分析模型普遍采用分詞技術結合Word2Vector或GloVe等靜態詞向量模型生成文本的向量表示,不能很好地解決一詞多義問題,且未能充分考慮文本層次結構的重要性,提出一種基于BERT和層次化Attention的微博情感分析模型BERT-HAN。該模型首先通過BERT生成蘊含上下文語意的動態字向量,然后通過兩層BiGRU分別得到句子表示和篇章表示,引入層次化Attention從字和句子兩個層面綜合判斷微博文本的情感傾向。實驗結果表明,相比其他詞向量模型,BERT的向量表征能力更強大,且層次化Attention增強了模型對文本層次結構的捕獲能力,進一步提升了微博情感分析的性能,具有較大的實用價值。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年9期)2015-11-10 03:11:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
